Sig 工程 - 第 3 部分 - Solana 的 AccountsDB
- syndica
- 发布于 2024-07-03 20:27
- 阅读 1329
本文是 Syndica 团队关于 Sig 工程更新系列博客的第三部分,重点介绍了 Solana 的自定义账户数据库 AccountsDB 的核心概念和 Syndica 团队的 Sig 实现细节,包括快照、账户文件、账户索引、读取和写入过程,以及后台任务(如刷新、清理、收缩和清除)的实现细节。文章还包括与 Agave 客户端的基准测试结果,展示了 Sig 在账户读写性能方面的优势。
这篇文章是我们将定期发布的一系列多篇博客文章的第三部分,旨在概述 Sig 的工程更新。你可以在这里找到第一部分,涵盖 Sig 的 Gossip Protocol, 这里 ,以及第二部分,涵盖 AccountsDB 等的前期进展, 这里 。
AccountsDB 是 Solana 的自定义账户数据库。本文包含核心概念的高级概述,并说明了 Syndica 团队的 Sig 实现细节。
快照
当验证者启动时,它必须首先跟上当前链的状态。由于 Solana 的历史数据达数百 TB,因此验证者节点仅在磁盘上保留最近的区块和交易。启动一个验证者节点并强制其追赶并验证从创世区块(第一个区块)起的每一个区块并不实际。
相反,Solana 验证者通过从另一个验证者节点下载快照来启动。快照包含每个账户在特定时间点的状态,该时间点由快照中的插槽编号表示,插槽编号标识一个特定的区块。在下载快照后,验证者节点从该插槽(通常在过去 24 小时内)启动,并仅验证最近的区块(即在快照之后创建的区块)。
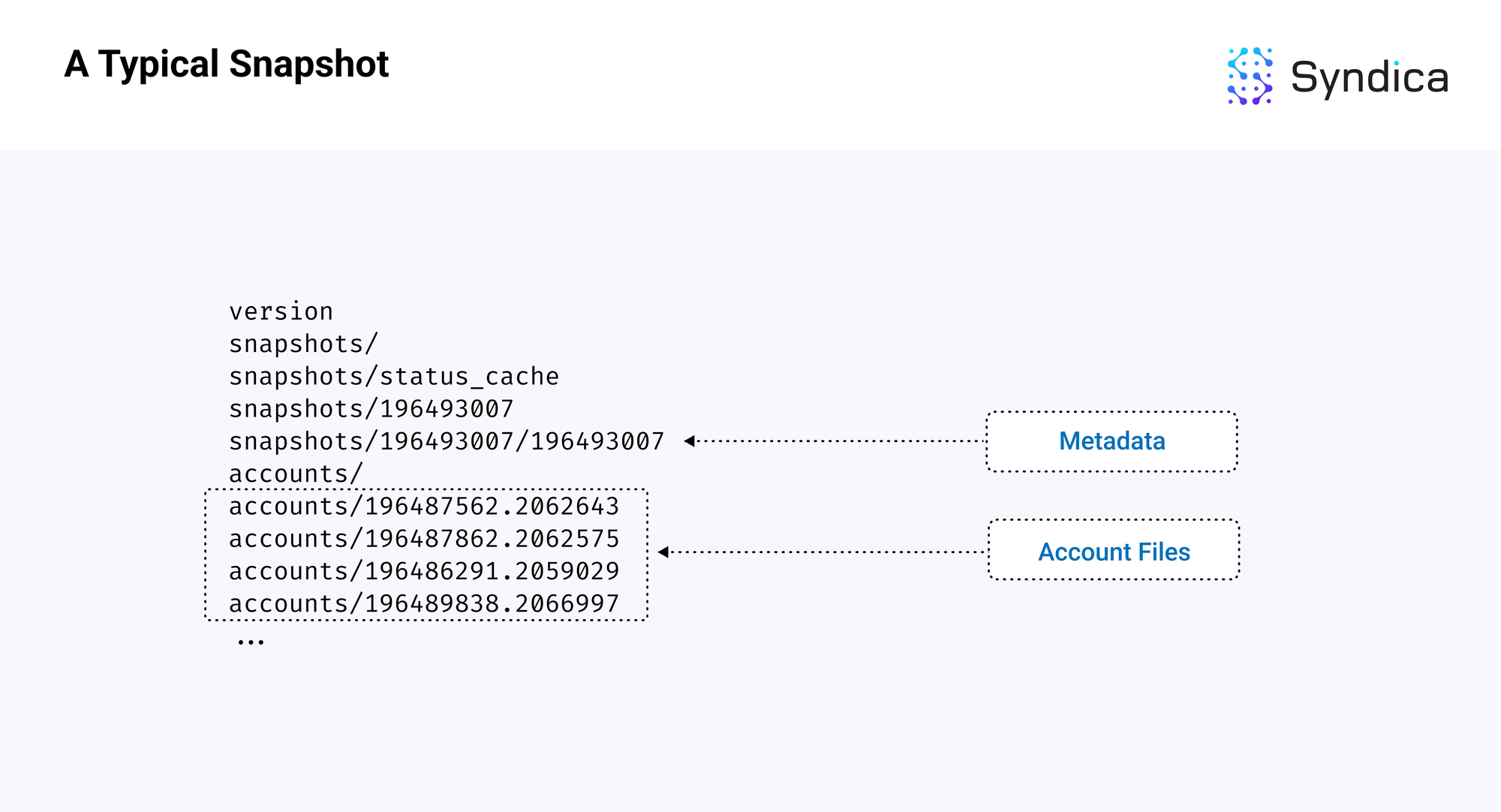
快照包含两个主要组件:
- 一个元数据文件,包含最新区块和数据库状态的信息
- 一个账户文件夹,包含在不同插槽中的账户数据的文件
以下是插槽 196493007 的标准 Solana 快照的示意图,两个组件已被高亮显示。
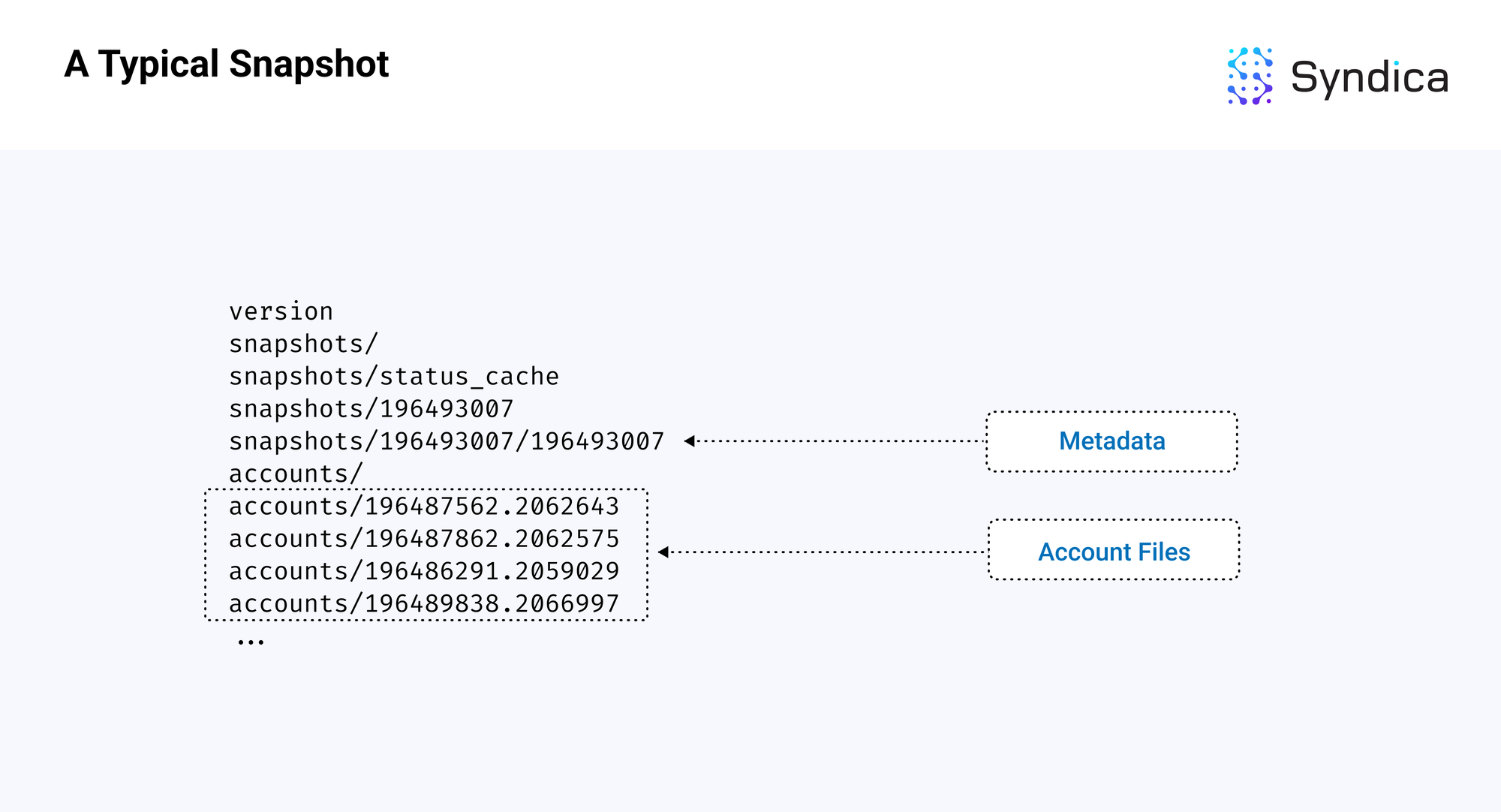
_注意:_快照以 tar 存档的形式构建和下载,并使用 zstandard 格式压缩,因此文件扩展名通常为 .tar.zst。从快照加载时的第一步是将其解压缩并解归档到上述目录结构中。
账户文件
快照中的主要组件之一是账户文件的集合,其中包含特定插槽的所有账户数据。每个文件以字节的列表形式组织账户。
注意: 在 Agave 实现中,包含账户的文件被称为 AppendVecs。然而,这个名称已有些过时,因为代码库中不再使用追加,因此在本文中我们将其称为“账户文件”。在 Sig 中,这些等同于 AccountFile 结构。
从文件中读取账户涉及:
- 解压缩和解归档快照到单独的账户文件
- 将每个账户文件单独加载到内存中
- 读取每个文件的整个长度,并组织成可以由 AccountsDB 代码使用的结构
账户文件格式如下所示:

注意: 由于账户的数据是一个可变长度的数组,我们首先需要读取 data_len 变量,以确定需要读取多少字节到数据字段中。在图中,账户头存储关于账户的有价值元数据(包括 data_len),而 data 字段包含实际的数据字节。AccountInFile 结构可以在 这里 找到。
解析文件中的所有账户的伪代码如下:
## mmap 文件只是一个字节集合
mmap_file: []u8 = ...
offset = 0
const StaticValues = struct {
write_version_obsolete: u64,
data_len: u64,
pubkey: Pubkey,
lamports: u64,
rent_epoch: Epoch,
owner: Pubkey,
executable: bool,
}
accounts = []
while (true) {
// 读取静态值
size_of_static = @sizeOf(StaticValues)
static_values: StaticValues = @cast(mmap_file[offset..offset+size_of_static])
offset += size_of_static
// 读取动态账户数据
data_len = static_values.data_len
account_data: []u8 = mmap_file[offset..offset+data_len]
offset += data_len
// 记录账户
accounts.append(
Account {
static_values,
data,
}
)
}账户索引
既然我们了解了账户文件如何存储账户数据,我们还需要按公钥组织账户(即,我们需要构建从给定公钥到文件中相应账户位置的映射)。这个映射也被称为 AccountIndex。
更具体地说,我们需要从公钥到一个元组 (file_id, offset) 的映射,其中 file_id 是要读取的账户文件的名称,而 offset 是文件中账户字节的索引。通过这个映射,我们可以通过打开与 file_id 关联的文件并从 offset 开始读取字节来访问公钥的相关账户。
账户也可以在插槽之间变化(例如,快照可能包括不同插槽中相同账户的多个版本)。为了将每个账户的 Pubkey 与多个文件位置的集合(或“Vec”)关联,映射还必须包含账户的相应插槽版本。因此,我们使用元组 (slot, file_id, offset),在本文中我们将其称为“账户引用”(或等同于 Sig 中的 [AccountRef](https://github.com/Syndica/sig/blob/a97959176d1a17242c684e091df6d20e8f54a0fa/src/accountsdb/index.zig?ref=blog.syndica.io#L40)结构)。账户索引的结构为 Map<Pubkey, Vec<(slot, file_id, offset)>>,该映射从公钥到一组账户引用。

由于 Solana 上有如此多的账户,索引可能会变得非常大,导致大的内存需求。为了减少这些需求,我们还使用基于磁盘的哈希表,该哈希表将哈希表的底层内存存储在磁盘上,从而最小化验证者的内存需求。
读取账户
如果我们想读取特定账户的数据并知道其公钥,我们可以在账户索引中查找其公钥以找到其位置。我们会找到最近插槽的引用,然后使用账户引用结构中存储的 file_id 和 offset 读取数据。验证者可以直接将这些数据解释为 AccountInFile 结构。
写入账户
AccountsDB 的另一个关键组件是跟踪新的账户状态。例如,当验证者处理新区块交易时,结果是在特定插槽的批量新账户状态。这些新状态随后需要写入数据库。
首先,这些账户被写入与插槽关联的缓存中,并且创建并索引账户引用以指向缓存位置。当插槽被根植(即,由集群中的超大多数确认,也称为“最终确认”)时,数据将从缓存写入新账户文件中,该文件与插槽相关联,并且索引将更新以指向这些新账户的位置。
注意: 这意味着一个账户可以存在于两个位置:缓存中或文件中。
背景线程
随着新账户状态写入数据库,我们执行四个关键任务以确保内存有效利用:
- 刷新
- 清理
- 缩小
- 清除
刷新
刷新定期将数据从内存推送到磁盘。例如,由于账户在有关插槽根植时首先存储在缓存中,因此它们被刷新到磁盘。仅写入已经根植的账户减少了(慢)磁盘写入的数量,同时也减少了我们使用的内存。
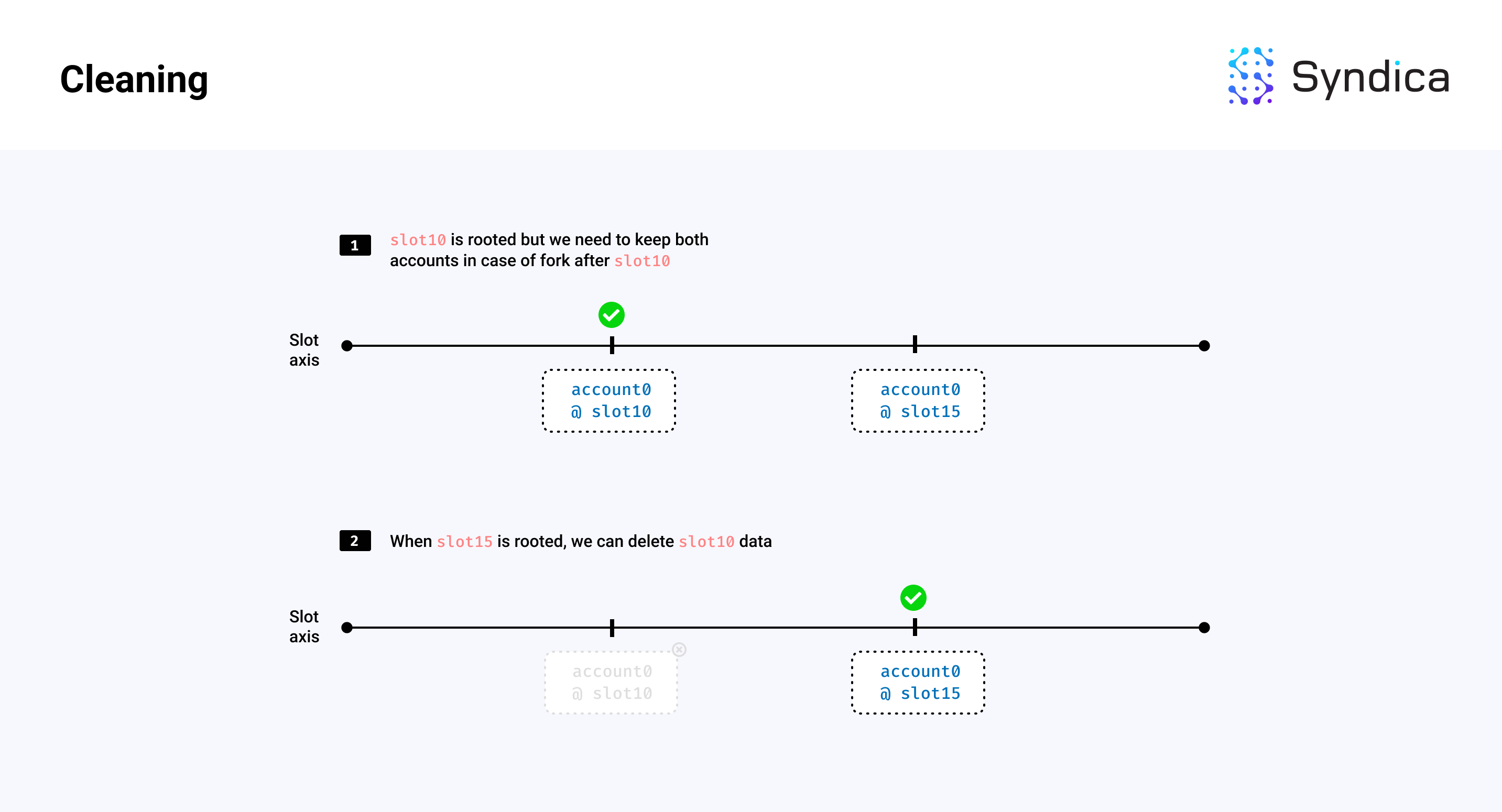
清理
我们还必须清理陈旧数据,以限制账户文件创建带来的内存增长。这包括移除旧的、不需要的账户状态和没有 lamports 的根植账户。
例如,如果我们有两个版本的账户,一个在插槽 10,另一个在插槽 15,并且插槽 15 已根植(即不会回滚),那么我们可以删除与插槽 10 相关的账户和索引数据。如果插槽 15 中的账户也有零 lamports,那么我们也可以删除该账户数据。
注意: 清理阶段删除的是账户索引中的条目,但不回收账户文件中占用的账户数据的存储区域。清理后,此区域被视为账户文件中的垃圾数据,这浪费了存储空间和网络带宽。这些垃圾数据将在缩小过程中被移除。
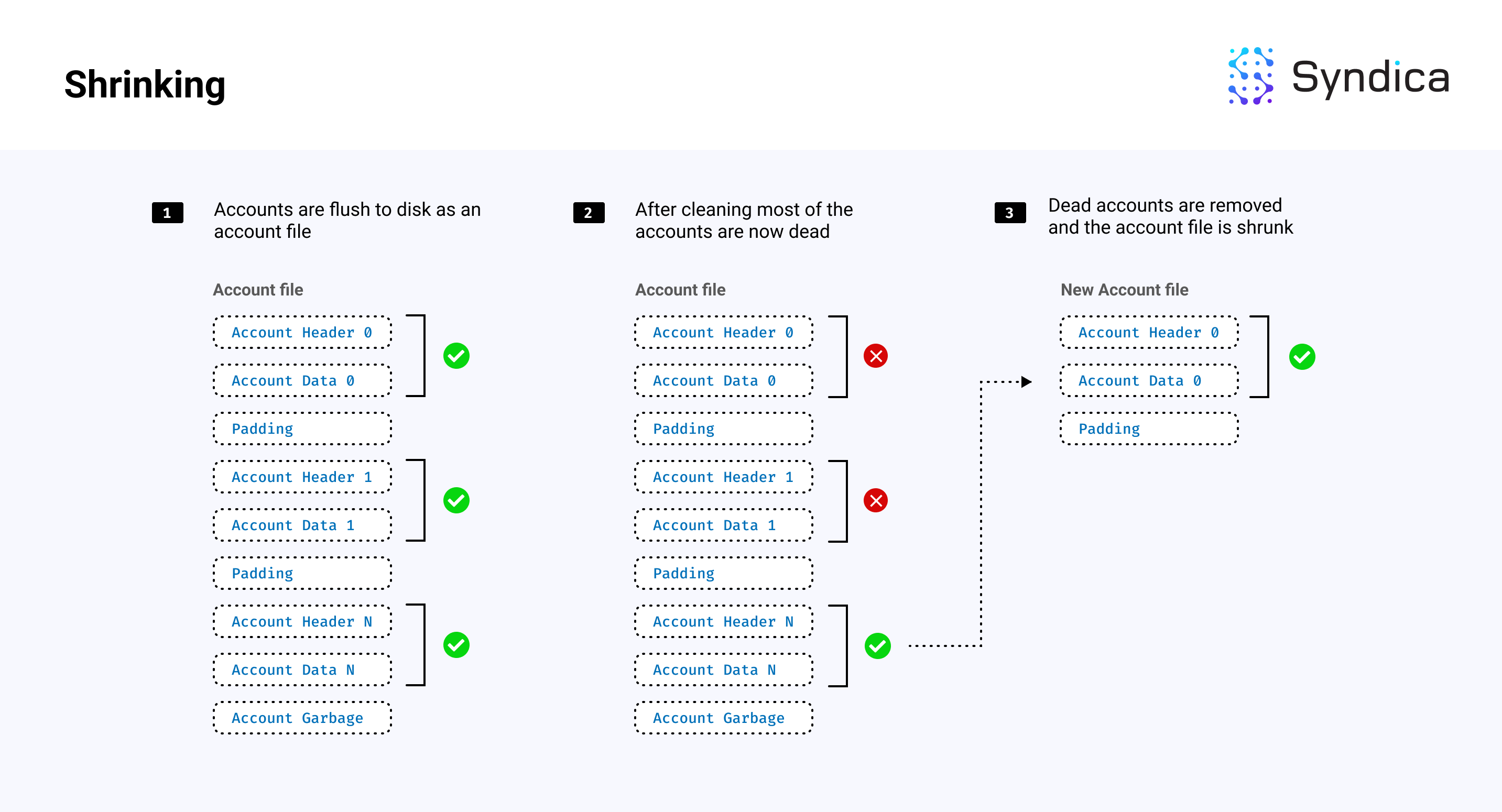
缩小
清理后,账户文件将包含“存活”和“死亡”账户,其中“死亡”账户已被“清理”,因此不再需要。当一个账户的文件中存活账户数量较少时,可以将这些账户复制到一个不包含死亡账户的较小文件中,从而节省磁盘内存。这被称为缩小。
注意: 由于清理从账户索引中删除了账户条目,因此要检查一个账户是否被清理(或被视为“死亡”),需要检查 (pubkey, slot) 元组是否存在于账户索引中。
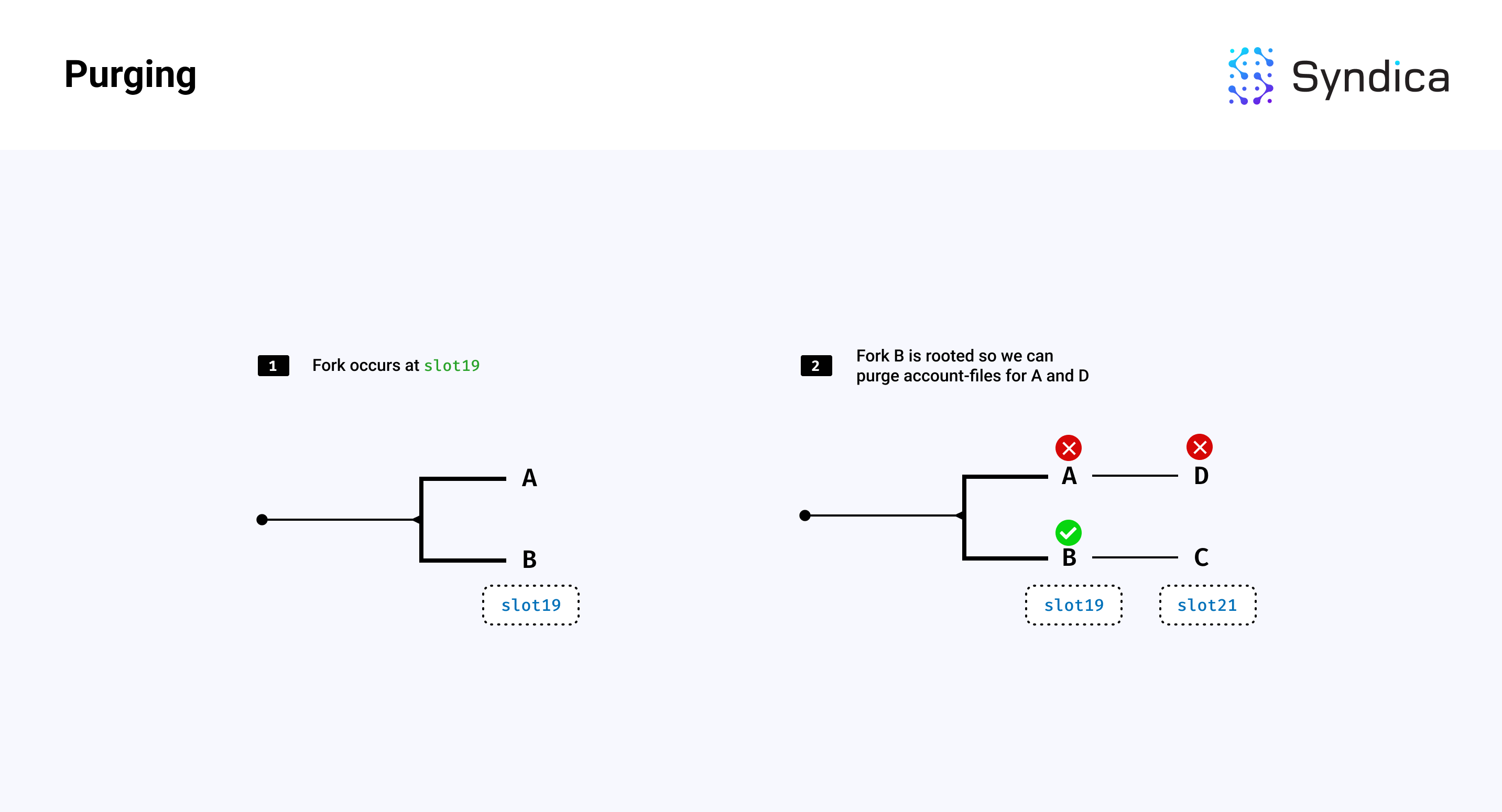
清除
我们还可以清除与已根植链分叉的插槽相关的账户数据。例如,如果存在一个分叉,并且一个分支变得根植,我们可以删除所有与另一个非根植分支相关的账户文件。
实现细节
在介绍了 AccountsDB 的高层组件后,接下来我们将深入探讨一些实现细节。
快照简介
我们将首先开始更详细地描述验证者如何从快照加载。
Solana 上有两种类型的快照:
- 完整快照,和
- 增量快照。
完整快照包括在特定插槽上网络上的所有账户。增量快照是更小的快照,仅包含与完整快照相比发生更改的账户。例如,如果网络处于插槽 100,则完整快照可能包含插槽 75 上的所有账户,而匹配的增量快照可能包含插槽 75 到插槽 100 之间的所有账户变化。
完整快照的创建可能昂贵,因为它们包含网络上的所有账户,而增量快照的创建相对便宜,因为它们仅包含网络账户的一个子集。考虑到这一现实,验证者的典型做法是偶尔创建完整快照,而更频繁地创建/更新增量快照。
完整快照遵循以下命名约定格式:
snapshot-{FULL-SLOT}-{HASH}.tar.zst
例如,snapshot-10-6ExseAZAVJsAZjhimxHTR7N8p6VGXiDNdsajYh1ipjAD.tar.zst 是插槽 10 上的完整快照,哈希为 ‘6ExseAZAVJsAZjhimxHTR7N8p6VGXiDNdsajYh1ipjAD’。
增量快照遵循命名约定格式:
incremental-snapshot-{FULL-SLOT}-{INCREMENTAL-SLOT}-{HASH}.tar.zst
例如,incremental-snapshot-10-25-GXgKvm3NMAPgGdv2verVaNXmKTHQgfy2TAxLVEfAvdCS.tar.zst 是在插槽 10 上建立的增量快照,并包含到插槽 25 的账户变化,哈希为 GXgKvm3NMAPgGdv2verVaNXmKTHQgfy2TAxLVEfAvdCS。
匹配的快照和增量快照将具有相同的 {FULL-SLOT} 值。当验证者启动时,由于它可以同时下载多个快照,它将找到 最新 的快照和匹配的增量快照进行加载和启动。
下载快照
要下载快照,验证者开始参与 gossip,以加入网络并识别其他节点。过了一段时间,潜在的下载快照的节点被识别为:
- 一个匹配的 shred 版本(即,匹配的网络版本/我们的硬分叉与他们的匹配)
- 一个有效的 RPC socket(即,我们可以从他们那里下载快照)
- 通过 gossip 共享的消息,表明他们有可供下载的快照
快照消息称为 SnapshotHashes(如下所示),这是一个 gossip 数据类型,包含:
- 最大可用完整快照的插槽和哈希
- 可用增量快照的插槽和哈希列表
pub const SnapshotHashes = struct {
from: Pubkey,
full: struct { Slot, Hash },
incremental: []struct { Slot, Hash },
wallclock: u64,
}验证者按顺序尝试从其可能的对等节点下载完整快照直到下载成功,优先选择具有更高插槽快照的节点。
注意: 如果我们有一个 '受信任' 验证者的列表(在启动时通过 CLI 提供),我们首先记录这些受信任的验证者发布的快照哈希。然后,我们仍然可以从任何验证者下载快照,但仅在快照的哈希匹配受信任验证者发布的哈希时才能下载。
要构建快照的下载 URL,我们使用节点的 IP 地址、RPC 端口和文件路径(基于前一部分提到的快照命名约定),构建下载 URL 并开始下载快照。下载速度会定期检查,看是否足够快。如果不够快,我们尝试从另一个节点下载。
一旦验证者下载了快照,它就会解压缩和解归档它,得到如下目录布局。
注意: 有关快照的规范,请参见 Richard Patel 的 Informal Guide to Solana Snapshots 。
账户索引架构
一旦我们有了快照,下一步就是构建 账户索引,它将公钥与账户的位置映射。
虽然索引可以被概念化为一个单一的映射,但实现将其拆分成多个独立的哈希表。我们将这些独立的哈希表称为 bins。
使用多个 bins 的目的是通过允许更多线程同时使用数据库来提高性能。如果使用单一映射来处理所有公钥,则单个线程中的单个操作将锁定整个数据库,从而防止其他线程在该操作完成之前与整个索引进行交互。通过 binning,每个操作只需锁定一个 bin。这使得其余的 bins 可用于其他线程。
为了将账户均匀分配到不同的 bins 中,我们需要一种快速的技术,以随意且确定性地将每个账户分配给一个 bin。每个 bin 由一个整数标识。每个账户由一个公钥标识。我们选择公钥中的前几位,将这些位转换为一个整数,并使用该整数选择账户应存储的 bin。由于账户公钥位均匀分布(即它们看起来是随机的),该技术使每个 bin 大致包含相同数量的账户。
/// 存储从Pubkey到账户位置的映射(AccountRef)
pub const AccountIndex = struct {
allocator: std.mem.Allocator,
// 引用的分配器(RAM或DISK)
reference_allocator: std.mem.Allocator,
// 分片哈希表
bins: []RwMux(RefMap),
// 计算器,用于知道公钥属于哪个 bin
calculator: PubkeyBinCalculator,
// 哈希表/bin 类型定义
pub const RefMap = SwissMap(Pubkey, AccountReferenceHead, pubkey_hash, pubkey_eql);
}注意: 计算公钥属于哪个 bin 的代码可以在 PubkeyBinCalculator 结构中找到。
N 位数据可以表示一个最大为 2^N 的数字。为了提高性能,我们希望有几千个 bins,因此我们使用公钥的前 13 位来分配 bins,将索引划分为 2^13 或 8192 个 bins。
注意: 基于前 N 位进行 bin 整理类似于在 gossip 中使用的方法(在本系列的 第一部分 中进行了讨论,涵盖了 Gossip Protocol)。
每个 bin 从公钥映射到指向账户引用的指针,账户引用被定义为以下 AccountRef 结构:
/// 账户的引用(在文件或缓存中)
pub const AccountRef = struct {
pubkey: Pubkey,
slot: Slot,
location: AccountLocation,
next_ptr: ?*AccountRef = null,
pub const AccountLocation = union(enum(u8)) {
File: struct {
file_id: u32,
offset: usize,
},
Cache: struct {
index: usize,
},
};
}为了减少内存分配(在性能上非常昂贵),我们将 bin 数据类型定义为 HashMap(Pubkey, *AccountRef)。这种数据类型使用对 AccountRef 的指针,该指针包含跨插槽的链表。
注意: 由于此哈希表在每个读写操作中都会使用,我们需要它快速,因此我们从头开始实现了自己的哈希表。有关更多详细信息,请阅读我们博客文章系列的第二部分,可以在 这里 找到。
这使我们可以在单个系统调用中分配一批引用,并通过添加新公钥或更新现有公钥的链表(而无需额外内存分配)来更新哈希表。
注意: 在 Agave 代码库中,他们对每个 bin 使用了 HashMap(Pubkey, Vec<AccountRef>)。在这种情况下,为一批账户添加新的引用将需要进行内存分配以调整每个更新键的向量大小。
完整架构在下图中描述:
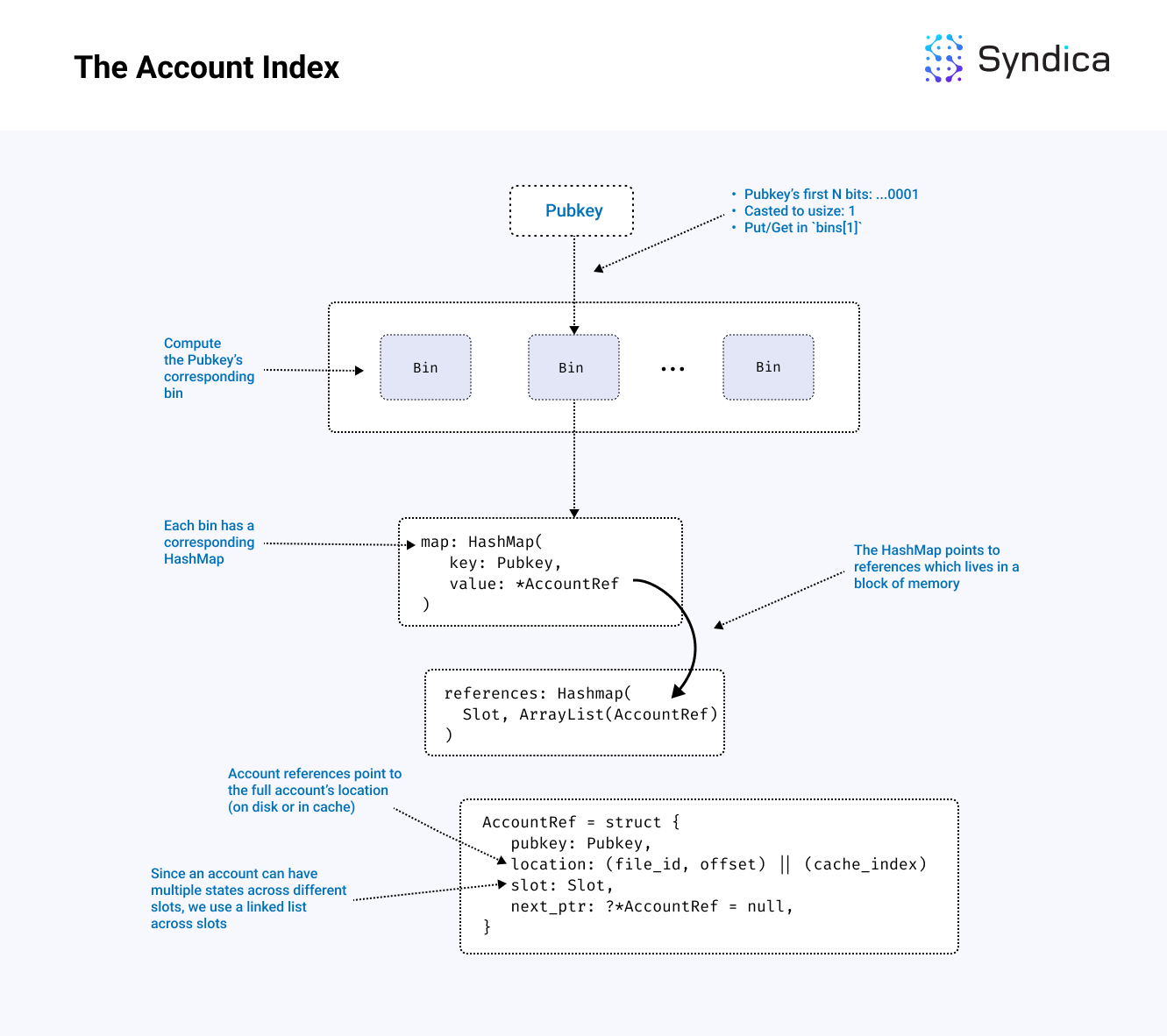
注意: 存储账户引用的内存块(上述图中的 references)也可以由磁盘内存支持,以减少内存需求。我们在本博客文章系列的第二部分讨论了如何高效使用磁盘内存,可以在 这里 找到。
生成账户索引
账户索引是在下载和解压缩快照后构建的。在 Sig 代码库中,构建索引的主要函数是 AccountsDB.loadFromSnapshot。
首先,找到所有账户文件路径,并在多个线程中进行处理。
对于每个账户文件路径,账户文件被验证和索引。具体来说,文件被映射到内存中,对于从文件中读取的每个账户,创建相应的账户引用并插入索引中。账户引用包括账户的 pubkey、插槽、file_id 和账户的位置偏移量。提取公钥的前几位以确定存储位置的 bin,并将 AccountRef 插入到该 bin 的哈希表中。
pub fn loadAndVerifyAccountsFiles(
self: *AccountsDB,
accounts_dir_path: []const u8,
file_names: [][]const u8,
accounts_per_file_est: usize,
) !void {
// 分配一批引用
var references = try ArrayList(AccountRef).initCapacity(
self.account_index.reference_allocator,
file_names.len * accounts_per_file_est,
);
for (file_names, 1..) |file_name, file_count| {
// 从 file_name 解析 "{slot}.{id}"
var fiter = std.mem.tokenizeSequence(u8, file_name, ".");
const slot = try std.fmt.parseInt(Slot, fiter.next().?, 10);
const file_id_usize = try std.fmt.parseInt(usize, fiter.next().?, 10);
// 打开账户文件
const abs_path = try std.fmt.bufPrint(&buf, "{s}/{s}", .{ accounts_dir_path, file_name });
const accounts_file_file = try std.fs.cwd().openFile(abs_path, .{ .mode = .read_write });
var accounts_file = try AccountFile.init(accounts_file_file, file_info, slot);
// 读取账户并用引用填充 `references`
try self.account_index.validateAccountFile(&accounts_file, bin_counts, &references);
}
// 插入到 bin 哈希表并构建引用链表
for (reference.items) |*ref| {
_ = self.account_index.indexRefIfNotDuplicateSlot(ref);
}
}注意: 当验证者为某个插槽构建快照并打包这些账户文件时,由于实现原因,验证者将继续向账户文件写入更新插槽的账户数据,而这些数据将会在快照的账户文件的末尾部分包含。由于这些数据不对应于快照的插槽,因此应忽略这些数据。当从文件中读取账户时,我们需要从快照元数据文件中读取长度(特别是,AccountsDB 元数据),以知道最后一个有用数据索引。
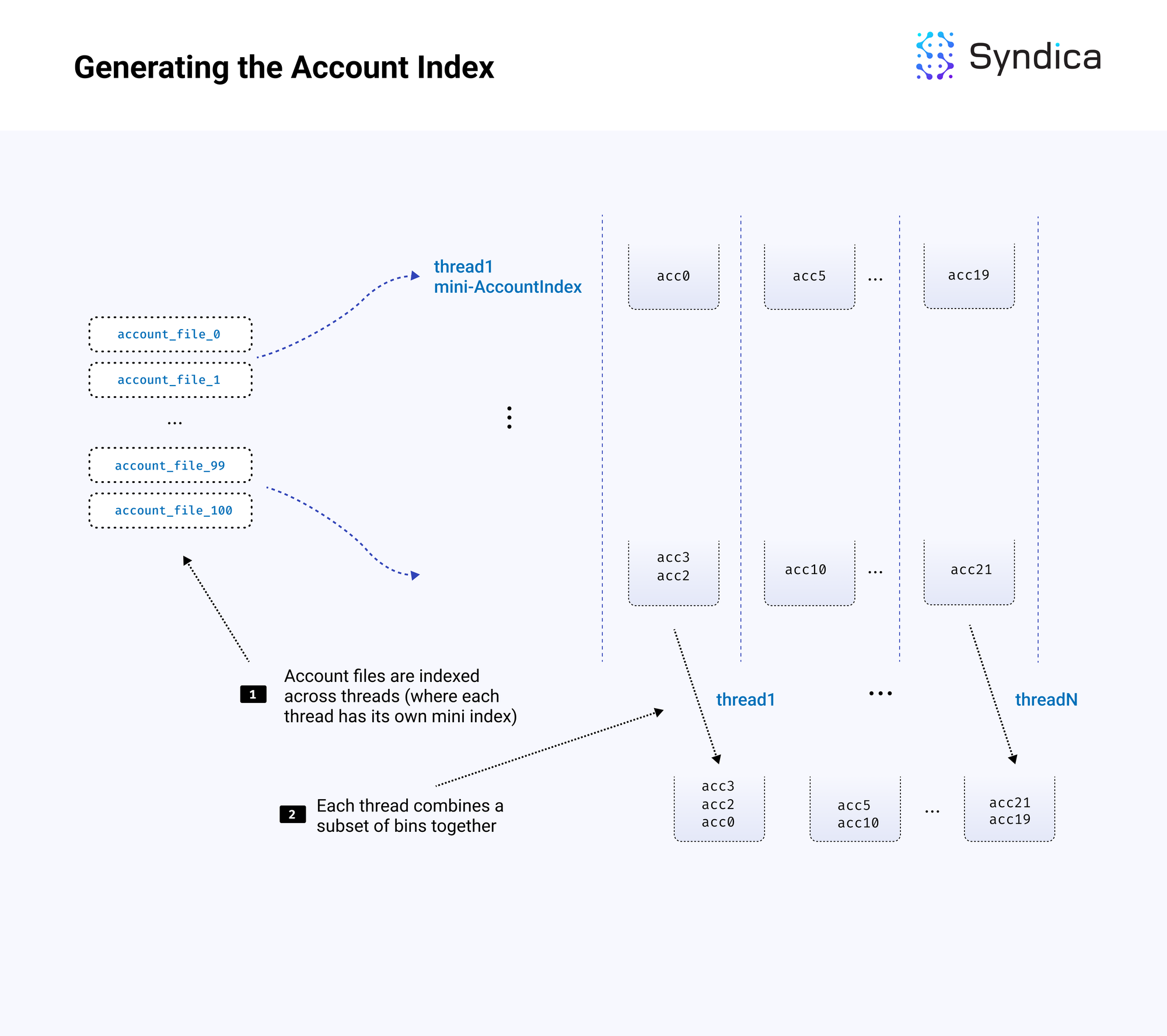
索引生成是并行进行的,通过在多个线程之间分配工作。每个线程创建自己的独立小索引,来自账户文件的子集。每个小索引与完整索引的 bin 数量相同,但仅包含部分账户。这种方法允许每个线程在不需要与其他线程共享内存的情况下不停地工作(这会导致锁竞争和性能下降)。
/// 从快照加载账户文件并生成账户索引
pub fn loadFromSnapshot(
self: *AccountsDB,
// 账户文件的位置
accounts_path: []const u8,
n_threads: u32,
) !void {
// 读取账户文件
var files = try readDirectory(self.allocator, accounts_dir_iter);
const filenames = files.filenames;
// 设置小索引
var loading_threads = try ArrayList(AccountsDB).initCapacity(
self.allocator,
n_threads,
);
for (0..n_threads) |_| {
var thread_db = try AccountsDB.init(
per_thread_allocator,
self.logger,
// 与主索引相同数量的 bins
.{ .number_of_index_bins = self.config.number_of_index_bins },
);
loading_threads.appendAssumeCapacity(thread_db);
}
// 生成线程以加载并索引账户
try spawnThreadTasks(
&handles,
// 主入口点
loadAndVerifyAccountsFilesMultiThread,
.{
loading_threads.items,
// 在线程之间分配文件名
filenames.items,
accounts_path,
},
filenames.items.len,
n_parse_threads,
);
// 合并线程索引到主索引
try self.mergeMultipleDBs(loading_threads.items, n_threads);
}在创建小索引后,必须将其合并到完整索引中。每个小索引都有一个小 bin 0。将每个小 bin 0 合并为一个哈希表,该哈希表成为完整索引中的 bin 0。对每个 bin 重复此过程,直到我们有一个包含 N 个 bins 的单一索引。
合并过程也是使用多个线程执行的。 假设使用 10 个线程进行合并。第一个线程将负责将来自每个索引的前 10% 的 bins 合并到完整索引的前 10% 的 bins。每个线程生成一组 bins,这些 bins 按原样包含在完整索引中。同样,我们有一种避免竞争的方法,为每个线程提供自己的孤立数据。
pub fn combineThreadIndexesMultiThread(
index: *AccountIndex,
thread_dbs: []AccountsDB,
// 任务特定
bin_start_index: usize,
bin_end_index: usize,
thread_id: usize,
) !void {
const total_bins = bin_end_index - bin_start_index;
// 对于此线程分配的每个 bin
for (bin_start_index..bin_end_index, 1..) |bin_index, iteration_count| {
const index_bin = index.getBin(bin_index);
// 计算各线程的引用总数
var bin_n_accounts: usize = 0;
for (thread_dbs) |*thread_db| {
var thread_bin = thread_db.account_index.getBin(bin_index);
bin_n_accounts += thread_bin.count();
}
// 确保主哈希表可以容纳所有线程的引用
if (bin_n_accounts > 0) {
try index_bin.ensureTotalCapacity(@intCast(bin_n_accounts));
}
// 对于每个线程的 bin
for (thread_dbs) |*thread_db| {
var thread_bin = thread_db.account_index.getBin(bin_index);
// 将所有引用插入主索引的链表
var ref_iter = thread_bin.iterator();
while (ref_iter.next()) |thread_ref| {
index.indexRef(thread_ref);
}
}
}
}以下是完整的加载过程:
写入账户
在写入与插槽关联的新账户批次时,账户首先写入到缓存中(即 accounts_cache 字段),这是从插槽到账户列表的映射(即,HashMap(Slot, ArrayList(Account)))。
/// 将一批账户写入缓存并更新索引
pub fn putAccountSlice(
self: *Self,
accounts: []Account,
pubkeys: []Pubkey,
slot: Slot,
) !void {
// 将账户写入缓存
{
const account_cache, var account_cache_lg = self.account_cache.writeWithLock();
defer account_cache_lg.unlock();
try account_cache.putNoClobber(slot, .{ pubkeys, accounts });
}
// 分配一批引用
var references = try ArrayList(AccountRef).initCapacity(
self.account_index.reference_allocator,
accounts.len,
);
for (0..accounts.len) |i| {
// 创建一个引用
const ref_ptr = references.addOneAssumeCapacity();
ref_ptr.* = AccountRef{
.pubkey = pubkeys[i],
.slot = slot,
.location = .{ .Cache = .{ .index = i } },
};
// 将引用插入 bin 并更新链表
_ = self.account_index.indexRefIfNotDuplicateSlot(ref_ptr);
}
}当插槽根植时,相应的账户将从缓存中移除并写入新的账户文件中。
读取账户
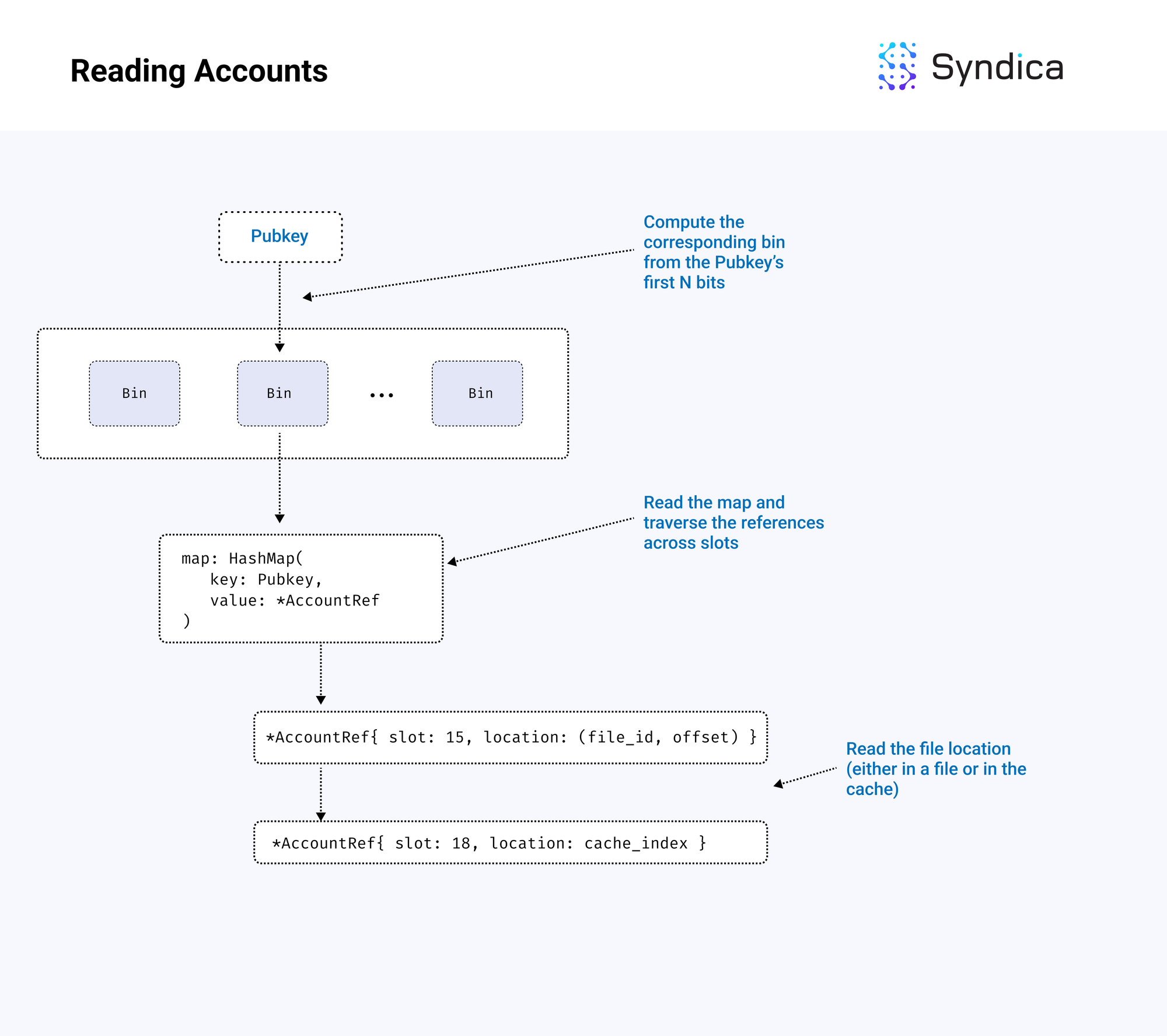
读取与公钥关联的账户的步骤如下:
- 计算公钥的 bin 索引,使用公钥的前 N 位
- 在 bin 的哈希表中查找公钥
- 遍历账户引用链表,直到找到特定插槽引用
- 使用引用的位置信息找到账户(在文件中或在缓存中)
背景任务
我们已经讨论了 AccountsDB 中读取/写入的工作原理;接下来我们将讨论 AccountsDB 如何确保内存的有效使用。
这包括在后台执行的四个任务:
后台任务的核心逻辑是:
- 获取最大的根植插槽
- 刷新小于或等于该根植插槽的插槽
- 清理已刷新账户文件
- 缩小在清理后仍然包含少量存活账户的账户文件
- 删除空账户文件或对应于已弃用分叉的账户
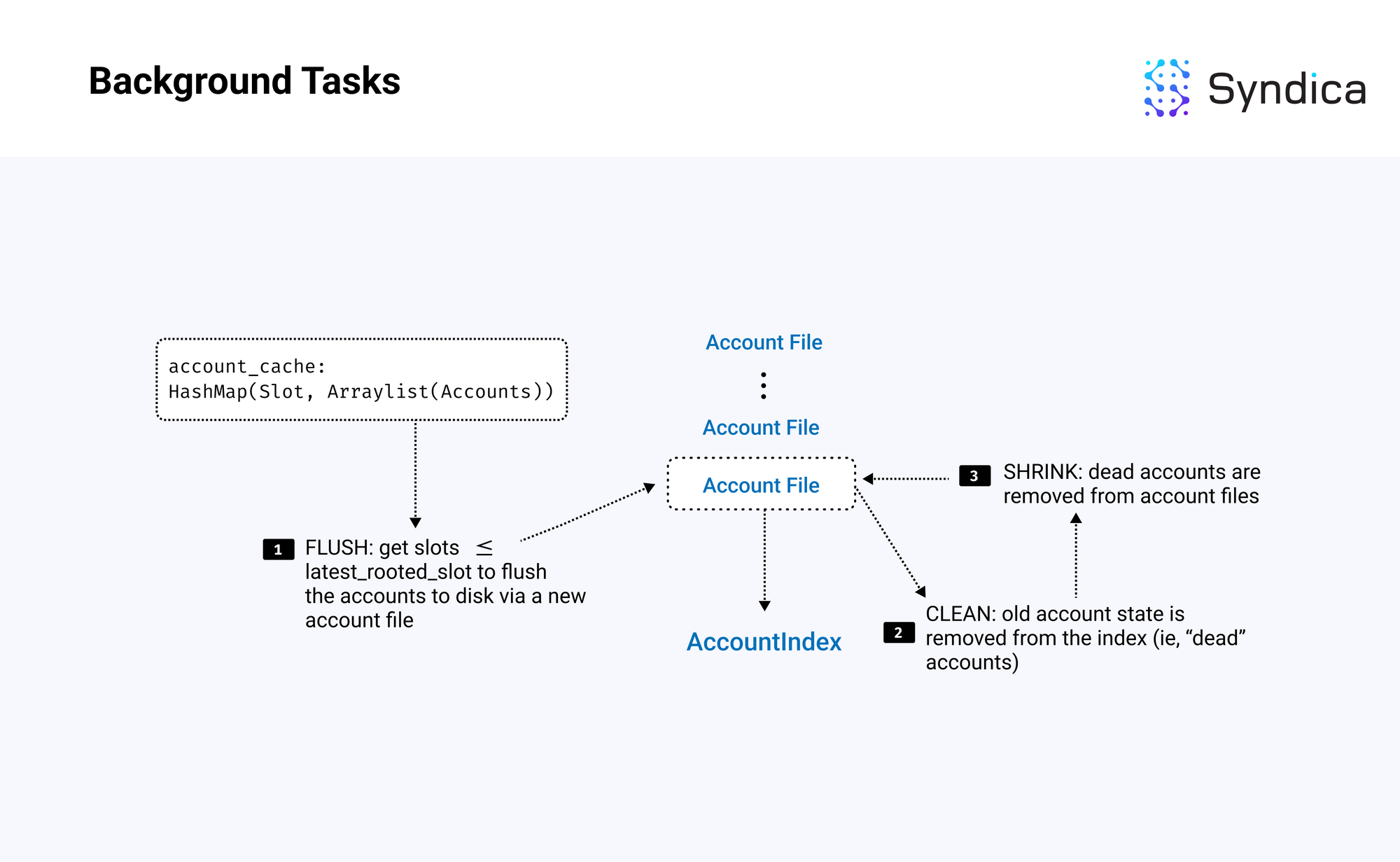
刷新
第一个后台任务是刷新,它从账户缓存读取并将与根植插槽相关的账户推送到新的账户文件的磁盘中。
注意: 这意味着每个根植插槽将有一个与之相关的账户文件,包含在该插槽中更改的账户。
刷新过程中的主要逻辑是 AccountsDB.flushSlot 函数,其接收一个插槽并执行以下操作:
- 检索缓存中与插槽相关的所有账户
- 计算账户的总字节大小
- 分配一个新的账户文件以写入这些账户
- 将账户写入账户文件
- 更新账户引用以指向新的账户文件
- 从缓存中移除这些账户
- 将账户文件排队以清理(使用
unclean_account_files参数)
/// 将一个插槽从缓存刷新到账户文件并更新索引
pub fn flushSlot(self: *Self, slot: Slot, unclean_account_files: *ArrayList(FileId)) !void {
// 获取缓存中与插槽相关的公钥 + 账户
const pubkeys, const accounts: []Account = account_cache.get(slot) orelse return error.SlotNotFound;
// 创建一个账户文件以写入账户到其中
var size: usize = 0;
for (accounts) |*account| size += account.getSizeInFile();
const file, const file_id, const memory = try self.createAccountFile(size, slot);
// 将账户写入文件
var offset: usize = 0;
for (0..accounts.len) |i| {
offset += accounts[i].writeToBuf(&pubkeys[i], memory[offset..]);
}
// 更新引用以指向文件
for (0..accounts.len) |i| {
// 获取链表头引用
var head_reference = self.account_index.getReference(&pubkeys[i]);
// 查找链表并将其更新为指向文件
var curr_ref: ?*AccountRef = head_reference.ref_ptr;
while (curr_ref) |ref| : (curr_ref = ref.next_ptr) {
if (ref.slot == slot) {
ref.location = .{
.File = .{ .file_id = file_id, .offset = offsets[i] }
};
break;
}
}
}
// 释放旧内存
self.allocator.free(accounts);
self.allocator.free(pubkeys);
// 排队以清理
try unclean_account_files.append(file_id);
}清理
清理查找“旧”账户或零 lamports 账户,并将其从索引中删除。主要清理方法是 AccountsDB.cleanAccountFiles。
对于每个排队清理的账户文件,该方法迭代存储在账户文件中的每个账户,查看它们在索引中的位置,并查找任何“旧”状态(例如,多个根植插槽)以从索引中删除。
在删除旧引用时,我们只考虑小于最大根植插槽的引用(这意味着我们仅考虑具有根植插槽的引用)。我们只想保留最新的引用(并从索引中删除所有其他引用)。如果这个引用的 lamports 也为零,我们可以将其从索引中删除。
在从索引中删除引用时,我们还会增加相应账户文件的 dead_accounts 计数器。如果一个账户文件在清理后包含所有死亡字节,我们会排队以删除账户文件。如果账户文件包含大多数死亡字节(基于某个阈值),我们会排队以缩小账户文件。
缩小
缩小从账户文件中移除死亡账户,以减少用于磁盘内存的数量,通过用不包含死亡账户的新较小文件替换它们。主要函数为 AccountsDB.shrinkAccountFiles。
对于每个被排队缩小的账户文件,该方法遍历账户以寻找存活账户。更具体地说,对于文件中的每个账户,我们通过检查 (pubkey, slot) 元组 是否存在于索引。如果它确实存在于索引中,那么账户仍然是存活的(并未被清理),因此将其复制到新的较小账户文件。
然后更新索引以指向新账户文件的位置。
清除
最后,当一个新插槽被根植时,会从缓存中清除与分叉插槽相关的账户,并删除索引数据。此外,当账户文件完全清理且仅包含死亡账户时,我们会删除完整账户文件。
基准测试
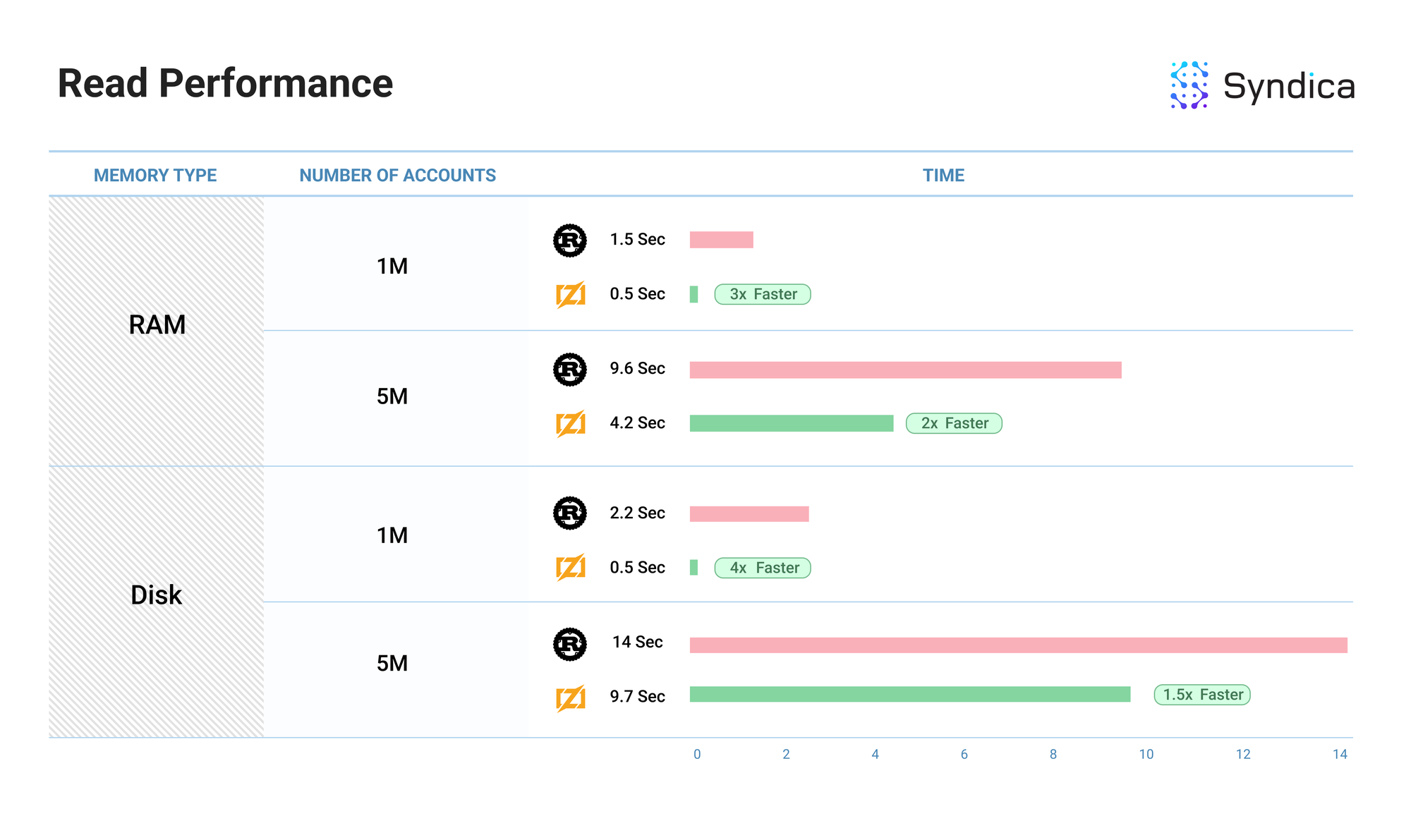
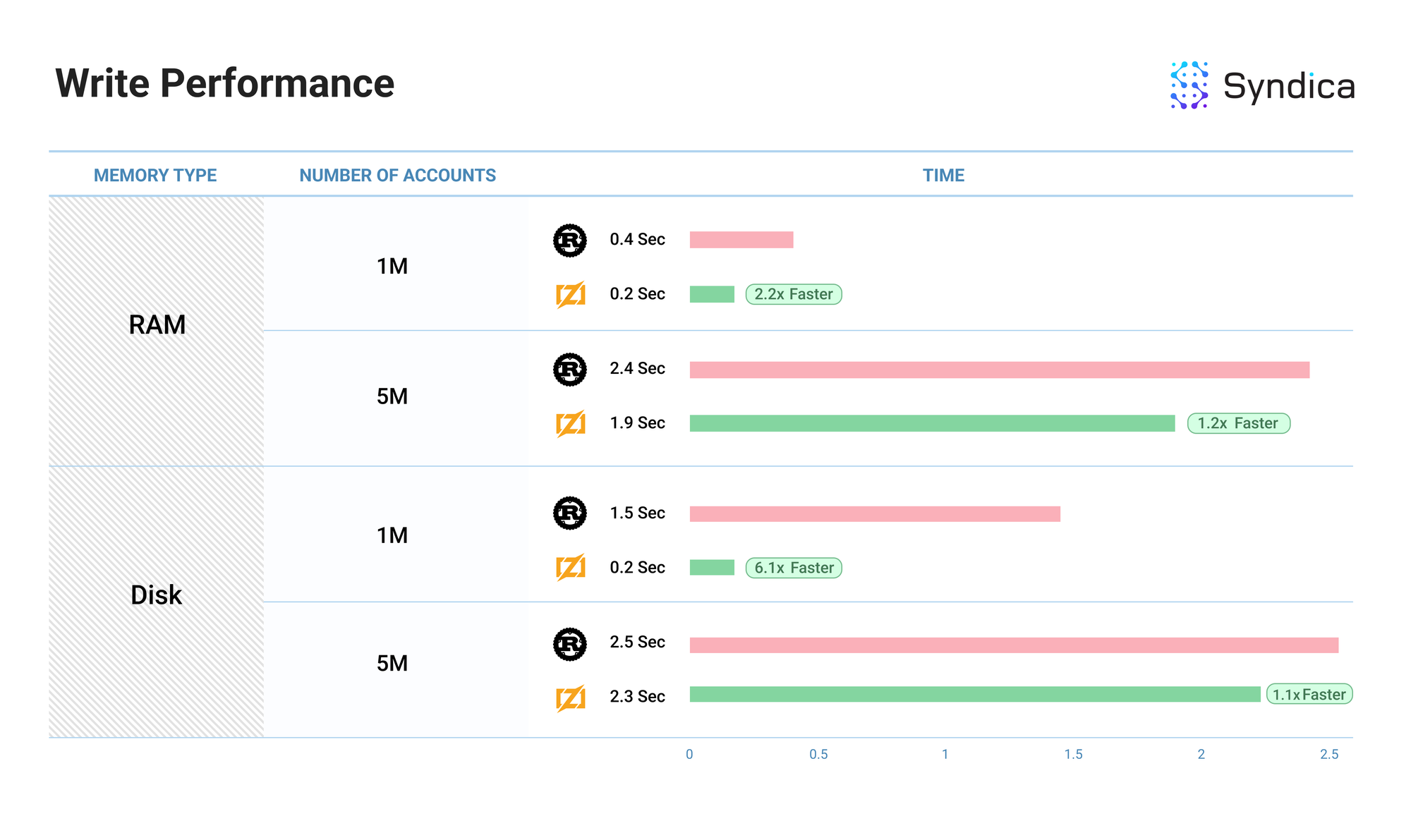
我们将我们的账户读写性能与 Agave 客户端 进行了基准测试。
基准测试测量了将 N 个账户 写入 数据库所需的时间(显示在“账户数量”列中)——每个账户都与唯一的公钥关联——以及随后从数据库中 读取 这些相同账户所需的时间。我们还使用 RAM 和磁盘内存对账户索引进行了基准测试(显示在“内存类型”列中)。
注意: “性能”列显示了性能的相对改善。Rust 的值将始终为 1,因为这是基准性能。
完整的 Sig 基准代码可以在 这里 找到。
注意: 这些基准显示了我们当前的 初始 实现 AccountsDB,并且随着我们构建更多的验证者客户端,可能会发生更改。此外,这些基准是单线程的,因此在多线程环境中,性能可能会有所不同。
结论
AccountsDB 是 Solana 节点的一个重要组成部分。它管理所有账户的状态,确保交易的准确执行和区块链的完整性。
本文涵盖了关键实现细节,包括快照的组织方式、账户索引的设计、如何读取和写入账户,以及后台任务如何有效管理内存。我们希望这篇文章能帮助社区更深入地理解 Solana 验证者的运行方式。
我们正在构建开源的 Sig;欢迎随时访问完整的 AccountsDB 代码 这里。
如果你是一位优秀的工程师,喜欢在协作快速的环境中工作,并且对推动 Solana 生态系统的进步感到兴奋,我们正在积极招募,并期待与你联系:
https://jobs.ashbyhq.com/syndica/15ab4e32-0f32-41a0-b8b0-16b6518158e9
- 原文链接: blog.syndica.io/sig-engi...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





