如何在 MCP 服务器成为你基础设施的万能钥匙前对其进行加固
- zealynx
- 发布于 2026-04-02 22:38
- 阅读 51
本文深入分析了模型上下文协议(MCP)在 AI 代理部署中存在的安全风险,探讨了其架构缺陷及认证、间接提示词注入等具体威胁。文章为技术人员提供了一套从身份验证、网络硬化到运行时隔离和可观测性的全面加固指南,旨在解决 AI 代理与特权基础设施连接时的安全瓶颈。
MCP 被称为 “AI Agent 的 USB-C”。这种类比在社区尚未完全消化的层面上是准确的——包括这样一个单一的通用端口也为攻击者提供了一个单一的通用入口。
Model Context Protocol 标准化了 LLMs 与外部工具(数据库、API、文件系统、代码执行环境)的对话方式。一个接口,连接任何后端。生产力的提升是实实在在的。但问题也同样存在:你现在在用户和你最高权限的基础设施之间放置了一个非确定性的推理引擎,并通过一个大多数团队以周末黑客松项目的安全姿态部署的协议进行连接。
本指南详细分析了 MCP 部署中实际出现的问题,为什么传统的 API 安全假设不再适用,以及在每个层级(身份、传输、运行时和可观测性)应实施什么措施来弥补漏洞。
如果你正在寻找快速参考版本,请参阅我们的 MCP 安全清单:AI Agent 的 24 项关键检查 或 交互式 MCP 清单。
经过强化的 MCP 部署中的“安全”是什么样的
一个经过强化的 MCP 部署会同时强制执行以下属性:
- 每一个工具调用都被视为需要加密证明的不可信交易
- 在执行链中的每个节点(而不不仅仅是边界)都验证身份
- 工具检索到的不可信数据在进入 Context Window 之前会经过确定性的清理
- 执行环境在内核级别是不可变的、极简的且沙盒化的
- 通过结构化、关联的审计日志实现端到端的可追溯性
如果缺少其中任何一项,你就存在漏洞。大多数生产环境的 MCP 部署都缺少这全部五项。
问题在于架构,而非配置

传统的 API 在确定性的边界内运行。你定义端点,根据模式(schema)验证输入,并通过中间件强制执行授权。控制流是可预测的。
MCP 服务器位于特权基础设施和非确定性推理引擎之间。LLM 决定调用哪些工具、传递哪些参数以及如何解释结果。当它通过 MCP 服务器采取行动时,它继承了委托的用户权限——这些权限的范围通常比任何单一 API 调用所授予的都要广泛得多。
该架构有三个组件:
- Host:运行 AI 的应用程序(IDE、聊天界面、自动化平台)
- Client:解析请求、管理上下文、与服务器通信
- Server:提供 AI 可以调用的工具、资源和 Prompt 模板
交互在这些 信任边界 之间持续流动。如果安全模型仅在边界进行验证,或者假设 LLM 会“听从指令”,那么这种设计从根本上就是失败的。
生态系统实际失败的原因
凭证危机
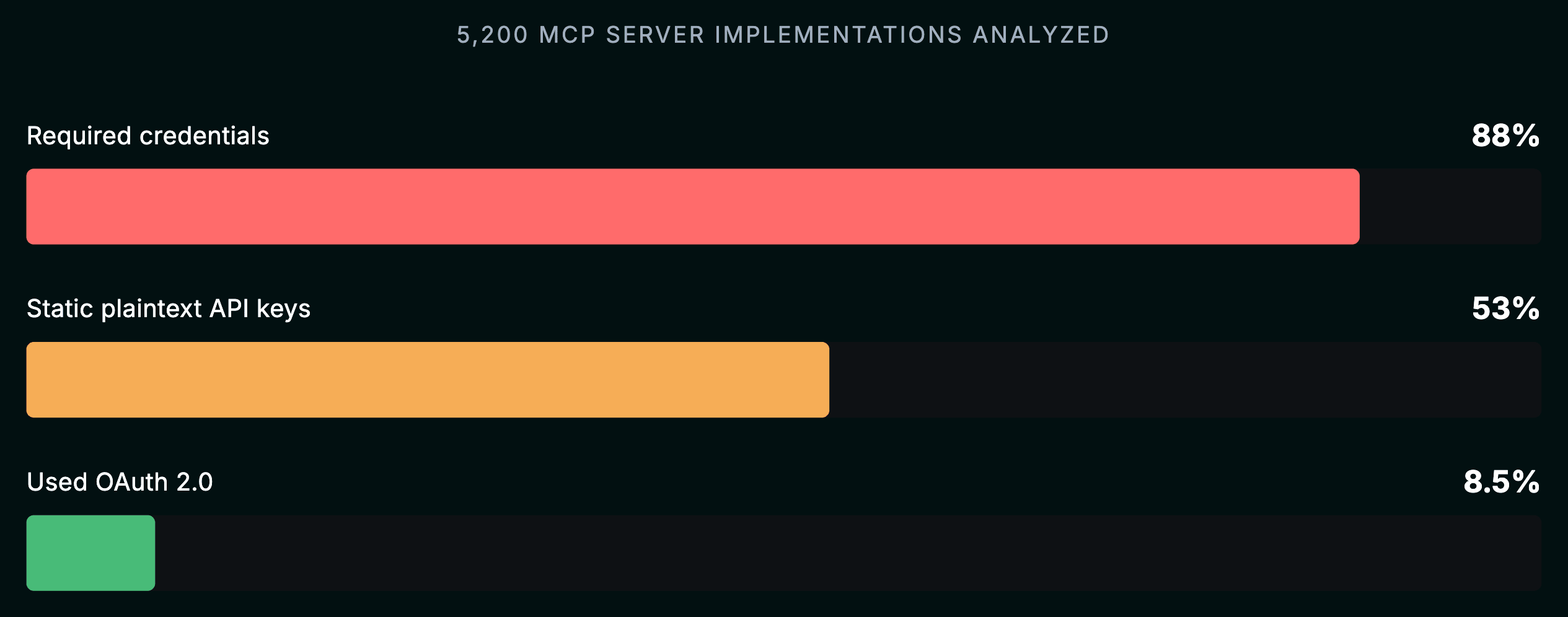
Astrix Security 在 2025 年的一项分析评估了 5,200 多个开源 MCP 服务器实现。数据不容乐观:
- 88% 的服务器需要凭证才能运行
- 53% 以上完全依赖以明文环境变量形式存储的静态、长寿命 API Key 或个人访问 Token
- 仅有 8.5% 使用了 OAuth 2.0
这是将早期的云时代安全实践应用到了一个比以前大几个数量级的 攻击面 上。
真实的漏洞,而非假设
NeighborJack:数百个 MCP 服务器默认绑定到 0.0.0.0。同一局域网内的任何设备都可以在无需身份验证的情况下连接并执行工具。
mcp-server-git CVEs(2026 年 1 月):Anthropic 自己的参考实现中出现了三个 CVE——路径穿越、任意文件删除,以及与文件系统服务器配合时形成的链式 RCE。由于各团队将参考架构克隆为模板,这些漏洞立即在生态系统中传播开来。
Asana 跨租户污染(2025 年 5 月):一个租户隔离缺陷影响了约 1,000 家企业客户。具有共享服务器的多租户 MCP 部署引入了传统隔离手段无法遏制的面向互联网的攻击面。
AI Engine WordPress 插件(2025 年 6 月):通过不安全的 MCP 工具配置实现的 权限提升 让低权限用户能够执行管理员功能。超过 100,000 个站点受到影响。
Supabase MCP + Cursor:通过恶意支持工单数据传递的 Prompt Injection 利用了 IDE 中权限过大的工具,将私有数据库表暴露给外部攻击者。
锁定身份和授权
防止混淆代理攻击(Confused Deputy Attack)
MCP Client、代理服务器和第三方 API 之间的交互创建了一个委托信任链,该链条容易受到混淆代理问题的影响。以下是具体的失效模式:
- MCP 代理使用固定的 OAuth 2.0 客户端 ID 连接到第三方 API
- MCP Client 动态注册并接收它们自己的客户端 ID
- 第三方认证服务器在初始用户授权后使用 Consent Cookie
- 攻击者利用动态客户端注册 + 现有的 Consent Cookie,在无需用户同意的情况下静默获取授权码
代理服务器利用其提升的权限代表攻击者采取行动。
必需的缓解措施:
- 在启动第三方 OAuth 流程 之前 实施针对每个 Client 的同意流程
- 维护每个用户的已批准
client_id值的本地注册表;针对该注册表验证所有请求 - 同意 UI 必须通过名称明确标识请求方 Client,显示请求的范围,并实施 CSRF 保护
- 通过
frame-ancestorsCSP 指令或X-Frame-Options: DENY防止 iframe 嵌套 - 为同意 Cookie 添加
__Host-前缀并设置Secure、HttpOnly和SameSite=Lax - 使用严格的字符串匹配验证
redirect_uri(不进行模式或通配符匹配) - 为每个 OAuth 请求生成一个加密安全的、具有短 TTL(≤10 分钟)的一次性
state参数
杜绝 Token 传递
Token 传递——即 MCP 服务器接受来自 Client 的身份验证 Token 并将其直接用于下游 API——在 MCP 安全规范中被明确禁止,但在实践中仍然很常见。
为什么这很危险:
- 绕过了应用层级的速率限制和请求验证
- 破坏了依赖于准确 Token 受众声明(Audience Claims)的监控
- 导致审计追踪断裂——你无法区分服务器发起的行动和 Client 伪造的请求
解决方法:MCP 服务器必须使用其自身具有加密范围的凭证独立于 Client Token 向下游服务进行身份验证。
防止会话劫持
如果你在 Client-Server 通信中使用持久会话 ID,而攻击者拦截了一个,他们将完全绕过初始身份验证。
实施要求:
- 尽可能避免使用有状态会话进行身份验证
- 在必须使用会话 ID 时,使用 CSPRNG (UUIDv4) 生成
- 频繁轮换
- 会话 Key 格式应为
<user_id>:<session_id>,这样被劫持的会话就无法冒充其他用户
用加密工作负载身份替换静态 Key
停止使用原始 API Key。采用加密工作负载身份标准:
-
SPIFFE/SPIRE:为微服务和 MCP 服务器提供短寿命、自动轮换、加密可验证的身份
-
Token Exchange (RFC 8693):交换用户的 OAuth Token 为适当范围的委托 Token,而不是直接传递用户 Token
-
DPoP (RFC 9449):将访问 Token 绑定到特定 Client 的公钥,防止拦截后的重放攻击
-
丰富授权请求 (RFC 9396):通过与服务器代码解耦的中心化策略引擎(Open Policy Agent、Amazon Cedar、OpenFGA)定义细粒度的访问规则
-
- *
防范间接 Prompt Injection
理解攻击模型

直接 Prompt Injection(“忽略之前的指令”)通过聊天界面针对模型。间接 Prompt Injection (XPIA) 更为危险:恶意指令嵌入在 Agent 通过合法工具调用检索到的不可信数据中。
核心问题:LLMs 将工具结果处理为扁平的文本流。它们在架构上无法区分数据上下文和嵌入的命令。对模型来说,获取到的邮件正文中隐藏的指令与系统消息是无法区分的。
工具中毒(Tool Poisoning)是一种变体,攻击者在 MCP 工具元数据(工具名称和描述)中嵌入恶意指令,从而操纵模型选择哪些工具以及如何格式化参数。关于 LLMs 如何处理对抗性输入的深入探讨,请参阅我们的 LLM 安全的认知基础 分析。
跨 MCP 集成的真实 XPIA 向量
| MCP 集成 | 注入机制 | 后果 |
|---|---|---|
| Gmail | 邮件正文中的隐藏 HTML (<div style="display:none">) |
静默外泄 30 天的收件箱内容 |
| Salesforce | 公共 CRM 字段中被操纵的文本 | Agent 创建零价值订单,绕过计费 |
| GitHub | PR 描述中不可见的 HTML 注释 | 未经审查的代码合并到 main 分支,跳过 CI |
| Slack | 共享频道中来自受损账户的消息 | 外泄 #finance 和 #deals 历史记录 |
| Zendesk | 入站支持工单中的 Payload | Agent 泄露活动用户账户列表 |
| Google Drive | 共享文档中的 1pt 白色文本 | 泄露来自其他合同的专有定价 |
| Web 搜索 | 竞品页面 HTML 注释中的指令 | Agent 生成带有伪造法律声明的竞争分析 |
| Gong | 录音通话中大声说出的指令 | Agent 将内部账户历史转发给外部潜在客户 |
| Jira | “重现步骤”字段中的指令 | Agent 将生产环境凭证发布到公共追踪器 |
| Notion | 折叠块中隐藏的指令 | Agent 承诺公司尚未发布的外部产品特性 |
构建确定性的 XPIA 防御
告诉 LLM “忽略外部指令”的系统 Prompt 是不起作用的。模型通过相同的神经通路处理保护性 Prompt 和恶意 Payload。这里没有权限边界。攻击者利用语义技巧、混淆和多语言命令来轻而易举地绕过基于 Prompt 的护栏。
防御必须发生在数据层,在不可信内容到达 Context Window 之前。这是 纵深防御 的核心原则。
第一层 —— 同步的基于正则的清理(<1ms):
- 应用 Unicode 规范化以防止同形文字攻击(例如,视觉上与 ASCII 相似的西里尔字母)
- 剥离注入的角色标记(
SYSTEM、ASSISTANT、<|im_start|>) - 中和隐藏在 Base64 或 URL 编码格式中的 Payload
第二层 —— 基于机器学习的句子级分类(~10ms):
正则无法捕捉新颖的、有创意地重新表述的攻击。轻量级的 MLP 分类器可以处理这一层。例如,StackOne Defender 框架使用了一个基于 MiniLM-L6-v2 的 22 MB ONNX 模型,可以在标准 CPU 上运行。
关键的设计选择是句子级分类。中毒的响应通常会将一条恶意句子埋在数百个单词的合法内容中。对整体进行分类会稀释信号。将文本拆分为句子,为每个句子评分(0.0 到 1.0),如果任何句子超过阈值,则隔离整个响应。这种方法实现了 90.8% 的 F1 分数,优于像 DistilBERT 和 Meta Prompt Guard v1 这样更大的模型。
工具感知的风险评分:根据数据源信任度自动分配风险配置文件。与未经身份验证的外部数据交互的工具(gmail_*、email_*)获得“极高风险”配置文件,并具有较低的分类阈值。内部数据库查询获得较低的风险配置文件。
边界注释:将清理后的工具结果包装在加密边界标签中(例如 <tool_output>...</tool_output>),并指示系统 Prompt 将这些边界内的内容仅视为惰性数据。
加固网络层
强制执行双向 TLS (mTLS)
标准 TLS 仅验证服务器。对于 MCP 来说,这还不够——你需要在服务器处理任何 JSON-RPC Payload 之前验证 Client 的身份。对于所有远程部署,mTLS 是强制性的。
实施清单:
- 使用
chmod 600保护证书文件和私钥,仅对服务器进程可读 - 永远不要将证书提交到版本控制系统
- 使用具有前向保密密码套件的 TLS 1.3
- 通过正确的使用者备用名称 (SAN) 强制执行主机名验证
- 使用 cert-manager、ACME 或内部 PKI 自动执行具有短有效期的证书轮换(几天/几周)
- 通过 CRL 或 OCSP 启用持续的撤销检查
隔离网络
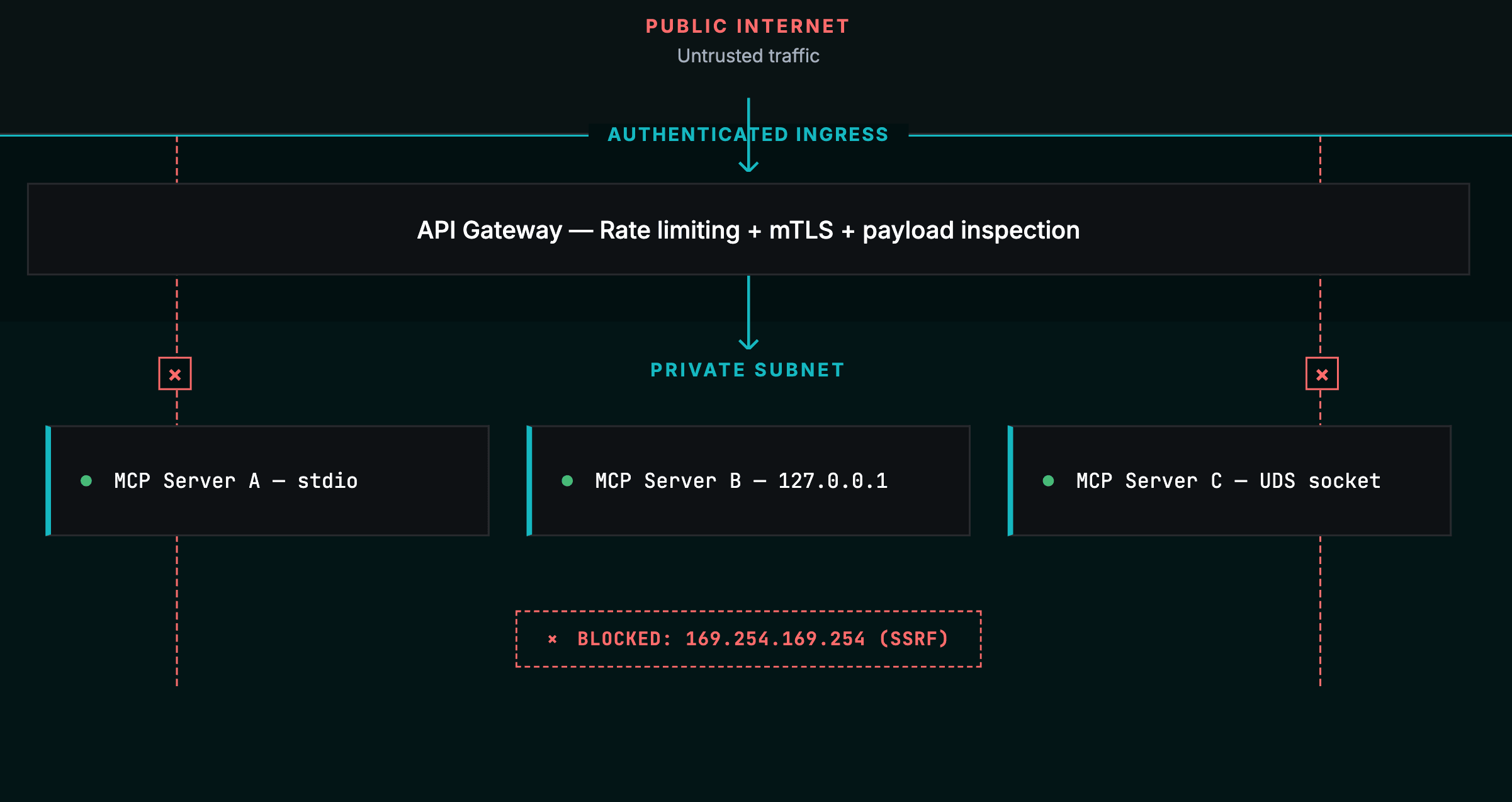
绑定(Binding):永远不要绑定到 0.0.0.0。对于仅限本地的服务器,使用 stdio 传输(将访问权限限制在父级 MCP Client 进程)或通过 Unix Domain Sockets 绑定到 127.0.0.1。对于远程部署,在严格的网络控制下使用 Streamable HTTP。
| 配置 | 要求 | 理由 |
|---|---|---|
| 默认策略 | 将 INPUT, FORWARD, OUTPUT 链设置为 DROP | 默认拒绝;仅允许显式允许的流量通过 |
| 状态追踪 | 允许 conntrack --ctstate RELATED,ESTABLISHED |
不要阻塞合法出站请求的返回流量 |
| 流量重定向 | 将 HTTP/HTTPS (80/443) NAT 重定向到 API 网关端口(如 8080) | 强制所有流量通过网关进行速率限制和 Payload 检查 |
| 出站 / SSRF 预防 | 拦截流向 169.254.169.254 的出站流量;仅允许必需的下游域名 |
防止 SSRF 攻击提取 IAM 凭证或遍历内部网络 |
| 分段 | 将 MCP 服务器放置在无法从公共互联网访问的私有子网中 | 外部 Client 通过经过身份验证的 Ingress 控制器进行路由 |
在生产环境中禁用所有调试、管理和状态端点。它们会泄露诊断信息。
约束运行时环境
妥善进行容器化
在宿主机上将 MCP 服务器作为原始脚本运行是一个严重的安全失效。但是,使用完整 Ubuntu 镜像的基础 Docker 容器也是一种虚假的安全。
使用经过强化的最小化镜像:Alpine Linux 或 Google 的 distroless 镜像。Distroless 镜像缺少包管理器、调试工具和 Shell(bash、sh)。即使攻击者在 MCP 代码中触发了 RCE,如果没有这些实用程序,他们也无法建立持久性、下载 Payload 或提升权限。
其他容器要求:
- 仅以非 root 用户身份运行
- 强制执行全局只读文件系统;仅将临时内存卷用于临时处理
- 在编排层设置 CPU 和内存配额,以防止死循环、过多的 API 调用或来自故障 Agent 的 DoS
管理工具预算
向 Agent 暴露数百个工具会降低推理性能,使 Context Window 臃肿,并扩大攻击面。
不要将每个下游 API 端点映射到一个单独的 MCP 工具。这种 1:1 映射是一种反模式(anti-pattern)。围绕整合后的用例设计工具,并使用 MCP “prompts” 作为宏来引导 LLM 行为。仅公开 Agent 明确定义的角色所严格需要的工具。
增加内核级沙盒
通过以下方式增强容器化:
- AppArmor / Seccomp / SELinux:自定义限制性配置文件,拒绝预料之外的系统调用(修改内核参数、原始网络套接字)
- Kata Containers / gVisor:用于高安全环境(金融交易、PII 处理、LLM 生成的代码执行)——在用户空间拦截系统调用的轻量级 VM,防止内核漏洞利用到达宿主机
- 具有远程证明的 可信执行环境:在数据处理前通过数学方式保证代码和内存的完整性
生命周期强制执行:当 Client 会话关闭时,强制终止所有 MCP 后台进程和临时执行环境。不留任何持久化据点。
从第一天起构建可观测性
结构化你的审计日志
标准的 Web 日志对于 MCP 来说是不够的。当出现问题时,你需要重构 LLM 的整个决策链:它推理了什么,调用了哪些工具,传递了哪些参数,检索了什么数据,以及它对结果做了什么处理。
每次交互必须包含:
- ISO 8601 时间戳
- 在 Client 请求、网关路由、LLM 推理、工具调用和响应交付中持续存在的关联/追踪 ID (Trace ID)
- 用于归因的服务器 ID、用户 ID、团队 ID
- 调用的方法、执行持续时间、响应大小、结果/错误状态
- 安全事件:被隔离的 Prompt 计数、策略违规、未授权访问尝试、上下文 Payload 异常
使用 OpenTelemetry 进行跨多工具、多服务器链的分布式追踪。如果你正在围绕 MCP 构建 事件响应 计划,结构化日志不是可选的——它们是你的主要取证数据源。
清理日志输出
日志绝不能包含 LLM 处理的凭证、API Key、环境变量或 PII。在应用层实施掩码逻辑,以便在写入磁盘或传输到 SIEM 之前脱敏授权标头、Token Payload 和敏感 Prompt 数据。
使用异步日志记录(例如 Pino)、批处理和缓冲,这样可观测性栈就不会成为延迟瓶颈或 DoS 向量。
通过 MCP 网关中心化
专用网关为监控整个组织的 LLM Token 生成、Agent 路由和工具使用模式提供了一个统一的控制平面。它维护服务器清单,跟踪每台服务器的生命周期数据、审批状态、健康指标和被隔离的 Prompt 计数。
确保供应链安全
进行加密验证
所有部署的 MCP 服务器在执行前都需要强制性的代码签名和完整性验证。使用 Sigstore 自动签署容器镜像并构建出处(provenance)。
维护一份 AI 软件物料清单 (AIBOM),跟踪所有模型、数据集和 MCP 依赖项的血缘。运行经过审核的内部私有已批准服务器注册表——不要让开发人员直接从公共仓库安装。关于 供应链攻击 在实践中如何传播的更多信息,请参阅我们的术语表。
运行协议特定的漏洞扫描程序
标准的 SAST 工具会遗漏 LLM 工具定义和 Prompt 模板中的语义风险。将专门的扫描程序集成到你的 CI/CD 流水线中:
- MCPSafetyScanner (AI Assurance Lab):多 Agent 工具,可模拟针对服务器工具注册表的 Prompt Injection 攻击,将发现的结果与安全知识库进行交叉比对,并生成修复报告
- Nova Proximity:深度参数分析,检测注入向量、Jailbreak 模式和可疑代码。支持最新的 MCP 规范 (2025-11-25),分析 Streamable HTTP 传输和会话管理
- MCP-Scan (Invariant):检测工具中毒和 “MCP Rug Pulls”——即初始良性的工具定义在审批后被恶意篡改
- Enkrypt MCPScan:涵盖 IDOR、DoS、最小权限审计、超时设置和 MCP 特定网络安全的全面分析
- Dockyard / MCP Sentinel:GitHub Actions,用于构建、扫描、签名 (Sigstore) 并发布 MCP 服务器的容器镜像
在每次重大代码更改后以及针对生产配置持续运行这些程序。如果你想对你的 MCP 部署进行专业评估,Zealynx 提供专门的 MCP 安全审计服务。
警惕特定领域的放大效应
MCP 漏洞的破坏半径在很大程度上取决于它连接的内容。
CRM / 营销自动化:一个通过 Salesforce、HubSpot 或 Klaviyo 运行培育活动的受损 Agent 可以读取客户通信、提取竞争情报,并发送未经授权的外部电子邮件。使用具有紧密范围限制的服务主体(例如 DATABRICKS_SERVICE_PRINCIPAL_ID,而非全局 Token)。对所有改变状态的操作强制执行“人在回路”授权:AI 起草,人类审批。
开发环境 / UI 生成:操作代码库(例如 Unity Editor 集成)或生成交互式 UI 组件(例如 Shopify MCP UI)的 MCP 服务器会授予对专有源代码的访问权限,并通过 AI 生成的界面元素创建 XSS/ 钓鱼 攻击面。
加密货币 / DeFi:这是风险最高的上下文。通过连接 MCP 的钱包工具暴露私钥或助记词是无法挽回的。警惕 “Multi-MCP 功能优先级劫持”(恶意插件劫持功能执行优先级)和 “跨 MCP 触发”(恶意服务器返回旨在触发其他已启用插件操作的 Prompt)。使用 Scrypt 保护静态密钥。强制执行本地、离线 LLM 执行——第三方模型提供商绝不能访问钱包数据或交易签名。对于 DeFi 团队,我们的 AI 红队指南 涵盖了如何系统地对这些场景进行压力测试。
下一步该做什么
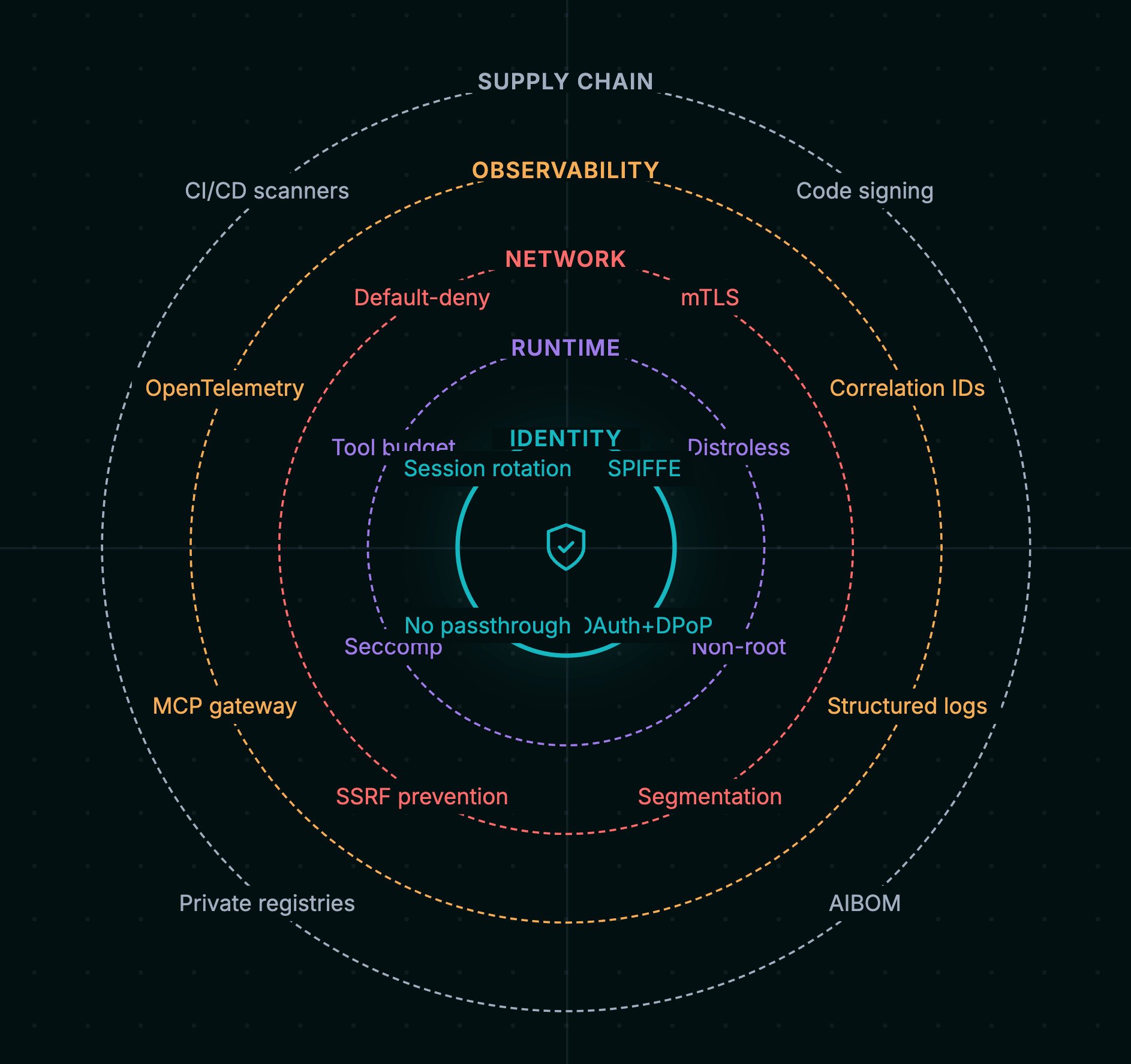
选择部署中最薄弱的一层并从那里开始:
- 审计你的凭证。如果你在环境变量中运行静态 API Key,请迁移到 SPIFFE/SPIRE,或者至少实施带有短寿命 Token 和 Token 交换 (RFC 8693) 的 OAuth 2.0。
- 扫描你的服务器。针对当前的工具定义运行 MCP-Scan 或 MCPSafetyScanner。你可能会发现以前不知道的工具中毒向量。
- 妥善进行容器化。切换到 distroless 基础镜像,强制执行非 root 执行,并添加 Seccomp/AppArmor 配置文件。
- 实施 XPIA 清理。在所有工具输出进入 LLM Context Window 之前,部署一个两层防御流水线(正则 + 机器学习分类器)。
- 记录一切。为每次工具调用添加关联 ID 和结构化的 JSON 日志。如果你无法在事件发生后重现发生了什么,你就无法修复它。
这些都不是可选的。MCP 将“AI 可以阅读我的邮件”到“AI 刚刚将我的整个收件箱转发到了一个外部地址”之间的距离缩短到了入站消息中的一个间接 Prompt Injection。该协议之所以强大,正是因为它具有通用性——而它之所以危险,也正是出于同样的原因。
如果你在为你的 MCP 部署进行 威胁建模 时需要帮助,或者想要专业的 AI 安全审计,我们随时为你提供帮助。
与我们联系
在 Zealynx,我们专注于 AI 安全审计 和 MCP 安全评估。无论你是部署第一个 MCP 服务器还是加固现有的集群,我们的团队都能识别自动化扫描程序遗漏的差距——从混淆代理漏洞到工具链中的间接 Prompt Injection。
常见问题解答:MCP 服务器加固
1. 什么是 Model Context Protocol (MCP),为什么它对安全很重要?
Model Context Protocol 是一个开放标准,它定义了 AI Agent (LLMs) 如何与外部工具和服务(数据库、API、文件系统和代码执行环境)进行通信。它对安全很重要,因为它在非确定性推理引擎和你的最高权限基础设施之间创建了一个单一的、标准化的接口。与控制流可预测的传统 API 不同,MCP 让 AI 决定调用哪些工具、传递哪些参数以及如何解释结果——所有这些都带有委托的用户权限。一个 MCP 服务器中的漏洞可能会级联到每一个连接的系统。有关基础概述,请参阅我们的 Model Context Protocol 术语表条目。
2. 什么是间接 Prompt Injection,它与直接 Prompt Injection 有什么不同?
直接 Prompt Injection 通过聊天界面针对 AI 模型——用户直接输入“忽略之前的指令”。间接 Prompt Injection (XPIA) 危险得多:攻击者在 AI 通过合法工具调用检索到的数据中嵌入恶意指令。例如,Google 文档中的隐藏文本、GitHub PR 中的不可见 HTML 注释或 Zendesk 中精心设计的支持工单。AI 在架构上无法区分检索到的数据和命令,因此它会像对待系统消息一样执行隐藏指令。防御必须在数据层(正则清理 + 机器学习分类)进行,即在内容到达 Context Window 之前,而不是通过基于 Prompt 的护栏。
3. MCP 部署中的混淆代理问题是什么?
混淆代理(Confused Deputy)是一种权限提升模式,其中受信任的中间体(MCP 代理服务器)被诱骗代表攻击者执行未经授权的操作。在 MCP 中,当攻击者利用动态 Client 注册和缓存的 Consent Cookie 来静默获取 OAuth 授权码时,就会发生这种情况。代理服务器随后使用其提升的权限执行请求,认为该请求来自合法用户。缓解措施需要针对每个 Client 的同意流程、严格的 redirect_uri 验证、受 CSRF 保护的同意 UI 以及具有短生存周期的加密安全一次性 state 参数。
4. 为什么我不能仅通过防火墙和 TLS 来保护我的 MCP 服务器?
标准 TLS 仅向 Client 验证服务器——它不验证 Client 是谁。MCP 需要双向 TLS (mTLS),其中双方都出示证书。但即使是 mTLS 也只能保护传输层。MCP 独特的风险发生在网络层之上:工具结果中的 Prompt Injection、元数据中的工具中毒、权限过大的工具注册表以及非确定性的 LLM 行为。你需要 纵深防御——在每个节点进行身份验证、运行时沙盒化、Context 注入前的数据清理以及结构化的可观测性。防火墙阻止网络层攻击;它无法阻止隐藏在 Zendesk 工单中的恶意指令外泄你的用户数据库。
5. 什么是工具中毒,攻击者如何利用它?
工具中毒是 Prompt Injection 的一种变体,攻击者直接在 MCP 工具元数据(工具的名称、描述或参数定义)中嵌入恶意指令。由于 LLM 读取这些元数据来决定使用哪些工具以及如何调用它们,中毒的工具可以操纵 AI 的工具选择、更改它传递的参数或重定向其输出。例如,工具描述可能包含隐藏指令,告诉模型在请求中始终包含用户的 API Key。防御措施包括对工具定义进行加密验证、针对已签名的工具注册表进行运行时完整性检查,以及使用像 MCP-Scan 这样能检测工具定义在审批后是否发生更改(“MCP Rug Pulls”)的专门扫描程序。
6. 团队应该如何处理加密货币和 DeFi 环境中的 MCP 安全?
DeFi 是风险最高的 MCP 部署上下文,因为私钥暴露是不可挽回的——区块链上没有“撤销”按钮。团队必须强制执行本地、离线 LLM 执行,这样第三方模型提供商就永远无法访问钱包数据或交易签名。警惕“Multi-MCP 功能优先级劫持”(恶意插件覆盖合法功能执行)和“跨 MCP 触发”(一个服务器的输出操纵另一个服务器的工具)。使用硬件支持的密钥存储,对所有价值转移操作强制执行人在回路,并将每个 MCP 工具结果都视为潜在的对抗性结果。有关 Web3 中全面的 AI 安全测试,请参阅我们的 AI 红队 和 AI 渗透测试 指南。
术语表
| 术语 | 定义 |
|---|---|
| Model Context Protocol | 定义 AI Agent 如何通过统一接口与外部工具和服务通信的开放标准。 |
| Prompt Injection | 操纵 AI 系统输入以绕过安全控制或提取未经授权信息的攻击技术。 |
| Context Window | LLM 在单次交互中可以处理的最大文本量,包括系统 Prompt、用户输入和工具结果。 |
| 信任边界 | 系统中信任级别发生变化的点,需要对跨越它的所有数据进行验证。 |
| 纵深防御 | 一种分层部署多个独立控制措施的安全策略,使得单一失效不会危及整个系统。 |
| 供应链攻击 | 针对软件供应链中安全性较低的环节而非直接针对主要目标的攻击。 |
| 权限提升 | 利用漏洞获得超出最初授权的高级访问权限。 |
| 可信执行环境 | 通过硬件级安全保证代码和数据完整性的隔离处理环境。 |
- 原文链接: zealynx.io/blogs/mcp-ser...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





