使用 TFHE-rs 实现 AES-128 密码系统的全同态版本
- ZamaFHE
- 发布于 2025-05-01 22:56
- 阅读 2083
本文介绍了在同态加密中进行转密码的概念,即同态应用加密或解密算法。Zama举办的TFHE-rs Bounty Season 7 就是关于同态应用 AES 加密算法的挑战。最终“sharkbot”的提交方案因其高效的 S-box 处理方法而获胜,该方案将 S-box 视为可计算的位级电路,并使用多种优化策略实现了最佳性能。其他参赛者也使用了类似方法,但性能略逊。
Nicolas Sarlin
在同态加密中,transciphering 是指同态地应用加密或解密算法的概念。这是 TFHE-rs Bounty Season 7 的主题,其中要求挑战者同态地应用 AES 加密算法。
在实践中,transciphering 可以减小加密数据的大小,以便存储或传输。例如,由于 FHE 加密会显著增加消息大小,因此限制交换数据量的一种实用策略是发送消息的 AES 加密以及 AES 密钥的 FHE 加密。然后,通过同态地应用解密,可以降低整体通信开销。
我们收到了许多非常高质量的提交,选择获胜者特别具有挑战性。我们特别高兴地看到不同提交实现的各种策略,每种策略都以独特的方式利用 TFHE-rs API 的不同部分。
经过仔细审查和基准测试,我们将大奖授予 “ sharkbot ” 的提交。
挑战
对于此赏金,我们对 AES 的“计数器”加密模式感兴趣(图 1)。在此模式下,明文被分成 128 位块。AES 密码加密一个计数器,该计数器由一个 64 位随机选择的 nonce (IV) 和每个块的 64 位增量值组成。然后,每个明文块与 AES 密码的输出进行异或。
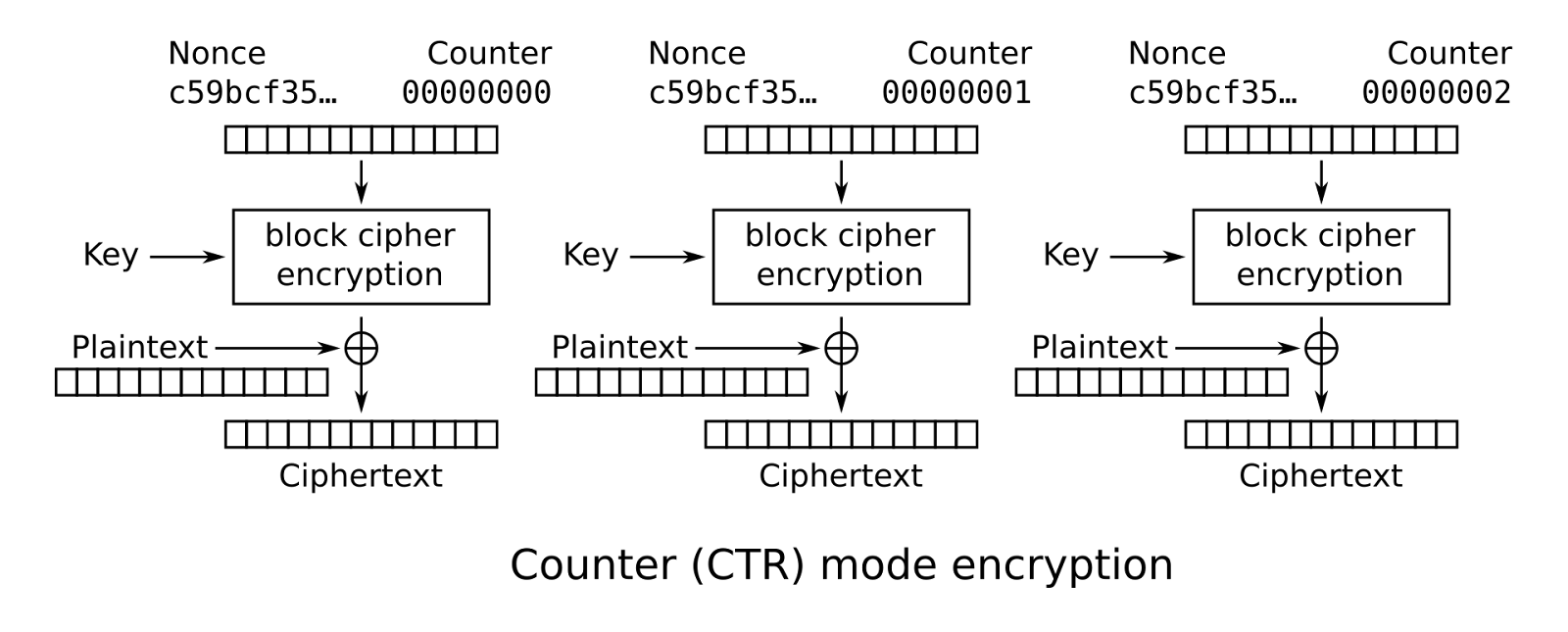
图 1:计数器 (CTR) 模式加密,维基百科,公共领域
这种类型的加密模式特别适合 FHE,因为它很容易并行化。
AES 分组密码首先使用密钥扩展过程进行初始化,该过程将初始 128 位密钥扩展为 11 个轮密钥 - 一个用于初始化,10 个用于加密轮。
密钥扩展本身包含多个步骤,尤其包括多次应用 SubBytes 操作,这将在下面进一步说明。
然后,每个 128 位明文块经历一个 10 轮的循环。每轮应用以下步骤:AddRoundKey、SubBytes、ShiftRows 和 MixColumns。
- AddRoundKey:轮密钥和当前状态之间的简单异或。
- ShiftRows:状态中的字节级移位 - 本质上在 FHE 计算下是免费的。
- MixColumns:更复杂,需要在伽罗瓦域内进行异或和乘法。
- SubBytes:将非线性查找表(S 盒)应用于每个字节(图 2)。此步骤对于 AES 安全至关重要,并且是 FHE 实现的最大挑战。
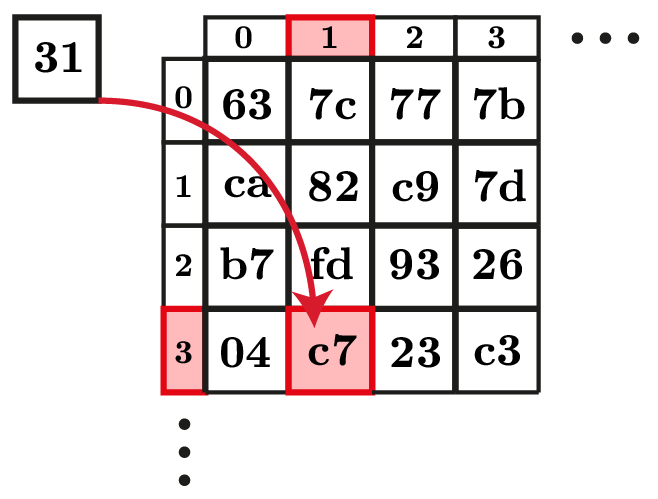
图 2:AES s-box,维基百科,公共领域
正如 TFHE-rs 深度剖析系列 中所解释的那样,TFHE-rs 的关键特性之一是 bootstrap 操作,它支持应用查找表 (LUT)。然而,Bounty Program Season 7 中的挑战是,对于大多数优化参数集,AES S-box 太大而无法放入单个 TFHE LUT 中。处理这种约束是我们收到的提交之间的主要区别。
获胜的解决方案
Sharkbot 的提交通过将 S 盒视为可计算的位级电路而不是字节级 LUT 而脱颖而出。这种方法并非 FHE 所特有,并且已被探索用于在低功耗电子设备中运行的 AES 实现。
具体来说,sharkbot 实现了 AES s-box 的 Boyar-Peralta 电路的 FHE 版本。这种紧凑的电路支持正向和反向 S 盒计算,使其可重用于解密。它包含一系列针对输入位的 XOR 和 AND 运算。
为了执行这些操作,获胜的提交实现了以下策略:
- Shortint layer:使用 TFHE-rs 的底层 shortint API 直接操作加密位。
- 参数调整:仔细选择参数以最大化线性(廉价)运算,并将昂贵的 bootstrap 的使用限制在需要刷新噪声时。
- 并行性:并行化每个 AES 块内部和不同 AES 块之间的操作。分析 S 盒计算的数据依赖关系图,以实现安全有效的并行执行。
因此,该提交实现了我们基准测试机器的 CPU 内核的最佳利用率,使其成为我们收到的最有效的解决方案。
这些技术使 AES 加密算法能够在 FHE 下完全执行,如下所示:
let encrypted_round_keys = fhe_key_expansion(&sks, &mut encrypted_key);
let mut encrypted_counters = fhe_generate_counters(&sks, number_of_outputs, &encrypted_iv);
encrypted_counters.chunks_mut(thread_pools.len()).for_each(|chunk|{
chunk.par_iter_mut().enumerate().for_each(|(i, input)|{
thread_pools[i % thread_pools.len()].install(||{
fhe_aes_encrypt(&sks, input, &encrypted_round_keys);
});
});
});
(注意:此实现尚未集成到 TFHE-rs 中。)
其他值得注意的提交
“ tomtau” 采用了非常相似的方法,后者获得了第二名。他们的 s-box 实现也使用了 Boyar-Peralta 电路,但这次受到了 Nigel Smart 的工作 的启发,Nigel Smart 为在 MPC 环境中使用而设计了类似的电路。该实现是使用 TFHE-rs 的布尔 API 完成的。
基准测试结果最终确定了最终排名:
- 🥇 sharkbot:每 2 秒 约 1 个 FHE AES 加密(在 14 秒 密钥扩展之后)
- 🥈 tomtau:每 6 秒 约 1 个 FHE AES 加密(在 6 秒 密钥扩展之后)
- 🥉 allanbrodum : 每 3 秒 约 1 个 FHE AES 加密,但密钥扩展为 34 秒。
( 注意:Allanbrodum 的提交以明文形式执行 IV 递增,因此它不是全同态的。)
所有基准测试均在具有 192 个物理 CPU 内核的 AWS hpc7a.96xlarge 实例上运行。
结论
这个赏金赛季突出了硬件设计技术(例如高效的按位电路)如何显着改善 FHE 计算。该原理已经出现在 TFHE-rs 的某些部分(例如,我们的移位/旋转操作使用 barrel shifter),并且它仍然是一个有希望的优化领域。
它还展示了 TFHE-rs API 的灵活性。虽然新 稳定的高级 API 有效地涵盖了大多数通用整数运算,但较低级别的访问仍然可以为 AES S-box 等特定用例释放额外的性能。
再次祝贺所有获奖者。第 Season 8 再见!
附加链接
- Star Zama 的 TFHE-rs GitHub 存储库 以支持我们的工作。
- 查看 Zama 的 TFHE-rs 文档。
- 在我们的 社区频道 上获得支持。
- 参与 Zama Bounty Program 以获得现金奖励。
阅读更多相关帖子
未找到项目。
- 原文链接: zama.ai/post/implement-f...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~






{kind=link}
{kind=link}