深入理解EVM操作码,让你写出更好的智能合约
- jix
- 发布于 2022-11-30 11:23
- 阅读 11494
那些非典型的开销导致经典的软件设计模式在合约编程语言中看起来既低效又奇怪。如果想要识别这些模式并理解他们导致效率变高/低的原因,你必须首先对以太坊虚拟机(即 EVM)有一个基本的了解。
你的一些编程“好习惯”反而会让你写出低效的智能合约。对于普通编程语言而言,计算机做运算和改变程序的状态顶多只是费点电或者费点时间,但对于 EVM 兼容类的编程语言(例如 Solidity 和 Vyper),执行这些操作都是费钱的!这些花费的形式是区块链的原生货币(如以太坊的 ETH,Avalanche 的 AVAX 等等...),想象成你是在用原生货币购买计算资源。
用于购买计算、状态转移还有存储空间的开销被称做 燃料(下文统称 gas )。 gas 的作用是确定交易的优先级, 同时形成一种能抵御【女巫攻击】(Sybil resistance)的机制 ,而且还能防止【停机问题】(halting problem)引起的攻击。
欢迎阅读我的文章 Solidity 基础 去了解 gas 的方方面面
这些非典型的开销导致经典的软件设计模式在合约编程语言中看起来既低效又奇怪。如果想要识别这些模式并理解他们导致效率变高/低的原因,你必须首先对以太坊虚拟机(即 EVM)有一个基本的了解。
什么是EVM?
如果你已经熟悉 EVM,请随时跳到下个部分: 什么是 EVM 操作码?
任何一个区块链都是一个基于交易的 状态机。 区块链递增地执行交易,交易完成后就变成新状态。因此,区块链上的每笔交易都是一次状态转换。
简单的区块链,如比特币,本身只支持简单的交易传输。相比之下,可以运行智能合约的链,如以太坊,实现了两种类型的账户,即外部账户和智能合约账户,所以支持复杂的逻辑。
外部账户由用户通过私钥控制,不包含代码;而智能合约账户仅受其关联的代码控制。EVM 代码以字节码的形式存储在虚拟 ROM 中。
EVM 负责区块链上所有交易的执行和处理。它是一个栈机器,栈上的每个元素长度都是 256 位或 32 字节。EVM 嵌在每个以太坊节点中,负责执行合约的字节码。
EVM 把数据保存在 存储(Storage) 和 内存(Memory) 中。存储(Storage)*用于永久存储数据,而*内存(Memory)*仅在函数调用期间保存数据。还有一个地方保存了函数参数,叫做*调用数据(calldata),这种存储方式有点像内存,不同的是不可以修改这类数据。
在 Preethi Kasireddy 的文章中了解有关以太坊和 EVM 的更多信息 Ethereum 是如何工作的?。
智能合约是用高级语言编写的,例如 Solidity、Vyper 或 Yul,随后通过编译器编译成 EVM 字节码。但是,有时直接在代码中使用字节码会更高效(省gas)。
EVM 字节码以十六进制编写。它是一种虚拟机能够解释的语言。这有点像 CPU 只能解释机器代码。

Solidity 字节码示例
什么是 EVM 操作码?
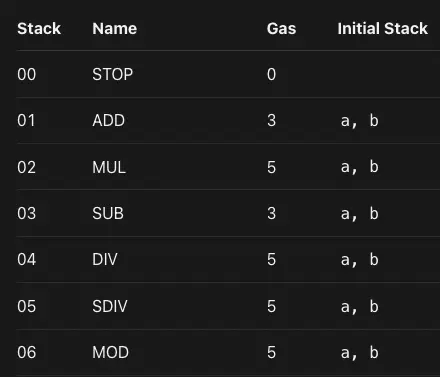
所有以太坊字节码都可以分解为一系列操作数和操作码。操作码是一些预定义的操作指令,EVM 识别后能够执行这个操作。例如,ADD 操作码在 EVM 字节码中表示为 0x01。它从栈中删除两个元素并把结果压入栈中。
从堆栈中移除和压入堆栈的元素数量取决于操作码。例如,PUSH 操作码有 32 个:PUSH1 到 PUSH32。 PUSH 在栈上 添加一个 字节元素,元素的大小可以从 0 到 32 字节。它不会从栈中删除元素。作为对比, 操作码 ADDMOD 表示 [模加法运算](https://libraryguides.centennialcollege.ca/c.php?g=717548&p=5121840#:~:text=Properties of addition in modular,%2B d ( mod N ) .) ,它从栈中删除3个元素然后压入模加结果。请注意,PUSH 操作码是唯一带有操作数的操作码。

操作码示例
每个操作码都占一个字节,并且操作成本有大有小。操作码的操作成本是固定的或由公式算出来。例如,ADD 操作码固定需要3 gas。而将数据保存在存储中的操作码 SSTORE ,当把值从0设置为非0时消耗 20,000 gas,当把值改为0或保持为0不变时消耗 5000 gas。
SSTORE 的开销实际上会其他变化,具体取决于是否已访问过这个值。可以在这里找到有关 SSTORE 和 SLOAD 开销的完整详细信息:
为什么了解 EVM 操作码很重要?
想要降低 gas 开销,了解 EVM 操作码极其重要,这也会降低你的终端用户的成本。由于不同的 EVM 操作码的成本是不同的,因此虽然实现了相同结果,但不同的编码方式可能会导致更高的开销。了解哪些操作码是比较昂贵的,可以帮助你最大程度地减少甚至避免使用它们。你可以查看 以太坊文档 以获取 EVM 操作码及其相关 gas 开销的列表。
下面是一些考虑了 EVM 操作码开销的反直觉设计模式的具体示例:
用乘法而不是指数: MUL vs EXP
MUL 操作码花费 5 gas 用于执行乘法。例如,10 * 10 背后的算术将花费 5 gas。
EXP 操作码用于求幂,其 gas 消耗由公式决定:如果指数为零,则消耗10 gas。但是,如果指数大于零,则需要 10 gas 加上指数字节数的 50 倍。
一个字节是 8 位,一个字节可以表示 0 到 2⁸-1 之间的值(即0-255),两个字节可以表示 2⁸ 到 2¹⁶-1 之间的值,以此类推。因此,例如求 10¹⁸ 将花费 10 + 50 1 = 60 gas,而求 10³⁰⁰ 将花费 10 + 50 2 = 160 gas,因为来表示 18 需要一个字节,表示 300 需要两个字节。
从上面可以清楚地看出,在某些时候你应该使用乘法而不是求幂。下面一个具体的例子:
contract squareExample {
uint256 x;
constructor (uint256 _x) {
x = _x;
}
function inefficcientSquare() external {
x = x**2;
}
function efficcientSquare() external {
x = x * x;
}
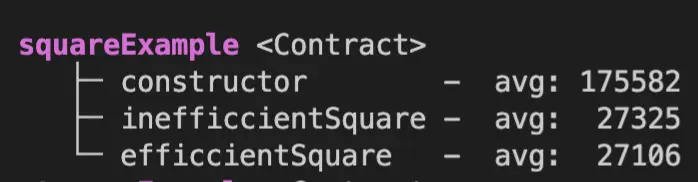
}inefficientSquare 和 eficcientSquare 两个方法都把状态变量 x 改为 x 的平方。然而,inefficientSquare 的算术开销为 10 + 1 50 = 60 gas,而 efficientSquare* 的算术开销为 5 gas。
由于上述算术开销之外的原因,inefficientSquare 的 gas 费用平均比 efficientSquare 多 200 左右。
缓存数据:SLOAD & MLOAD
众所周知,缓存数据可以大规模地提升更好的性能。同样,在 EVM 上使用缓存也极端重要,即使只有少量操作,也会明显节省 gas。
SLOAD 和 MLOAD 两个操作码用于从存储和内存中加载数据。MLOAD 成本固定 3 gas,而 SLOAD 的成本由一个公式决定:SLOAD 在交易过程中第一次访问一个值需要花费 2100 gas,之后每次访问需要花费 100 gas。这意味着从内存加载数据比从存储加载数据便宜 97% 以上。
下面是一些节省潜在 gas 的示例代码:
contract storageExample {
uint256 sumOfArray;
function inefficcientSum(uint256 [] memory _array) public {
for(uint256 i; i < _array.length; i++) {
sumOfArray += _array[i];
}
}
function efficcientSum(uint256 [] memory _array) public {
uint256 tempVar;
for(uint256 i; i < _array.length; i++) {
tempVar += _array[i];
}
sumOfArray = tempVar;
}
}合约 storageExample 有两个函数: inefficientSum 和 efficientSum
这两个函数都将 _array 作为参数,这是一个无符号整型数组。他们都会把合约的状态变量 sumOfArray 设置为 _array 中所有元素的总和。
inefficcientSum 使用状态变量进行计算。请牢记,状态变量(例如 sumOfArray)保存在 存储 中。
efficcientSum 在内存中创建一个临时变量 tempVar,用于计算 _array 中值的总和。然后将 tempVar 赋值给 sumOfArray。
当传入的数组仅包含 10 个无符号整数时, efficientSum的 gas 效率比 inefficcientSum 高 50% 以上。

它们的效率随着计算次数的增加而增加:当传入 100 个无符号整数的数组时,eficcientSum 比 inefficcientSum 的 gas 效率高 300% 以上。

避免使用面向对象编程模型:CREATE 操作码
CREATE 操作码用于创建包含关联代码的新帐户(即智能合约)。它花费至少32,000 gas,是 EVM 上最昂贵的操作码。
最好尽可能减少使用的智能合约数量。这与典型的面向对象编程不同,在典型的面向对象编程中,为了可复用性和清晰性,鼓励定义多个类。
这是一个具体的例子:
下面是一段使用面向对象方法创建“vault”的代码。每个“vault”都包含一个 uint256 变量,并在构造函数中初始化:
contract Vault {
uint256 private x;
constructor(uint256 _x) { x = _x;}
function getValue() external view returns (uint256) {return x;}
}
// Vault 结束
interface IVault {
function getValue() external view returns (uint256);
} // IVault 结束
contract InefficcientVaults {
address[] public factory;
constructor() {}
function createVault(uint256 _x) external {
address _vaultAddress = address(new Vault(_x));
factory.push(_vaultAddress);
}
function getVaultValue(uint256 vaultId) external view returns (uint256) {
address _vaultAddress = factory[vaultId];
IVault _vault = IVault(_vaultAddress);
return _vault.getValue();
}
} // InefficcientVaults 结束每次调用 createVault() 时,都会创建一个新的 Vault 智能合约。存储在 Vault 中的值由传递给 createVault() 的参数决定。然后将新合约的地址存储在数组 factory 中。
这是另一段实现相同功能的代码,但用映射代替了创建:
contract EfficcientVaults {
// 映射:vaultId => vaultValue
mapping (uint256 => uint256) public vaultIdToVaultValue;
// 下一个 vault 的 id
uint256 nextVaultId;
function createVault(uint256 _x) external {
vaultIdToVaultValue[nextVaultId] = _x;
nextVaultId++;
}
function getVaultValue(uint256 vaultId) external view returns (uint256) {
return vaultIdToVaultValue[vaultId];
}
} // EfficcientVaults 结束每次调用 createVault() 时,参数都存储在一个映射中, 映射的 ID 由状态变量 nextVaultId 确定,而 nextVaultId 在每次调用 createVault() 时递增。
这种实现上的差异导致 gas 成本大幅降低。
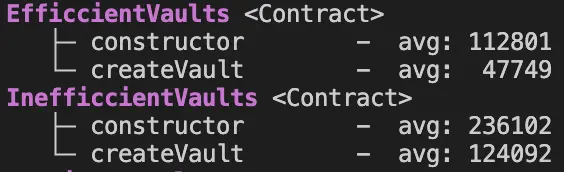 EfficcientVaults 的 createVault() 与 IneficcientVaults 相比,效率提高了 61%,消耗的 gas 减少了约 76,300。
EfficcientVaults 的 createVault() 与 IneficcientVaults 相比,效率提高了 61%,消耗的 gas 减少了约 76,300。
应该注意的是,在某些情况下在合约中创建新合约是可取的,并且通常是为了不可变性和效率。随着合约的大小增加,与合约的所有交互的交易成本也将增加。 因此,如果你希望在链上存储大量数据,最好通过多个单独的合约分离这些数据。除此之外,应避免创建新合约。
存储数据:SSTORE
SSTORE 是将数据保存到存储的 EVM 操作码。一般而言,当将存储值从零设置为非零时,SSTORE 花费 20,000 gas,当存储值设置为零时,SSTORE 花费 5000 gas。
由于这种成本的存在,在链上存储数据效率低下且成本高昂,应尽可能避免。
这种方法在 NFT 中最为常见。开发人员将 NFT 的元数据(图像、属性等)存储在去中心化存储网络(如 Arweave 或 IPFS)上,而不是将其存储在链上。唯一保存在链上的数据是一条指向元数据的链接。可通过所有 ERC721 合约内置的 tokenURI() 函数获得此链接。

tokenURI() 函数的标准实现。 (来源:OpenZeppelin)
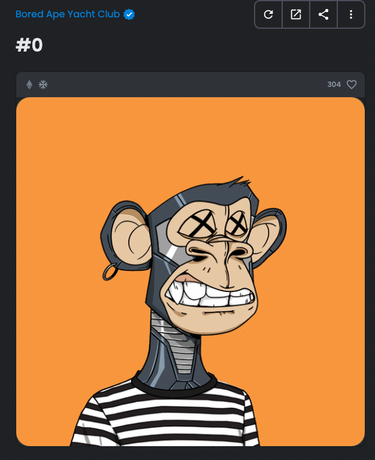
例如无聊猿Bored Ape Yacht Club smart contract。 调用 tokenURI( ) 函数,传入 tokenId: 0, 函数返回以下链接: ipfs://QmeSjSinHpPnmXmspMjwiXyN6zS4E9zccariGR3jxcaWtq/0
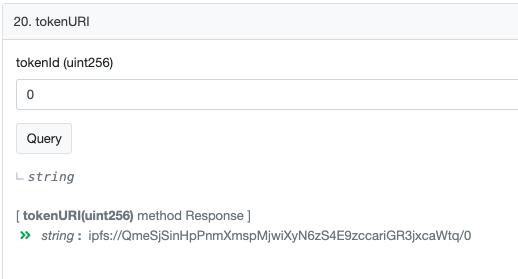
如果点击链接,你将看到 BAYC #0 元数据的 JSON 文件:
这些数据在OpenSea上很容易验证: OpenSea:
还应注意,由于存储成本,某些数据结构在 EVM 中根本不可行。例如,使用邻接矩阵表示图(a graph using an adjacency matrix) 是完全不可行的,因为它的空间复杂度是 O(V²) 。
以上所有代码都可以在我的*Github*上找到
感谢你阅读,希望你喜欢这篇文章!
如果有机会,我愿意介绍更多的 gas 优化和细微差别。要了解更多信息,我建议使用以下资源:
- 变量压缩打包大法 和 内存数组优化 作者: Franz Volland
- Solidity gas 优化技巧 和 Solidity 节省 gas 和字节码大小的魔法 作者: Mudit Gupta
- EVM: 从 Solidity 到字节码, 内存和存储 作者: Ethereum 工程小组
- 以太坊黄皮书



