基于本地EL内存池的Blob Sidecar实证命中率 - 网络
- 以太坊中文
- 发布于 2025-05-28 11:40
- 阅读 1189
这篇研究探讨了以太坊执行层(EL)mempool中blob sidecar的命中率,旨在评估分布式区块构建的可行性。研究发现,大多数情况下,EL在区块提议前已拥有必要的blob数据,表明当前网络在CL侧链主题上发送冗余信息,浪费了资源,因此建议在EL mempool中进行分片,以优化网络资源使用,比如提议使用Blob mempool DHT。

本研究由 ProbeLab 团队的 @cortze 和 @yiannisbot 完成(probelab.io),并得到了 EF 和 PeerDAS 社区的反馈。
简介
作为以太坊提高可扩展性路线图的一部分,引入了 blob transaction,以便在每个插槽中包含更多数据。因此,可以添加的 blob 越多,链上可以支持的数据就越多,这有利于 rollups 和其他扩展解决方案。
因此,人们一直有兴趣增加每个区块的 target 和 maximum blob 数量。然而,这引发了一些担忧:
- 虽然机构 stake 者可能拥有处理更多 blob 的硬件和带宽,但许多家庭 stake 者却没有。这会在验证者参与中造成潜在的不平衡。
- 增加 blob 计数也可能影响某些节点保持同步的能力,尤其是在 reorgs 或恢复事件期间,节点需要从较小的对等节点集中下载大量数据。
目前,除了查看我们从其他节点下载区块或 blob 的速度之外,我们没有太多方法来衡量网络在这些情况下的处理能力(请查看我们的文章,扩展了这个想法)。这提供了一些见解,但不足以完全了解网络在压力恢复下的行为。
一种可能的减少单个验证者负载的方法是通过 distributed block building。由于执行层 (EL) 通常在 blob transaction 被包含在区块中之前收到许多 blob transaction,因此区块构建者可以通过假设其他节点的本地 mempool 已经包含区块验证所需的 blob 来减少初始带宽使用。
本文的工作建立在我们最近的研究之上,我们在该研究中测量了 blob sidecar 的理论 EL mempool 命中率。该分析表明,在超过 75% 的情况下,EL 在区块提议之前就已经拥有必要的 blob 数据。然而,该研究并未检查 EL 是否能够及时为来自共识层 (CL) 的 engine_getBlobsV1 调用提供 blob。
在本次后续研究中,我们研究了 EL mempool 中 blob sidecar 的实际命中率,以更好地了解 distributed block building 在实践中的可行性,尤其是在帮助带宽或资源有限的验证者方面。
概括
-
监控 CL 和 EL 之间的本地
engine_GetBlobsV1调用显示 EL 的 mempool 具有很高的实际 blob 命中率:- 总请求的 76.6% 成功地从本地 EL mempool 中检索,以在 100 毫秒内验证区块。
- 剩余的 23.4% 的请求得到了部分响应。然而,在大多数这些部分响应中 (98%),从请求列表中只缺少一个blob sidecar。
- 当前网络状态表明,通过 gossipsub 网络重新分配所有 sidecar 可能会产生一些冗余流量,因为目前,当广播新区块时,大多数 blob 已经存在于 EL mempool 中。
方法论
为了生成和收集所有必需的样本,以保持对 EL blob mempool 的一致视图,我们开发了自定义工具,该工具为 CL 节点到 EL 客户端的每个 engine_GetBlobsV1 请求/响应提交一个条目行。
为此,我们在 Prysm fork 上开发了一个新的 event-stream endpoint,该 endpoint 不仅会暴露有关 Engine API 请求的数据,还会暴露响应和时间信息。
研究细节
收集数据的时间和方式的详细信息:
- 收集的数据属于以下日期:
| 日期 | Pre-Pectra | Post-Pectra |
|---|---|---|
| 从 | 2025-05-02 |
2025-05-07 |
| 到 | 2025-05-07 |
2025-05-11 |
- 我们使用了以下客户端对:
- Prysm (
custom-fork) ↔ Nethermind (v1.31.9)
- Prysm (
- 我们从西班牙的家庭设置中的 Intel Nuc 运行两个客户端。
分析
通过超过 9 天的数据,以下图表总结了 Pectra 链 blob target 和 max 参数之前和之后的网络状态:
- Pectra 之前:
blob-target=3和blob-max-value=6。 - Pectra 之后:
blob-target=6和blob-max-value=9。
每个插槽的 blob 数据
以太坊社区对增加 blob target 和 maximum 值表现出浓厚的兴趣,因为这些值与网络的可扩展性直接相关。更高的 blob 限制可以通过允许更多数据发布在链上来帮助 rollups 和其他扩展解决方案。
然而,如下面的条形图所示,在此期间只有 70% 的区块包含 blob transaction。这表明,虽然容量存在,但在实践中并非总是得到充分利用。
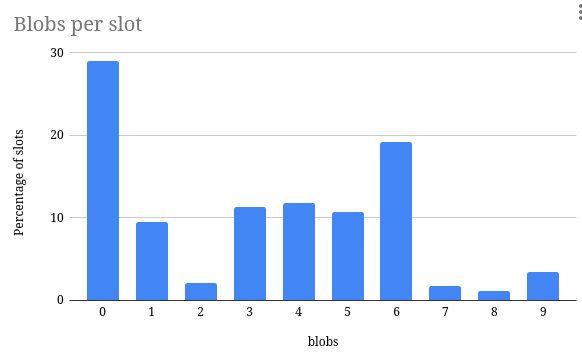 \
image582×354 4.74 KB
\
image582×354 4.74 KB这些模式可能会随着时间的推移而发生变化,尤其是现在 Pectra 升级增加了可以容纳在一个区块中的 blob 数量。以下条形图比较了 Prysm 通过 engine API 在升级前后请求的 blob,展示了 blob transaction 的新分布是如何变化的。
在 Pectra 之前,摘要显示只有 53% 的请求至少包含一个 blob transaction,并且其中 71.87% 的请求在本地 EL 客户端中提供了所有链接的 blob sidecar。
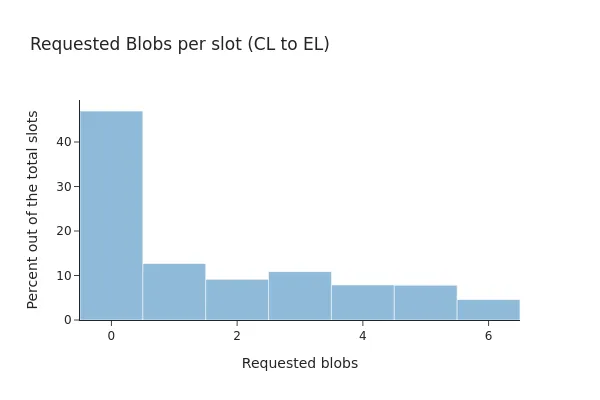 \
image600×400 21.3 KB
\
image600×400 21.3 KB在 Pectra 之后,该百分比几乎没有变化,52% 的请求至少包含一个 blob transaction,其中 81.82% 的请求在 EL 客户端中提供了所有 blob。
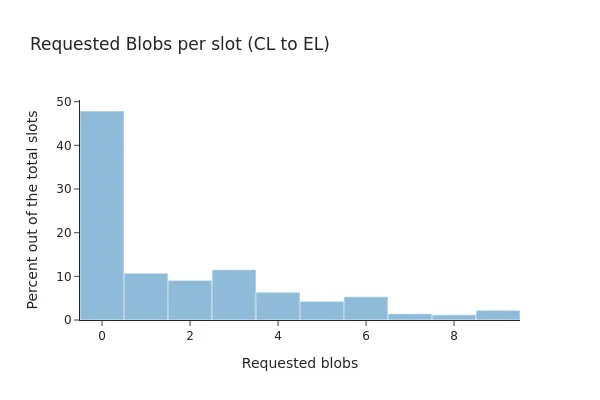 \
image600×400 23.6 KB
\
image600×400 23.6 KB编辑:
之前的版本错误地假设 CL (Prysm) 从 EL 请求的 blob 数量与 CL 区块中包含的 blob 数量相匹配。然而,这种关系是不正确的,至少对于 Prysm 来说是这样。
在那些 Prysm 在区块本身到达之前就知道 blob sidecar 的情况下,Prysm 将省略从发送给 EL 的请求中请求该 blob。因此,当将其与每秒的 blob 进行比较时,会产生每个插槽的请求 blob 的不匹配分布。
以下 Sankey 图总结了 CL 客户端从与 engine API 的交互中获得的响应流。数据是经过 9 天汇总的,因为在 Pectra 升级前后期间没有显着差异。该图显示,与区块总数相比,CL 收到的部分 engine_getBlobsV1 请求的数量相对较少。
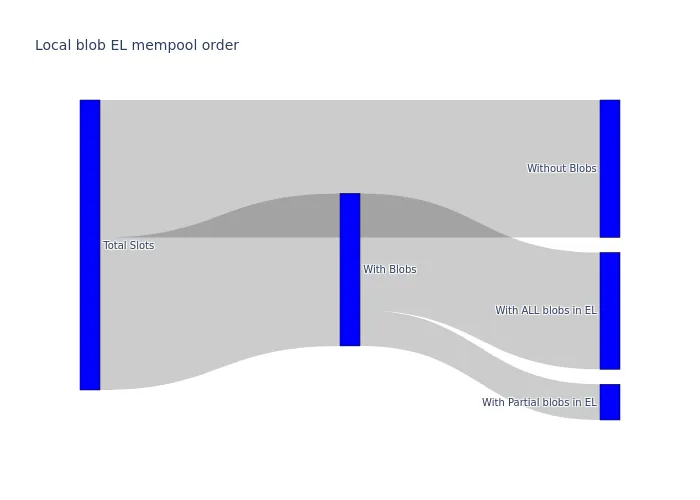 \
image700×500 38.7 KB
\
image700×500 38.7 KBengine 响应的精确度
并非所有执行层 (EL) 客户端都以相同的方式处理 engine_getBlobsV1 请求。有些可能只在拥有 所有 请求的 blob 时才响应,而另一些可能只在拥有其中一些 blob 时才返回部分响应。在我们的设置中,Nethermind 返回部分响应,这使我们能够衡量在请求时 EL mempool 中存在多少请求的 blob。
下图显示了这些响应在 Pectra 硬分叉前后的分布。两个图表都显示了 engine API 返回的 blob 数量的直方图,按请求的 blob 数量分组。如图所示,两种主要的响应模式是最常见的:
- engine API 返回所有请求的 blob sidecar。
- engine API 返回除一个请求的 blob sidecar 之外的所有 sidecar。
Pectra 之前:
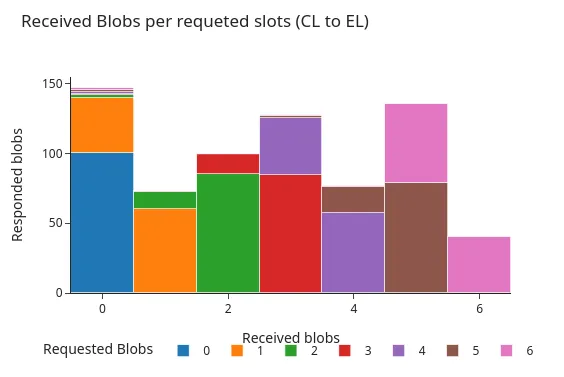 \
image564×377 33.3 KB
\
image564×377 33.3 KBPectra 之后:
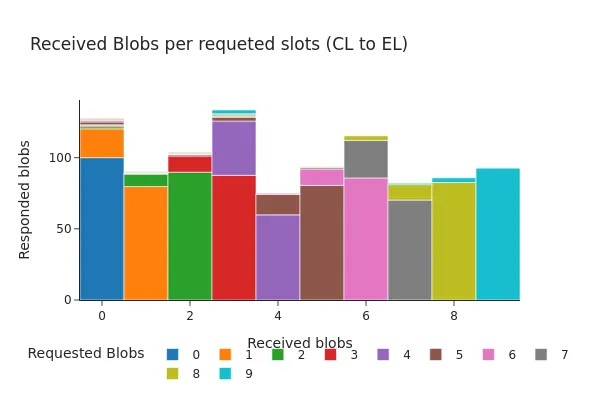 \
image600×400 39 KB
\
image600×400 39 KB除了存在包含多达 9 个 blob(由 Pectra 升级启用)的请求外,这两个图显示了非常相似的分布。在超过 98% 的情况下,在请求时,EL 中提供了所有请求的 blob,或者仅缺少一个 blob。
虽然始终只缺少一个 blob 似乎不寻常,但我们认为对此行为有几种合理的解释:
- 缺少的 blob transaction 可能是私有 mempool 的一部分,这意味着它没有被公开传播,只能通过 CL gossip 获得。
- EL 可能太晚才知道该transaction,或者可能没有足够的时间在发出
engine_getBlobsV1请求之前下载完整的 payload。
为了更好地了解情况,我们使用 Xatu 的 mempool 数据库交叉引用了缺少的 blob transaction。结果表明,58% 的缺失 sidecar 从未在公共 mempool 中看到,这支持了许多这些transaction可能是私有的或最近广播的说法。
| 是响应的一部分吗? | 在公共 mempool 中见过吗? | sidecar 数量 |
|---|---|---|
| true | true | 197156 |
| false | true | 4571 |
| false | null | 6392 |
Engine API 调用和 blob 重建时间
由于共识层 (CL) 不能无限期地等待执行层 (EL) 的响应,因此几个客户端团队已经讨论是否应该对 engine_getBlobsV1 请求强制执行超时,如果是,那么什么值是合适的。
下图显示了 engine API 的请求/响应持续时间(以毫秒为单位)的累积分布函数 (CDF)。
Pectra 之前:
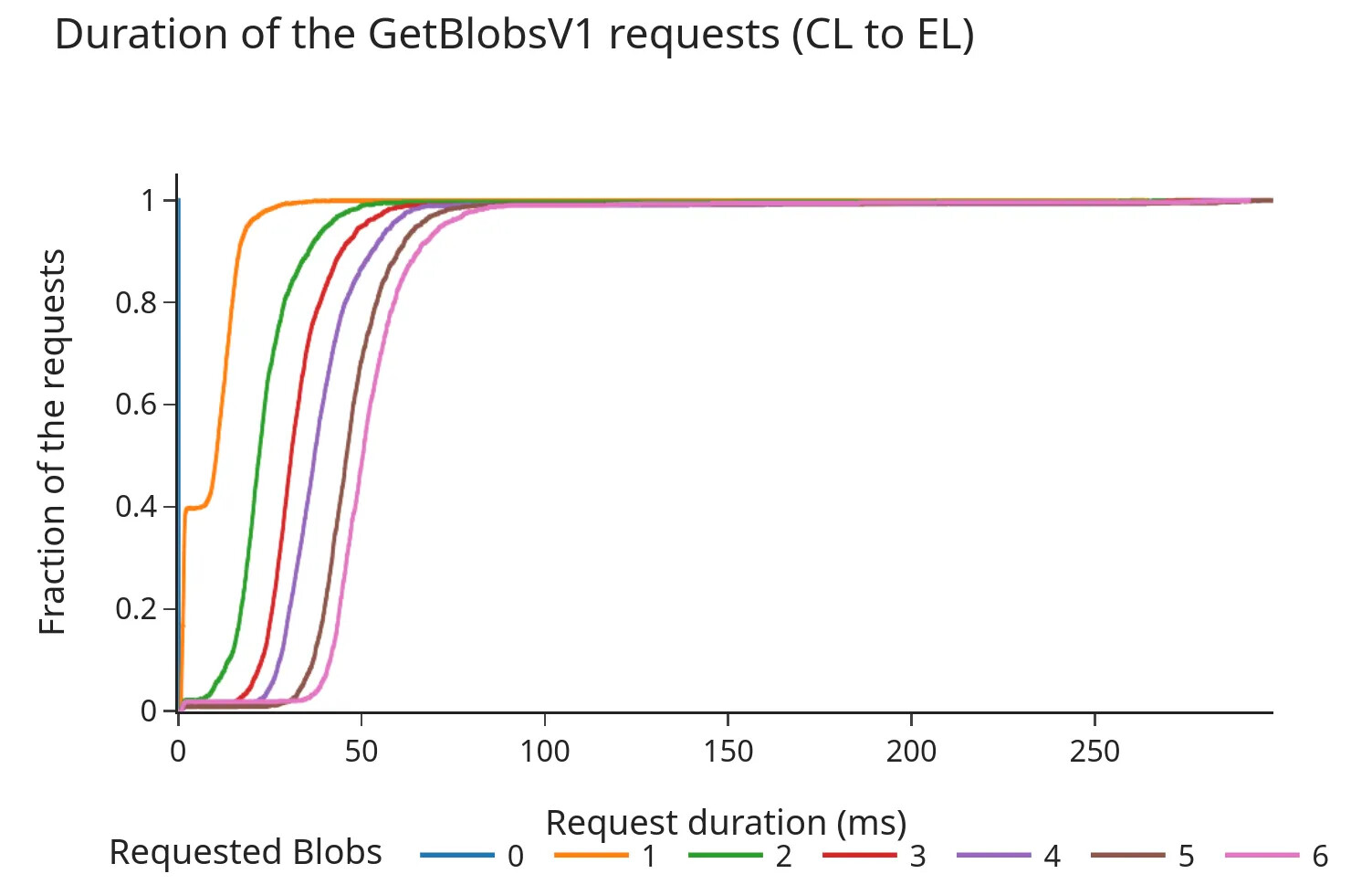 \
image1503×980 111 KB
\
image1503×980 111 KBPectra 之后:
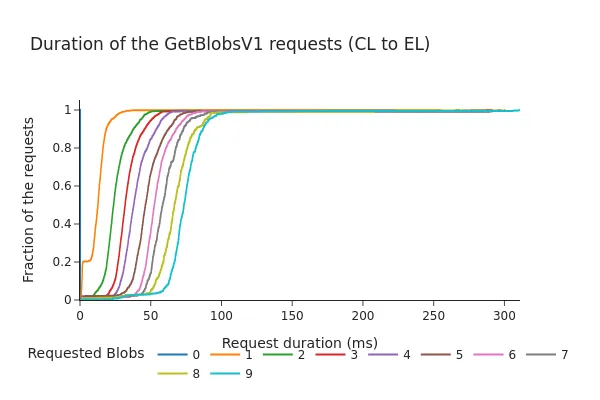 \
image600×400 60.9 KB
\
image600×400 60.9 KB- CDF 显示,即使在 Pectra 分叉以及每个区块增加 3 个额外 blob 之后,98% 的请求也在 100 毫秒内完成。
- 总持续时间往往随着请求的 blob 数量的增加而几乎线性地增加。虽然这些时间仍在通常被认为是“安全范围”的时间内(之前的讨论建议超时时间约为 200-250 毫秒),但数据表明,增加每个插槽的 blob 计数可能会导致从 EL 的 blob mempool 中获取的时间更长,尤其是在更高的负载下。
结论
本研究和我们之前的研究与 @cskiraly 的 一篇 并行进行,并且,尽管方法不同,但两项工作都得出相同的结论:
在当前的网络状态和链的使用趋势下,大多数 blob sidecar 在被包含到信标区块时已经在 EL 中可用。
虽然这个结论通常是个好消息,但它表明当前网络正在使用其相当大一部分资源通过 CL sidecar topic 发送冗余信息,这反过来又留下了充足的改进空间。
一方面,这种冗余确保了所有 CL 节点都有及时处理新区块提议所需的数据,从而成功提供了弹性。另一方面,它也成为了自己的瓶颈,因为所有 blob sidecar 都需要在略低于 4 秒的时间内通过网络广播(假设 time-games 正在缩短该窗口)。
建议
主要目的是减少网络开销和节点过载,因此值得围绕 PeerDAS 和 blob sidecar 共享展开讨论。
-
根据以太坊当前的 PeerDAS 提案,我们只在 CL 上分片 sidecar,这是对 Blob 重新分配阶段的优化。然而,这只是部分解决了问题,因为我们仍然会将所有 blob transaction 发送到 EL mempool,如果节点的带宽允许,它们将谨慎地下载所有 blob。
-
即使使用 distributed block building,它可以有助于更快地广播 blob,我们仍然会发送(至少部分)冗余信息。
IDONTWANT消息在这里有所帮助,但我们仍然会生成许多重复项,这最终会增加网络开销和节点负载。
可能的未来
将分片转移到 EL 的 mempool 具有明显而重要的好处:
-
在 EL 上分片 sidecar 可以简化验证网络中 blob 的 seeding 和一些预计算步骤,这可能是 transaction 提议者的一项新职责,即对 blob-cell 应用纠删码并启动广播。
-
可以提议/应用负载平衡属性来分配 blob,这消除了 CL 必须广播 sidecar 的当前“4 秒”时间限制。因为 blob 尚未包含在内,所以我们不需要对其传播强制执行任何截止日期。这进一步意味着较慢的用户在广播这些分片时可以“承受”一些额外的延迟。
-
EL 目前比 CL 更有效地下载 blob:
- 在 EL 层中提取 blob 时没有时间限制,因此,无需一次下载我们看到的所有 blob。
- EL 决定何时发送单个 pull sidecar 请求,从而避免了 GossipSub 在其平均 mesh 对等节点上引起的重复 → 默认为每个消息
D-2个重复项 (链接)
这在很大程度上符合 @cskiraly 的提议:在执行层 (EL) 而不是在共识层 (CL) 实现分片可能效率更高。
这个想法仍处于草案形式,并探讨了我们如何优化网络资源的使用,因为还有一些未解决的问题需要解决。
作为这种情况的一个例子,我们希望重新回顾并分享 ProbeLab 团队几个月前开始起草的一个仍在进行中的 Blob mempool DHT 提案。它旨在演示 CL 和 EL 如何同步运行以实现更有效地利用网络带宽和存储(将提案的详细信息留待以后的文章)。与往常一样,欢迎所有反馈。
- 原文链接: ethresear.ch/t/empirical...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





