错过证明:理解和微调Lighthouse的技术指南
- sigmaprime
- 发布于 2024-06-18 13:51
- 阅读 787
本文针对以太坊共识机制的技术读者,解释了验证者节点错过证明的原因,包括区块延迟、gas费高峰期、节点资源限制、网络问题等,并提供了使用Lighthouse日志和仪表板诊断问题的方法,以及调整参数以降低错过证明率的建议。
序言
这篇文章面向对以太坊共识机制有基本了解的技术读者。话虽如此,你可能作为一位非技术型的 Staker 来到这里,因为你注意到你的节点错过了一些证明(因此未能在网络上实现 100% 的性能),并且想知道如何纠正它。本文旨在为这两类读者提供有用的信息。
对于技术性不强的读者,我将介绍可能存在的问题(在简介中),并解释一些可以帮助你的节点提高效率的简单方法(在常见问题和潜在调整参数部分)。中间部分旨在帮助你准确诊断当前节点面临的问题,技术性不强的读者可以跳过这些部分。
简介
错过证明的数量是一个被广泛使用的指标,并且在某种程度上被不正确地与特定共识客户端的性能联系起来。这个指标是有用的,因为它与你的验证者的利润直接相关,验证者错过证明越少,利润就越高,而且网络也越健康。尽量减少错过证明的数量符合每个人的最佳利益。事实上,在网络上拥有一组地理位置分散的节点实际上将有助于减少错过证明的数量,并使其更加强大和去中心化。鉴于个人无法改变网络的一般结构,我们面临的问题是:我们如何才能尽量减少本地节点错过证明的数量?
在我们深入研究如何减少错过证明之前,我们必须首先了解当单个验证者错过证明时会发生什么。为此,让我们(非常简单地)了解一下证明实际上是什么以及投票过程是如何运作的。
每个 epoch(6.4 分钟),每个验证者必须对他们当前对链的看法“投票”一次。这包括三个主要值:
- Head - 我们认为的链的当前 Head 区块
- Source - 最新的 被证明(justified)区块
- Target - 该 epoch 的第一个区块
每个验证者决定这些值并将信息放入一个我们称为Attestation 的对象中。验证者客户端将此数据结构的签名版本发送到一个(或多个)信标节点。然后,信标节点必须在特定的 gossipsub 主题上找到(或维护)对等节点(gossipsub 是一种发布/订阅网络协议,用于将消息传播到网络中的所有节点),该证明必须在该主题上发送。一旦发送,平均有 16 个 聚合器 (aggregators)(它们只是网络上的其他共识节点),它们将所有匹配的证明分组到一个分组证明中,我们称之为 AggregateAttestation。每个证明变量(如上所述)的唯一选择都有一个。然后,聚合器 (aggregator) 必须将这些分组的证明发送到另一个 gossipsub 主题,我们称之为 aggregate_topic,所有区块提议者都在侦听该主题。然后,当未来的区块提议者要去创建一个区块时,它会选择使其利润最大化的 AggregateAttestation。这可以简单地理解为收集与大多数人一致的证明,这意味着如果验证者没有与大多数人一起投票,则其证明可能会被排除(有关此过程的更多详细信息,请参阅我们关于 Attestation\ Packing 的博客)。如果验证者的证明在此过程中被包含到一个区块中,则证明已成功(前提是该区块没有成为孤块),因此不被归类为 错过 (missed)。如果此过程的任何阶段失败,则证明将被错过。现在的诀窍是确定对于任何给定的节点,此过程在哪个阶段失败。将错过证明指标与共识客户端联系起来具有误导性的原因是,此过程涉及许多参与者,通常涉及其他客户端和网络上的其他节点。这是一个粗略的流程图,高亮显示了你的本地节点所扮演的部分以及超出你的本地节点控制范围的部分。

如你从此图中看到的,实际上有很多外部参与者参与到此过程中,这些参与者会导致错过证明,而这完全超出了你的本地节点的控制范围,而与你的共识客户端无关。
这并不是说我们可能无法改进某些方面 :)(尽管我们尽力在 Lighthouse 中设置最佳默认值)。
让我们列举一下所有可能导致错过证明的因素,然后(使用 Lighthouse 的指标)尝试诊断你的本地节点的原因。
什么会导致错过证明
延迟的区块或延迟的 Blob
如果你收到一个区块及其关联的 Blob 较晚(晚于 Slot 开始后的 4 秒),你将无法证明它是 Head 区块。这是因为在 Slot 开始后的 4 秒,你需要进行证明。
在这些情况下,你的证明可能与大多数人一致,也可能不一致。如果区块足够快地到达网络上的大多数节点,但只是迟到了你的本地节点,则你的证明将是少数派。如果你的证明是少数派,则很可能不会被包含到一个区块中。同样,我们参考 Attestation Packing 博客文章以获取更多详细信息。
请注意,这些在很大程度上不是你的本地节点的故障,可能是由以下原因引起的:
- 区块生产者实际上生产区块较晚 - 这已成为区块构建器的常态,因为生产者现在在构建区块时需要执行许多额外的步骤。区块构建器现在可以延迟生产和后续传播,直到网络上的一些节点太晚收到它为止。你的节点无法解决这种情况。
- 区块在网络中的传播非常慢 - 这也是一种网络效应,在很大程度上与你的节点无关,但是你可以通过调整 Lighthouse 标志来改善这种情况,我们稍后将介绍。
- 你的本地网络带宽已达到饱和 - 如果你的本地网络已达到饱和,你将排队消息。Lighthouse 已经做出了专门的工程选择,以尽可能优先处理区块,但最终,如果你的网络连接无法处理所需的带宽,你将会看到很大一部分看似延迟的区块/Blob,因为你的网络滞后。
区块处理时间
一旦从网络接收到区块,Lighthouse 需要检查其有效性,应用分叉选择规则,并最终将其添加到本地数据库中。此步骤需要 CPU、RAM 和磁盘写入。
可能是你的节点正在使用速度较慢的 SSD。QLC 和无 DRAM 的 SSD 相对较慢,并且可能需要花费相当多的时间来处理区块。要了解你的 SSD 是否属于此类,请参阅 众包 SSD\ 列表。
或者,你的节点可能正在努力应对 CPU 资源。这两种情况都可能导致延迟,从而无法证明收到的区块是有效的,这可能会导致证明中的少数 Head 投票,并最终导致不包含在未来的区块中。
执行层验证时间
为了使 Lighthouse 能够将区块视为有效的投票对象,它必须与执行层客户端检查其是否有效。此过程可能会消耗一些时间并导致错过当前 Head 区块的少数民族证明。
验证者客户端时序和错误
这通常不是问题的根本原因。验证者客户端必须从信标节点请求要签名的证明。它必须签名并返回它。在大多数操作条件下,这几乎不消耗时间。但是,如果验证者客户端与信标节点之间的距离很远,并且连接是间歇性的,则可能会延迟证明,这可能会导致不包含。此外,如果验证者客户端位于另一台计算机上并且时钟未同步,则验证者客户端可能会在错误的时间执行证明。
在网络上发布证明
为了在网络上发布生成的证明,每个信标节点必须找到一组已订阅与我们要发布的证明关联的 gossipsub 主题的对等节点。有 64 个唯一的主题(证明子网)。Lighthouse 的默认对等节点计数为 100 个节点。它尝试维护一组 100 个对等节点,以便在任何给定的时间,我们都有一些跨越每个可能主题的对等节点。因此,当节点需要发布证明时,我们有几个对等节点可以将其发送到。可能会发生在你需要发送证明的时候,我们需要的主题上的对等节点立即断开连接(无论出于何种原因)。在这种情况下,Lighthouse 会记录一条发布警告,指出 InsufficientPeers。Lighthouse
尝试为此主题发现更多对等节点,并在可以连接到有用的对等节点后立即重新发布你的证明。如果失败,你的证明可能会丢失或延迟。
聚合器未聚合你的证明
一旦你的节点在网络上发布了你的证明,网络上的一个伪随机节点必须接收它并决定聚合你的证明。这样做是他们的工作,但是可能会发生你的证明被错过或未正确聚合(即,它与聚合器不同,或者聚合器未及时看到该证明)。如果发生这种情况,你的证明将被错过,并且不会包含到任何区块中。你无法使用本地节点来防止这种情况。
区块生产者未包含你的证明
最后,一旦你的证明及时制作、聚合并发送到 Aggregate 主题,它就会被区块生产者拾取。由于区块空间有限,区块生产者随后承担着决定将哪些 Aggregate 包含到区块中以及将哪些 Aggregate 排除在外的艰巨任务,即,并非所有证明都可以放入单个区块中。如果你的证明无法包含在某个 epoch 中的任何区块中,你将注册一次错过证明。同样,我将感兴趣的读者推荐到 Attestation\ Packing 帖子,以了解为什么你的证明可能未包含在内的详细信息。简而言之,如果你的证明不是多数(即,迟到的区块导致错过 Head 投票,或者证明发布较晚),那么你的证明就更难包含在区块中。多数“压缩”(更技术性地说是聚合)更好,因此更多它可以放入一个区块中,从而为区块生产者提供更多利润(因此这就是他们所做的事情)。
如果你的证明具有错误的目标,则其价值会降低,并且对于区块提议者来说利润要少得多,因此更有可能将其排除在区块之外。如果你的证明具有错误的来源,则无法将其包含在区块中,并且将被视为错过证明。幸运的是,具有不正确的来源的可能性很小,因为这是我们对上次经过验证的 Slot 的看法(如果我们在跟踪正确的链,则几乎总是达成一致)。
总而言之,与仅匹配目标(和来源)的证明相比,在 Head、Target 和来源上与大多数人匹配的证明更有可能被包含在内,并且与仅匹配来源的证明相比,被包含在内的可能性更高。
你的节点无法控制区块生产者将哪些内容打包到其区块中,我们能做的最好的事情就是尝试使你的本地节点投票赞成网络上每个其他节点将投票的内容。
孤立区块
最后,即使你完成了以上所有步骤并且你的证明已包含在区块中,如果该区块随后传播的时间过长,则可能会被孤立并实际上从链中分叉出来,这意味着你的证明也是如此。如果你包含在其中的区块被孤立,你可能会看到该 epoch 的错过证明。Lighthouse 收集来自孤立区块的证明,并尝试将其打包到以后生成的区块中,因此仅仅因为该区块被孤立并不意味着你的证明也将被孤立,但是它们现在也与后续区块的区块空间竞争被包含在内,因此更有可能被排除在外。
在 Lighthouse 中诊断错过证明
在本节中,我们将介绍当前的工具和一些分析,以识别错过证明的根本原因,并评论最可能的原因。我们将通过一个真实世界的示例,了解我在家中运行的验证者在主网上错过证明的情况(澳大利亚的网络连接较差,因此在开始之前,我猜想这与网络有关)。
Lighthouse 日志
Lighthouse 发出了一些有用的日志,可以帮助我们诊断错过证明。为了完整起见,我将列出一些有用的命令来查看这些日志,以便你可以自己调查此处提到的一些问题。
如果你在 Beacon 节点上设置了 --validator-monitor-auto 标志,它将跟踪你的验证者是否错过了每个 epoch 的任何证明。
你可以从以下默认路径访问你的 Beacon 节点日志文件:
~/.lighthouse/mainnet/beacon/logs/beacon.log
要查看你是否错过了任何证明,你可以观看 (tail -f) 或搜索 (grep) 日志中的 Previous epoch attestation。例如:
$ grep "Previous epoch attestation" beacon.log
给了我以下内容:
Apr 22 00:16:20.257 INFO Previous epoch attestation(s) failed to match head, validators: ["xxxx", "xxxx"], epoch: 278438, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1050
Apr 22 00:16:20.257 INFO Previous epoch attestation(s) failed to match target, validators: ["xxxx"], epoch: 278438, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1059
Apr 22 00:16:20.257 INFO Previous epoch attestation(s) had sub-optimal inclusion delay, validators: ["xxxx"], epoch: 278438, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1068
从这些日志中,我们可以看到每个验证者在每个 epoch 中的表现。这些日志告诉我们,我们的证明错过了 Head 投票,错过了 Target 投票,“次优包含延迟”告诉我们,我们的证明没有立即包含在下一个区块中,而是包含在后面的区块中。这些日志对于跟踪验证者的证明性能非常有用。
我们可以通过以下方式查看传入的区块和发出的证明:
$ grep -e "Slot timer" -e "Unaggregated attestation" -e "Sending pubsub" -e "New block received" ~/.lighthouse/mainnet/beacon/logs/beacon.log
这对我来说导致了以下结果 (片段):
Apr 22 00:42:53.001 DEBG Slot timer, sync_state: Synced, current_slot: 8910212, head_slot: 8910212, head_block: 0x3ef2…a2b8, finalized_epoch: 278442, finalized_root: 0xb4ac…e385, peers: 99, service: slot_notifier, module: client::notifier:180
Apr 22 00:43:00.317 INFO New block received, root: 0xa7a5f4be80bec9114c4fef16543d5bd9532dec9735c1d1e1dd44d7553ad11d19, slot: 8910213, module: network::network_beacon_processor::gossip_methods:916
Apr 22 00:43:03.001 INFO Unaggregated attestation, validator: X, src: api, slot: 8910213, epoch: 278444, delay_ms: 11, index: 43, head:0xa7a5f4be80bec9114c4fef16543d5bd9532dec9735c1d1e1dd44d7553ad11d19, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1263
Apr 22 00:43:03.045 DEBG Sending pubsub messages, topics: [Attestation(SubnetId(XX))], count: 1, service: network, module: network::service:656
Apr 22 00:43:05.001 DEBG Slot timer, sync_state: Synced, current_slot: 8910213, head_slot: 8910213, head_block: 0xa7a5…1d19, finalized_epoch: 278442, finalized_root: 0xb4ac…e385, peers: 96, service: slot_notifier, module: client::notifier:180
Apr 22 00:43:12.456 INFO New block received, root: 0x462f1dd0cfb3fa7f42c11d15c54cb0c053606bb8dc2457486442ad74fc0bb7e7, slot: 8910214, module: network::network_beacon_processor::gossip_methods:916
Apr 22 00:43:15.001 INFO Unaggregated attestation, validator: X, src: api, slot: 8910214, epoch: 278444, delay_ms: 11, index: 43, head: 0x462f1dd0cfb3fa7f42c11d15c54cb0c053606bb8dc2457486442ad74fc0bb7e7, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1263
Apr 22 00:43:15.104 DEBG Sending pubsub messages, topics: [Attestation(SubnetId(X))], count: 1, service: network, module: network::service:656
Apr 22 00:43:17.002 DEBG Slot timer, sync_state: Synced, current_slot: 8910214, head_slot: 8910214, head_block: 0x462f…b7e7, finalized_epoch: 278442, finalized_root: 0xb4ac…e385, peers: 96, service: slot_notifier, module: client::notifier:180
这显示了 Slot 中途的时间(“Slot timer”),然后是下一个 Slot 的区块到达(“New block received”),然后是信标节点生成并在网络上发送证明(“Unaggregated attestation”)和(“Sending pubsubmessages”)。
你可以通过验证者客户端日志查看哪个验证者正在发送哪些消息。这些日志的默认位置是:
~/.lighthouse/mainnet/validators/logs/validator.log
一些信息日志的片段显示了任何给定时间的证明:
Apr 22 00:49:15.104 INFO Successfully published attestations type: unaggregated, slot: 8910244, committee_index: XX, head_block: 0xd8d987ac0ba9a441b135d183913d7a69464481b44319ff35a1099b22f8530110, validator_indices: [XXXX], count: 1, service: attestation
Apr 22 00:49:15.105 INFO Successfully published attestations type: unaggregated, slot: 8910244, committee_index: XX, head_block: 0xd8d987ac0ba9a441b135d183913d7a69464481b44319ff35a1099b22f8530110, validator_indices: [XXXX], count: 1, service: attestation
从这些日志中,我们可以匹配哪个验证者正在哪个 Slot 上生成证明。因此,如果错过了证明,我们可以识别出确切的验证者和一个 Slot。
接下来,查看特定 Slot 的区块是否延迟到达会很有用。这可能是错过证明的原因。为了识别这些区块,我们搜索 Lighthouse 信标日志以查看:
$ grep -e "Delayed head" ~/.lighthouse/mainnet/beacon/logs/beacon.log
这对我来说,结果是:
Apr 22 00:50:51.376 DEBG Delayed head block, set_as_head_time_ms: 305, imported_time_ms: 106, attestable_delay_ms: 4037, available_delay_ms: 3963, execution_time_ms: 325, blob_delay_ms: 2775, observed_delay_ms: 3637, total_delay_ms: 4376, slot: 8910252, proposer_index: 255573, block_root: 0x05de8a29c9404ea5c2ae7914ddb81936bef8a85ced6455b88dd1014558e32c3f, service: beacon, module: beacon_chain::canonical_head:1503
Apr 22 00:51:27.017 DEBG Delayed head block, set_as_head_time_ms: 114, imported_time_ms: 35, attestable_delay_ms: 3892, available_delay_ms: 3867, execution_time_ms: 192, blob_delay_ms: 3867, observed_delay_ms: 3594, total_delay_ms: 4017, slot: 8910255, proposer_index: 1054833, block_root: 0x8991f3d82f94145a1153ca7677f4f72192d0f5fa0a387f34316c68c44082eb39, service: beacon, module: beacon_chain::canonical_head:1503
这给了我一个延迟到达的区块列表,因此我们没有足够的时间来证明该区块。如果其中一个区块与你的验证者需要证明的 Slot 相吻合,则可能是你的本地节点错过了证明中的此区块,并且随后是少数投票,并且没有与下一个区块中的其他区块一起包含在内。此日志显示了一些延迟指标,我们将在下一节中更详细地介绍。
如果你想查看延迟到达的区块和 blob,我们可以搜索:
grep -e "Delayed head" -e "Gossip block arrived late" -e "Gossip blob arrived late" ~/.lighthouse/mainnet/beacon/logs/beacon.log
它显示了诸如
Apr 22 00:36:39.056 DEBG Gossip blob arrived late, commitment: 0xb90d…cf12, delay: 4.050169655s, slot: 8910181, proposer_index: 1047912, block_root: 0xdb8fa58ceb049f2ec2ae65b5e6097f11d866c5a453f7303923143a0066e9f7ef, module: network::network_beacon_processor::gossip_methods:631
Apr 22 00:36:39.110 DEBG Gossip block arrived late, block_delay: 4.105806458s, slot: 8910181, proposer_index: 1047912, block_root: 0xdb8fa58ceb049f2ec2ae65b5e6097f11d866c5a453f7303923143a0066e9f7ef, module: network::network_beacon_processor::gossip_methods:906
Apr 22 00:36:39.903 DEBG Delayed head block, set_as_head_time_ms: 132, imported_time_ms: 38, attestable_delay_ms: 4759, available_delay_ms: 4731, execution_time_ms: 625, blob_delay_ms: 4056, observed_delay_ms: 4105, total_delay_ms: 4902, slot: 8910181, proposer_index: 1047912, block_root: 0xdb8fa58ceb049f2ec2ae65b5e6097f11d866c5a453f7303923143a0066e9f7ef, service: beacon, module: beacon_chain::canonical_head:1503
在这里,我们可以看到区块和 blob 都到达得很晚,这可能会导致我们错过证明中的 Head 投票。
我们现在先暂时不使用日志,而改用更方便用户使用的工具来分析错过的证明。
错过证明仪表板
我们构建了一个仪表板来帮助进行分析。它被称为 missed-attestations,可以在我们的
lighthouse-metrics
仪表板页面中找到。(你需要 Lighthouse 的 v5.2.0 或更高版本才能使此仪表板工作。)你需要在 Lighthouse 上启用 --metrics 标志,并运行 lighthouse-metrics docker 容器,如该存储库中所述。
它看起来像这样:
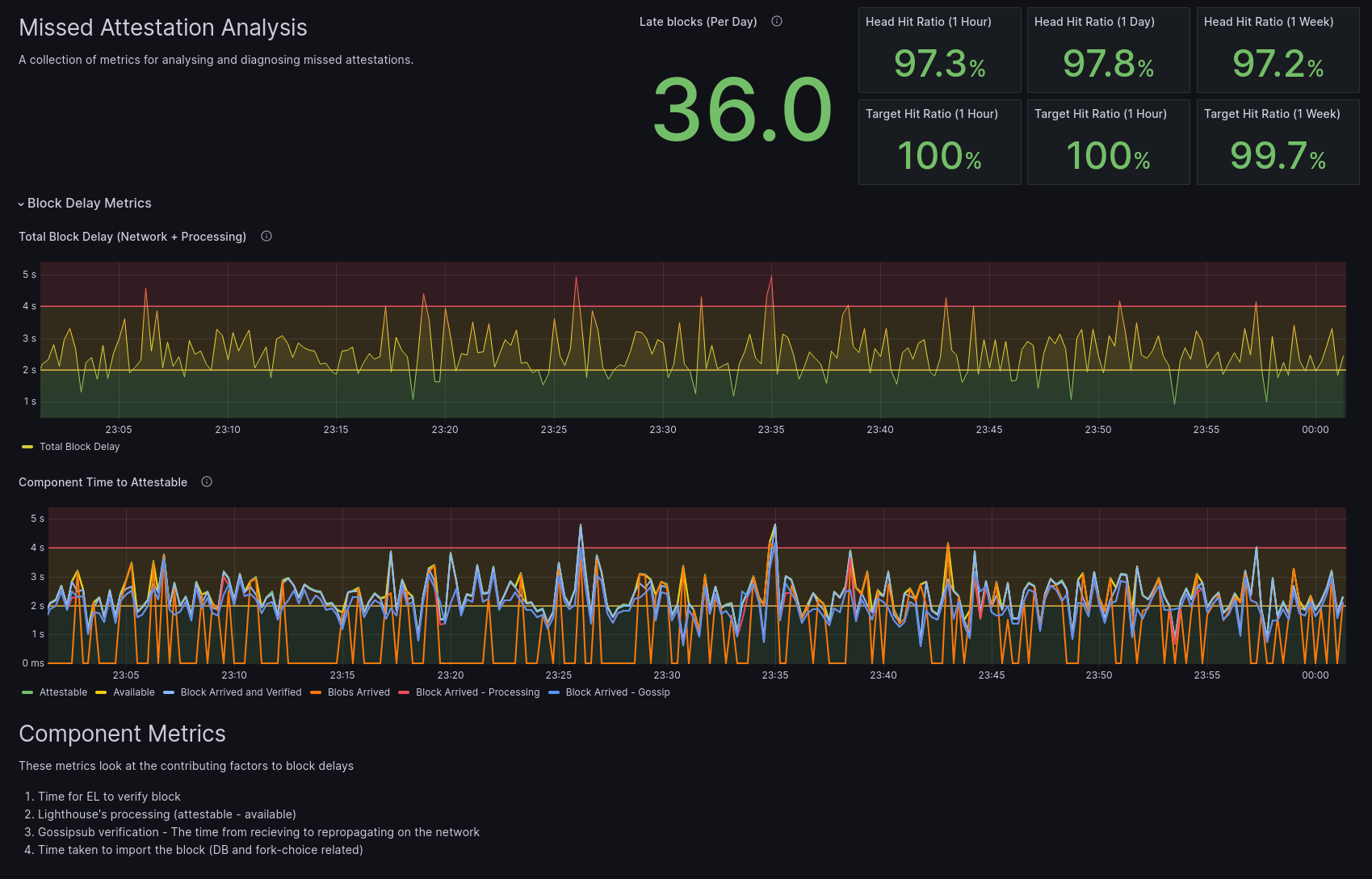
这提供了可用于分析错过证明的指标的概述。此仪表板右上角的值为你提供了在网络上延迟到达的区块的最后 1 小时、1 天和 1 周的预期性能统计信息。第一行显示了 head hit ratio。这是我们期望与 head 投票匹配的证明的百分比。更具体地说,区块及时到达以便我们的证明及时投票的百分比。
第二行指示我们本地节点的证明在其 Target 投票中匹配的预期百分比。也就是说,epoch 的第一个区块及时到达,以便它们可以包含在本地节点的证明中。这些百分比与 100% 的偏差通常表明区块到达得太晚,我们可能会在证明中错过它们。这可能是全局网络问题(超出你的本地节点的控制范围)或你的本地互联网连接问题。让我们更详细地了解一下延迟区块的影响。
延迟区块
正如我们所讨论的那样,延迟区块可能是我们的证明未包含在区块中的原因之一。让我们详细地看一下一些指标。
第一个图表显示了你的本地信标节点正在接收的区块的计时高级概述。
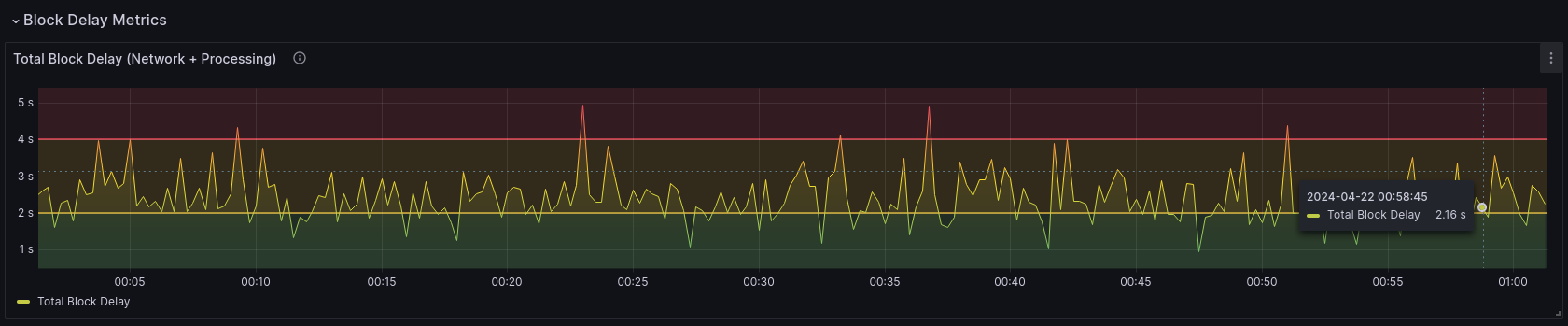
这给出了我们接收和导入区块所需的总时间。它给出了区块和 blob 的到达和处理延迟的高级视图在你的 Lighthouse节点中。位于红色区域的节点通常到达太晚,无法及时证明。
第二个图表更有用,旨在直接了解为什么区块到达得太晚的根本原因。它测量了 Lighthouse 接收一个区块并使其准备好供验证者客户端证明的所有组件的时间。最长的时间是“可证明的”时间。这是自插槽开始以来,区块可供验证者证明的时间。如果此值位于红色区域,那么我们的验证者将无法证明此区块。
它显示了每个区块的计时组件。
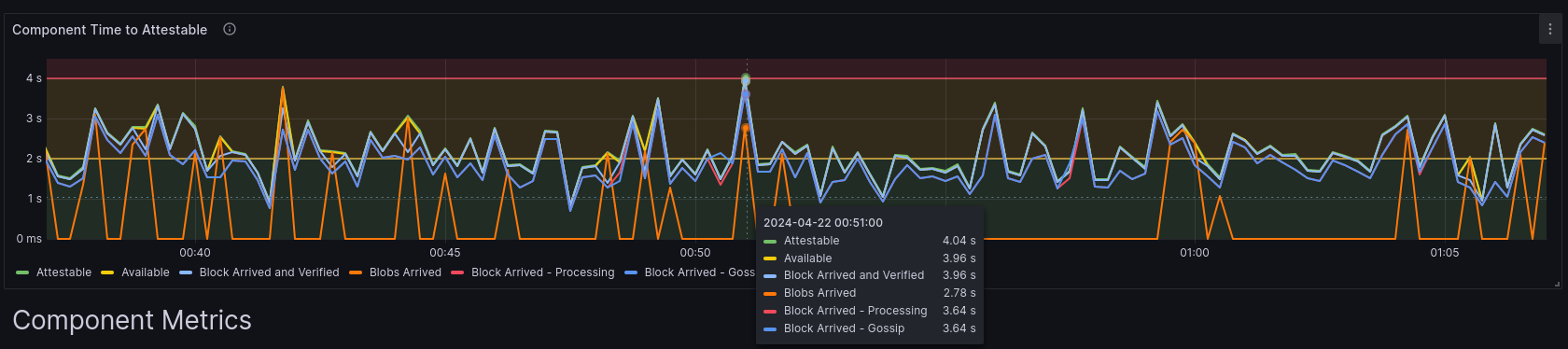
以下是此图中每个组件的描述:
- 区块到达 - Gossip - 这是区块通过 gossipsub 到达我们的网络所花费的时间。
- Blob 到达 - 这是所有必需的 blob 到达我们的网络所花费的时间。为了使我们开始处理一个区块,我们需要所有blob和区块到达。因此你会注意到,所有其他计时在 blob 或区块到达后发生。另请注意,某些区块没有任何 blob。在这种情况下,blob 计时设置为 0,你可以在图上看到。
- 区块到达 - 处理 - 这是区块实际开始被处理的时间。Lighthouse 有一个排队系统。当本地节点过载时,区块可能会等待一段时间才能被处理。如果你的节点没有遇到 CPU 资源问题,则此时间应与区块到达 - Gossip 指标大致相同。
- 区块到达并验证 - 一旦我们从网络接收到一个区块(无论 blob 如何),我们需要使用执行层验证它。此指标记录了我们将区块放在网络上并询问 EL 是否有效所花费的时间。它是(区块到达 - Gossip + 执行层时间)。如果你的EL速度较慢(例如,由于SSD速度较慢)或需要花费大量时间来执行此请求,你会在此处注意到很大的差异。
- 可用 - 一旦我们收到该区块,与 EL 检查其是否有效并且所有 blob 都已到达,该区块就变为可用。
此指标应与
max(block_arrived_and_verified, blobs_arrived) - 可证明 - 这是区块已被处理并且可供验证者证明的时间。如果这发生在距离槽开始时间 4 秒之前,则验证者可以使用此区块进行证明。
在上面的示例中,该区块可证明的时间太晚了(4.04 秒)。我们可以看到我们所有的 blob 都及时到达(2.78 秒),但是区块在网络上到达得太晚是最大的问题(3.64 秒)。然后,执行层花费了 320 毫秒(3.96 秒 - 3.64 秒,这是一个不错的值),只剩下 40 毫秒来处理该区块并使其准备好进行证明(可证明)。在这种情况下,这时间不够,因此,如果我们正在证明这个槽,我们很可能错过了 Head 投票(假设对于网络的其余部分来说,它并不晚)。
该仪表板显示了在其自己的图中分解的一些额外组件,以便轻松识别区块导入时间的潜在问题。
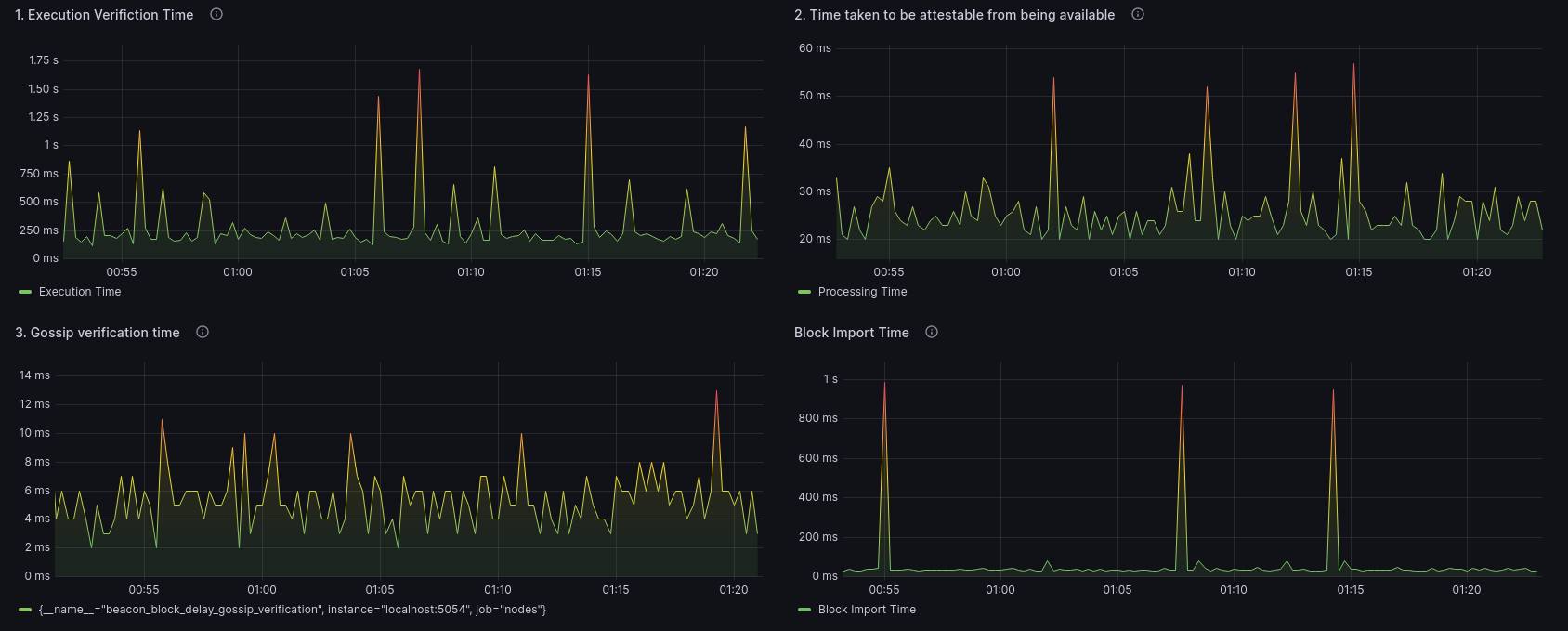
我的本地节点稍微关注的一个领域是执行验证时间。我们可以看到经常出现峰值,范围高达 1.5 秒,这是值得与我的 EL一起调查的事情。
对等体不足
错过证明的另一个来源是本地 Lighthouse 节点在我们需要证明的特定子网上没有足够的对等体。在这种情况下,Lighthouse 将记录以下形式的警告:
WARN Could not publish message kind: beacon_attestation_43, error: InsufficientPeers, service: libp2p
你可以搜索这些日志来查找此类问题的任何发生情况。
仪表板也已设置为识别这些问题。仪表板的第二部分看起来像这样:
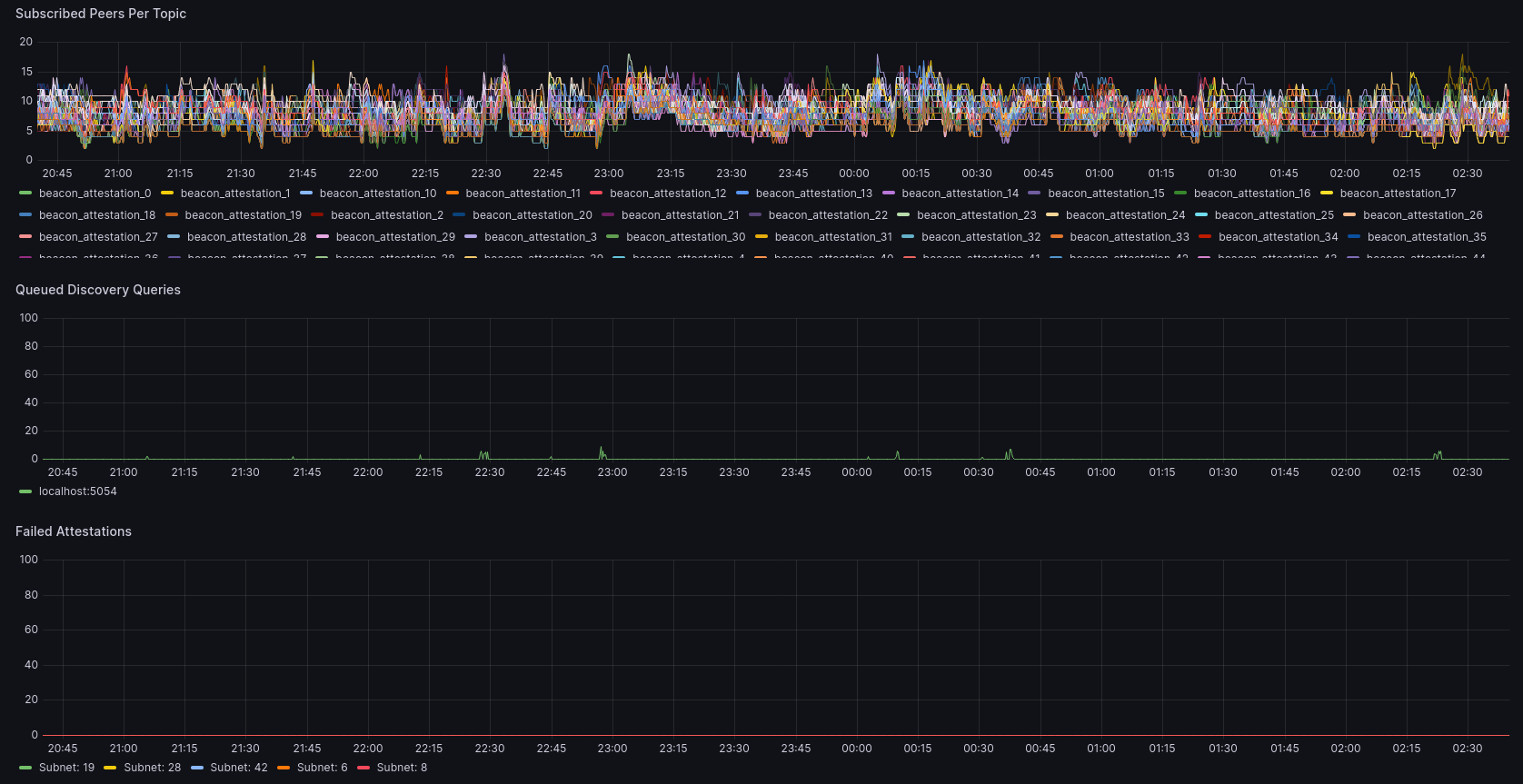
此部分显示三个图表。第一个图表列出了所有 64 个证明子网和 4 个同步委员会子网的 peer 数量。Lighthouse 的目标是在所有子网上保持这些 peer 的均匀分布。只要你在所有子网上至少有一个 peer,我们就应该始终能够将证明发布到网络。在此示例中,我的节点在任何给定子网上似乎有 5 到 15 个 peer。你可能会发现一个下降,其中一群节点断开连接,其中一个子网达到 0。这可能是错过证明的原因。
第二个图表给出了排队的发现请求列表。理想情况下,这应该主要为 0(如我的所示)。在正常运行中,Lighthouse 实际上不应该需要发现查询,因为它应该保持有用的 peer 的连接,而无需发现任何 peer。但是,如果一群 peer 从子网中掉线,Lighthouse 将启动一堆发现请求,以尝试搜索这些子网上的 peer 以进行连接。这将反映在此图中。如果你的节点不断进行发现请求,则可能会对它们进行排队,并且重要的请求会被延迟。这是网络连接不良的标志。
最后,最后一个图表显示了在子网上未能发布证明的次数。在此示例中,没有失败,因此该图表没有数据显示。但是,如果存在错过的证明,你应该会注意到峰值,这些峰值可能与给定子网上没有 peer 以及一些尝试查找这些 peer 的发现搜索相对应。如果你在底部图表中看到峰值,那么你很可能在查找和维护 peer 方面遇到问题。
真实案例研究
让我们追踪我错过的一个证明,看看我们是否可以确定原因。
我收到一封跟踪电子邮件,说验证者 X 在 epoch 278438 中错过了一个证明。
让我们看看我们的验证者客户端日志中关于该 epoch 的信息:
Apr 22 00:08:53.001 INFO All validators active slot: 8910042, epoch: 278438, total_validators: 64, active_validators: 64, current_epoch_proposers: 0, service: notifier
Apr 22 00:09:03.115 INFO Successfully published attestations type: unaggregated, slot: 8910043, committee_index: XX, head_block: 0xa4f55d872a5ef856469116245b81d7ad5b585b471a75f13707fa74fe787d9503, validator_indices: [xxxx], count: 1, service: attestation
看起来错过的是 slot 8910043 上的证明。beaconcha.in 上快速查看该 slot 显示区块根是 0x90af..,我们投票支持它的父区块 0xa4f55..。这表明区块延迟。让我们快速搜索我们的日志:
$ cat beacon.log | grep "8910043" | grep -e "Delayed" -e "On-time"
这将搜索以查看区块是否延迟或准时。结果:
Apr 22 00:09:03.344 DEBG Delayed head block, set_as_head_time_ms: 118, imported_time_ms: 41, attestable_delay_ms: 4209, available_delay_ms: 4184, execution_time_ms: 245, blob_delay_ms: 3985, observed_delay_ms: 3938, total_delay_ms: 4344, slot: 8910043, proposer_index: 726785, block_root: 0x90af45310b4c42692669acaab9dd94cada18ce6509e37f7232e826dbce2c7521, service: beacon, module: beacon_chain::canonical_head:1503
正如我们所怀疑的那样,区块延迟到达我们的节点。它在 4.2 秒后变得可证明。主要延迟是由于网络,因为区块在 slot 后 3.9 秒到达,blob 也在 slot 后 3.9 秒到达。在 EL 上验证区块花费了 245 毫秒,这意味着它在 slot 的 4.18 秒内可用(超过我们的 4 秒截止时间)。因此,我的验证者无法证明这个头区块,并且在被接受到区块中时,很可能在证明中处于少数。
如果我们查看 beaconcha.in 上以下区块(8910044)上的证明,我们可以看到该区块已满(它具有最大数量的证明 128)。快速浏览一下,似乎这些聚合证明中的大多数都投票支持延迟区块0x90af..。因为我的验证者投票支持 0xa4f55..,所以我的证明似乎是少数,并且未被选择包含在区块中。
由于我属于少数派,并且此区块略有延迟到达,这意味着网络的其余部分准时看到了此区块。这通常意味着两件事之一。
1) 我的地理位置(澳大利亚)具有一些固有的延迟,这意味着大多数网络看到了该区块,但我独自在南半球的岛屿上看到了它,而且无法证明。由于大多数网络不在澳大利亚,那么我被视为少数选民,其他澳大利亚人也看到了此区块,他们的证明也可能被遗漏。应该注意的是,该区块可能已延迟发布,但发布时间足够早,可以到达大多数网络,只是到达澳大利亚的额外延迟使得我的节点证明它太晚了。
2) 我的互联网连接很差。这种情况比我希望的要多。我的家庭网络可能会因其他家庭成员下载内容而饱和,从而导致我的节点下载区块的时间比应有的时间长。再加上澳大利亚拥有地球上一些最糟糕的互联网连接的事实,我的一些延迟区块实际上是由于我的本地互联网连接造成的(而且我不能仅仅责怪地理延迟)。帮助识别这种情况的一种方法是查看网络在区块上的一般参与情况。在此示例中,slot 8910043 上有 29222 个(唯一验证者)投票。一个区块上应该有大约 total_validator_count/32 个投票,在撰写本文时约为 31k。因此,29222 票表明参与率约为 94%。你还可以查看后续区块的同步委员会参与情况,在这种情况下约为 90%。这是相对较低的,表明该区块对于约 10% 的验证者而言是延迟的。如果此比率很高,约为 98% 以上,则很可能只是你的本地节点看到它延迟了,而不是它在网络上延迟发布。
让我们也从我们的仪表板中查看此区块。通过将此区块出现的 UTC 时间(4 月 22 日 00:09:03)与我们的仪表板进行比较,我们看到:
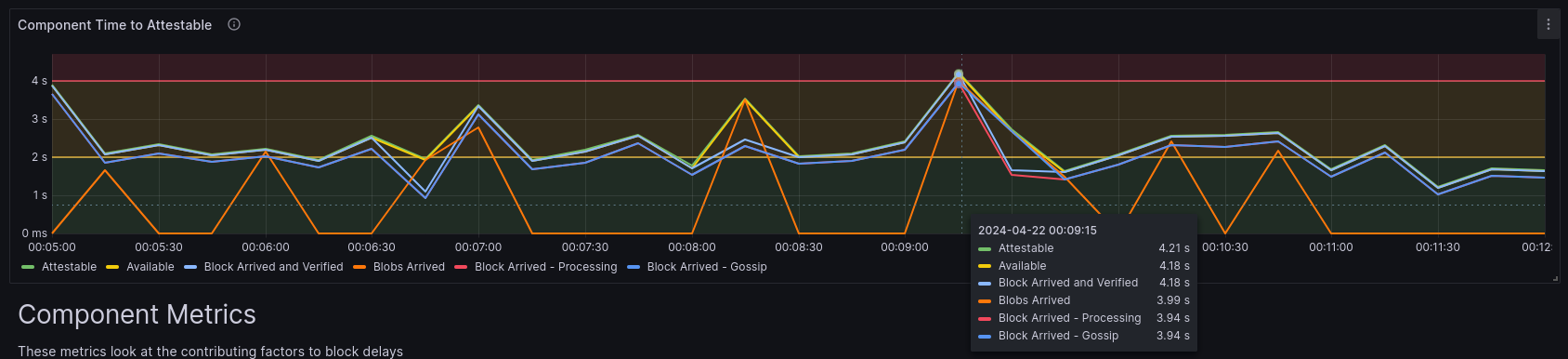
此图显示了延迟到达的区块。此区块延迟到达的主要原因是所有blob到达的时间太长(3.99 秒)。blob延迟到达完全与网络有关。子网稳定性图表未显示任何错误,并且大多数网络及时看到了此区块。因此,事实上,我们证明了错误的头部,这使得此证明不太可能被包含到此 epoch 的任何区块中。
常见问题和潜在的调整参数
在这里,我们列出了一些错过证明的最可能的原因,以及用户可以采取的潜在措施来改进它们。
延迟区块
正如我们所见,延迟区块是错过或次优包含证明的主要原因。正如我们所讨论的,有多种因素可能导致延迟区块,包括:
- 区块构建者/提议者延迟生成/发送它们
- 你的节点的地理距离相对于网络上大多数节点的延迟增加了
- 你的本地网络的带宽可能已饱和
如果你在云提供商上运行节点,虽然这对多样性不利,但将其放置在欧洲或美国附近可能会减少错过证明的数量。更好的解决方案是让大多数节点在地理上多样化,以便从所有节点感受到平均延迟,并且延迟区块将简单地被网络孤立。
如果你不关心带宽,Lighthouse 有一个 CLI 参数,可以增加节点的带宽使用率,以加快网络传播速度(即缩短获取区块/blob的时间)。该参数是 --network-load。将此值设置为 5 将增加 Lighthouse 的带宽,并应改善区块时间,从而降低错过证明的发生率(前提是你的网络带宽可以处理负载)。
我们还在努力改进协议,以提高网络的效率,Lighthouse 将在接下来的几个版本中尝试一些新的 gossipsub 设计,以在不增加带宽成本的情况下提高传播速度。
子网上没有足够的 Peer
这似乎是用户之间的另一个常见问题。如上所述,Lighthouse 试图在所有子网上保持 peer 的均匀分布。该算法需要一段时间才能筛选 peer,直到找到一组良好的稳定 peer。因此,当你最初启动客户端时,在启动后最多约 30 分钟,Lighthouse 的 peer 集可能不稳定,你可能会看到错过证明,并显示 InsufficientPeers 警告。让客户端运行一段时间应该会为你提供一组稳定的 peer。
该算法严重依赖于 peer 的入站流量。这意味着我们期望大量新 peer 连接到我们。为了使这种情况发生,你需要确保已正确转发 UDP(发现)和 TCP (libp2p) 端口。有关更多详细信息,请参阅 Lighthouse 书籍的高级网络部分。
如果你发现自己不断遇到此问题,则将 --target-peers 标志(默认为 100)增加到更高的数字,如 150 或 200,应该可以改善这种情况(因为你将有更多的 peer 在子网之间进行平衡)。但是,它也会增加带宽成本。
其他
以上是我们所见过的错过证明的两个主要原因。错过证明的另一个可能原因是由于时钟未同步。为此,你可以使用 timedatectl 进行检查,并确保字段 System clock synchronized 已启用(设置为 yes)。从指标仪表板中,你可能会注意到处理区块(CPU 受限)或执行验证(EL 运行缓慢,可能是由于 SSD 速度较慢)中的过度时间延迟。在这些情况下,你可能需要增加机器的资源,或者如果资源消耗的原因不明显,请通过我们的 Discord 联系我们中的一位。
未来
我们意识到以太坊共识网络的一些不足之处。我们正在努力改进协议,这些协议将在 Lighthouse 的未来几个版本中发布。这有望改善网络传播,但是我们无法修复区块生产者/提议者延迟发布区块的问题。我们能做的最好的事情是让网络孤立整个网络都认为太晚的区块。
在未来的硬分叉中,可能会有一些更改为与大多数人不同的证明提供区块中的额外空间,从而允许更大的包含和提高节点见证延迟区块的弹性。这些更改应提高整体参与率,并应减少网络上错过的证明的数量。
与此同时,我希望这里的信息对你有用,并且读者现在能够自我诊断错过证明的根本原因。
- 原文链接: blog.sigmaprime.io/attes...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





