以太坊技术系列-以太坊数据结构
- web3探索者
- 发布于 2022-02-21 09:43
- 阅读 6212
本篇文章和大家介绍一下以太坊的数据结构。
本篇文章和大家介绍一下以太坊的数据结构,上篇文章我们提到,以太坊为了实现智能合约这一功能,使用了基于账户的模型。我们来看看以太坊中数据结构。
账户状态树
哈希表
既然是基于账户的模型,我们需要通过账户地址找到账户的状态。就像通过银行卡号可以找到你在银行中的各种信息一样。最简单的想法当然是一个简单的哈希表 key是账户地址 value是账户状态。但这里有个问题解决不了。
轻节点如何校验账户合法性?
上篇我们说过,区块链中有2类节点,全节点和轻节点,轻节点只会存储block header,所以轻节点如何才能校验账号是否合法呢?
Merkle Tree(哈希树)
这个思路和我们平时用的md5校验一致,我们会对区块内的信息进行hash运算从而得出区块内信息唯一确定的值,区块链所有节点中这个值都是相同的。
在这个过程中我们用到了一种数据结构Merkle Tree(哈希树),我们先看下Merkle Tree(哈希树)的示意图。
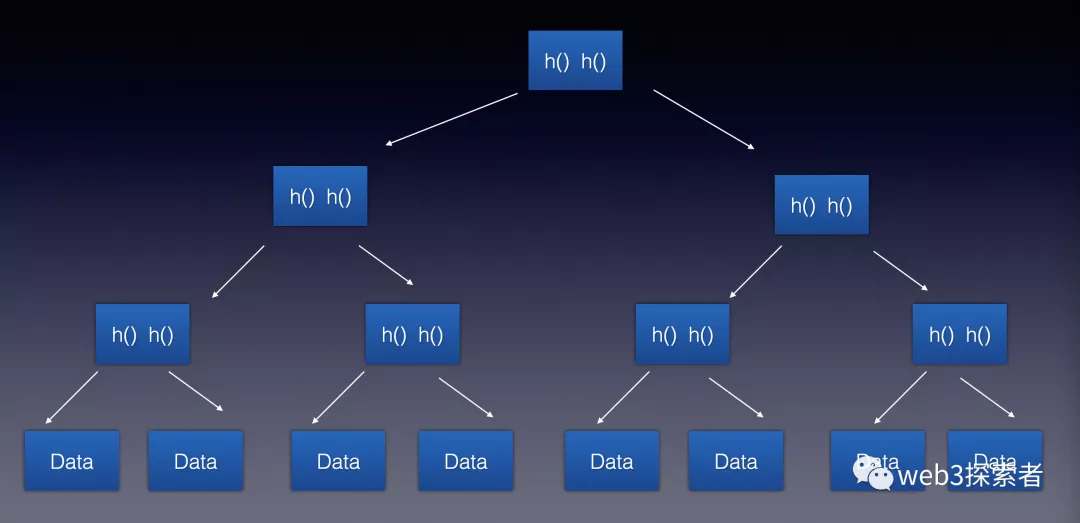
上篇文章说到区块链中的链表(哈希链)和我们平时常见链表不同的是将指针从地址改为了hash指,这里也一样,哈希树和二叉树的区别有2个
1.将地址改为了哈希值
2.只有叶子节点存储数据
回到之前的问题轻节点是如何校验1个账户或交易是否是在链上的呢?
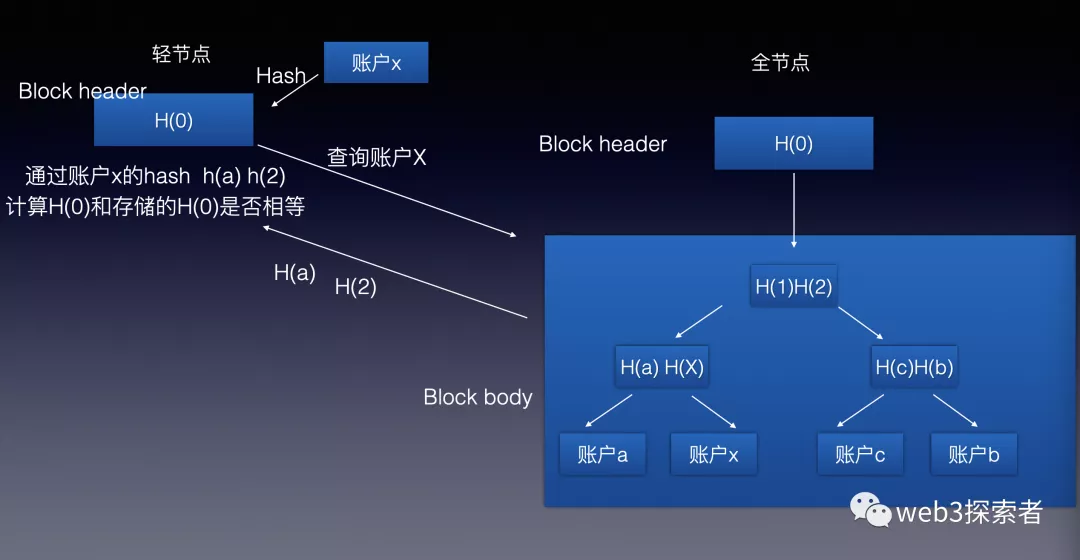
整个流程如上图所示
1.轻节点需要判断1个账号是否合法
2.轻节点由于只存储block header,所以拿到1个账号的时候会向全节点发出请求
3.全节点存储了所有账户状态,将账户路径中的需要计算用到的hash值返回给轻节点
4.轻节点本地进行计算根hash值,如果计算结果和自己存储一致则账户合法,不一致则不合法。
那以太坊中的账户信息的数据结构就是这样吗?
直接用这样的数据结构来存储账户信息会有2个问题
查找困难
生成hash值不确定
第1个问题应该比较容易发现,在这个树中寻找1个账号需要的复杂度是O(n),因为没有任何顺序。
第2个问题其实也是因为无序导致的,无序的组合每个节点针对同一批账户生成的hash值不一致,这就导致无法达成共识。
字典树
既然2个问题都和顺序有关,那我们类似二叉排序树一样,使用哈希排序树是不是就可以解决问题了呢?
使用排序树后会带来另外1个问题
插入困难
因为要维持树是有序的,很可能带来树结构的很大变动。
以太坊中使用了另外一种数据结构字典树。和哈希树不同,字典树应该是很多地方都有使用。我们简单来看下字典树的结构。
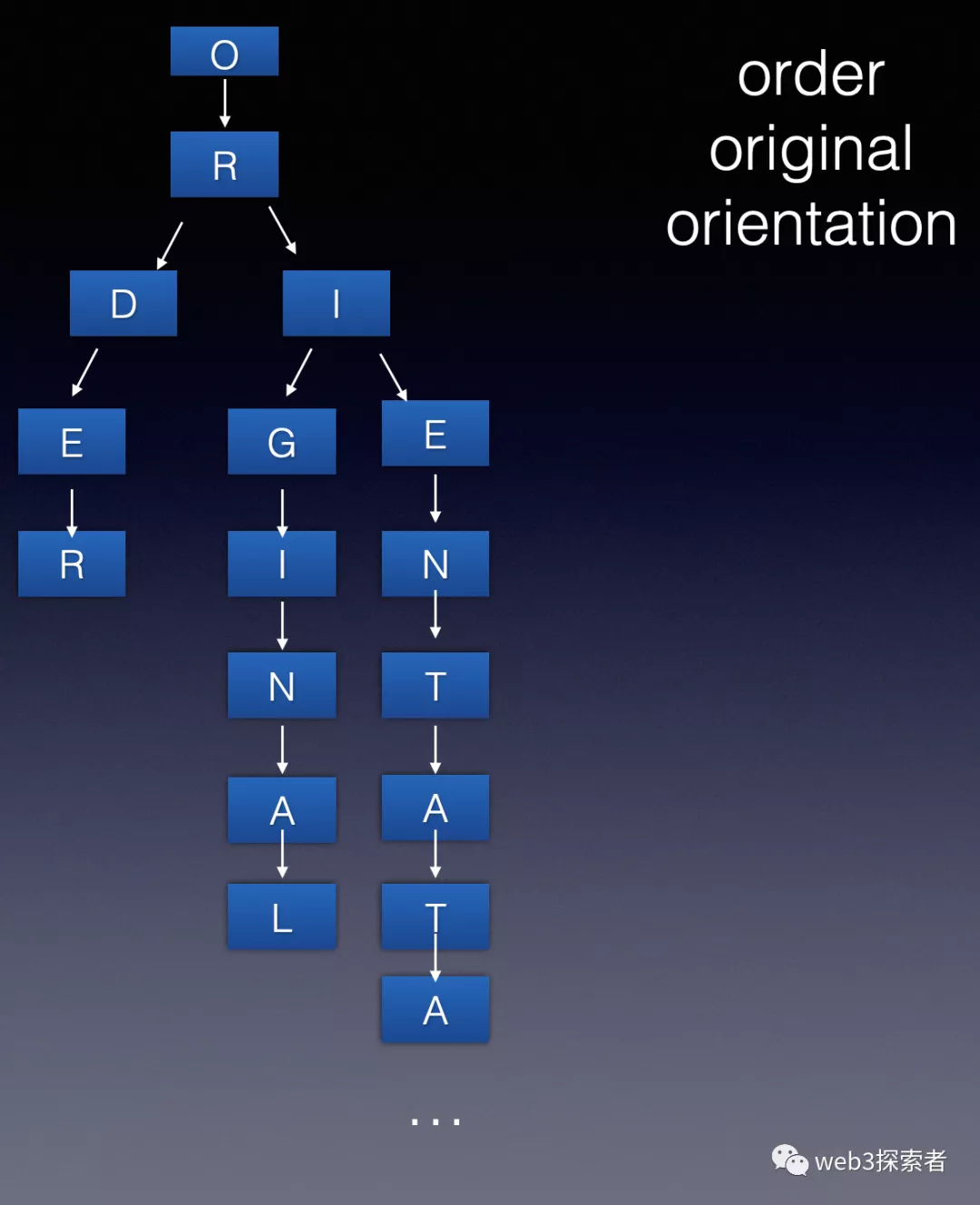
字典树能够较好地解决哈希树的2个缺点1.查找困难 2.生成的hash值不确定以及排序二叉树的1个缺点 插入困难。
但字典树我们可以看到可能树的深度可能由于部分元素导致整棵树深度非常深。
压缩字典树
这时我们可以进一步优化,将相同路径进行压缩。这就是压缩字典树。
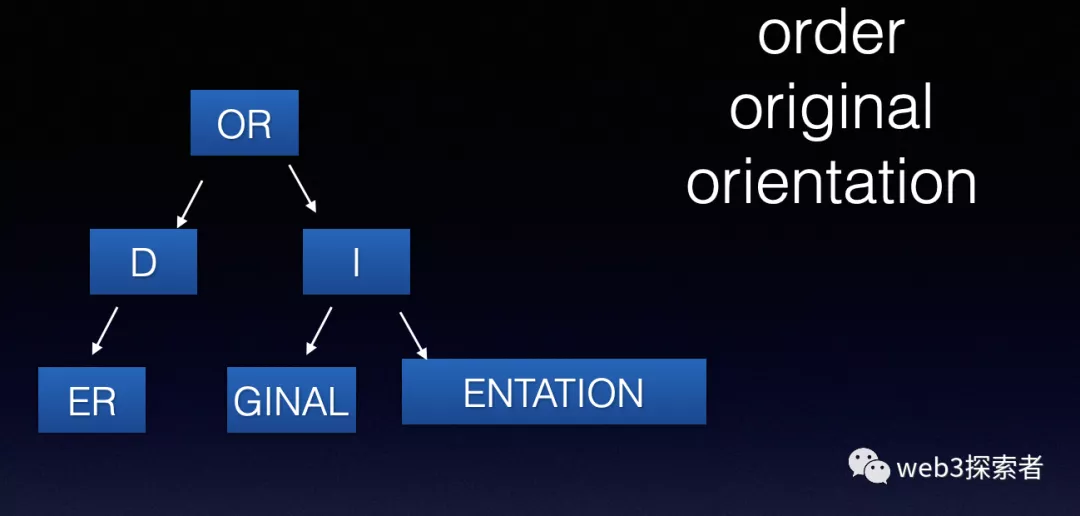
MPT(哈希压缩字典树, 有专业翻译,但个人认为这样翻译比较易理解)
将哈希树和压缩字典树结合,就可以得到以太坊存储账户的最终数据结构-MPT。
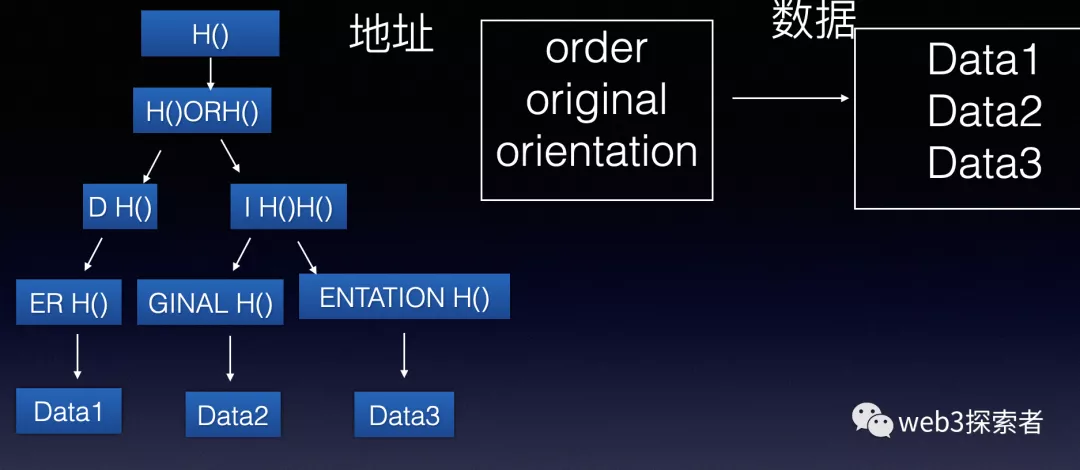
将压缩字典树里面的指针从地址改为指针,并且将数据存储在叶子节点中即可。
状态树存储域
介绍完状态树的数据结构,我们接下来讨论1个问题,区块中存储的账户状态是什么样的范围。有2种选择。
只保存当时区块中产生交易的账户状态。
保存全局所有的账户。
我们可以看下这2种方式,无非就是空间和时间的平衡,只保存当前区块产生的交易意味着是做懒加载(需要的时候才去寻找账户),在区块链中这个代价是非常大的,因为寻找的账户之前从未交易过,这样会遍历整个区块链。另外一种保存全局的账户方式虽然看起来空间消耗较大,但查找快捷,而且空间的问题我们可以通过其他方式优化。所以最终以太坊选择了第2种每个区块都报错全局所有账户的方式。
我们来看下以太坊中是如何保存状态树的。
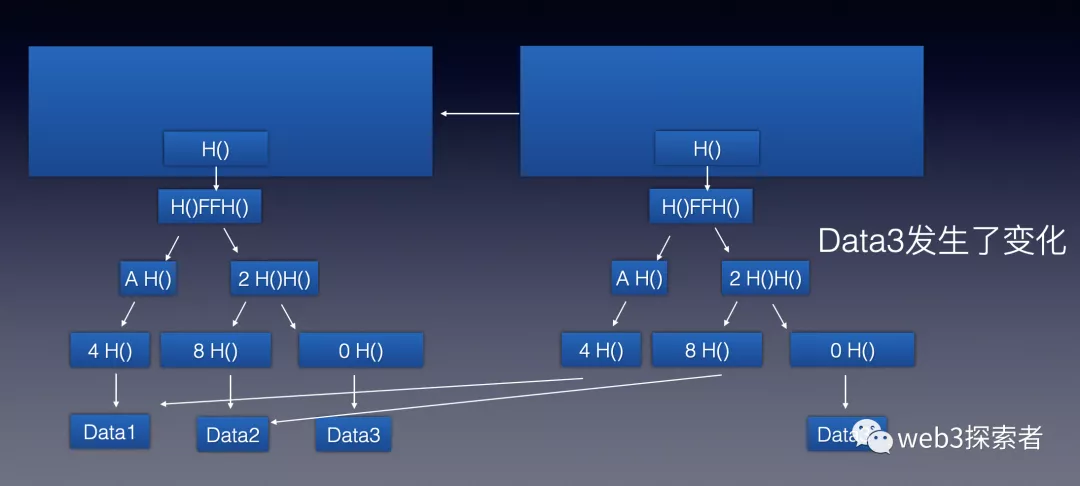
可以看到以太坊中虽然每个区块都保存了全部账户,但是会将未发生变化的账户状态指向前1个节点,本身只存储发生变化的状态,这样可以较大程度优化空间占用。
交易树&收据树
介绍完以太坊中比较复杂的状态树后,我们继续来看看以太坊中的另外两棵树,交易树和收据树。
首先介绍一下,为什么需要交易树&收据树。
1.交易树
虽然以太坊是基于账户的模型,但是就像银行不仅会存储银行卡的余额,还会存储卡中的每笔钱怎么来的以及怎么花的。交易树中就存储着当前区块中的包含的所有交易。
2.收据树
由于智能合约的引入增加了不少复杂性,所以以太坊用收据树存储着一些交易操作的额外信息。比如交易过程中执行日志就包含在收据树中方便查询。收据树和交易树是一一对应的。每发生一次交易就会有一次收据。
和状态树不同交易树和收据树只维护当前区块内发生的交易,因为当时区块发生交易时不需要再去查找另外1个交易,也就之前需要可能遍历整个区块链的查找操作了。
由于以太坊中的出块速度较快,我们进行一些查询一些符合条件交易的时候会面临大量数据遍历困难的问题。收据树中引入了布隆过滤器可以帮助我们有效缓解这一困难。
布隆过滤器
布隆过滤器将大集合中每个元素进行hash运算映射到1个较小的集合,这时再来1个元素要判断是否在大集合的时候,不需要遍历整个大集合,而是去进行hash运算去小集合中寻找是否存在,如果不存在,肯定不在大集合中,如果存在则不能说明任何问题。
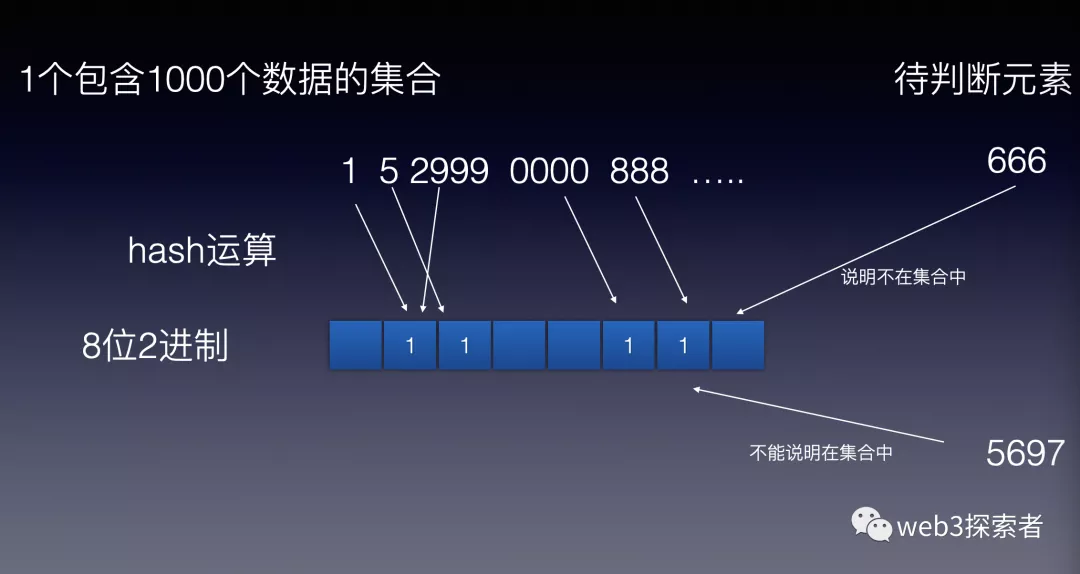
如上图所示,布隆过滤器只能证明某1个元素不在集合中,不能证明1个元素在结合中。
以太坊中如果我们要在较多区块中寻找某1个交易,则可以利用布隆过滤器,过滤掉肯定不存在目标交易的区块,然后进入收据树内继续利用布隆过滤器筛选,剩下的才是可能的目标交易的交易,进行一一比对即可。
总结
我们介绍了以太坊的核心数据结构,状态树&交易树&收据树,他们都是使用相同的数据结构-哈希压缩字典树。但状态树是维护1颗全局账户树,交易树和收据树则是维护本区块内的交易或收据。
介绍完数据结构后,后面我们会用几篇文章来介绍以太坊中的一些核心算法,比如共识机制,挖矿算法等。
更多web3相关文章 可关注公众号 "web3探索者"





