Sunnyside Devnet更新 - 04/01
- testinprod
- 发布于 2025-09-18 18:53
- 阅读 967
本文是Sunnyside Devnet的更新报告,重点是测试不同的共识层(CL)客户端(Lighthouse, Prysm, Teku, Lodestar, Grandine)在处理大量blob时的性能。测试目的是确定每个CL客户端可以处理的最大blob数量,并分析了geth的blobpool行为以及getBlobs命中率与blob吞吐量之间的关系。
Sunnyside Devnet 更新 - 04/01
概述
此测试旨在确定每个 CL 可以处理的最大 blob 数量。 因此,我们在测试中只运行了节点的单一组合
lighthouse/geth:
40 个 blobs/块
prysm/geth:
25 个 blobs/块
teku/geth:
30 个 blobs/块
lodestar/geth:
25 个 blobs/块
grandine/geth:
20 个 blobs/块
nimbus 还没有带有 getBlobs 的 PeerDAS 版本,所以我们稍后会运行这个测试
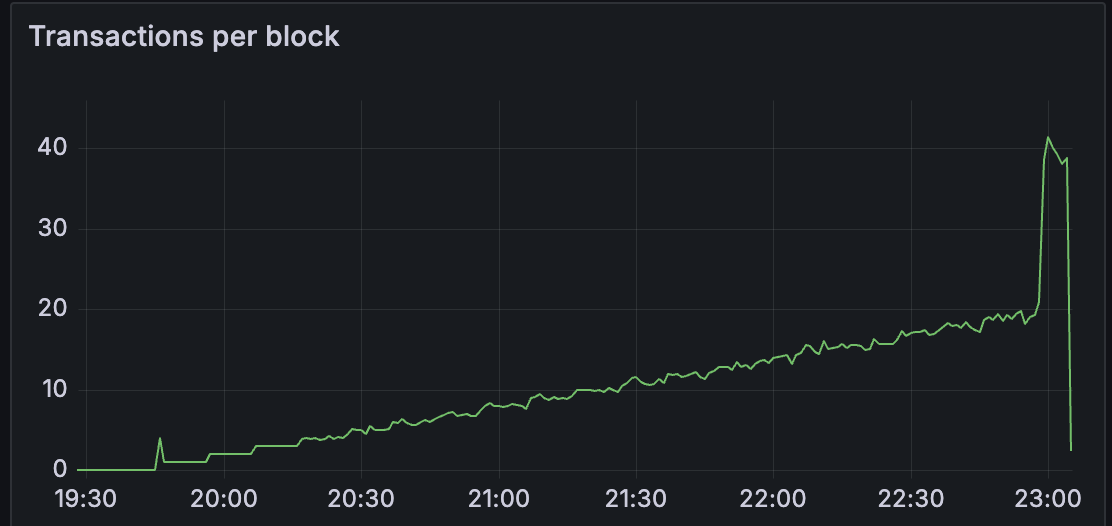
从上面的测试中:
我们正在调查 geth 的 blobpool 的行为,以及 getBlobs 命中率与 blob 吞吐量之间的相关性如何
在理想的 EL blob 命中率下,客户端可以处理比以前的测试更多的 blob。
然而,客户端之间的 blobs 吞吐量存在差异。
测试方法与之前的测试相同。
Lighthouse
使用 50 个 lighthouse-geth 节点,其中 25 个是完整节点,25 个是超级节点:
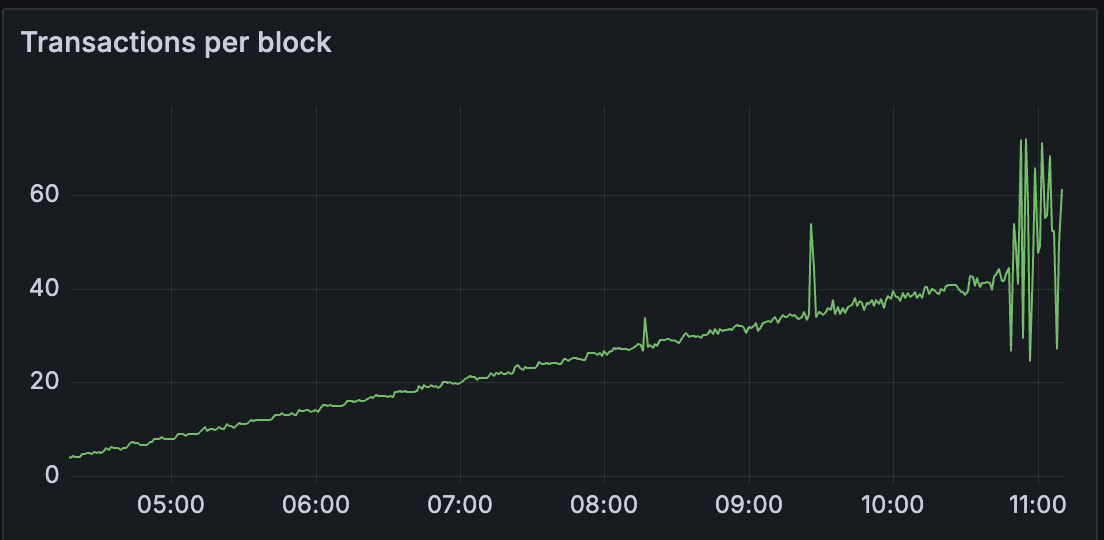
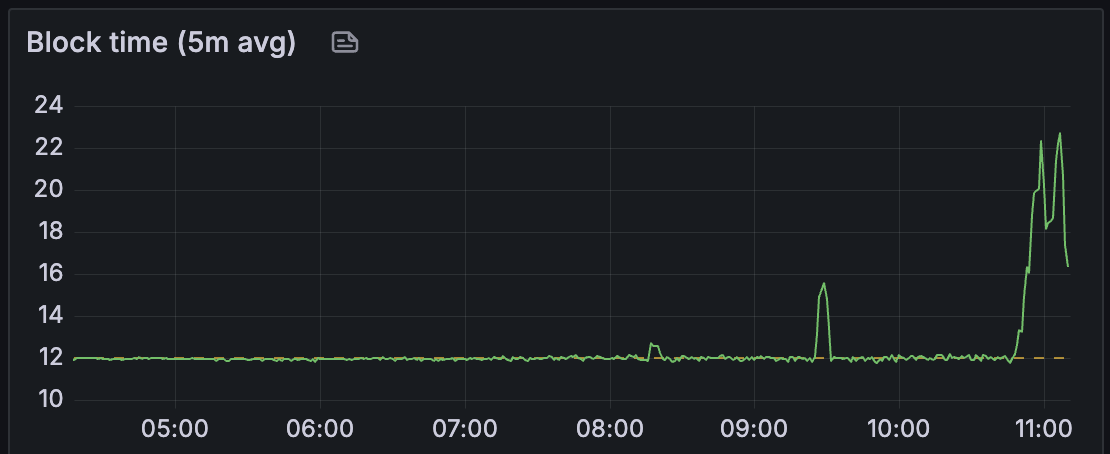
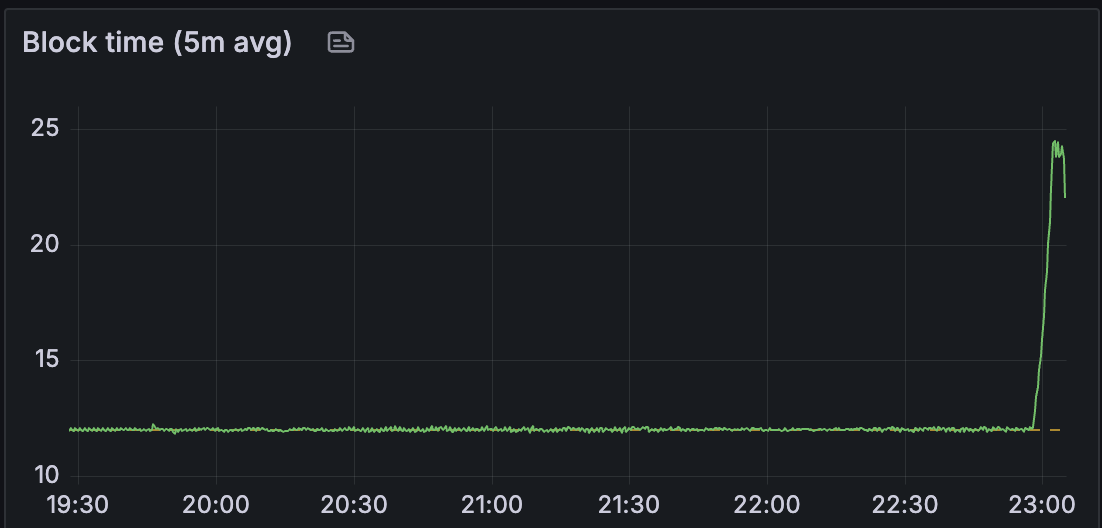
我们看到区块时间保持稳定,直到大约 40 个 blobs/区块。
我们可以观察到区块导入延迟和 attestable_slot_start 时间持续增长,到网络变得不健康时超过 8 秒。
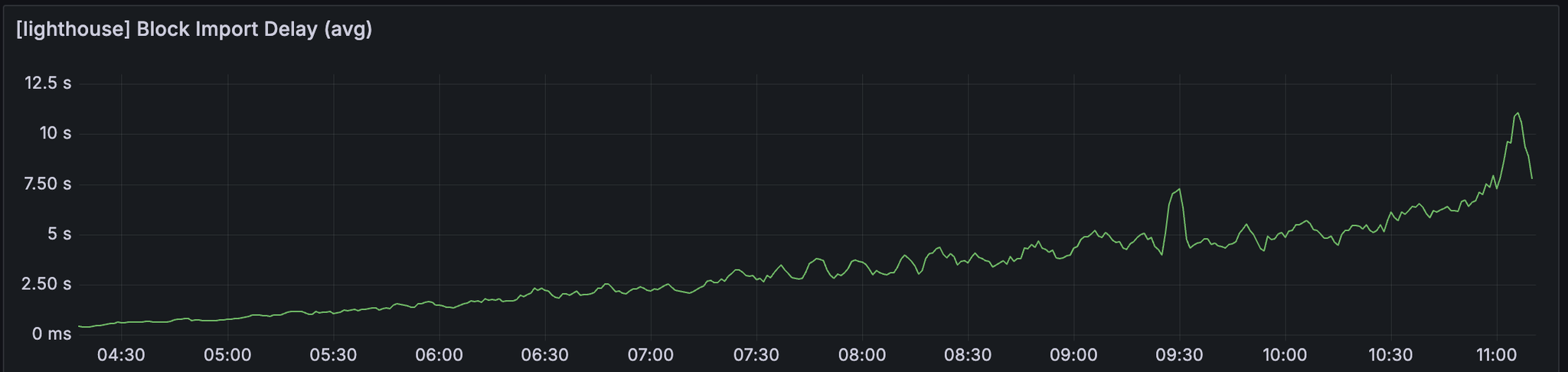
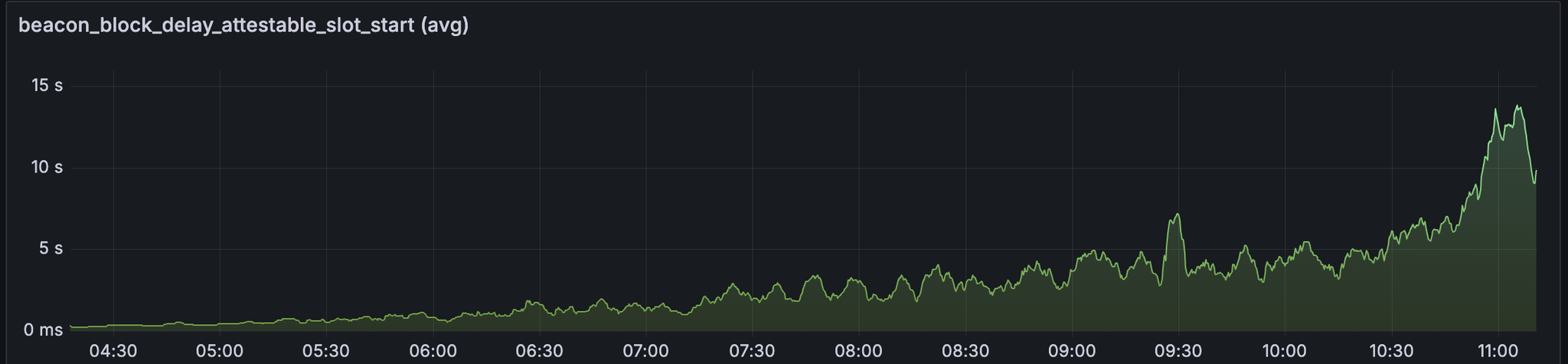
发现
以上图表中奇怪的是,指标稳步增长,直到 UTC 时间 10:50 左右出现突然的峰值。 我们想确定在此时间范围内是否发生了任何因素。
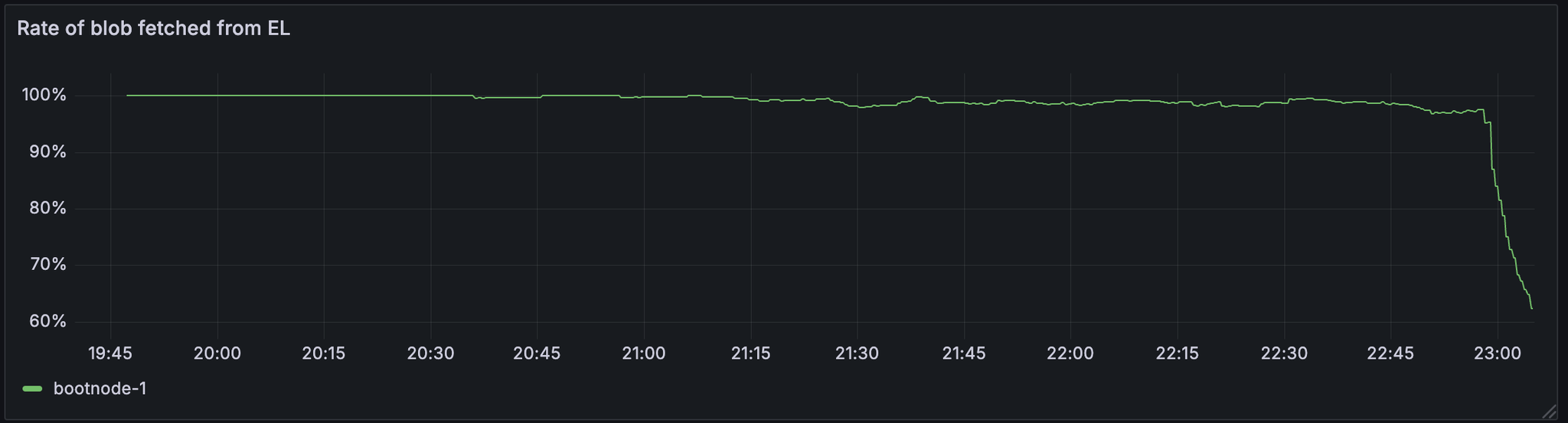
GetBlob
这也是我们注意到 getBlob 的命中率显着下降的时候。

虽然需要调查具体情况,但我们认为 blob 获取率的降低可能是导致错过 slot 的原因。
在 Geth 中,blobpool 的数据使用量在此期间显着下降,
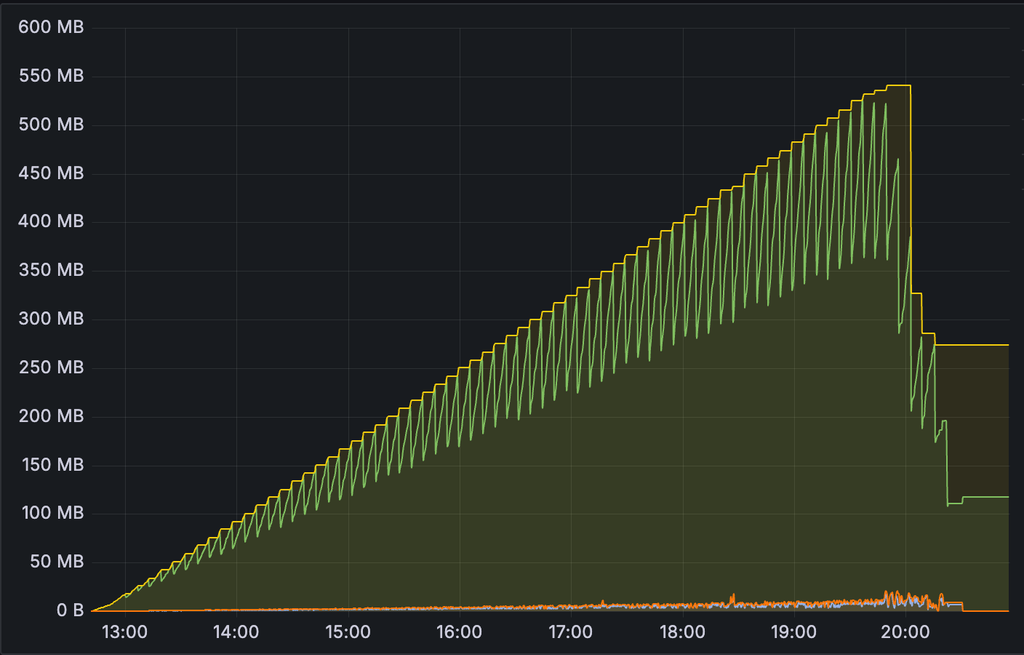
Blobpool 大小
ALT
并且大多数交易都回复了
otherreject
.
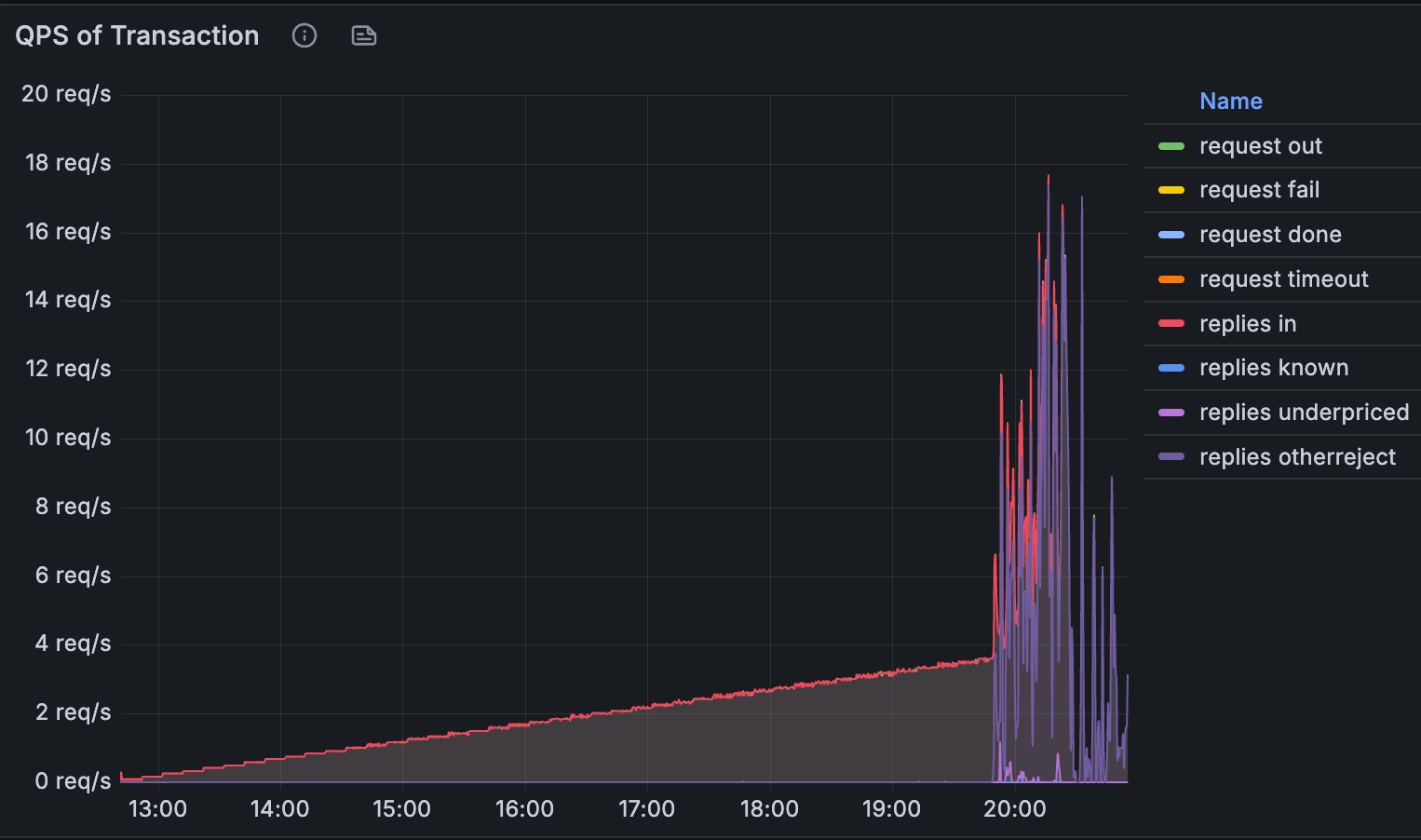
对 Geth 的 blobpool 行为的更多调查正在进行中 here
了解降低的 getBlobs 命中率是否会导致网络故障,或者网络故障是否会导致 getBlobs 命中率追溯性下降也很重要。
列重构
在同一时间戳附近,CL 开始重构更多列。 这可能是由于 EL 中缺少 blob,CL 必须 gossip & 重构单个列
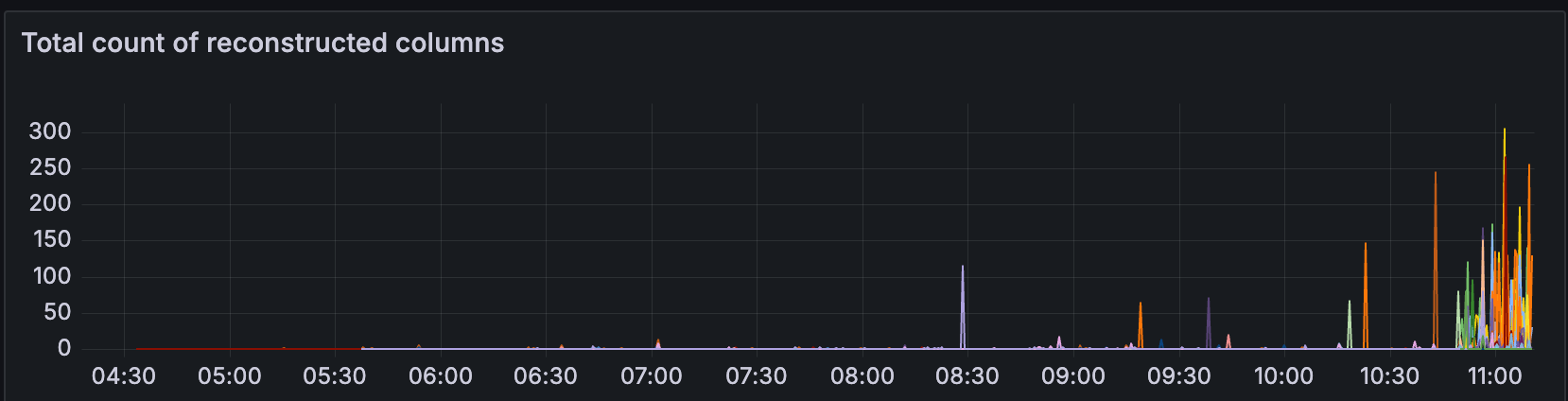
随着 blob 的增加,我们还可以观察到数据列 sidecar 计算和重构的计算时间增加。
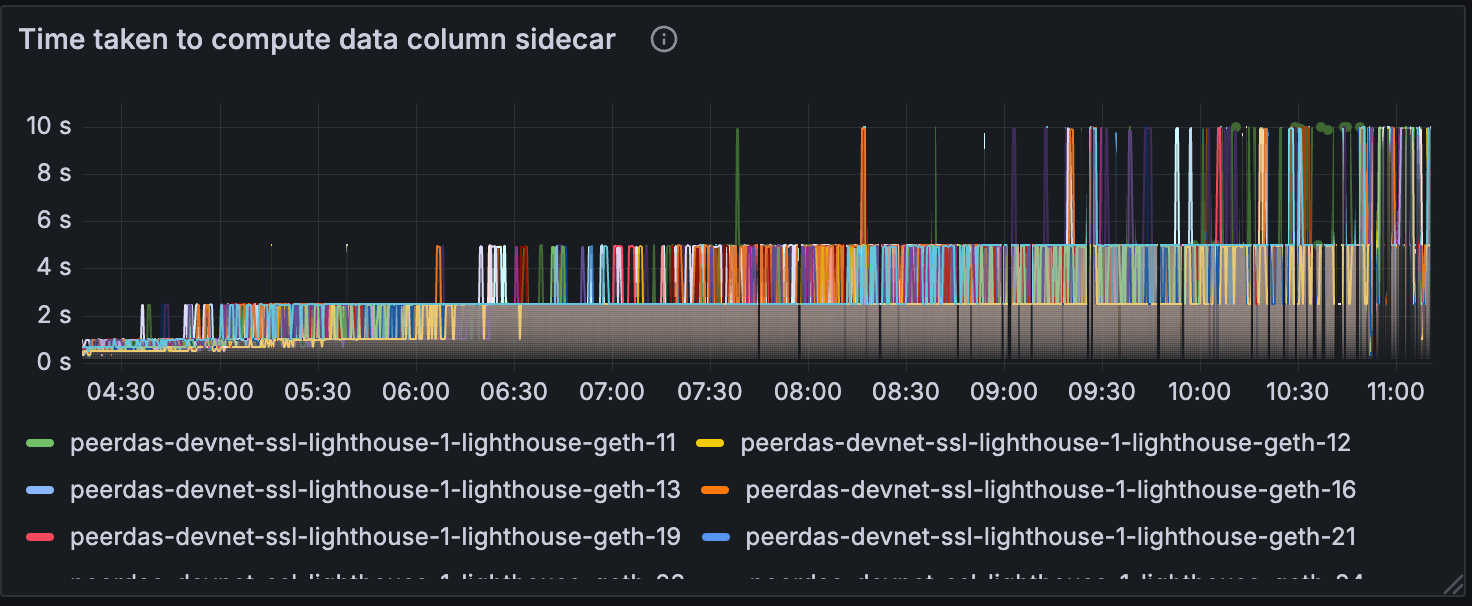
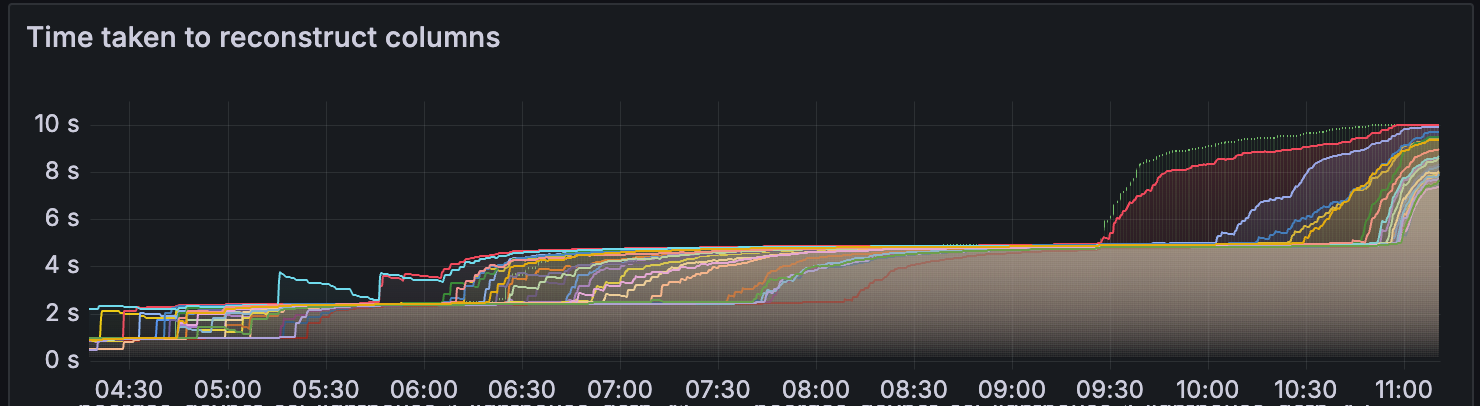
一件有趣的事情是,当网络健康时,上述运行时超过 4-6 秒。 我们需要确定多长的运行时对于正确的区块传播是安全的,以及其他因素如何与此时间相互作用。
Gossipsub
另一个有趣的观察结果是,在此期间,来自 CL 的 gossipsub 对于少数超级节点有所减少。
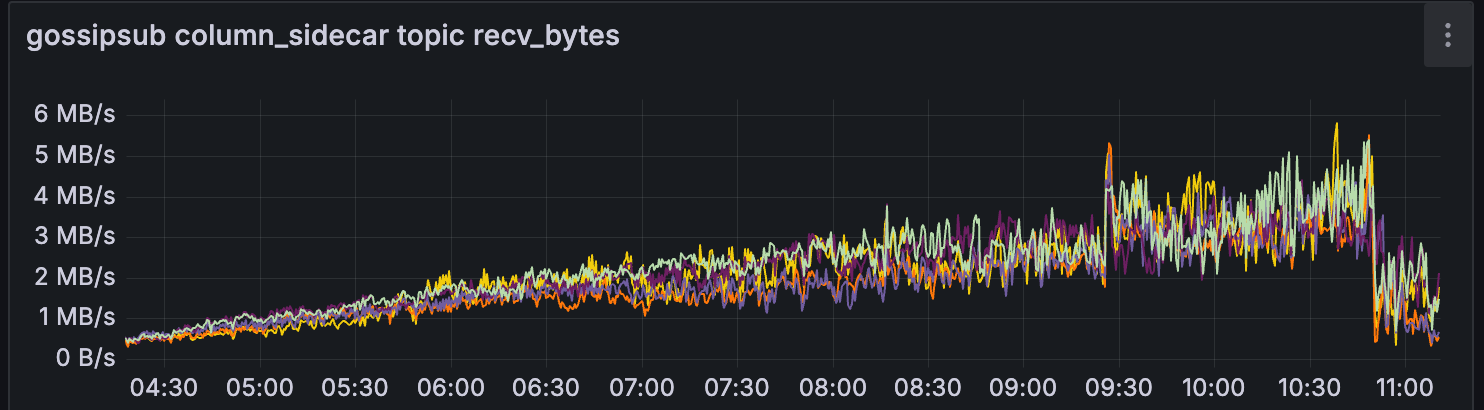
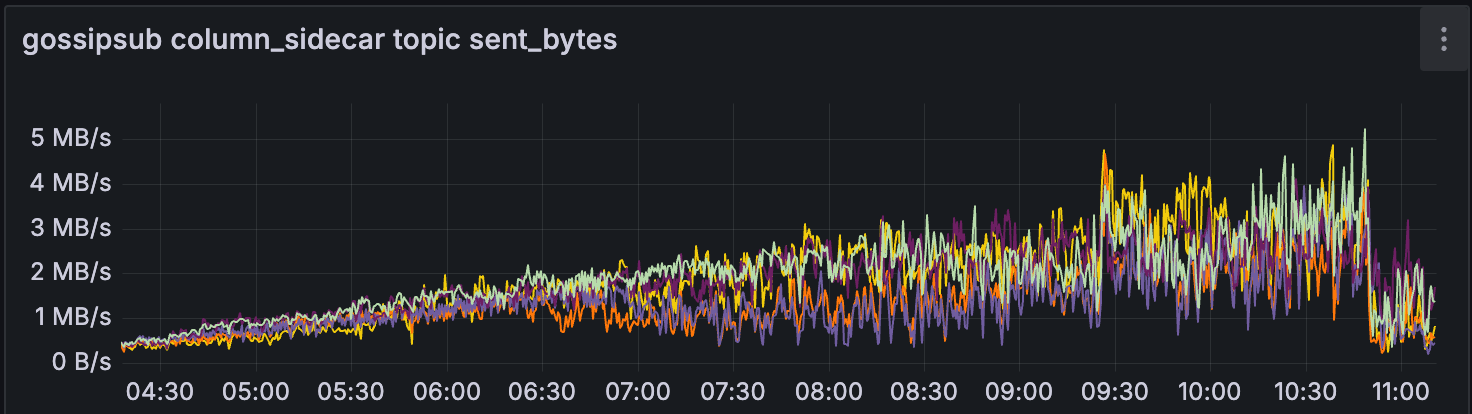
我天真的假设是,当 getBlob 命中率降低时,CL 使用 gossipsub 来传播 blob 的需求会增加。
这可能是因为这些超级节点根本无法在传播 blob 之前获得所有数据列,因为它们无法从 EL 中获得。
Teku
对于 teku,我们观察到区块时间保持健康,直到大约有 30 个 blobs/区块。
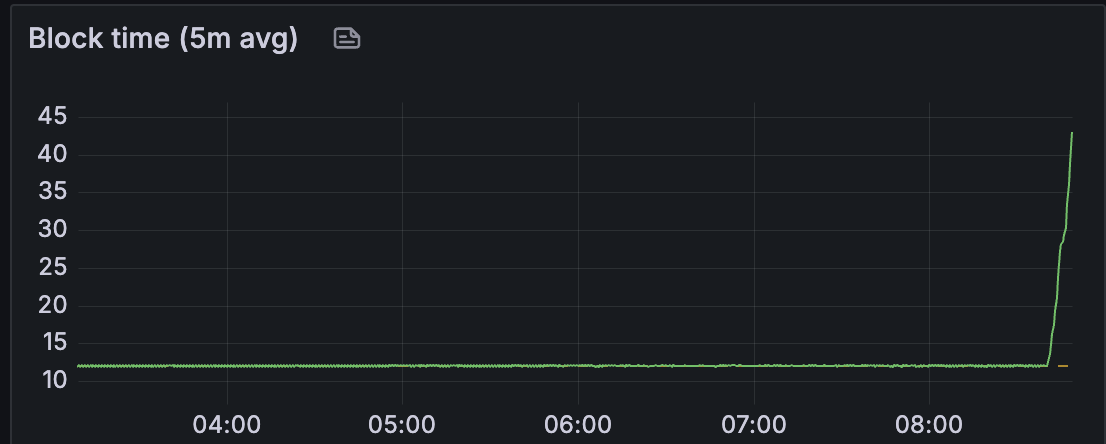
我们还看到区块导入延迟和 attestable_slot_start 时间保持稳定在 4 秒以下,直到网络在大约 08:40 变得不健康。
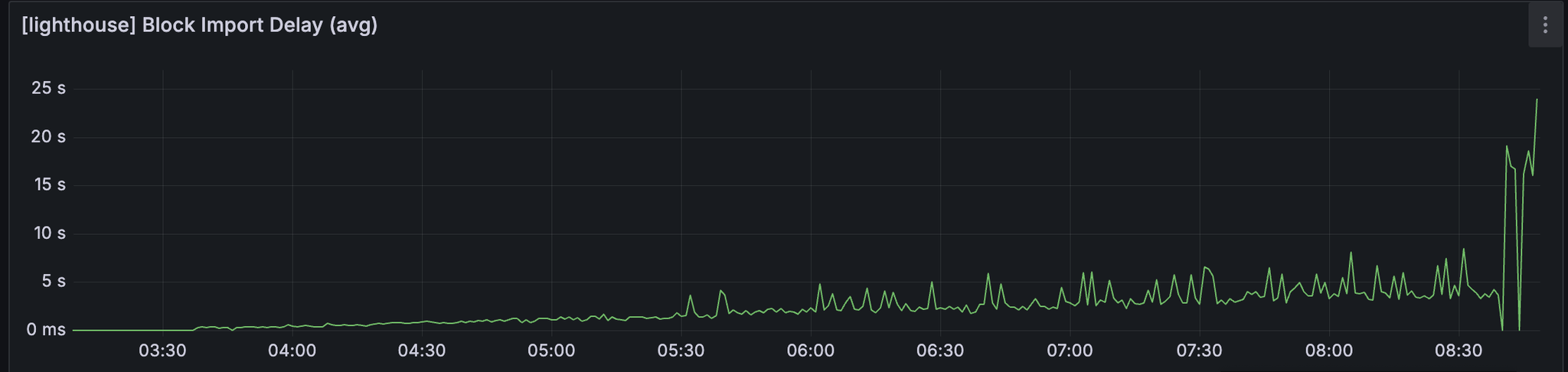
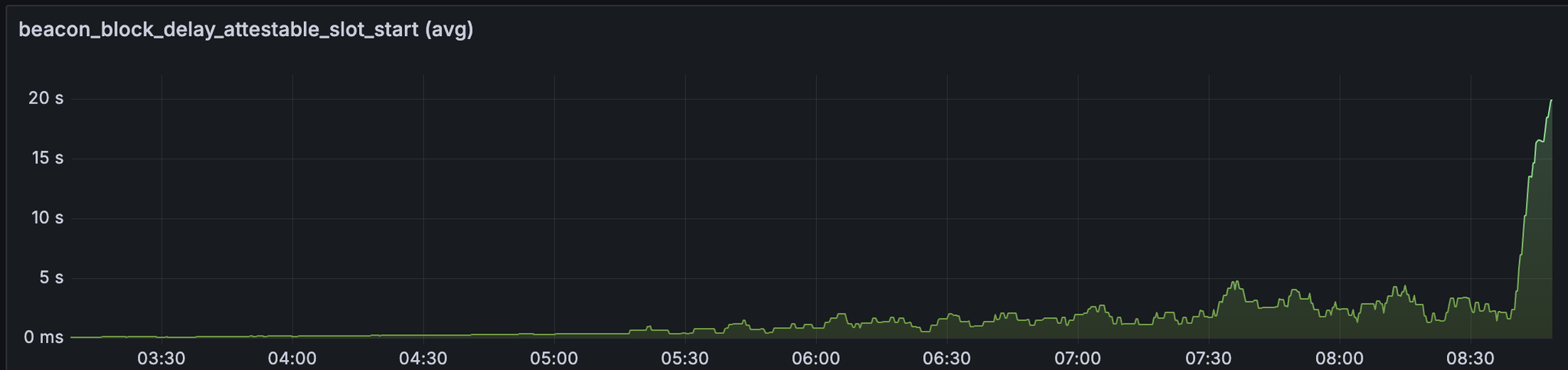
发现
我们注意到在此测试中,getBlob 命中率也显着下降。
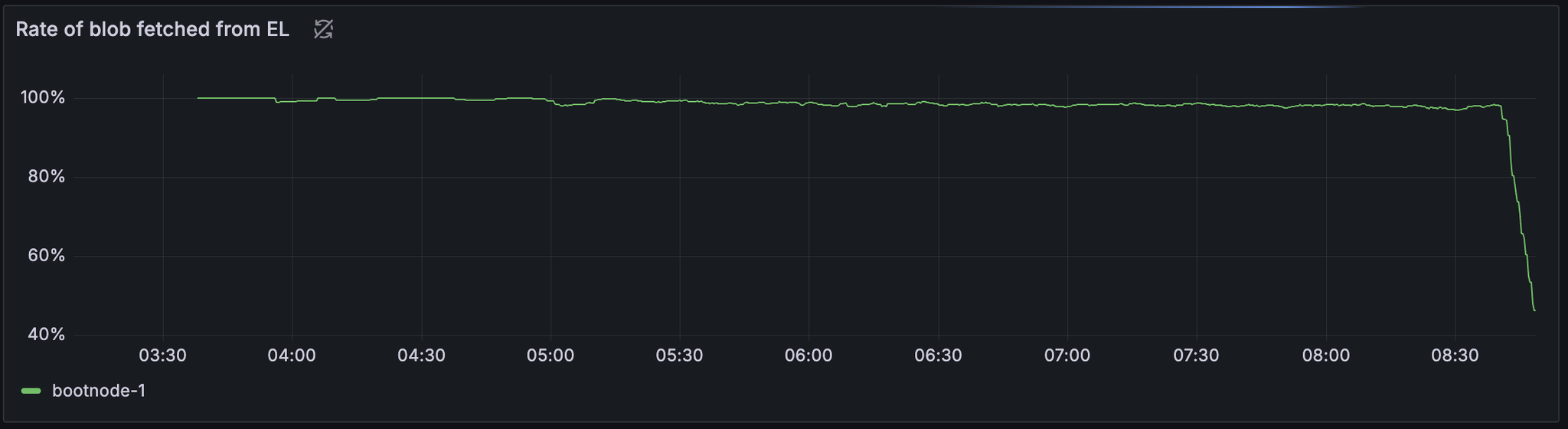
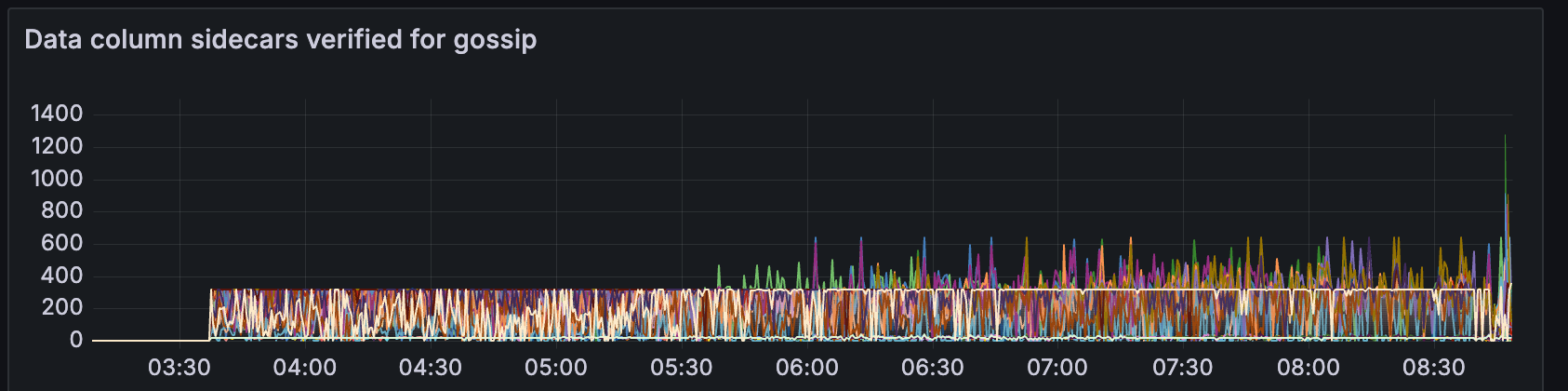
数据列验证
我们还可以看到数据列处理失败的数量增加,

以及 gossip 验证的运行时间

但是,实际通过 gossip 验证的数据列 sidecar 的数量并没有以相同的比例增加。 我们可能需要调查为什么会有如此多的列处理失败以及为什么 gossip 验证的运行时间会增加。
节点 RAM 使用量
我们还注意到,超级节点开始消耗大约是完整节点 2 倍的 RAM。

Ram 使用量在大约 20 个 blobs/区块时出现分歧。 这可能是预期的,因为超级节点需要处理所有列以增加区块。 但是,我们希望确认 teku 团队是否预期这种 RAM 使用量的差异。
Grandine
对于 grandine,我们观察到区块时间保持健康,直到大约有 20 个 blobs/区块。
观察
我们注意到在此测试中,getBlob 命中率也显着下降。
正如预期的那样,随着 getBlobs 命中率的降低,CL 中使用的 gossipsub 带宽更高。
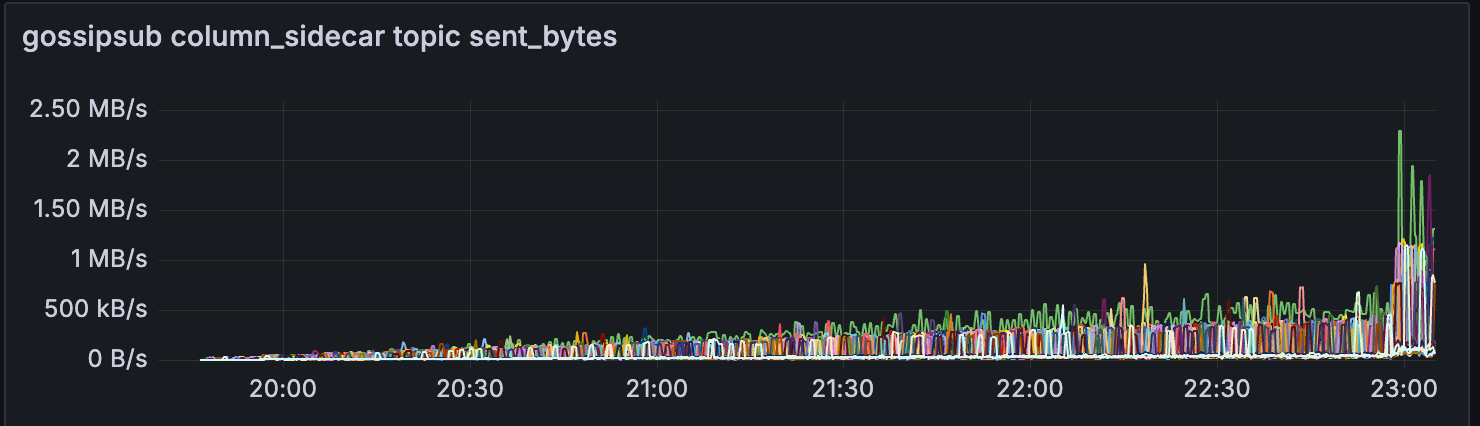
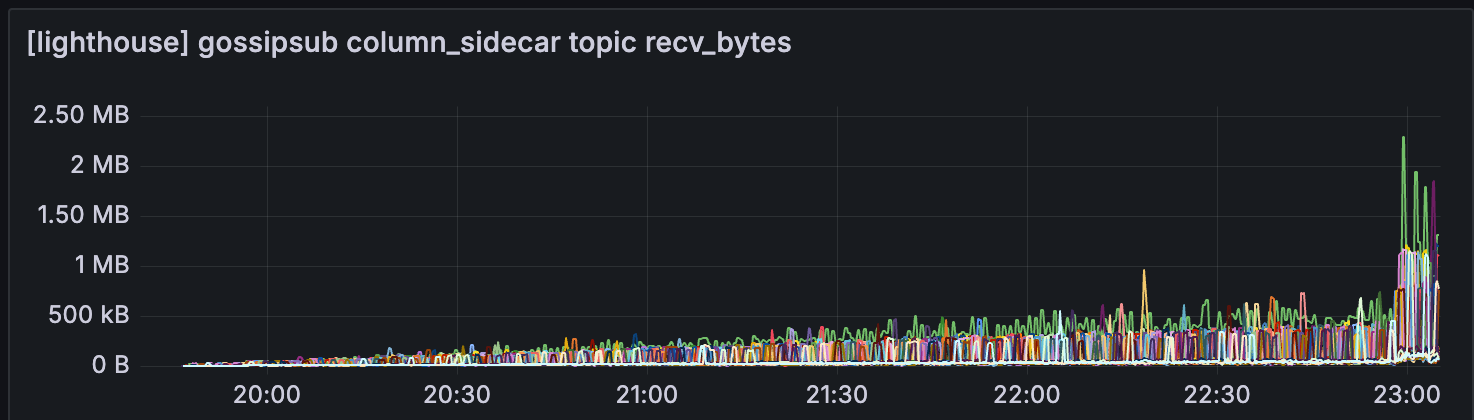
Lodestar
对于 lodestar,我们观察到区块时间保持健康,直到大约有 25 个 blobs/区块。
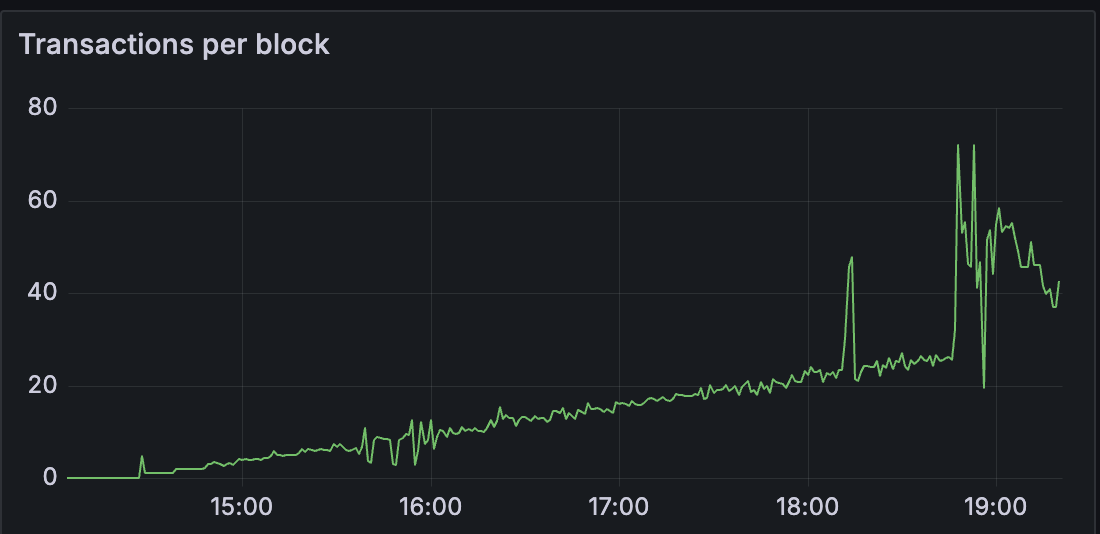
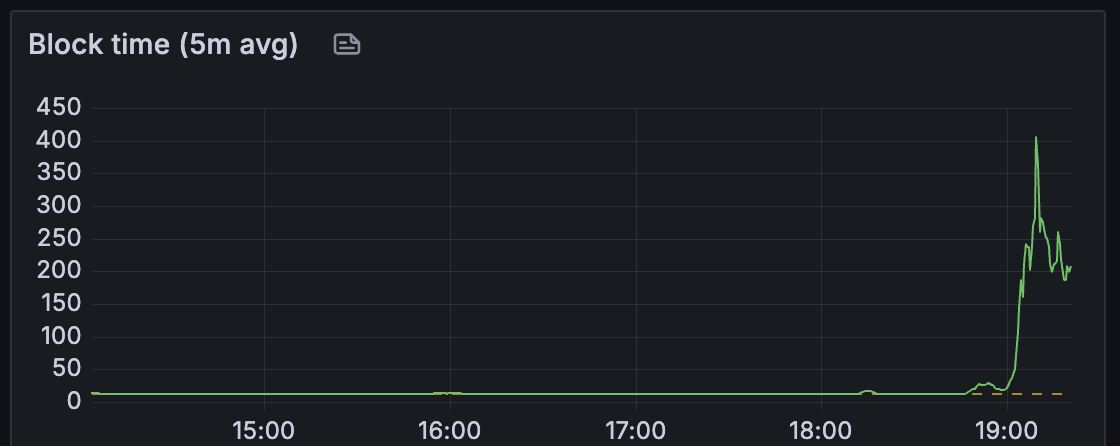
发现
节点落后
当我们放大 18:30-19:30 时,我们可以注意到节点开始完全无法跟随链并停滞。
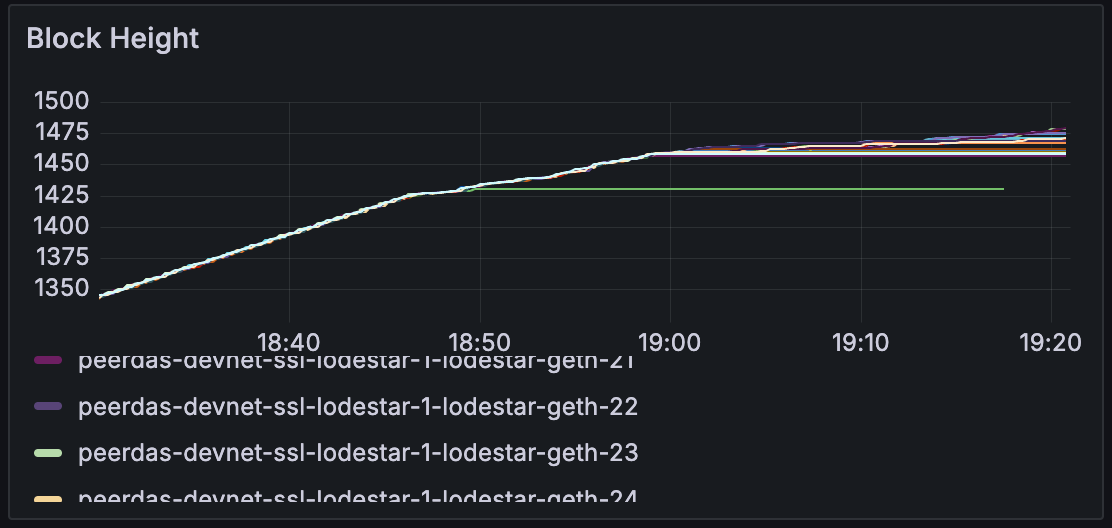
节点最好选择排除 blob 或缓慢跟随链,但需要调查节点为何停滞。
带宽使用
在事件发生时,节点的带宽使用量增加了 5 倍以上。


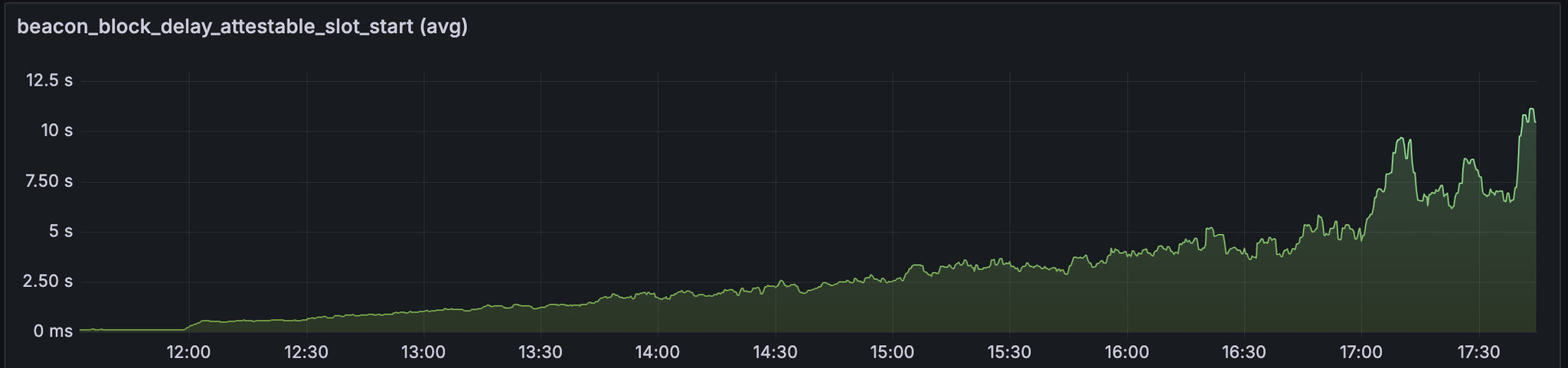
Prysm
对于 prysm,我们观察到区块时间保持健康,直到大约有 25 个 blobs/区块。
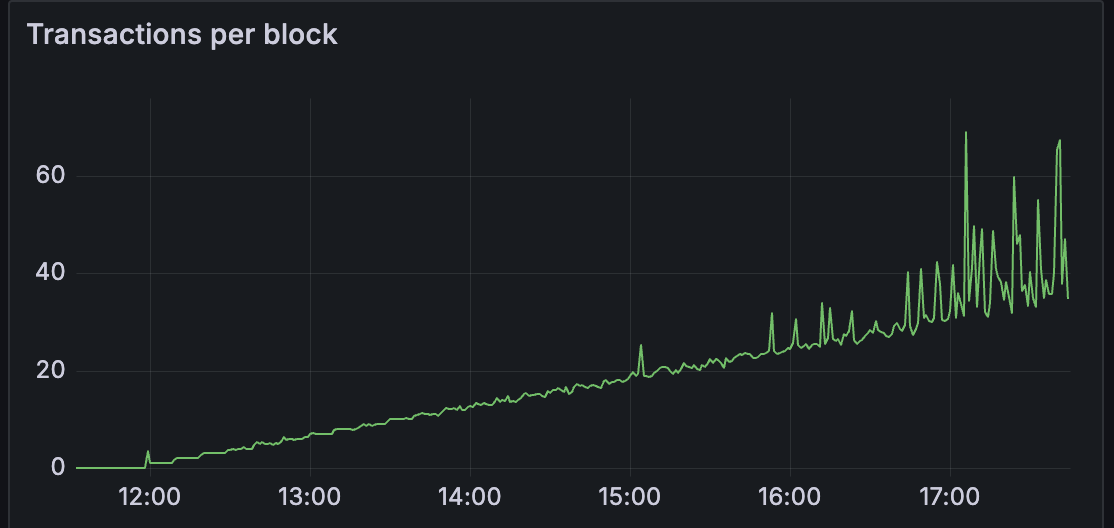
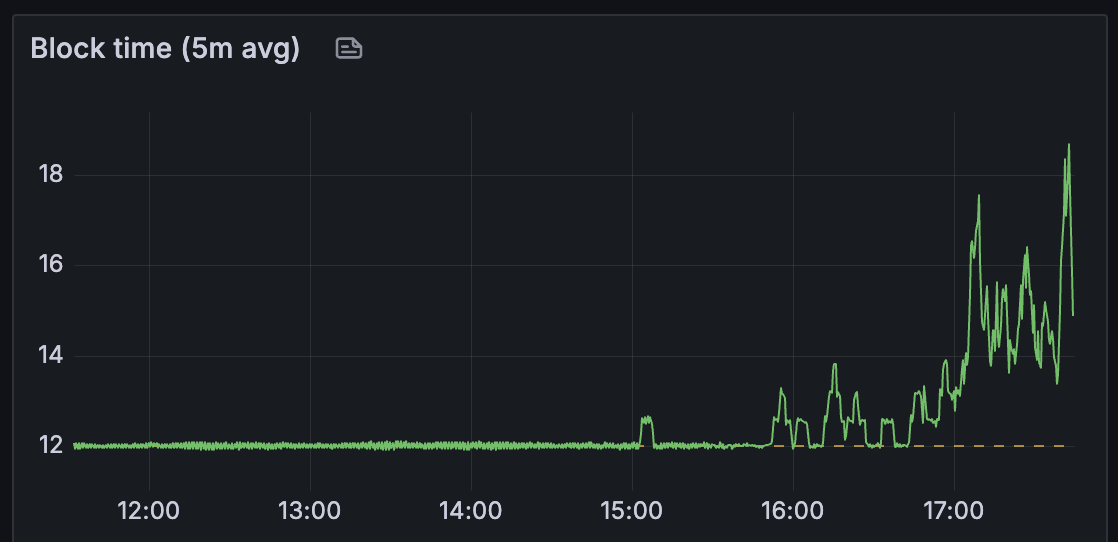
观察
我们可以观察到区块到达延迟和 attestable_slot_start 也与上述指标一致。
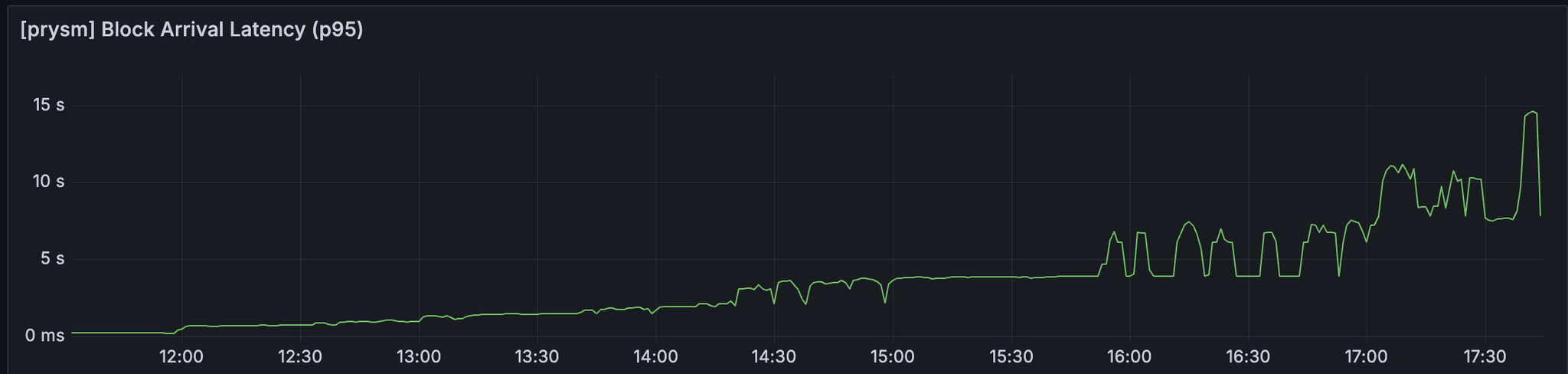
此测试中使用的 prysm 版本是
data-columns-storage-1039f5b
. 此 commit 似乎正在使用
getBlobsV2
,但 geth 尚未实现
getBlobsV2
。 这与
peerdas-devnet-5
中的客户端版本相同 - 这是预期的吗?
下一步
我们的下一个目标是
对于已确定的客户端之间 blob 吞吐量差异,找出可能影响此的实现细节
继续调试 geth 的 blobpool 实现
一旦分布式 blob 发布准备就绪,量化其相对于现状的性能改进
在没有 EL blob gossiping 的情况下运行相同的测试,以了解 getBlobs 如何影响 PeerDAS 性能
使用具有无限 blobpool 大小的其他 EL 客户端运行相同的测试,以确定其他 EL 客户端的行为如何
在分析每个客户端时,很难并排比较指标,因为某些指标仅存在于某些客户端中。 因此,我们可以从每个测试中提取的细节量存在差异。
为了解决这个问题,最好在客户端之间统一基本指标(包括 PeerDAS 和非 peerdas)
- 原文链接: testinprod.notion.site/S...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





