我觉得 Zig 最有意思的地方,不是快,而是它很少跟你打马虎眼
- King
- 发布于 2小时前
- 阅读 20
这两天我重新过了一遍Zig0.15.2的官方文档,最大的感受不是“这门语言真猛”,而是另外一件事:它不太爱糊弄你。很多语言上手的时候都挺顺。变量一写,函数一调,内存怎么来的先别管,错误怎么处理先别管,反正程序先跑起来再说。Zig不是这个路子。它经常会逼你提前回答一些问题:这
这两天我重新过了一遍 Zig 0.15.2 的官方文档,最大的感受不是“这门语言真猛”,而是另外一件事:
它不太爱糊弄你。
很多语言上手的时候都挺顺。
变量一写,函数一调,内存怎么来的先别管,错误怎么处理先别管,反正程序先跑起来再说。
Zig 不是这个路子。
它经常会逼你提前回答一些问题:
- 这个值到底有没有可能是空?
- 这个函数失败了怎么办?
- 这段内存是谁分配的?
- 谁负责释放?
- 这玩意儿是运行时算,还是编译时就得确定?
刚开始会觉得它有点“较真”。
但看久了会发现,这种较真其实挺有价值,因为系统编程里很多坑,本来就不是因为你不会写,而是因为以前有太多东西被默认糊过去了。
从一个 Hello World 就能看出来 Zig 的脾气
比如最简单的程序:
const std = @import("std");
pub fn main() !void {
std.debug.print("Hello, Zig!\n", .{});
}这里最值得注意的其实不是 print,而是这个:
pub fn main() !void第一次看到 Zig 的人,通常都会多看一眼这个 !void。
它的意思很直接: 这个函数要么正常结束,要么返回一个错误。
这就是 Zig 很典型的地方。它不喜欢把“失败”藏起来。 不是某个约定俗成的返回值,也不是某种神出鬼没的异常机制,而是直接写在类型里。
我觉得这其实很接近 Zig 那句很出名的话:
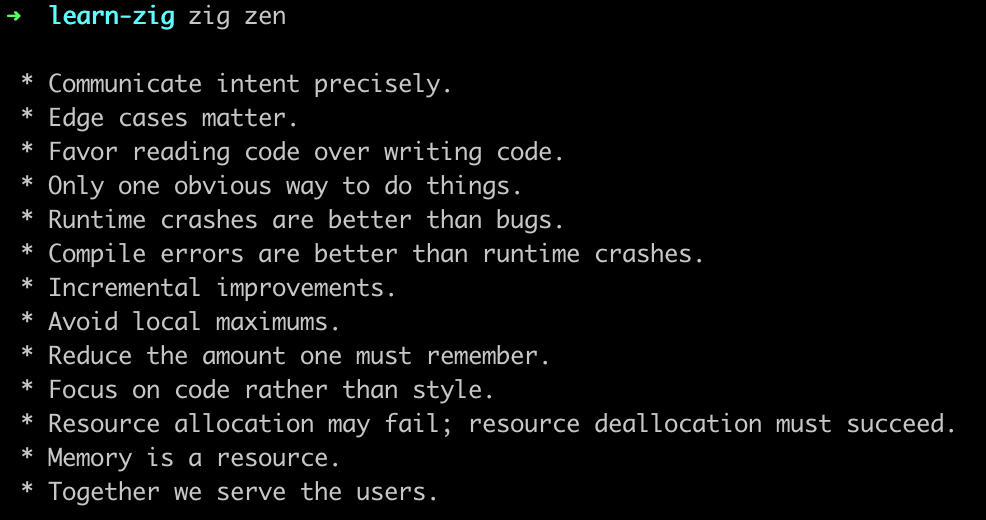
Communicate intent precisely.
准确表达意图。
这句话说起来很虚,但放到代码里就一点也不虚。 会失败就写出来,会是空就写出来,要清理资源就写出来。Zig 很多地方都是这个思路。
Zig 最适合新手先建立的,不是语法,而是直觉
我现在越来越觉得,学 Zig 如果一开始就去背一堆语法细节,很容易把自己绕进去。
它更像是一门先要建立直觉的语言。
第一个直觉:空值和失败不是一回事
这件事 Zig 分得特别清楚。
?T 的意思是,这个东西可能没有值。
!T 的意思是,这个过程可能失败。
乍一看只是两种写法,实际上区别很大。
因为现实里“没有”和“出错”真的不是一回事。
比如你查配置:
- 没配这个字段,是“没有”
- 配置文件读失败了,是“出错”
很多语言或者很多业务代码,喜欢把这两种情况揉在一起。 最后逻辑就会越来越脏。
Zig 一上来就把这件事拆开,我觉得是很对的。 它很在意边界情况,这也很像 Zig Zen 里的另一句:
Edge cases matter.
边界情况很重要。
这句话听着像废话,但真写过线上代码就知道,它一点都不废。主流程谁都会写,真正容易出问题的,经常就是那些“应该不会吧”的地方。
第二个直觉:资源清理不要靠记性
这个我觉得是 Zig 很讨人喜欢的一个点。
如果你写过稍微复杂一点的代码,应该都遇到过这种场景:
- 文件打开了,后面某一步报错,忘了关
- 内存申请了,中间 return 了,忘了 free
- 锁加了,分支一绕,人就忘了 unlock
这种事不是因为你笨,是因为人脑本来就不适合记所有退出路径。
所以 Zig 的 defer 很好用:
defer file.close();意思就是,别管后面怎么走,这个作用域结束时都执行。
如果只想在出错时执行,还有 errdefer。
这个设计没什么花活,但非常实在。资源申请完,清理逻辑立刻写在旁边,读的时候也轻松,改的时候也不容易漏。
这也是为什么我觉得 Zig 有一种很少见的“朴素感”。 它不喜欢拿复杂概念吓人,很多时候就是给你一个刚刚够用、但特别好用的语义。
第三个直觉:内存不是背景板
这可能是 Zig 跟很多现代语言差别最大的地方之一。
很多时候我们会不知不觉把内存当成背景设施。 函数返回一段数据,好像它“本来就在那里”;字符串切一下,好像那就是一个轻飘飘的新对象。
Zig 不太让你这么想。
尤其是你开始接触 slice、allocator 这些东西之后,很快就会意识到: 内存不是舞台背后的工作人员,它就是台上的角色。
比如 slice 这个东西,刚学的时候很容易把它想成“轻量数组”。
但你多看几遍就会明白,它更像是“对一段已有内存的视图”。 它不拥有内存,它只是引用那段内存。
这就逼着你去想几个以前可能懒得想的问题:
- 这块内存是谁的?
- 它现在还活着吗?
- 这个 slice 会不会因为底层扩容而失效?
这类问题在别的语言里不是不存在,只是经常被包装得太好,看起来像不存在。
Zig 不喜欢这种包装。 它会把 allocator、生命周期、失败路径都尽量放到明面上。
所以 Zig Zen 里我很喜欢两句:
Resource allocation may fail; resource deallocation must succeed.
资源申请可能失败,但资源释放必须成功。
Memory is a resource.
内存也是资源。
这两句特别像 Zig 的底色。不是在讲大道理,就是在提醒你:别把最重要的成本假装成空气。
Zig 给我的感觉,不像是在“简化世界”,更像是在“停止自欺欺人”
这可能是我最想说的一点。
很多语言的思路是: 把复杂性包起来,让你先快乐地写。
这当然有价值,而且很多场景下非常有价值。 但 Zig 走的是另一条路。它更像是在说:
- 复杂性本来就在那
- 你早晚得处理
- 那不如现在就说清楚
所以它会特别在意错误处理。 特别在意资源管理。 特别在意代码读起来是不是直。 特别在意能不能在更早的时候暴露问题。
Zig Zen 里还有两句,也很能说明这件事:
Runtime crashes are better than bugs.
运行时崩溃,也比悄悄出 bug 强。
Compile errors are better than runtime crashes.
编译错误,又比运行时崩溃更好。
这两句第一次看有点硬。 但你真做过工程,就会知道它说得挺实在。
最可怕的不是程序挂了。 最可怕的是它没挂,但结果已经悄悄错了,而且你过几天才发现。
Zig 很多设计,都是想把这种问题往前推。 能在编译期发现,就别拖到运行时。 能在运行时立刻炸出来,就别让它伪装成“还行”。
这门语言其实不只是适合“底层大牛”
我一开始也有点这种误解,觉得 Zig 是那种离普通开发者有点远的语言。
但后来我反而觉得,它很适合拿来重新学一遍“程序到底是怎么回事”。
特别是如果你属于下面这几种情况:
- 写过 C/C++,但受够了一堆历史包袱
- 想学系统编程,但 Rust 一上来有点陡
- 想真正搞懂错误处理、内存、slice、allocator 这些基本问题
- 想写一些小而硬的 CLI 或工具程序
Zig 都挺值得试试。
因为它不是靠堆很多概念来显得高级,反而是不断逼你把事情说清楚。 从这个意义上说,它甚至有点像一门“帮助你重新建立编程常识”的语言。
我现在理解的 Zig,不是“更现代的 C”,而是一种很克制的工程观
看完官方文档之后,我对 Zig 最深的印象反而不是性能,不是 comptime,甚至也不是它的工具链。
而是一种很统一的气质。
它不太鼓励你耍聪明。 它不太鼓励你把代码写得只有自己看得爽。 它一直在提醒你,代码最终是给人读的,是给用户服务的。
所以 Zig Zen 里最后那句才会那么顺:
Together we serve the users.
我们最后服务的,是用户。
前面那些看起来很“硬”的东西—— 显式错误处理、资源管理、边界情况、编译期检查——其实都不是为了显得语言有个性,而是为了把程序写得更可靠一点,让人少踩一点坑。
这个出发点我挺喜欢的。
结论
如果你问我 Zig 值不值得学,我现在的答案很简单:
值得。
不一定是因为它会替代什么, 也不一定是因为它将来会多流行, 而是因为它会逼你重新想清楚几件特别基础、但又特别重要的事:
- 什么叫失败
- 什么叫边界情况
- 什么叫资源
- 什么叫把意图写清楚
很多语言教你怎么把功能做出来。 Zig 更像是在教你,怎么别含糊地把程序写出来。
这一点,我觉得挺难得。
最后一起来回顾 Zig Zen: