Claude + Obsidian:构建本地化 AI 研究引擎与技能图谱指南
- the_smart_ape
- 发布于 2小时前
- 阅读 16
本文介绍了如何利用 Claude AI、Obsidian 和 Markdown 文件构建一个本地化的“研究技能图谱”系统。通过建立一套包含六个分析维度(技术、经济、历史等)、来源评估和冲突协议的结构化框架,用户可以将 AI 转化为具备深度思考能力的虚拟研究部门,实现知识的持续沉淀与复用。

我在过去 6 个月中为 4 个客户构建了一个研究系统:一家知名媒体公司、两家咨询公司和一名独立分析师。
总的来说,他们将研究成本降低了约 60%。其中一家公司用这个系统和一名负责审核输出的高级编辑取代了三名初级研究员。
没有花哨的工具。没有每月 500 美元的订阅费。没有打开 47 个 Chrome 标签页。只有一个包含 .md 文件的文件夹,一个 AI Agent (Claude),以及一个只需输入一个研究问题就能生成多角度分析的系统,而这通常需要一个团队花费两周时间。

这篇文章是完整的拆解。包含每个文件、每个链接、每个模板。到最后,你将拥有一个可以在一小时内构建完成的可用研究引擎。
什么是研究技能图谱?
大多数人使用 AI 进行研究时,会打开 ChatGPT 并输入“为我研究 X”,结果得到的是一段听起来像维基百科介绍的表面总结。然后你又要花几个小时亲自去核实并填补空白。那不是研究;那只是多了几个步骤的 Google 搜索。
问题不在于 AI;而在于缺乏结构。你没有提供方法论、评估标准或思考框架。你每一次都在雇佣一个患有健忘症的天才。
研究技能图谱修复了这个问题。
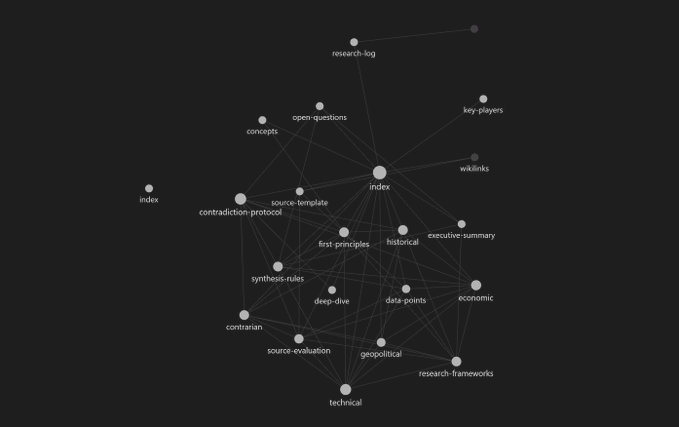
它是一个由相互关联的 Markdown 文件组成的文件夹,每个文件都是一个“知识节点”。在每个文件中,你使用 [[wikilinks]] 来引用其他节点。当你让 Claude 指向这个文件夹时,它会遵循这些链接,阅读你的方法论,应用评估标准,并在合成所有内容之前通过六个不同的视角分析该主题。
区别在于:单个 Prompt 给你的是摘要;而技能图谱给你的是一个研究部门。
为什么要使用六个视角而不是单个 Prompt?
你不再是问“研究主题 X”,而是强迫 AI 从根本不同的角度对同一个问题重新思考六次:
- 技术视角: 数据怎么说?只看数据。
- 经济视角: 跟着钱走。谁付钱,谁获利,什么样的激励机制驱动了行为?
- 历史视角: 什么模式在重复?哪些背景正在被遗忘?
- 地缘政治视角: 放大到全球棋局。涉及哪些国家和权力动态?
- 反向视角: 如果共识是错误的怎么办?谁从当前的叙事中受益?
- 第一性原理视角: 忘掉一切。仅从基本事实出发重新构建。
每个视角产生的结果往往相互矛盾。这种张力正是真正洞察力所在。
文件夹结构
你可以在桌面文件夹中或在 Obsidian 中创建此结构。
/research-skill-graph (研究技能图谱)
├── index.md (索引文件)
├── research-log.md (研究日志)
├── methodology/ (方法论)
│ ├── research-frameworks.md (研究框架)
│ ├── source-evaluation.md (来源评估)
│ ├── synthesis-rules.md (合成规则)
│ └── contradiction-protocol.md (矛盾协议)
├── lenses/ (视角)
│ ├── technical.md (技术)
│ ├── economic.md (经济)
│ ├── historical.md (历史)
│ ├── geopolitical.md (地缘政治)
│ ├── contrarian.md (反向)
│ └── first-principles.md (第一性原理)
├── projects/ (项目)
│ └── (每个研究主题一个子文件夹)
├── sources/ (来源)
│ └── source-template.md (来源模板)
└── knowledge/ (知识)
├── concepts.md (概念)
└── data-points.md (数据点)文件 1:index.md(指挥中心)
这是向 AI 简报的文件,告诉它你是谁以及如何执行该系统。
## 研究技能图谱 —— 指挥中心
### 1. 任务
深层研究系统,接收一个问题并产生多角度分析。该系统不使用零散的笔记,而是通过 6 个研究视角强制进行结构化思考。
研究问题:[在此粘贴你的问题]
范围:[定义边界]
时间跨度:[回顾期]
输出目标:[需要辅助的决策]
### 2. 节点图谱
#### 方法论
- [[research-frameworks]] —— 选择合适的研究结构
- [[source-evaluation]] —— 判断信任的标准
- [[synthesis-rules]] —— 如何结合研究结果
- [[contradiction-protocol]] —— 当来源不一致时该怎么办
#### 视角
- [[technical]] —— 机械数据和数字
- [[economic]] —— 金钱、市场和激励
- [[historical]] —— 模式和背景
- [[geopolitical]] —— 权力动态和联盟
- [[contrarian]] —— 挑战共识
- [[first-principles]] —— 基本事实
#### 输出
- [[executive-summary]] —— 最多 500 字的综合摘要
- [[deep-dive]] —— 按视角分类的完整分析
- [[key-players]] —— 重要人物/组织
- [[open-questions]] —— 我们仍然不知道的内容
### 3. 执行指令
1. 阅读此文件以了解范围。
2. 阅读 [[research-frameworks]] 以选择方法。
3. 阅读 [[source-evaluation]] 以了解证据标准。
4. 针对每个视角(技术 → 经济 → 历史 → 地缘政治 → 反向 → 第一性原理):
a. 仅通过该视角研究主题。
b. 记录发现、来源和置信度。
c. 记录矛盾之处。
5. 应用 [[contradiction-protocol]] 和 [[synthesis-rules]]。
6. 生成所有 4 个输出文件。
7. 更新 [[concepts]] 和 [[data-points]]。文件 2:research-frameworks.md
## 研究框架
### 框架选择
#### 类型 1:验证(“X 是否真实?”)
- 技术 → 反向 → 历史
#### 类型 2:因果分析(“为什么 X 会发生?”)
- 历史 → 经济 → 技术 → 地缘政治 → 反向
#### 类型 3:情景规划(“如果 X 发生会怎样?”)
- 第一性原理 → 技术 → 经济 → 地缘政治
### 研究深度层级
- 层级 1:快速扫描(30 分钟,3 个视角,5 个来源)
- 层级 2:标准(2-3 小时,6 个视角,15-25 个来源)
- 层级 3:深度挖掘(1-2 天,6 个视角,50 个以上来源)文件 3:source-evaluation.md
## 来源评估
### 来源层级系统
- 层级 1:原始数据(原始数据集,同行评审的研究)
- 层级 2:专家分析(特定领域的机构,书籍)
- 层级 3:知情评论(专家博客,Newsletter)
- 层级 4:大众媒体(主流新闻,维基百科用于定位)
- 层级 5:社交/轶事(Twitter, Reddit)
### 警示信号
- 未引用方法论
- 结论中存在财务激励
- 将相关性与因果关系混为一谈文件 4:synthesis-rules.md
## 合成规则
### 过程
1. 视角总结:每个视角一段话。
2. 一致性映射:识别 4 个以上视角指向同一方向的地方。
3. 张力映射:识别视角不一致的地方。记录这些张力。
4. 二阶洞察:结合视角(例如,技术 + 经济)。
5. 置信度校准:陈述证据以及什么会改变你的想法。文件 5:contradiction-protocol.md
## 矛盾协议
### 当来源不一致时
1. 检查它们是否使用相同的数据或定义。
2. 识别根源:不同的数据、解读、范围或时间框架。
3. 记录,不要解决:“来源 A 认为 X,来源 B 认为 Y。”
4. 如果无法解决,升级到 [[open-questions]]。文件 6-11:六个视角
每个视角文件都遵循类似的结构。以下以技术视角为例:
## 视角:技术
剥离观点。数字说明了什么?
### 核心问题
1. 数据显示了什么?
2. 可衡量的输入和输出是什么?
3. 存在哪些硬性的物理或数学约束?
4. 数据在哪些方面不完整?
### 输出格式
- 指标:[测量项]
- 数值:[数字]
- 来源:[层级 1 或 2 来源]
- 趋势:[变化方向]其他视角(经济、历史、地缘政治、反向、第一性原理)使用相同的格式,但专注于各自的核心问题(例如,经济视角关注“谁获利?”,反向视角关注“主流叙事是什么?”)。
文件 12:source-template.md
## 来源模板
- 标题/作者/日期/URL
- 层级:[1-5]
- 关键主张
- 提取的数据
- 方法论备注
- 我的评估复利效应
该系统随着时间的推移而改进。knowledge/concepts.md 和 knowledge/data-points.md 会在所有项目中积累数据。在完成几个项目后,你的 AI 将从一个经过验证的数据点库开始。research-log.md 跟踪每个项目,确保你的第 10 个项目是在前 9 个项目的背景下开始的。
如何使用该系统
- 方法 1:Claude Projects。 创建一个新项目,上传所有文件,并提供一个主题及指令:“遵循 index.md 中的执行指令。”
- 方法 2:粘贴上下文。 将
index.md和相关的视角文件复制到任何 AI 聊天窗口中。 - 方法 3:Claude Code + Obsidian。 将 Claude Code 指向你的本地库 (Vault)。Agent 直接读取和写入文件,自主演化图谱。
使用 Obsidian 进行可视化
在 Obsidian 中将你的文件夹作为库 (Vault) 打开,以查看图谱视图。index.md 位于中心,各个视角向外辐射。这有助于你发现研究空白(断开连接的节点)和项目之间意想不到的联系。

为什么这优于传统研究
传统研究往往迷失在确认偏差中,并产生非结构化的总结。技能图谱研究强制执行六个不同的角度,对来源进行分层,并记录矛盾。内置的“反向”视角充当了魔鬼代言人,挑战研究结果以确保最终分析的稳健性。
实施清单
- 创建文件夹结构: 20 个文件,6 个文件夹。
- 填写 index.md: 定义任务和执行步骤。
- 填写 6 个视角文件: 为每个视角定义核心问题。
- 填写方法论: 设定来源层级和合成规则。
- 上传至 Claude: 使用 Project 提供上下文。
- 测试与迭代: 根据输出质量更新视角文件。
- 原文链接: x.com/the_smart_ape/stat...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





