如何像量化交易台一样模拟每个模型,每个公式,可运行代码
- gemchange_ltd
- 发布于 17小时前
- 阅读 140
本文详细阐述了如何构建机构级的预测市场模拟引擎,从蒙特卡洛方法的基础讲起,逐步引入重要性采样、序列蒙特卡洛、方差缩减技术和尾部依赖建模(如Copula),最后介绍代理人模型和完整的生产级系统架构。文章旨在提供可运行的代码以实现每个技术层。

如何像量化交易台一样模拟。每一个模型,每一个公式,可运行的代码。
- 这不是一个技术列表。
这是一个故事——一个从抛Coin开始,以机构级模拟引擎结束的故事。
每个部分都建立在前一个部分之上。跳过任何部分都可能导致数学内容无法理解。按顺序阅读,到最后你将获得堆栈每一层的可运行代码。
免责声明:非财务建议,请自行研究
第一部分:颠覆一切的抛Coin
你正盯着一份Polymarket合约。“美联储会在3月降息吗?”“是”的交易价格是$0.62$。
你的直觉是:那是一个$62\%$的概率。也许你认为它应该是$70\%$。所以你买入。
恭喜你。你刚刚做了每个散户交易员都会做的事情。你把一个预测市场合约当作一个已知偏差的抛Coin游戏,估算了你自己的偏差,并下注于差额。
-
你不知道你对$70\%$的估计有多大信心。
-
你不知道明天的就业报告发布后,它应该如何变化。
-
你不知道它与Polymarket上其他六份与美联储相关的合约是如何关联的。
-
你不知道从现在到结算之间的价格路径是否能让你即使最终正确也能获利退出。
抛Coin只有一个参数:$p$。
一个嵌入在相关事件投资组合中的预测市场合约,具有时变信息流、订单簿动态和执行风险,则有几十个参数。
第二部分:蒙特卡洛。一个不被足够重视的基础
本文中的每个模拟最终都归结为蒙特卡洛:从分布中抽取样本,计算统计量,重复。
事件概率 $p=P(A)$ 的估计量就是样本均值:
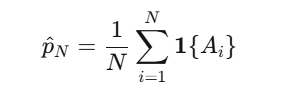
中心极限定理给出了收敛速度:$O(N^{-1/2})$,方差为 $\text{Var}(\hat{p}_N)=p(1-p)/N$。
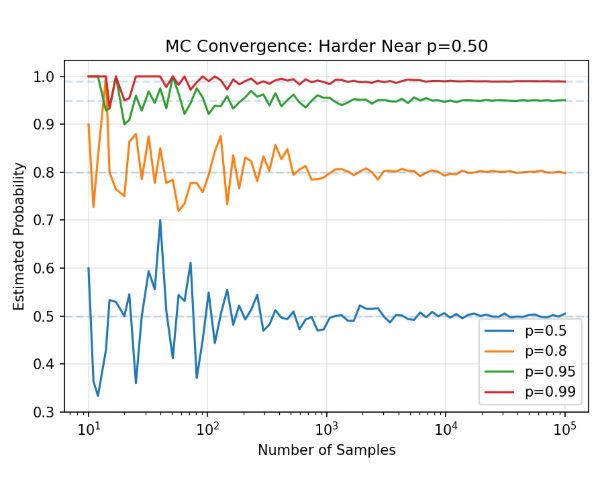
当 $p=0.5$ 时,方差最大。一个交易价格为50美分的合约,即平台上最不确定、交易最活跃的合约,正是你的蒙特卡洛估计最不精确的地方。
当 $p=0.50$ 时,要在 $95\%$ 置信度下达到 $\pm 0.01$ 的精度:
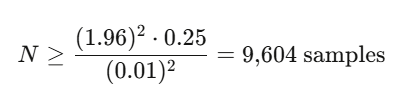
这还算可控。但当你需要模拟路径而不仅仅是终点时,情况会迅速恶化。
你的第一个可运行模拟
目标:估计一个与资产Hook的二元合约支付的概率(例如,“苹果公司股价在3月15日收盘时会高于$200$美元吗?”)
这有效。对于一份合约,一个标的资产,假设对数正态动态。真实的预测市场打破了所有这些假设。
评估你的模拟
在我们改进模拟之前,我们需要一种方法来衡量它的好坏。Brier Score 是标准的校准指标:
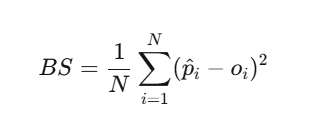
Brier score 低于 $0.20$ 算好。
低于 $0.10$ 则非常棒。
最好的选举预测者(538,Economist)在总统竞选中历史性地达到了 $0.06-0.12$ 的分数。
如果你的模拟能超越这个,你就有优势。
第三部分:当$100,000$个样本还不够时
现在故事升级了。
Polymarket 承载着极端事件的合约。“标准普尔500指数会在一周内下跌 $20\%$ 吗?” 交易价格为 $0.003$。使用 $100,000$ 个样本的粗略蒙特卡洛模拟,你可能只看到零次或一次命中。
你的估计要么是 $0.00000$ 要么是 $0.00001$ ——两者都毫无用处。
这并非一个理论问题。这就是大多数散户交易者无法正确评估尾部风险合约的原因。
让稀有事件变得常见
重要性采样(Importance sampling)用一个过采样稀有区域的概率测度替换原始概率测度,然后用似然比或Radon-Nikodym导数校正偏差。
不是直接有用,但它告诉你目标是什么。
实际中常用的方法是指数倾斜(exponential tilting)。
如果你的标的遵循一个随机游走,其增量 $\Delta_i$ 具有矩生成函数 $M(\gamma)=E[e^{\gamma\Delta}]$,你倾斜分布:
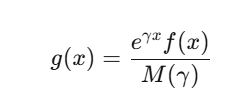
选择 $\gamma$ 使稀有事件变得典型。对于当总和超过一个大阈值时支付的合约,$\gamma$ 求解Lundberg方程 $M(\gamma)=1$。
尾部风险合约的重要性采样
在极端合约上,IS 可以将方差减少 $100-10,000$ 倍。
这意味着 $100$ 个 IS 样本比 $1,000,000$ 个粗略样本提供更好的精度。
这并非微小的改进。这是“我们无法定价”与“我们正在交易”之间的区别。
第四部分:用于实时更新的序列蒙特卡洛
但是当故事从静态估计转向动态模拟时我需要做什么呢?
想象一下:现在是选举之夜。美国东部时间晚上 $8:01$。佛罗里达州的投票站刚刚关闭。初步结果显示一个候选人领先 $3$ 个百分点。
你的模型需要立即更新,将这个新数据点纳入对佛罗里达州、俄亥俄州、宾夕法尼亚州、密歇根州以及所有相关州的概率估计中。
这就是滤波问题,而工具是序贯蒙特卡洛(Sequential Monte Carlo)粒子滤波器。
状态空间模型
定义:
-
隐藏状态 $x_t$:事件的“真实”概率(未观测到)
-
观测 $y_t$:市场价格、民意调查结果、选票计数、新闻信号
状态通过 logit 随机游走演变(保持概率有界):
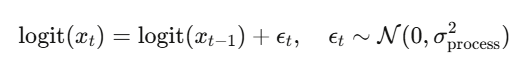
观测是真实状态的带噪声读数:
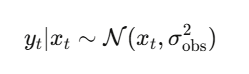
Bootstrap 粒子滤波器
该算法维护 $N$ 个“粒子”——每个粒子都是对真实概率的假设,并随着数据到来重新加权:
用于实时预测市场的粒子滤波器
为什么这比直接使用市场价格更好?
因为粒子滤波器可以平滑噪声并传播不确定性。
当市场因一笔交易从 $0.58$ 飙升到 $0.65$ 时,滤波器会识别出真实概率可能没有发生那么大的变化,它会根据观测过程的波动性来调整更新。
第五部分:三个堆叠的方差减少技巧
在我们离开蒙特卡洛领域之前,这里有三种技巧,它们与上述所有内容呈乘法关系。
自由对称性
当支付函数是单调的(二元合约总是如此——更高的价格意味着超过行权价的概率更高)时,方差减少是有保证的:
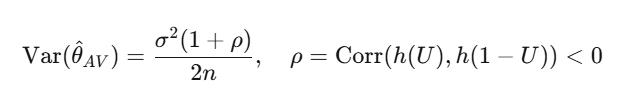
典型的减少量约为 $50-75\%$。除了函数评估加倍(你反正也打算这样做)之外,没有额外的计算成本。
利用你已知的信息
如果你正在模拟随机波动率下的二元合约 ${ST > K}$(没有解析解),则使用Black-Scholes数字期权价格 $p{BS}$(有解析解)作为控制变量:

分而治之
将概率空间划分为 $J$ 个层(strata),在每个层内抽样,然后合并。方差总是 $\le$ 粗略蒙特卡洛(根据总方差定律),最大收益来自Neyman分配:$n_j \propto \omega_j \sigma_j$(对高方差的层进行过采样)。
堆叠所有三种方法
在每个层内部使用对偶变量(antithetic variates),并进行控制变量校正,你通常可以实现比粗略蒙特卡洛高 $100-500$ 倍的方差减少。这在生产环境中并非可选。这是基本要求。
第六部分:相关矩阵无法建模的东西
分层贝叶斯模型通过共享的全国摇摆参数隐含地编码了相关性。
但尾部依赖性(极端同步变动的趋势,而这在线性相关性中不会显现)呢?
$2008$ 年,高斯 copula 在建模尾部依赖性方面的失败导致了全球金融危机。在预测市场中,同样的问题出现了:当一个摇摆州出现意外结果时,所有摇摆州同时翻转的概率远高于高斯 copula 预测的概率。
Sklar 定理
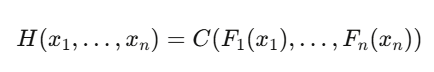
其中 $C$ 是copula(纯粹的依赖结构),$F_i$ 是边际 CDF。你可以单独建模每个市场的边际行为,然后用一个捕获依赖性(包括尾部依赖性)的copula将它们粘合起来。
尾部依赖问题
高斯 copula:尾部依赖性 $\lambda_U=\lambda_L=0$。极端同步变动被建模为零概率。
这对于相关预测市场来说是灾难性的错误。
Student-t copula
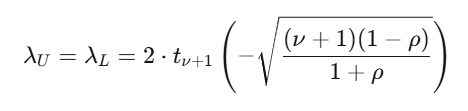
当 $\nu=4$ 且 $\rho=0.6$ 时,尾部依赖性约为 $0.18$——这意味着当一个合约达到极端时,极端同步变动发生的概率为 $18\%$。高斯 copula 会说是 $0\%$。
Clayton copula:仅下尾部依赖性($\lambda_L=2^{-1/\theta}$)。当一个预测市场崩溃时,其他市场也随之崩溃。没有上尾部依赖性。
Gumbel copula:仅上尾部依赖性($\lambda_U=2-2^{1/\theta}$)。相关的正向决议。
模拟相关的预测市场结果
这正是高斯 copula 在 $2008$ 年失败的原因,并且它会再次在预测市场投资组合中失败。
Student-t copula,当 $\nu=4$ 时,通常显示极端联合结果的概率高出 $2-5$ 倍。
如果你在不建模尾部依赖性的情况下交易相关的预测市场合约,你正在运营一个在最关键情境下会崩溃的投资组合。
Vine Copula
对于 $d>5$ 个合约,二元 copula 是不够的。Vine copula 将 $d$ 维依赖性分解为 $d(d-1)/2$ 个二元条件 copula,这些 copula 排列成树状结构:
-
C-vine(星形):一个中心事件驱动一切(例如,总统赢家 -> 所有政策市场)
-
D-vine(路径):顺序依赖性(例如,初选结果流向大选)
-
R-vine(一般图):最大灵活性
构建按 $\vert \tau_{\text{Kendall}} \vert$ 排序的最大生成树,通过 AIC 选择对-copula 族,并顺序估计。实现:pyvinecopulib (Python), VineCopula (R)。
第七部分:基于代理的模拟
到目前为止的一切都假设你了解数据生成过程,并且只需要模拟它。
但是预测市场由异质代理(informed traders、noise traders、market makers 和 bots)组成,它们的交互产生了一种内生动态,这是任何封闭形式的 SDE 都无法捕捉的。
零智能启示
即使每个交易者都完全非理性,市场也可以是有效的。
Gode & Sunder ($1993$) 表明,零智能代理——仅受预算约束提交随机订单的交易者——在连续双向拍卖中实现了接近 $100\%$ 的配置效率。
Farmer, Patelli & Zovko ($2005$) 将此扩展到限价订单簿。
这解释了伦敦证券交易所 $96\%$ 的横截面价差变动。一个参数。$96\%$。
基于代理的预测市场模拟器
价格收敛的速度取决于知情交易者与噪声交易者的比例、做市商利差对信息流的反应方式,以及知情交易者为何以牺牲噪声交易者为代价获取利润。
第八部分:生产堆栈
以下是完整的系统,从市场数据到交易执行:
-
第一层:数据摄取 - 来自Polymarket CLOB API的WebSocket feed(实时价格、交易量) - 新闻/民意调查feed(经NLP处理成概率信号) - 链上事件数据(Polygon)
-
第二层:概率引擎 - 分层贝叶斯模型(Stan/PyMC)州级后验 - 粒子滤波器实时更新新观测 - 跳跃扩散SDE路径模拟用于风险管理 - 集合:模型输出的加权平均
-
第三层:依赖性建模 - Vine copula合约之间的成对依赖性 - 因子模型共享国家/全球风险因子 - 通过t-copula进行尾部依赖性估计
-
第四层:风险管理 - 基于EVT的VaR和预期短缺 - 逆向压力测试识别最坏情况 - 相关性压力:如果州相关性飙升怎么办? - 流动性风险订单簿深度监控
-
第五层:监控 - Brier score跟踪(我们校准了吗?) - 盈亏归因(哪个模型组件增加了价值?) - 回撤警报 - 模型漂移检测
参考文献
-
Dalen ($2025$). "Toward Black-Scholes for Prediction Markets." arXiv:$2510.15205$
-
Saguillo et al. ($2025$). "Unravelling the Probabilistic Forest: Arbitrage in Prediction Markets." arXiv:$2508.03474$
-
Madrigal-Cianci et al. ($2026$). "Prediction Markets as Bayesian Inverse Problems." arXiv:$2601.18815$
-
Farmer, Patelli & Zovko ($2005$). "The Predictive Power of Zero Intelligence." PNAS
-
Gode & Sunder ($1993$). "Allocative Efficiency of Markets with Zero-Intelligence Traders." JPE
-
Kyle ($1985$). "Continuous Auctions and Insider Trading." Econometrica
-
Glosten & Milgrom ($1985$). "Bid, Ask, and Transaction Prices." JFE
-
Hoffman & Gelman ($2014$). "The No-U-Turn Sampler." JMLR
-
Merton ($1976$). "Option Pricing When Underlying Stock Returns Are Discontinuous." JFE
-
Linzer ($2013$). "Dynamic Bayesian Forecasting of Presidential Elections." JASA
-
Gelman et al. ($2020$). "Updated Dynamic Bayesian Forecasting Model." HDSR
-
Aas, Czado, Frigessi & Bakken ($2009$). "Pair-Copula Constructions of Multiple Dependence." Insurance: Mathematics and Economics
-
Wiese et al. ($2020$). "Quant GANs: Deep Generation of Financial Time Series." Quantitative Finance
-
Kidger et al. ($2021$). "Neural SDEs as Infinite-Dimensional GANs." ICML
- 原文链接: x.com/gemchange_ltd/stat...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





