修复Euler前端性能的架构
- eulerfinance
- 发布于 2026-01-13 17:37
- 阅读 790
本文探讨了在DeFi前端开发中,由于数据量增长和对链上数据的实时性需求,导致React Query过度使用、useMemo滥用以及不稳定的重新渲染等性能问题。文章提出了Fetch -> Mapper -> Hook架构模式,通过分离数据获取、转换和UI展示,结合queryClient.fetchQuery进行缓存,简化了数据流,提高了前端性能和可维护性。
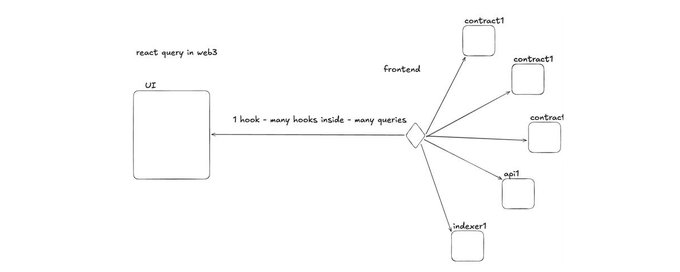
修正 Euler 前端性能的架构
现代 DeFi 前端试图提供最大的透明度:
所有内容都在链上获取,所有内容都在实时计算,所有内容都是响应式的。
这在开始时运作良好。
你有一个干净的 UI,一些合约调用,几个Hook,一切都感觉易于管理。
但随着项目的增长,数据也会增长:
-
更多的 vault(金库)
-
更多的市场
-
更多的余额
-
更多的派生状态
-
更多的 APY
-
更多的用户仓位
突然,你的前端正在做后端 + 数据库的工作,但却是在 React 组件内部。
早期的微小错误,这里的辅助Hook,那里的抽象——开始堆积起来。
更多的条件,更多的 memo,更多的状态。
在你注意到之前,你已经在与你从未打算创造的复杂性作斗争。
这篇文章解释了为什么会发生这种情况,为什么 React Query 在 web3 中变得极其棘手,以及一个简单的架构 fetch → mapper → hook(获取 → 映射器 → Hook)——如何永久性地解决这些问题。
客户端上的数据过多
随着我们数据集的增长,我们意识到并非所有内容都需要从链上实时获取。
有些数据计算成本很高,很少更改,或者是从多个来源聚合的。
因此,我们将特定类型的数据转移到后端(或 subgraph/task worker),然后使用 Fetch → Mapper → UI 模式来消费它。
但是,如果你已经有后端,这种模式不是不太有用吗?
你可能会争辩说,一旦你引入后端,Fetch → Mapper → UI 架构的必要性就降低了。
但事实是:
即使有强大的后端,你始终会有必须直接来自链上的数据。
这些值对于后端来说太时间敏感、用户特定或交易门控,无法安全地卸载到后端。
这造成了一个不可避免的挑战:
你的前端必须合并两个不同的世界:
-
后端提供的数据(已缓存、已聚合、变化缓慢)
-
链上数据(实时的、响应式的、每个用户的)
Fetch → Mapper → UI 模式正是使这成为可能的原因。
-
fetchers(获取器)隔离了数据来自何处以及如何来自何处(BE 或链)。
-
mappers(映射器)组合、规范化、格式化和协调这两个来源。
-
UI 接收一个单独、干净、稳定的数据对象——不知道(或不关心)它来自 RPC、BE 还是两者。
过度使用 useMemo
在传统的应用程序中,后端为你准备数据。
在 web3 中,区块链为你提供原始的、原始的状态,因此你必须自己计算所有内容。
更多的数据 → 更多的派生计算 → 更多的 useMemo。
只有 10 个 vault 时,即使每个 vault 有 20 个 memo 也不是什么大问题。但是一旦 vault 的数量增长,它就会成为一个问题。
-
10 个 vault → 200 个 memo
-
500 个 vault → 1 万个 memo!
每次重新渲染都会触发:
-
依赖性比较
-
重新计算
-
差异比较
-
内存使用
-
竞争条件
随着数据的增长,“安全错误”的数量降至零。
一个不稳定的依赖关系会降低性能。
在 web3 中,React query 对于链上获取来说太难了
我审查了很多 DeFi 项目,我们中的许多人试图像在 web2 应用程序中一样使用 useQuery,这是一个巨大的错误。
你可能想知道,如果我正在构建 web2 或 web3 应用程序,这对 react-query 有什么影响。我只是在进行 RPC 调用而不是 HTTP,对吧?但事情并没有那么简单。
在 web2 中,你有一个数据库或后端服务来计算、格式化和连接数据,你得到 1 个Hook - 1 个查询 - 你需要的一切。

在 web3 中,你只有链。它更加原始,你必须在前端完成 DB 为你做的事情,所以最终你会得到这样的情况:
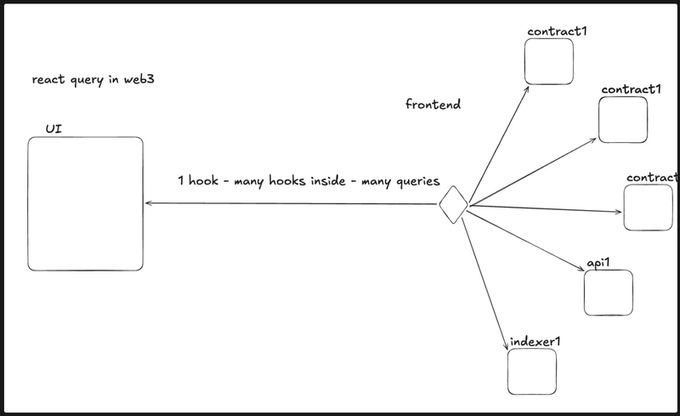
起初,这似乎没什么大不了的。你首先会想,“我只需在 enabled 字段中添加一个 if,以便仅在需要时才获取。”
然后你向 queryKeys 添加一些自定义的重新获取逻辑。
然后,你计算跨多个 useQuery Hook的组合加载和错误状态。
也许你甚至会撒上一些缓存或手动重新获取调用“只是为了处理边缘情况”。
在你意识到之前,你已经在Hook之上构建了Hook,数百行之深——充满了分支条件、复杂的依赖规则,没有直接的 if、else 或循环。它变得难以遵循,难以调试,甚至更难维护。
看看简单但仍然令人困惑的重Hook方法:
const useVault = (id) => {
const { data: vault, ...vaultQuery } = useQuery(...)
const { data: apy, ...apyQuery } = useQuery(...)
const { data: tvl, ...tvlQuery } = useQuery(...)
const { data: debt, ...debtQuery } = useQuery(...)
return {
vault,
apy,
tvl,
debt,
loading: vaultQuery.isLoading || apyQuery.isLoading || tvlQuery.isLoading || debtQuery.isLoading,
error: vaultQuery.error || apyQuery.error || tvlQuery.error || debtQuery.error,
}
}这也意味着,对于每个数据点,我们现在不仅有值本身,而且还有附加到它的整个 React Query 状态包 - 加载、错误、状态标志、获取时间戳等等。
而且由于大多数这些Hook相互依赖,如果任何底层查询正在加载,则整个复合Hook都会变为“加载”。在实践中,你无论如何都需要所有数据,因此多个 useQuery 调用最终仅用于一个目的:缓存。
这引出了一个显而易见的问题:
为什么不直接一起获取所有内容呢?
const useVault = (id) => {
const { data, ...query } = useQuery(
['vault', id],
async () => {
const vault = await fetchVault(id)
const apy = await fetchApy(id)
const tvl = await fetchTvl(id)
const debt = await fetchDebt(id)
return {
vault,
apy,
tvl,
debt,
}
}
)
return {
...data,
...query,
}
}更容易阅读!
在 mapper 中获取所有内容后,你只需将整个操作包装在单个 useQuery 中。这为你提供了 React Query 的反应性、加载和挂起状态、错误处理以及所有其他好处 - 而无需将逻辑分散在多个Hook中。
更容易阅读、维护和推理,对吧?在我看来:绝对是。
但你可能正在考虑的下一个问题是:
“那么缓存呢?”
这就是事情变得有趣的地方。
React Query 还通过 queryClient 提供了一个非Hook API。当你第一次发现 queryClient.fetchQuery 时,它完全改变了我处理数据获取的方式。你可以访问你在项目根目录初始化的相同查询客户端,并在任何地方调用 .fetchQuery() - 完全支持 staleTime、refetchOnWindowFocus、retries 和所有其他 React Query 选项。
这是一个简单的 fetch 函数示例,该函数检索 vault 的所有者并将其缓存 30 分钟:
export const fetchVaultOwner = async (vaultId: string) => {
return queryClient.fetchQuery({
queryKey: ["vaultOwner", vaultId],
queryFn: () =>
Vault.read
.owner({
vaultId,
})
.then((res) => res.unwrap()),
staleTime: 1000 * 60 * 30, // 30 minutes
});
};这意味着无论何时你在更高级别的操作中使用此 fetch 函数,调用都已被缓存 - 无需在其他任何地方定义缓存逻辑。
有了这种模式,我之前展示的那个大型、复杂的Hook就没有理由再在Hook内部调用Hook了。它可以简单地调用普通的 fetch 函数。
现在想象一下需求发生了变化。
例如,在获取任何内容之前,你现在需要检查 vault 是否已验证,如果未验证,则抛出错误。
在旧的基于Hook的方法中,你需要更新每个内部Hook,添加 enabled 条件,并触摸大约 10 个不同的位置。
使用普通的 fetch 函数,更改变得微不足道 - 你只需编写如下内容:
export const fetchVaultOwner = async (vaultId: string) => {
const vault = await fetchVault(vaultId);
if (!vault.isVerified) {
throw new Error("Vault is not verified");
}
return queryClient.fetchQuery({
queryKey: ["vaultOwner", vaultId],
queryFn: () =>
Vault.read
.owner({
vaultId,
})
.then((res) => res.unwrap()),
staleTime: 1000 * 60 * 30, // 30 minutes
});
};在计算最终状态时,你也可能会遇到问题。
也许你之前没有处理某些错误情况,而现在你需要处理。
也许你需要准确地了解何时重新获取各个查询。
使用重Hook方法,这会很快变得复杂,并且可能会发生许多意外行为。
不可预测的重新渲染
这个问题自然是从之前的问题中出现的。
当你的数据层变得过于 reactive 并且与多个Hook过于紧密地耦合时,UI 开始以感觉随机或无法控制的方式重新渲染。
第一个本能始终是相同的:
“让我们把它包装在 useMemo 中。”
但是 useMemo 并不能消除复杂性——它会增加更多:
-
另一个依赖数组
-
另一个相等性检查
-
更多的内存
-
另一个可能出错的地方
你现在不是稳定你的 UI,而是有另一个 reactive 层需要管理。
让我们做一些数学运算。
想象一下一个在内部使用的Hook:
-
7 个不同的 useQuery 调用 → 7 个 query key
-
几个包装在 useMemo 中的格式化或排序操作 → 3–5 个以上的依赖数组
你现在维护着 10 多个单独的依赖数组,React 必须在每次渲染时比较所有这些数组,对于使用此Hook的每个功能。
随着应用程序的扩展:
-
依赖数组的数量增加
-
query key 的数量激增
-
一个不稳定的引用会触发级联
-
UI 变得更难预测
-
小错误会导致大量的重新渲染风暴
即使每个依赖项都是“正确的”,React 仍然需要将所有这些数组存储在内存中并不断地比较它们。将其乘以数十个组件,成本就会变得很高。
这就是为什么“只是添加更多 useMemo”不是一种性能策略——这是一个架构需要简化的信号。
用于获取数据的 Fetch - mapper - hook 层
从我们之前的数据获取方法中移开,帮助我们简化了系统。我们在获取数据时引入了三个层:
-
fetch 函数(我们已经在 fetchOwner 示例中介绍过)
-
useQuery 之前的 mapper 层,它调用尽可能多的 fetch 函数
-
最后使用 useQuery 包装此 mapper 并获得 UI 的反应性
我已经部分介绍了为什么我们需要这个,但是如果你有兴趣查看有关此方法的图表和更多详细信息,你可以查看此博客。#
创建无法支持项目演进的早期抽象
几乎每个团队都会在某个时候犯这个错误,包括我自己。在项目的早期阶段,你通常不完全了解真实的数据流、真实的规模或功能的演进方式。
你以最好的意图创建抽象:为了干净、可重用、“面向未来”。但事实是,早期的抽象通常根本不是面向未来的。它们建立在后来被证明是错误的假设之上。
最后的想法
React Query 是一个很棒的库,但 web3 从根本上不同于 web2。你不能像对待 HTTP 端点一样对待链上 RPC 调用。当你尝试这样做时,你最终会得到:
-
大量的嵌套Hook
-
过多的查询
-
损坏的加载/错误状态
-
到处都是 useMemo
-
不可预测的渲染
-
复杂的依赖数组
-
Hook在任何人注意到之前增长到 500–800 行
通过将获取移出Hook,简化管道,并让 Promise.all 完成繁重的工作——同时仍然使用 React Query 进行反应性——你可以获得更清晰的架构:
-
可调试
-
可预测
-
高性能
-
可扩展
-
易于维护
最重要的是:
你的前端停止与区块链作斗争 - 并开始与之合作。
- 原文链接: x.com/eulerfinance/statu...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





