Meta神经计算机与微软Memento:AI前沿论文周报
- dair_ai
- 发布于 2小时前
- 阅读 13
本文汇总了2026年4月初的顶级AI论文,核心涵盖了Meta提出的将计算与存储统一的“神经计算机”、微软开发的LLM上下文压缩技术Memento、以及关于单智能体与多智能体系统效率的对比研究。内容还涉及编码智能体原子技能训练、医疗AI模型MedGemma 1.5等前沿领域,旨在提升大模型的推理性能与实际应用效能。

本周顶级 AI 论文 (4月6日 - 4月12日)
1. Neural Computers
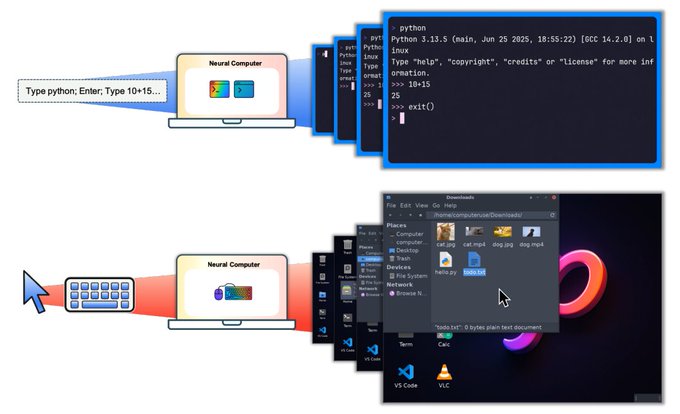
来自 Meta AI 和 KAUST 的研究人员提出了 Neural Computers (NCs),这是一种新兴的机器形式,它将计算、内存和 I/O 统一在单个学习到的运行时状态中。与执行明确程序的传统计算机、在外部环境中行动的 Agent 或学习动力学的世界模型不同,NCs 的目标是使模型本身成为运行中的计算机,建立了一种新的计算范式。
- 从硬件栈到神经网络潜空间栈: 经典计算机将计算、内存和 I/O 分隔成模块化的硬件层。Neural Computers 将这三者折叠成由神经网络携带的单个潜空间运行时状态。模型的隐藏状态同时充当工作内存、计算基座和接口层,消除了程序与执行环境之间的界限。
- 以视频模型作为原型基座: 团队将 NCs 实例化为视频模型,根据指令、像素输入和用户操作生成屏幕帧。两个原型涵盖了命令行界面(NCCLIGen,用于渲染和执行终端工作流)和图形桌面(NCGUIWorld,学习指针动力学和菜单交互),两者在训练时都无法访问内部程序状态。
- 早期运行时基语的出现: 原型证明,学习到的运行时可以直接从原始界面轨迹中获得 I/O 对齐和短程控制。CLI 模型执行短命令链,并具有结构准确的输出渲染,而 GUI 模型在受控设置中学习到连贯的点击反馈和窗口转换。
- 通往全神经计算机 (Completely Neural Computers) 的路线图: 长期目标是 CNC:一个具备图灵完备性、通用可编程且除非明确重新编程否则行为一致的系统。主要的公开挑战包括跨会话的例行程序重用、无灾难性遗忘的受控能力更新,以及用于长程推理的稳定符号处理。论文 | 推文
2. Memento: Teaching LLMs to Manage Their Own Context
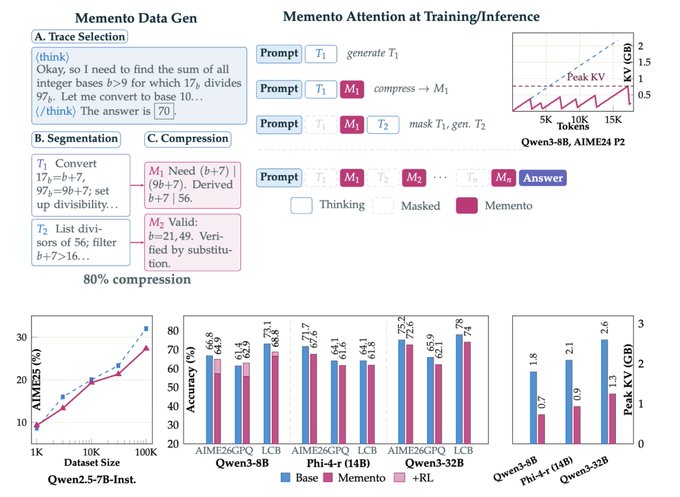
微软的新研究教导推理模型在生成过程中压缩自己的思维链。Memento 训练模型将推理分割成块,将每个块总结为紧凑的 “memento”,然后从 KV cache 中逐出原始块。模型仅基于 mementos 继续推理,在将吞吐量几乎翻倍的同时,将峰值内存降低了 2-3 倍。
- 分块压缩架构: 模型学习使用特殊 Token 标记推理边界,生成捕获关键结论和中间值的简明摘要,然后从上下文中丢弃整个块。从那时起,模型只能看到过去的 mementos 以及当前活动的块,在不丢失关键信息的情况下保持上下文紧凑。
- KV cache 减少且准确率损失极小: Memento 应用于包括 Qwen2.5-7B、Qwen3 8B/32B、Phi-4 Reasoning 14B 和 OLMo3-7B-Think 在内的五种模型,实现了 2-3 倍的峰值 KV cache 减少,准确率差距很小,且随规模增大而缩小。被擦除的块仍然在模型利用的 KV cache 中留下了有用的痕迹。
- 实际吞吐量提升: 除了节省内存外,缩短的上下文长度直接转化为更快的推理。该方法使服务吞吐量几乎翻倍,使其在延迟和内存都是限制因素的生产部署中立即发挥作用。
- 开源资源: 微软以 MIT 许可证发布了全部代码库、包含 228K 条带有块分割和压缩摘要的推理轨迹的 OpenMementos 数据集,以及一个用于 KV cache 块掩码的自定义 vLLM 分支。在约 30K 个示例上进行标准的监督微调足以教导这种能力。论文 | 推文
3. Memory Intelligence Agent (MIA)
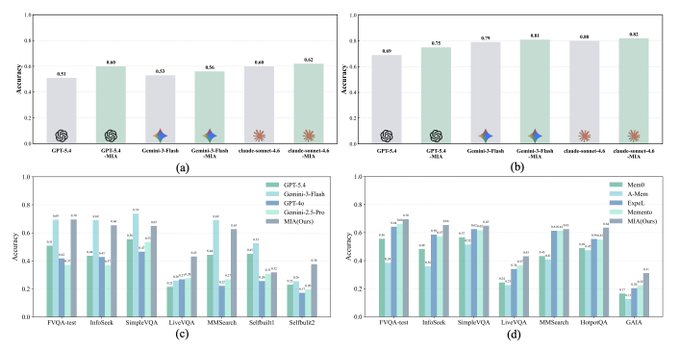
大多数内存增强的研究 Agent 将内存视为静态检索库,导致演化效率低下且存储成本上升。MIA 引入了 Manager-Planner-Executor 架构,其中内存管理者 (Memory Manager) 维护压缩的搜索轨迹,规划者 (Planner) 生成策略,执行者 (Executor) 进行搜索和分析信息。该框架通过双向内存转换,在 LiveVQA 上将 GPT-5.4 的性能提升了高达 9%。
- 双向内存转换: MIA 实现了参数化内存(模型权重)和非参数化内存(检索到的上下文)之间的双向转换。这使得系统能够内化频繁访问的知识,同时将稀有或易变的信息保持在可检索的形式,优化了存储效率和访问速度。
- 交替强化学习: 这三个 Agent 通过交替 RL 进行训练,每个 Agent 的策略都会根据其他 Agent 的行为而改进。这种协同进化的训练确保 Agent 能够开发出互补的策略,而不是竞争同一个信号。
- 测试时参数更新: 与标准的检索增强系统不同,MIA 可以在推理过程中动态更新其参数化内存。这种测试时学习使 Agent 能够适应新领域和不断演化的信息而无需重新训练,在信息格局变化时保持相关性。
- 广泛的基准测试覆盖: 该框架在涵盖问答、知识密集型任务和长篇研究综合的 11 个基准测试中均表现出提升。考虑到视频问答需要跨时间序列的有效内存管理,在 LiveVQA 上高达 9% 的提升尤为显著。论文 | 推文
4. Single-Agent LLMs vs. Multi-Agent Systems
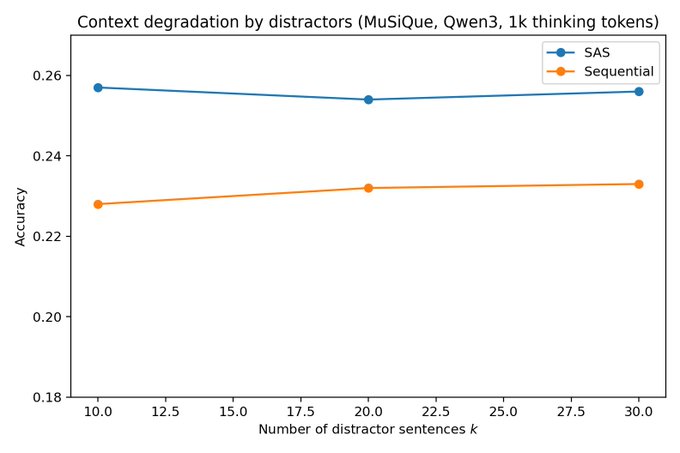
这篇斯坦福大学的论文挑战了多 Agent LLM 领域的一个核心假设,其研究表明,在计算得到适当控制时,单 Agent 系统在多跳推理上的表现始终与多 Agent 架构相当或更好。作者提出了一个基于数据处理不等式 (Data Processing Inequality) 的信息论论证。
- 计算是隐藏的混淆因素: 大多数报道的多 Agent 收益实际上是由增加的测试时计算混淆的,而非架构优势。当推理 Token 预算保持不变时,性能差距会消失或反转,这表明之前的比较无意中衡量的是计算扩展而非协同收益。
- 信息论基础: 作者将其分析建立在数据处理不等式之上,认为在固定推理 Token 预算且上下文利用完美的情况下,单 Agent 系统在本质上具有更高的信息效率。将推理分散到多个 Agent 会在每次移交时引入信息损失。
- 基准测试伪影放大了 MAS 的收益: 在对 Qwen3、DeepSeek-R1-Distill-Llama 和 Gemini 2.5 的测试中,研究发现了显著的评估伪影,特别是在 Gemini 2.5 的基于 API 的预算控制中,这些伪影夸大了明显的多 Agent 优势。标准基准测试还包含偏向于多 Agent 分解的结构性偏见。
- 对系统设计的实际意义: 研究结果建议,团队在致力于多 Agent 架构之前,应明确控制计算、上下文和协作之间的权衡。在许多情况下,将相同的 Token 预算分配给具有更丰富上下文的单 Agent,能以更低的系统复杂度产生更强的结果。论文 | 推文
5. The Universal Verifier for Agent Benchmarks
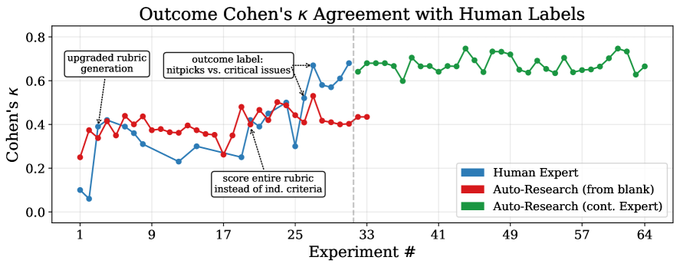
微软研究人员引入了 Universal Verifier(通用验证器),它基于四项设计原则,用于对计算机使用 Agent 的轨迹进行可靠评估。该验证器将误报率降至接近于零,而 WebVoyager 的误报率超过 45%,WebJudge 超过 22%。
- 四项设计原则: 验证器建立在:非重叠的评分标准以减少噪音;分离过程和结果奖励以获得互补信号;区分可控与不可控失败的级联无错评估;以及关注轨迹中所有屏幕截图的分而治之的上下文管理。
- 接近零的误报: 目前的验证器遭受惊人的高误报率,这会破坏基准测试分数和训练数据。Universal Verifier 与人类裁判的一致性达到了人类间的一致性水平,使其足够可靠,可用于评估和 RL 奖励信号生成。
- 累积的设计收益: 没有任何单一的设计选择在性能改进中占据主导地位。作者证明,收益源于所有四项原则共同作用的累积效应,每一项都贡献了有意义的改进,这些改进是复合的,而不是任何一项作为万灵丹。
- 自动化研究的局限性: 团队使用了一个自动研究 Agent 来复制验证器的设计过程。该 Agent 在 5% 的时间内达到了专家验证器质量的 70%,但无法发现驱动最大收益的结构化设计决策,这表明人类的洞察力对于系统级设计仍然至关重要。论文 | 推文
6. Scaling Coding Agents via Atomic Skills
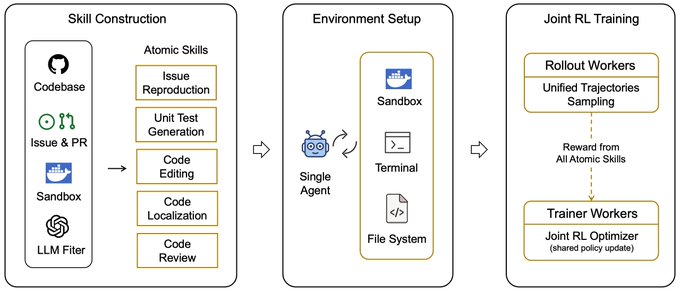
本文提出识别五项原子编程技能(代码定位、代码编辑、单元测试生成、问题复现和代码评审),并通过对这些基础能力的联合强化学习来训练 Agent。
- 原子技能分解: 该框架不再将软件工程视为单一的复合任务,而是正式确定了构成更高级能力的五项基本操作。这使得跨新型任务类型的灵活重组成为可能。
- 跨技能的联合 RL: Agent 通过联合强化学习进行训练,同时优化所有五项原子技能的表现。这种联合训练产生的表示捕获了编程操作之间共享的底层结构。
- 对未见任务的强大泛化: 联合 RL 在五项原子技能和五项复合任务中将平均性能提高了 18.7%。这些改进迁移到了未见的复合任务,包括漏洞修复、代码重构、机器学习工程和代码安全。
- 一种新的扩展范式: 这项工作确立了通过掌握基础技能来扩展编程 Agent,比任务级优化更具样本效率和可迁移性。论文 | 推文
7. Agent Skills in the Wild
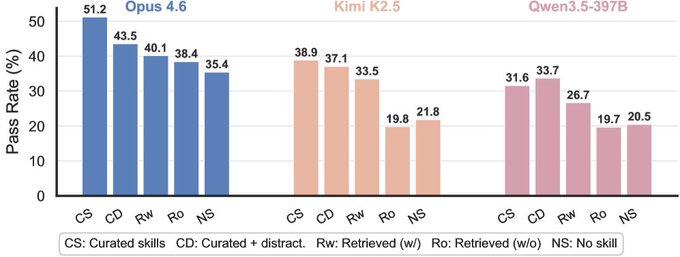
这篇来自加州大学圣塔芭芭拉分校和麻省理工学院的论文首次全面研究了在逐渐现实的设置下的技能效用,揭示了技能的收益远比目前的评估所暗示的要脆弱得多。
- 渐进式难度框架: 研究从使用手工制作、特定任务技能的理想条件,转向需要从 34K 个现实世界技能中检索的现实场景。性能收益在每一步都持续下降。
- 检索是瓶颈: 核心故障模式不是技能执行,而是技能选择。当 Agent 必须从庞大的库中识别正确的技能时,检索步骤引入的错误会级联到执行过程中。
- 细化策略有帮助但不能解决问题: 查询特定和查询无关的细化方法显示出改进,但在现实检索条件下的性能仍远低于理想的基准线。
- 对技能生态系统的意义: 随着 Agent 技能生态系统的增长,研究结果表明,如果技能发现没有相应的进展,仅仅扩大技能库会产生边际效用递减。论文 | 推文
8. MedGemma 1.5
谷歌发布了 MedGemma 1.5 技术报告,引入了一个 40 亿参数的医学 AI 模型,将其能力扩展到 3D 医学成像(CT/MRI 卷)、全切片病理学、多时间点胸部 X 射线分析,并改进了医学文档理解。该模型取得了显著进展,包括在全切片病理学上的宏 F1 值提升了 +47%,在 EHR 问答上提升了 +22%。论文 | 推文
9. LightThinker++: Reasoning Compression & Memory Management
LightThinker++ 超越了静态压缩,引入了三个明确的内存基语:Commit(将一个步骤归档为紧凑摘要)、Expand(检索过去的步骤进行验证)和 Fold(折叠上下文以保持信号清晰)。该框架在标准推理任务中将峰值 Token 使用量减少了 70%,同时获得了 +2.42% 的准确率,并在超过 80 轮的长程 Agent 任务中保持稳定。论文 | 推文
10. Thinking Mid-training: RL of Interleaved Reasoning
- 原文链接: x.com/dair_ai/status/204...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





