Sunnyside Devnet更新 - 03/18
- testinprod
- 发布于 2025-03-25 19:45
- 阅读 1413
本文总结了Sunnyside在Pectra和PeerDAS devnet上进行的三项测试的更新。
概述
对于具有 20% 节点带宽受限(100Mbps / 50Mbps)的 pectra devnet,网络可以安全地处理 15 个 blobs
对于具有 18 个 fullnode、16 个 supernode、8 个 custody 要求的 peerdas devnet,
网络可以处理每个区块 10 个 blobs。
对于具有带宽受限节点的 pectra devnet,
当 blobs 的范围在 0-50 之间时,网络使用率大多保持在 50Mbps 以下
非带宽限制节点可以正确地提议/推进链
lodestar 具有更高的区块传播时间
背景
Sunnyside 在过去一周进行了 3 项测试:
运行具有不同带宽限制的节点 Pectra devnet,以识别与带宽相关的任何瓶颈
运行具有不同带宽限制的节点 Pectra devnet,并确定哪个 blob 计数对网络是可持续的。
运行 PeerDAS devnet,并发送 fuzzed blob 交易,直到网络不健康。
使用 spamoor 工具对其 blobs 场景进行 blobs 模糊处理
测试 1
执行了与上周相同的测试,但具有不同的带宽限制:
| 带宽限制节点 | 基线 | 测试 A | 测试 B | 测试 C |
| 无限制 | 52 | 40 | 40 | 40 |
| 150 Mbps | 0 | 12 | 6 | 0 |
| 100 Mbps | 0 | 0 | 6 | 6 |
| 50 Mbps | 0 | 0 | 0 | 6 |
带宽限制大于通常被称为“家庭质押者”带宽的 20Mbps,因为我们开始假设这些节点的网络容量也将增加。
带宽应用于节点中运行的特定容器,而不是整个节点。 这适用于信标和执行两个容器
Shell
Copy
execution\_container\_id=$(docker inspect execution -f '{{.State.Pid}}')mkdir -p /var/run/netns
ln -sfT /proc/$execution\_container\_id/ns/net /var/run/netns/execution
ip netns exec execution ip -br -c link
tc -n execution qdisc add dev eth0 handle 10: root tbf burst 32kbit rate {{ bandwidth }}mbit latency 100ms结果
首先,当我们查看整个测试过程中的区块时间时,我们可以看到网络随着我们从测试 A 移动到 C 而变得更加不稳定:
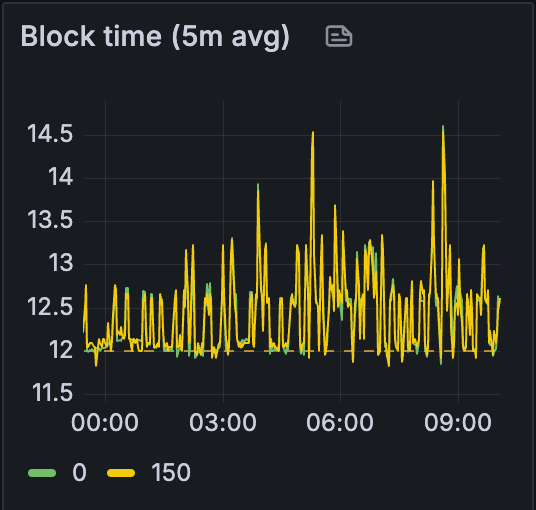
测试 A
ALT
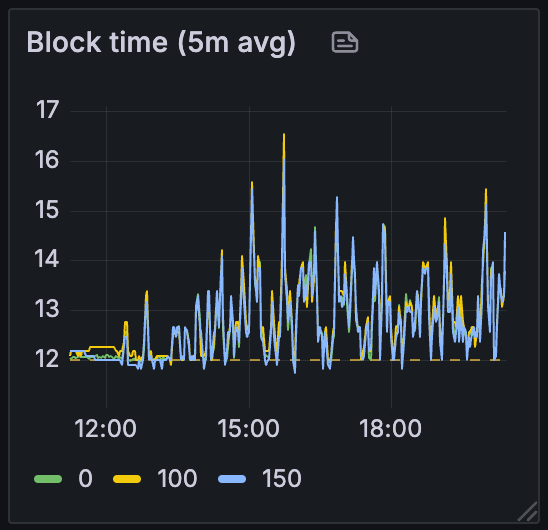
测试 B
ALT
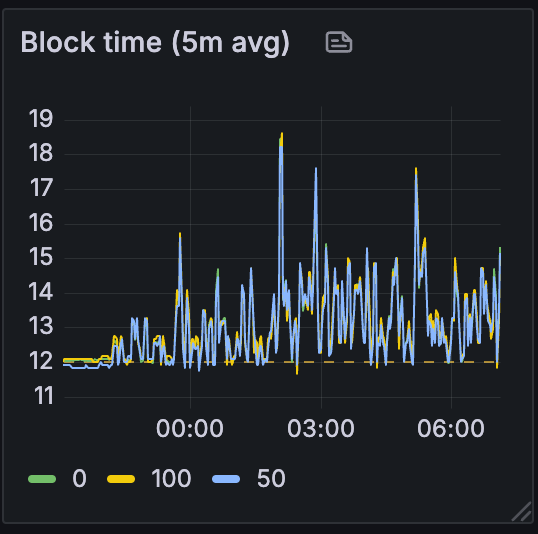
测试 C
ALT
为了简单起见,我们将使用基线和场景 C 来比较测试结果。
基线
ALT
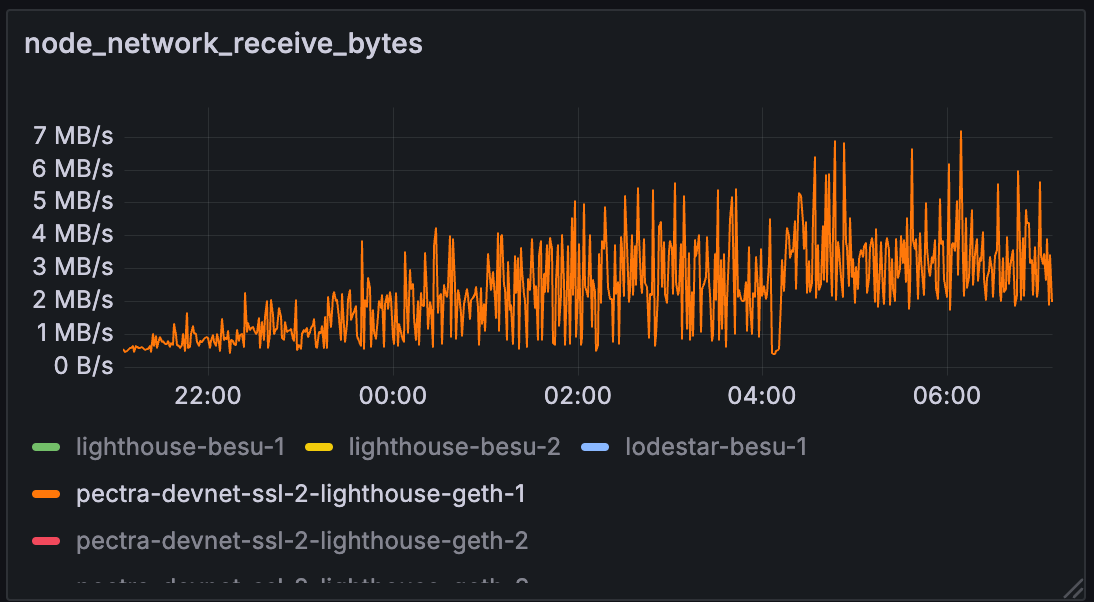
测试 C
ALT
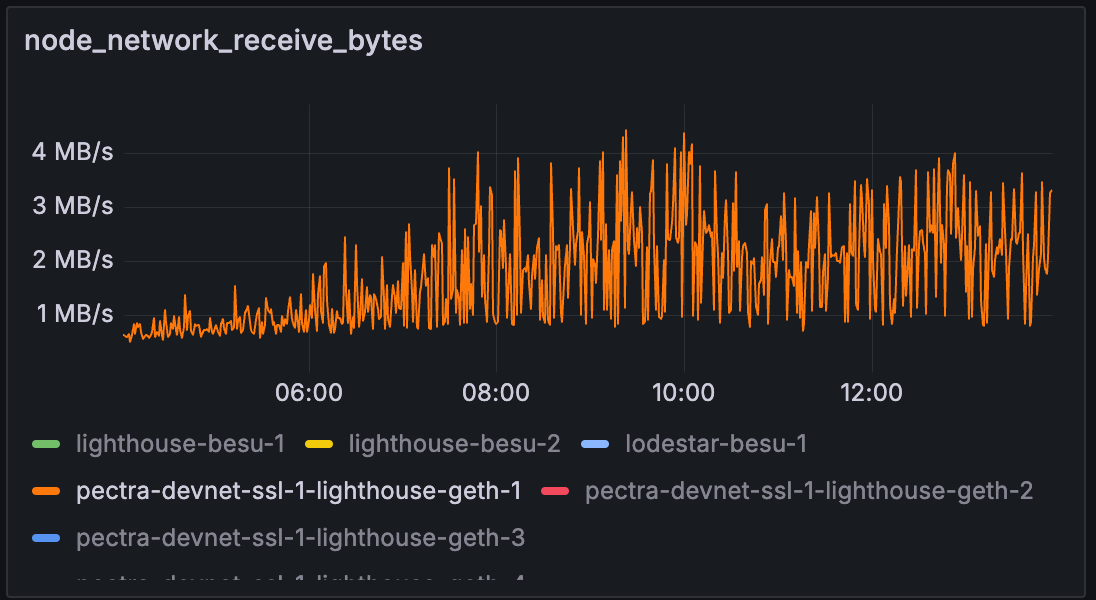
在测试 C 中,lighthouse-geth-1 的带宽限制为 50Mbps,相当于大约 6.25MB/s。
我们可以看到,整个测试过程中的网络使用率都保持在带宽限制附近。 一个异常是测试 C 中的网络使用率实际上更高。
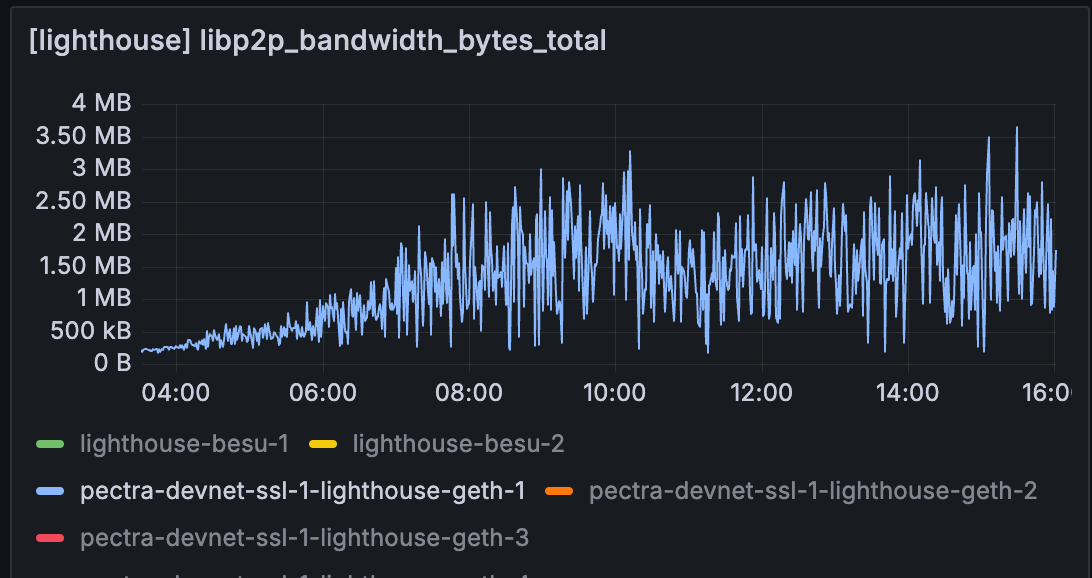
基线
ALT
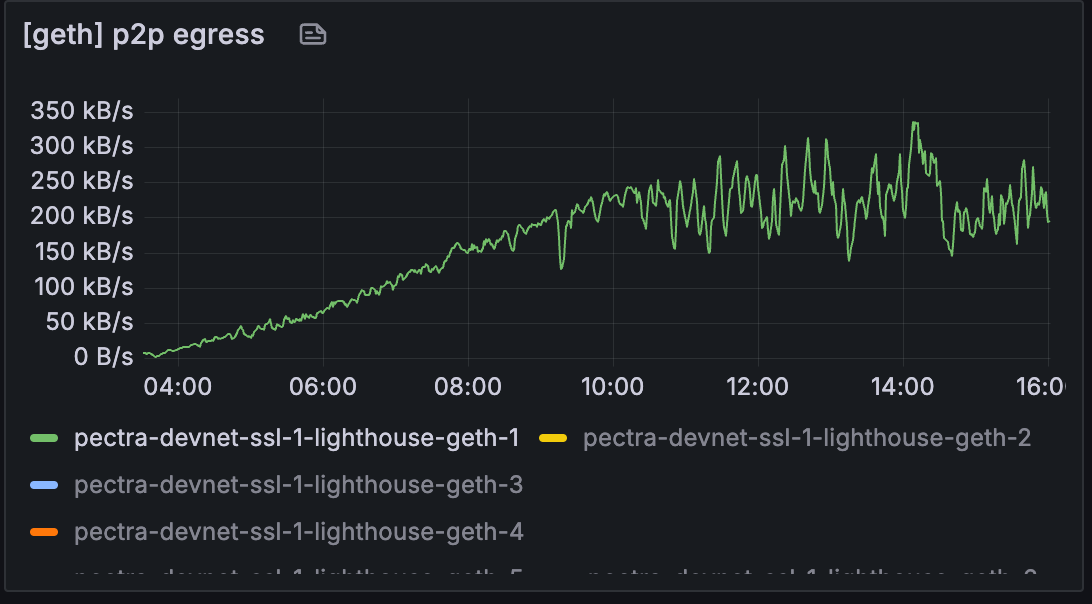
基线
ALT
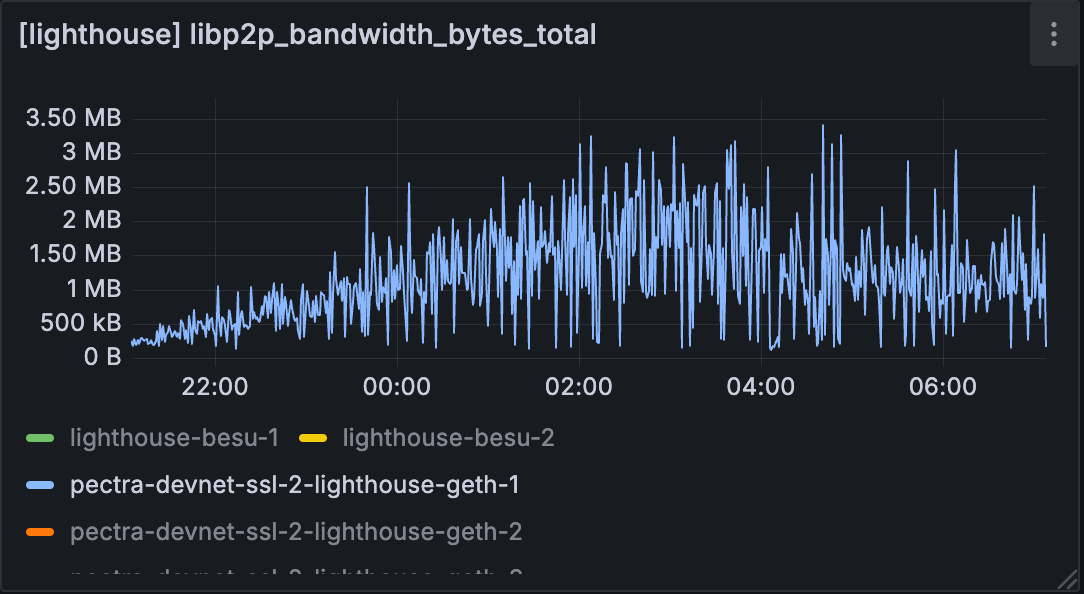
测试 C
ALT
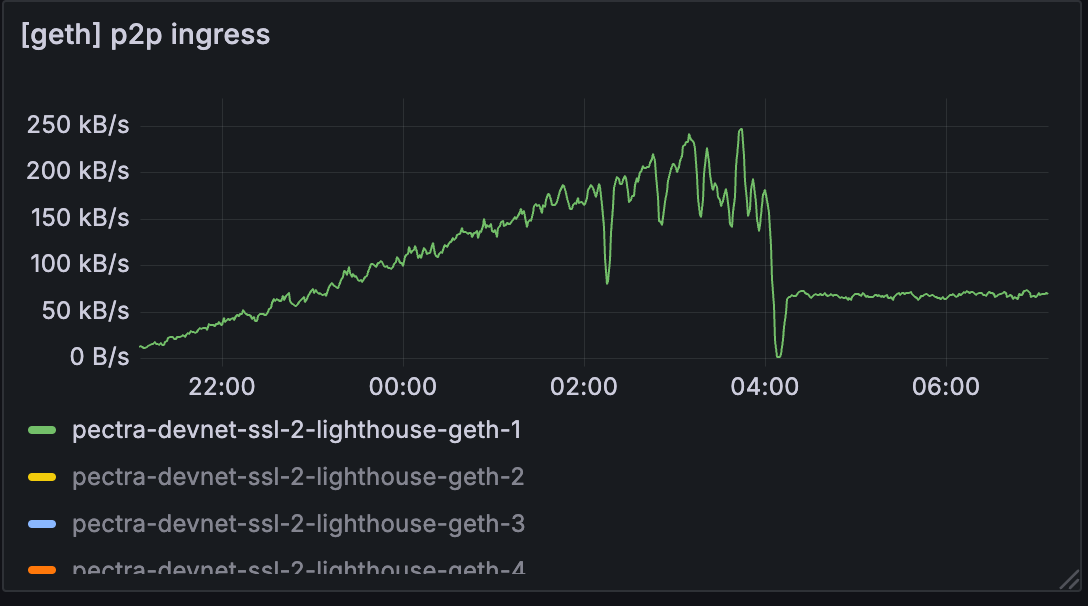
测试 C
ALT
但是,当我们查看 lighthouse 或 geth 的实际使用情况时,使用量仍然略低。 节点的整体带宽可能会受到其他程序使用的影响。 但是,我们将进一步研究为什么带宽限制节点的节点带宽更高。
基线
ALT
基线
ALT
测试 C
ALT
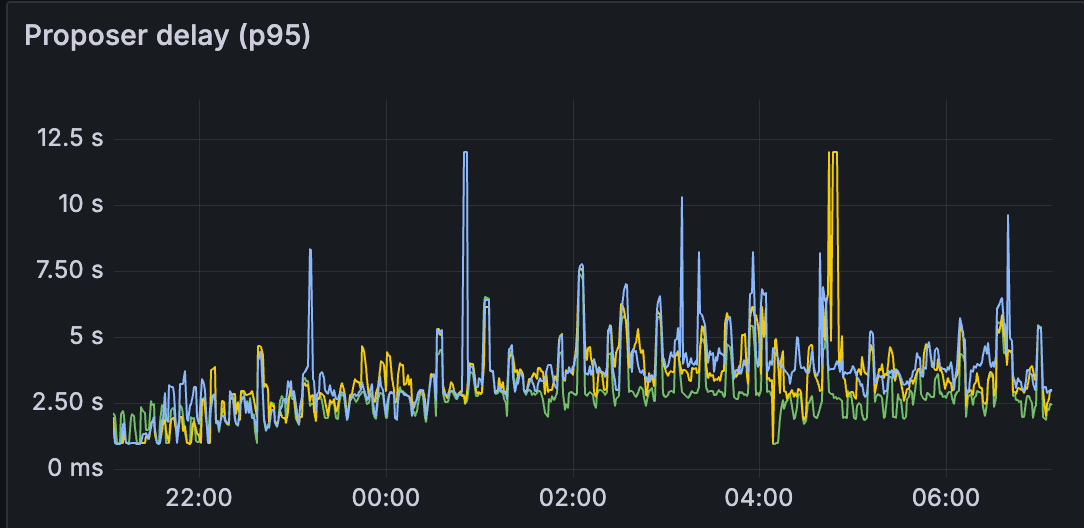
测试 C
ALT
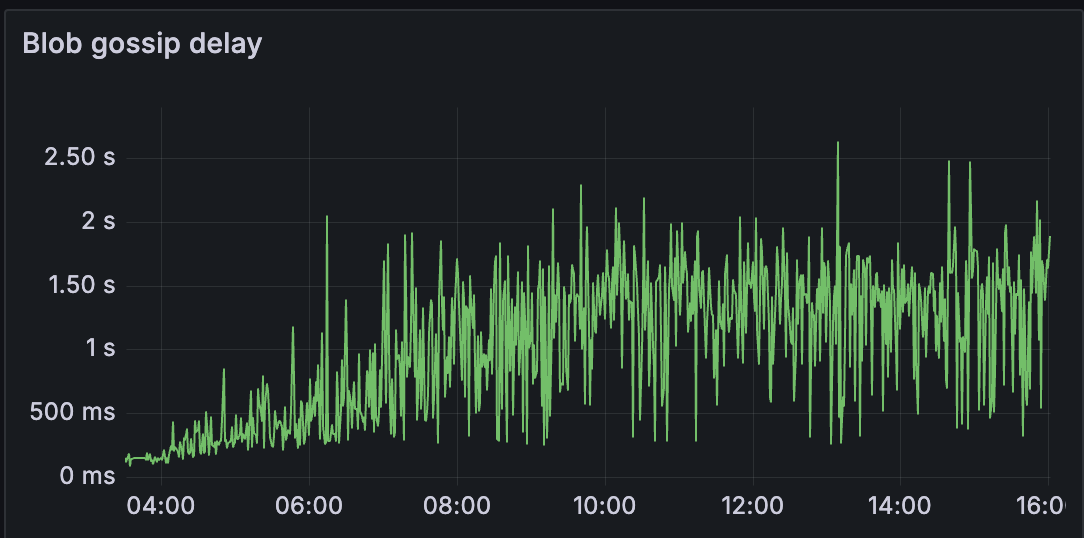
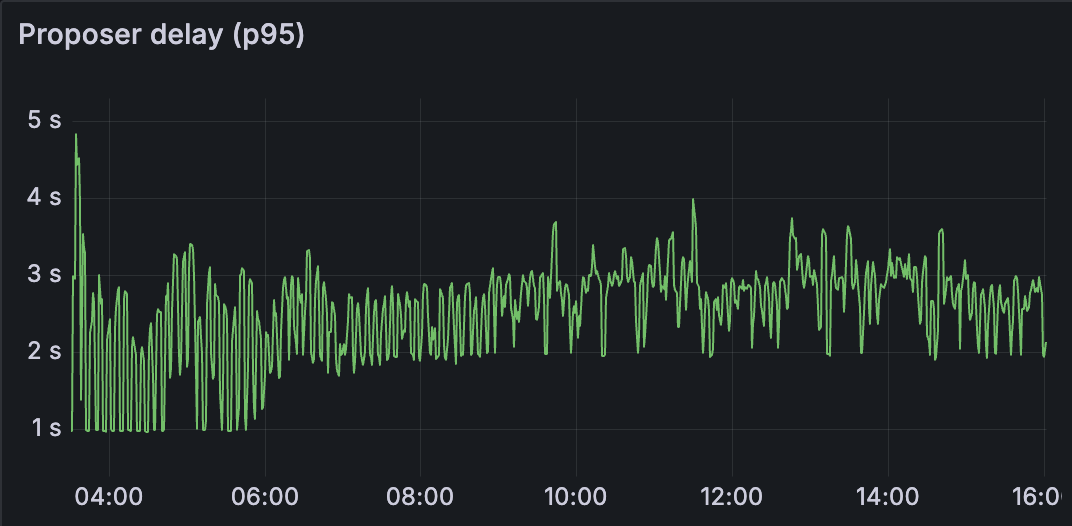
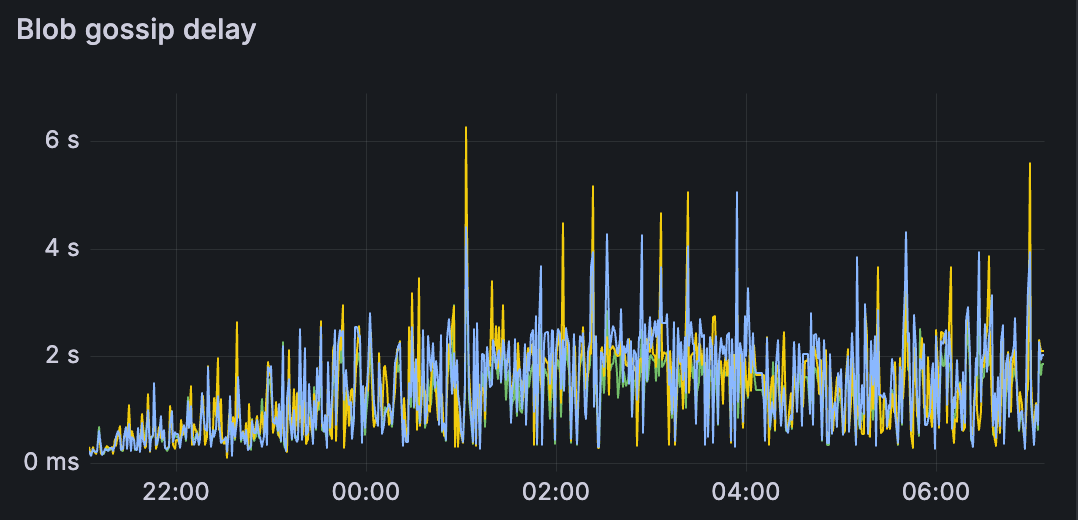
我们可以观察到,对于测试 C,其他指标(如 blob gossip 延迟和 proposer 延迟)明显更高。 这会影响网络的区块时间和整体健康状况。
发现
错过 Proposers
在基线测试中,没有 proposer 未能提议区块的 slot。
在测试 C 中,我们确定了未能提议/将区块包含到链中的验证器索引列表。
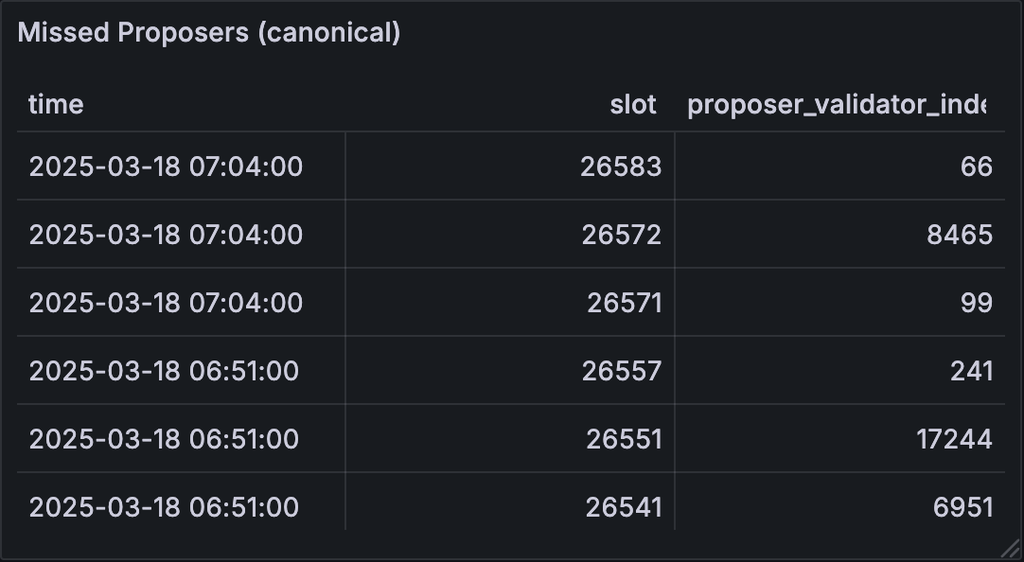
在总共 207 个错过的 slot 中,202 个来自带宽限制的 proposer,而只有 5 个来自非限制节点。
由于 20% 的节点具有带宽限制,因此网络能够处理非限制节点之间的新区块;只有限制节点无法提议。
GetBlob 命中率
在整个测试过程中,与其他客户端相比,geth 从 EL 获得的 blob 命中率明显更高。

测试 C
ALT
但是,geth 的 blob 命中率也下降了一次(04:00 之后)
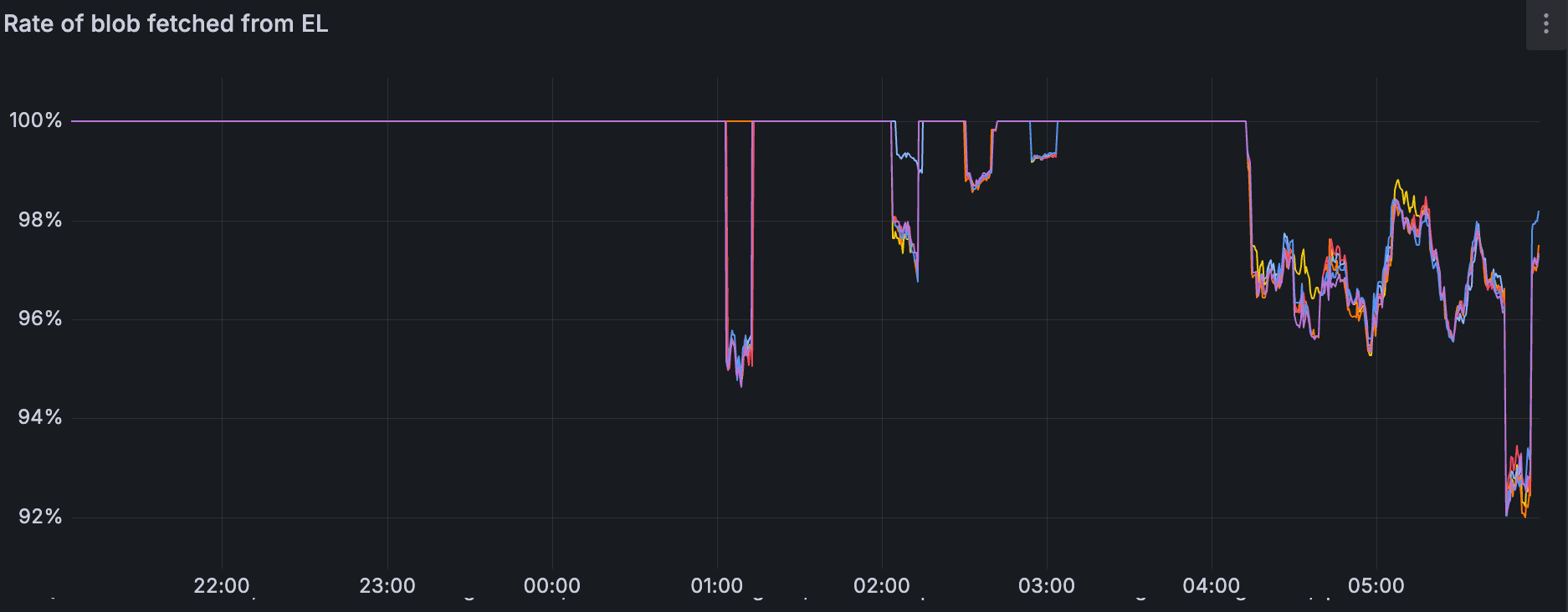
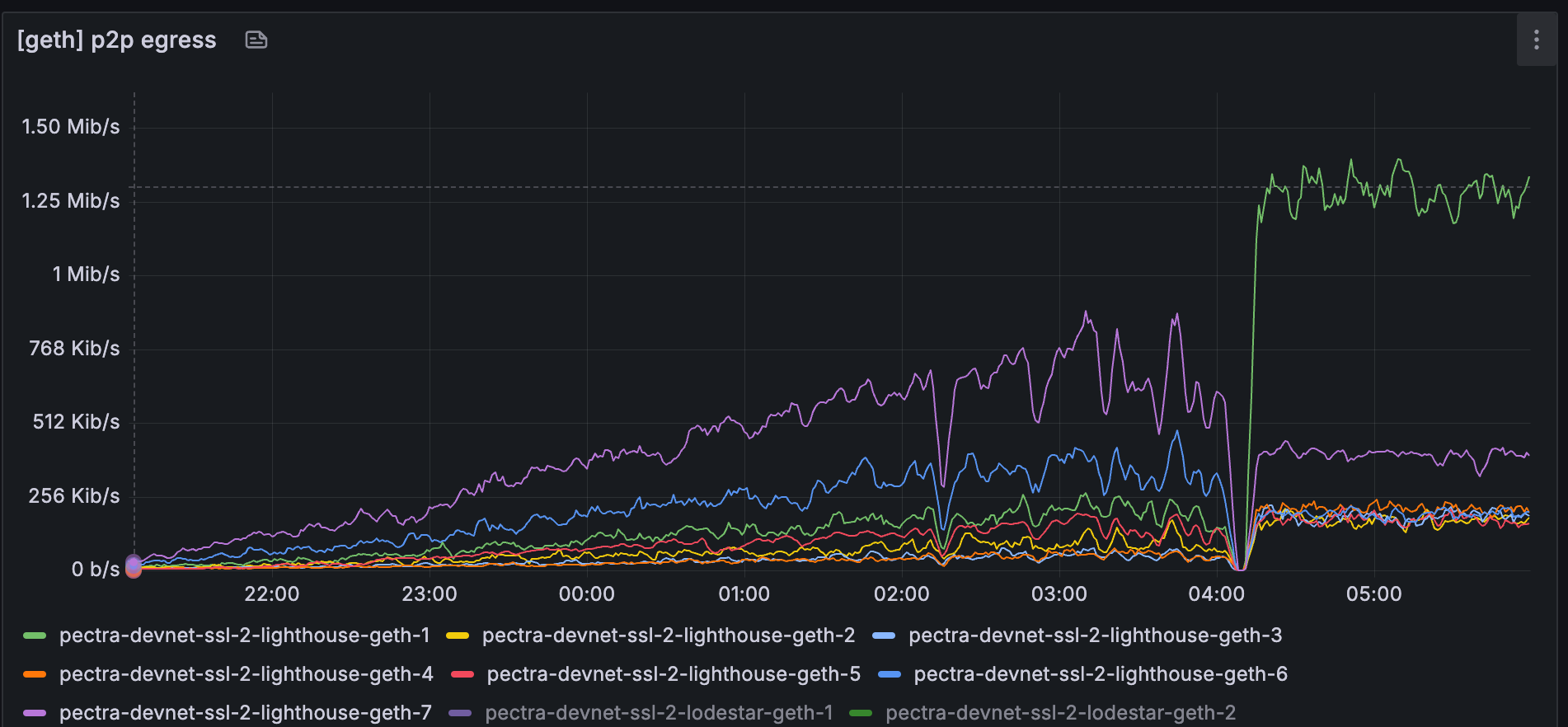
对于 lighthouse-geth-1,请注意它如何在 04:00~05:30 期间保持 100%。
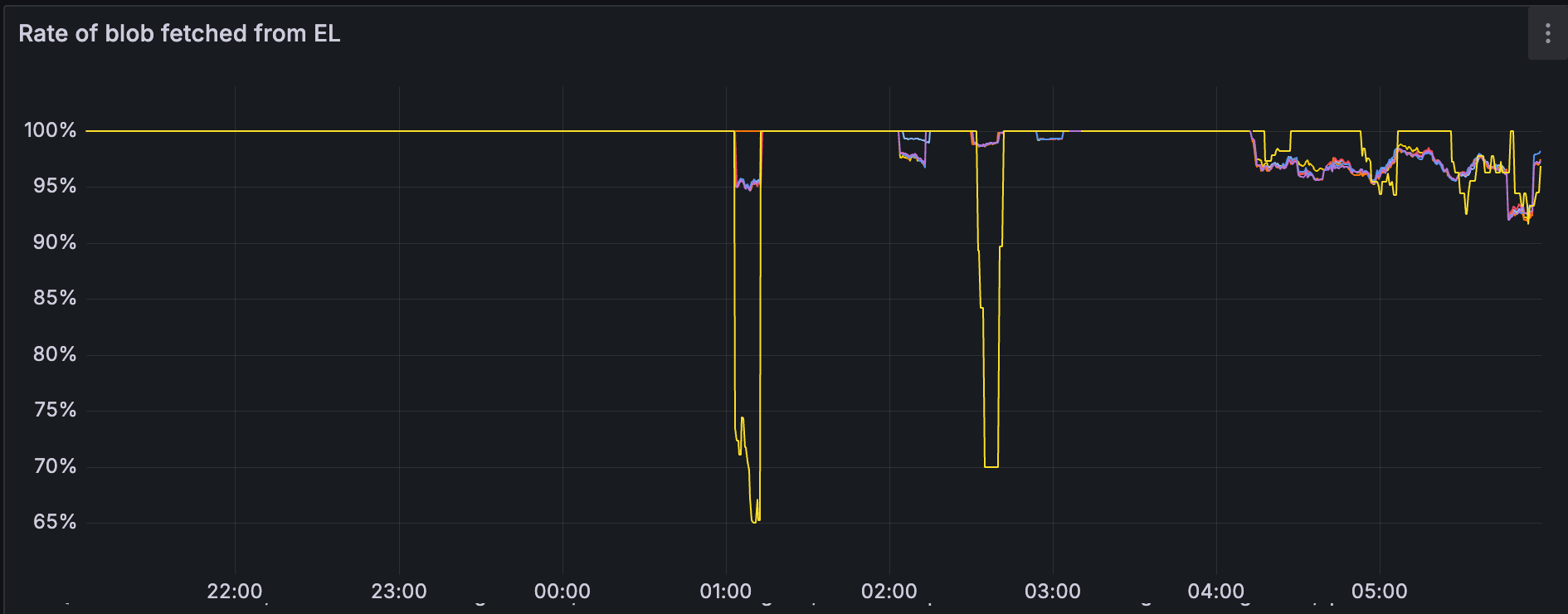
此时间范围对应于 lighthouse-geth-1 中 p2p 出口指标的增加。 我最初的假设是 p2p 入口可能与 blob 命中率有关,但我们看到与 blob 命中率相关的 p2p 出口率。
内存使用量
在整个测试 A、B 和 C 期间,节点都在长时间运行。
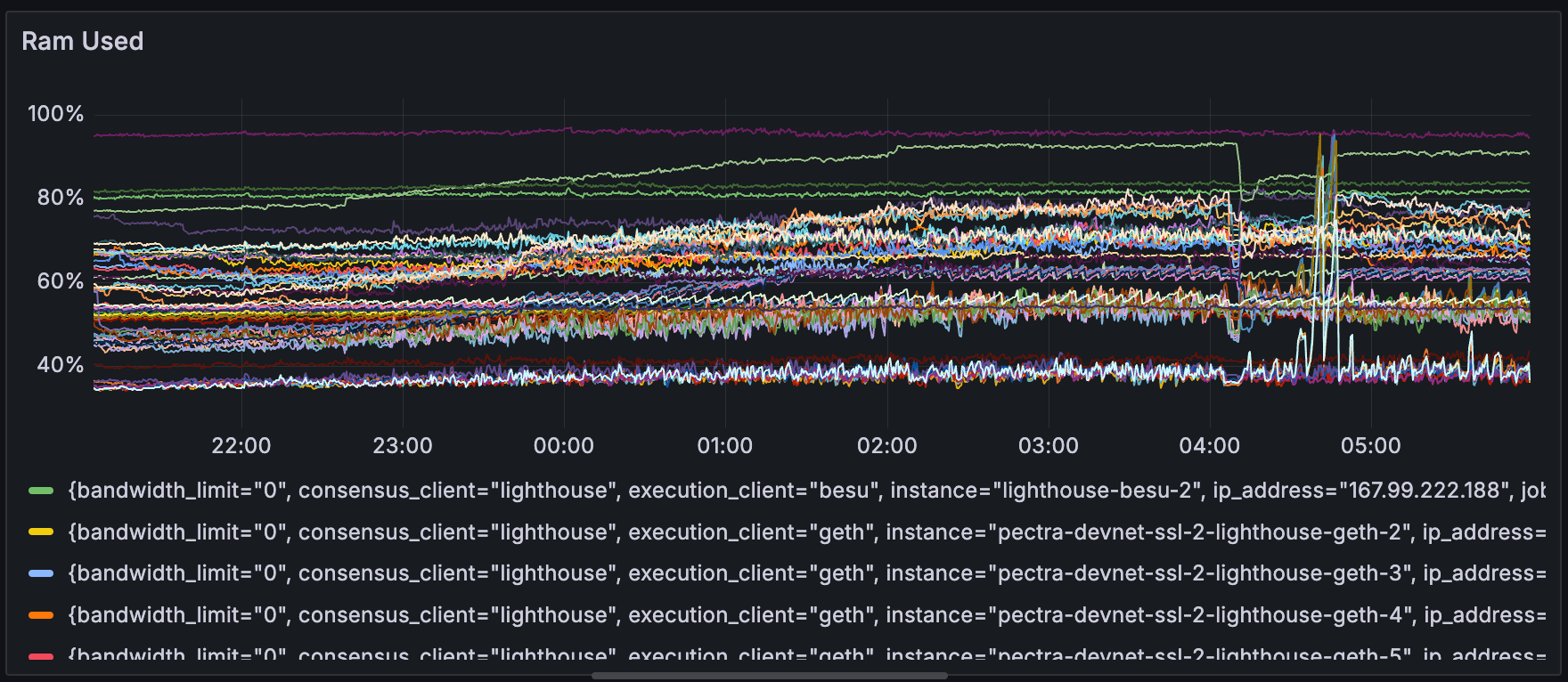
这导致一些节点具有很高的内存使用率,而与 blob 计数无关。 这可能表明存在泄漏或未清理的内存。 需要进一步测试以确定内存使用率是否在这些测试中发挥了作用。
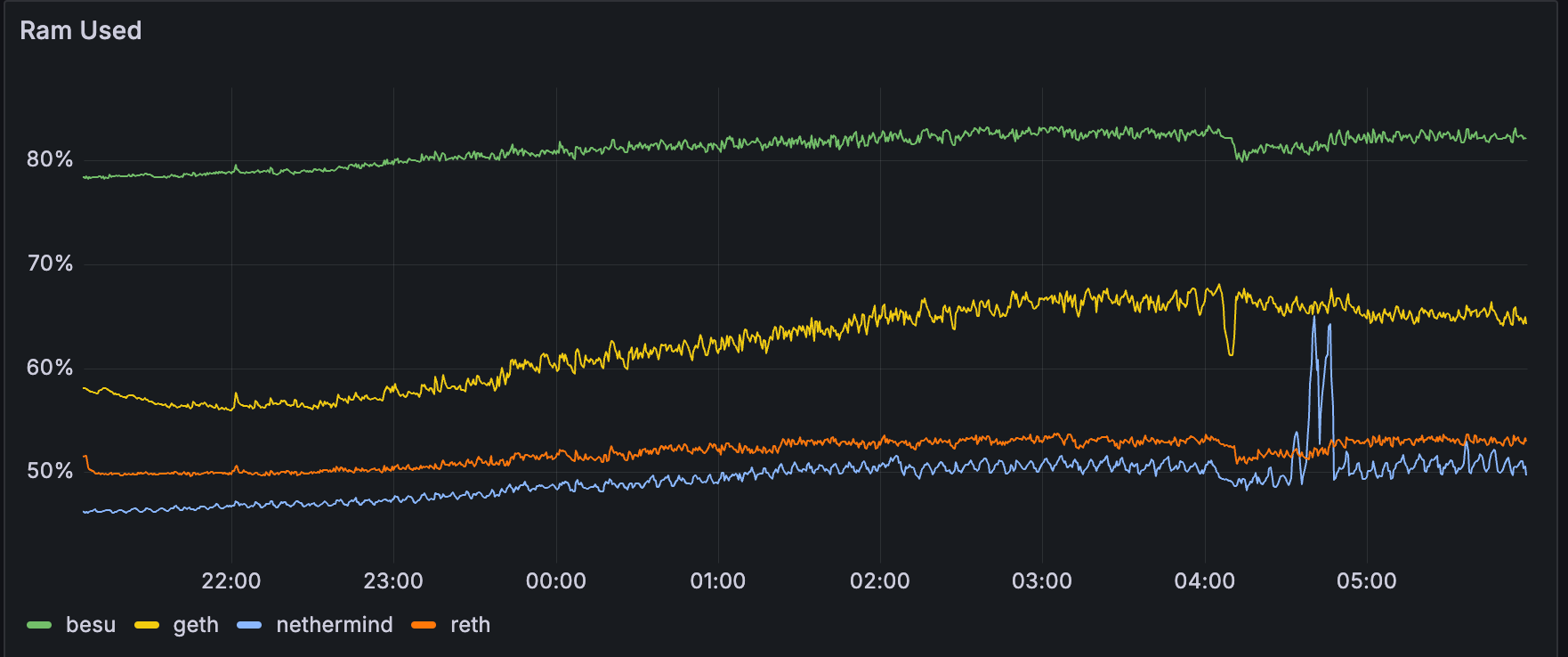
如果我们查看按执行客户端类型分组的指标,我们可以看到与其他客户端相比,besu 的内存占用量明显更大。
Lodestar 区块传播时间
我们从 xatu 数据中导出了每个客户端的区块传播时间。
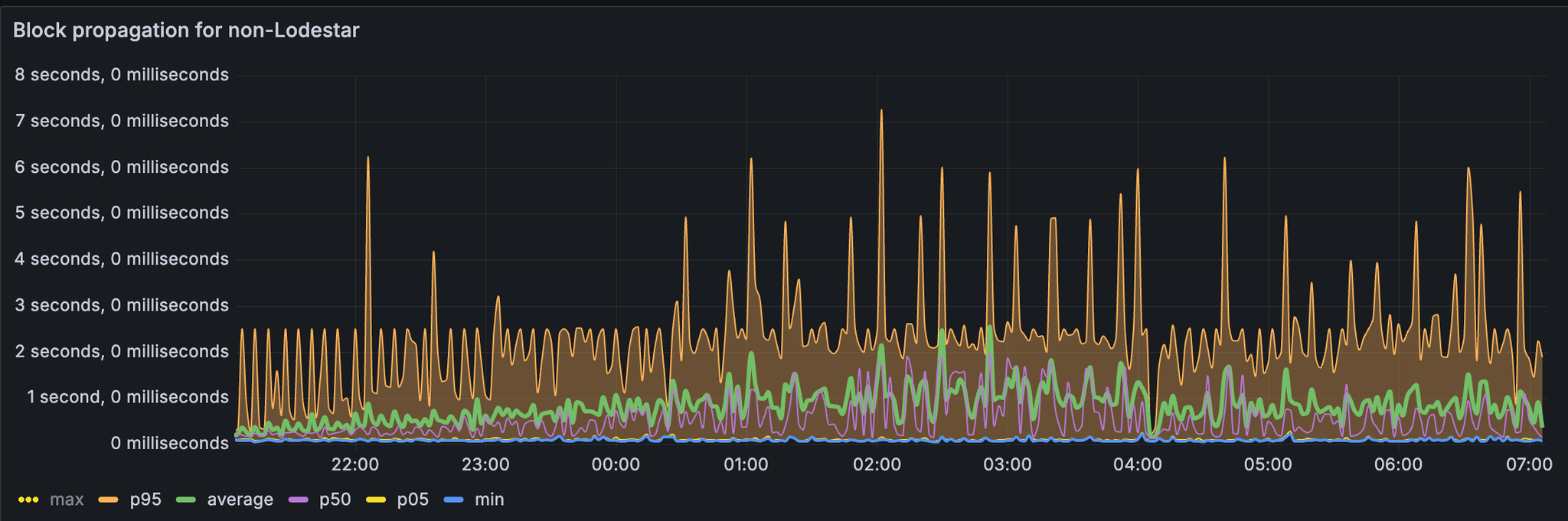
对于非 lodestar 节点,我们可以观察到大多数 p95 都适合在 4 秒内。
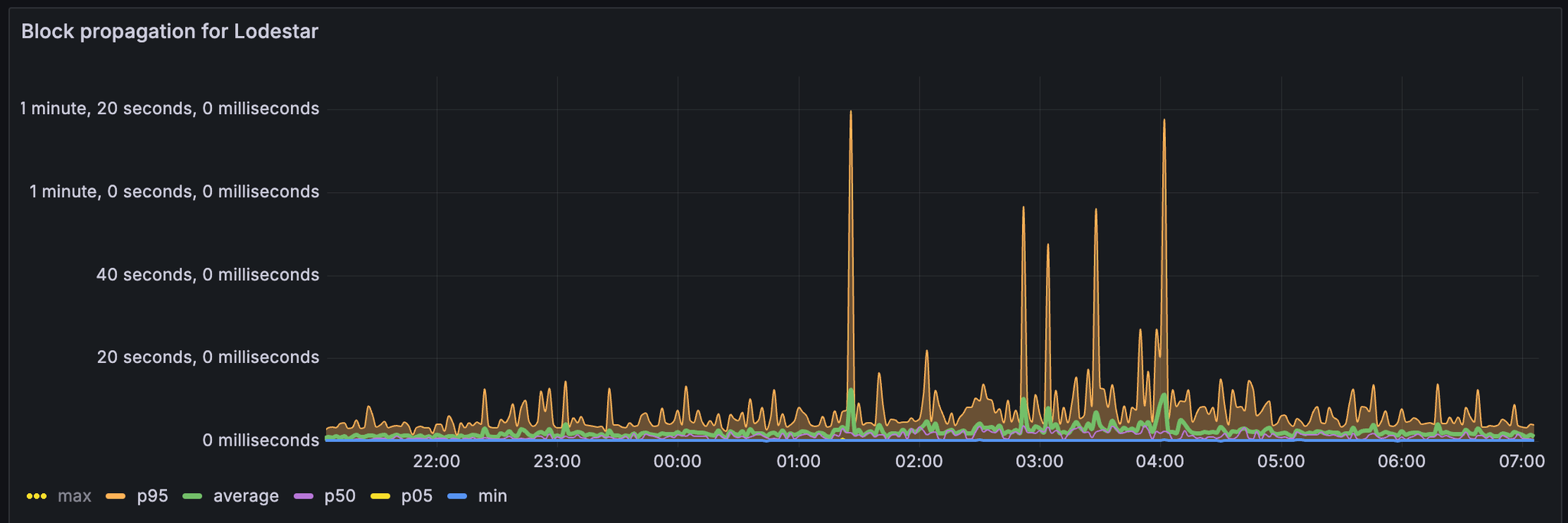
对于 lodestar,p95 和平均值具有更高的异常值,有时会超过 1 分钟。
测试 2
我们使用条件 C 进一步测试,以确定 pectra devnet 可以处理的稳定数量的 blobs。
结果
我们从每个区块 35 个 blobs 减少到 15 个 blobs。
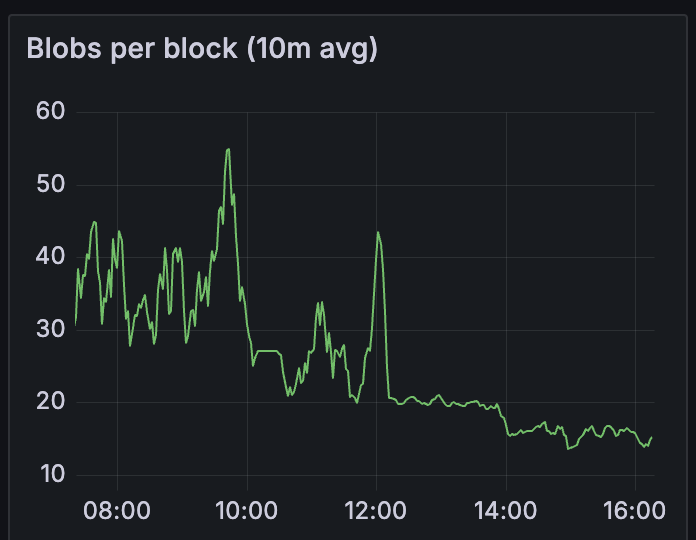
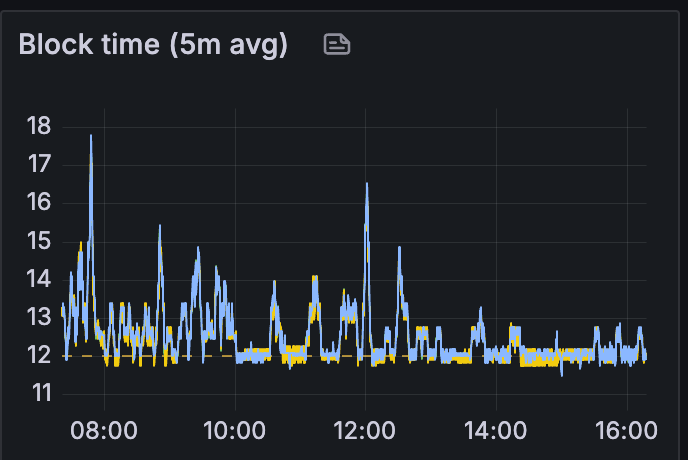
衡量网络健康状况的最简单方法是区块时间:我们观察到区块时间稳定在每个区块 15~20 个 blobs 左右。
这也在其他指标中显示出来:(请参阅 12:00 至 16:00)
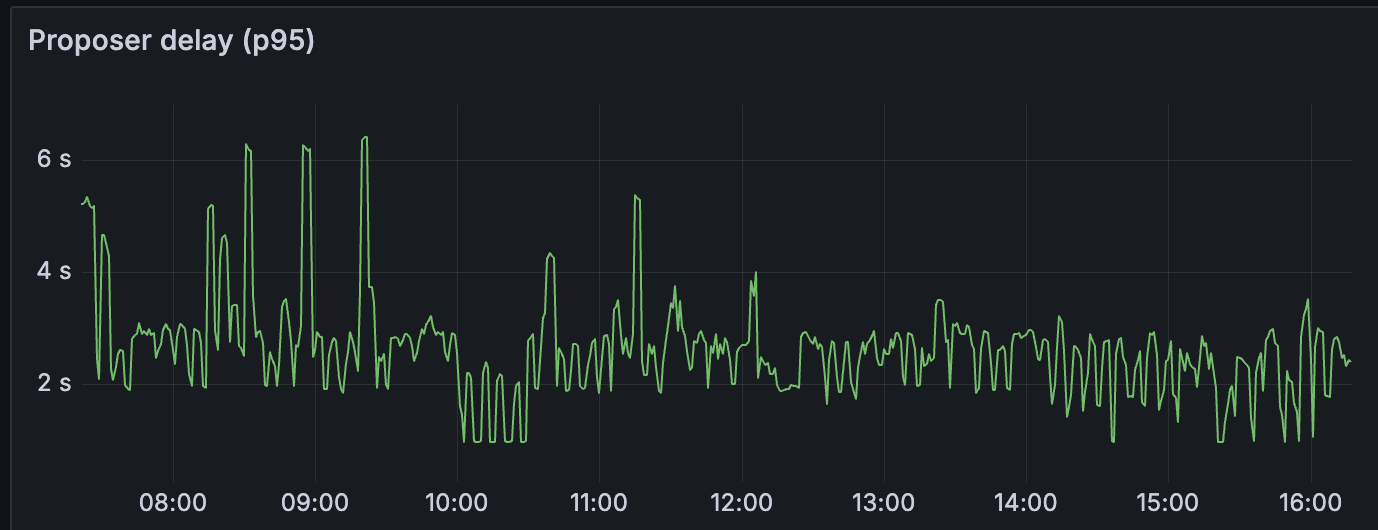
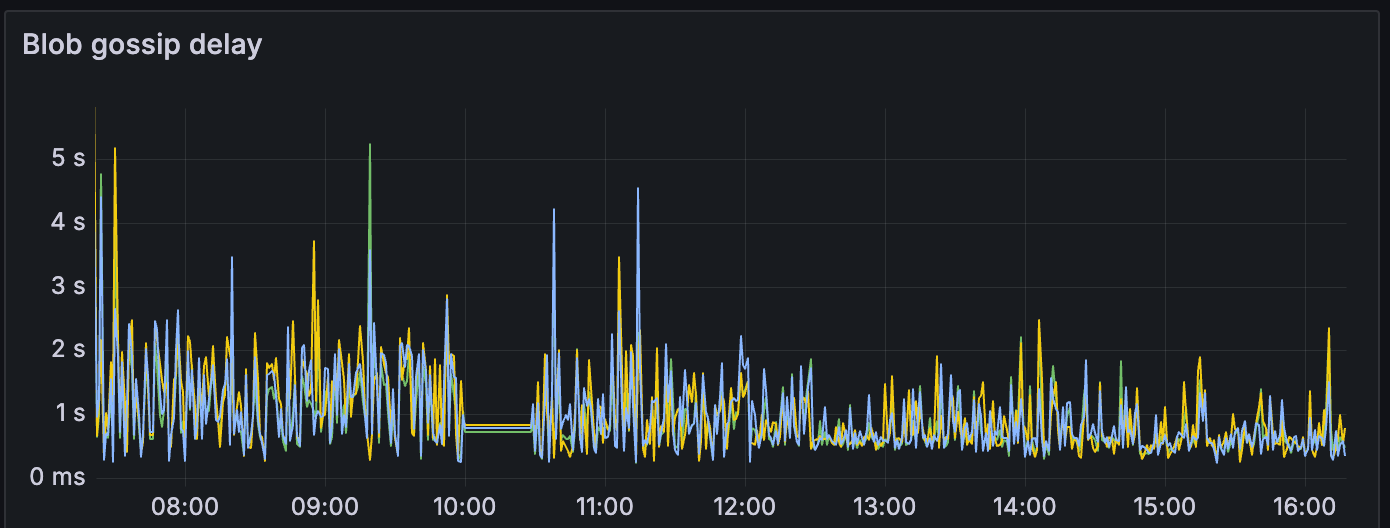
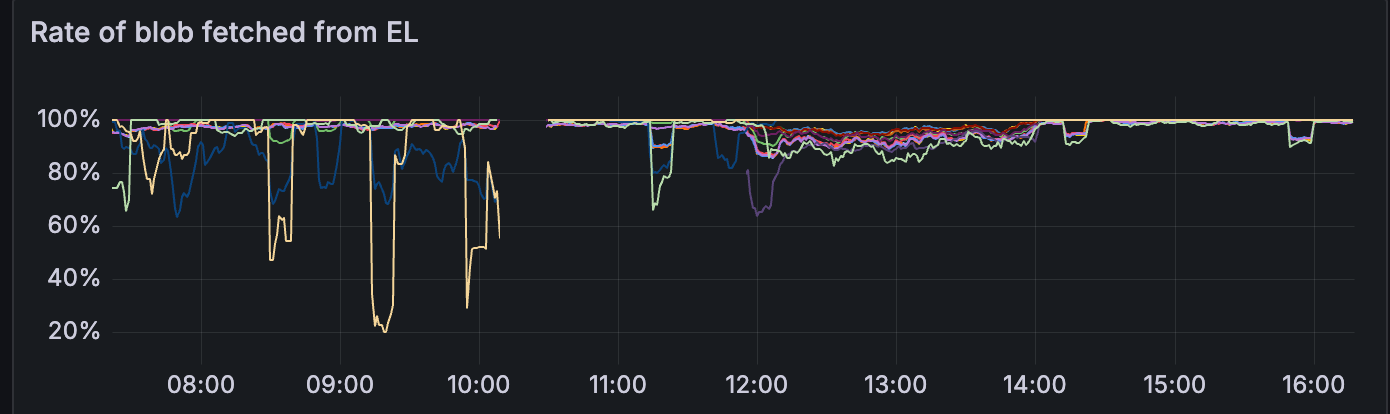
请注意指标在 12:00 之后如何稳定,这是我们开始发送每个区块 15 个 blobs 的时间。
因此,我们测试了 pectra devnet 在每个区块 15 个 blobs 的情况下是健康的,其中
10% 的节点带宽限制为 100 Mbps
10% 的节点带宽限制为 50 Mbps
测试 3
在此测试中,我们旨在确定当前 peerDAS 实现可以处理多少个 blobs。
我们使用了以下配置:
JavaScript
Copy
exportDATA\_COLUMN\_SIDECAR\_SUBNET\_COUNT=128exportSAMPLES\_PER\_SLOT=8exportCUSTODY\_REQUIREMENT=8// increased from default due to small network sizeexportMAX\_BLOBS\_PER\_BLOCK\|ELECTRA\|FULU=72exportTARGET\_BLOBS\_PER\_BLOCK\|ELECTRA\|FULU=48网络参与者:-16 个超级节点 -18 个完整节点
我们向网络发送 blob 交易,从 1 开始,每 10 分钟增加一个 blob。
结果
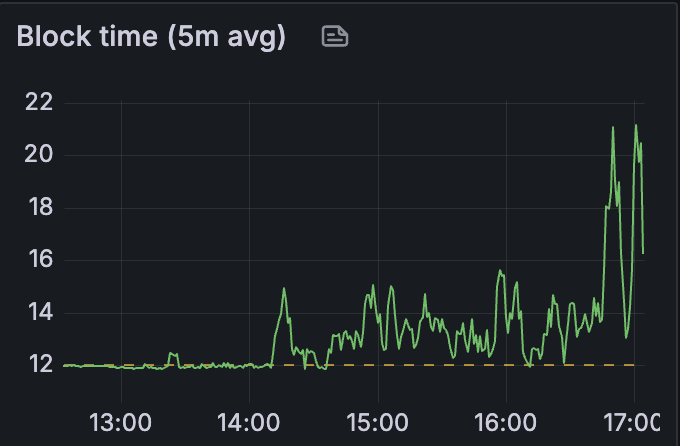
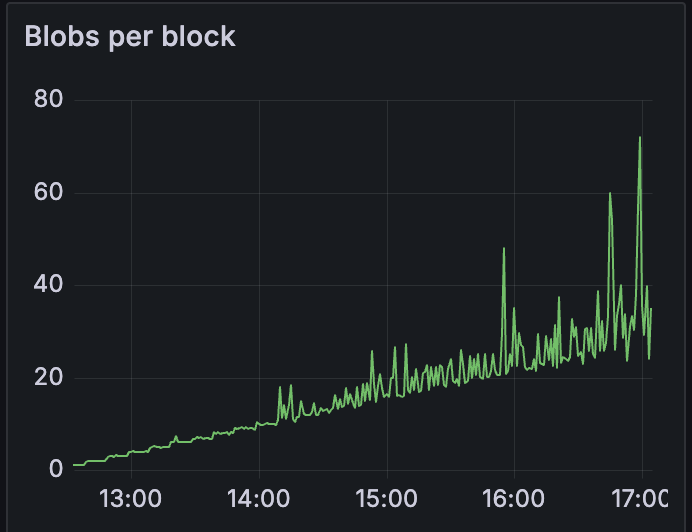
我们发现网络在 blob 计数超过 10 之前是健康的
请参阅以下指标,这些指标展示了 14:00 之后的网络状态。
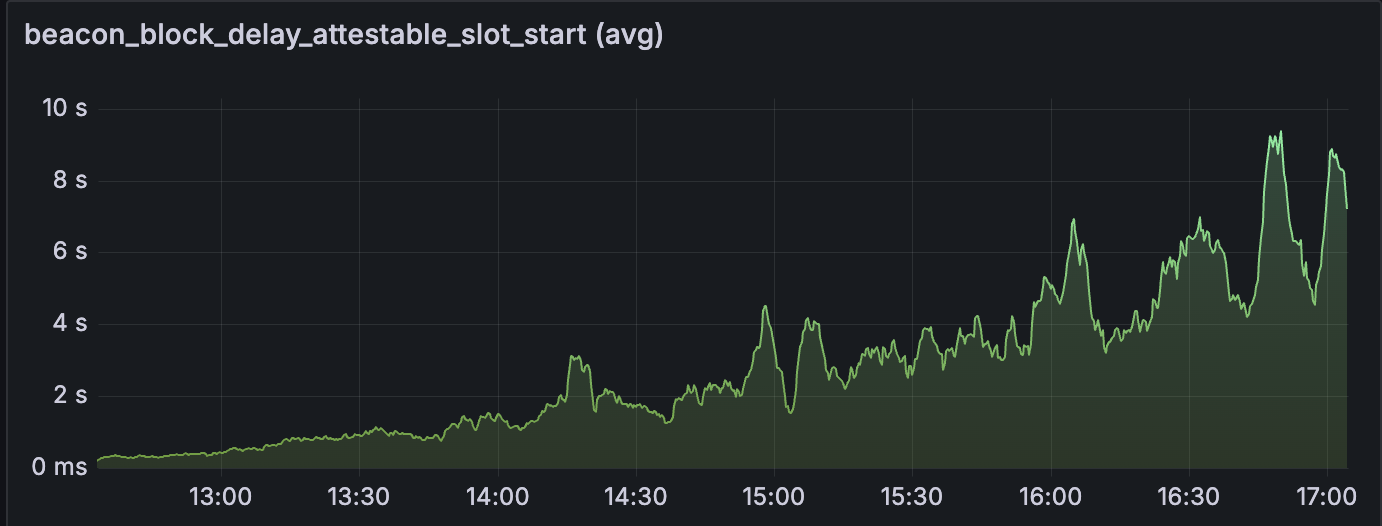
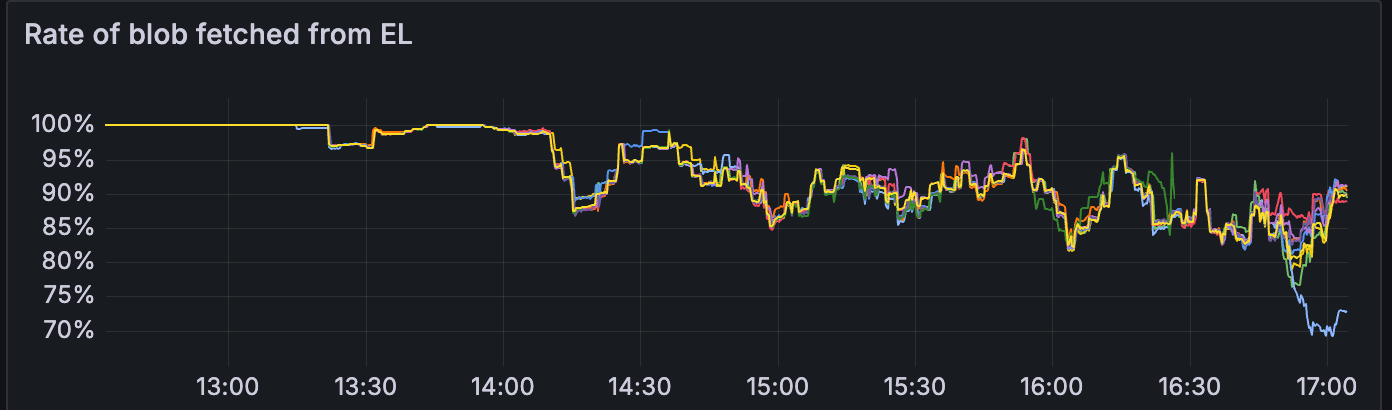
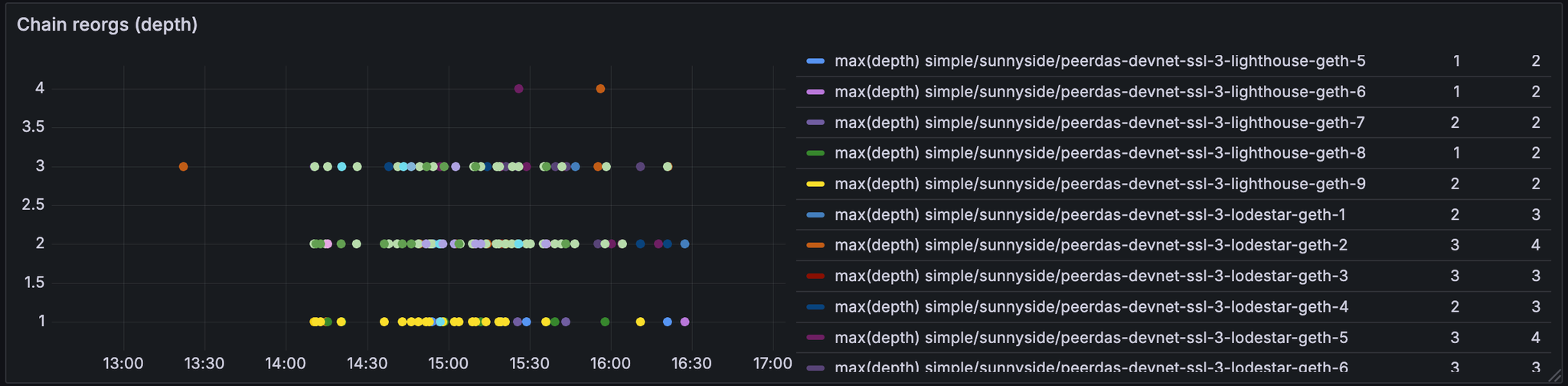
发现
数据列 sidecar 验证
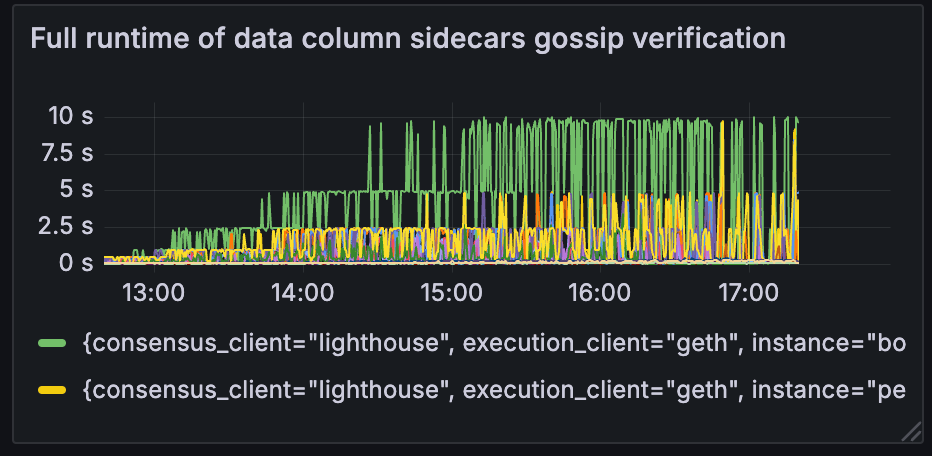
当 blobs 吞吐量超过 10 个 blobs 时,数据列 sidecar gossip 验证增加超过 4 秒。
我们需要更多与 peerdas 性能相关的指标:grafana
我们的下一个目标是确定哪些指标与 peerDAS 无法保管更多 blobs 相关。
Grandine
我们使用各种配置运行了 peerDAS devnet。
一项测试运行包含两个 grandine-geth 客户端。 在相同的测试条件下,与其他客户端不同,grandine-geth 对无法跟上网络。
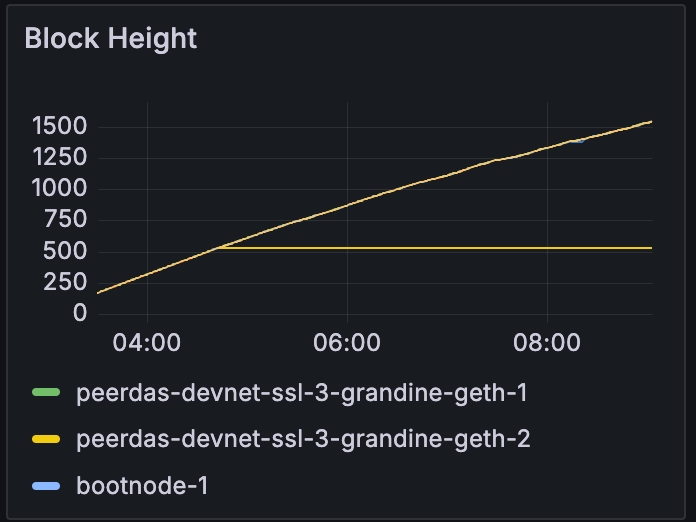
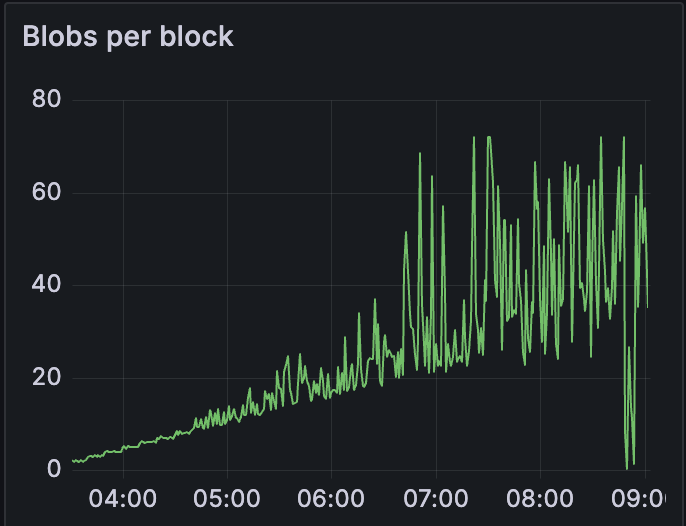
在相似的 blob 计数 (~10) 下,grandine-geth 节点停止跟随网络。
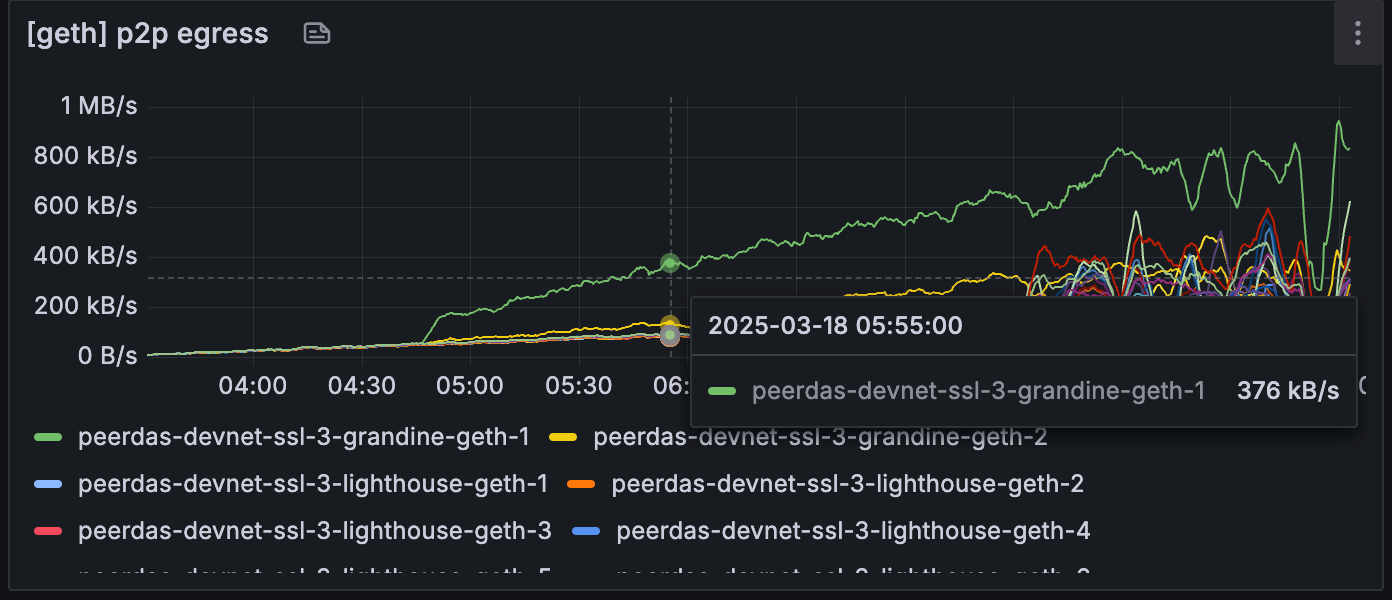
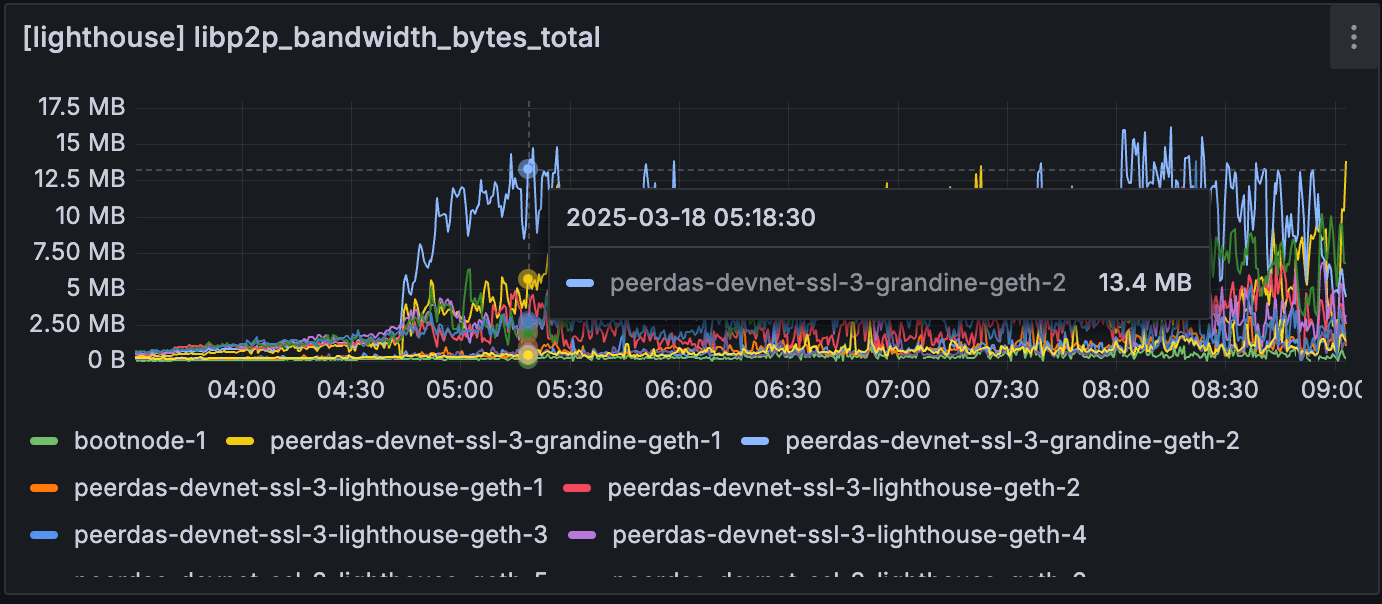
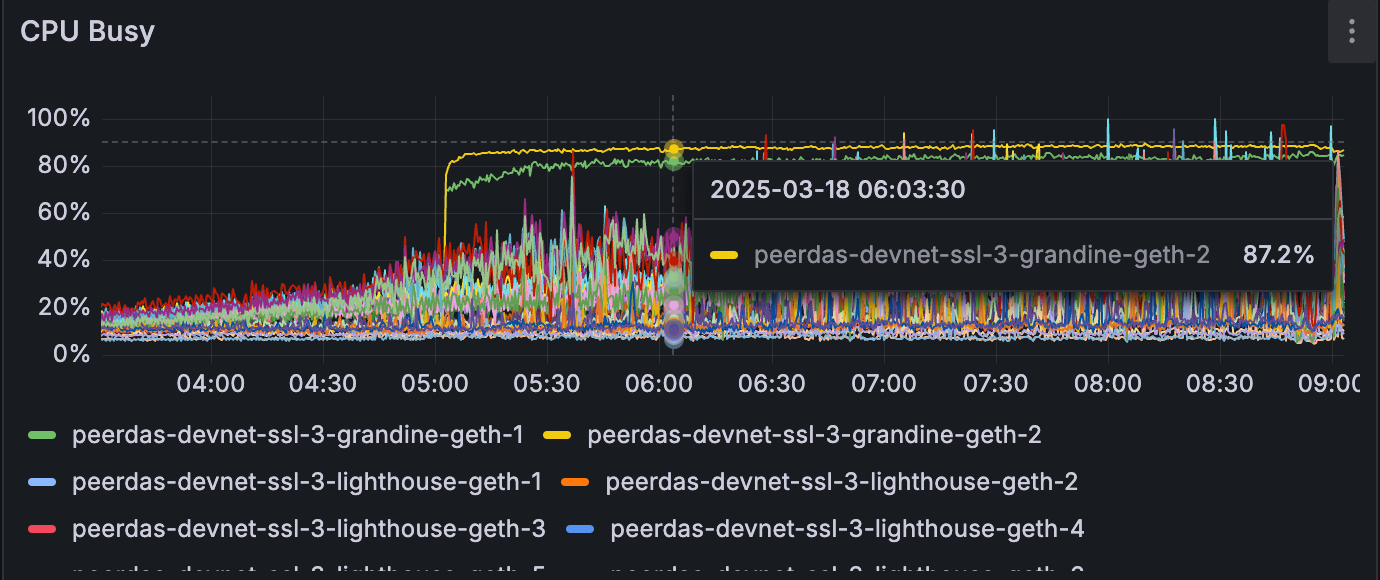
但是,Grandine 节点开始使用明显更多的网络/CPU 资源,即使它没有进展。 这可能是由于 grandine 努力将节点恢复到头部,但需要调查才能找出它无法恢复的原因。
下一步
我们的下一个目标是对上述发现进行根本原因分析:为什么 peerdas devnet 在 10 个 blobs 之后无法跟上,并找出失败点在哪里。
我们还将开始运行更多随机配置的 peerdas,看看网络如何/在哪里会失败,并希望带来一些分析。
- 原文链接: testinprod.notion.site/S...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





