更快的 Sumcheck:第一部分
- zksecurity
- 发布于 2025-11-22 16:55
- 阅读 655
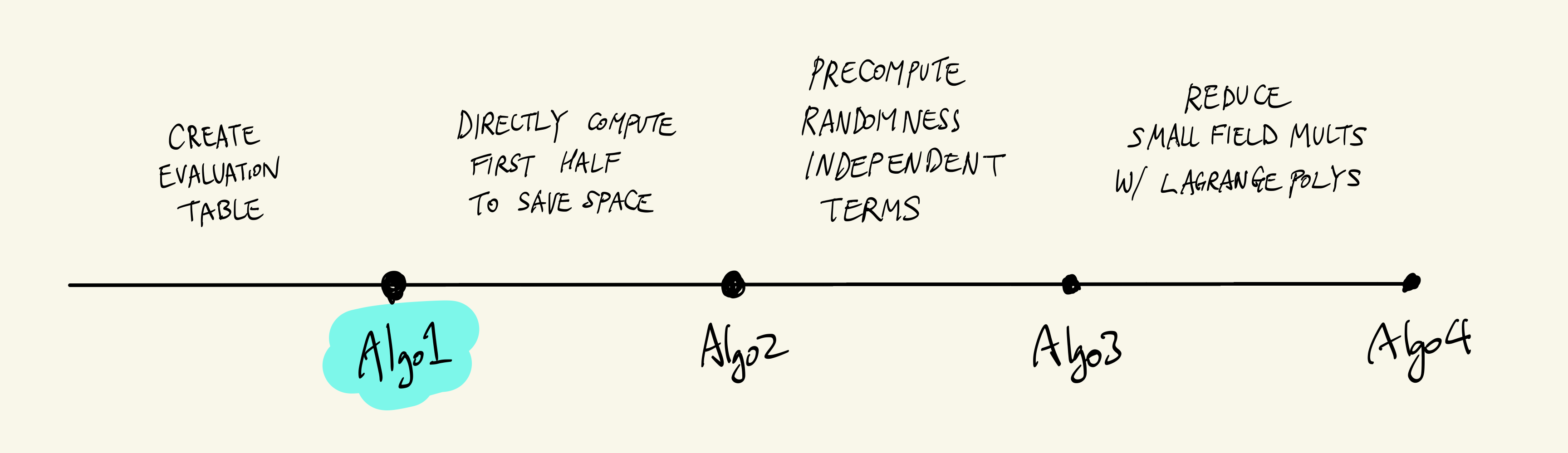
本文介绍了加速 Sumcheck 协议证明时间的优化方法,尤其是在需要证明的值在一个小域,而随机性来自一个相对大域的情况下。文章详细讲解了四种算法,重点在于减少大域乘法(ll multiplication)的次数,通过预计算r无关项、分组d位、Lagrange插值等技术,逐步优化Sumcheck协议的计算效率,并提供了相应的 SageMath 代码实现。
注意
这篇文章需要对 sumcheck 协议有一定的了解。 如果你不熟悉它,我们建议你阅读我们的互动教程:使用 SageMath 了解 Sumcheck 和 MLE
简介
在本系列文章中,我们将介绍 加速 Sum-Check 证明 论文中描述的优化。 为了帮助解释,我们还将分享我们在 SageMath 中实现的算法,该算法可在 GitHub 上找到。
该论文的主要动机是加速针对特定情况的 sumcheck 的证明时间:要证明的值在一个小域中,而随机性是从一个相对较大的域中提取的。 例如,在证明 zkVM 时,我们经常尝试证明 32 位整数的寄存器值和布尔值的标志。 另一方面,出于安全原因,我们经常在 sumcheck 中从大域中提取随机性,例如,对于基于哈希的 SNARK,使用约 128 位的域,对于基于椭圆曲线的 SNARK,使用约 256 位的域。
这意味着在整个 sumcheck 协议中,证明者需要在大的域中进行大量操作,这些操作通常比在小域中的操作慢得多。
更具体地说,我们可以将 sumcheck 协议中的算术运算(我们只考虑乘法)分为三类:
- ss: small × small
- sl: small × large
- ll: large × large
由于 ll 乘法是最昂贵的,所以本文旨在最大限度地减少这些乘法的数量。
预备知识
在深入研究优化之前,让我们从一些预备知识开始。
多线性多项式
设 $p: F^l \rightarrow F$ 是一个多线性多项式。 那么,我们可以使用 eq~ 多项式将其写成在某个布尔超立方体 ${0,1}^l$ 上的加权评估的和:
$p(x_1,x_2,\dots,xl) = \sum{b \in {0,1}^l} eq~((x_1,x_2,\dots,x_l),b) \cdot p(b)$,
其中 $x_1,x_2,\dots,x_l \in F$ 是变量,$p(b)$ 是在布尔超立方体上的评估,$eq~((x_1,x_2,\dots,x_l),b)$ 是权重。
我们可以通过迭代 $x_i$ 的布尔值并将结果相加来移除任何变量 $x_i$。 例如,如果我们要移除 $x_l$,我们将得到以下等式:
$p(x_1,x2,\dots,x{l-1}) = \sum{x' \in {0,1}^1} \sum{b \in {0,1}^{l-1}} eq~((x_1,x2,\dots,x{l-1}),b) \cdot p(b,x')$。
类似地,我们可以将 $F$ 中的任何值分配给 $x_i$。 例如,我们可以将 $(x_1,x2,\dots,x{l-1}) = (r_1,r2,\dots,r{l-1})$ 分配给上面的等式,得到以下等式:
$p(r_1,r2,\dots,r{l-1}) = \sum{x' \in {0,1}^1} \sum{b \in {0,1}^{l-1}} eq~((r_1,r2,\dots,r{l-1}),b) \cdot p(b,x')$。
这两个技巧是我们在 sumcheck 协议中需要的全部。
Sumcheck 协议
在整个 sumcheck 协议中,在每一轮 $i$ 中,我们将计算 $x_i$ 的单变量多项式,并在来自大域的随机值 $r_i$ 处对其求值。
例如,在第 $i=1$ 轮中,我们创建一个单变量多项式 $s_1$ 如下:
$s1(X) = \sum{x' \in {0,1}^{l-1}} \sum_{b \in {0,1}^1} eq~(X,b) \cdot p(b,x')$。
然后,我们在来自大域的随机值 $r_1$ 处评估 $s_1$,并将其发送给 verifier,得到以下等式:
$s_1(r1) = \sum{x' \in {0,1}^{l-1}} \sum_{b \in {0,1}^1} eq~(r_1,b) \cdot p(b,x')$。
对于一般的第 $i$ 轮,单变量多项式如下所示:
$si(X) = \sum{x' \in {0,1}^{l-i}} \sum_{b \in {0,1}^{i-1}} eq~((r1,\dots,r{i-1}),b) \cdot p(b,X,x')$。
乘积多线性多项式的 Sumcheck
在这篇文章中,我们将研究在一个特殊情况下,我们在 $d$ 个多线性多项式 $p_1,p_2,\dots,p_d$ 的乘积上运行 sumcheck。 因此,我们将等式 $s_i(X)$ 重写为:
$si(X) = \sum{x' \in {0,1}^{l-i}} \prod{k=1}^d \left( \sum{b \in {0,1}^{i-1}} eq~((r1,\dots,r{i-1}),b) \cdot p_k(b,X,x') \right)$
算法 1:使用评估表
现在我们准备好深入研究了!
在每一轮中计算 $s_i(X)$ 的一种简单方法是保留每个 $p_k(X)$ 在布尔超立方体 ${0,1}^{l-i}$ 上的所有评估的表,并在我们进行每一轮时更新它。
这涉及一个大小为 $d \cdot 2^l$ 的初始表,并且在每个后续回合中,所需的大小减半。

图 1.1:从第 $i=1$ 轮开始的评估表。
一个简单的观察是,这种方法在空间和时间方面都是低效的,因为初始表的大小很大,并且我们需要从第二轮开始执行 ll 乘法。
我们能做得更好吗?
注意
查看 SageMath 代码 以获取此算法的实现。
算法 2:直接计算每一轮的 pk

解决空间问题的一个简单方法是直接计算所有 $b \in {0,1}^{i-1}$、$x' \in {0,1}^{l-i}$ 和 $k \in [d]$ 的 $p_k(b,X,x')$,直到评估表的大小变得足够小。
例如,我们可以直接计算多项式直到第 $l/2$ 轮,然后切换到算法 1,此时我们将从大小为 $d \cdot 2^{l/2}$ 而不是 $d \cdot 2^l$ 的表开始。
然而,我们并没有解决从第二轮开始的 ll 乘法问题。
注意
查看 SageMath 代码 以获取此算法的实现。
算法 3:预计算与 r 无关的项

将好的与坏的分开
请注意,一旦小值与大值相乘,对结果进行的任何进一步的算术运算都将是 ll 乘法。 因此,为了最大限度地减少坏的(ll 乘法),我们将尽最大努力将好的(ss 乘法)与坏的分开,尽可能延迟大值和小值的乘法。
回想一下,证明者需要计算的等式如下:
$si(X) = \sum{x' \in {0,1}^{l-i}} \prod{k=1}^d \left( \sum{b \in {0,1}^{i-1}} eq~((r1,\dots,r{i-1}),b) \cdot p_k(b,X,x') \right)$。
你可以看到,这需要在遍历所有 $x'$、$k$ 和 $b$ 值之前,将 eq~ 项(一个大值)与 $p_k$ 项(一个小值)相乘,这将导致一个大值。
但是,如果我们分别对每个项的 $x'$、$k$ 和 $b$ 值进行迭代,_然后_将结果相乘,我们可以最大限度地减少 ll 乘法的数量! 此外,$p_k$ 与 $r$ 无关,因此我们可以预先计算这些值。
让我们逐步了解如何做到这一点。
首先,我们将对 $b$ 的求和与对 $k$ 的乘积的顺序切换:
$\sum{x' \in {0,1}^{l-i}} \sum{b_1,...,bd \in {0,1}^{i-1}} \prod{k=1}^d \left( eq~((r1,\dots,r{i-1}),b_k) \cdot p_k(b_k,X,x') \right)$。
如果对 $b_1,...,b_d$ 的新求和看起来不熟悉,让我提醒你,内部乘积现在返回所有 ${b_1,\dots,b_d}$,因此我们需要迭代这些变量的所有可能值。
接下来,我们展开 eq~ 函数的定义。 请注意,eq~ 有两种表示形式:
$eq~((r1,\dots,r{i-1}),bk) = \prod{j=1}^{i-1} (r_j \cdot b_k[j] + (1-r_j) \cdot (1-bk[j])) = \prod{j=1}^{i-1} (r_j b_k[j] \cdot (1-r_j)^{1-b_k[j]})$,
我们将使用第二种表示形式。
因此,我们有以下新表达式:
$\sum{x'} \sum{b_1,...,bd} \prod{k=1}^d \left( \prod_{j=1}^{i-1} (r_j b_k[j] \cdot (1-r_j)^{1-b_k[j]}) \cdot p_k(b_k,X,x') \right)$。
让我们更进一步,将对 $k$ 的乘积与对 $j$ 的乘积交换。
$\sum{x'} \sum{b_1,...,bd} \left( \prod{j=1}^{i-1} rj^{\sum{k=1}^d b_k[j]} \cdot (1-rj)^{d - \sum{k=1}^d bk[j]} \right) \cdot \left( \prod{k=1}^d p_k(b_k,X,x') \right)$。
最后,让我们将对 $x'$ 的求和移到内部,就在对 $k$ 的乘积之前。 我们不需要以任何方式更改此总和,因为 r 项不依赖于 $x'$。
$\sum_{b_1,...,bd} \left( \left( \prod{j=1}^{i-1} rj^{\sum{k=1}^d b_k[j]} \cdot (1-rj)^{d - \sum{k=1}^d bk[j]} \underbrace{\vphantom{\prod}}{\text{r相关项}} \right) \cdot \left( \sum{x'} \prod{k=1}^d p_k(bk,X,x') \underbrace{\vphantom{\prod}}{\text{r无关项}} \right) \right)$。
正如你所看到的,我们最终得到了两个项的乘法,一个依赖于大值 $r$,另一个独立于它。 请注意,乘法的次数等于 $2^{d \cdot (i-1)}$,因为我们正在为 $d$ 个多项式中的每一个迭代 $i-1$ 位。 有关 $d=3$ 和 $i=5$ 的情况的直观表示,请参见下文。

图 3.1:上面的每个橙色圆圈代表一个布尔值,该图说明了迭代所有 $d \times (i-1)$ 位。
但是我们可以使乘法次数更少吗? 事实证明我们可以!
将 d 位分组为单个 [0,d] 标量值
此优化的关键观察结果是 r 相关项不依赖于单个 $d \cdot (i-1)$ 位,而是依赖于 1 到 $i-1$ 之间特定索引处的 $d$ 位之和。 你可以看到以下项中的指数正在对索引 $j$ 处的 $d$ 位求和:
$\prod_{j=1}^{i-1} rj^{\sum{k=1}^d b_k[j]} \cdot (1-rj)^{d - \sum{k=1}^d b_k[j]}$。
因此,我们可以迭代 $d$ 位的 和 的所有可能值,而不是所有可能的 $d$ 位。 立即,这从 $2^d$ 个可能值改进到 $d+1$ 个可能值(对于 $d$ 位,最小和为 0,最大和为 $d$)。 因此,迭代总数从 $2^{d \cdot (i-1)}$ 减少到 $(d+1)^{i-1}$。
接下来,我们还需要更改我们迭代与 r 无关的项的方式。 我们将迭代相同的 $2^{d \cdot (i-1)}$ 个可能值,但顺序不同。
更具体地说,对于 $[0,d]^{i-1}$ 中的每个总和,我们将迭代加到给定总和的 $d$ 位的 所有可能值。 有关 $d=3$ 和 $i=5$ 的示例的直观表示,请参见下图。

图 3.2:较低的矩形表示 $(d+1)^{i-1}$ 个值,而较高的矩形表示 $2^{d \cdot (i-1)}$ 个值,虚线显示了每个较低的矩形如何对应于一个或多个较高的矩形。
因此,我们可以定义一个新变量 $v := (\sum_{k=1}^d bk[j]){j \in [i-1]}$,它可以被认为是 图 3.2 中的一个较低的矩形,并将等式 $s_i(X)$ 重写为如下形式:
$\sum{v \in [0,d]^{i-1}} \left( \left( \prod{j=1}^{i-1} r_j^{v[j]} \cdot (1-rj)^{d - v[j]} \underbrace{\vphantom{\prod}}{\text{r相关项}} \right) \cdot \left( \sum{x'} \sum{b_1,\dots,bd \in {0,1}^{i-1} \atop v = \sum{k=1}^d bk} \prod{k=1}^d p_k(bk,X,x') \underbrace{\vphantom{\prod}}{\text{r无关项}} \right) \right)$。
r 无关项看起来很多,但它所做的只是取一个给定的 $v$,或 图 3.2 中的一个较低的矩形,并迭代加到 $v$ 的所有可能的 $b_1,...,b_d$ 值,或连接到给定较低矩形的所有较高的矩形。
这意味着我们只是重新组织了我们计算 r 无关项的方式,但是我们已成功地将 r 相关项与无关项的乘法量从 $2^{d \cdot (i-1)}$ 减少到 $(d+1)^{i-1}$。
预计算 r 无关项,即累加器
由于 r 无关项仅依赖于 $v$ 和 $X$,因此我们可以将新函数 $A_i(v,X)$ 定义为以下形式:
$Ai(v,X) = \sum{x'} \sum_{b_1,\dots,bd \in {0,1}^{i-1} \atop v = \sum{k=1}^d bk} \prod{k=1}^d p_k(b_k,X,x')$。
我们将此称为累加器,因为它_累加_所有 r 无关值。 关于此累加器的好处是,由于它不依赖于验证者提供的随机数 $r$,因此我们可以在 sumcheck 协议开始之前预先计算它!
增量计算 r 相关项
在将所有内容放在一起之前,让我们看看如何简化 r 相关项:
$\prod_{j=1}^{i-1} r_j^{v[j]} \cdot (1-r_j)^{d - v[j]}$
请注意,由于每个 $j \in [1,i-1]$ 的 $v[j]$ 都有 $d+1$ 个可能值,因此可以将其视为大小为 $d+1$ 的 $i-1$ 数组的张量积。 例如,给定 $d=2$ 和 $i=3$,该项将如下所示:
$[r_1^0 \cdot (1-r_1)^2, r_1^1 \cdot (1-r_1)^1, r_1^2 \cdot (1-r_1)^0] \otimes [r_2^0 \cdot (1-r_2)^2, r_2^1 \cdot (1-r_2)^1, r_2^2 \cdot (1-r_2)^0]$
这确实导致 $(d+1)^{i-1} = (2+1)^{3-1} = 9$ 个值。
另一个观察结果是,可以增量计算此张量积,即取上一轮数组和大小为 $d+1$ 的新数组的张量积。
因此,我们可以将 r 相关项重写为:
$R_{i+1} := R_i \otimes (r_i^k \cdot (1-ri)^{d-k}){k=0}^d$,
其中初始值设置为 1:$R_1 = 1$。
将所有内容放在一起
现在我们准备好将所有内容放在一起了!
我们现在可以将等式 $s_i(X)$ 重写为:
$\sum_{v \in [0,d]^{i-1}} R_i[index(v)] \cdot A_i(v,X)$,
其中 $index(v)$ 是大小为 $(d+1)^{i-1}$ 的数组中 $v$ 的索引。
在实践中,我们不想为整个 sumcheck 协议运行此算法,而只想运行前几轮,然后切换到算法 1。 我们建议查看该论文的第 4.1 节以获取更多详细信息。
信息
查看 SageMath 代码 以获取此算法的实现。
算法 4:最终算法

但是我们仍然可以做得更好!
算法 4 通过减少 ss 乘法的数量来改进算法 3,同时将 sl 和 ll 乘法的数量保持在同一水平。
主要动机是,在算法 3 中,尽管 r 相关项和无关项之间只有 $(d+1)^{i-1}$ 次乘法,但我们需要迭代所有 $b_1,...,b_d \in {0,1}^{i-1}$,这相当于 $2^{d \cdot (i-1)}$ 个值。
那么,有没有一种方法可以将迭代次数减少到 $(d+1)^{i-1}$ 呢?
简而言之,我们可以通过将多项式 $\prod_{k=1}^d p_k((r1,\dots,r{i-1}),X,x')$ 视为 $Y1,...,Y{i-1}$ 上的函数并将其重写为以下形式来实现这一点:
$F(Y1,...,Y{i-1}) = \prod_{k=1}^d p_k(Y1,...,Y{i-1},X,x')$。
由于每个 $Y1,...,Y{i-1}$ 具有 $d$ 次,因此我们可以将 Lagrange 插值应用于每个变量。 以下是表达式的逐步方法:
$\prod_{k=1}^d p_k(Y1,...,Y{i-1},X,x') = \sum_{v1 \in [0,d]} L{v_1}(Y1) \cdot \prod{k=1}^d p_k(v_1,Y2,...,Y{i-1},X,x') = \sum_{v1 \in [0,d]} L{v_1}(Y1) \cdot \sum{v2 \in [0,d]} L{v_2}(Y2) \cdot \prod{k=1}^d p_k(v_1,v_2,Y3,...,Y{i-1},X,x') = \sum_{v1 \in [0,d]} L{v_1}(Y1) \cdot \sum{v2 \in [0,d]} L{v_2}(Y2) \cdots \sum{v{i-1} \in [0,d]} L{v{i-1}}(Y{i-1}) \cdot \prod_{k=1}^d p_k(v_1,v_2,v3,...,v{i-1},X,x') = \sum{v \in [0,d]^{i-1}} \prod{j=1}^{i-1} L_{v_1}(Y1) \cdot \prod{k=1}^d p_k(v,X,x')$。
其中 $b_k[j]$ 是第 k 个多项式的第 j 个位。
这意味着我们可以迭代 over $[0,d]^{i-1}$ 上的 $Y1,...,Y{i-1}$ 的所有可能值,并在每个向量处评估多项式。
因此,我们可以将方程 $s_i(X)$ 重写为:
$si(X) = \sum{x' \in {0,1}^{l-i}} \sum{v \in [0,d]^{i-1}} \prod{j=1}^{i-1} L_{v_j}(rj) \cdot \prod{k=1}^d pk(v,X,x') = \sum{v \in [0,d]^{i-1}} \prod{j=1}^{i-1} L{v_j}(rj) \underbrace{\vphantom{\prod}}{\text{$r$ 相关项}} \cdot \sum{x' \in {0,1}^{l-i}} \prod{k=1}^d pk(v,X,x') \underbrace{\vphantom{\prod}}{\text{$r$ 无关项}}$,
在这里,我们再次创建了 r 相关项和无关项的内积。 同样,由于 $L_{v_j}(r_j)$ 项与 $x'$ 无关,因此我们可以在 sumcheck 协议开始之前预先计算它们。
信息
查看 SageMath 代码 以获取此算法的实现。
结论
在这篇文章中,我们追溯了如何针对要证明的值在一个小域中,而随机性是从一个相对较大的域中提取的情况优化 sumcheck 协议。
在下一篇文章中,我们将讨论如何优化大素数域中的 eq~ 函数和 sl 乘法。
zkSecurity 为包括零知识证明、MPC、FHE 和共识协议在内的密码系统提供审计、研究和开发服务。
- 原文链接: blog.zksecurity.xyz/post...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





