指南:如何在 16G Mac Mini 运行 35B 大模型
- leopardracer
- 发布于 3天前
- 阅读 190
作者详细介绍了如何在16GB内存的Mac Mini上,利用内存映射(mmap)和混合专家模型(MoE)架构成功运行35B参数的AI模型,并构建了一个结合本地和云端模型的AI代理三层路由系统。文章分享了从Qwen切换到Gemma 4的基准测试结果、优化技巧及详细设置教程。

我将所有内容都迁移到了一台无头 (headless) Mac Mini M4 上,这是起售价 599 美元、配备 16GB RAM 的基础款。我最初使用较小的 Qwen 模型进行消息分类和上下文压缩,随后找到了一种在 16GB 内存上运行 350 亿参数模型的方法,速度达到每秒 17 个 Token 且 零交换 (zero swap)。尽管普遍认为 32GB 是最低配置,但我已经成功运行这套配置大约一周了。
当 Google 在 Apache 2.0 协议下发布 Gemma 4 时,我针对我的 Qwen 配置进行了基准测试。分类速度从 8.5 秒提高到 1.9 秒。在几小时内,我就更换了模型。
这就是我如何在一台 600 美元的机器上容纳 35B 模型、本地模型如何为 24/7 AI Agent 提供服务、模型路由如何在三个层级间工作,以及为什么 Gemma 4 成为了我的新首选。
用于自动化的本地 AI
我的 Mac Mini 作为一个无头 (headless) AI 自动化服务器运行,处理 iMessages、电子邮件、计划任务以及超过 35 项专业技能。虽然主要的“大脑”是 Claude Code,但将它用于每一项细微任务既昂贵又容易达到使用限制。我需要一种方法来本地且免费地处理常规工作。
最初简单的消息分类现在已经覆盖了:
- 消息分诊 (Message triage): 在 2 秒内对传入消息进行分类(问题、请求、想法等)并评估紧急程度。
- 上下文压缩: 在将消息发送给 Claude 之前,将 500 字的消息压缩为 30 字的摘要。
- 信号压缩: 汇总一整天的日志和指标,为规划调用节省大约 15 倍的 Token。
- 电子邮件预处理: 根据分诊情况决定是否启动完整的 Claude 会话。
- 记忆整合: 聚类并合并每日笔记,以“整理” Agent 的记忆碎片。
- 回退 (Fallback): 在 Claude 受到速率限制或离线时处理操作任务。
这种本地设置减少了 30-40% 的 Claude API 会话,使订阅周期更长,并为常规工作提供更快的响应。
三个层级,一台 600 美元的机器
并非每个任务都需要相同水平的智能。我构建了一个具有三个本地层级加云端的路由系统。
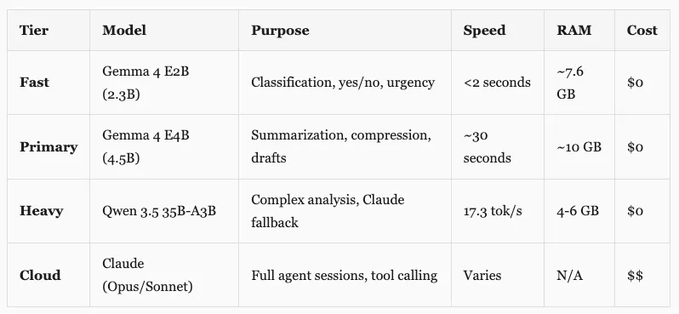
快速层 (The Fast Tier)
运行于每条传入消息,以分类类型和紧急程度。它需要极快(2 秒以下),以决定消息是否可以完全跳过 Claude(例如:问候语或仅供参考的信息)。
主层 (The Primary Tier)
处理需要语言理解的任务,如上下文压缩和生成报告。4.5B 模型处于速度与质量之间的最佳平衡点。
重型层 (The Heavy Tier)
35B 模型处理复杂的预处理,如压缩每日自动化信号,并作为 Claude 的弹性回退方案。当主 API 不可用时,它负责处理健康检查和维护。
分诊路由逻辑
- 传入消息进入分诊环节。
- 快速层进行分类并评估紧急程度。
- 如果是问候语/仅供参考的信息,则跳过 Claude。
- 如果是长文本,由主层或重型层进行摘要。
- 将分类结果添加到 Claude 的 Prompt 前部以节省 Token。
安全规则确保涉及金钱、部署或工作相关主题的消息绕过本地分诊,直接发送给 Claude。
35B 的秘诀:将 SSD 作为 GPU 显存
在 16GB RAM 上运行 35B 模型本应是行不通的。标准精度的 Qwen 3.5 35B-A3B 超过了 16GB。我第一次尝试使用 Ollama 时系统冻结了。解决方案是使用带有 --mmap 标志的 llama.cpp。
这种设置实现了每秒 17.3 个 Token 的速度,且剩余 81% 的内存,零交换 (zero swap)。

为什么这行得通
两个因素使这成为可能:模型架构和 macOS 文件处理。
- 专家混合模型 (MoE): Qwen 3.5 35B-A3B 拥有 350 亿个参数,但每个 Token 只有 30 亿个活跃参数。
- 内存映射 (
--mmap):llama.cpp不是将整个模型加载到 RAM 中,而是将文件映射到 SSD。操作系统将模型视为虚拟地址空间,仅将特定 Token 实际需要的权重(专家)页入内存。
M4 的统一内存架构和高速 NVMe SSD 允许按需页入权重,而不会产生明显的瓶颈。令人惊讶的是,35B 模型比旧的 9B 模型更快(17.3 对比 12.6 Token/秒),因为 MoE 每个 Token 需要的计算量更少。
更换大脑:从 Qwen 到 Gemma 4
我最初在所有层级都运行 Qwen 3.5,但 Google 的 Gemma 4 发布改变了局面。其 Apache 2.0 许可证非常适合生产基础设施,其基准测试显示在推理和多模态能力(视觉和音频)方面有巨大提升。
性能对比
- 分类: Gemma 4 快了 4.4 倍(1.9 秒对比 8.5 秒)。
- 摘要: Gemma 4 快了 1.8 倍(27.1 秒对比 49.8 秒)。
分诊的速度差异是决定性因素。我通过在中心化文件中更改模型常量来更新了我的架构。目前重型层仍保留在 Qwen 35B 上,而快速层和主层则通过 Ollama 使用 Gemma 4。
思考模式陷阱
Qwen 和 Gemma 都有用于复杂推理的“思考 (thinking)”模式。然而,对于简单的分类,这种模式是一场灾难。由于模型会生成内部推理过程,它可能会将一两个词的回答变成一个耗时 30 秒的过程。
通过在 Ollama API 调用中设置 think: false,分类速度从 30 秒提高到 1 秒以内,且这些特定任务的准确性没有损失。
弹性链
本地模型提供了可用性。我的 Agent 使用瀑布式回退系统:
Claude Sonnet -> Haiku -> 本地 35B -> 本地主层 -> OpenRouter -> 队列
如果 Claude 达到速率限制或出现身份验证错误,系统会自动级联到下一层。这确保了即使主 API 在凌晨 4 点宕机,Agent 仍能使用本地 35B 模型执行操作检查和维护。
设置指南
硬件
- Mac Mini M4 (16GB RAM) 或任何配备 16GB+ RAM 的 Apple Silicon Mac。
选项:Gemma 4(当前设置)
## 安装 Ollama (0.20+)
brew install ollama
## 拉取模型
ollama pull gemma4:e2b # 快速层 (视觉+音频)
ollama pull gemma4:e4b # 主层35B 重型层
## 安装 llama.cpp
brew install llama.cpp
## 下载 Qwen 3.5 35B GGUF
pip3 install huggingface-hub
python3 -c "from huggingface_hub import hf_hub_download; \
hf_hub_download('unsloth/Qwen3.5-35B-A3B-GGUF', \
'Qwen3.5-35B-A3B-UD-IQ3_XXS.gguf', \
local_dir='~/.local/share/llama-models')"
## 使用 mmap 启动 llama-server
llama-server \
--model ~/.local/share/llama-models/Qwen3.5-35B-A3B-UD-IQ3_XXS.gguf \
--port 8081 --ctx-size 16384 --n-gpu-layers 0 --mmap \
--flash-attn on --threads 8关键提示
OLLAMA_MAX_LOADED_MODELS=1: 对于 16GB 系统至关重要,以防止内存耗尽。--n-gpu-layers 0: 在llama.cpp中,这强制操作系统通过mmap管理页面。- 上下文窗口: 我对分类使用 4K,摘要使用 32K,重型 35B 模型使用 16K。
核心经验教训
本地模型现在已成为可行的生产基础设施。在复杂的编码方面,它们不如 Claude 强大,但在分诊和数据压缩方面表现出色。
mmap 标志是在有限内存上运行大型模型最重要的优化手段。将模型配置中心化使迁移变得容易,而在更换模型前进行基准测试可确保速度提升的同时,不会带来不可接受的准确性权衡。
下一步,我计划测试 Gemma 4 26B MoE 变体,作为 Qwen 35B 重型层的潜在替代方案,从而将整个技术栈迁移到单一模型系列。
- 原文链接: x.com/leopardracer/statu...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





