PPPT:利用推拉相变对抗GossipSub开销 - 网络
- 以太坊中文
- 发布于 2025-04-10 22:41
- 阅读 1338
本文提出了一种名为PPPT(Push-Pull Phase Transition)的GossipSub优化方案,旨在减少p2p网络中消息传播时的带宽开销,特别是重复消息带来的冗余。PPPT通过结合push和pull模式,并根据节点与消息源的距离(跳数)动态调整传播策略,在延迟和带宽利用率之间取得更好的平衡,从而优化GossipSub协议的性能。

PPPT: 使用推拉式相位转换对抗Gossipsub的开销
作者: @cskiraly
注意: PPPT的早期版本和本文讨论的算法于2024年5月在我们的FullDAS文章中介绍。一个带有测量的版本也在2025年1月进行了展示,并以幻灯片形式传播。
最近, 几个研究小组开始研究类似的主题,同时在各种讨论论坛上分享想法。其中一项出色的工作刚刚以“GossipSub v2.0”的名义发表。ProbeLab团队也参与了相关的标准化工作。我们没有在本文中对这些方法进行直接比较,而是留待进一步讨论(例如,在下面的评论中)。
在我们之前的文章中,我们介绍了批量发布,显示了DAS分散中显著的延迟改进,对抗了发布者的带宽瓶颈。
即使在源头实现了批量发布,由于重复数据,GossipSub在p2p重新分发期间仍然存在大量带宽开销。在这篇文章中,我们解决了这个担忧,展示了减少甚至消除这种开销的技术。
当然,没有免费的午餐。这里介绍的技术带有妥协,我们也将详细说明。
GossipSub的开销
GossipSub被引入作为一种_“具有适度放大因子和良好扩展性能的通用pubsub协议”_。虽然它的带宽效率比简单的FloodSub好得多,但它仍然具有显著的带宽开销,引起了对一些以太坊用例的担忧。
GossipSub基于两种主要技术,我们在本文中称之为推送(push)和拉取(pull)。
-
对于任何给定主题,GossipSub构建一个近似度为D的随机网格,并主动地沿着这个网格推送消息。
-
它还在更大的邻域图上发布“HAVE”元数据(这是GossipSub的gossip部分,使用所谓的IHAVE消息),并通过基于此信息拉取来恢复丢失的消息。
在GossipSub的基本版本中,PUSH用于快速传播,而PULL仅用于恢复损失。一个节点从一个peer接收到消息后,会将其排队,以便发送给其所有D-1个mesh peer(D-1,因为它不会发回给它接收消息的peer)。这是首次接收时的行为。其他接收被认为是重复的,并且很容易被过滤掉。我们试图在这里回答的问题是:
我们有多少重复数据,我们能做什么来在性能上没有(或少量)牺牲的情况下减少这个数量?
重复次数与副本数
有时,考虑副本比考虑重复数据更容易。如果一个节点收到C个消息副本,只有第一个是有用的,而其余C-1个是重复的。
发送的副本数
很明显,每个订阅该主题的N个节点都将有“第一次接收”,之后它会发送D-1个副本,因此我们将在整个系统中总共发送N * (D-1)个副本。在所有这些副本中,只有N-1个是有用的,其他的都一定是重复的。
接收的副本数
一个节点接收到的平均副本数也将相同:D-1,仅仅因为将所有节点发送和接收的消息数相加,我们得到相同的数字。然而,D-1只是平均值。接收到的副本数可能因节点而异。事实上,它介于1和D之间(实际上,节点度数可能略微偏离D,因此接收到的副本数也可能略微偏大)。
哪些是幸运地收到少量重复数据的节点?
直觉很简单:当消息首先由源发送出去时,D个节点将收到它。这些节点是在第一跳中收到它的节点。由于网格的随机构建,这些节点成为mesh邻居的概率相当低。这D个节点中的两个发送到同一节点的概率也很低。所以当它们发送给它们的所有邻居(除了返回给源)时,第二跳节点将全部获得它们的第一个副本,并且不发回。因此,我们的第一跳节点几乎不会收到重复数据。我们有比第一跳节点更多的第二跳节点,其中一些(但很少)会相互连接,并且它们的一些邻居(第三跳)也将是共同的。等等。
在扩散过程的最后,经过许多跳之后,情况非常不同。一个在例如5跳后第一次收到消息的节点仍然将其发送给其他D-1个节点,但是这些邻居已经是收到消息的节点的概率(即消息是重复的)相当高。
跳数与接收到的重复数据
虽然跳计数器不是标准GossipSub消息结构的一部分,但我们已经修改了nim-libp2p代码以包含一个,因此我们可以轻松收集有关每个跳计数接收到的重复数据分布的信息。更准确地说,我们使用第一个接收到的副本的跳计数器,它是与源的某种图形距离。一个节点稍后也会收到其他副本,最可能具有更大的跳计数(尽管由于不同的链路延迟,较小的跳计数也是可能的)。为简单起见,我们在这里使用第一次接收的跳计数器,而不是最短路径。
请注意,此跳计数器用于我们实验中的测量目的,不用于实际应用(稍后请参阅隐私问题)。
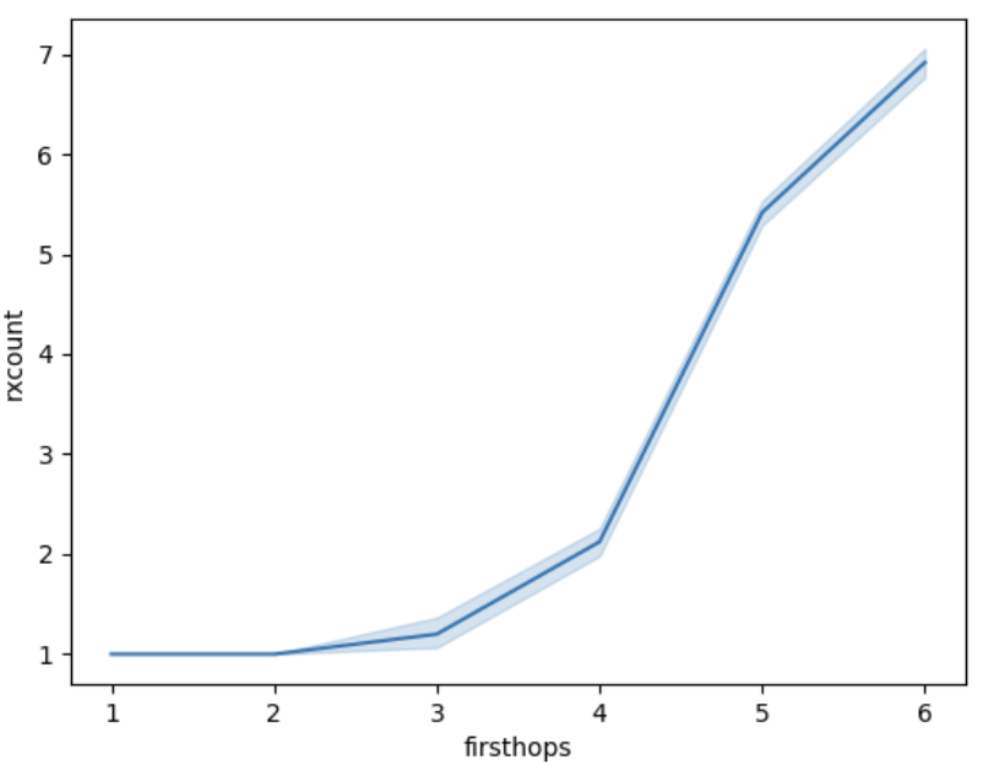
下图显示了接收到的消息副本数量的分布,作为节点与源的距离的函数(firsthops:遇到的第一个跳计数器值)。
 \
rxcount_push990×766 58.7 KB
\
rxcount_push990×766 58.7 KB图1: 每个peer接收到的消息数量(1 + 重复数据),作为peer与消息源的跳距离的函数。
正如我们所看到的,节点接收消息越晚(firsthop计数越大),在此第一次接收之后它获得的重复数据就越多。如果我们将节点数量也几乎以指数方式随着firsthop计数增长这一事实添加到其中,就很清楚的是,要消除重复数据,我们应该从扩散的后期阶段删除它们。在下文中,我们将比较几种尝试实现此目的的方法,但在进入那里之前,我们展示了没有重复数据发生的极端情况。
拉取模式
消除重复数据的最简单方法是仅使用PULL模式。一旦收到消息,一个节点会向其peer发送D-1条IHAVE消息。这是对协议的一个小但非常简单的修改。在拉取模式下,每个跳都需要更多时间,因为IHAVE (A->B),IWANT (B->A),然后消息本身 (A->B) 增加了3倍的延迟,而不是简单的PUSH。IHAVE和IWANT也增加了额外的流量字节,但这可以忽略不计,具体取决于消息大小。
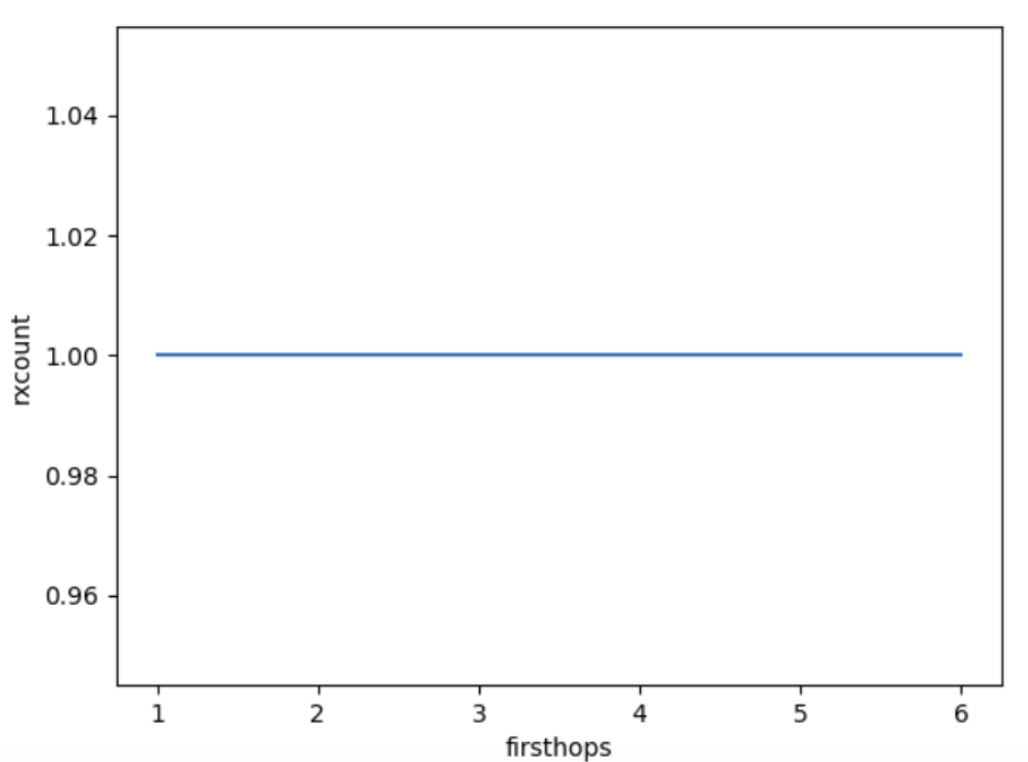
下图显示了拉取模式下重复数据与firsthop计数的关系。相当无聊。
 \
duplicates_pull1028×762 24.7 KB
\
duplicates_pull1028×762 24.7 KB
图2: 使用纯拉取时,每个peer接收到的消息数量(1 + 重复数据)。只是为了显示与推送的区别,否则很无聊。
基于延迟的抑制
除了从PUSH切换到PULL之外,我们还有另一种方法来减少开销:只需避免发送即可。
大部分重复数据实际上是由于消息在同一A - B链接上双向传输造成的。如果我们在转发之前添加一个小的(\delta)延迟,则可能会收到一些重复数据,然后我们可以避免在这些链接上发回,从而发送少于D-1个副本。请注意,IDONTWANT在这方面起作用,甚至在验证消息之前,就在转发之前发送一个小的“警告”。
如果在此时间范围内收到重复数据,我们不会在这些链接上发回。因此,我们的一些节点将发送少于D-1个副本。请注意,由于GossipSub消息验证延迟,所有实现中都会发生一些等待。Nim实现已经使用此延迟来抑制发送消息,而其他一些实现则没有这样做。
理解延迟-带宽权衡
通过以上所有介绍,我们现在已经达到了可以绘制纯PUSH和纯PULL这两个极端之间的权衡空间的地步,并为决策逻辑添加了延迟。
我们介绍了四种不同的策略,每种策略都有一个参数,允许我们“调整”权衡。
-
等待 (\delta): 我们能做的最简单的事情就是在接收后等待\delta时间,然后再发送副本。如果在此时间范围内收到重复数据,我们不会在这些链接上发回。因此,我们的节点可以发送少于D-1个副本。请注意,由于gossipsub消息验证延迟,所有实现中都会发生一些等待。Nim实现已经使用此延迟来抑制发送消息,而其他一些实现则没有这样做。(suppressNone)
-
等待并拉取 (\delta): 在此策略中,我们再次等待\delta时间,但是如果收到重复数据,我们不仅会抑制发送。我们还切换到PULL模式,在所有剩余链接上发送IHAVE。(SuppressIfSeen)
-
推送-拉取 (d): 在此策略中,我们有D个邻居,但我们仅向这些邻居的子集PUSH,而对其余邻居使用PULL模式。我们使用d参数来设置权衡,推送到d个随机选择的peer,而向其余peer发送IWANT。(suppressAbove)
-
推拉式相位转换 (d), 或 PPPT: 在我们的最后一个变体中,我们依赖于跳计数器。当一个节点第一次收到跳计数值为h的消息时,它会发送max(0, d-h)个PUSH,并PULL其余的消息。(suppressOnHops)
请注意,只有最后一个使用跳计数器,其余的都可以在不修改消息格式的情况下实现(我们在代码中使用跳计数器来收集统计信息)。公开跳数是一个有争议的话题,我们将在后面更详细地讨论。
模拟场景
为了得出性能指标,我们使用我们基于Shadow和nim-libp2p的模拟器。我们使用以下参数运行模拟:
-
1000个节点订阅了该主题
-
1KB的小消息大小
-
将节点带宽限制为对称的20 Mbps。
-
p2p延迟:之前的图是节点之间统一的50毫秒延迟,以简化Push与Pull效果的表示。但是,这种统一性会产生副作用,因此在以下图中,我们使用从真实互联网测量中得出的延迟 (RIPE Atlas数据库),将我们的每个节点映射到地球上的随机位置。平均延迟为62毫秒,但是有很多链路比这快得多。
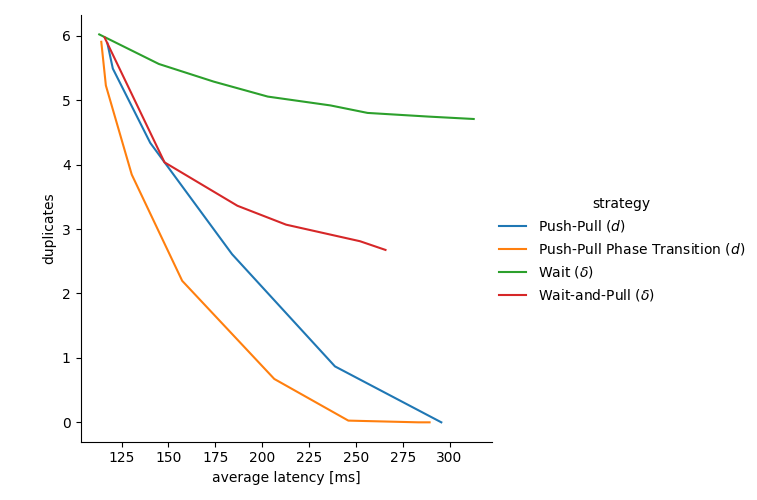
下图显示了重复数据和接收延迟之间的权衡空间,其中的点表示根据两个指标,给定策略使用给定参数的性能:
-
x轴显示实现的平均传递延迟(我们可以为例如第95个百分位延迟绘制类似的图)。较小的值更好,纯PUSH在左侧,纯PULL在右侧。
-
y轴表示平均副本数。较小的值更好,纯PULL在底部(收到1个副本),纯PUSH在顶部(平均收到大约D-1个副本)。
当我们更改每种策略的相应参数时,我们可以绘制其在重复数据和延迟之间进行折衷的权衡曲线。例如,绿色曲线的最左边的点表示没有等待(\delta=0),而最右边的点显示,当我们等待\delta=70毫秒后再转发消息时,重复数据减少但延迟增加。
类似地,对于其他曲线,最左边的点是我们设置参数使得策略未被触发时。这意味着Wait-and-Pull的(\delta=0)和Push-Pull和Push-Pull相位转换的d的大值(大于D)。
 \
duplicate_suppression_strategies757×500 30.3 KB
\
duplicate_suppression_strategies757×500 30.3 KB
图3: 接收到的平均副本数(即带宽利用率)与平均接收延迟之间的权衡。每条曲线代表一种策略,而曲线上的点代表策略的不同参数化。
等待 (\delta) 的效果最差,增加了延迟,同时仅略微减少了重复数据的数量。
等待并拉取 (\delta) 取得了明显更好的结果。实际上,在很短的时间内获得重复数据可以用作处于扩散过程后期的估计量,而无需显式的跳计数器。
即使它是不需要估计器或跳计数的固定策略,推送-拉取 (d) 也能提供令人印象深刻的收益。
最后,PPPT的性能优于之前的任何策略,使我们能够以较小的延迟增加消除几乎所有重复数据,并在延迟加倍时消除所有重复数据。
讨论
上面介绍的策略只是可能的策略的大量示例。这些策略的组合和变体可以很容易地得出。我们不知道有一种通用理论可以提供某种最佳方案,尤其是在互联网的异构环境中。
虽然我们的研究是初步的,并且可以评估更多内容(不同的节点计数;不同的消息大小;不同的带宽限制;等等),但我们已经可以强调一些方面:
跳计数器的优势是显而易见的
很明显,添加跳计数器可以显着减少重复数据,同时保持较低的延迟。在详细分析了系统中重复数据的位置之后,这不足为奇,它只是证实了跳数实际上是从推送切换到拉取的良好触发因素。
固定策略的性能一点也不差
更令人惊讶的是(至少对我而言),固定策略的性能也相当合理,尽管性能曲线显然受到没有跳数信息的影响。
跳计数和隐私
还应该清楚的是,跳计数会损害发布者的隐私……如果一开始就存在的话。我们认为,libp2p和GossipSub的用途是不需要考虑发布者隐私的。即使在以太坊用例中,通常也很容易对发送者进行去匿名化,并且在这些情况下,跳数并没有使其变得更加容易。
跳计数可以被欺骗
跳计数的另一个缺点是很容易在上面撒谎。此外,跳数不应成为peer评分的一部分,因为它会进一步激励作弊。但是,我们认为这并不是一个根本问题,因为谎报跳数的节点只会减慢(或加快)其自己的扩散树子树的速度,而不会产生全局影响。
GossipSub用例是不同的
我们提出了重复数据缓解策略,作为权衡空间的原因:即使在以太坊中,GossipSub也有许多用例(更不用说以太坊之外的用途了)。可以为不同的用例(或主题,或消息大小)选择不同的策略和参数。
关于基于RTT优化邻域
也许还值得一提的是,我们关于第一跳中没有重复数据的推理假设了随机邻域。通常(在文献和对话中)有基于测得的RTT优化邻域的想法。不幸的是,这种优化具有改变覆盖图结构的副作用,从而导致第一跳中出现更多的重复数据,并导致更大的直径。可以仔细设计基于RTT的优化,但重要的是要注意这些副作用。
IHAVE流量开销
在我们的图中,我们计算了消息副本,但没有计算IHAVE消息的开销。这种简化是否合理取决于消息大小及其与消息ID及其在IHAVE消息中的编码的关系。我们注意到,可以进行一些优化来移动这里的指针。
-
如果链接上有很高的消息频率,则可以以小的额外延迟为代价将它们的单个IHAVE消息聚合在单个消息中。
-
这种IHAVE聚合也可以在多个主题上执行,并具有受控的额外延迟。
-
在某些用例中,如果消息可以从结构化消息ID空间接收ID,则也可以压缩此类聚合的IHAVE消息。DAS就是这种情况,我们提出了基于位图的IHAVE消息,但是基于位图的压缩也可以用作更通用的工具。
如何重现
跳数和所有策略都已作为nim-libp2p的一部分实现,并将在后续的branch中发布。
我们的模拟框架还进行了一些临时更改以适应这些模拟,这些更改也将作为后续操作发布。
- 原文链接: ethresear.ch/t/pppt-figh...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





