Web2 的心智模型不适用于 Web3
- 92srdjan
- 发布于 2026-01-13 17:37
- 阅读 541
本文提出了一种更适合 Web3 场景的数据获取方法,通过 Fetch -> Mapper -> UI 三层架构,将复杂性隔离,中心化缓存,避免过多的 hooks 和重渲染,从而提高性能和可维护性。这种方法借鉴了后端架构的思想,将前端分为数据获取层、数据转换层和UI展示层,使得代码更清晰、可预测,并易于扩展。
正确的链上数据获取方式
本文的目标
- 开发者友好
- 性能提升
- 更简单的代码维护
- 更智能的缓存
- 简单、可预测的数据失效
另外,这里的目标不是构建一个适用于所有人的完美、包罗万象的抽象。
目标是创建一个简单、可扩展的基线,任何开发者都可以理解、快速采用,并随着项目的增长进行扩展。
React Query 完全改变了我们许多人对 React 中数据和状态的看法。它是一个令人难以置信的库 - 但在 web3 中,我们很多人(包括我自己)都在无意中使用错误的方式使用它。
让我们来探讨一下原因。
Web2 的思维模式在 Web3 中行不通
在一个典型的 web2 前端中,你会从后端或数据库中获取准备好的数据 - 一个单一的事实来源:
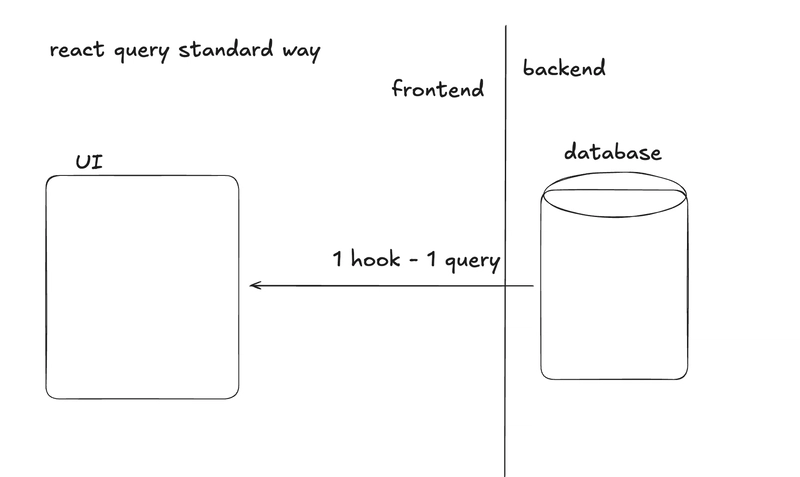
它很干净。一个请求 → 一个响应 → 一个 useQuery。
但在 web3 中,你的 "后端" 是:
- 多个合约
- 多个 RPC 端点
- 多种格式
- 有时是一个 subgraph
- 并且没有服务器来聚合或准备数据
因此,完全相同的 UI 最终看起来更像是这样:
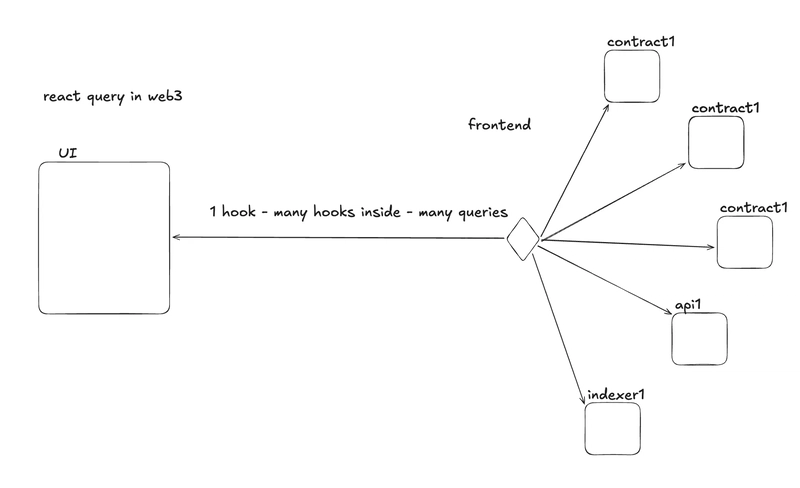
这就是事情出错的地方。
从 3 个合约中获取数据?
你现在有:
- 3 个不同的 hook
- 3 组
enabled逻辑 - 3 个 query key
- 3 个 loading/error 状态
- 之上的 memoized 转换
- 选择器
- 排序
- 由不稳定引用引起的重新渲染
它变得太复杂了。太 reactive 了。太难维护了。
一个单独的 hook 增长到 500 多行条件和嵌套 hook。
那么我们该怎么办?
我们回到有效的方法。
一个更简单的模型:Fetch → Mapper → UI
我们从后端架构中汲取灵感——后端架构通常有三个层:
- 表示层
- 服务层
- 基础设施层
对于 web3 前端,等价物变为:
UI → Mapper → Fetcher
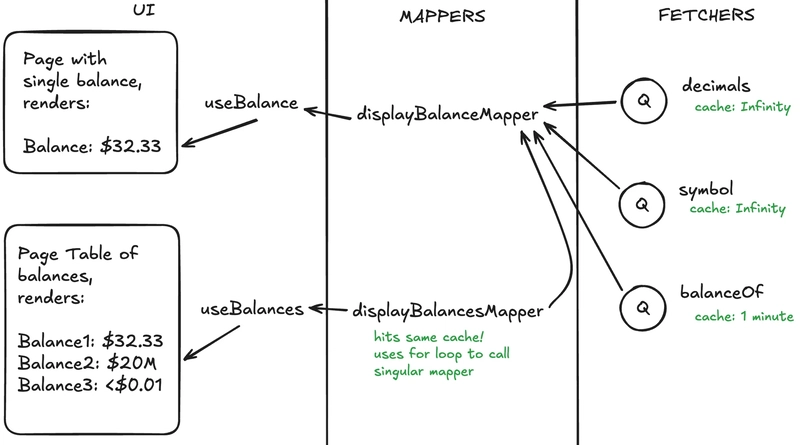
此模型恢复了可预测性,提高了性能,简化了调试,并使缓存保持在控制之下。
让我们来分解一下。
Layer1 — Fetcher (RPC/网络 + 缓存)
Fetcher 层负责:
- 实现实际的 RPC / HTTP 调用
- 使用 React Query 的非 hook API 进行缓存
- 没有其他
这是关键的见解:
你不要在这一层使用 hook。直接获取 queryClient,而不是 useQueryClient。
你使用:
queryClient.fetchQuery()React Query 仍然处理:
- 缓存
staleTime- 重试
- 后台更新
- 以及
fetchQuery中的所有其他非 reactive 方面
但不会在不应该引入 reactivity 的地方引入 reactivity。
请看一个如何获取 decimals、balance 和使用 mapper 映射这些值的示例:
export const getTokenDecimalsQuery = (token: Address, chainId: number) => ({
...readContractQueryOptions(getWagmiConfig(), {
abi: erc20Abi,
address: token,
chainId,
functionName: "decimals",
args: [],
}),
staleTime: Infinity,
});
export async function fetchTokenDecimals(token: Address, chainId: number) {
return getQueryClient().fetchQuery(getTokenDecimalsQuery(token, chainId));
}^ 这里,fetcher 永久缓存 token decimals。
export const getTokenBalanceQuery = (
token: Address,
chainId: number,
account: Address,
) => ({
...readContractQueryOptions(getWagmiConfig(), {
abi: erc20Abi,
address: token,
chainId,
functionName: "balanceOf",
args: [account],
}),
staleTime: 1 * 1000, // 1 分钟
});
export async function fetchTokenBalance(
token: Address,
chainId: number,
account: Address,
) {
return getQueryClient().fetchQuery(
getTokenBalanceQuery(token, chainId, account),
);
}^ 这里,fetcher 将 balance 缓存 1 分钟。
无论:
- 哪个 mapper 调用它
- 有多少屏幕使用它
- 有多少组件引用它
此 RPC 调用 balanceOf 最多每 1 分钟发生一次。(或者在 decimals 情况下只发生一次)
你的 UI 保持快速,你的应用程序保持稳定,并且缓存保持集中。
Layer2 — Mapper(业务逻辑和数据整形)
Mapper 层是将所有内容整合在一起的地方。
它:
- 了解 UI 需要什么
- 了解链/API 如何提供数据
- 调用多个 fetcher
- 格式化和派生值
- 将数据合并为干净、可用的结构
- 使用纯 JS(if/else, map, for, switch, 提前返回)
因为 fetcher 是非 hook 函数,mapper 也是非 hook 函数。
因此你可以使用正常的控制流,而没有 React 的限制。
这是一个例子
import { formatBigIntToViewNumber, ViewNumber } from "react-display-value"
export async function displayBalanceMapper(params: {
token: Address;
chainId: number;
account: Address;
}): Promise<ViewNumber> {
const { token, chainId, account } = params;
// 并行获取元数据(永久缓存)+ balance(1 分钟缓存)
const [decimals, symbol, rawBalance] = await Promise.all([\
fetchTokenDecimals(token, chainId), // 通常命中缓存(只有第一次不命中)\
fetchTokenSymbol(token, chainId), // 通常命中缓存(只有第一次不命中)\
fetchTokenBalance(token, chainId, account), // 每分钟刷新一次\
]);
return {
// 为视图格式化(准备)你的值,不要让原始值走得更远
balanceFormatted: formatBigIntToViewNumber(rawBalance, decimals, symbol)
};
}Mapper 成为你项目的业务逻辑大脑。
这个 mapper 简单而干净,
将它与 "hook 密集型" 方法进行比较,想象一下你尝试使用传统的 "hook 密集型" 模式构建任何更复杂的东西 - 为每个小数据点使用单独的 useQuery - 事情很快就会失控:
- 多个
enabled条件 - 多个 loading/error 状态
- 嵌套 hook
- 深度分支逻辑
- 没有干净的方法可以提前
return emptyState - 没有办法提前
throw error
更糟糕的是,当你需要为任何动态事物获取数据时 - token 列表、vault、市场、position 等 - hook 密集型方法就会崩溃。在数组上进行映射现在需要 useQueries,这会引入更多的 reactivity、更多的条件,并且仍然无法干净地解决条件获取问题。
没有简单的旧式 for 循环来获取东西!
你需要用于表格的可排序数据?没问题,让我们创建 displayBalancesMapper:
export async function displayBalancesMapper(params: {
tokens: Address[];
chainId: number;
account: Address;
}): Promise<DisplayBalanceRow[]> {
const { tokens, chainId, account } = params;
if (!tokens?.length) return []; // 简单的空数组返回
// 并行启动所有 token 行;缓存有效地处理重复项
const rows = await Promise.all(
tokens.map((token) =>
displayBalanceMapper({ token, chainId, account }),
),
);
// 示例:按标准化金额降序排序(对于 UI tables)
rows.sort((a, b) => b.sortKey - a.sortKey);
return rows;
}第 3 层 — UI(简单组件,智能数据)
一旦数据到达 UI 层,一切就又变得简单了。
UI 组件应该:
- 显示格式化的数据
- 避免领域逻辑
- 避免调用 fetcher
- 避免进行链上计算
- 完全依赖 React Query 缓存和 mapper 输出
UI 和 hook 应该是 "dumb" 的:
export function getDisplayBalanceQuery(
token?: Address,
chainId?: number,
account?: Address,
) {
return {
queryKey: ["useDisplayBalance", chainId, token, account] as const,
queryFn: () => displayBalanceMapper({ token: token!, chainId: chainId!, account: account! }),
enabled: Boolean(token && chainId && account),
// UI 级别的“隐藏 mapper”缓存,以减少格式化引起的重新渲染
staleTime: 30_000, // 15 秒窗口;根据需要调整 15 秒–1 分钟
};
}
export function useDisplayBalance(
token?: Address,
chainId?: number,
account?: Address,
) {
return useQuery(getDisplayBalanceQuery(token, chainId, account));
}并且格式化应该早在渲染之前就完成了:
import { DisplayTokenValue, DisplayTokenAmount } from "react-display-value"
// 处理 loading、error 状态,而且完美地渲染值
// 示例:<span customStyleHere>$</span><span customStyleHere>34.22</span> 等
<DisplayTokenValue {...rest} {...data?.balanceFormatted} />
// 用户看到 '$42.22',可以选择单独设置 $ 符号的样式例如,使用我们新库中的数字格式化逻辑,该库可以完成繁重的工作,并保持足够广泛,以便 mapper 可以满足任何 UI 需求:
👉 https://github.com/WingsDevelopment/react-display-value
这完全消除了对 useMemo 的需求。
你渲染的每一条数据都已经:
- 格式化
- 规范化
- 四舍五入
- 签名
- 符号化
- 准备好显示
你在 UI 中的 useQuery 变成了 mapper 周围的 reactive 包装器:
useQuery({
queryKey: ["something", params],
queryFn: () => mapper(params),
});没有复杂性。
没有额外的获取。
没有嵌套 hook。
通过 UI 级别缓存防止不必要的重新渲染
这里还有另一个强大的技巧:
你可以使用一个带有短缓存窗口(例如 15-60 秒或更长)的 useQuery 来“隐藏”你的 mapper。
这样:
- 繁重的格式化
- 昂贵的 map
- 大量数字缩减
- 符号/签名解析
- 和其他 CPU 密集型 mapper 逻辑
...将每 15-60 秒或任何你需要的时间运行一次,即使组件重新渲染多次。
这会将 mapper 变成一个迷你 "UI 缓存层",从而大大减少复杂仪表板或表格中的重新渲染和 CPU 占用。
这是一个非常简单的优化,但回报是巨大的,尤其是在数据繁重的 DeFi 应用程序中。
最后的想法
React Query 非常强大 - 但 web3 和链上数据获取改变了我们必须使用它的方式。
传统的做法(大量的 hook、大量的 memo、大量的 reactivity)在你应用程序增长到超出少量 RPC 调用时就会崩溃。
通过采用 Fetch → Mapper → UI 架构:
✔ 你隔离了复杂性
✔ 你集中了缓存
✔ 你移除了嵌套 hook
✔ 你避免了重新渲染风暴
✔ 你将 React Query 保持在其所属的位置
✔ 即使在规模化的情况下,你也能获得可预测的行为
✔ 你使你的代码库更容易维护
这种方法并不试图解决所有问题。
它为你提供了一个清晰、可扩展的基础,任何团队成员都可以理解、扩展和信任 - 这与大多数 web3 应用程序最终形成的脆弱的 hook 汤相反。
在一个前端必须像后端一样运行的世界中,这种架构决定了一个代码库是在自身重量下崩溃,还是优雅地增长。
更多内容即将推出
本文设定了基线。接下来,我将发布简短、重点突出的深入探讨,这些探讨建立在 Fetch → Mapper → UI 模式之上:
- 组合多个数据源
- 超越缓存策略 - 组失效、单数失效
- 识别数据方向 - 何时
useMemo实际上是正确的工具 - 错误处理和部分数据
- 测试和可观察性
- 原文链接: dev.to/92srdjan/the-web2...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





