Solana XDP 延迟优化解析
- harsh_patel
- 发布于 1天前
- 阅读 28
本文探讨了在 Solana 网络中使用 XDP (eXpress Data Path) 优化延迟的技术方案。通过将 Jito Shredstream 的标准 Linux UDP 内核栈替换为基于 eBPF 的内核绕过技术,作者实现了更低且更稳定的数据传输延迟。文章详细解释了 AF_XDP 的工作原理、NIC 队列映射以及在实际主网环境下的基准测试结果。

Solana 验证器客户端的性能一直是其工程文化的核心。为了追求极致的性能,XDP (Express Data Path) 和 eBPF 成为了必然的选择。Solana 验证器有多个“端口”用于接收来自网络的“数据包”,从网络工程师的角度来看,这些包括交易(投票和非投票)、Shreds、修复请求或 Gossip 消息。
以下是验证器中涉及网络 I/O 的主要进程:
- Gossip
- RPC (TCP)
- Ip_echo (TCP)
- Tvu
- Tvu_quic
- Repair
- Repair_quic
- Serve_repair
- Serve_repair_quic
- Ancestor_hashes_requests_quic
- Ancestor_hashes_requests
- Tpu
- Tpu_forwards
- Tpu_vote
- Tpu_quic
- Tpu_forwards_quic
- Tpu_vote_quic
- Retransmitter
- Broadcast
这些进程都使用网络套接字进行 I/O,并且都能从 XDP 的性能提升中受益。XDP eBPF 程序在内核分配 sk_buff 之前、在 softirq/NAPI 批量处理之前以及在大部分网络栈之抢跑。这就是它在现代硬件上每核心能达到 10–20+ Mpps 的原因。
为了在生产环境中测试性能,我选择了 Jito shredstream。Jito shredstream 代理是一个原生的 UDP 摄取和分发系统,它通过原始 UDP 接收直接从区块引擎推送的 Solana Shreds,主要供交易者和索引器使用,以实现最低延迟的访问。传统的 shredstream 使用 sendmmsg() 和 recvmmsg() 系统调用,这些调用依赖于内核网络栈。
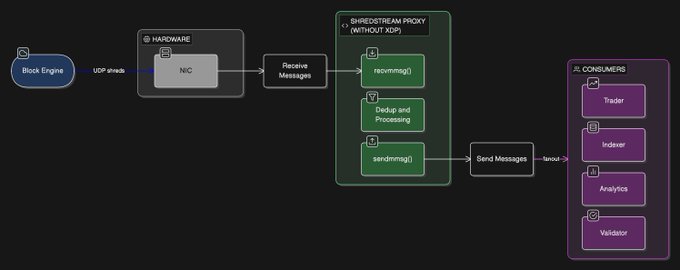 原生 Shredstream 架构
原生 Shredstream 架构
XDP Shredstream 架构设计
在修改后的架构中,我将内核系统调用替换为 XDP 发送和接收循环。同时附加了一个带有过滤器的 eBPF 程序,用于识别目标数据包 (Shreds) 并将其重定向到特定的网卡 (NIC) 队列。
为什么选择特定队列?因为在 XDP 进程初始化期间,每个选定的 NIC 队列都绑定了一个 AF_XDP 套接字。网卡暴露一组固定的物理硬件队列,这些队列通过名为 XSK map 的哈希表结构映射到用户态的 AF_XDP 套接字文件描述符。eBPF 程序通过 XSK map 确定在数据包通过过滤器后应将其交给哪个套接字。
这种模型非常清晰:一个 NIC 队列对应一个 AF_XDP 套接字,对应一个用户态 XDP 进程(接收或发送),并绑定到一个物理 CPU 核心。
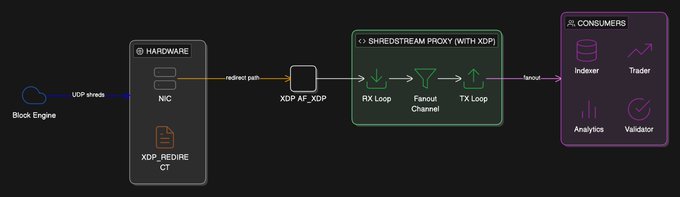 XDP Shredstream 架构
XDP Shredstream 架构
延迟测量:起点与终点
为了对比内核栈与内核旁路 (Kernel Bypass) 的性能,我测量了代理的内部转发延迟。
UDP 路径
起点设在 recvmmsg() 调用之前,终点设在用户态调用 sendmmsg() 且内核 UDP 发送路径返回之后。该测量涵盖了内核接收处理、套接字移交给用户态、用户态转发工作以及内核发送路径。
XDP 路径
起点设在数据包进入 AF_XDP 用户态接收路径时,终点设在数据包提交到 AF_XDP 发送环 (TX ring) 时。该测量涵盖了用户态接收循环、复制、去重、通道移交、发送循环工作以及 AF_XDP 发送提交,基本排除了内核网络路径。
两者之间的差距大致就是 XDP 消除的内核栈成本。


基准测试结果分析
在多次运行中,XDP 的表现始终保持稳定,而 UDP 则表现出较多噪声。虽然 UDP 的中位数延迟较低,但在高百分位 (p90、p95、p99) 中,UDP 变得非常不稳定,延迟甚至会延伸到毫秒级。
相比之下,XDP 在不同运行周期内都保持在极窄的范围内。这表明 XDP 的主要优势不仅在于降低平均延迟,更在于在实时流量下提供极佳的一致性。
测试设置与启动序列
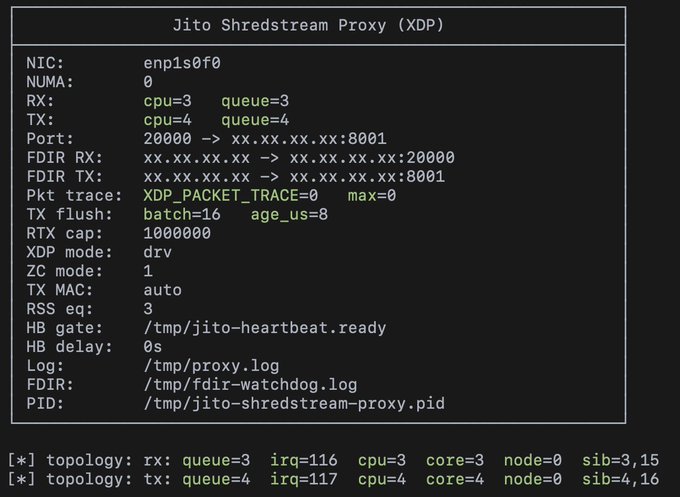
原生 UDP 和 XDP 二进制文件集成在同一个 CLI 中。XDP 进一步分为 SKB 和 DRV 附加模式。测试脚本先运行 UDP 模式,然后花费约 12 秒拆卸并设置 XDP,再启动 XDP 用户态进程。
启动序列中的挑战
原生 UDP 代理通过 gRPC 向 Jito 区块引擎发送心跳。在 UDP 模式下,绑定套接字不会重置网卡。但在 XDP 模式下,将程序附加到网卡时,驱动会重置接口,导致短暂的链路闪断。在此期间,DNS 解析、TCP 连接和 TLS 握手都会失败。
解决方案:
- 重新排序启动逻辑:心跳线程仅在转发器和 XDP 线程完全启动后才开始。
- 外部门控文件:二进制文件会等待一个外部文件出现后再启动心跳。该文件仅在 XDP 附加、套接字绑定、中断亲和性等规则验证通过后才会创建。
- 安全延迟:在门控文件出现后增加可配置的延迟,确保系统完全稳定。
管道差异对比
除了架构图展示的区别外,还有几个关键点:
- 批处理边界:原生 UDP 从一开始就是批处理优先的。XDP 在接收环上是面向环的,但转发到发送循环的逻辑是逐包进行的,随后在发送端根据批次大小和最大延迟重新批处理。
- 数据包构建:XDP 在用户态构建 L2/L3/L4 报头并直接写入 AF_XDP 发送环;而原生 UDP 将数据包构建和传输委托给内核栈。
- 线程拓扑:UDP 为每个套接字运行一个监听线程和一个发送线程。XDP 为每个队列对运行一个接收线程和一个发送线程,是更显式的按队列管道模型。
总结与展望
数据证明,在 p99 延迟下,XDP shredstream 保持在 200 微秒以下,而原生 UDP 则会达到数十毫秒。这是 XDP 内核旁路首次在 Solana 实时主网流量下与原生内核栈进行对比基准测试。
这些数字揭示了内核栈的实际成本,以及移除它后所获得的性能提升。这不仅对 shredstream 意义重大,对于验证器的所有网络端口同样具有参考价值。
未来的研究方向将包括:
- 接收路径的 CPU 分析
- 合并接收-发送循环的基准测试
- 更换内部组件(如将 crossbeam 替换为简单的 SPSC 队列)
SO_BUSY_POLLING与 Run-to-completion 套接字模式的对比分析
- 原文链接: x.com/harsh_patel/status...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





