从零开始的聚合器开发: Lotus Router 合约解析
- WongSSH
- 发布于 2025-04-14 16:29
- 阅读 3042
Lotus Router是一个专门针对MEV交易的交易路由合约,支持多种DeFi协议,如Uniswap V2/V3等。文章详细介绍了合约的核心逻辑、数据结构及压缩编码方法,展示了如何在处理复杂回调及数据解码时,使用内联汇编来优化执行效率和减少calldata体积,并指出代码中存在重入攻击的风险。
概述
Lotus Router 是 jtriley2p 开发的一个用于 MEV 的交易路由的合约。此处我们需要特别强调该路由合约是适用于 MEV 交易的,该路由合约完全不会处理来自 Uniswap 合约的回调内的数据,这使得交易发起者必须预先计算出精确数值已进行交易。
目前路由合约支持以下几个协议:
- Uniswap v3
- Uniswap v2
- Uniswap Flashloan
- ERC20 Transfer and TransferFrom
- WETH Wrap and Unwrap
- Dynamic Contract Call
实际上,看上去功能很多,但合约并不复杂。合约的核心功能主要聚集在使用内联汇编进行 Calldata 编码和解码上。我认为 Lotus Router 可以作为学习内联汇编后的第一个实战项目。
由于 Lotus Router 涉及到了 MEV 方面的内容,jtrileyp2p 编写此合约后不久就被其先前所在的企业发起了 版权投诉,认为 jtrileyp2p 窃取了公司机密来完成了该路由合约的编写。在此处,我们复制一段来自 Lotus Router Readme 的一段话:
从事搜索和解决问题的公司像我们一样,反复构建前沿的路由技术。
搜索者和解决者用“阿尔法衰退”等伪学术术语为保密辩护,以囤积最前沿的技术和伴随而来的资本。
我们厌倦了不断重复构建同样的软件。
我们厌倦了签署一份又一份的保密协议。
我们厌倦了不断重复自己。
所以我们,研究者和开发者,编写该软件以意图使路由技术的前沿民主化。
所以我们,研究者和开发者,编写该软件以意图解放一个寄生行业的秘密。
所以我们,研究者和开发者,编写该软件以意图揭示隐藏在字节码混淆器和我们当地精英主义背后的优雅简约。幸好,我们拥有 IPFS 作为去中心化工具。读者可以非常简单的使用 bafkreif2ffb2kghamkdjp5pcgrsxu26hx42w3imujcq6zeqacwzsg5pbla 获得代码的 zip 压缩版本,读者也可以选择直接使用 pinata gateway 下载。
基础执行逻辑
对于所有的路由合约,我们都可以将路由合约视为一个虚拟机,该虚拟机接受来自 calldata 的指令,然后进行对应的动作。比如我们可以想路由合约传入以下 2 条指令:
- 使用 Uniswap V2 将 ETH 兑换为 USDC
- 使用 Uniswap V3 将 USDC 兑换为 USDT
路由合约就会读取指令 1 完成第 1 步兑换,然后读取指令 2 完成第 2 步操作。我们首先不考虑 Uniswap 系列的回调情况,我们只需要将 calldata 分割成一系列指令,然后在循环中依次执行就可以。我们可以编写如下代码:
fallback() external payable {
Ptr ptr = findPtr();
Action action;
bool success = true;
while (success) {
(ptr, action) = ptr.nextAction();
if (action == Action.Halt) {
assembly {
stop()
}
} else if (action == Action.DynCall) {
bool canFail;
address target;
uint256 value;
BytesCalldata data;
(ptr, canFail, target, value, data) = BBCDecoder.decodeDynCall(ptr);
success = dynCall(target, value, data) || canFail;
} else {
success = false;
}
}此处的 ptr 并不是指内存指针而是 calldata 指针,记录我们目前在 calldata 内读取的位置。而 nextAction 是指读取下一个 bytes,其实现如下:
function nextAction(
Ptr ptr
) pure returns (Ptr, Action action) {
assembly {
action := shr(0xf8, calldataload(ptr))
ptr := add(ptr, 0x01)
}
return (ptr, action);
}我们会在后文介绍路由合约特殊的 calldata 编码逻辑时再次详细介绍以上代码的含义。此处我们只需要知道 action 其实是一个枚举类型,被编码在每一个动作最前面。 action 的编码如下:
<action> ::=
| ("0x00")
| ("0x01" . <swap_uni_v2>)
| ("0x02" . <swap_uni_v3>)
| ("0x03" . <flash_uni_v3>)
| ("0x04" . <transfer_erc20>)
| ("0x05" . <transfer_from_erc20>)
| ("0x06" . <transfer_from_erc721>)
| ("0x07" . <transfer_erc6909>)
| ("0x08" . <transfer_from_erc6909>)
| ("0x09" . <deposit_weth>)
| ("0x0a" . <withdraw_weth>)
| ("0x0b" . <dyn_call>) ;继续回到 fallback 函数内的 while (success) { 循环,该循环最终跳出循环的条件是:
success = false该条件出现的原因包含解析出的action没有被定义或者是在不允许调用失败(canFail = False)的情况下出现了调用失败action = 0x00该条件本质上就是读取到了 calldata 的末尾。根据CALLDATALOAD的定义,当 calldataload 读取大于当前 calldata 长度的数据时,calldataload 将会返回0
此处可能会令读者迷惑的是 canFail 变量。简单来说, call 操作失败并不会直接导致当前执行中断,我们可以不处理返回的错误继续执行合约代码。当然,在 solidity 中,默认情况下调用失败会直接导致合约中断执行。在使用 try-catch 是一个例外情况。
危险警告:我们上述 while 循环内的代码并没有做重入攻击防护,实际上 Lotus Router 源代码内也没有处理 call 之后的重入锁定。没有做重入防护的原因是路由合约大部分情况下内部并没有资金,一般来说我们会在调用时转入资金,在调用结束后将所有资金从路由合约内转出,更加重要的是路由合约应该仅于受信任合约交互。当然,假如读者认为存在进行重入防护的情况,读者可以自己编写重入锁定相关的代码。
接下来,我们需要处理一种最复杂的情况。Uniswap V2 和 Uniswap V3 都存在 callback 的回调逻辑,我们需要对回调逻辑进行特殊处理,这是因为一旦发生回调,我们上下文中的 calldata 会被 Uniswap 回调中的 calldata 会 覆盖原有上下文中的 calldata。我们以 Uniswap V3 的 callback 为例,以下代码来自 Uniswap V3 合约:
function uniswapV3SwapCallback(
int256 amount0Delta,
int256 amount1Delta,
bytes calldata data
) external;简单来说,我们可以在调用 swap 等函数时,传入 data 参数,然后 Uniswap 在执行 swap 结束后,会使用反向调用发起交易合约,Uniswap V3 内存在以下代码:
IUniswapV3SwapCallback(msg.sender).uniswapV3SwapCallback(amount0, amount1, data);我们会使用 data 参数来解决回调覆盖上下文 calldata 的问题。具体来说,我们会将当前没有完成的 calldata 以 data 的形式直接发送给 Uniswap V3。这样,我们会接受回调时就可以获得之前的上下文信息。这意味着在接受回调后,我们需要在新的上下文 calldata 内检索出我们需要的 data。仍以 uniswapV3SwapCallback 为例,我们需要跳过 amount0Delta 和 amount1Delta,直接处理 data 字段。上文中出现的 findPtr 就是进行该操作的,我们可以看到其实现如下:
function findPtr() pure returns (Ptr) {
uint256 selector = uint256(uint32(msg.sig));
if (selector == takeAction) {
return Ptr.wrap(0x04);
} else if (selector == uniswapV2Call) {
return Ptr.wrap(0xa4);
} else if (selector == uniswapV3SwapCallback) {
return Ptr.wrap(0x84);
} else if (selector == uniswapV3FlashCallback) {
return Ptr.wrap(0x84);
} else {
revert Error.UnexpectedEntryPoint();
}
}我们会直接跳过不需要的 amount0Delta 等信息直接进入 data 字段,然后继续从 data 内读取数据。值得注意的是,此时路由合约的代码执行更加类似递归系统。下图展示进行 A -> B -> C 的流程,与我们的预期并不一致,在 Uniswap V3 中,我们协议先进行 B -> C 的兑换,然后再进行 A -> B 的兑换。注意,Lotus Router 并不会自动帮助用户进行代币转账操作,下图中的由 Lotus Router 发起的 trasfer A 和 transfer B 都需要调用者自己将其编码到 calldata 内部。
sequenceDiagram
Lotus->>+MarketBC: swap(B, C)
MarketBC-->>Lotus: transfer C
MarketBC->>+Lotus: uniswapV3SwapCallback
Lotus->>+MarketAB: swap(A, B)
MarketAB-->>Lotus: transfer B
MarketAB->>+Lotus: uniswapV3SwapCallback
Lotus-->>MarketAB: transfer A
Lotus-->>MarketBC: transfer B
Lotus->>-MarketAB: return
MarketAB->>-Lotus: return
Lotus->>-MarketBC: return
MarketBC->>-Lotus: return
非常幸运的是,Uniswap V4 引入了 Flash Account 系统,我们可以以任意顺序进行兑换只需要在最后补齐代币即可
上述递归流程可以被拆分为如下流程:
sequenceDiagram
Lotus->>+MarketBC: swap(B, C)
MarketBC-->>Lotus(1): transfer C
MarketBC->>+Lotus(1): uniswapV3SwapCallback
Lotus(1)->>+MarketAB: swap(A, B)
MarketAB-->>Lotus(2): transfer B
MarketAB->>+Lotus(2): uniswapV3SwapCallback
Lotus(2)-->>MarketAB: transfer A
Lotus(2)-->>MarketBC: transfer B
Lotus(2)->>-MarketAB: return
MarketAB->>-Lotus(1): return
Lotus(1)->>-MarketBC: return
MarketBC->>-Lotus: return
总结来说,对于常规调用,Lotus Router 会使用 while 循环逐个处理,但对于带有回调的情况,Lotus Router 会将未执行的 calldata 作为参数发送出去,然后在回调中使用 findPtr 寻找之前传入的未执行 calldata。
压缩编码
众所周知,solidity 的 ABI 编码是没有经过优化的,使用 solidity 编码获得的 calldata 体积往往较大。大部分路由合约都会有自己的一套独特的压缩编码方法。Lotus Router 就有一套自己的编码格式,该编码格式受到了 bigbrainchad.eth 的启发。这套编码方法的核心是不进行任何前导 0 的填充以降低 calldata 体积。在上文中,我们已经展示过了 action 的情况,不同的参数代表后续 calldata 代表的动作。在 action 后,我们就需要指定具体的动作内容,我们此处以 ERC20 代币的转移为例,ERC20 代币转账的 calldata 可以被编码为以下格式:
<transfer_erc20> ::=
. <can_fail_bool>
. <token_byte_len_u8>
. <token>
. <receiver_byte_len_u8>
. <receiver>
. <zero_for_one_bool>
. <amount_byte_len_u8>
. <amount> ;can_fail_bool 指当前调用是否可失败,而 token_byte_len_u8 代表代币地址的长度,Lotus Router 并不对任何参数进行前缀 0 补全,所以我们需要使用 token_byte_len_u8 手动指定 token 代币地址的长度。 receiver_byte_len_u8 和 receiver 的组合同理。 zero_for_one_bool 由于该参数属于 bool 类型,其长度固定为 1 bit,所以我们不需要指定其长度。 amount_byte_len_u8 和 amount 也是因为 amount 的长度并不确定,所以需要使用 amount_byte_len_u8 指定。简单来说,在 Lotus Router 内除了 bool 类型之外的所有类型都是被视为动态类型需要指定长度的。
由于 Uniswap V2 等兑换涉及到递归过程,所以 Uniswap V3 等编码方法较为特殊。以 Uniswap V3 为例:
<swap_uni_v3> ::=
. <can_fail_bool>
. <pool_byte_len_u8>
. <pool>
. <recipient_byte_len_u8>
. <recipient>
. <zero_for_one_bool>
. <amount_specified_byte_len_u8>
. <amount_specified>
. <sqrt_price_limit_x96_byte_len_u8>
. <sqrt_price_limit_x96>
. <data_byte_len_u32>
. <data> ;我们可以看到相比于常规的 transfer_erc20 编码, swap_uni_v3 增加了 data_byte_len_u32 和 data 内容。其中, data_byte_len_u32 代表 data 的长度,而 data 部分则代表其他的交易数据,比如我们可以在 data 部分写入 transfer_erc20 的数据。
在具体执行流程中,当路由合约执行 swap_uni_v3 动作时,该合约会将 data 部分的数据作为附加数据发送给 Uniswap 的合约,然后在 callback 流程中继续执行 data 内的动作。
当我们了解完上述内容后,我们可以阅读 BBCDecoder 内的代码。BBCDecoder 的核心作用就是将我们压缩后的 action 进行解码操作。此处以 decodeSwapUniV3 为例介绍。
按照惯例,我们首先观察函数的定义:
function decodeSwapUniV3(
Ptr ptr
)
internal
pure
returns (
Ptr nextPtr,
bool canFail,
UniV3Pool pool,
address recipient,
bool zeroForOne,
int256 amountSpecified,
uint160 sqrtPriceLimitX96,
BytesCalldata data
)
{该函数会接受 ptr 作为输入。ptr 指当前 Router 在 calldata 内读取的指针。我们会在后文介绍 ptr 的具体实现。而 BytesCalldata 也是一个类似指针的数据类型,指向 swap_uni_v3 内的 data 在 calldata 内部的起始位置。我们会在后文介绍 Lotus Router 调用 UniV3Pool 内的 swap 函数时再次介绍。
在具体的解码流程中,我们首先解码 canFail 变量,使用的代码如下:
nextPtr := ptr
canFail := shr(u8Shr, calldataload(nextPtr))此处我们首先使用 calldataload 在 nextPtr 部分读取已有的 calldata 到 EVM 的栈顶,然后使用 shr 将读取的 calldata 向右移动 uint256 internal constant u8Shr = 0xf8; 位。右移结束后,当前栈内仅剩余 canFail 变量。由此,我们就完成了 canFail 的解码。
接下来,我们需要读取第一个包含长度的变量 pool。我们首先读取长度信息:
nextPtr := add(nextPtr, 0x01)
nextByteLen := shr(u8Shr, calldataload(nextPtr))
nextBitShift := sub(0x0100, mul(0x08, nextByteLen))
nextPtr := add(nextPtr, 0x01)此处第一步 nextPtr := add(nextPtr, 0x01) 的目的是跳过刚刚读取的 canFail 变量。calldataload 会按照 bytes 为单位读取数据,所以此处只需要将原有的 nextPtr 增加 1 即可,此时我们的 calldata 内的指针会向右移动 8 bit 跳过刚刚读取的 canFail 变量。 然后类似读取 canFail,我们可以使用 nextByteLen := shr(u8Shr, calldataload(nextPtr)) 较为简单的读取 pool 的长度信息。接下来,我们需要计算 pool 需要右移的数量。正如上文所述,Lotus Router 编码的核心是通过长度信息节约了 pool 的前缀 0 ,此处我们需要将 pool 前缀 0 进行复原。对前缀 0 的计算是简单的,我们只需要使用 nextBitShift := sub(0x0100, mul(0x08, nextByteLen)) 。最后,我们将 nextPtr 增加 1 以跳过当前的 pool_byte_len_u8 变量。
当我们使用 pool_byte_len_u8 计算出 pool 前缀 0 的数量后,我们可以简单的使用读取 256bit 然后右移的方案较为方便的获取 pool 变量:
pool := shr(nextBitShift, calldataload(nextPtr))后续 recipient 和 zeroForOne 的解码流程类似,代码如下:
nextPtr := add(nextPtr, nextByteLen)
nextByteLen := shr(u8Shr, calldataload(nextPtr))
nextBitShift := sub(0x0100, mul(0x08, nextByteLen))
nextPtr := add(nextPtr, 0x01)
recipient := shr(nextBitShift, calldataload(nextPtr))
nextPtr := add(nextPtr, nextByteLen)
zeroForOne := shr(u8Shr, calldataload(nextPtr))较为特殊的可能是 amountSpecified 的解码方案,因为 amountSpecified 是一个 int256 类型,该类型包含符号情况。相关代码如下:
nextPtr := add(nextPtr, 0x01)
nextByteLen := shr(u8Shr, calldataload(nextPtr))
nextBitShift := sub(0x0100, mul(0x08, nextByteLen))
nextPtr := add(nextPtr, 0x01)
amountSpecified := shr(nextBitShift, calldataload(nextPtr))
amountSpecified := signextend(sub(nextByteLen, 0x01), amountSpecified)笔者曾在 Uniswap V4 解析文章 介绍过 signextend 的用法,简单来说,signextend 可以将一个二进制数据拓展为 int 类型。signextend(b, x) 就是根据 b 判断 x 的数据类型。我们会将 x 的前 $256 − 8(b + 1)$ 位提取并扩展为带符号的 int256 类型。此处使用 sub(nextByteLen, 0x01) 的原因就是为了正确提取 int256。
由于 amountSpecified 是一个 int256 类型,所以给出其压缩方法可能更加有利于读者理解解码过程。在压缩 int256 类型中,最重要的就是计算 amount_specified_byte_len_u8 的数值。在 BBCEncoder 代码中,我们可以找到如下函数:
function byteLen(
uint256 word
) internal pure returns (uint8) {
for (uint8 i = 32; i > 0; i--) {
if (word >> ((i - 1) * 8) != 0) return i;
}
return 0;
}
function byteLen(
int256 word
) internal pure returns (uint8) {
uint256 adjusted;
if (word < 0) {
adjusted = uint256(-word);
} else {
adjusted = uint256(word);
}
if (byteLen(adjusted) == 32) return 32;
else return byteLen(adjusted << 1);
}其中 byteLen(uint256) 是一个用于 uint256 不包含前缀 0 的部分长度的计算,而 byteLen(int256) 是一个用于 int256 压缩长度计算的函数。我们可以看到 Lotus Router 实际上将 int256 输入转化为 uint256 进行了长度计算。此处需要特别注意 byteLen(adjusted) == 32 的情况,此时直接返回 32 的一个原因就是为了解码后获得的 amountSpecified 的正负情况保持。
EVM 内使用补码表示负数,读者可以自行证明使用上述编码和解码方案后,
amountSpecified的正负情况不会发生变化。笔者目前可以在感知上理解这一过程,但较难给出具体描述
最后,我们观察 data 的解码,过程如下:
nextPtr := add(nextPtr, nextByteLen)
nextByteLen := shr(u32Shr, calldataload(nextPtr))
data := nextPtr
nextPtr := add(nextPtr, 0x04)
nextPtr := add(nextPtr, nextByteLen)nextPtr := add(nextPtr, nextByteLen) 跳过了刚刚读取的 amountSpecified 变量,而 nextByteLen 读取了 data 的长度。需要注意的,与 pool 等类型使用 u8 表示长度不同,data 使用了 u32 表示长度,所以此处引入了 uint256 internal constant u32Shr = 0xe0; 用来位移读取 data_byte_len_u32 变量。
完成上述所有的解码工作后,我们最终需要将 nextPtr 置于正确位置,我们首先需要使用 nextPtr := add(nextPtr, 0x04) 跳过 data_byte_len_u32 变量,然后使用 nextPtr := add(nextPtr, nextByteLen) 跳过 data 变量。
具体调用
当我们完成压缩 calldata 的解压缩后,我们就需要进行具体的调用操作。我们首先分析较为简单的 ERC20 的 transfer 操作,该操作代码的核心是判断 transfer 调用返回值的问题。本质上以下代码就是一种 safeTransfer 的实现。
function transfer(ERC20 token, address receiver, uint256 amount) returns (bool success) {
assembly ("memory-safe") {
mstore(0x00, transferSelector)
mstore(0x04, receiver)
mstore(0x24, amount)
success := call(gas(), token, 0x00, 0x00, 0x44, 0x00, 0x20)
let successERC20 := or(iszero(returndatasize()), eq(0x01, mload(0x00)))
success := and(success, successERC20)
mstore(0x24, 0x00)
}
}此处我们需要了解 call 的具体参数。call 调用的参数依次为 gas, address, value, argsOffset, argsSize, retOffset, retSize 参数。其中 argsOffset 和 argsSize 代表发起调用使用的 calldata 在内存中的起始位置和长度,而 retOffset 和 retSize 是将 call 调用结束后返回值写入内存的位置和需要写入内存的返回值的大小。在一些内联汇编编程中,我们会将 retOffset 和 retSize 都设置为 0,然后通过 RETURNDATACOPY 指令手动读取返回值。
所以上述代码内部的 success := call(gas(), token, 0x00, 0x00, 0x44, 0x00, 0x20) 可以翻译为将当前合约剩余的所有 gas 都用于 call 操作,call 的目标合约地址是 token。使用的 calldata 从 0x00 开始,长度为 0x44,并将 call 操作可能的返回值写入 0x00 区域,并且只读取 call 返回值的前 32bytes。
在 success := call(gas(), token, 0x00, 0x00, 0x44, 0x00, 0x20) 部分之上的三行代码都是在内存中的 0x00 - 0x44 区域拼接 calldata 的逻辑代码。mstore(0x00, transferSelector) 在 0x00 - 0x04 部分写入了 transfer 的选择器,而 mstore(0x04, receiver) 则是在选择器后写入 transfer 代币的接受地址,而 mstore(0x24, amount) 则代表转账数量。
此处需要特别注意 ERC20 代币 transfer 的结果可能存在好几种情况,一般认为存在以下几种情况:
transfer调用被revert,此时call会返回false,即上述代码内的success会被置为falsetransfer调用不会被revert,但是存在返回值标志调用是否正确,具体可以分为:- 返回值使用
true代表调用成功,上述代码内的eq(0x01, mload(0x00)就是在校验返回值是否为true - 调用成功后不返回任何内容,上文中的
iszero(returndatasize())就是针对这种代币合约
- 返回值使用
还有一种最特殊的情况,即用户调用的合约是一个 EOA 账户,对 EOA 账户发起的调用不会失败,同时也不存在返回值,在上述代码中,这种情况会被认为是完成了 transfer 动作。在一些更加严格的 SafeTransferLib 内会对这种情况进行处理,比如在 solady 内存在以下代码:
/// @dev Sends `amount` of ERC20 `token` from the current contract to `to`.
/// Reverts upon failure.
function safeTransfer(address token, address to, uint256 amount) internal {
/// @solidity memory-safe-assembly
assembly {
mstore(0x14, to) // Store the `to` argument.
mstore(0x34, amount) // Store the `amount` argument.
mstore(0x00, 0xa9059cbb000000000000000000000000) // `transfer(address,uint256)`.
// Perform the transfer, reverting upon failure.
let success := call(gas(), token, 0, 0x10, 0x44, 0x00, 0x20)
if iszero(and(eq(mload(0x00), 1), success)) {
if iszero(lt(or(iszero(extcodesize(token)), returndatasize()), success)) {
mstore(0x00, 0x90b8ec18) // `TransferFailed()`.
revert(0x1c, 0x04)
}
}
mstore(0x34, 0) // Restore the part of the free memory pointer that was overwritten.
}
}solady 代码中使用了 iszero(extcodesize(token)) 判断调用地址是否是一个合约。最后,我们需要特别注意一个问题,此处的内联汇编代码是内存安全的。众所周知,在 solidity 中,0x40 - 0x60 是有用来存储空闲内存指针位置的特殊内存位置。所谓空闲内存指针就是指指向当前未被使用的内存位置的指针。而 memory-safe 的内联汇编需要保证 0x40 - 0x60 指向合适的位置。比如我们在内联汇编内在原有的空闲内存后增加了一些内存存储数据,此时我们就需要更新 0x40 - 0x60 内的数据,使空闲指针指向我们增加的内存数据后。但我们注意到 transfer 操作似乎没有对 0x40 - 0x60 位置进行特殊处理。
我们可以发现此处的 transfer 使用了 0x00 - 0x44 区域,此处与 0x40 - 0x60 的空闲指针区域存在交叉,交叉区域是 0x40 - 0x44 范围。该范围可能会存在 calldata 内的 amount 低位。所以我们需要将该区域的可能存在的 amount 低位数据清零。最简单的方法就是 mstore(0x24, 0x00),该语句会将 0x24 - 0x44 内存范围内的数据清零,刚好达到我们清零低位垃圾值的目的。
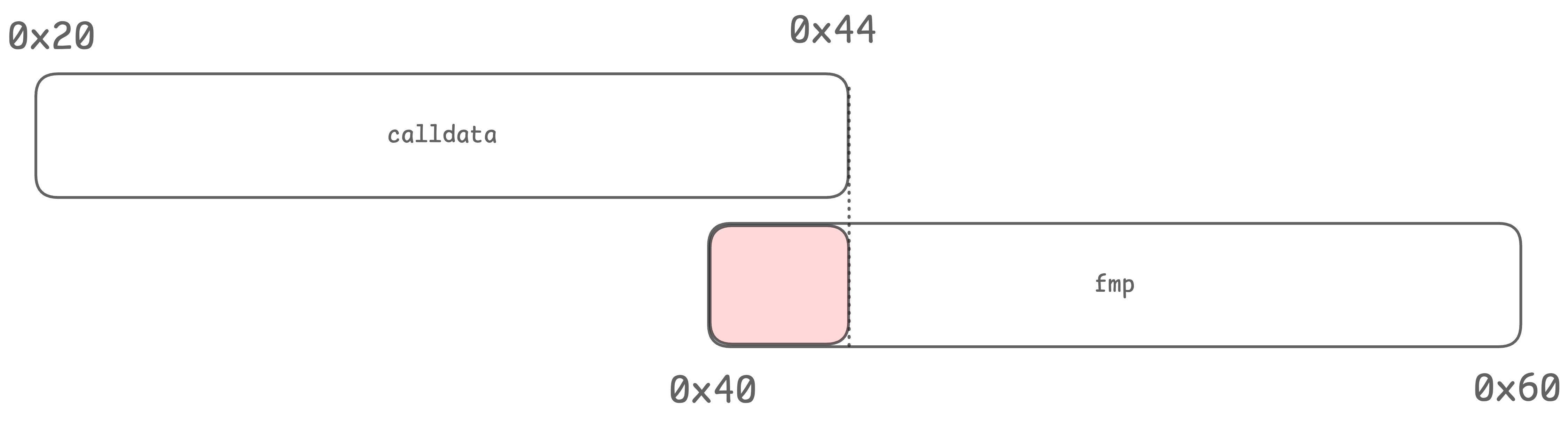
另一个与 memory-safe 有关的代码是 transferFrom 的实现,该实现的具体代码如下:
function transferFrom(
ERC20 token,
address sender,
address receiver,
uint256 amount
) returns (bool success) {
assembly ("memory-safe") {
let fmp := mload(0x40)
mstore(0x00, transferFromSelector)
mstore(0x04, sender)
mstore(0x24, receiver)
mstore(0x44, amount)
success := call(gas(), token, 0x00, 0x00, 0x64, 0x00, 0x20)
let successERC20 := or(iszero(returndatasize()), eq(0x01, mload(0x00)))
success := and(success, successERC20)
mstore(0x40, fmp)
mstore(0x60, 0x00)
}
}由于 transferFrom 函数使用的内存范围是 0x00 - 0x64 区域,此处完全覆盖了 0x40 - 0x60 区域。所以我们无法使用上文介绍 transfer 的使用 mstore(0x24, 0x00) 清零低位垃圾值的方法。此处我们使用另一种简单的方法,就是直接使用 let fmp := mload(0x40) 缓存 0x40 内部的原有内容,然后在代码执行最后使用 mstore(0x40, fmp) 方法将 fmp 内部的内容写回到内存相关位置中。
此处需要注意的是,我们没有对 fmp 内部的内容进行任何修改,这是因为我们认为内存中的数据在 call 之后就会失效,所以此处也没有对 fmp 调整。在某些需要保存内存中数据的情况,我们需要手动调整 fmp 使得内存中的数据不会被再次覆写。最后,特别注意的是 transferFrom 对 0x60 - 0x80 区域进行了清理,这是因为 solidity 约定该区域的数值仅应该为 0 而不能被写入,具体请参考 Layout in Memory 文档。
但是需要注意的是,在 Lotus Router 内并没有完全遵循
0x60 - 0x80的清理规则,比如在ERC6909内的transferFrom就没有实现0x60 - 0x80的清理规则
而 dynCall 则是使用了另一种方法,或者叫 dynCall 没有使用任何方法清理内存。这是因为 dynCall 使用了 fmp 作为 calldatacopy 数据的存储位置,此时 fmp 指向了 solidity 内部的空闲内存,所以不会产生可能的内存冲突。同时,根据 solidity 的内存布局,fmp 不会指向 zero solt(即 0x60 - 0x80 区域),所以此处也不需要进行 zero solt 的清理。关于为什么不在最后增加 fmp 的数值使得 fmp 指向新的空闲内存,这是因为 dynCall 残留在内存中的数据没有任何意义,所以可以随意覆盖写入。最后我们也需要注意 call 调用参数中的 retOffset, retSize 都为 0 所以此处也不需要管理返回值内存写入的问题。
function dynCall(address target, uint256 value, BytesCalldata data) returns (bool success) {
assembly ("memory-safe") {
let fmp := mload(0x40)
let dataLen := shr(0xe0, calldataload(data))
data := add(data, 0x04)
calldatacopy(fmp, data, dataLen)
success := call(gas(), target, value, fmp, dataLen, 0x00, 0x00)
}
}总结
Lotus Router 是一个适合内联汇编新手阅读的范例代码。我们可以观察到如何使用内联汇编进行解压缩工作,以及内联汇编与 solidity 代码之间的内存安全问题。Lotus Router 另一个巨大的贡献在于该合约给出了一套较为简单且高效的 calldata 压缩方案,同时并给出了所有的解压缩和压缩的 solidity 代码实现。最后,我们需要注意到 Lotus Router 这种基于递归的代码设计思路。





