使用 Admin API 监测 RPC 使用并设置预警
- QuickNode
- 发布于 2天前
- 阅读 30
本文详细介绍了如何使用Quicknode Admin API构建一个主动的RPC信用额度预警系统。该系统能够获取RPC使用数据,计算使用趋势和预测何时达到额度上限,并通过多渠道(如Slack、PagerDuty、Email等)发送通知,同时支持与Prometheus和Grafana集成,以实现全面的监控和可视化,帮助团队有效管理RPC成本并避免服务中断。
概述
管理 RPC 使用量对于维持可预测的成本和避免服务中断至关重要。默认情况下,Quicknode 会发送使用量通知电子邮件,但许多团队需要更强的灵活性:向 Slack 频道发送警报、与 PagerDuty 等事件管理工具集成、同时通知多个团队成员,或在现有监控仪表板中可见。
本指南将向你展示如何构建一个主动警报系统,该系统监控你的 RPC 信用点使用量,并在你达到限额之前发送多渠道通知。该系统会计算使用趋势并预测你何时会达到信用点限额,从而为你提供优化使用量或升级计划的时间。
你将学到什么
- 如何从 Quicknode Admin API 获取 RPC 使用量数据
- 如何计算使用量预测并确定警报严重程度
- 如何配置多渠道警报(Slack、Discord、PagerDuty、Opsgenie、电子邮件、Webhooks)
- 如何使用 cron 或 GitHub Actions 安排自动使用量检查
- 如何暴露指标用于 Prometheus 监控并构建 Grafana 仪表板
你将需要什么
- 一个 Quicknode 账户,可以是任何付费计划
- 一个具有
CONSOLE_REST权限的 Quicknode API 密钥 - 已安装 Node.js v18+
- 至少一个可用的警报渠道(Slack、Discord、PagerDuty、Opsgenie、SendGrid 或自定义 webhook)
注意: Admin API 适用于所有付费账户。请查看定价了解详情。
为什么需要主动使用量警报?
基于 Admin API 构建的自定义警报解决方案为你提供了强大的功能:
- 多渠道分发:将警报发送到 Slack、Discord、PagerDuty、Opsgenie 或你的团队使用的任何 webhook 端点
- 预测分析:根据当前消费趋势提前几天了解何时将达到限额
- 团队可见性:同时向正确的渠道中的正确人员发出警报
- 自定义阈值:设置符合你运营需求的警告和严重级别
- 基础设施集成:将使用量数据连接到你现有的 Prometheus 和 Grafana 监控栈
了解 Usage API
Quicknode Admin API 提供 v0/usage/rpc 端点来检索你的 RPC 信用点使用量数据。此端点返回有关你查询的时间段的信息。
API 请求
curl -X GET "https://api.quicknode.com/v0/usage/rpc?start_time=START_TIMESTAMP&end_time=END_TIMESTAMP" \
-H "x-api-key: YOUR_API_KEY_HERE" \
-H "Content-Type: application/json"参数:
start_time:时间段开始的 Unix 时间戳(秒)(默认为当前计费周期的开始)end_time:时间段结束的 Unix 时间戳(秒)(默认为当前时间)
API 响应
该端点返回一个 JSON 对象,其中包含以下字段:
{
"start_time": 1704067200,
"end_time": 1705363200,
"credits_used": 1000000,
"credits_remaining": 4000000,
"limit": 5000000,
"overages": null
}| 字段 | 描述 |
|---|---|
start_time |
时间段开始的 Unix 时间戳 |
end_time |
时间段结束的 Unix 时间戳 |
credits_used |
在计费周期内消耗的 RPC 信用点总数 |
credits_remaining |
在达到你的计划限额之前可用的信用点 |
limit |
你的计划在计费周期内的信用点总分配限额 |
overages |
超过限额使用的信用点(会产生额外费用) |
有了这些数据,警报系统就可以计算你的使用百分比,预测你何时会达到限额,并将警报发送到你配置的渠道。让我们设置项目并探索每个组件的工作原理。
设置项目
步骤 1:克隆仓库
git clone https://github.com/quiknode-labs/qn-guide-examples.git
cd qn-guide-examples/admin-api/usage-alerting步骤 2:安装依赖项
npm install这将安装所需的包:
dotenv:从.env文件加载环境变量typescript:TypeScript 编译器ts-node:直接运行 TypeScript 文件
步骤 3:配置环境变量
复制示例环境文件并添加你的配置:
cp .env.example .env打开 .env 并配置你的设置:
## Quicknode API Key (required)
## Get your API key from: https://dashboard.quicknode.com/api-keys
## Required permission: CONSOLE_REST
QUICKNODE_API_KEY=your_api_key_here
## Alert Thresholds (percentage of limit)
## Alerts trigger when usage >= threshold
ALERT_THRESHOLD_WARNING=80
ALERT_THRESHOLD_CRITICAL=95
## Alerting Channels (configure the ones you want to use)
## See sections below for setup instructions for each channel
SLACK_WEBHOOK_URL=
PAGERDUTY_ROUTING_KEY=
DISCORD_WEBHOOK_URL=
OPSGENIE_API_KEY=
SENDGRID_API_KEY=
SENDGRID_FROM_EMAIL=
ALERT_EMAIL_RECIPIENTS=
GENERIC_WEBHOOK_URL=至少,你需要设置 QUICKNODE_API_KEY 并配置至少一个警报渠道。为了测试,你可以将 Webhook.site 或 TypedWebhook 等在线 webhook 测试工具用于 GENERIC_WEBHOOK_URL。
理解代码
警报系统由三个主要组件组成:获取使用量数据、计算预测和发送警报。每个组件都在代码库中实现为单独的函数,这使得理解和修改变得容易。你可以在项目的 src/index.ts 文件中找到这些函数。
获取使用量数据
fetchUsage 函数从 Admin API 检索你当前计费周期的使用量数据。它接受可选的 startTime 和 endTime 参数来查询特定的时间范围,并返回包括已用信用点、剩余信用点和你的计划限额在内的使用量响应。如果未提供时间参数,它将默认为你当前的计费周期。
计算预测
calculatePrediction 函数分析你当前的使用率并预测你是否会超过限额。它从 API 获取使用量响应并计算几个有用的指标:
- 日均使用量:根据已过去的时间计算的每日平均信用点消耗量
- 月度预测:如果当前费率持续,计费周期的估计总使用量
- 距限额天数:以当前费率计算,距离达到限额还有多少天
- 预测超额使用量:超出限额的估计信用点
该函数使用基于你日均消耗量的简单线性预测,这对于大多数具有相对一致使用模式的用例效果良好。
确定警报严重程度
determineAlertLevel 函数使用可配置的阈值来确定何时发出警报以及严重程度。它同时考虑了你当前的使用百分比和上面计算的预测:
| 条件 | 严重程度 |
|---|---|
| 已经产生超额费用 | 严重 |
| 使用量 >= 严重阈值(默认 95%) | 严重 |
| 预计在 3 天或更短时间内达到限额 | 严重 |
| 使用量 >= 警告阈值(默认 80%) | 警告 |
| 预计本月将超过限额 | 警告 |
配置警报渠道
该项目包括六个预构建的警报渠道。根据你的团队需求配置一个或多个。这些集成作为示例,你可以轻松扩展代码库以添加其他渠道,如 Microsoft Teams、Datadog 或任何其他接受 webhook 有效负载的服务。
- Slack
- PagerDuty
- Discord
- Opsgenie
- 电子邮件 (SendGrid)
- 通用 Webhook
Slack
Slack 集成使用传入 webhook向频道发布格式化的消息。
设置:
- 转到 Slack API: Incoming Webhooks
- 为你的工作区和频道创建一个新的 webhook
- 将 webhook URL 复制到你的
.env文件中:
SLACK_WEBHOOK_URL=https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX警报格式:
Slack 警报包含带有颜色编码的附件,其中以结构化布局显示使用统计数据和预测。
运行脚本
检查模式
以检查模式运行,查看你的使用量和预测,而不发送警报:
npm run check示例输出:
Running in check mode (no alerts will be sent)
Fetching Quicknode RPC usage...
=== Quicknode RPC Usage Report ===
Period: Jan 1, 2024 - Jan 15, 2024
Days in Period: 15 elapsed, 16 remaining
----------------------------------
Credits Used: 4,125,000
Credits Remaining: 875,000
Limit: 5,000,000
Current Usage: 82.5%
----------------------------------
PREDICTIONS
Daily Average: 275,000 credits/day
Projected Monthly: 8,525,000 credits (170.5%)
Days Until Limit: ~3 days
Projected Overage: 3,525,000 credits
==================================
Thresholds: Warning=80%, Critical=95%
Would trigger: WARNING alert此示例显示你已使用 82.5% 的信用点,已过去 15 天的情况。按照当前速率,预计你将在大约 3 天内超过限额。
警报模式
以警报模式运行,检查使用量并在超过阈值时发送警报:
npm run dev或用于生产环境:
npm run build
npm start发送警报时的示例输出:
Fetching Quicknode RPC usage...
=== Quicknode RPC Usage Report ===
Period: Jan 1, 2024 - Jan 15, 2024
Days in Period: 15 elapsed, 16 remaining
----------------------------------
Credits Used: 4,125,000
Credits Remaining: 875,000
Limit: 5,000,000
Current Usage: 82.5%
----------------------------------
PREDICTIONS
Daily Average: 275,000 credits/day
Projected Monthly: 8,525,000 credits (170.5%)
Days Until Limit: ~3 days
Projected Overage: 3,525,000 credits
==================================
Alert level: WARNING
Sending alerts to 2 channel(s)...
[OK] slack
[OK] pagerduty安排警报
由于 Admin API 是一个 REST 服务,警报是在你查询它时生成的,而不是自动推送的。这使得调度对于主动监控至关重要。如果没有定期检查,你将不会收到警报,直到你手动运行脚本。
将脚本安排在与你的使用模式和响应需求相匹配的时间间隔运行。更频繁的检查(每隔几小时)可以及早发现使用量高峰,而不太频繁的检查(每天)可能足以应对可预测的工作负载。
使用 Cron (Linux/macOS)
添加 cron 作业以每 6 小时运行一次检查:
crontab -e添加此行(调整为你的安装路径):
0 */6 * * * cd /path/to/usage-alerting && npm start >> /var/log/quicknode-alerts.log 2>&1使用 GitHub Actions
在 .github/workflows/usage-alerts.yml 创建一个工作流文件:
name: Quicknode Usage Alerts # 工作流名称
on:
schedule:
# Run every 6 hours
- cron: '0 */6 * * *' # 每 6 小时运行一次
workflow_dispatch: # 允许手动触发
jobs:
check-usage: # 作业名称
runs-on: ubuntu-latest # 在 Ubuntu 最新版上运行
steps:
- name: Checkout repository # 步骤名称:检出仓库
uses: actions/checkout@v4
- name: Setup Node.js # 步骤名称:设置 Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
- name: Install dependencies # 步骤名称:安装依赖
working-directory: admin-api/usage-alerting # 指定工作目录
run: npm install
- name: Run usage check # 步骤名称:运行使用量检查
working-directory: admin-api/usage-alerting # 指定工作目录
env:
QUICKNODE_API_KEY: ${{ secrets.QUICKNODE_API_KEY }}
ALERT_THRESHOLD_WARNING: '80'
ALERT_THRESHOLD_CRITICAL: '95'
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
run: npm run dev设置 Secret:
- 转到你的仓库设置 > Secrets and variables > Actions
- 添加以下秘密:
QUICKNODE_API_KEY:你的 Quicknode API 密钥SLACK_WEBHOOK_URL:你的 Slack webhook URL(或其他渠道秘密)
替代方案:Prometheus AlertManager
如果你的团队已经使用 Prometheus,你可以完全跳过基于 cron 的调度。相反,使用此项目中包含的 Prometheus exporter,并配置 AlertManager 以根据指标阈值处理通知。此方法将警报逻辑集中到你现有的监控基础设施中。
高级:Prometheus 集成
对于使用 Prometheus 和 Grafana 进行监控的团队,该项目包含一个自定义 Prometheus exporter,它暴露 Quicknode 使用量指标。此 exporter 将 v0/usage/rpc API 数据转换为 Prometheus 格式,使你能够:
- 构建显示使用量限额和剩余信用点的 Grafana 仪表板
- 通过 AlertManager 设置 Prometheus 警报规则
- 在单个 Prometheus 实例中结合 Quicknode 使用量指标与其他厂商指标
注意: Quicknode 还为企业客户提供了一个 Prometheus Exporter,它暴露了 RPC 请求、端点响应状态和延迟等额外指标。请遵循该指南学习 Prometheus 基础知识并构建全面的 Grafana 仪表板。本项目中的 exporter 专门关注所有付费计划可用的计费和使用量指标。
Exporter 工作原理
exporter 遵循标准的 Prometheus 模式。它运行一个简单的 HTTP 服务器,按需响应抓取请求:
-
被动操作:exporter 运行一个 HTTP 服务器并等待请求。它不按自己的计划获取数据,也不运行后台作业。
-
Prometheus 控制时序:Prometheus 配置为按你指定的时间间隔(例如,每五分钟)抓取
/metrics端点。 -
按需获取:当 Prometheus 访问
/metrics端点时,exporter 调用 Quicknode API,将响应格式化为 Prometheus 指标,并返回它。 -
无状态设计:exporter 不在请求之间缓存或存储数据。每次抓取都返回来自 API 的最新数据。
这种设计意味着你完全通过 Prometheus 配置控制抓取频率。根据你需要更新指标的频率调整 scrape_interval。
启动 Exporter
npm run exporter这将在端口 9091 上启动一个指标服务器(可通过 EXPORTER_PORT 配置):
Quicknode Prometheus Exporter running on http://localhost:9091
Metrics endpoint: http://localhost:9091/metrics
Health endpoint: http://localhost:9091/health可用指标
| 指标 | 类型 | 描述 |
|---|---|---|
quicknode_credits_used |
gauge | 当前计费周期中使用的 RPC 信用点总数 |
quicknode_credits_remaining |
gauge | 当前计费周期中剩余的 RPC 信用点 |
quicknode_credits_limit |
gauge | 计费周期的 RPC 信用点总限额 |
quicknode_usage_percent |
gauge | RPC 信用点使用百分比 |
quicknode_overages |
gauge | 超过限额使用的 RPC 信用点 |
quicknode_exporter_scrape_success |
gauge | 上次抓取是否成功 |
Prometheus 配置
在你的 prometheus.yml 中添加 exporter 作为抓取目标:
scrape_configs:
- job_name: 'quicknode-usage'
scrape_interval: 5m
static_configs:
- targets: ['localhost:9091']如果你在 Docker 中运行 Prometheus,并且 exporter 在你的宿主机上运行,请更新目标以使用 host.docker.internal:9091,并在你的 Docker Compose 文件中添加以下 extra_hosts:
services:
prometheus:
image: prom/prometheus:latest
extra_hosts:
- "host.docker.internal:host-gateway"构建仪表板
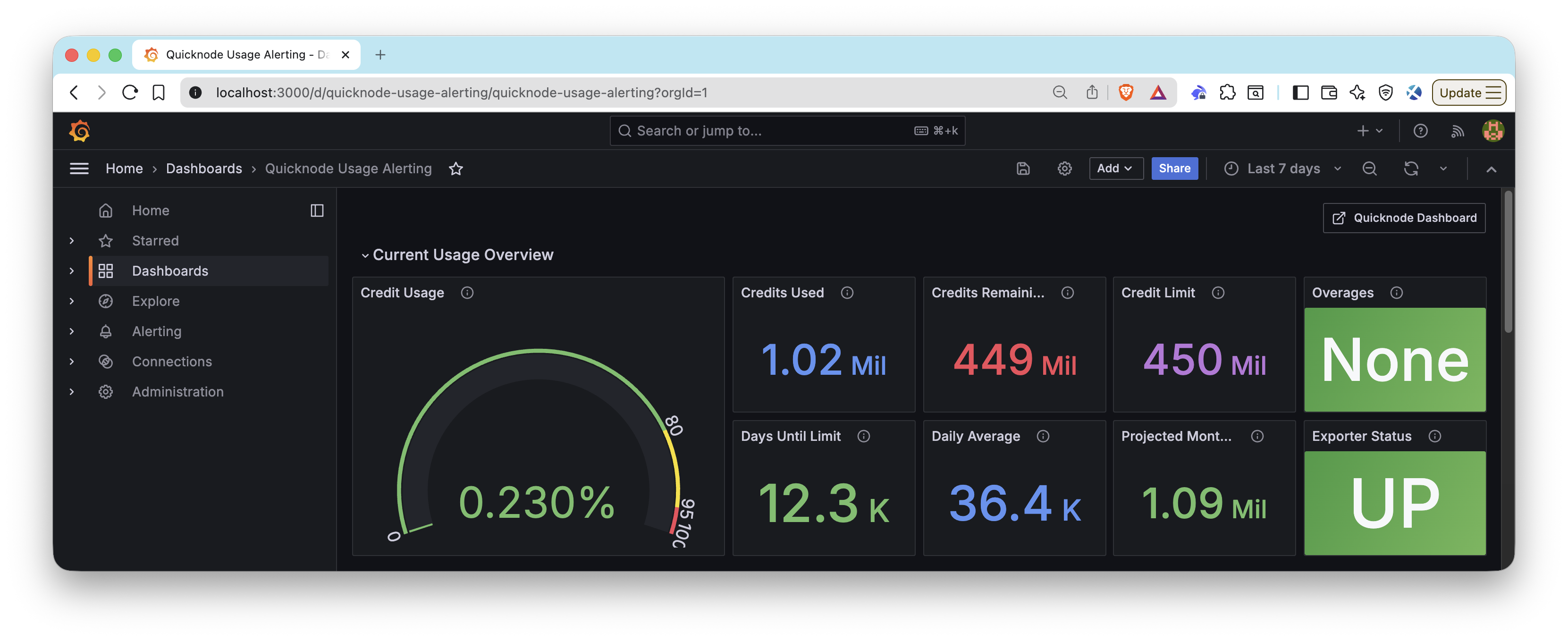
有关使用 Quicknode 指标构建 Grafana 仪表板的完整指南,请参阅我们的指南:如何构建 Grafana 仪表板来监控你的 RPC 基础设施。
配套仓库包括预构建的仪表板配置:
- 使用量警报仪表板:在
admin-api/usage-alerting/dashboards/quicknode-usage-alerting-grafana.json中找到 Grafana 仪表板 JSON。直接将其导入到你的 Grafana 实例中,或将其放置在你的预配置文件夹中。 - 完整监控栈:
admin-api/grafana-dashboard目录包含一个完整的 Prometheus 和 Grafana 监控栈的 Docker Compose 设置。
结论
你现在已经为你的 Quicknode RPC 使用量设置了一个主动警报系统。通过该系统,你可以:
- 监控整个组织的使用量
- 在你的团队实际使用的渠道上接收警报
- 在限额发生之前预测何时会达到限额
- 避免意外的超额费用
多渠道警报和使用量预测的结合,为你有效管理 RPC 基础设施提供了所需的可见性。
下一步
现在你已设置了使用量警报,请考虑以下增强功能:
- 构建全面的仪表板:遵循我们的 Grafana Dashboard 指南以可视化随时间变化的使用量趋势
- 以编程方式管理基础设施:使用 Admin API 在监控使用量的同时自动化端点管理
- 审查你的计划限额:如果你持续接近限额,请查看 Quicknode 定价以了解你的选项
- 探索完整的 Admin API:查看 Admin API 文档以了解更多端点和功能
常见问题
如何以编程方式检查我当前的 Quicknode RPC 信用点使用量?
使用 Admin API 向 https://api.quicknode.com/v0/usage/rpc 发送 GET 请求,包含你的 API 密钥,以检索当前计费周期的 credits_used、credits_remaining 和 limit。
Admin API 在 Quicknode 中有什么用?
Admin API 允许对 Quicknode 中的所有操作进行编程管理,包括创建、更新和删除端点,设置速率限制,以及获取详细的使用量数据,例如按端点、方法或区块链划分的信用点。
如何将 Quicknode 使用量指标与 Prometheus 和 Grafana 集成?
该项目包含一个自定义 Prometheus exporter,它在 /metrics 端点暴露 Quicknode 使用量指标。使用 npm run exporter 运行 exporter,配置 Prometheus 来抓取它,并导入提供的 Grafana 仪表板 JSON 以可视化已用信用点、剩余信用点、使用百分比和超额费用。
此使用量监控系统支持哪些警报渠道?
该系统支持六个预构建的渠道:Slack、Discord、PagerDuty、Opsgenie、电子邮件(通过 SendGrid)和通用 webhook。你可以配置一个或多个渠道,并扩展代码库以添加额外的集成。
我可以按端点或方法细分 RPC 信用点使用量吗?
可以,使用 GET 请求向 /v0/usage/rpc/by-endpoint 或类似的端点,可以查看跨端点、方法或区块链的信用点消耗量的详细细分。
如果你有疑问或遇到问题,请在我们的 Discord 中联系我们。通过关注我们的 Twitter (@Quicknode) 或我们的 Telegram 公告频道了解最新动态。
我们 ❤️ 反馈!
告诉我们你是否有任何反馈或对新主题的请求。我们很乐意听取你的意见。
- 原文链接: quicknode.com/guides/qui...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 0
- 分类: 通识
- 标签: RPC使用监控 Quicknode Admin API 多渠道预警 Prometheus grafana GitHub Actions





