Recon Magic 简介
- Recon
- 发布于 2026-01-08 16:17
- 阅读 574
Recon Magic 是一种使用 Agentic Workflows 的智能合约模糊测试工具,通过优化标准化行覆盖率,实现了更高效的状态模糊测试。与传统方法相比,Recon Magic 采用钳制处理程序和快捷功能,显著提高了测试效率,平均提速 38 倍。实验结果表明,在多个实际项目中,Recon Magic 能够实现更高的代码覆盖率。
Recon 帮助你构建和运行不变性测试
Recon Magic 介绍
使用 Agentic Workflows 以快 38 倍的速度编写有状态模糊测试 - 内部基准测试

简介
在这篇文章中,我们概述了一种标准化的方法来评估智能合约模糊测试的有意义的行覆盖率,我们称之为标准化行覆盖率。
然后,我们详细介绍了如何在 Recon Magic 的实现中使用它作为优化函数,Recon Magic 是一种 agentic workflow,可以对用 Solidity 编写的任何生产智能合约系统实现高标准化行覆盖率。
我们认为,下面展示的改进代表了在智能合约系统中实现有状态模糊测试能力的一个重大转变,使其速度提高数倍,因此更易于广泛使用。
标准化行覆盖率
在有状态模糊测试的上下文中,行覆盖率定义为给定合约中,具有给定配置的测试套件在模糊测试活动过程中能够达到的行数。
在使用有状态模糊测试测试系统时,我们可以将合约中所有函数的一个子集定义为感兴趣的函数。这个子集允许 fuzzer 实际探索可能的系统状态。当使用 Recon 的 Chimera 框架 时,这个子集只能通过 TargetFunctions 合约中定义或继承的函数访问。其他感兴趣的函数是通过目标函数作为内部函数或通过外部调用来调用的函数。
鉴于我们的目标是测试所有可能的智能合约状态组合,我们需要一种方法来提取和分类仅覆盖我们感兴趣的函数。 这促使我们创建了一个新的子类别,我们称之为标准化行覆盖率,它对智能合约的行覆盖率进行分类,前提是已删除所有由 view/pure 函数和未调用函数贡献的不相关的行。
当前用于有状态模糊测试的工具(即 Echidna、Medusa 和 Foundry)将给定目标合约中的所有函数完整集合合并到它们生成的覆盖率报告中。因此,view、pure 和未使用的函数都包含在合约覆盖率的总体计算中:
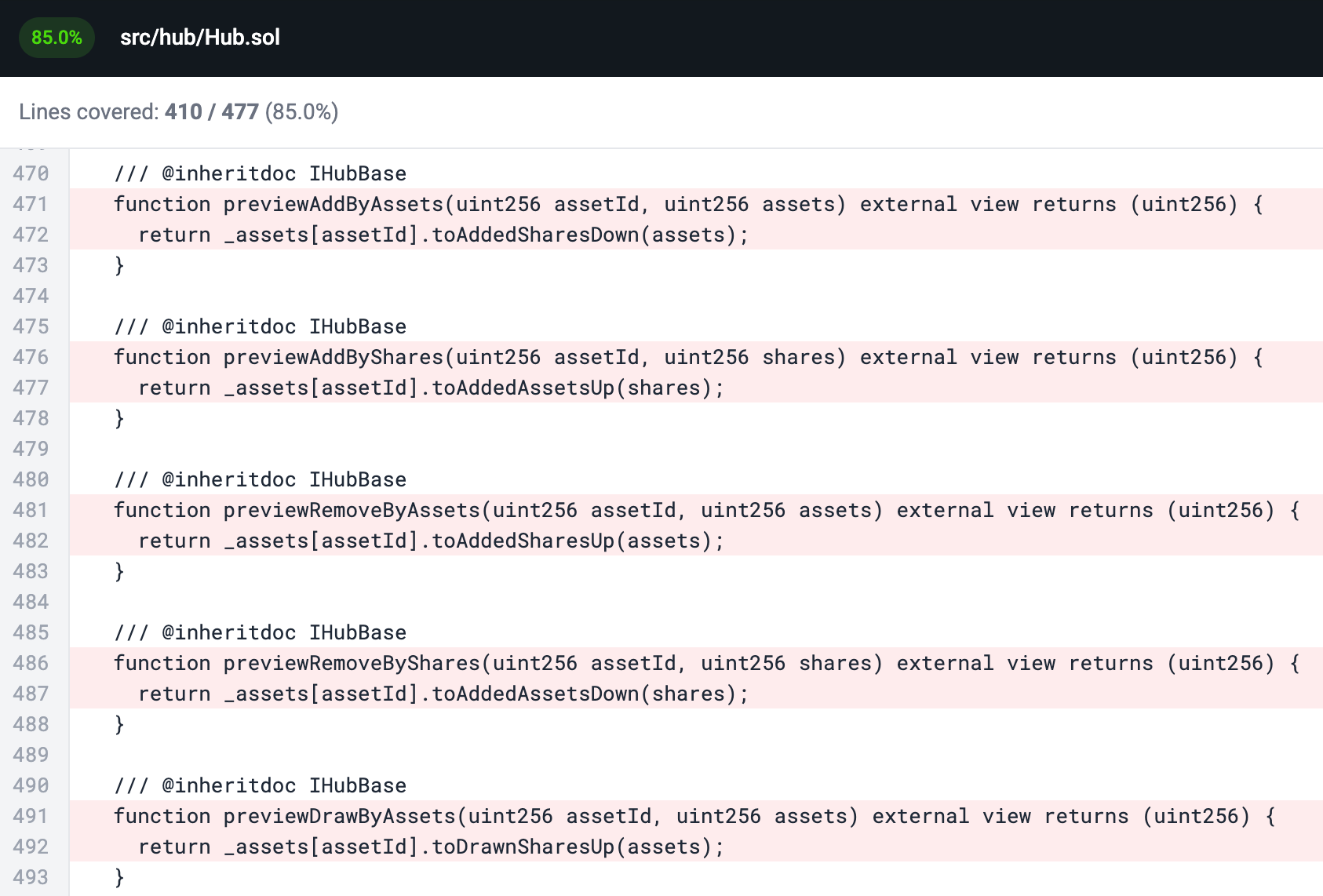 在 Hub 合约中,我们看到 fuzzer 无法覆盖这些 view 函数,因为它们没有为它们定义目标函数。但实际上,在覆盖率分析中,这些并不重要,因为它们不会导致 fuzzer 的状态更改。
在 Hub 合约中,我们看到 fuzzer 无法覆盖这些 view 函数,因为它们没有为它们定义目标函数。但实际上,在覆盖率分析中,这些并不重要,因为它们不会导致 fuzzer 的状态更改。
标准化行覆盖率将这些函数的一个子集定义为可以更改系统状态的函数,这些函数是 fuzzer 定位以探索有意义的组合的函数。这不仅包括顶级目标函数,还包括出现在目标函数的调用跟踪中的任何函数,其中可能包括内部函数、外部合约调用和库函数。
有了这个定义,我们可以说达到标准化行覆盖率是表明 fuzzer 已达到 100% 行覆盖率的更好指标(有关更好的指标,请参见未来的工作)。
一种 Agentic Workflow
 用于与 Recon Magic agentic workflow 交互的界面。
用于与 Recon Magic agentic workflow 交互的界面。
创建一个达到标准化行覆盖率的测试套件是一项重要的任务。主要困难在于创建测试支架,以定义要调用的函数子集,并确保 fuzzer 可以轻松访问这些函数中的所有可能路径。传统上,这需要花费大量时间,并且需要一个迭代周期,即编写测试套件、运行 fuzzer,然后重新评估以确定覆盖率是否随着最新更改而提高。
鉴于这是一项重复性的任务,并且遵循某些启发式方法,因此非常适合应用 agentic AI workflow 来加速该过程。
最近,我们着手创建一个这样的 agentic workflow,并使用以下几点来衡量 workflow 输出的质量:
-
高(理想情况下是完全)标准化行覆盖率
-
代码可以轻松维护
-
代码反映了经验丰富的工程师的编写方式
-
避免引入测试套件错误(偏差、错误的假设和常见错误)
实现标准化行覆盖率是 agentic workflow 的主要目标函数,而其他点旨在指导 agent 如何实现此目标。
为了确保编写的代码质量高且易于维护,我们对 agent 进行了约束,以便它使用以下最佳实践来实现套件:
-
通过调用 unclamped handler 来创建 clamped handlers,创建输入空间的子集,同时允许 fuzzer 通过 unclamped handler 探索状态空间的其余部分。
-
clamped handlers 的输入值使用动态系统状态值或测试套件设置中的静态值进行 clamping。
-
实现快捷方式函数(调用多个 handlers 的函数),这些函数允许探索如果仅依靠 fuzzer 的随机调用可能难以达到的状态。
-
如果代码使用 Foundry 编译,则可以由 Echidna 和 Medusa 运行。
另一个隐含的要求是,workflow 默认使用我们的 Chimera 框架来创建测试套件,因为它已经处理了 agent 否则必须自己做出的许多设计决策。
Chimera 框架在 Recon Book 中进行了深入讨论。 我们认为有充分的理由使用它,因为它是使用最广泛的模糊测试框架之一,可以从此 公共模糊测试活动列表 中看到。 此外,我们创建的默认使用该框架的 扩展 的下载量已超过 700 次。
下面我们分享了所创建的 workflow 的结果,该 workflow 确定性地遵循这些指导原则,并且在绝大多数情况下,AI Workflow 生成的测试套件不仅可用,而且与 Recon 工程师的编写方式非常相似(如果不是完全相同)。 更重要的是,它可以系统地实现任何项目的高标准化行覆盖率。
方法论
Recon Magic agentic workflow 使用的方法论围绕着 clamped handlers 和 shortcut 函数 的实现。
Clamped Handlers
Clamped handlers 通过限制输入值来减少给定函数的搜索空间。clamped handlers 的有效 clamping 策略大致分为以下两类:
- 使用测试套件设置中的值来限制输入
// 这是一个示例,展示了一个 handler,它使用在测试套件设置中铸造给用户的资产余额来限制购买金额。
- 使用系统状态中的值来限制输入
// 这是一个示例,展示了一个 handler,它使用调用清算的参与者的债务来限制清算金额。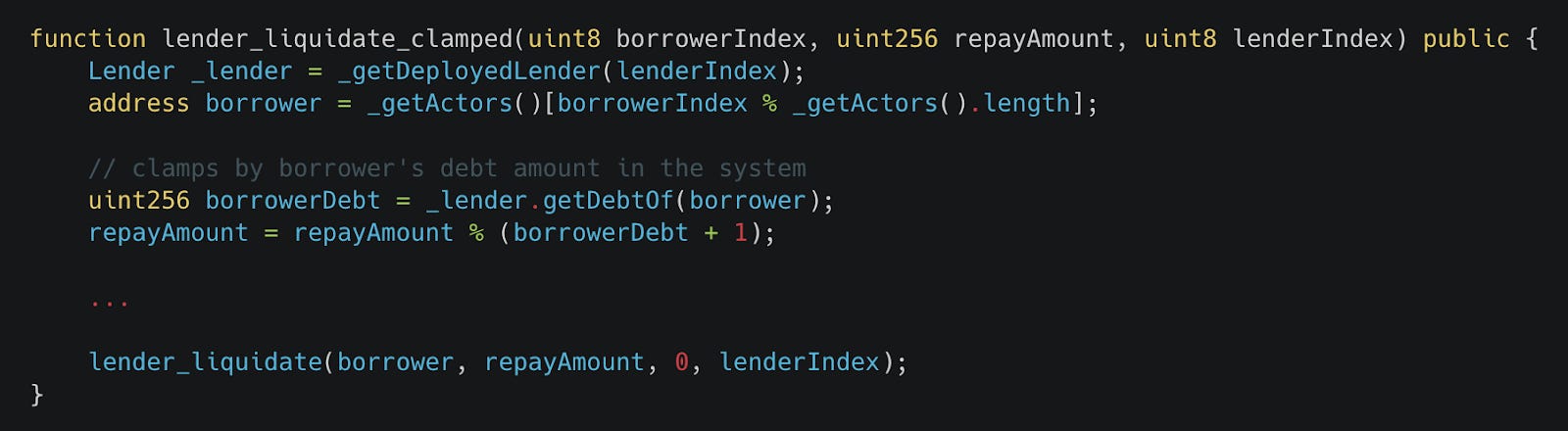
快捷方式函数
快捷方式函数类似于 clamped handlers,因为它们允许更大的状态探索。但是,快捷方式函数不是仅包含一个状态更改函数调用,而是将多个状态更改函数调用组合到一个函数中:
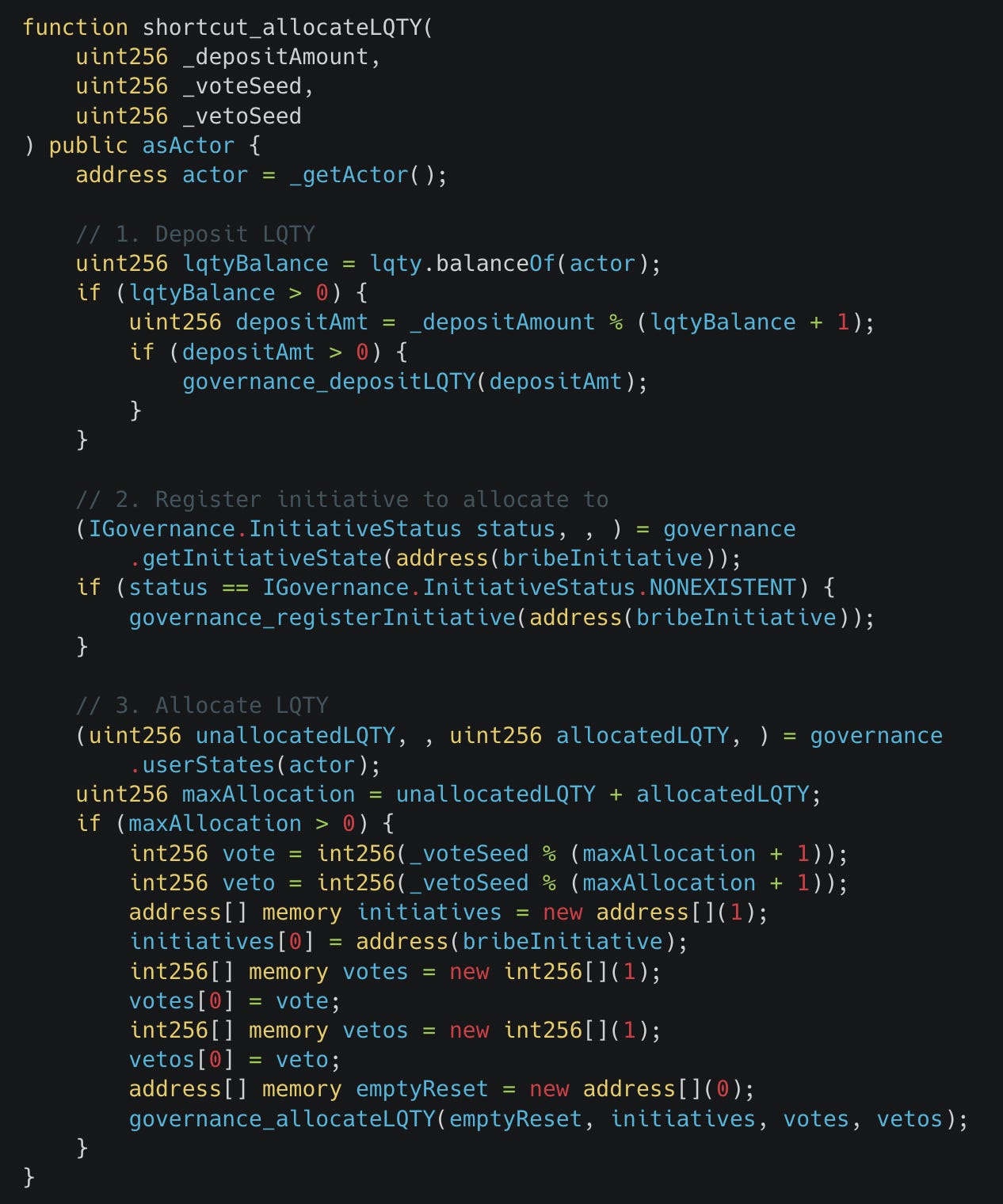 上面是 workflow 为 Liquity Governance V2 仓库生成的快捷方式函数示例。请注意,它使用特定的输入值调用了三个状态更改 handler 函数,从而更有可能达到特定状态。
上面是 workflow 为 Liquity Governance V2 仓库生成的快捷方式函数示例。请注意,它使用特定的输入值调用了三个状态更改 handler 函数,从而更有可能达到特定状态。
这允许 fuzzer 探索深度状态转换,如果通过单个 handlers 调用,则可能需要更长的时间才能实现。
评估
为了评估我们的 workflow 的有效性,我们比较了经过 4 小时模糊测试运行后两种不同测试用例(unclamped handlers 与 clamped handlers 和快捷方式)的标准化行覆盖率。
两种测试用例的设置都以有效的方式部署系统,这使得 fuzzer 有可能探索所有有意义的状态。unclamped 目标函数版本在没有使用 clamping 减少任何目标函数的搜索空间的情况下,直接在此设置上运行 fuzzer(对照组)。clamped 目标函数版本已运行 workflow(实验组)以应用 clamping 以及实现快捷方式函数。
此测试在 5 个不同的真实世界代码库(Liquity Governance V2、Superform Periphery V2、Monolith、AAVE V4 和 Nerite)上执行。
结果
Recon Magic 的平均运行时间约为 2-3 小时(具体取决于代码库的复杂性)即可实现高标准化行覆盖率,而人工工程师之前平均需要 3-5 天,效率提高了 38 倍(之前平均为 96 小时,现在为 2.5 小时)。
以下基准测试比较了对照套件和实验套件的标准化行覆盖率,该测试在 Recon 云运行器上以断言模式运行 Echidna 4 小时。结果如下所示(每个运行的链接都在图片说明中提供):
- Liquity Governance V2(感兴趣的核心合约是 BribeInitiative 和 Governance)
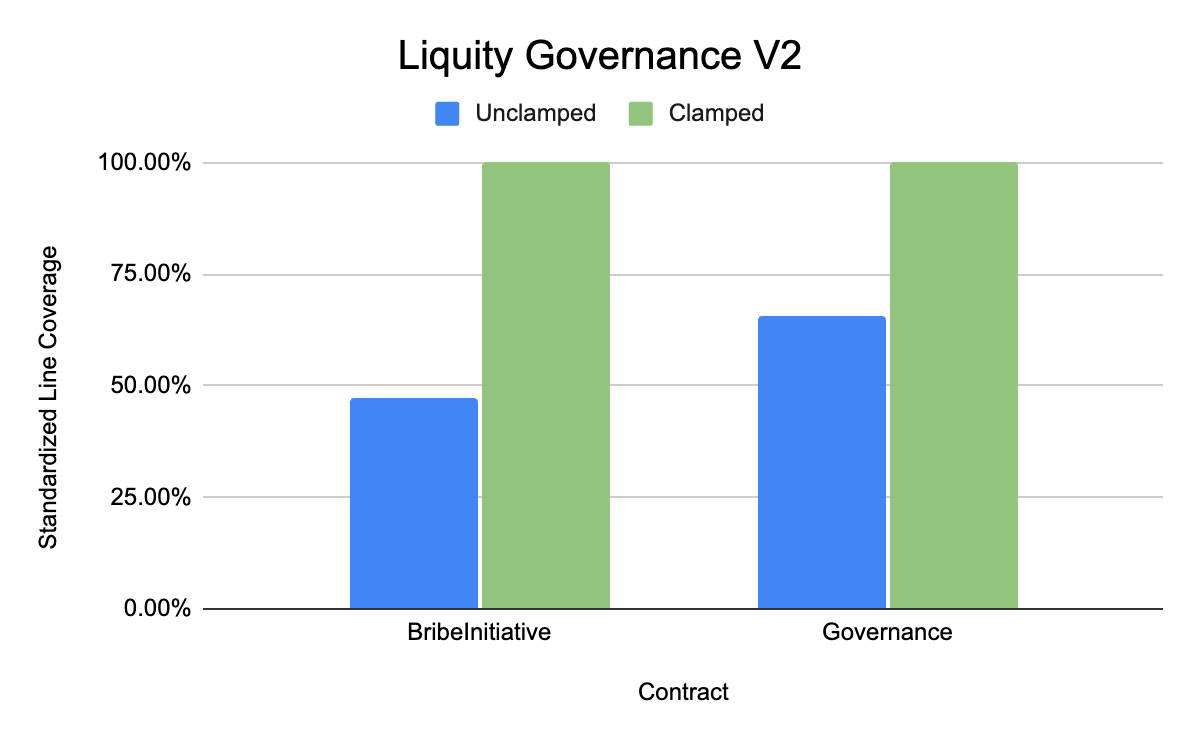 Liquity V2 Governance 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
Liquity V2 Governance 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
- Monolith(核心目标合约是 Lender、Coin、Vault、Factory、InterestModel)
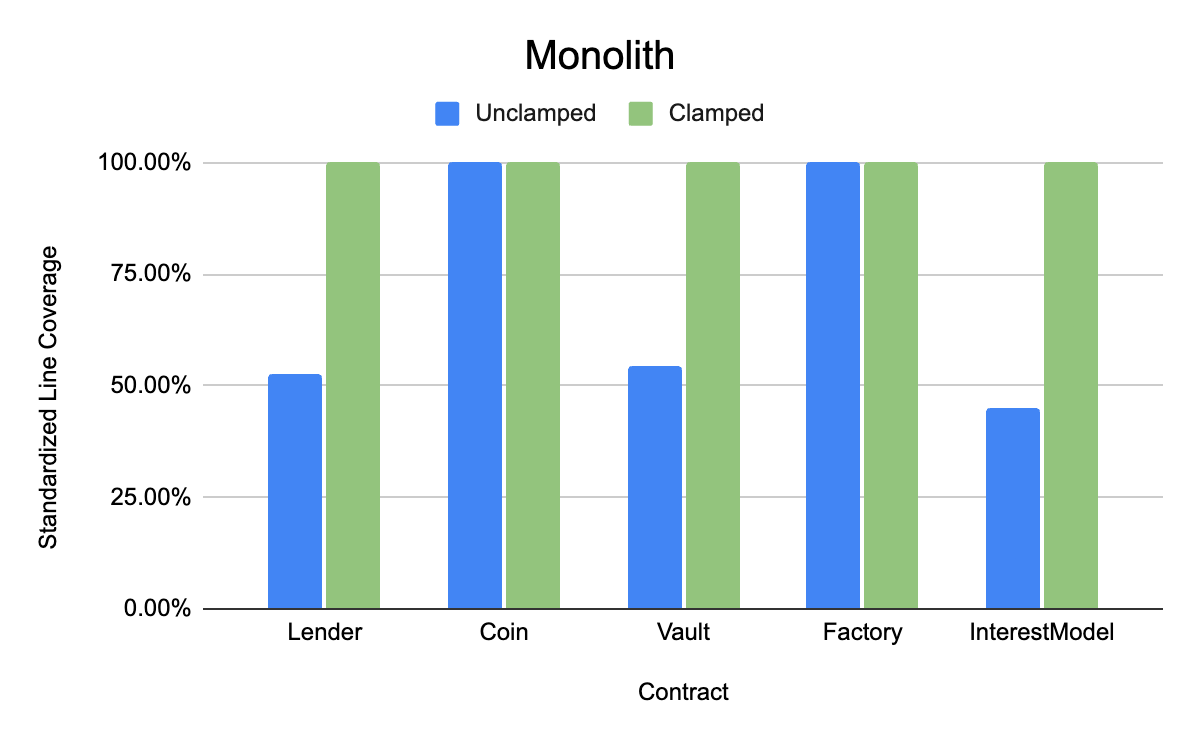 Monolith 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
Monolith 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
- AAVE V4(核心目标合约是 Hub)
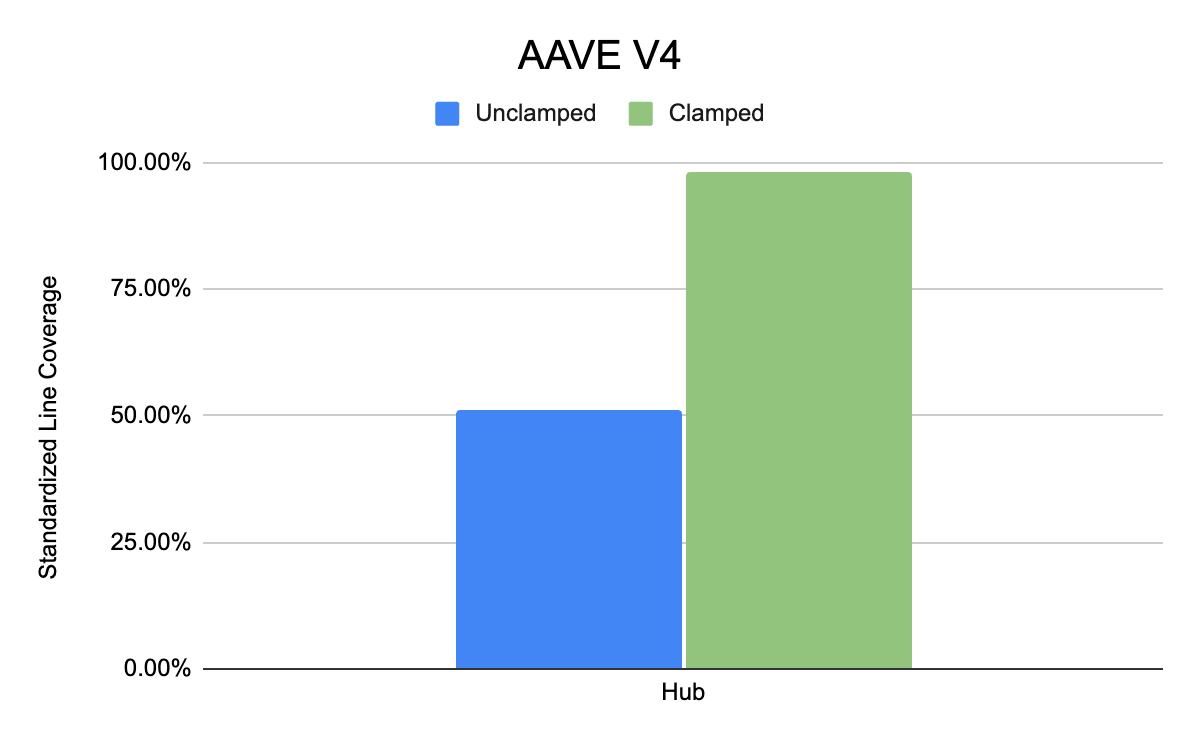 AAVE V4 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
AAVE V4 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
- Superform Periphery(核心目标合约是 SuperGovernor、SuperVault、SuperVaultEscrow 和 SuperVaultStrategy)
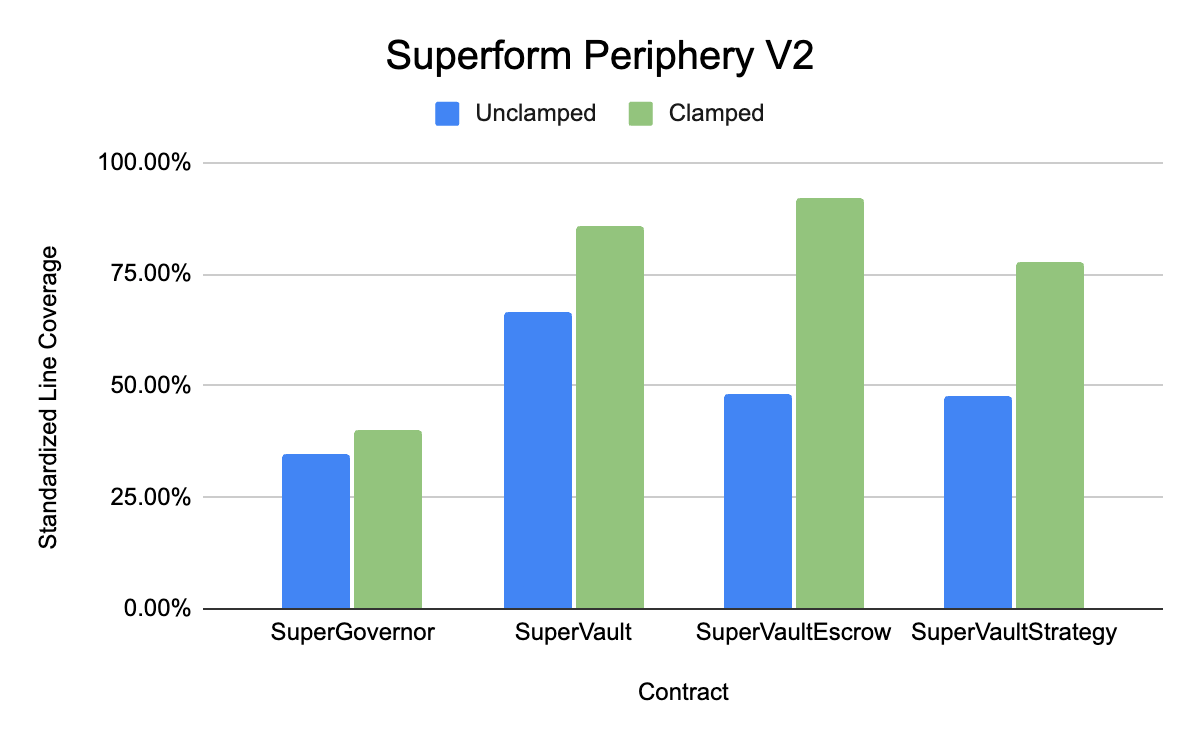 Superform Periphery V2 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
Superform Periphery V2 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
- Nerite(核心目标合约是 BorrowerOperations、StabilityPool 和 TroveManager)
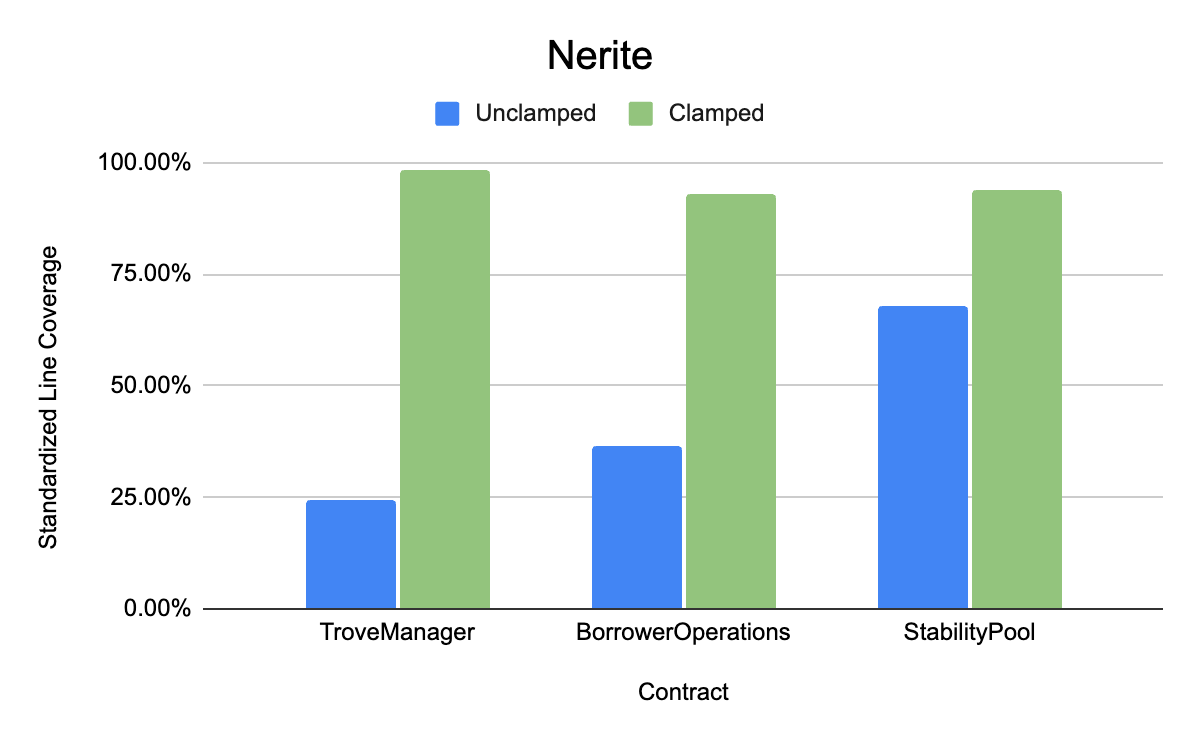 Nerite 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
Nerite 存储库中 clamped 与 unclamped handlers 中产生的标准化行覆盖率。
未解决的边缘情况
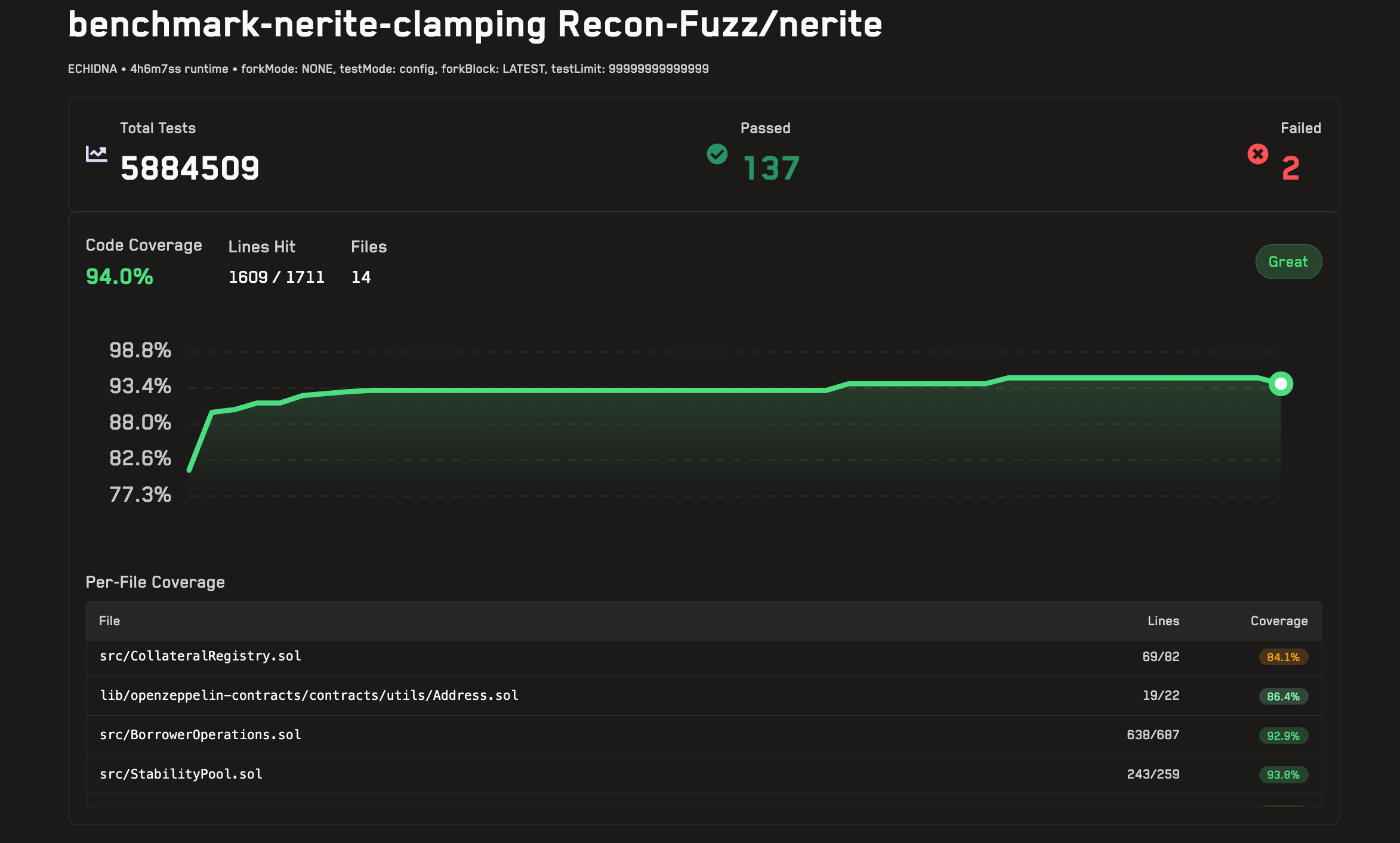 Nerite 的 clamped 运行的标准化行覆盖率。
Nerite 的 clamped 运行的标准化行覆盖率。
应该注意的是,对于 Nerite,已经达到了高覆盖率,但即使在运行 workflow 并进行迭代尝试以覆盖它之后,仍然存在重要的边缘情况未被发现。这是一个需要改进的明确领域,我们正在努力。
我们针对此类情况的临时解决方案是识别问题的根源,并以易于理解的格式提供它,以便人工在环路中可以快速实施修复以覆盖剩余的未覆盖行。
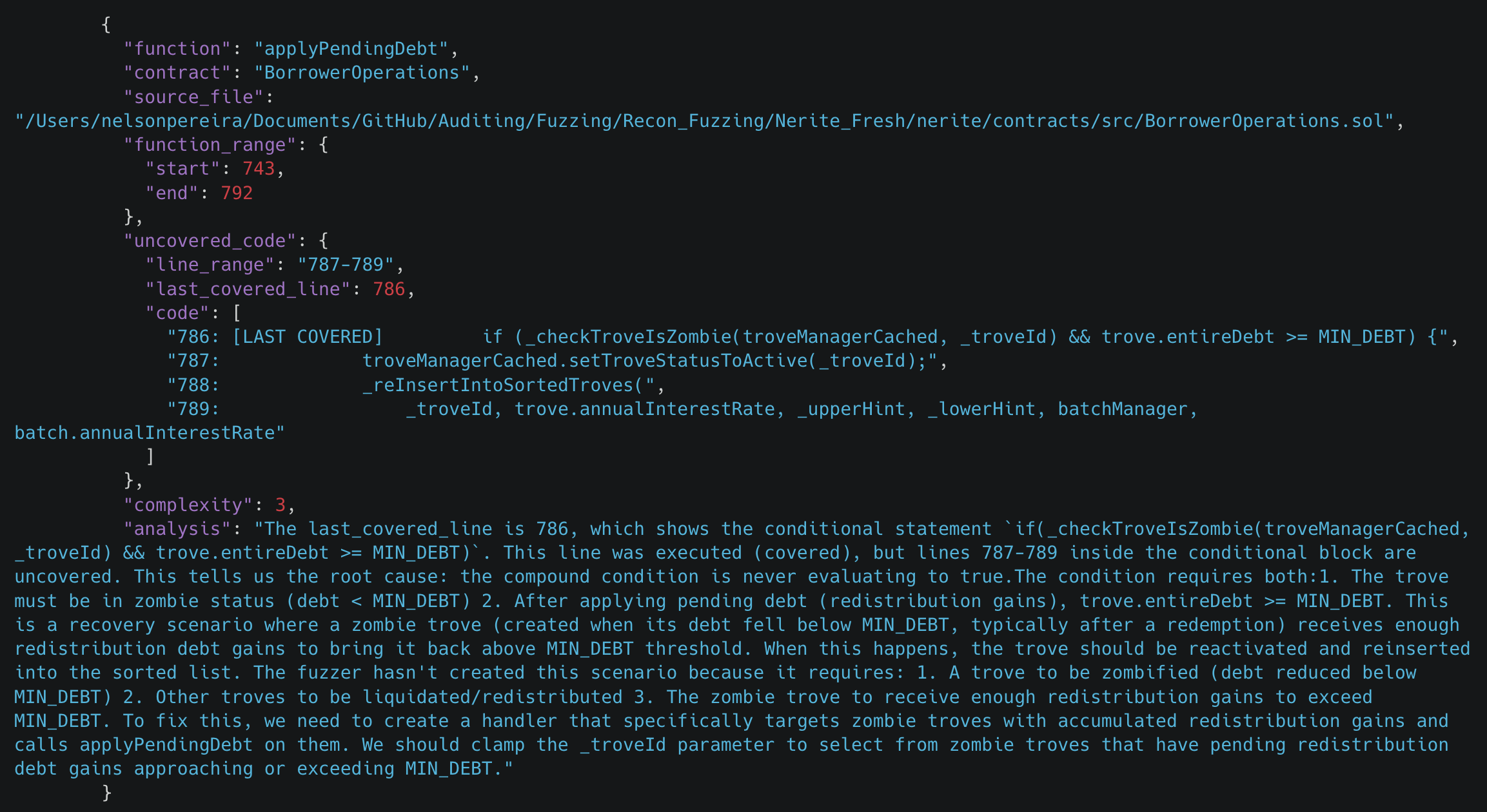 Nerite 中与僵尸 trove 相关的关键未覆盖行之一。此 JSON 由 workflow 生成,高亮显示了未覆盖的行以及人工在环路中可以实施以解决它的建议修复。
Nerite 中与僵尸 trove 相关的关键未覆盖行之一。此 JSON 由 workflow 生成,高亮显示了未覆盖的行以及人工在环路中可以实施以解决它的建议修复。
覆盖率结果
从上面的基准测试可以看出,workflow 应用了 clamping 和快捷方式的实验组在给定时间内始终比 unclamped 的情况实现了更高的行覆盖率。我们认为,鉴于这一点以及实施 clamped handlers 的时间大大减少,这些基准测试证明了使用 Recon Magic 来实现完全标准化行覆盖率的令人信服的案例。
此外,由于 agent 采取的方法仅创建 clamped handlers 和快捷方式,同时保持 unclamped handlers 不变,因此运行 agent 没有已知的缺点,因为在最坏的情况下,它只会实施无效的 clamped handlers,但不会减少 fuzzer 可访问的搜索空间。
可重复性
AI agent 的非确定性性质意味着 workflow 的两次运行不会输出完全相同的 clamped handlers。但是,我们已经在 workflow 中提供了其他工具和问题的细分,使其更有可能创建与我们的最佳实践一致的输出,因此即使没有两个实现完全相同,它们仍然可以有效地提高覆盖率。
Workflow 还在某些预定义的步骤中提交更改。这可以确认 workflow 的给定步骤实现了哪些更改,从而更容易理解和评估 agent 在特定步骤中的推理。
 可以从 Recon Magic UI 中提供的文件链接中看到生成它们的步骤的输出。
可以从 Recon Magic UI 中提供的文件链接中看到生成它们的步骤的输出。
虽然我们无法证明 AI 实施了基准存储库中的所有 clamping 更改,但我们证明了情况确实如此。我们进一步鼓励任何希望复制我们结果的人使用 Recon Magic “覆盖率 V2” workflow 在 此处 的默认设置存储库上,然后运行 fuzzer 以评估 clamped 和 unclamped 设置的覆盖率。
可以通过使用结果部分下每个图表下的 Recon Pro 结果页面的链接找到基准存储库的覆盖率结果的证明。标准化行覆盖率是使用感兴趣的目标函数的调用树计算的,并显示在作业的页面上。
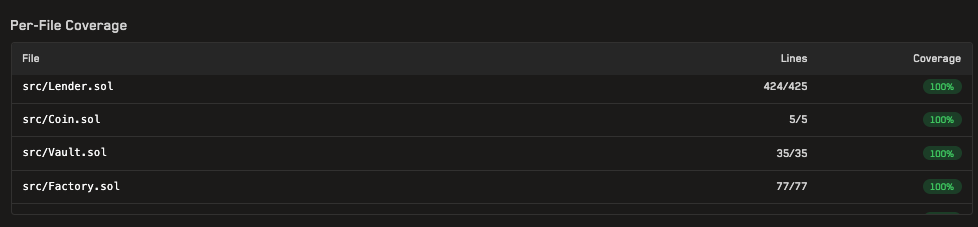 标准化行覆盖率显示在给定作业页面的“按文件覆盖率”部分中。
标准化行覆盖率显示在给定作业页面的“按文件覆盖率”部分中。
标准化行覆盖率值将与覆盖率报告中显示的值不同,因为它仅使用感兴趣的函数计算,而报告中的值是使用合约中定义的所有函数计算的。
未来工作
我们在上面已经看到了使用标准化行覆盖率如何使我们更清楚地了解我们在模糊测试活动中实际关心覆盖的内容。然后,我们看到了使用标准化行覆盖率作为优化函数如何使我们能够创建一个 agentic workflow,从而实现对任何项目的高覆盖率。
但是,行覆盖率有很多缺陷,即无法有效地判断特定条件组合的覆盖率。但是,当前用于不变性测试的工具将其用作 fuzzer 功效的主要指标,因此我们决定使用标准化行覆盖率作为此基准测试的主要指标。
基于函数不还原输入及其可能组合(我们称之为覆盖率类别)的更细致的覆盖率指标将可以更好地评估所有可能状态中的覆盖状态。
然后,可以通过使用突变测试来评估运行的敏感性来改进此指标。这将修改 agent 实施的更改,以确定它们是否直接导致输出覆盖率的增加。
Recon Magic 发布
Recon Magic 正在进行私人 beta 测试,很快将进行公开 beta 测试,届时我们将发布 50 个邀请码。
如果你想在 Recon Magic 发布时成为首批尝试它的人之一,请加入我们的 Discord 频道。
- 原文链接: getrecon.substack.com/p/...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 25
- 分类: 安全
- 标签: 模糊测试 智能合约 代码覆盖率 Agentic Workflow Recon Magic Solidity





