ZKsync Airbender:最快的开源 RISC-V zkVM
- ZKsync 中文
- 发布于 2025-06-25 23:10
- 阅读 2119
ZKsync 发布了 Airbender,这是一个高性能的通用 ZK 证明器,旨在满足互操作性、去中心化和可扩展性的实际需求。Airbender 是最快的开源 RISC-V zkVM,其性能优于其他领先系统,例如在单个 GPU 上证明以太坊区块的时间少于 35 秒,并通过利用 ZKsync OS,能够在大约 17 秒内证明平均以太坊区块的执行。

隆重推出 ZKsync Airbender:世界上最快的开源 RISC-V zkVM
今天,我们很荣幸地推出 ZKsync Airbender,这是一款高性能、通用型 ZK 证明器,旨在满足互操作性、去中心化和可扩展性的实际需求,而无需妥协。
Airbender 不仅仅是快速。它是我们见过的最快的开源 RISC-V zkVM。在基准测试中,Airbender 的性能远远超过了其他领先系统。它已实现:
-
ZKsync 区块的亚秒级证明,以及使用单个商用 GPU 约 3 秒的证明
-
比最接近的竞争者快约 4-6 倍。
-
单个 H100 上最快的证明(底层为每秒 2180 万个周期,端到端为每秒 850 万个周期)
-
仅使用 单个(!)GPU 即可平均在不到 35 秒的时间内证明以太坊区块(而现有的设置使用 50-160 个 GPU 在 12 秒内进行证明,具体取决于区块的大小)。
-
Airbender 还可以在 17 秒内证明以太坊区块而无需递归,这告诉我们 在单个 GPU 上进行实时证明是可能的。
这些性能提升不仅仅是数字。它们开启了一个未来,在这个未来,链可以实时协调和结算,开发人员可以使用本地证明生成构建客户端应用程序,并且整个生态系统都可以从更快、更便宜和更去中心化的基础设施中受益。
世界上最快的开源 RISC-V zkVM
Airbender 速度很快,我们有数据可以支持。
我们使用标准化的 Fibonacci 程序,针对两个领先的 zkVM 证明系统 RiscZero 和 SP1 (Turbo) 对 Airbender 进行了测试,以确保同类比较。基准测试在 NVIDIA L4 和 H100 GPU 上运行,我们测量了两个阶段的性能:
-
基础证明:证明生成的第一轮
-
STARK 递归:后续轮次,其中将基本证明聚合为一个或少量最终证明。
以下是 Airbender 的性能(MHz 越高,系统越快):
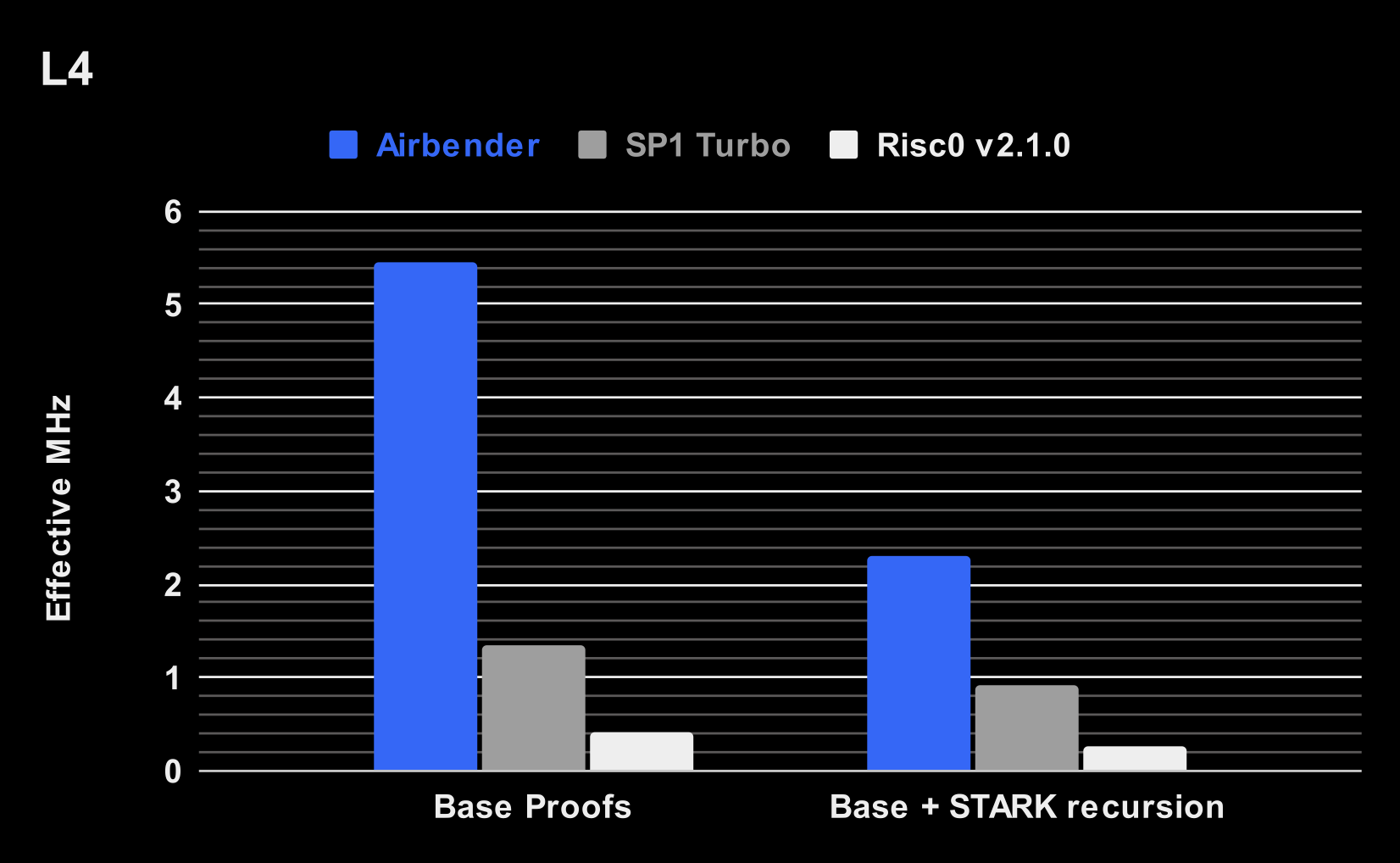
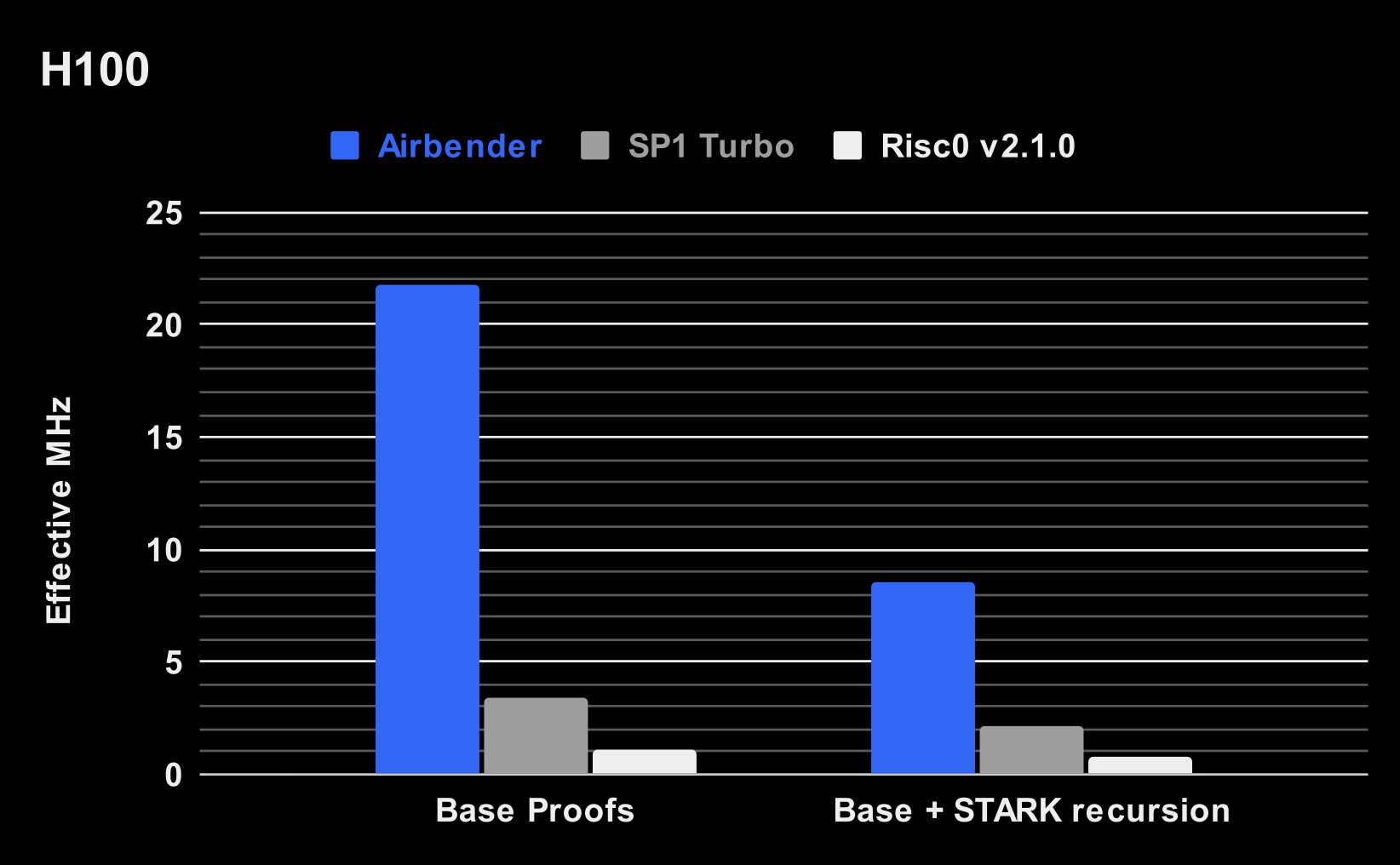
这些数字表明:
-
Airbender 是功能强大的 ( H100) GPU 和更小、更经济的 ( L4) GPU 上最快的 基础层证明器。在 H100 上,它实现了 21.8 MHz(每秒证明的周期数为百万次),而 SP1 Turbo 为 3.45 MHz,RiscZero 为 1.1 MHz。
-
Airbender 是 最快的端到端证明器(包括递归):比 SP1 Turbo 快 2.5-4 倍,比 RiscZero 快 8.5-11 倍。
你可以在此处自行重现 这些基准测试 .。这些是早期结果——我们才刚刚开始。未来几周可能会有更多改进。
在单个(!)GPU 上实现接近实时的以太坊证明
通过利用 ZKsync Airbender 和 ZKsync OS(我们新的 EVM 执行环境),我们能够在使用 ZKsync OS 存储模型的情况下,在大约 17 秒内 使用单个 H100 证明平均以太坊区块的执行(在递归之前),并在大约 35 秒内完成端到端证明(带递归)。这些 基准测试可以在此处重现。
这是一个重大的突破,为家庭证明以太坊铺平了道路。
现有的替代方案需要大量的硬件才能实现相当的结果。例如,在 Succinct 的实时证明公告中,SP1 Hypercube 花费了大约 12 秒来证明以太坊区块,但需要 50-160 个 GPU(Nvidia 4090,大致相当于 H100)。
Airbender 以一小部分硬件实现了可比的性能。更高效的证明不仅仅意味着更低的成本。它还实现了我们正在构建的未来:一个去中心化的链网络,可以实时协调、结算和互操作。
值得注意的是,SP1 使用了不同的执行环境和存储模型,因此这不是 zkVM 的同类比较。但这正是我们的观点:我们的性能源于整个系统的实力,从 zkVM 到引擎再到证明架构。Airbender 的效率是 ZKsync 堆栈中深度集成的产物。最终,重要的不仅仅是原始基准测试,而是系统实际可以做什么。ZKsync 可以使用消费级硬件提供接近实时的区块证明。这是一个突破。
ZKsync 链及其他链的亚秒级区块证明
所有新的 ZKsync 链都将使用 Airbender 作为未来的证明系统,取代当前的 Boojum 证明器。Abstract、Sophon、GRVT、Lens 和 Memento 等链将能够迁移到 Airbender,并利用其速度和效率。Airbender 将每次传输的证明成本降低至仅 0.0001 美元,已经比 Boojum 便宜 10 倍以上,从而为弹性网络中的应用程序带来了有意义的节省和性能提升。
Airbender 不仅仅适用于 ZKsync 链。其开源设计和 RISC-V zkVM 使其适用于证明任何类型的程序。它为通用、可验证的应用程序开启了更广阔的未来。其设计支持在普通消费硬件上进行证明,为游戏、身份和去中心化 AI 中的新用例打开了大门。我们将继续改进开发人员体验,并将在 @ZKsyncDevs on X 上分享更新。
亲自测试 Airbender!
我们发布了一个有趣的应用程序来展示 Airbender 的功能。它旨在突出这种性能在实践中的意义:从提交 tx 到 ZKsync OS 测试网上的完整区块证明验证。
虽然 Airbender 仍处于测试阶段,尚未准备好投入生产,但开发人员可以立即开始使用 Airbender 进行构建。我们正在积极努力改进开发人员体验,并欢迎任何尝试过的开发人员提供反馈。
无论你是构建私有链、ZK 原生应用程序还是跨链基础设施,Airbender 都提供了一个灵活的 zkVM 和专门为快速、原生互操作性构建的证明系统。它的性能还解锁了新的应用程序设计模式,链可以近乎实时地进行通信,开发人员可以以无需信任、低延迟的执行方式跨网络协调逻辑。
技术深入探讨
什么是 ZKsync Airbender?
这些基准测试令人兴奋,但让我们退一步。什么是 Airbender?
Airbender 是 ZKsync 的新 zkVM 和证明系统,旨在生成 RISC-V 字节码执行的 ZK 证明。它与 ZKsync OS 一起构建,ZKsync OS 是我们用于 ZKsync 链的模块化操作系统,专为支持各种执行环境而定制,包括 EVM、EraVM 和 WASM。简而言之,Airbender 和 ZKsync OS 为在弹性网络中构建的团队带来了更高的性能和更多的可定制性。
核心证明引擎基于 AIR 约束,这些约束被编译成在 Mersenne31 素数域上高度优化的 DEEP STARK 证明。该系统支持自定义机器配置、预编译电路(例如 Blake2s/Blake3、大整数算术)和递归证明模式。
这种架构允许开发人员和协议运营商针对不同的用例进行优化:去中心化、成本效益或证明压缩。
证明架构
Airbender 的性能,包括在单个 GPU 上证明链的突破,是通过一组精心设计的组件实现的。
证明管道遵循一个五阶段结构,该结构针对灵活性和吞吐量进行了优化:
-
见证承诺: 计算低度扩展 (LDE) 和跟踪承诺。
-
查找和内存参数: 使用查找表验证内存操作。
-
STARK 商多项式: 通过 AIR 多项式对电路约束进行编码。
-
DEEP 多项式构造: 实现 FRI 批处理以减少证明大小。
-
FRI IOPP: 生成最终的邻近证明。
执行模型
Airbender 实现了 RISC-V 32I+M 指令集,以标准的提取-解码-执行循环运行。 字节码通过 ROM 加载,并以大约 400 万个周期为单位进行处理。 通过内存参数将块缝合在一起,可以水平扩展 Prover 性能。
该系统支持 内核模式,用于 ZKsync OS 系统级逻辑。
设计考虑因素
-
混合 CPU/GPU: Airbender 支持使用 CPU、单个 GPU 或多个 GPU 进行证明。 对于后两个选项,CPU 执行 RISC-V 模拟和跟踪,然后 GPU 计算见证生成和其余步骤。
-
RAM 支持的寄存器: 所有 32 位寄存器都在 RAM 中实现,从而简化了电路并将寄存器管理推迟到内存查找。
-
Mersenne31 字段算术: 针对 STARK 性能优化的快速算术运算。
-
自定义预编译: 通过基于 CSRRW 操作码的委派机制支持加密操作和大整数数学。
致谢
感谢许多帮助推动该行业发展的密码学家和工程师。 特别感谢 RiscZero 开创了 RISC-V zkVM、Starkware 开创了包括 Circle STARK 在内的 STARK,以及 Polygon 开创了 Mersenne31 Prime 和 Circle Group 的工作。 更多详细的致谢可以在 Airbender 存储库中找到。
- 原文链接: zksync.mirror.xyz/ZgRmbY...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





