使用Rust和Aya编写eBPF程序
- jkrishna
- 发布于 2025-10-11 21:15
- 阅读 334
本文介绍了如何使用Rust和Aya库编写eBPF程序,包括Hello World程序、BPF Maps(哈希表、Ring Buffer),以及Tail Call的应用。通过实例展示了如何在内核态和用户态之间传递数据,以及如何利用eBPF进行系统观测和动态行为修改。
要点速览
如果你是 eBPF 的新手,我建议阅读之前的文章 学习 eBPF - 第一章 ,以了解 eBPF 是什么以及它为什么重要。
在本章中,我们将重点介绍编写 eBPF 程序。虽然本书使用 C 和 Python,但我将使用 Rust 和 Aya 库来实现相同的示例。
如果你想了解 Aya 项目的结构,例如内核代码和用户空间代码的位置,可以参考我的博客 深入研究 Aya 项目结构
开始
现在让我们开始编写一个基本的 eBPF 程序——传统的 "Hello World"。
在每个编程旅程中,Hello World 都是第一个仪式,所以我们将以同样的方式开始我们的 eBPF 旅程。
#[kprobe]
pub fn hello(ctx: ProbeContext) -> u32 {
info!(&ctx, "Hello World!");
0
}
let program: &mut KProbe = ebpf.program_mut("hello").unwrap().try_into()?;
program.load()?;
program.attach("execve", 0)?; // 如果我们不附加到任何函数,这将永远不会被触发我们在这里的代码有两个不同的部分:eBPF 程序本身,它将在内核中运行,以及一些用户空间代码,我们在其中将该程序加载到内核中并读取它生成的跟踪。
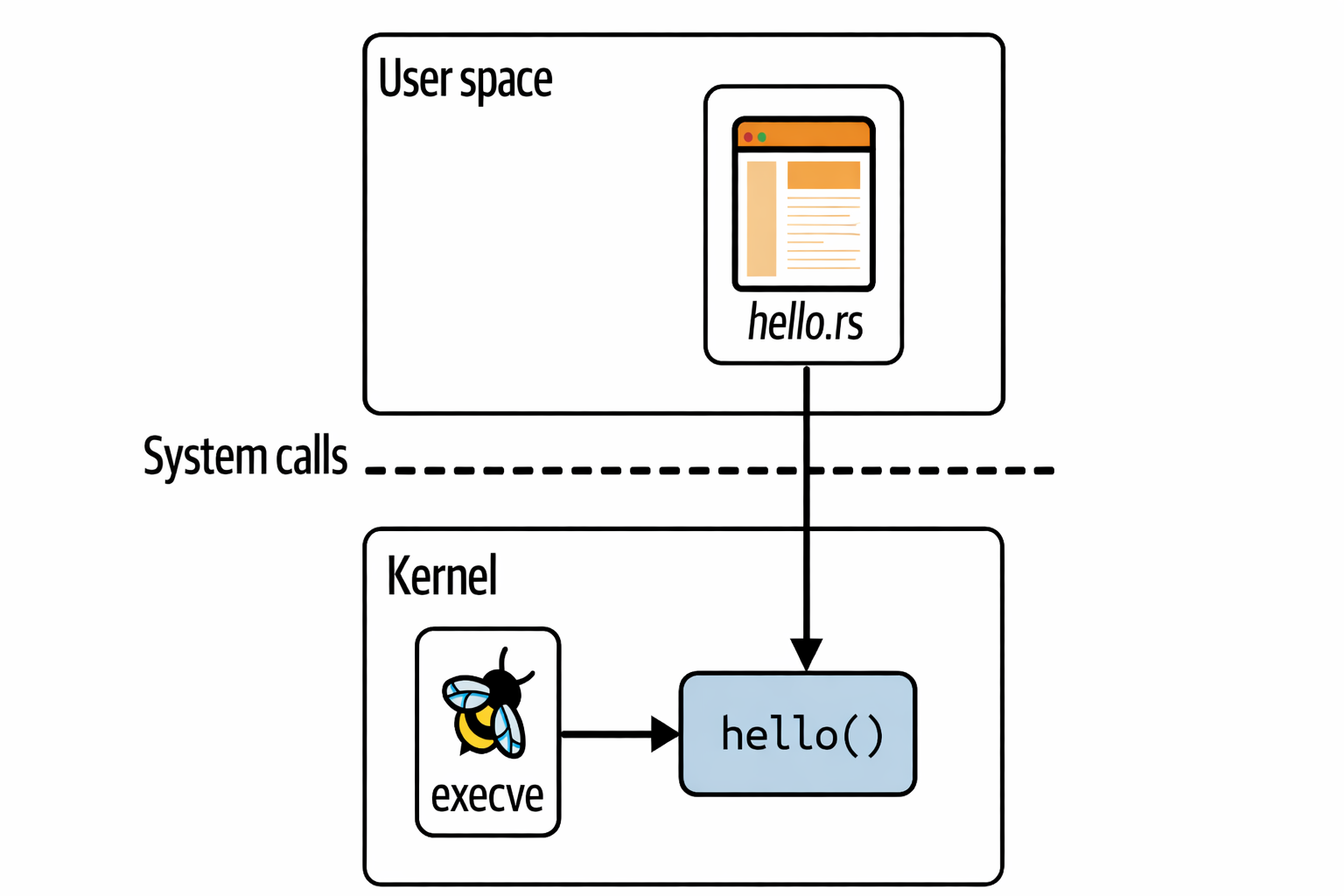 正如你在上图中所看到的,rust 代码是用户空间部分,而 hello() 是在内核中运行的 eBPF 程序
正如你在上图中所看到的,rust 代码是用户空间部分,而 hello() 是在内核中运行的 eBPF 程序
所以现在让我们来看看源代码的每一行,以便更好地理解它
这里我们有一个名为 hello()的 kprobe 函数。#[kprobe] 是一个宏,它告诉编译器这个函数是一个 eBPF 程序,它将以 kprobe 程序类型在内核中运行。
在这里,info() 是一个辅助函数,它将消息打印到内核日志中,类似于 bpf_trace_printk() 函数,该函数在书中显示用于将消息打印到内核日志中。
当我们比较这两个函数 info() 和 bpf_trace_printk()时,我们可以看到它们在功能上是相似的。
整个 eBPF 程序被定义为一个名为 program 的字符串。在任何语言中,无论是 C 还是 Rust,eBPF 程序都需要编译成字节码,然后才能加载或执行。
因为它是一个字符串,我们在函数中以字符串的形式提供函数名。
let program : &mut kprobe = ebpf.program_mut("hello").unwrap().try_into()?;
// 根据内核函数,我们有字符串变化
program.load()?;program.load()?; 会将 eBPF 程序字节码加载到内核中。
每个 eBPF 程序都需要附加到一个事件。如果你看到我们的例子,我们将我们的程序附加到系统调用 execve,当任何事情或任何人在该机器上开始一个新的程序执行时,它会工作,这将调用 execve,这将触发 eBPF 程序。
将程序附加到事件的代码如下:
program.attach("execve",0)?; // 如果我们不附加到任何函数,这将永远不会被触发执行查看以下执行说明:
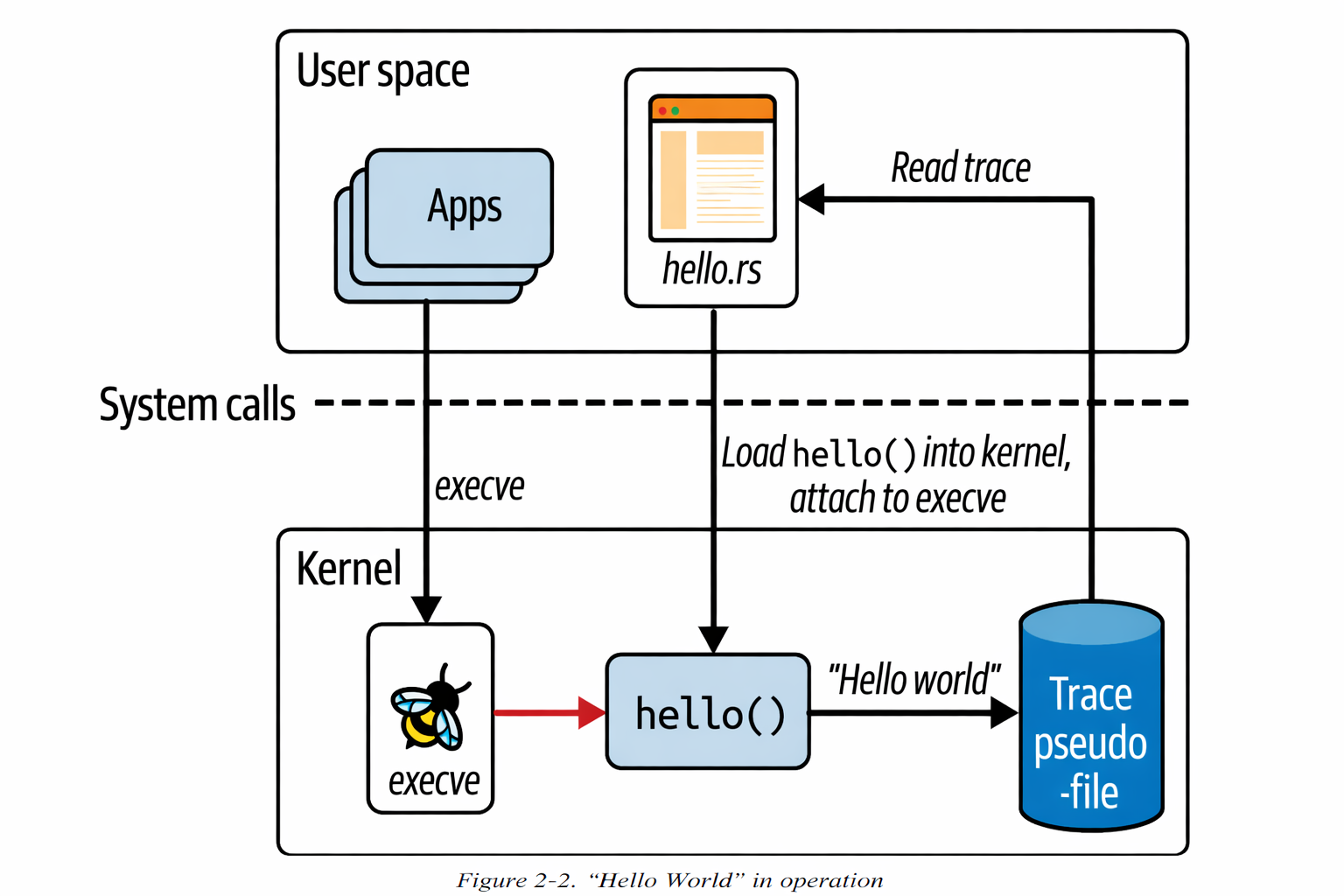
一旦 hello eBPF 程序被加载并附加到一个事件,它就会被从预先存在的进程生成的事件触发。所以这里有第一章的几个要点
-
• eBPF 程序可以用来动态地改变内核的行为。不需要重启系统来应用更改。eBPF 代码一旦附加到一个事件,就开始生效。
-
• 不需要改变任何其他应用程序,它们就能被 eBPF 看到。无论你在那台机器上有终端访问权限,如果你在其中运行一个可执行文件,它将使用
execve()系统调用,并且如果你有附加到该系统调用的hello程序,它将被触发以生成跟踪输出。同样地,如果你有一个运行可执行文件的脚本,它也会触发helloeBPF 程序。你不需要改变任何关于终端的 shell、脚本或你正在运行的可执行文件的任何东西。
BPF 映射
"映射(map)" 是一种数据结构,可以从 eBPF 程序和用户空间访问。映射是将扩展 BPF 与其经典的先驱区分开来的非常重要的特性之一。
映射可以用于在多个 eBPF 程序之间共享数据,或者在用户空间应用程序和在内核中运行的 eBPF 代码之间进行通信。典型的用途包括:
- • 用户空间写入配置信息,供 eBPF 程序检索。
- • 一个 eBPF 程序存储状态,供另一个 eBPF 程序以后检索。
- • 一个 eBPF 程序将结果或指标写入一个映射,供将呈现诸如数据包计数、系统调用计数、延迟柱状图等结果的用户空间应用程序检索。
所以,这其中最核心的思想是:
用户空间 <------ 共享 ------> 内核 (eBPF)
BPF MAP在 Linux 中定义了各种类型的 Bpf 映射,并且在 内核文档 中也有关于它们的一些信息。
一般来说,这些都是键值存储,从这里开始,你将看到哈希表、perf 和 fing 缓冲区以及 eBPF 程序数组的映射示例。
一些映射类型被定义为数组,它有 4 字节索引作为键类型;其他映射是哈希表,可以使用一些任意数据类型作为键。
有许多映射类型针对特定类型的操作进行了优化,例如:
一些 eBPF 映射保存关于特定类型对象的信息,例如 socketmaps 和 devmaps。这些保存关于套接字和网络设备的信息,并被与网络相关的 eBPF 程序使用。
甚至还有一个 map-of-maps 来支持存储关于映射的信息。
哈希表映射
与之前的例子一样,这个 eBPF 程序将被附加到一个 kprobe,该 kprobe 位于 execve 系统调用的入口处。它将使用键值对填充哈希表,其中键是用户 ID,值是用户调用 execve 系统调用的次数的计数器。
内核端的代码如下所示:
// 1
#[map(name = "COUNTER_TABLE")]
static mut COUNTER_TABLE: HashMap<u32, u64> =
HashMap::<u32, u64>::with_max_entries(1024, 0);
#[kprobe]
pub fn hello(ctx: ProbeContext) -> u32 {
unsafe {
// 2
let uid = (bpf_get_current_uid_gid() & 0xFFFFFFFF) as u32;
// 3
let map = &mut *core::ptr::addr_of_mut!(COUNTER_TABLE);
// 4
let counter = match map.get_ptr(&uid) {
Some(ptr) => core::ptr::read(ptr),
None => 0,
};
// 5
let _ = map.insert(&uid, &(counter + 1), 0);
}
0
}这里我指出了代码中重要的行,所以现在让我们讨论其中的每一个:
1 -> 这是我们使用 aya 库中的 HashMap 和 map 宏声明 COUNTER_TABLE 的一行,这个 #[map] 属性告诉内核这是一个哈希映射,应该将其创建为内核对象。
2 -> 这是我们使用 bpf_get_current_uid_gid() 函数获取当前用户 ID 的地方。在这里,0xFFFFFFFF 用于屏蔽 UID 的高 32 位,这些位在内核中未使用。UID 的剩余低 32 位存储在 uid 变量中。
3 -> 在这里,我们使用原始指针从哈希映射中获取计数器表值。
注意: 在这里我们使用原始指针是有原因的,因为在
rust中,我们不能创建一个可变的STATIC变量的可共享引用,因为它是一个全局变量,也可能被其他循环或线程访问,所以我们使用原始指针从STATIC变量中获取值。
4 -> 在这里,我们检查当前用户 ID 的计数器是否在哈希映射中存在,如果不存在,那么我们在 counter 中获取该值,如果存在,那么我们返回 0
5 -> 在这里,我们最终插入 uid 和 counter 值,并对其进行递增,因为它在哈希映射中不存在时为 0。
这些都是内核端的所有重要行,我希望你理解了。
现在,如果我们看到用户空间代码,它看起来更像之前的例子,加载和附加都与此类似。唯一的补充是我们将从用户空间加载映射并使用它。代码如下所示:-
// 1
let program : &mut KProbe = ebpf.program_mut("hello").unwrap().try_into()?;
program.load()?;
program.attach("execve",0)?;
// 2
let map = ebpf
.map_mut("COUNTER_TABLE")
.context("failed to get the counte table hashmap")?;
// 3
let counter_table: HashMap<&mut _, u32, u64> = HashMap::try_from(map)?;
// 4
loop {
print!("counters");
for result in counter_table.iter() {
let (uid,counter) = result;
println!("UID {}=> {}", uid, counter);
}
// 5
std::thread::sleep(std::time::Duration::from_secs(2));
}1 -> 这是我们从内核空间加载我们的 eBPF 程序的地方,基于它们,加载它们并将它们附加到内核。
2 -> 在这里,我们从内核空间加载映射,并将其存储在 map 变量中。
3 -> 我们在 2 中获得的值是一种映射类型,它是一个原始内核Handle,所以在这里我们通过使用 HashMap::try_from 函数验证它,将其转换为 HashMap。
4 -> 这是我们通过迭代 counter_table 哈希映射来打印计数器的循环。
5 -> 在这里,我们让循环休眠 2 秒,然后再再次打印计数器。因此,我们有时间添加更多用户并看到计数器增加。
查看此 分支 以获取此代码执行
现在我们已经完成了关于映射的基本代码,所以现在让我们继续本章的下一个主题。
Perf 和环形缓冲区映射
环形缓冲区
让我们了解一下什么是环形缓冲区。
环形缓冲区是一种以循环方式存储数据并具有固定大小的数据结构。在环形缓冲区内部,有两个指针:一个 写入 指针和一个 读取 指针。
任意长度的数据被写入到当前写入指针所在位置的环形缓冲区中。数据的长度与数据本身一起存储在标头中。写入数据后,写入指针向前移动到该数据的末尾,使其准备好进行下一次写入操作。
请查看此图以获得更好的理解:
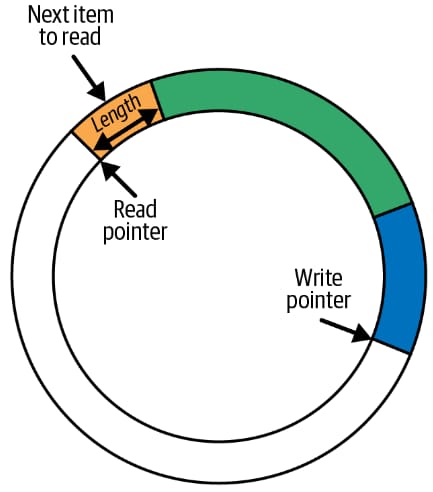
与写入类似,读取操作也以相同的方式工作。数据从当前读取指针所在的位置读取。读取操作使用数据标头来确定要读取多少数据。读取后,读取指针以与写入指针相同的方向前进,以便它指向下一个可用的数据块。
如果读取指针赶上写入指针,这意味着环形缓冲区是空的,并且没有数据可供读取。如果写入操作导致写入指针超过读取指针,则新数据不会写入环形缓冲区。相反,数据被丢弃,并且丢弃计数器递增。
读取操作还包括丢弃计数器,这有助于指示自上次成功读取以来是否丢失了任何数据。在实际场景中,读取和写入操作很少以相同的速率发生,因此必须仔细调整环形缓冲区的大小,以处理数据流的变化并减少数据丢失的可能性。
让我们看看实际情况,之前我们有代码,每当我们进行 execve 系统调用时都会运行,现在在这个代码中,我们每次都会将字符串 Hello world 写入屏幕,并由 syscall 创建,然后它还会查找进程 ID 和名称以命令进行 execve() 系统调用
现在代码如下所示:
// 1
#[map]
static EVENTS: RingBuf = RingBuf::with_byte_size(4096, 0);
// 2
#[repr(C)]
pub struct Data {
pub pid: u32,
pub uid: u32,
pub command: [u8; 16],
pub message: [u8; 12],
}
#[kprobe]
pub fn hello(ctx: ProbeContext) -> u32 {
// 3
let mut data: Data = unsafe { core::mem::zeroed() };
// 4
let pid = (bpf_get_current_pid_tgid() >> 32) as u32;
let uid = (bpf_get_current_uid_gid() & 0xFFFFFFFF) as u32;
data.pid = pid;
data.uid = uid;
// 5
let comm = bpf_get_current_comm()?;
data.command = comm;
// 6
data.message.copy_from_slice(b"hello world\0");
// 7
if let Some(mut buf) = EVENTS.reserve::<Data>(0) {
// 8
buf.write(data);
// 9
buf.submit(0);
}
0
}现在,基于这些要点,我将解释此代码中的所有内容:
1 -> EVENTS 是用于存储数据的 RingBuf 映射。
2 -> Data 是一个结构体,用于存储我们要发送到用户空间的数据。repr(C) 宏用于确保结构体在内存中的布局方式与 C 兼容。
3 -> 在这里,data 是一个类型为 Data 的变量,它是我们定义的结构体,并使用零内存对其进行初始化。
4 -> 在这里,我们获取当前进程的 pid 和 uid,并将它们分配给 data 结构体的 pid 和 uid 字段。
5 -> comm 是正在运行的当前进程的名称,我们通过 bpf_get_current_comm() 辅助函数获取它。
6 -> message 只是我们尝试添加到结构体中的静态消息。
7 -> EVENTS.reserve::<Data>(0) 用于在环形缓冲区中为我们要发送到用户空间的数据保留空间。
8 -> buf.write(data) 用于将数据写入环形缓冲区。
9 -> buf.submit(0) 用于将数据提交到用户空间。
现在让我们移动到用户空间并在那里调用这个内核程序:
// 1
let hello: &mut KProbe = ebpf.program_mut("hello").unwrap().try_into()?;
hello.load()?;
hello.attach("execve", 0)?;
// 2
let map = ebpf
.map_mut("EVENTS")
.context("Failed to get the events map from the kernel")?;
// 3
let mut events: RingBuf<_> = RingBuf::try_from(map)?;
// 4
#[repr(C)]
#[derive(Debug)]
// 5
struct Data {
pid: u32,
uid: u32,
command: [u8; 16],
message: [u8; 12],
}
loop {
// 6
while let Some(record) = events.next() {
// 7
let data = unsafe { ptr::read_unaligned(record.as_ptr() as *const Data) };
// 8
println!(
"pid={} uid={} comm={} msg={}",
data.pid,
data.uid,
bytes_to_str(&data.command),
bytes_to_str(&data.message)
)
}
}
// 9
pub fn bytes_to_str(bytes: &[u8]) -> String {
let end = bytes.iter().position(|&b| b == 0).unwrap_or(bytes.len());
String::from_utf8_lossy(&bytes[..end]).to_string()
}现在让我们逐行浏览代码:
1 -> 这是我们已经看到过的相同部分,它从内核获取 kprobe 程序,加载它并将其附加到内核 execve 系统调用。
2 -> let map = ebpf.map_mut("EVENTS") 用于从内核获取事件映射,并在失败时抛出错误上下文。
3 -> let mut events: RingBuf<_> = RingBuf::try_from(map)? 用于从事件映射创建一个环形缓冲区。
4 -> #[repr(C)] 用于指定结构体的布局。
5 -> Data 是一个结构体,它定义了存储在环形缓冲区中的数据的结构。这与内核空间中的 Data 结构体类似。
6 -> while let Some(record) = events.next() 用于迭代存储在环形缓冲区中的事件。
7 -> let data = unsafe { ptr::read_unaligned(record.as_ptr() as *const Data) }; 用于从环形缓冲区读取数据。在这里,我们使用 read_unaligned 从环形缓冲区读取数据,因为从环形缓冲区获取的字节不能保证对齐。
8 -> println!("pid={} uid={} comm={} msg={}", data.pid, data.uid, bytes_to_str(&data.command), bytes_to_str(&data.message)) 用于打印数据。
9 -> pub fn bytes_to_str(bytes: &[u8]) -> String 用于将字节转换为字符串。
请在此处查看环形缓冲区执行的图示:
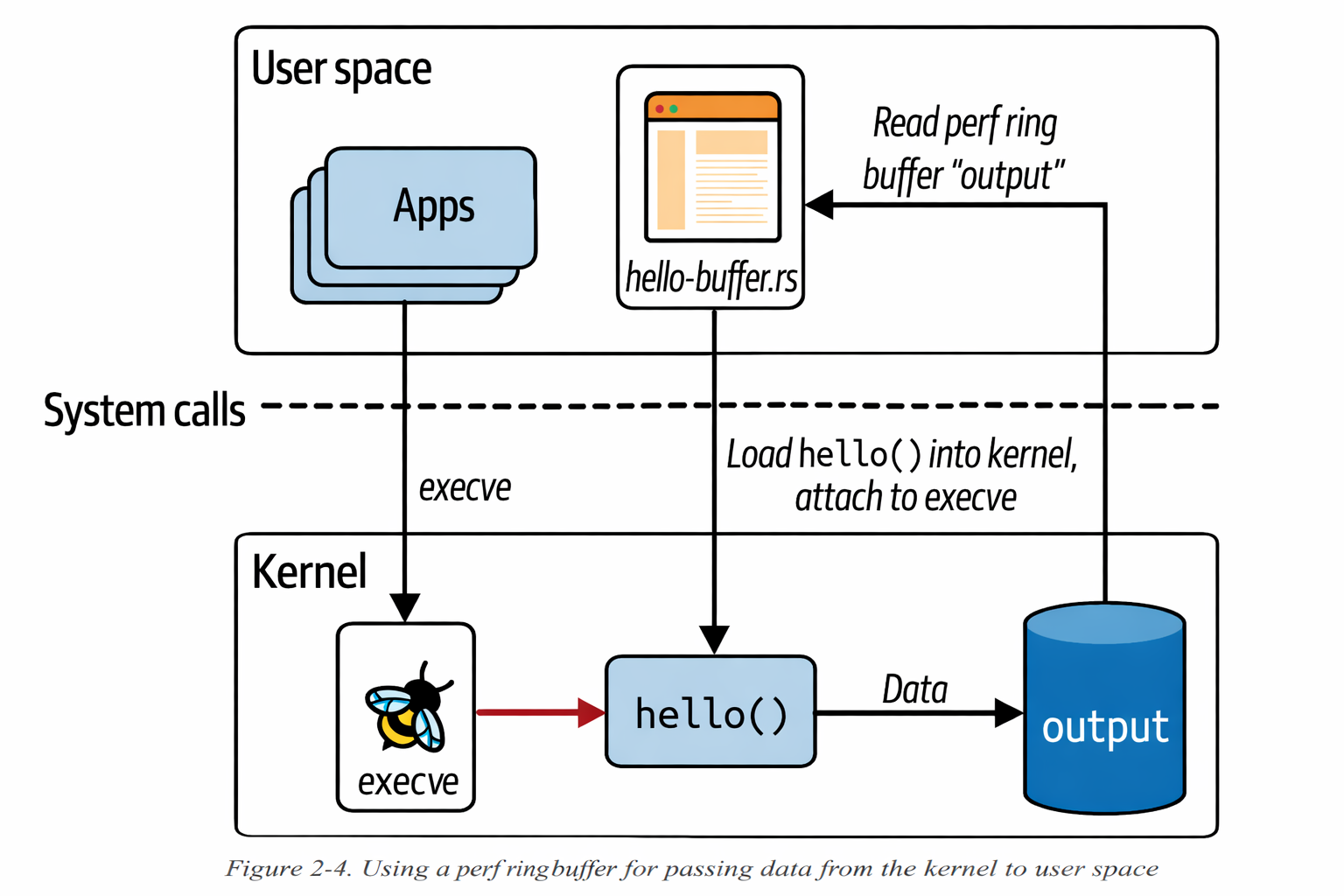
在这里,除了环形缓冲区代码示例之外,我们可以看到我们有一堆辅助函数,这些函数可以帮助我们获取有关用户 ID、进程 ID 和当前命令名称的信息。
像这样的上下文信息在 eBPF 代码中可用,这使得它对于可观察性来说非常强大和有价值。
此外,随着我们进入各个章节,还有多个示例展示了如何针对不同的用例使用 eBPF。
函数单元
在本章中,我们使用了许多内核提供的辅助函数。但是如果你想将你正在编写的代码拆分为不同的函数怎么办?在开发中,对此有一句格言 不要重复自己。
在早期,内核不支持函数调用。因此,开发人员为了解决这个问题,他们指示编译器 always_inline 函数。它看起来像这样:
static __always_inline void my_function(void *ctx, int val)在 rust 中,我们在函数上使用属性
#[inline(always)]
fn my_function(ctx: *mut u8, val: i32) {
// 函数体
}普通函数和内联函数之间的区别在此图中以视觉方式区分
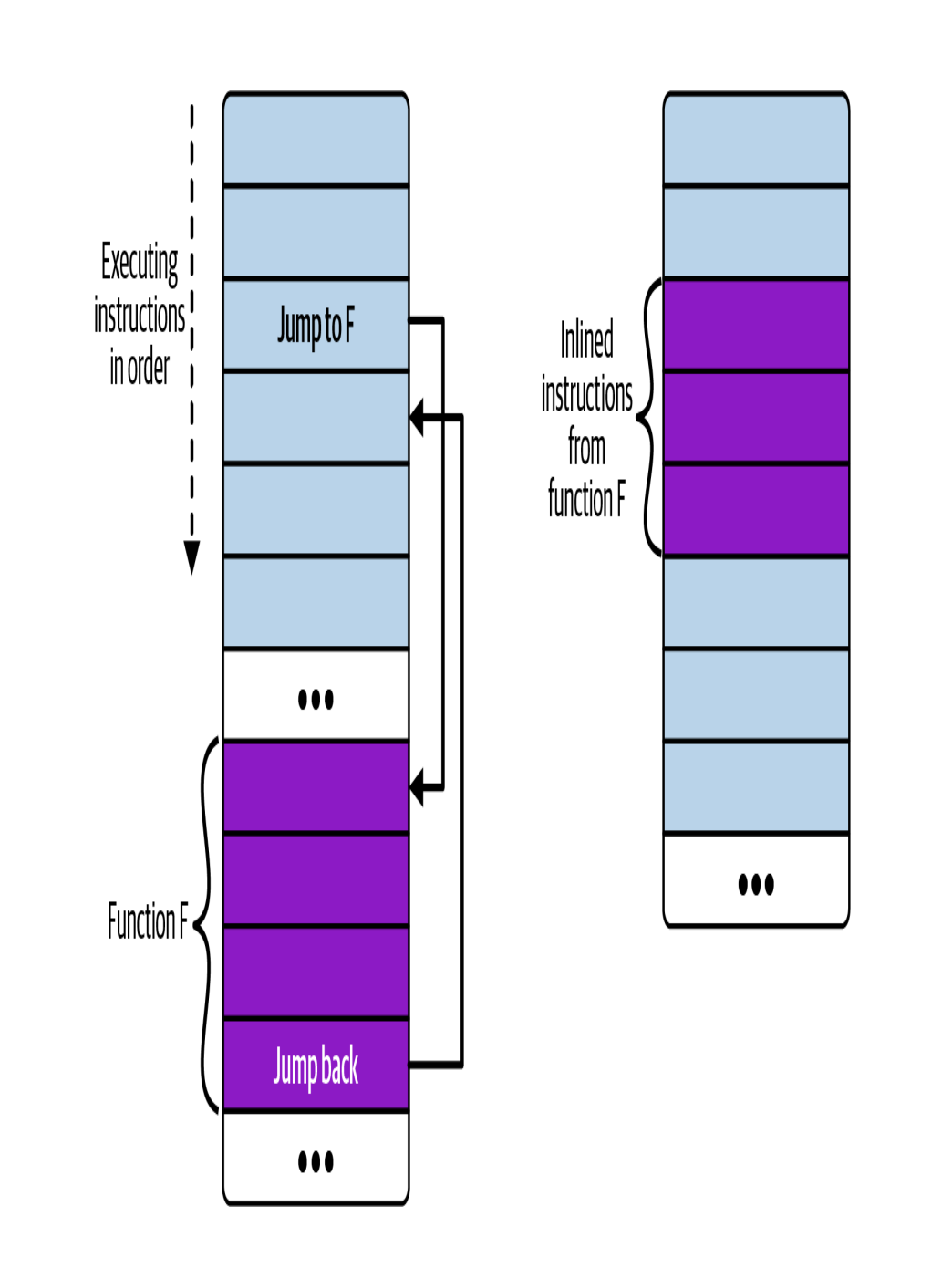
如果从多个位置调用该函数,则会导致该函数指令的多个副本出现在已编译的可执行文件中。(有时编译器可能会选择内联一个函数以进行优化)
尾调用
正如在 ebpf.io 中描述的那样,尾调用将跳转以执行其他 eBPF 程序并替换执行上下文,类似于 execve 系统调用如何用一个新的进程替换当前进程。
现在,让我们像如何在 eBPF 中使用 rust 实现尾调用一样跳转到代码。
// 1
#[map(name = "SYSCALL")]
static SYSCALL: ProgramArray = ProgramArray::with_max_entries(300, 0);
// 2
#[raw_tracepoint]
pub fn hello(ctx: RawTracePointContext) -> u32 {
// 3
let opcode = unsafe { get_opcode(&ctx) };
unsafe {
// 4
// 尾调用是在这里进行的
SYSCALL.tail_call(&ctx, opcode)?;
}
// 5
// 仅当尾调用失败时才执行
info!(&ctx, "tail call failed");
0
}
fn get_opcode(ctx: &RawTracePointContext) -> u32 {
unsafe { (*ctx.as_ptr()).arga[1] as u32 }
}
// 6
#[raw_tracepoint]
pub fn hello_execve(ctx: RawTracePointContext) -> u32 {
info!(&ctx, "Executing a program");
0
}
// 7
#[raw_tracepoint]
pub fn hello_timer(ctx: RawTracePointContext) -> u32 {
let opcode = unsafe { (*ctx.as_ptr()).args[1] as u32 };
let msg = match opcode {
222 => " Creating a timer",
226 => "Deleting the timer",
_ => "Some other timer operations",
};
info!(&ctx, msg);
0
}
// 8
#[raw_tracepoint]
pub fn ingnore_opcode(ctx: RawTracePointContext) -> u32 {
0
}现在让我们逐点检查这里的每一行代码。
1 -> SYSCALL 是一个程序数组,用于存储程序发出的系统调用。
注意: Linux 包含近 300 个系统调用
2 -> 使用宏 #[raw_tracepoint] 来定义一个原始跟踪点函数。这样我们就可以将这个程序附加到跟踪点 sys_enter。
3 -> 由于我们将程序附加到跟踪点 sys_enter,我们需要从上下文中获取系统调用的操作码。基于操作码,我们可以忽略系统调用或执行系统调用。
4 -> 在这里,我们对程序数组中与操作码匹配的条目进行尾调用。
5 -> 如果尾调用失败,我们执行系统调用。如果尾调用成功,我们忽略这一行。
6 -> hello_execve 是一个程序,它将被添加到程序数组 SYSCALL 中。当操作码指示它是一个 execve() 系统调用时。
7 -> hello_timer 是另一个程序,它将被添加到程序数组 SYSCALL 中。当操作码指示这是一个定时器操作时。
8 -> ignore_opcode 是一个什么都不做的尾调用程序。当我们不希望生成任何跟踪时,我们使用这个系统调用。
现在让我们移动到用户空间,让我们看看我们如何调用这些:
// 1
let hello: &mut RawTracePoint = ebpf.program_mut("hello").unwrap().try_into()?;
hello.load()?;
hello.attach("sys_enter");
// 2
let execve: &mut ProgramFd = ebpf.program_mut("hello_execve").unwrap().try_into()?;
execve.load()?
let timer: &mut ProgramFd = ebpf.program_mut("hello_timer").unwrap().try_into()?;
timer.load()?;
let ignore: &mut ProgramFd = ebpf.program_mut("ignore_opcode").unwrap().try_into()?;
ignore.load()?;
// 3
let mut syscall_map = ProgramArray::try_from(ebpf.map_mut("SYSCALL")?)?;
// 4
syscall_map.set(59, execve, 0);
syscall_map.set(222, timer, 0);
syscall_map.set(226, timer, 0);
syscall_map.set(21, ignore, 0);
syscall_map.set(22, ignore, 0);
// 5
aya_log::EbpfLogger::init(&mut ebpf);让我们逐点理解每一行代码的作用:
1 -> 在这里,我们不是附加到 kprobe,而是这次我们将程序附加到 sys_enter 跟踪点。
2 -> 在这里,我们只是调用和加载程序,而不将它们附加到任何跟踪点。
3 -> 用户空间代码在 syscall_map 中创建条目。该映射不需要填充所有系统调用。如果操作码为空,则尾调用将被忽略。
4 -> 基于我们从 syscall_map 获取的操作码,我们调用适当的程序。
5 -> 在用户终止程序之前,在屏幕上打印跟踪输出。
运行此程序将为虚拟机上运行的每个系统调用生成跟踪输出,除非操作码有一个将其链接到 ignore_opcode() 尾调用的条目。
请在此处的 github 仓库 here 查看代码
注意:请查看 Paul Chaignon 关于各种不同内核版本上 BPF 尾调用的成本 的博客文章。
自内核版本 4.2 以来,eBPF 中就支持尾调用,但长期以来,它们与进行 BPF 到 BPF 的函数调用不兼容。此限制已在内核 5.10.10 中取消。
你可以将最多 33 个尾调用链接在一起,再加上每个 eBPF 程序 100 万条指令的复杂性限制,这意味着今天的 eBPF 程序员有很多自由来编写非常复杂的代码以完全在内核中运行。
总结
我希望通过展示 eBPF 程序的一些具体示例,本章可以帮助你巩固你对在内核中运行的 eBPF 代码(由事件触发)的心理模型。你还看到了使用 BPF 映射从内核传递到用户空间的数据示例。
- 原文链接: jkrishna.xyz/blog/learni...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





