我们的密码学专家解答 10 个关键问题
- Trail of Bits
- 发布于 2024-07-26 15:23
- 阅读 1225
本文是针对密码学领域中一些常见但可能令人困惑的技术的专家问答,涵盖了SNARKs中的 commitment schemes、哈希函数的构造、椭圆曲线密码学(ECC)的攻击方式、后量子密码系统、Fiat-Shamir heuristic、PLONK 证明系统的改进、zkEVMs的设计决策、zkEVMs的性能改进、Shamir 密钥共享方案以及 folding schemes的技术细节。
密码学是电子和互联网的一个基本组成部分,它有助于保护信用卡、手机、网页浏览(希望你正在使用 TLS!),甚至最高机密的军事数据。密码学在区块链领域也同样重要,像以太坊这样的区块链依赖于哈希、默克尔树和 ECDSA 签名等基本组件来发挥作用。配对、全同态加密和零知识证明等创新技术也已进入区块链领域。
对于许多人来说,密码学似乎是一个复杂而令人困惑的 “数学魔法” 难题。作为一名区块链安全工程师,我一直对密码学着迷,但从未深入研究过这个话题。幸运的是,我在 Trail of Bits 的同事都是世界级的密码学专家!我向他们提出了十个问题,以帮助你解开密码学的一些谜团。请记住,有些问题相当高级,可能需要额外的背景知识。但如果你是一位有抱负的加密爱好者,请不要灰心 —— 继续阅读!
1. 你能概述一下用于 SNARKS 的最常见的承诺方案吗?
多项式承诺方案是一种协议,其中证明者承诺一个特定的多项式,并生成一个证明来证明该承诺是有效的。该协议由三个主要算法组成:
- 承诺
- 开放
- 验证
在承诺阶段,证明者发送他们的承诺 —— 即,他们声称的在给定点对多项式 f 的评估值(因此是一个值 a,使得 f(x) = a)。该承诺应该是具有约束力的,这意味着一旦证明者承诺了一个多项式,他们就不能 “改变主意”,可以这样说,并为不同的多项式生成有效的证明。它也可能是隐藏的,因为以加密方式提取 x 的值 x 使得 f(x) = a 是不可行的。在开放阶段,证明者发送一个证明来证明该承诺是有效的。在验证阶段,验证者检查该证明的有效性。如果证明是有效的,我们知道证明者知道 x 使得 f(x) = a,具有很高的概率。
我们已经熟悉一种向量承诺,即默克尔树。多项式承诺方案的属性是相似的,但它们适用于多项式。目前在生产中使用的最常见的承诺方案有:
- KZG (Kate-Zaverucha-Goldberg),例如,用于 EIP 4844 中的 danksharding
- FRI (Fast Reed-Solomon Interactive Oracle Proofs of Proximity),用于 STARKs
- 像 Pedersen 承诺这样的承诺被用于像 Bulletproofs 这样的证明系统中(由 Monero 和 Zcash 使用)
KZG 承诺利用了这样一个事实:如果多项式 f(x0) = u 在某个点 x0,那么 f(x) - u 必须有一个因子 (x - x0)。根据 Schwartz-Zippel 引理,如果我们选择一个足够大的域,则不同的多项式 g(x) - u 被 (x - x0) 除的可能性非常小。在高层次上,我们可以利用这一点来承诺 f(x) 的系数并生成一个证明,验证者可以通过椭圆曲线配对非常快速地检查该证明,而无需揭示多项式本身。
FRI 使用纠错码来 “提高” 验证者发现无效承诺的概率。然后,我们可以使用默克尔树来承诺纠错多项式的评估。开放包括向验证者提供一个默克尔认证路径。
Pedersen 承诺使用离散对数问题。准确地说,给定一组基元素 (g0, g1, … gn),我们可以将系数 a0, … an 承诺为 C = g0 * a0 + g1 * a1 + … + g1 * an。我们可以将其与 Inner Product Argument(超出了本文的范围)相结合,以生成一个多项式承诺方案,其开放和验证算法基于内积参数。
KZG 具有非常小的证明大小,由一个群元素组成。然而,这涉及到一个可信设置,并且必须删除该可信设置参数,否则任何人都可以伪造证明。FRI 不需要可信设置,并且在理论上是后量子安全的,但具有非常大的证明大小。最后,Pedersen 承诺和 IPA 不需要可信设置,但需要线性验证时间。
还存在其他的承诺方案,例如 Dory、Hyrax 和 Dark,但它们在实践中使用得较少。
要了解有关这些承诺的更多信息,请查看 我们的 ZKDocs 页面。
2. 哈希函数无处不在,但很少有人掌握其内部工作原理。你能澄清流行的构造(例如,MD、Sponge)并强调它们之间的区别吗?
大多数人熟悉的哈希函数,如 MD5 和 SHA1,都是 Merkle-Damgard 构造。我们都熟悉和喜爱的 keccak256 函数是一种 Sponge 构造。
在 Merkle-Damgard 构造中,任意长度的消息被解析成具有特定大小的块。关键部分是压缩函数被应用于每个块,使用前一个块作为下一个压缩函数的密钥(对于第一个块,我们使用一个 IV,或初始化向量来代替)。Merkle-Damgard 构造表明,如果压缩函数是抗冲突的,那么整个哈希函数也将是抗冲突的。
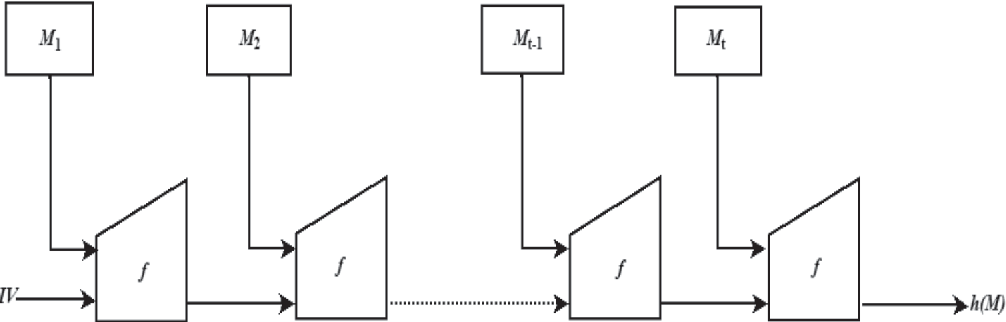
图 1:Merkle-Damgard 构造
相比之下,Sponge 构造不使用压缩函数。Sponge 构造的核心包括两个阶段:一个 “吸收” 阶段,其中消息的部分与初始状态进行异或,同时对初始状态应用一个置换函数;然后是一个 “挤压” 阶段,其中一部分输出被提取并作为哈希输出。
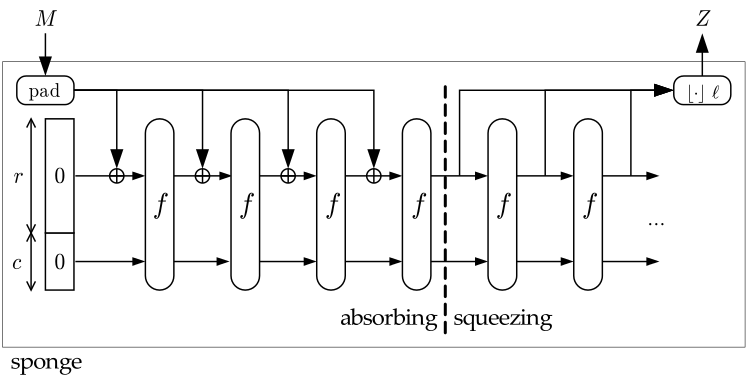
图 2:Sponge 构造
值得注意的是,与 Merkle-Damgard 构造相比,Sponge 构造不易受到 长度扩展攻击 的影响,因为并非所有最终结果都用作哈希函数的输出。
3. 椭圆曲线密码学 (ECC) 更加神秘,被认为是密码学中的一个主要 “黑匣子”。存在许多陷阱和技术攻击。你能阐明一些对椭圆曲线的理论攻击,如 Weil descent 和 MOV 攻击吗?
ECC 通常被认为是密码学中一个复杂且有些神秘的部分,可能存在各种技术攻击的漏洞。两个值得注意的理论攻击是 Weil descent 和 MOV 攻击。让我们稍微揭开这些攻击的神秘面纱。
本质上,ECC 的安全性依赖于解决某个数学问题的难度,该问题被称为椭圆曲线上的离散对数问题。选择标准椭圆曲线的特殊目的,就是为了使这个问题难以破解。这就是为什么,在实践中,Weil descent 和 MOV 攻击通常对标准曲线都不可行。
- Weil descent 攻击:这种方法涉及使用代数几何中的概念,特别是称为 Weil descent 的技术。这个想法是将离散对数问题从其在椭圆曲线上的原始形式(一种复杂的代数结构)转换为在更简单的代数结构(如超椭圆曲线)上的类似问题。这种转换可以使用已知的算法(如指标微积分)更容易地解决该问题,但前提是原始椭圆曲线足够简单。标准化的曲线通常足够复杂,可以抵抗这种攻击。
- MOV 攻击:此攻击使用称为 Weil 配对的数学函数将椭圆曲线离散对数问题 (ECDLP) 转换为有限域中的离散对数问题,这是一个不同的数学设置。这种攻击的可行性取决于一个称为嵌入度的属性,它本质上衡量了 ECDLP 对有限域设置的 “可转换性”。如果嵌入度较低,MOV 攻击可以通过将问题转移到存在更有效攻击方法的域来显着削弱安全性。但是,通常选择常用的椭圆曲线以具有较高的嵌入度,从而使 MOV 攻击不切实际。
总而言之,虽然这些对椭圆曲线的理论攻击听起来令人生畏,但在标准密码学应用中仔细选择椭圆曲线通常会使这些攻击无效。
4. 随着技术的发展以及量子计算机的威胁迫在眉睫,人们一直在努力创建后量子密码系统,如基于格的密码学和基于同源的密码学。你能概述一下这些系统吗?
基于格的密码学(Lattice-based cryptography)使用格(显然),格是基向量集合的整数线性组合。关于格有很多难题,例如最短向量问题(给定一个基,找到格中最短的向量)和最近向量问题(给定一个格和一个格外的点 p,找到格中离 p 最近的点)。下图来自 EuroCrypt 2013 上的演示文稿,说明了这一点:
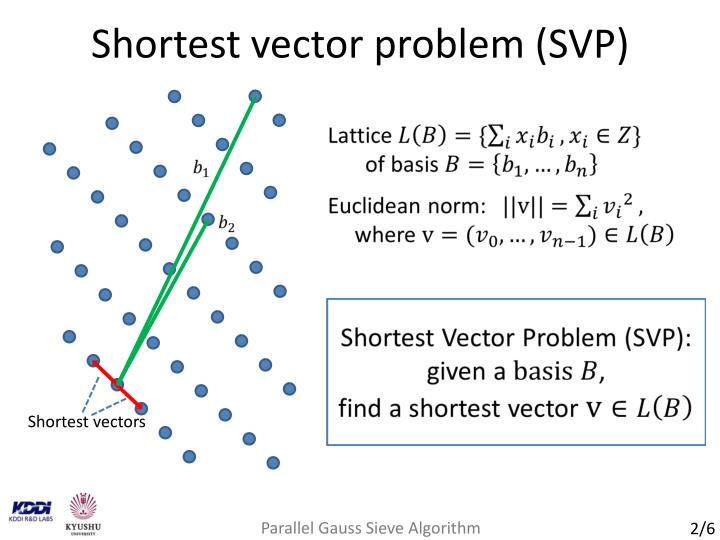
图 3:最短向量问题
有趣的是,可以证明关于格的大多数难题实际上与最短向量问题一样困难。已知解决这些问题的算法,即使是量子算法,也需要指数时间。我们可以利用这些难题来构建密码系统。
另一方面,基于同源的密码学(Isogeny-based cryptography)涉及使用同源(显然),同源是椭圆曲线之间的同态。我们基本上可以使用这些同源来创建标准椭圆曲线 Diffie-Hellman 密钥交换的后量子版本。在 5,000 英尺的高度上,我们可以使用底层的同源作为私钥,并将公共椭圆曲线的图像作为公钥,而不是将组元素作为具有随机整数的公钥发送。如果 Alice 和 Bob 组合彼此的同源并计算曲线的 j 不变量,他们每个人都可以获得一个共享秘密,因为 j 不变量是一个数学函数,对于同构椭圆曲线是相同的。
然而,supersingular 基于同源的 Diffie-Helman 密钥交换受到 密钥恢复攻击 的影响,该攻击不需要量子计算机,因此是不安全的。目前正在对实际上可抵抗量子计算机的基于同源的密钥交换算法进行更多研究。
5. Fiat-Shamir 启发式方法在整个交互式 oracle 证明领域中被广泛使用。关于这种启发式方法及其理论安全性,有哪些有趣的事情需要注意?
Fiat-Shamir 用于将交互式 oracle 证明系统转换为非交互式证明系统。
顾名思义,这允许证明者证明计算结果,而无需验证者在线。这是通过对公共输入进行哈希处理,并将该哈希解释为随机输入来完成的。如果哈希函数是真正的随机 oracle - 也就是说,如果哈希函数可以近似随机性 - 那么我们可以通过这种方式模拟验证者的随机数。
有几个与安全性相关的注意事项:
- 哈希必须包含所有公共输入;这个概念通常被称为强 Fiat-Shamir 变换。弱 Fiat-Shamir 变换仅包含一个或有限数量的输入的哈希,而强 Fiat-Shamir 变换包含所有公共输入的哈希。正如你可以想象的那样,弱 Fiat-Shamir 变换是不安全的,因为它允许证明者伪造恶意证明。
- 即使在使用强 Fiat-Shamir 变换时,也可能出现更微妙的理论问题。协议必须具有 “逐轮” 安全性的概念,这大致意味着作弊的证明者必须 “一次性” 走运,因此无法磨出哈希值,直到他们收到 “幸运” 输入。这通常意味着使用 Fiat-Shamir 的逐轮协议需要具有更高的安全参数,例如 128 位安全性。幸运的是,像 SumCheck 和 Bulletproofs 这样的系统在理论上是逐轮安全的,因此可以安全地使用强 Fiat-Shamir 启发式方法来创建非交互式公共币协议。
Fiat-Shamir 变换被广泛使用,并且在实现时必须格外小心,因为即使是微小的错误配置也可能允许恶意证明者伪造证明,这可能会产生灾难性的后果。要了解有关 Fiat-Shamir 以及潜在陷阱的更多信息,请参阅 此概述博客文章 以及关于 Frozen Heart 漏洞的 另一篇博客文章。
6. 最近 PLONK 交互式 Oracle 证明系统取得了显著进展。你能详细说明正在改进的内容以及改进方式吗?
交互式 oracle 证明是 SNARK 中的主要信息理论组件,它允许证明者生成一个证明,以使验证者相信 “知识”,以便可以高概率地发现虚假证明。
不同协议之间的关键因素是它们对证明者效率的改进以及灵活性的提高。例如,PLONK 证明系统通常需要大量的电路门,并且许多传统计算在电路内部进行编码的效率不高。此外,证明者必须将这些门编码为多项式,这需要大量的计算时间。PLONK 的变体有助于解决这些问题;这些包括:
- Turboplonk,与普通的 PLONK 相比,它支持具有两个以上输入的自定义门,而普通的 PLONK 每个门只允许两个输入。使用 Turboplonk 可以为复杂的算术运算(如位移和 XOR)提供更大的灵活性。
- UltraPLONK,它支持查找表,证明者只需证明 “电路困难” 计算(例如,SHA-256),并且他们的输入/输出对作为见证的一部分存在。更具体地说,在包含这些值的特定单元格上启用的附加约束可以轻松验证其有效性。
- Hyperplonk,它消除了对数论变换 (NTT) 的需求。PLONK proving 系统通常需要一个大的乘法子群才能计算 NTT,你可以将其视为 离散傅里叶变换 的密码友好版本。Hyperplonk 而是使用 sumcheck 协议 和多线性承诺,从而减少了大部分的证明者开销。
目前,大多数 API 支持 UltraPLONK 扩展(例如,对于 Halo2 和 Plonky2),因为这同时支持自定义门和查找。Hyperplonk 很有希望,但仍在进行微调,并且在常用库中使用的不多。PLONK IOP 不断改进,以更快且更好地支持递归计算,并且还在开发更多变体。
7. 我们经常听到 zkEVM 以及构建它们的项目,如 Scroll、Polygon 和 zkSync。你能解释一下构建一个 zkEVM 涉及的各种设计决策吗?(类型 1/2/3 等)
你可以根据它们与以太坊的 “完全兼容” 程度来考虑不同类型的 zkEVM,其中 1 型是最等效的,而 4 型是最不等效的。
1 型 zkEVM 在各个方面都等同于以太坊的执行和共识层,这保持了与下游工具的兼容性,并允许轻松验证 L1 区块。但是,它们具有最高的证明者开销,因为 EVM 本身包含许多 ZK 不友好的技术(keccak、Merkle 树、堆栈)。目前,PSE 团队和 Taiko 正在努力构建 1 型 zkEVM。
2 型 zkEVM 旨在与 EVM 等效。2 型和 1 型之间的区别在于 EVM 之外的对象(如状态 trie 和区块验证)的行为会有所不同,因此大多数以太坊客户端本身将与此 zkEVM 不兼容。优点是证明时间更快,而主要缺点是等效性较低。例如,2 型 zkEVM 可能会使用修改后的状态 trie,而不是以太坊使用的 Merkle tries。Scroll 团队和 Polygon 都在致力于成为 2 型 zkEVM,但是就他们目前的状态而言,将他们指定为 3 型更为合适。
3 型 zkEVM 也具有更快的证明时间,但通过使用更少的等效性来实现此目的。这些 VM 删除了 EVM 中难以在电路中本地执行的部分,如 keccak256,并用 ZK 友好的哈希函数(如 Poseidon)替换它们。此外,他们可能会使用不同的内存模型,而不是像 EVM 那样仅仅基于堆栈;例如,他们可能会使用寄存器。Linea 是 3 型 zkEVM 的一个例子;但是,与 Scroll 和 Polygon 一样,他们正在努力改进以使其成为 2 型。
最后一种类型的 zkEVM 是 4 型,它只是旨在采用像 Solidity 和 Vyper 这样的语言,并将其编译为 ZK 友好的格式以生成证明。显然,这是最不相等的(以至于它甚至可能没有 EVM 兼容的字节码),但权衡是证明生成最快。zkSync 的 zkEVM 是 4 型 zkEVM 的一个例子。
8. 我们目前在生产中拥有 zkEVM,Scroll、zkSync 和 Polygon 都进行了主网部署。我们可以对这些 zkEVM 进行多少改进才能解锁消费级证明/验证?
尽管从理论上讲,可以通过 plonkish 算术化、查找和增量可验证组合 (IVC) 的组合来解决构建 zkEVM 和创建有效证明的主要挑战,但在我们真正创建 ZK 证明所承诺的大规模可扩展性之前,仍然存在许多工程挑战。当前的基准 表明,在 32 核 Intel Xeon Platinum CPU 上生成 128K Pedersen 哈希的 UltraPLONK 证明的生成速度相当快,仅需约三秒钟;但是,内存需求仍然很高,约为 130 GB。可以进行许多可能的进一步优化:
- 使用更小的字段:现代 CPU 以 64 位字运行,而 SNARK 内部的计算通常在椭圆曲线组中运行,大约为 256 位。这意味着电路内部的字段元素必须拆分为多个肢体,这会产生大量的计算成本。通过使用 Goldilocks 等较小的字段并执行基于 FRI 的验证(请参阅 你能概述一下用于 SNARKS 的最常见的承诺方案吗?),可以提高证明者的计算速度,但代价是更大的证明大小和更慢的验证速度。
- 硬件改进和并行化:许多 FPGA 和 ASICS 也可以用于优化 SNARK 生成。SNARK 证明通常涉及大量的哈希和椭圆曲线运算。事实上,大约 60% 的证明生成包括多标量乘法或 MSM。因此,使用专为这些操作设计的专用硬件可以显着提高性能。此外,专用计算硬件还可以更有效地执行 NTT。ZK 领域的许多团队(如 Ingonyama)都在尝试使用 FPGA/GPU 硬件加速来加速这些操作。此外,虽然电路综合的某些部分无法并行化,但诸如见证生成之类的事情可以并行完成,这进一步加快了证明生成。Matter Labs 的 Boojum 就是这样一种执行此操作的 SNARK 证明系统。
- 最后,仍然有许多理论上的改进 可以进一步加快证明生成和验证。除了进一步加速递归 SNARK 证明(如 Goblin Plonk)的工作之外,更快的查找参数(如 Lasso)也将带来更高的性能。可以优化椭圆曲线运算本身的算法。例如,可以通过 曲线自同态和 Barrett 约简 比标准的 “double-and add” 算法更快地执行标量乘法。使用 扭曲爱德华曲线 而不是 Weierstrass 形式来表示点也可以加快点加法。最后,像 Binius 这样的 SNARK 使用二进制字段塔来使其对硬件更友好。
随着 SNARK 的改进越来越高级,SNARK 即将在消费级硬件上运行是现实的。将来,有可能在智能手机上生成 zkSNARK。
9. 你能讨论一下密钥共享方案,如 Shamir 的密钥共享,它们的潜在用例,以及你观察到的常见错误吗?
Shamir 的密钥共享 (SSS) 是一种在各个方之间拆分一组密钥的方法,以便他们中的一组可以一起恢复密钥,但是少于阈值的参与者无法了解任何信息。
Shamir 密钥共享的主要思想是使用这样一个事实,即任何 p + 1 个点的集合唯一地确定一个 p 次多项式。通过使用 拉格朗日插值,参与者的阈值可以协同工作以恢复共享密钥(在本例中为多项式的常数项)。可验证密钥共享扩展了 SSS,并涉及发布基于离散对数的承诺给共享集合。密钥共享广泛用于阈值签名(如 tECDSA)和各种多方计算协议。
与所有密码学方案一样,有几个需要注意的潜在问题可能会使 SSS 或 Feldman 的可验证密钥共享完全不安全:
- 与参与者共享 0 点会无意中泄露密钥。这是由定义决定的,因为 0 点是参与者必须协同工作才能恢复的密钥。但是,由于多项式在有限域上定义,因此必须注意不要生成任何与 0 模等效的共享。
- 确保共享之间的差值不为 0 或模等价。要重新计算共享密钥,使用拉格朗日插值,这涉及计算机共享之间差值的模逆。如果共享之间的差值为 0,则协议失败,因为 0 没有模逆。
- 在为可验证密钥共享创建承诺时,请确保验证已提交多项式的度数(即,生成方发送的系数数量)。恶意方可以发送比必要更多的系数,从而提高每个人的阈值。
10. 用于递归证明的折叠方案最近变得非常流行。你能简要概括一下它们的工作方式吗?
很乐意!折叠方案是称为增量可验证计算的问题的一种解决方案。增量可验证计算 (IVC) 背后的问题是:给定一个函数 F 和一个初始输入 v0,其中 v_i = F^i(v0),你能否验证每个索引 i 处 F 的计算?一个具体的例子是具有 EVM 状态转换函数 F 和世界状态 w0。IVC 询问是否可以验证先前的状态转换函数的执行,直到最终状态:

图 4:IVC ( 来源)
以前的 IVC 方法涉及让证明者生成一个 SNARK,其验证电路嵌入在函数 F 中。这种方法有效,但效率相当低,因为证明者需要在 F 的每次迭代中生成一个 SNARK,并且验证者需要验证它,这将需要大量在电路上昂贵的非原生字段算术。此外,与在验证者中嵌入大型 SNARK 电路相比,折叠方案提供了大量优势。批处理大小现在可以是动态的,而不是必须在 SNARK 验证期间指定批处理大小。此外,可以为每个状态转换并行完成证明,并且证明者可以在观察到第一笔交易后立即开始生成证明,而不必等待整个批处理完成。
折叠方案起源于 Nova,并引入了一个新思想:验证者不会在每次调用 F 时验证 SNARK,而是会将当前实例 “折叠” 到累加器中。在执行结束时,验证电路将简单地检查累加器的一致性。更技术地讲,给定约束系统的两个见证,验证者可以将他们的承诺组合为称为松弛 R1CS 的见证承诺,这是一个 R1CS 实例以及一个标量 u 和一个错误向量 e。错误向量用于 “吸收” 由组合两个承诺产生的交叉项,标量用于 “吸收” 乘法因子。这使我们可以为下一轮保留 R1CS 的结构。通过重复执行此操作,验证者可以将每个新的见证实例折叠到累加器中,该累加器将在计算结束时进行检查。要将此累加方案转换为 IVC,验证者所要做的就是验证折叠是否正确完成。这样做会验证 F 的每次调用,且该验证与折叠实例的数量无关。
折叠方案已经进行了多次更新和改进。例如,Sangria 方案将折叠推广到 Plonkish 算术化,而不仅仅是 R1CS。HyperNova 将 Nova 推广到可定制的约束系统 (CCS),这是一种更通用的约束系统,可以表达 Plonkish 和 AIR 算术化。
增量可验证计算和证明携带数据(IVC 到有向无环图的推广)的最新改进非常有希望,并且可以实现对区块链的极快、简洁的验证。不断进行更多改进,我们可能会在未来看到更多改进。
迈向更好的密码学安全性
密码学不断发展,理论与实现之间的差距越来越小。越来越多有趣的密码学协议和新颖的实现涌现出来,包括多方计算、增量可验证组合、全同态加密以及介于两者之间的所有内容。
我们很乐意看到更多这些新协议和实现,因此,如果你希望我们进行审核,请 告诉我们!
- 原文链接: blog.trailofbits.com/202...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





