【草案】Sunnyside Devnet更新 - 09/29
- testinprod
- 发布于 2025-09-03 23:28
- 阅读 1058
本文是Sunnyside Devnet的更新报告,分析了在接近主网1/8规模的网络中,blob吞吐量、网络使用情况、GetBlobsV2指标、CPU和RAM使用率等关键性能指标。报告指出,全节点的上行链路带宽是限制因素, EL P2P的峰值成为比预期更大的波动来源。并建议关注上传带宽、P2P网络和客户端的异常值,以便安全地扩展BPO。
[草案] Sunnyside Devnet 更新 - 09/29
你可以在这里找到所有已发布的报告:
总览
约 1700 个节点的 devnet(主网的 1/8)维持了约 22/33 个 blob 并且运行在约 48/72 个 blob;fullnode 上的上行链路限制(50Mbps)经常被达到。
在 22/33 → 48/72 个 blob 之间,网络使用量翻了一番;supernode 的 column gossip 大约是 fullnode 的 16 倍,而 EL P2P 使用对 fullnode 而言变得更加沉重。
在规模上,EL P2P 峰值超过了 column gossip 峰值,增加了不稳定性;来自 column gossip 的上传峰值较为温和,可能是因为更高的 CL 对等节点计数(100-200)。
GetBlobsV2 的可靠性随着 blob 数量的增加而下降;Geth/Nethermind 显示出比命中率更高的可用性(暗示了部分 blob),而 Reth 明显有所改善。
与较小的 devnet 相比,CPU/RAM 使用率上升了约 10%;一些验证器在同步期间显示出压力;许多非验证器达到了 90%+ 的 RAM(在低于 EIP-7870 指导的 8GB 设置上)。
简介
与 EthPandaOps 合作
这次部署了近 1700 个节点来模拟大约 1/8 的主网,Sunnyside & Base 提供了近 800 个节点。我们相信,在 Fusaka 之前,以这样的规模运行将给予 blob 扩展最接近的近似值之一。
我们的目标是提供我们对 blob 扩展的分析和观点:blob 吞吐量、瓶颈和硬件要求,以及 PandaOps 的深入分析。PandaOps 的分析为我们提供了充分的理由,说明为什么我们可以高度自信地进行早期的 BPO,但他们发现从 20 个或更多 blob 开始,证明变得不太稳定,这让人怀疑是否可以在以后的 BPO 中扩展到超过 20 个 blob。
正如许多人预料的那样,我们认为满足 EIP-7870 的网络要求是主要的瓶颈之一,以及其他因素,这使得及时证明变得困难。同时,EF P2P 团队一直在建议,通过一些与分叉无关的更改,我们可能能够以更高的 blob 计数获得更高的稳定性。
让我们深入探讨与较小的 devnet 相比,大规模测试中的此类瓶颈和新发现,以帮助进一步制定 BPO 计划。
Devnet 信息
设置 & 配置
以下是 Sunnyside Lab 节点的设置。请查看  HackMDfusaka-devnet-5 spec - HackMD 了解总体规范。
HackMDfusaka-devnet-5 spec - HackMD 了解总体规范。
| 验证节点 | 非验证节点 | |
|---|---|---|
| 节点组合 | 所有 390 个 Lighthouse & <br>196 个 Teku DigitalOcean Fullnode | 所有 180 个非验证节点<br>(5 x 6 个 CL x 6 个 EL) |
| 硬件 | 8 个 vCPU / 16GB RAM / NVMe SSD | 4 个 vCPU / 8GB RAM / NVMe SSD |
| 带宽上限 | 50/25Mbps(PandaOps 有 100/50) | 50/15Mbps |
| 验证器分布 | 每个节点 8 个验证器 | N/A |
| Supernode 分布 | 没有来自 Sunnyside Labs 的 | N/A |
图片:
网络配置: GitHubfusaka-devnets/network-configs/devnet-5 at main · testinprod…
GitHubfusaka-devnets/network-configs/devnet-5 at main · testinprod…
测试场景
我们主要分析了 devnet 数据的最后 36 小时,包括前 24 小时的 blob 吞吐量,每块大约 22/33 个目标/最大 blob(相当于 BPO3 的值)和接下来的 12 小时的 ~48/72 个 blob(BPO5 值)。
这是最稳定的时期,具有高 blob 吞吐量,在修复和调试了大多数已知的客户端和设置问题之后。请注意,在分析时已经启用了 BPO5。
| 大致的目标/最大 Blob | 22/33 | 48/72 |
|---|---|---|
| 时间线 | 2025-09-17 19:00 ~ | 2025-09-19 10:00 ~ |
Sunnyside Labs Grafana Dashboard per BPO
结果
1. Blob 吞吐量
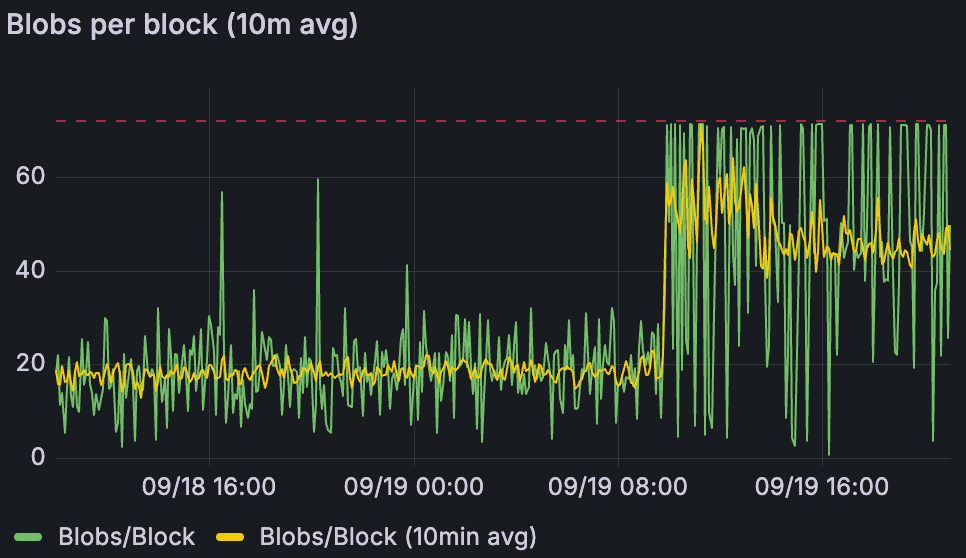
Blob 吞吐量保持在 ~22/33 个 blob,然后自 09/19 10:00 以来为 ~48/72 个 blob。
ALT
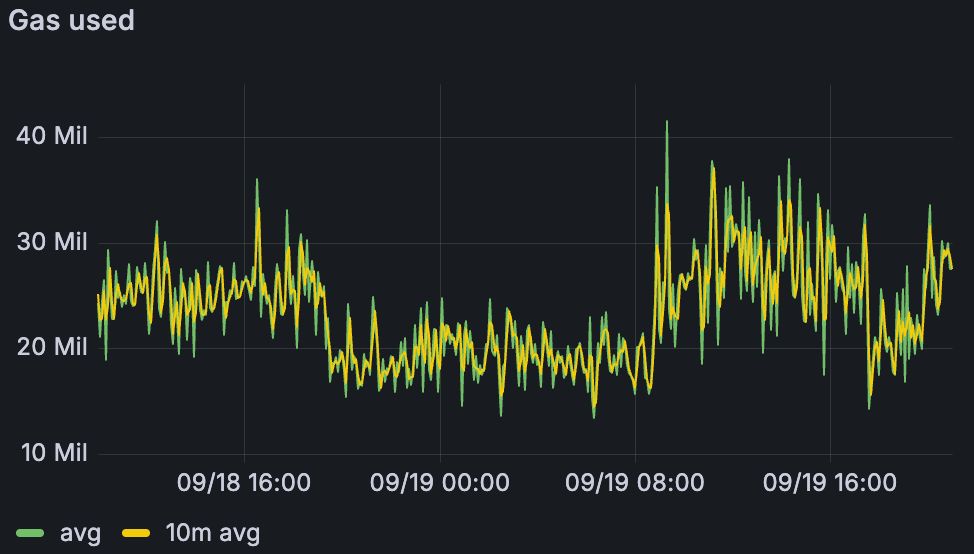
同一分析期间的 Gas 使用情况。最大值设置为 100M gas(峰值 ~46M)。
ALT
在一段时间内以相似的速率持续 spamming blob 使我们能够探索 blob 扩展中的潜在瓶颈,例如网络带宽使用、CPU & RAM 利用率、GetBlobsV2 和数据列 gossiping。
2. 网络使用情况
从我们的分析来看,网络带宽一直是 blob 扩展的主要阻碍之一。我们之前建议,当 fullnode 的 gossipsub 数据列 sidecar uploadburst 在增加的 blob 计数下持续达到带宽上限时,网络变得不稳定。
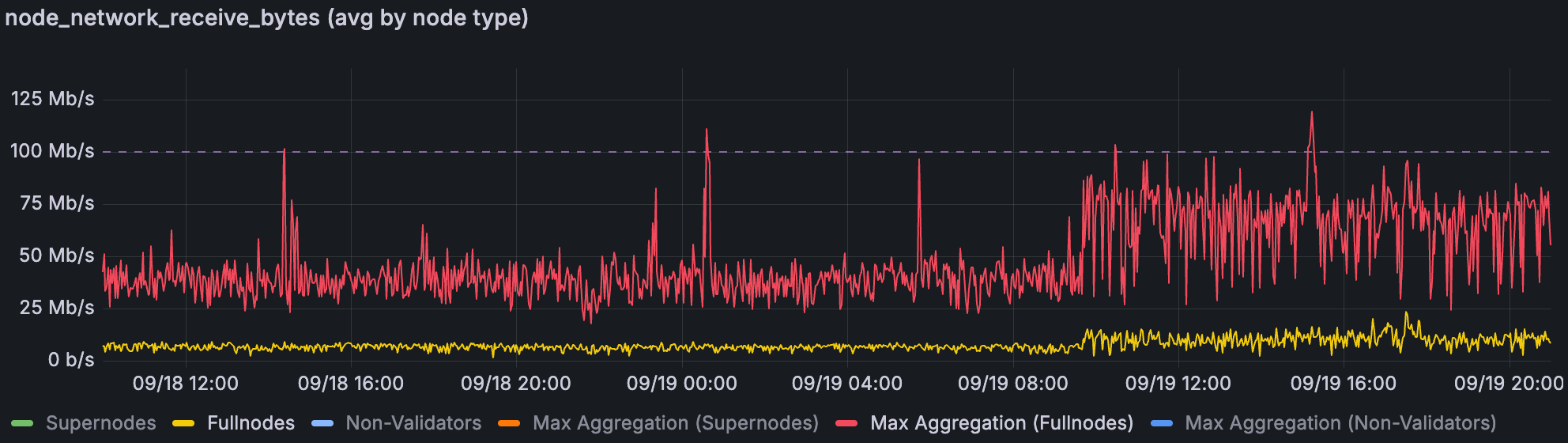
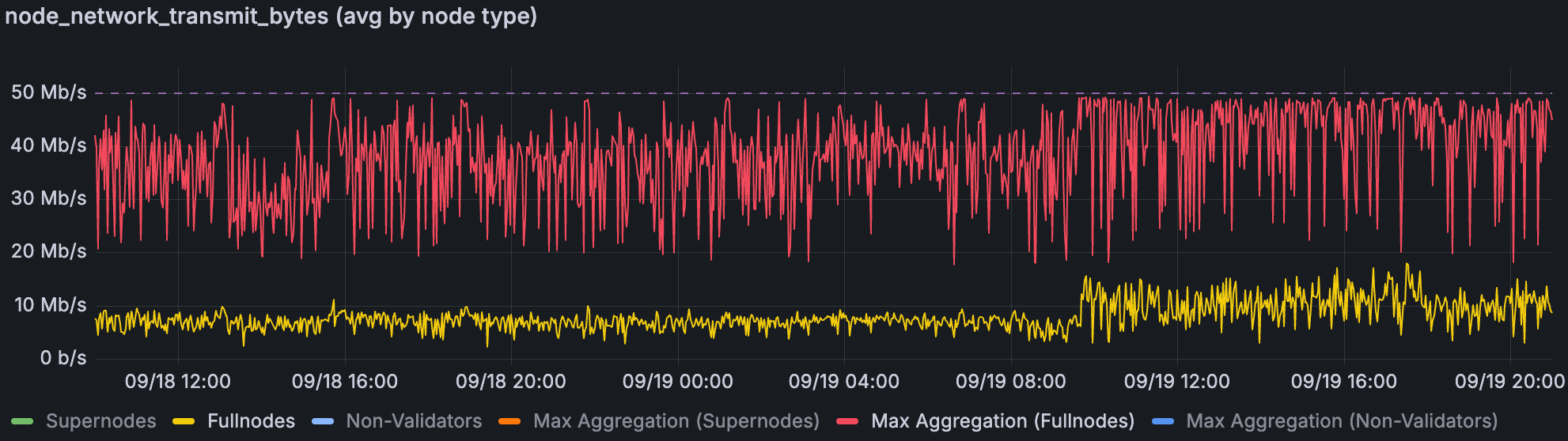
在 22/33 个 blob 和 48/72 个 blob 时的 Fullnode 上传带宽(从 ~09/19 10:00)。
ALT
在分析期间,我们可以看到,当我们于 9 月 19 日 10:00 左右提高到 48/72 个 blob 时,fullnode 上传已经有规律地达到 50Mbps 的峰值,并且非常频繁。另一方面,100Mbps 的下载上限足以处理流量。Supernode 在两个方向上都被限制为 1Gbps,这有足够的空间来满足它们的峰值使用。
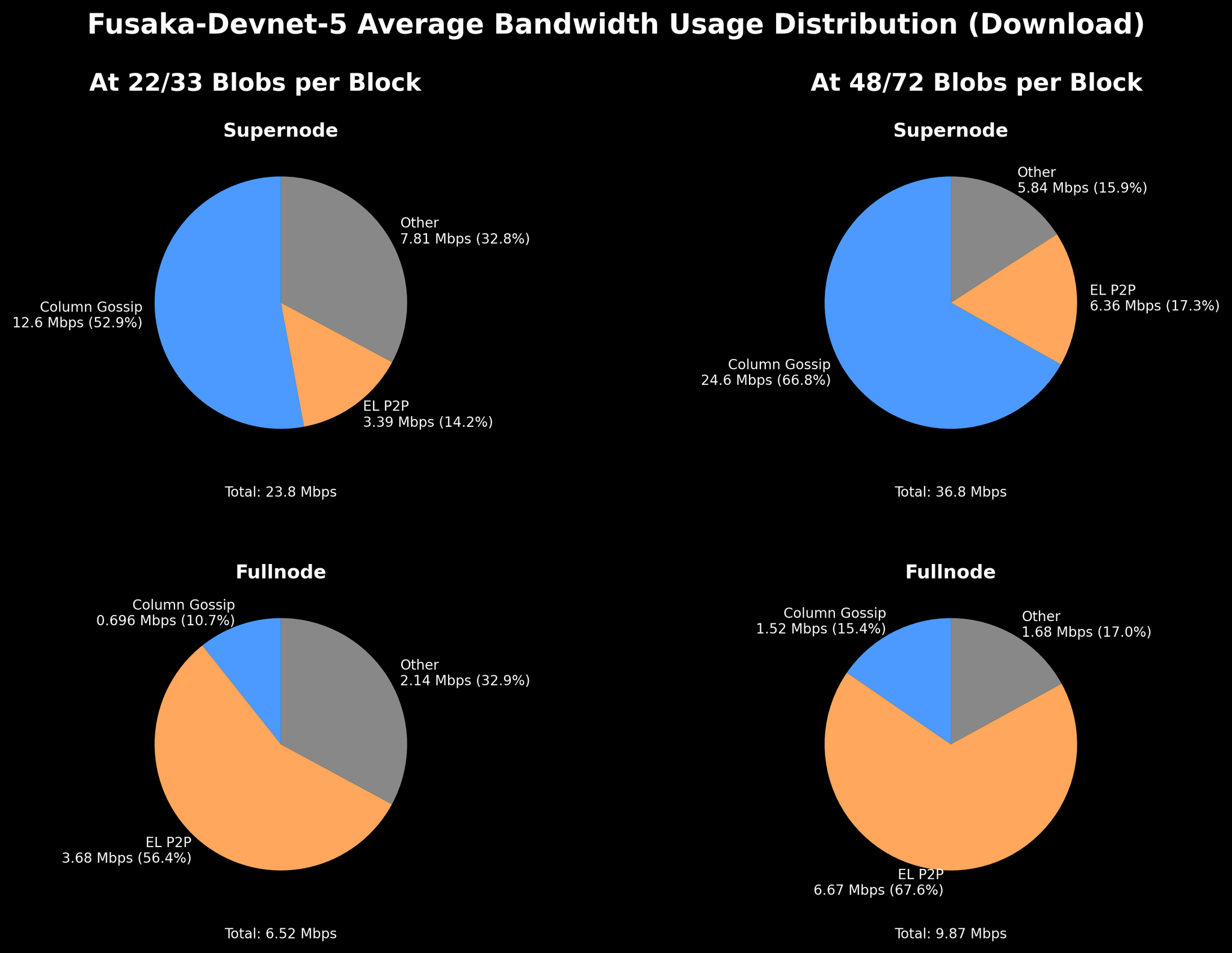
注意:上传具有相似的分布和使用情况。仅来自 Geth 和 Erigon 的 EL P2P 使用。“其他”部分是这三个指标的剩余部分。非验证器具有与 fullnode 相似的分布。
ALT
查看这些 blob 吞吐量下每个节点类型的网络使用分布,
大多数是 column gossiping 和 EL P2P,每种都与 blob 计数成比例增长(在 48/72 时大约是 22/33 的两倍)
Supernode 的 column gossip 是 fullnode 的 ~16 倍,这是合理的,因为 supernode 管理 128 列,而 fullnode 管理 8 列
跨节点类型的相似 EL P2P 使用(supernode 实际上在整个时间里略低)
考虑到 fullnode 的上传已达到最大容量,EL P2P 对 fullnode 造成了沉重负担。
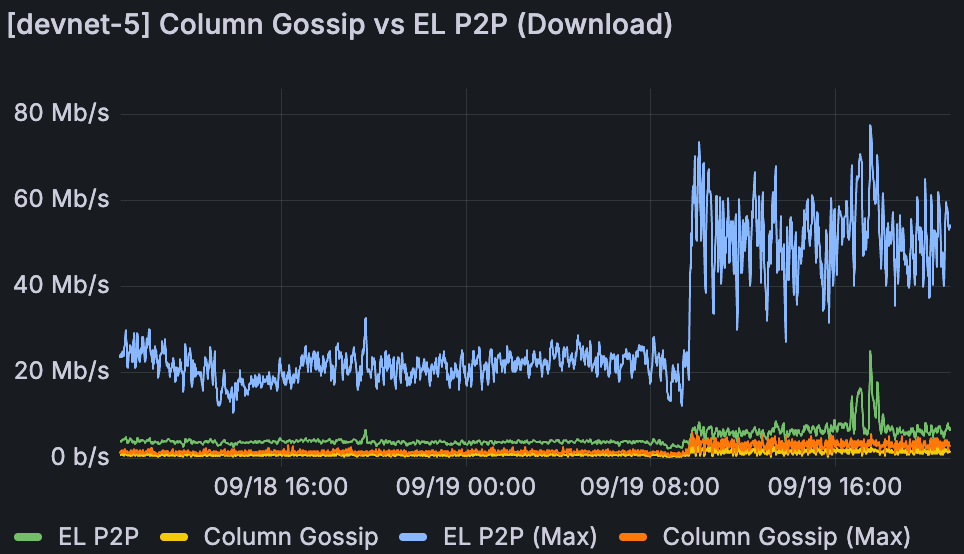
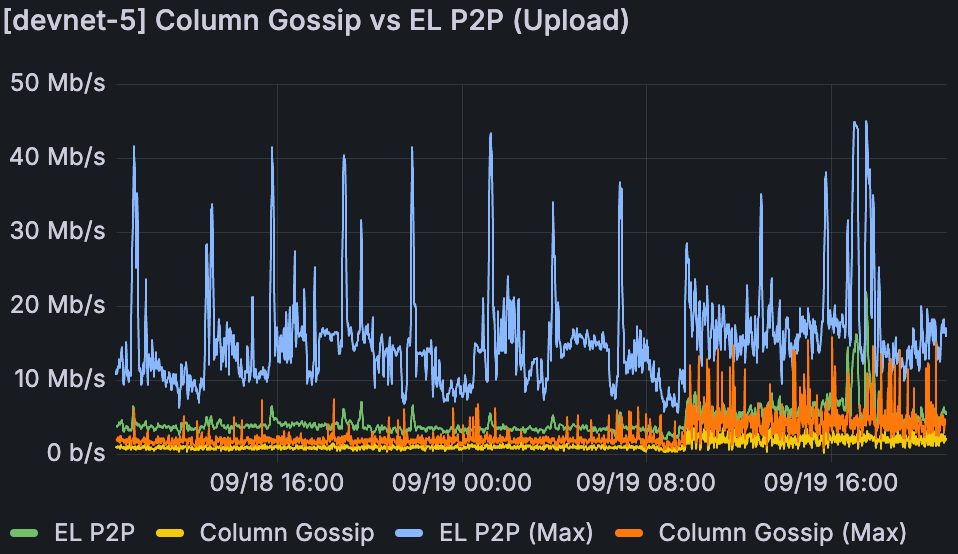
devnet-5 中 Fullnode 带宽使用情况,相同的分析期间。
ALT
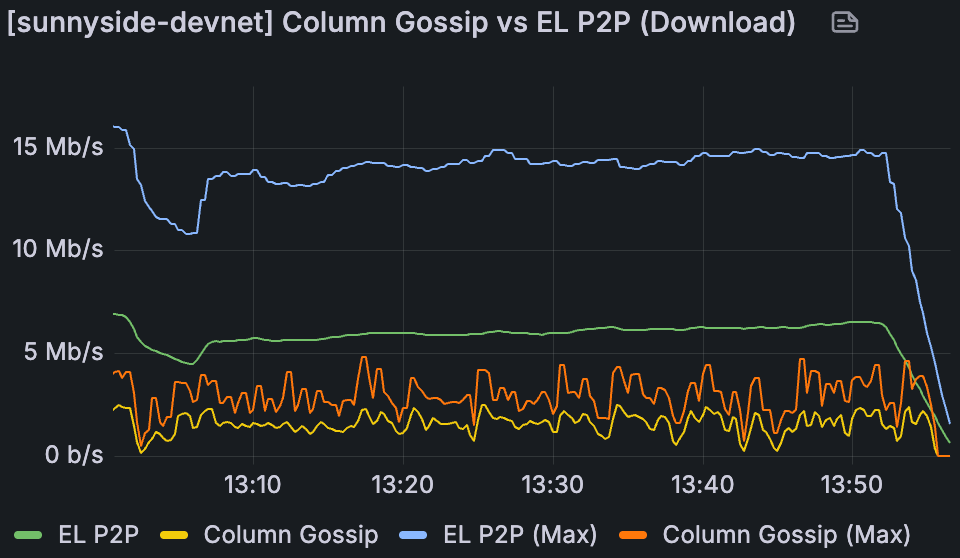
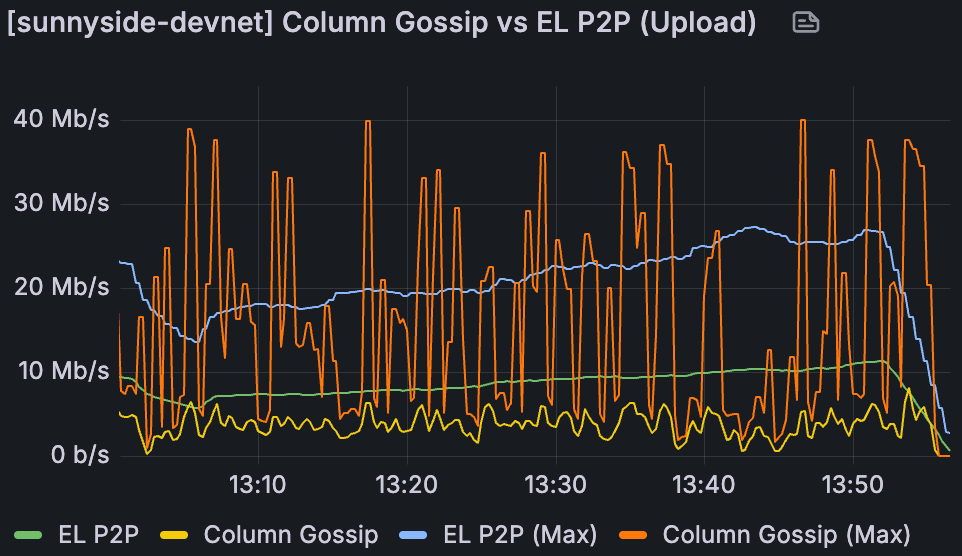
在最新的 Sunnyside devnet 之一的 60/72 个 blob 中,Fullnode 带宽使用情况,带宽不受限制。
ALT
来自执行层的 P2P 使用量在我们之前的 devnet 中也占了带宽消耗的很大一部分。
然而,其峰值在 devnet-5 中按比例放大更多,超过了 column gossiping 使用峰值,而 column gossiping 使用峰值以前是较小 devnet 中的主要问题。
即使我们必须考虑到 devnet-5 中进行了频繁的同步测试,但与较小的网络相比,使用通常变得更加不稳定。
有趣的是,column gossiping(上传峰值)在 devnet-5 中变得更加温和,也许是
更积极地与 EL 竞争带宽(因为 EL 已经达到带宽上限),或者
由于每个人都有更多的 CL 对等节点,因此每个节点需要提供服务的列的请求较少。我们发现 CL 对等节点的数量平均达到客户端的最大值(范围从 100 到 200),与具有 50~100 个节点规模的较小 devnet 可以负担的更多对等节点相比,这是一个更大的对等节点数量。
3. GetBlobsV2 指标
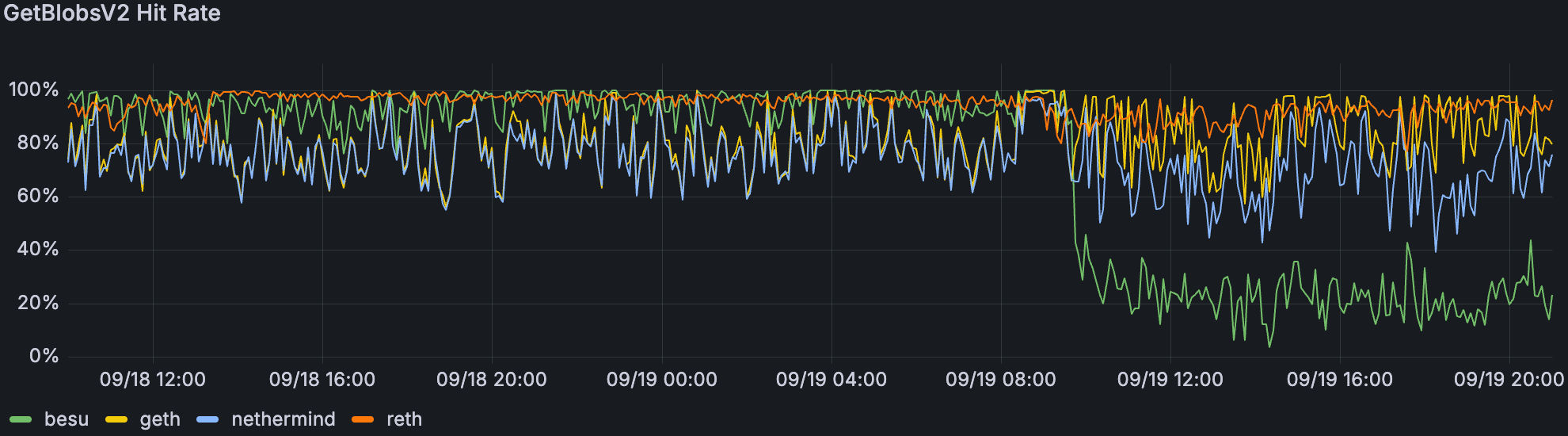
在 22/33 个 blob 和 48/72 个 blob 时,GetBlobsV2 返回成功的百分比(从 ~09/19 10:00)。
ALT
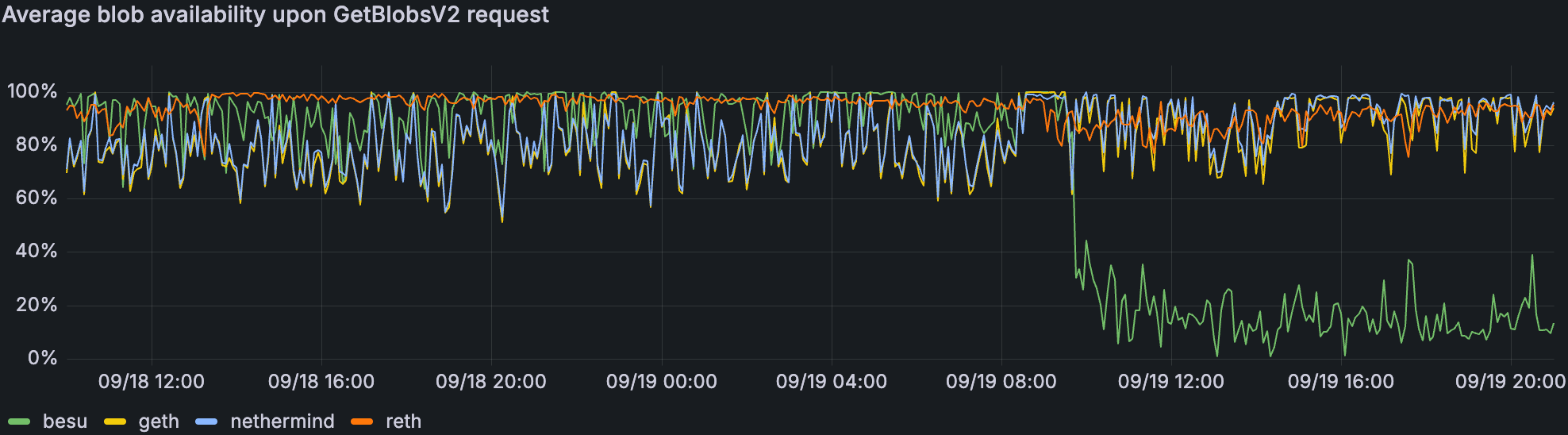
调用 GetBlobsV2 时可用的 blob 数量。相同的分析期间。
ALT
与我们最近的 devnet 相比,出现了类似的趋势:
随着 blob 吞吐量的增加,性能较差,并且
Geth & Nethermind 的 blob 可用性高于命中率。
第二点可能表明它们更有可能有很多部分可用的 blob,而不是完全可用以具有更高的命中率。这可能表明来自 GetBlobs API 的部分返回可能有助于 CL 在更高的 blob 计数下。
Supernode 在更高的 blob 吞吐量下具有略低的命中率和 blob 可用性,而非验证节点具有比验证节点更高的命中率。我们可以推测,尽管 supernode 的带宽上限远高于其使用量,但它们更依赖于 EL。
此外,Reth 的 GetBlobsV2 性能得到了显著改善。除了任何代码优化之外,我们从指标中观察到以前的问题已得到解决,例如 OOM 和对等连接。Reth 平均维持 ~120 个对等节点,是 Geth 和 Nethermind 对等节点的两倍多。拥有相当数量的对等节点集可能提高了 blob 的可用性。
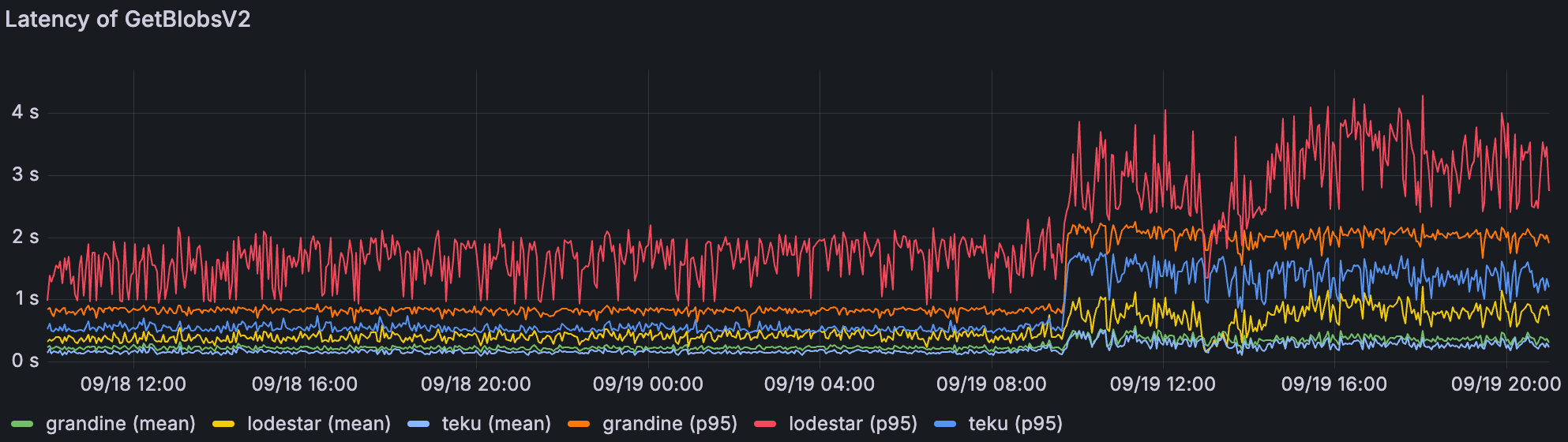
在相同的分析期间。
ALT
在使用该指标的客户端中,在更高的 blob 吞吐量下观察到更高的延迟。Lodestar 节点通常必须等待 GetBlobsV2 返回直到证明窗口(4 秒),这仔细地表明与其他客户端相比,对 EL 的依赖性更高。
4. 数据列
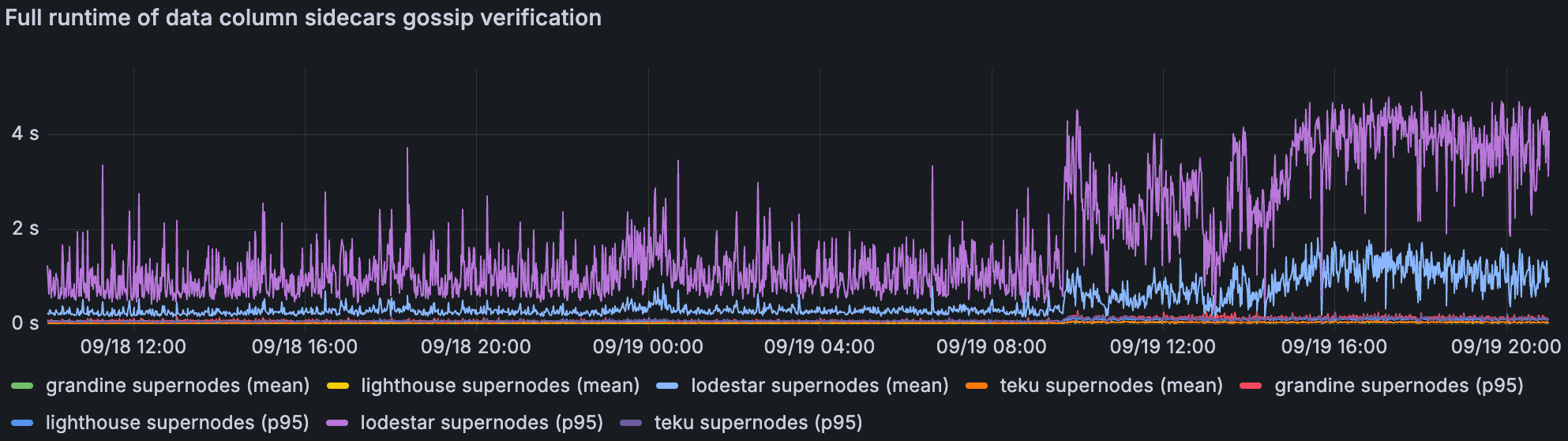
大多数客户端在几百毫秒内验证了高 blob 吞吐量下的 column sidecar,如果它们可以接收到所有需要的列,则可以及时证明。然而,Lodestar supernode 难以快速验证,这使得它们不太可能完全参与网络。
5. CPU & RAM 使用情况
与之前具有相同硬件规范的较小 devnet 相比,在 devnet-5 中发现了更高的 CPU 和内存平均利用率(平均增加约 10%)。异常高利用率的主要原因是节点在跟踪或同步链时卡住。尽管如此,在分析期间总体使用情况是稳定的。
请注意,所有节点的部署使用的 RAM 都小于 EIP-7870 建议的 RAM。验证节点为 16GB,非验证节点为 8GB,而建议分别使用 64GB 和 32GB。
5.1. 验证节点
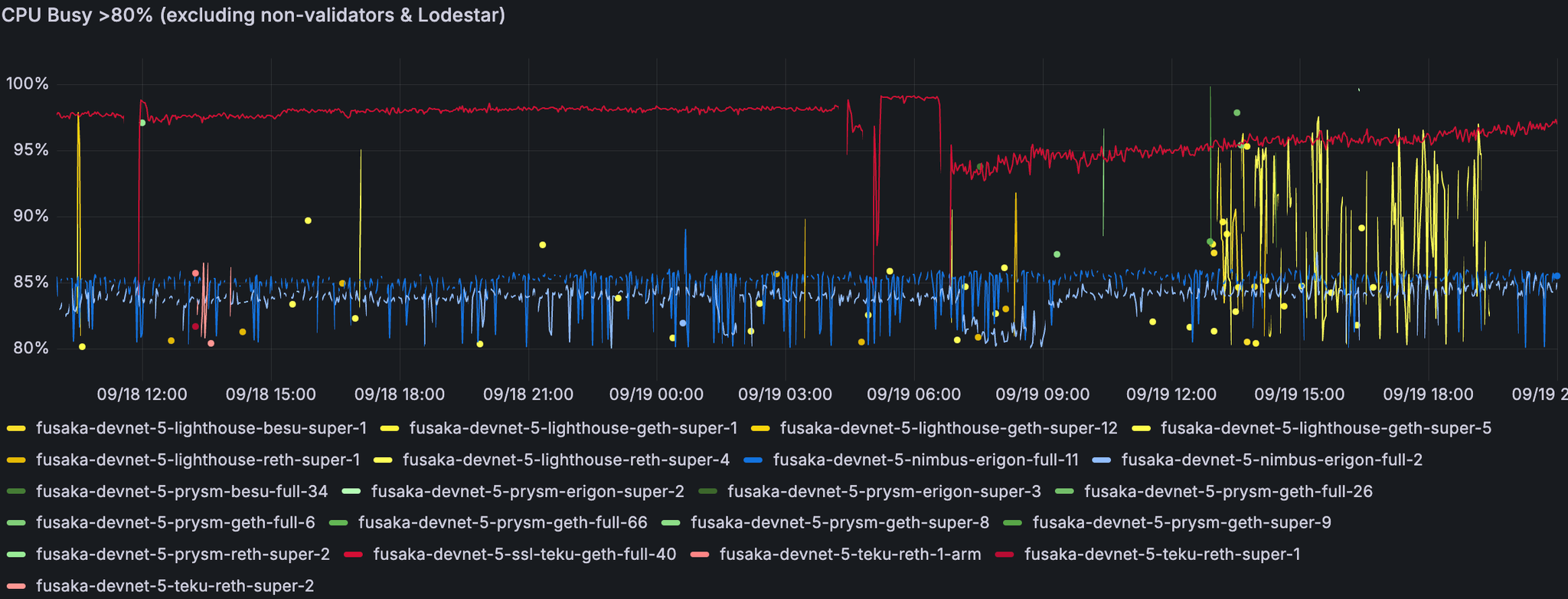
一些 supernode 和少数 fullnode 显示出有时接近其处理能力的迹象。此处的 Teku 和 Nimbus 节点卡在同步中。在分析期间,没有 Nethermind 实例报告 CPU 使用率超过 80%。
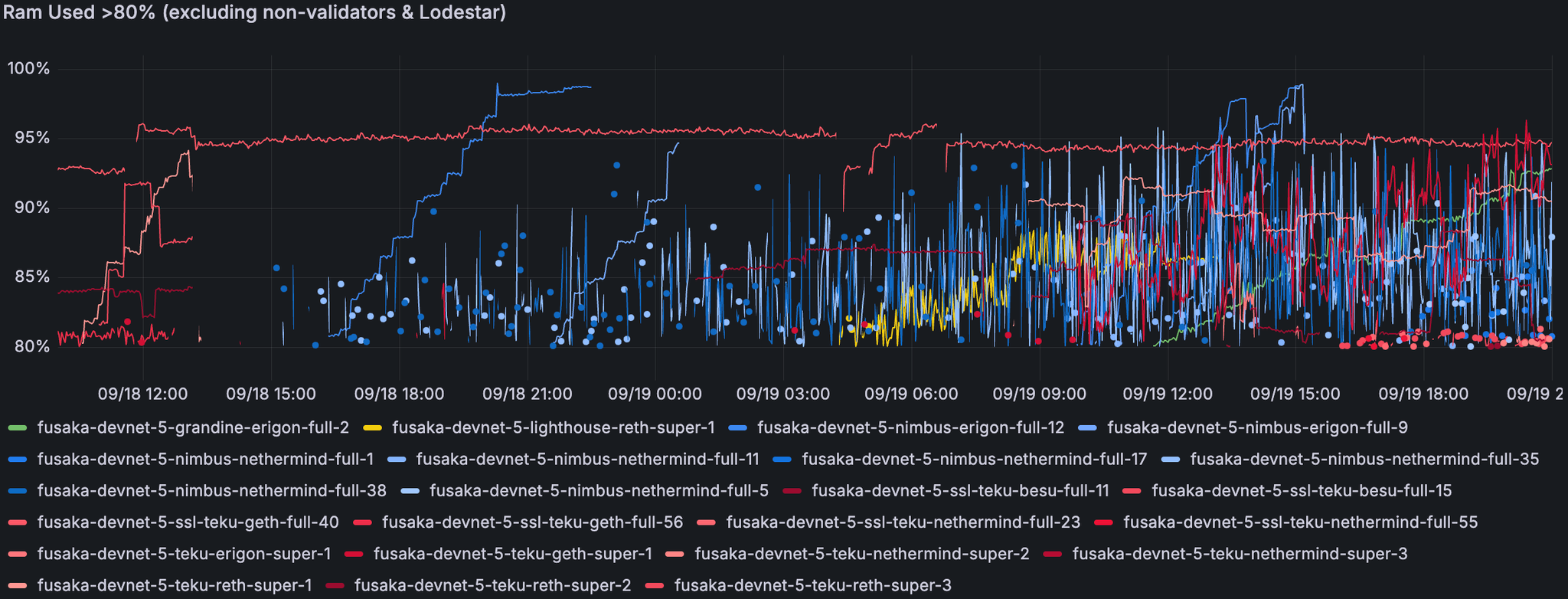
此处大多数具有高 RAM 使用率的节点都卡住或正在同步链。
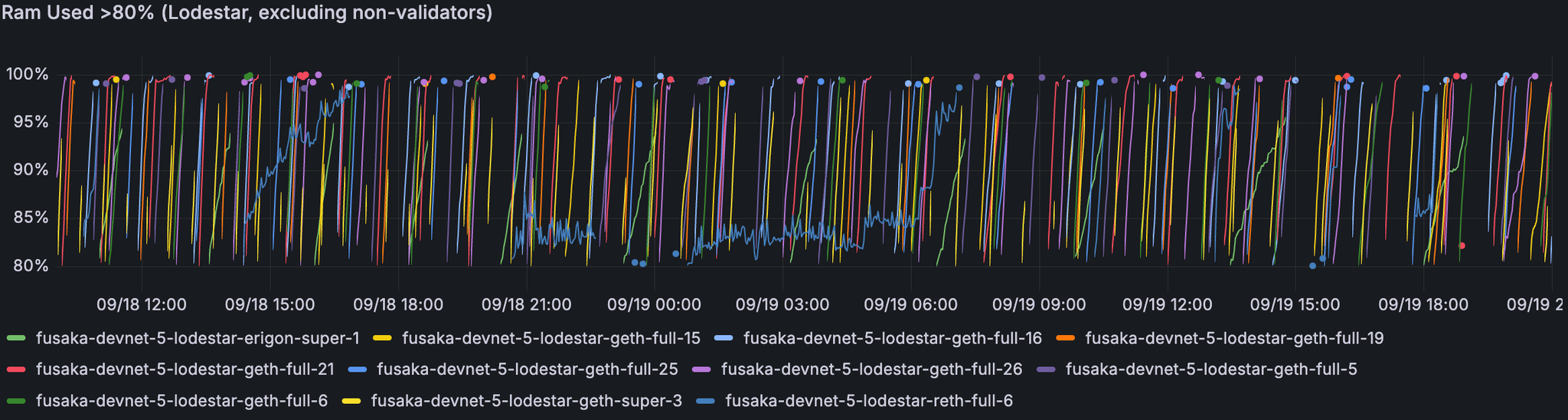
一些 Lodestar 节点的 CPU 和 RAM 利用率急剧上升。
5.2. 非验证节点
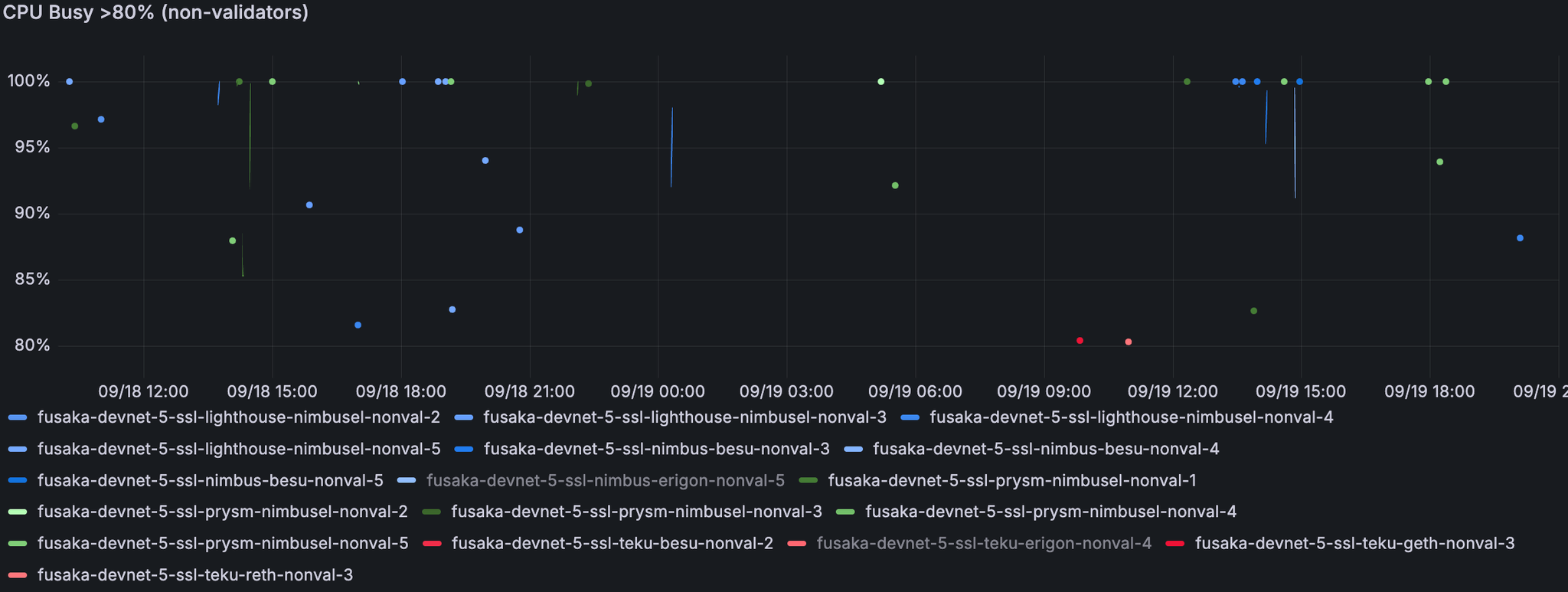
尽管在处理使用中只有少量峰值,但非验证节点通常可以使用 4 个 vCPU。上面两个未选中的节点卡在跟踪链中。
我们为非验证器设置的内存(8GB)不足。超过一半的非验证节点(110+/180)达到 90%+ 的内存。
5.3. 关于硬件要求的评论 (EIP-7870)
Devnet-5 节点满足 EIP-7870 建议的硬件要求,除了内存要求(远低于建议)。Supernode 具有 1Gbps 带宽,这在 EIP 中没有指定。
在高 blob 负载下,数据表明,考虑到同步和突然使用峰值的情况,最好所有节点类型都具有良好的 CPU 和 RAM。在当前的实现下,验证节点(cgc=8)需要更高的上传带宽似乎很明显。根据 Devnet-5 和我们之前的 devnet 使用情况,首选 100Mbps 的上传带宽。
6. 其他
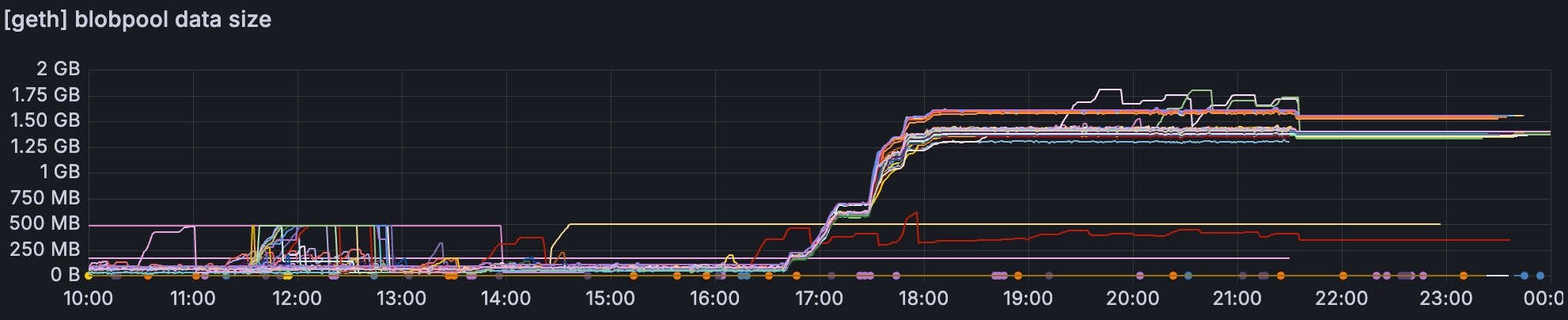
最后 12 个小时的 devnet,blob 吞吐量约为 ~48/72。
ALT
在 48/72 的高 blob 吞吐量期间,许多 Geth blobpool 的数据大小在某个时间点显著增加。
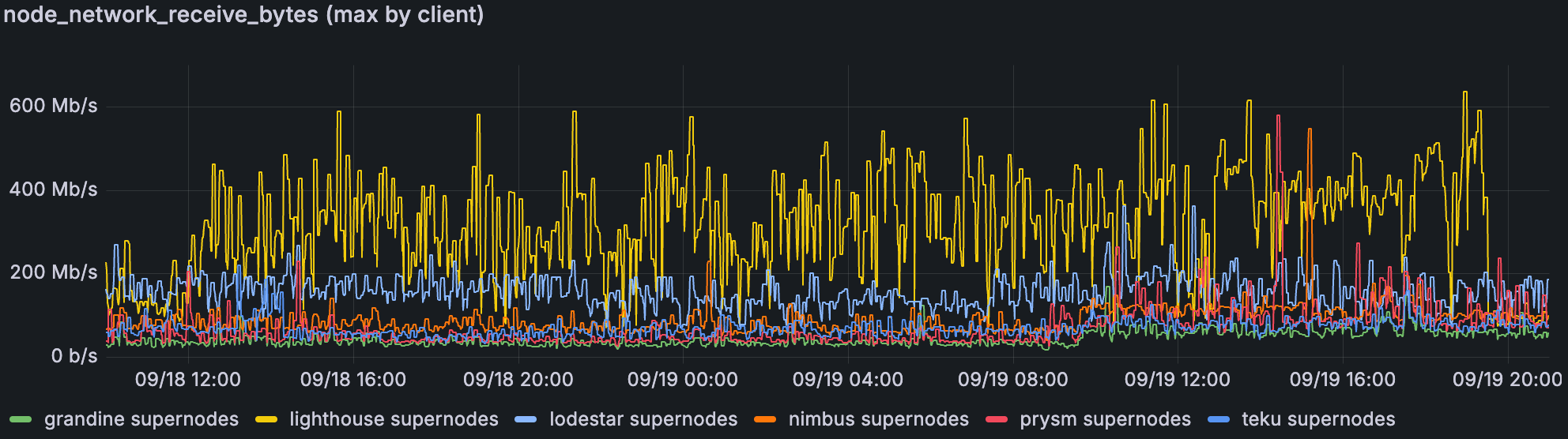
最后 36 小时的 devnet,blob 吞吐量约为 ~22/33 和 ~48/72。Transmission 显示出类似的模式,但差距较小。
ALT
与其他的对应节点相比,许多 Lighthouse supernode 异常地消耗了更多的网络带宽(双向)。
结论 & 讨论
在具有实际对等节点计数的 ~1/8 规模下,网络维持 22/33 个 blob 并在 48/72 个 blob 下运行,有明显的迹象表明 fullnode 上的上行链路容量是限制因素。随着 blob 数量的增加,来自 CL 和 EL 的 P2P 使用量都会增加,但 EL P2P 峰值增长为比预期更大的波动来源。客户端通常能够足够快地验证列,但 GetBlobsV2 的成功率和延迟会随着负载而降低;Reth 改进了其性能,这令人鼓舞。总体而言,该数据支持继续进行 BPO 扩展,但要谨慎对待上传带宽、P2P 网络和特定于客户端的异常值。
展望未来,如果我们要实施与分叉无关的 P2P 更改,则重点应放在提高带宽效率和改进客户端 blob 处理(例如 GetBlobs 中的部分返回)上,并且我们应鼓励节点运营商提供接近 EIP-7870 指南的资源。通过这些改进,网络似乎能够在安全限制内进一步扩展 blob,同时保持证明和数据的可用性。
最重要的是,非常感谢 EthPandaOps 提供参与大规模 devnet 的机会,以及核心开发人员一直在密切合作。
后续步骤
我们的目标是继续帮助 EthPandaOps 贡献 blob 扩展测试工作,以安全地交付 BPO。一旦明确并确认,我们将通知你任何更新。
- 原文链接: testinprod.notion.site/D...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





