SP1 Turbo:世界上最快的zkVM变得更快了
- Succinct
- 发布于 2025-01-23 22:35
- 阅读 1542
SP1 Turbo是SP1的最新版本,通过CUDA优化,在成本和延迟方面有显著改进,尤其是在GPU并行化处理时,能更接近实时以太坊证明。它引入了Secp256R1和RSA签名验证等新的预编译,使得SP1成为zkEVM和rollup工作负载的最佳zkVM,开发者可以通过文档和prover network beta开始使用。
SP1 Turbo (v4.0.0) 是 SP1 的最新升级版本,提供了显著的成本和延迟改进。SP1 Turbo 是一个速度极快的 zkVM,在各种 ZK 工作负载方面具有一流的性能,包括 rollups (zkEVMs)、轻客户端、签名验证和其他区块链计算。
- SP1 Turbo 为各种 ZK 工作负载提供最快的速度和最低的成本。
- SP1 Turbo 在跨并行 GPU 集群运行时具有无与伦比的延迟,越来越接近实时以太坊证明。
- 此版本引入了新的预编译,例如 Secp256R1 和 RSA 签名验证。
- 立即开始使用 SP1 Turbo,请阅读我们的 文档。
SP1 Turbo 性能
SP1 在各种 ZK 工作负载的成本、延迟和吞吐量基准测试中提供了一流的性能。这要归功于我们团队的硬核性能工程,他们花费了数月时间进行 CUDA 优化,以提高 GPU 利用率。
我们展示了自 2 月份首次发布以来,SP1 性能随时间的推移,这展示了一个“ZK 摩尔定律”的实际应用。请注意,此图中的点不完全可比,因为 SP1 的初始版本仅具有 CPU 证明,而最近的版本是在 GPU 节点上进行基准测试的,并且性能因程序而异。 尽管如此,性能正在呈指数级增长。
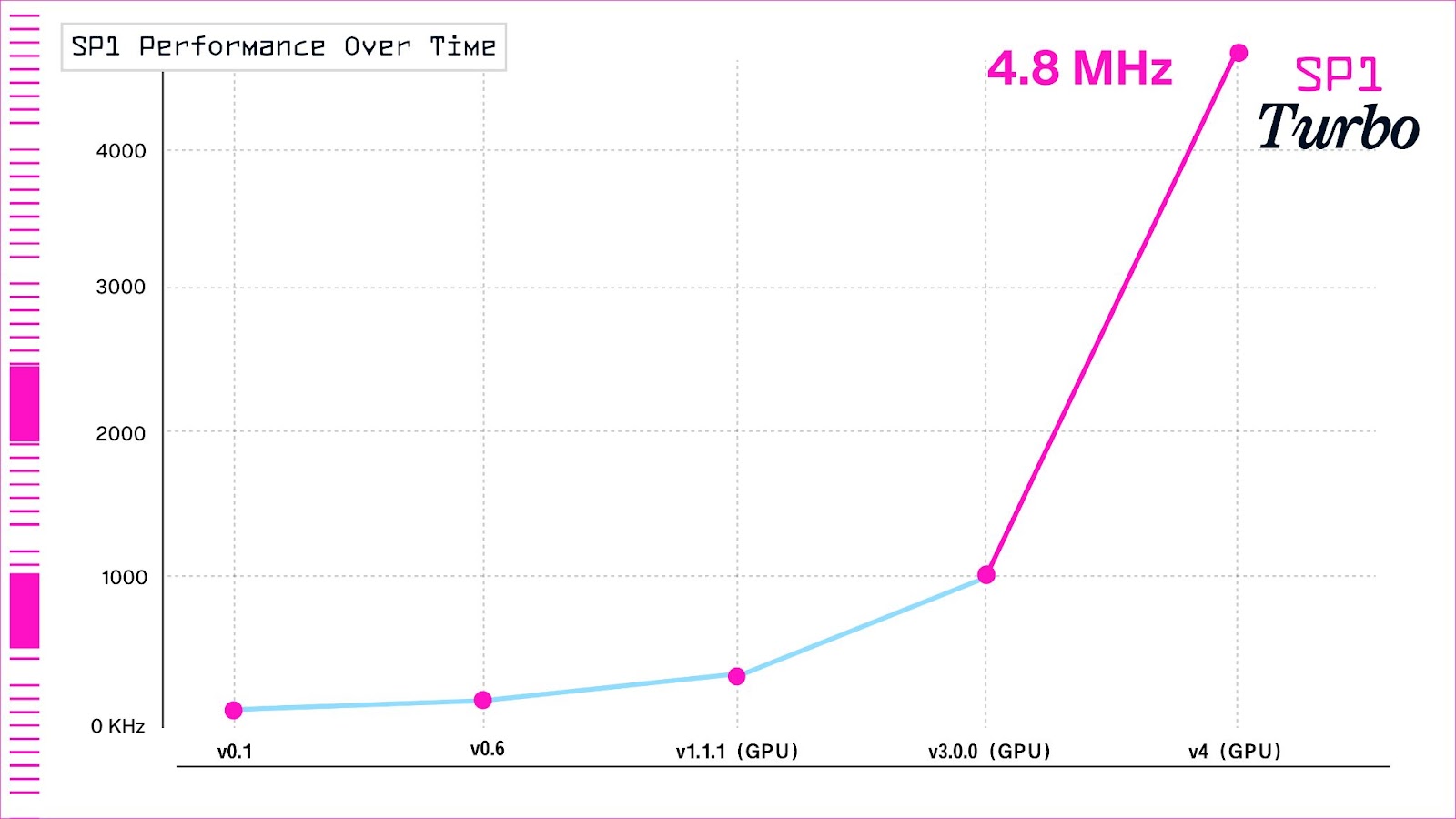 Caption: SP1 随时间推移的性能 [1]。
Caption: SP1 随时间推移的性能 [1]。
单 GPU 性能基准
为了展示 SP1 Turbo 在单个 GPU 节点上的性能有多好,我们将它在一组基准测试程序上的证明时间与 SP1 V3.0.0 进行了比较。 为了保持一致性,我们在同一云 GPU 机器 (AWS g6.xlarge) 上对两个版本进行了基准测试。 我们测量了启用递归/恒定证明大小的端到端证明时间。
| 程序 | SP1 Turbo 端到端证明时间 | SP1 V3.0.0 证明时间 | 改进 |
| Loop-1M | 2.04 秒 | 13.1 秒 | 6.4 倍 |
| Loop-100M | 95.7 秒 | 239.7 秒 | 2.5 倍 |
| Fibonacci | 6.1 秒 | 23.2 | 3.8 倍 |
| Tendermint | 21.4 秒 | 38.5 秒 | 1.8 倍 |
| Reth | 682.6 秒 | 1120 秒 [2] | 1.6 倍 |
SP1 Turbo 在各种程序和工作负载大小上始终优于 SP1 V3.0.0,无论是否使用预编译。 此外,对于典型的以太坊主网区块,SP1 Turbo 实现的证明成本低至几美分。
SP1 数据表 上提供了更全面的基准测试集。 可以使用我们的基准测试存储库重现这些基准测试。
多 GPU 性能基准
虽然在单个 GPU 上运行的基准测试为比较 zkVM 提供了标准化且可复制的环境,并且对于推断证明成本(通过将证明时间乘以实例成本)也很有用,但当涉及到延迟时,它们并不能说明全部情况,延迟是证明程序所需的端到端时间。
跨多个 GPU 并行化单个程序的证明生成可以使延迟远低于在单台机器上进行证明。 请注意,证明成本保持相对不变,因为我们使用了更多的机器,每台机器的使用时间都较短 [3]。 对于 SP1 来说,并行化证明生成是很自然的,因为 SP1 已经将长程序的证明“分片”为大约 200 万个周期的块,并生成每个分片的单独证明,然后在之后递归地组合它们以获得单个最终 STARK。
SP1 Turbo 在云中许多 GPU 集群上进行证明时,可提供令人难以置信的速度。 请注意,SP1 的单机性能在 900 KHz 到几 MhZ 之间变化,具体取决于工作负载和机器实例,这表明跨多个 GPU 并行化证明可以显着提高延迟。 希望利用这一点的开发人员今天可以使用 Succinct 的 Prover Network Beta。
SP1 Turbo 使我们接近实时以太坊证明,在 < 40 秒内证明真实的以太坊主网区块。 查看我们集群上一些真实以太坊区块的证明时间。

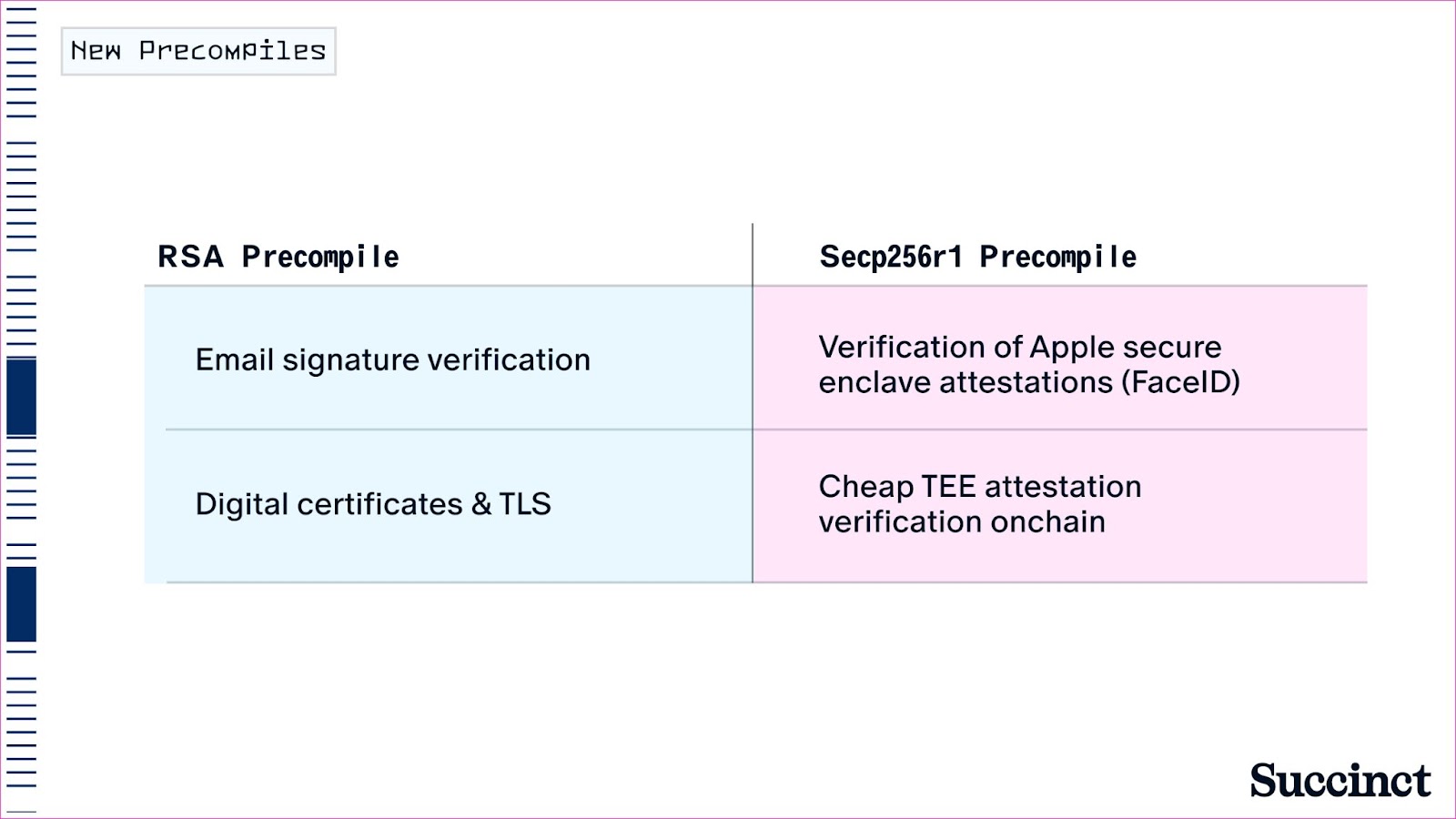
SP1 Turbo 中的新预编译
在此版本中,我们有全新的预编译,包括 secp256r1 和用于高效 RSA 签名验证的 bigint 算法。 预编译是用于密集型密码操作的专用电路。 它们为大量使用加密(如哈希函数和签名验证)的区块链工作负载提供了数量级的性能提升。 预编译是 SP1 成为 zkEVM 和其他 rollup 工作负载最快的 zkVM 的一个重要原因。
通过这些预编译,SP1 在支持的预编译种类方面成为市场领先的 zkVM。
SP1 Turbo 幕后:硬核性能工程和新密码学
在 SP1 Turbo 中,我们使用了一种新的内存一致性参数,通过基于椭圆曲线的多重集哈希函数。 内存一致性是 zkVM 中的一个主要组成部分,它确保在执行过程中,当从给定的内存地址读取数据时,此处看到的值是上次写入同一地址的值。 在 SP1 V1 中,我们遵循 Spartan 的离线内存检查方法(其本身基于 Blum 等人 [BEG+94])。
SP1 Turbo 中使用的方法与其他已考虑的方法相比具有显着优势:
- Merkelizing Memory - 从打开 Merkle 路径引入了显着的开销。
- 指纹识别 + 大乘积参数(又名 logUp 和 GKR/Thaler,用于 SP1 V1)- 这些解决方案需要验证者随机性,该随机性从 Fiat-Shamir 获得。 这需要在我们可以继续处理内存参数之前完成计算。 在我们当前的解决方案中,我们在计算进行时动态运行内存参数。
我们有一份由我们的密码学负责人 @ronrothblum 和安全负责人 @rkm0959 撰写的关于此主题的详细 说明。
立即使用并联系我们
SP1 Turbo 现已上市,可以投入生产使用。 开发人员可以在本地或使用我们的 prover 网络 beta 版开始使用它。 从我们的 文档 中了解更多信息。 我们还为从 V3 升级到 Turbo 的用户提供了 迁移指南。
如果你有兴趣试用 SP1 Turbo 或通常使用我们的任何集成,请 联系我们。
- OP Succinct (OP Stack rollups) https://blog.succinct.xyz/op-succinct/
- RSP (zkEVM with Reth + SP1) https://github.com/succinctlabs/rsp
- SP1 contract call https://github.com/succinctlabs/sp1-contract-call
- SP1 Helios (Ethereum light client with SP1) https://github.com/succinctlabs/sp1-helios
- SP1 Tendermint (Tendermint light client with SP1) https://github.com/succinctlabs/sp1-tendermint-example
- SP1 Blobstream https://github.com/succinctlabs/sp1-blobstream
- SP1 Solana verifier https://github.com/succinctlabs/sp1-solana
或使用 SP1 构建任何其他东西。
引用
[BEG+94] Blum, M., Evans, W., Gemmell, P., Kannan, S., & Naor, M. (1994). Checking the correctness of memories. Algorithmica, 12, 225-244.
脚注
[1] MHz 是在具有大约 4 亿个周期的 Fibonacci 计算(不进行递归)的程序中,在单个 4090 GPU 实例上为 SP1 V1、V3 和 Turbo 计算的。 通过递归,SP1 V3/V4 的性能分别为 0.7/3.0MHz。 SP1 v.06 和 v.01 性能数据来自之前的博客文章,不完全可比,因为它们是在 CPU 实例上测量的,并且基准测试的程序是周期数少得多的 Fibonacci 工作负载。
[2] 此数字来自我们早期版本的以太坊区块证明器,称为 SP1 Reth。 证明时间是使用周期数之差推断出来的。
[3] 这是假设许多 GPU 具有恒定的利用率,这需要一些最小的吞吐量(每秒证明的周期数)才能使 GPU 饱和。 如果你的工作负载非常突发(例如,在 1 分钟内证明一个具有 150 亿个周期的程序,然后在 20 分钟内不进行任何证明),那么启动许多机器并让它们闲置意味着证明生成成本更高。
- 原文链接: blog.succinct.xyz/sp1-tu...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





