基于递归STARK的带宽高效内存池 - 网络
- 以太坊中文
- 发布于 2026-01-13 14:58
- 阅读 7
文章提出了在后量子环境中,为解决以太坊中基于STARKs的交易或数据广播时产生的巨大带宽开销问题。解决方案是Mempool节点定期生成递归STARK,将所有有效对象的证明聚合起来,从而显著减少需要广播的数据量,尤其适用于后量子签名聚合和分布式区块构建中的Blob根广播。
假设你有大量对象可以由用户发送,所有这些对象(如果有效)都需要被广播,以便它们能被最终的构建者节点发现并包含。还假设有效性条件可以用 STARK 表示,并且我们处于一个后量子环境中,其中椭圆曲线 SNARKs 将无法工作。
这至少适用于以太坊中的三个用例:
- 后量子执行层签名聚合,尤其是当用户使用隐私协议时
- 后量子共识层签名聚合,以处理大量验证者
- 广播 blob 根,在分布式区块构建模型中,我们假设 blob 的总数对于构建者来说太大,无法完全下载,因此构建者必须从 blob 提交者那里下载根,然后使用 DAS 验证其可用性。STARK 验证了擦除编码计算正确
问题:STARKs 开销很大,即使在高度尺寸优化的实现中也占用 128 kB。如果用户发送的每个对象都与完整的 128 kB STARK 开销一起广播给所有人,那么带宽需求(对中间内存池节点和构建者而言)将是令人难以承受的。
我们可以这样解决这个问题。
当用户向内存池发送一个对象时,他们可以随对象发送一个直接有效性证明(例如一个或多个签名,通过某些验证函数的 EVM calldata),或者一个证明有效性的 STARK。
内存池节点遵循以下算法:
- 它们被动等待并接收用户发送的对象。当它们看到一个对象时,它们验证其证明。如果证明有效,它们就接受它。
- 每个周期(例如 500ms),它们生成一个递归 STARK,证明他们所知道的所有仍然有效的对象的有效性。它们将此证明转发给它们的对等节点,同时向每个对等节点发送它们尚未发送给该对等节点的任何对象(不带证明)。
递归 STARK 的逻辑如下。公共输入是位域或哈希列表,表示证明所证明其有效性的对象集合。证明随后需要:
- 0 个或更多对象,及其有效性证明(可以是直接证明或 STARKs)
- 0 个或更多相同类型的其他递归 STARKs
- 要丢弃的对象的哈希列表的位域(这允许丢弃已过期对象)
该证明证明了所有对象以及输入给它的所有递归 STARK 的所有公共输入的有效性的并集,减去被丢弃的对象。
以图表形式(此处用于执行层签名聚合用例):
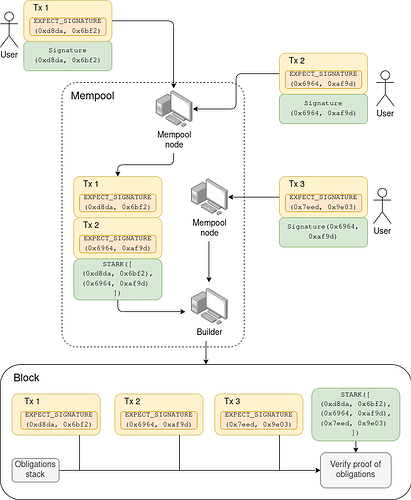
在此示例中,第一个内存池节点看到 Tx 1 和 Tx 2(带有直接证明),并创建一个递归 STARK,证明 {Tx 1, Tx 2} 是有效的。第二个内存池节点看到来自第一个节点的消息,其中包含 Tx 1 和 Tx 2(不带直接证明)以及 STARK,它还看到 Tx 3(带有直接证明),并创建一个递归 STARK,证明 {Tx 1, Tx 2, Tx 3} 是有效的。它将此发送给它的对等节点,其中一个是构建者,构建者接收并包含它。
如果构建者收到多条包含非完全重叠对象集合的消息,并且构建者想要同时包含它们,构建者可以自己创建一个递归 STARK 将它们组合起来。构建者也可以丢弃他们认为不再有效以进行包含的任何对象(此处指交易)。
此方案的总开销是:
- 每个对象,不带其证明,被广播到每个节点(注意:在共识层聚合的情况下,这可以压缩到每个参与者 1 比特)。这与今天的现状具有相同的带宽,除了我们可以去除签名。
- 每个节点都有额外的入站和出站带宽,等于每个周期一个 STARK 的大小,乘以其对等节点的数量(例如,8 个对等节点和 500ms 周期,即 128 kB * 8 / 0.5 = 2 MB/秒)。这是恒定的,不会随着用户发送的对象数量的增长而增加。
- 原文链接: ethresear.ch/t/recursive...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





