PeerDAS-devnet-7 更新 - Optimism
- optimism
- 发布于 2025-06-02 21:44
- 阅读 778
Optimism Collective 旗下的 Sunnyside Labs 对 PeerDAS 进行了测试,在 modified peerdas-devnet-7 测试网中,实现了接近 50 个 blobs/block 的吞吐量。但超过这个阈值后,网络压力增大,共识延迟增加,blob 获取变得不可靠
我们最近在一个修改过的 peerdas-devnet-7 测试网上对 PeerDAS 进行了全面测试(非常感谢 EthPandaOps 领导规范工作!)。这个 devnet 由 Optimism Collective 的核心开发团队 Sunnyside Labs 运行,用于衡量不同的执行层和共识层客户端组合在压力下处理 blob 吞吐量的能力。
在构建 Superchain 时,我们需要既可靠又经济实惠的数据可用性。我们可以在一个区块中容纳的每个额外的 blob 都会降低将 L2 数据发布到以太坊的成本。这对每个人来说都是一个胜利 —— 用户支付更少,开发者可以利用共享的流动性和跨链分发,以及数据密集型应用(如链上游戏)可以在不大幅增加成本的情况下进行扩展。L2 上更多的活动也将把更多的交易费用返还给以太坊,通过为验证者提供更多的收入潜力来加强其安全性。
这就是我们跨整个客户端矩阵进行 blob 吞吐量压力测试的原因。在受控条件下基准测试每个共识/执行对,有助于我们尽早发现隐藏的瓶颈并测量当前的性能上限。它还使我们能够坚持保持以太坊的稳定性和性能,并确保增加 blob 容量不会以牺牲网络健康为代价。我们的目标是与核心开发者和客户端团队合作,将有希望的峰值转化为持续的性能。
在这篇文章中,我们将回顾我们的基准测试结果,突出优点,并深入探讨我们在此过程中发现的稳定性挑战。
如果你想回顾该系列,请查看以下 Sunnyside实验室 的前期报告:
概括:我们达到了 50 个 blob,但找到了上限
我们运行了这个 devnet,使用了 60 个节点,以了解随着 blob 吞吐量的增加,网络的支撑情况如何。我们使用不同的 EL/CL 组合,一致地达到了接近 50 个 blob/区块。 超过这个阈值,我们开始看到网络压力:共识延迟堆积,blob 获取变得不可靠,并且一些超级节点开始失效。模式很明显,共识客户端在区块导入延迟和错过证明窗口方面存在困难,使得网络在高负载下更难保持进度。
环境配置
这一轮将我们的设置从 36 个节点扩展到 60 个节点(33 个超级节点,27 个完整节点)。每个节点都以 4 个 vCPU 和 8 GB RAM 运行。我们使用 Spamoor 测试了所有主要的 EL/CL 组合,以逐渐增加每个区块的 blob 数量。与前几轮不同,我们没有在各个阶段之间重置链,而是持续增加 blob 负载,以压力测试故障点。
| 组件 | 版本 |
|---|---|
| 共识层 | 为 devnet-7 规范构建的 alpha 版本 |
| 执行层 | 启用了 getBlobsV2 编译的 alpha 版本 |
| 网络 | 修改后的 peerdas-devnet-7,60 个节点,8 个验证者,12 秒 slot |
| 硬件 | 每个节点 4 个 vCPU / 8 GB RAM 的 digitalocean 实例 |
| 负载 | spamoor blob 生成器,单调递增的负载(没有强制重置) |
注意: 我们在 2025 年 5 月 17 日至 19 日运行了此测试。所有客户端共享相同的对等节点限制和 gossip 配置。日志和指标被传输到共享的 Grafana + Prometheus 设置。
我们运行了两个具有相同拓扑的并行 devnet,以发现运行之间的差异。Spamoor 从 1 个 blob / 区块开始,每十分钟增加一个 blob。这使我们能够在累积压力下测试网络和客户端行为,从而捕获长期压力对共识同步、blob 传播和执行获取可靠性的影响。
主要发现
Blob 吞吐量
网络 blob 吞吐量在每个区块 50 个 blob 左右达到峰值。 之前的运行仅看到特定的客户端对(如 lighthouse/besu 和 lighthouse/geth)达到了每个区块 43-50 个 blob;其他组合通常在变得不稳定之前停滞在 18-35 个 blob 之间。这一次,即使使用不同的执行和共识客户端组合,我们也能够始终如一地达到接近每个区块 50 个 blob 的水平(我们将继续调查这是否可以归因于分布式 blob 构建,这是 devnet 7 规范的一部分)。
但是,超过 50 个 blob 会导致性能下降,包括 slot 丢失和链重置,从而无法维持更高的吞吐量。我们观察到的重复的峰值和下降模式表明,在这些条件下,每个区块 50 个 blob 代表了我们当前的 网络上限。
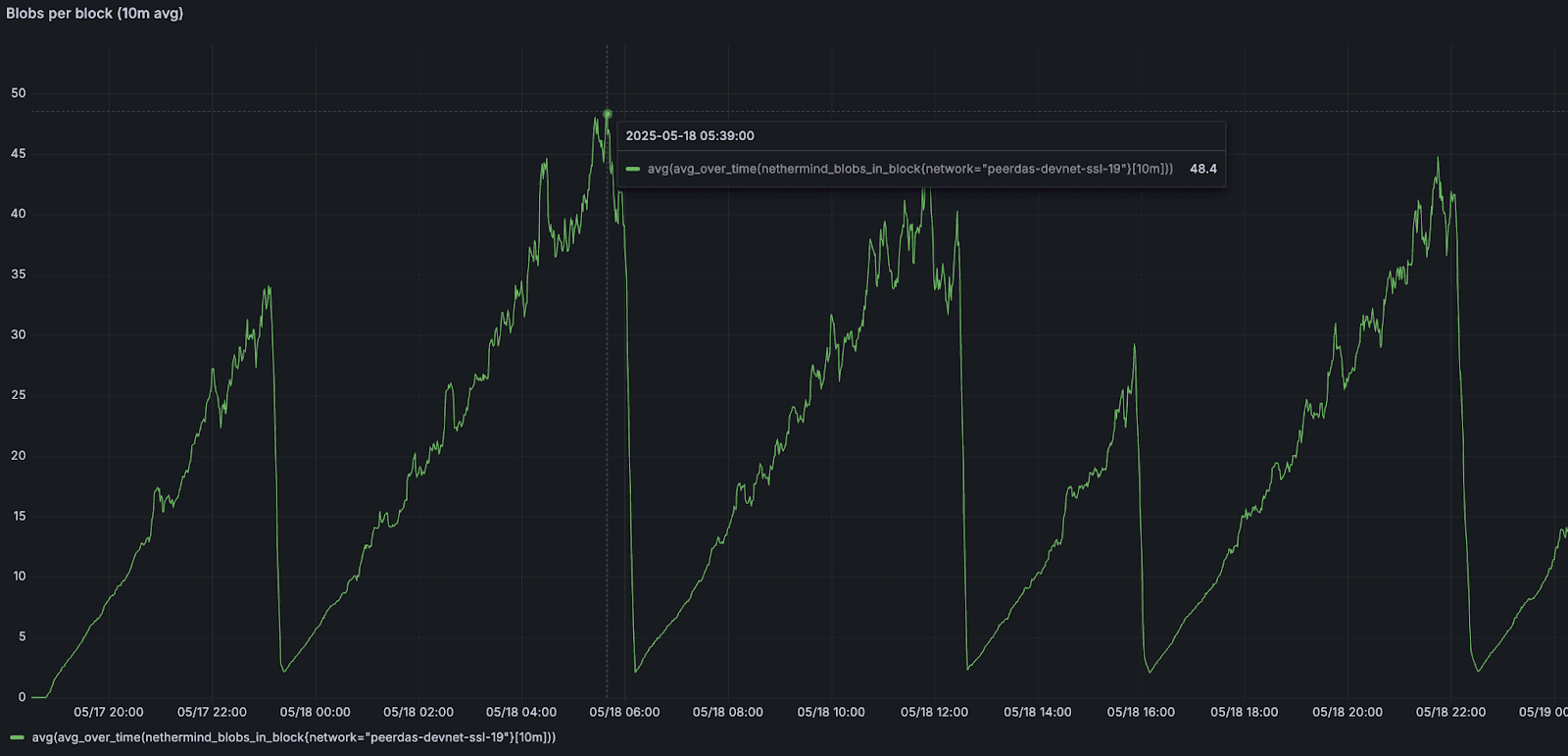
该图绘制了 Nethermind 的每区块 blob 数量的 10 分钟滚动平均值。峰值标志着 spamoor 必须重置之前最高的持续吞吐量。
共识延迟
随着 blob 负载的增加,共识延迟不断累积:区块到达延迟,导入滞后,并且证明错过了它们的窗口。这些复合延迟导致 slot 丢失和整体网络参与度降低。
我们测量了三种变得有问题的延迟:
-
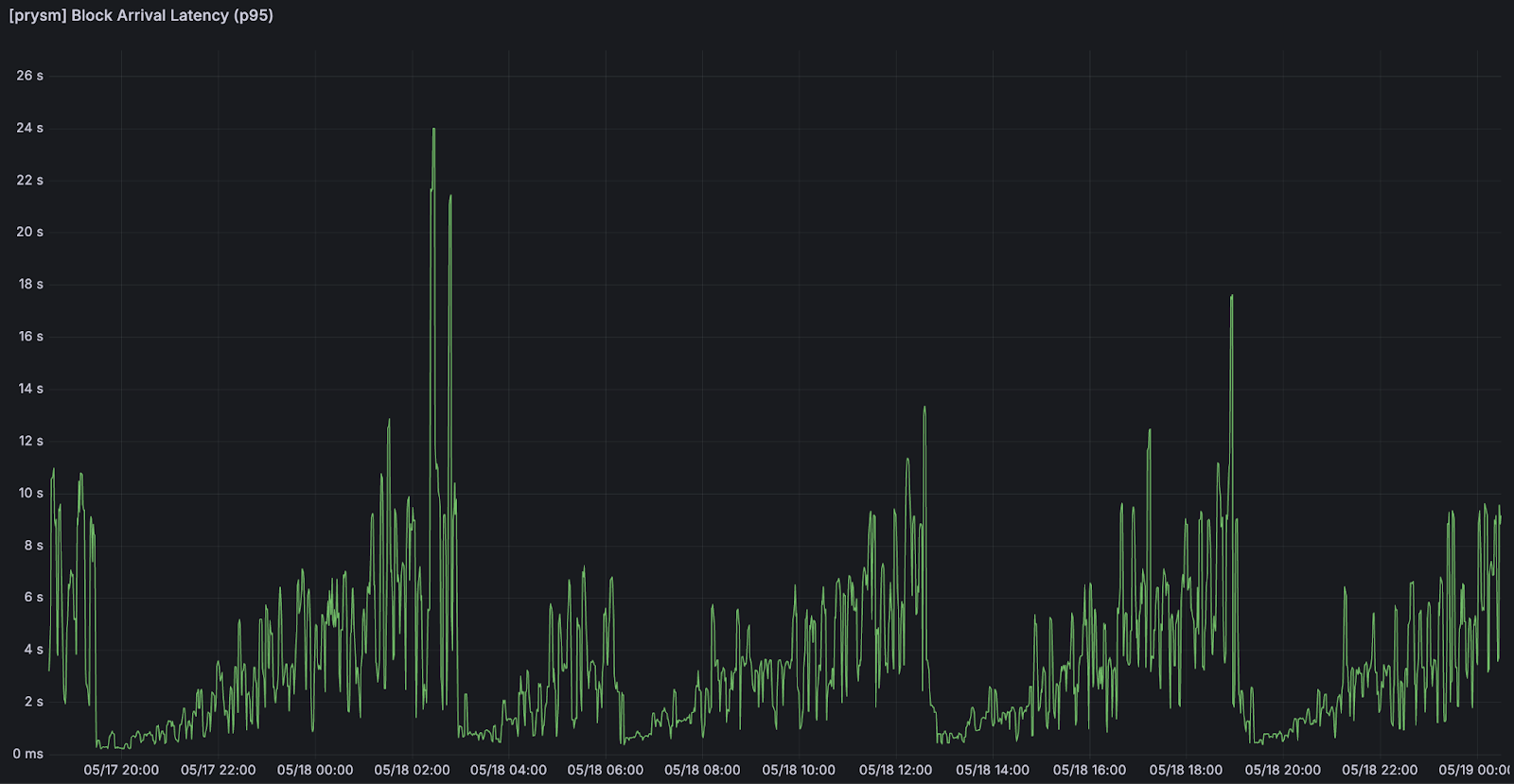
区块到达延迟:区块到达节点所需的时间
-
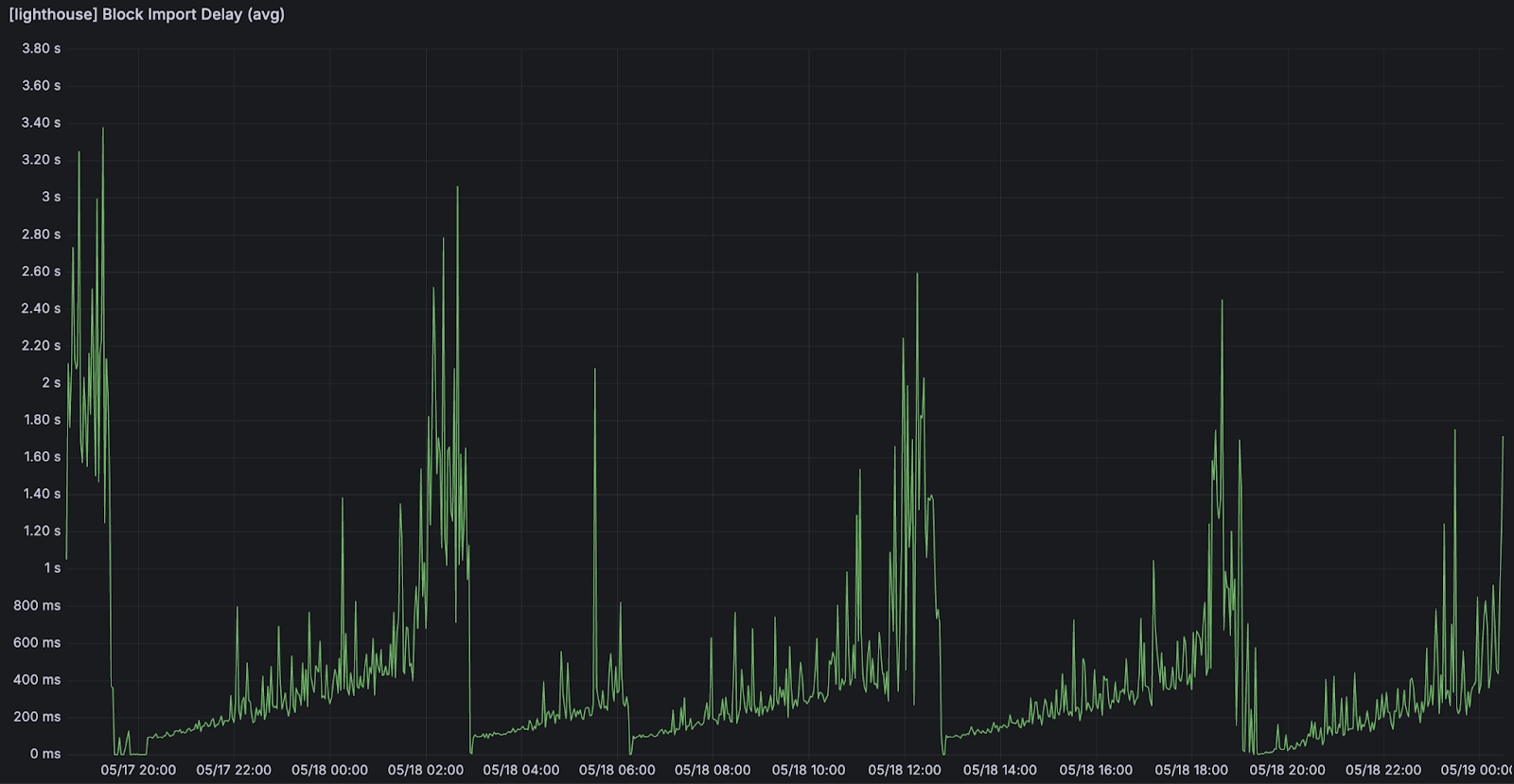
区块导入延迟:一旦区块到达后的处理时间(验证和执行新到达的区块)
-
证明时序问题:错过正确证明的窗口
为了可靠地超过 50 个 blob 的阈值,客户端必须最大限度地减少共识延迟并优化区块处理的每个阶段。
 <br>由于区块到达造成的延迟。随着 blob 数量的增加,我们可以注意到区块到达延迟的增加。 <br>由于区块到达造成的延迟。随着 blob 数量的增加,我们可以注意到区块到达延迟的增加。 |
 <br>来自区块导入的延迟。随着 blob 数量的增加,我们可以注意到区块导入延迟的增加。 <br>来自区块导入的延迟。随着 blob 数量的增加,我们可以注意到区块导入延迟的增加。 |
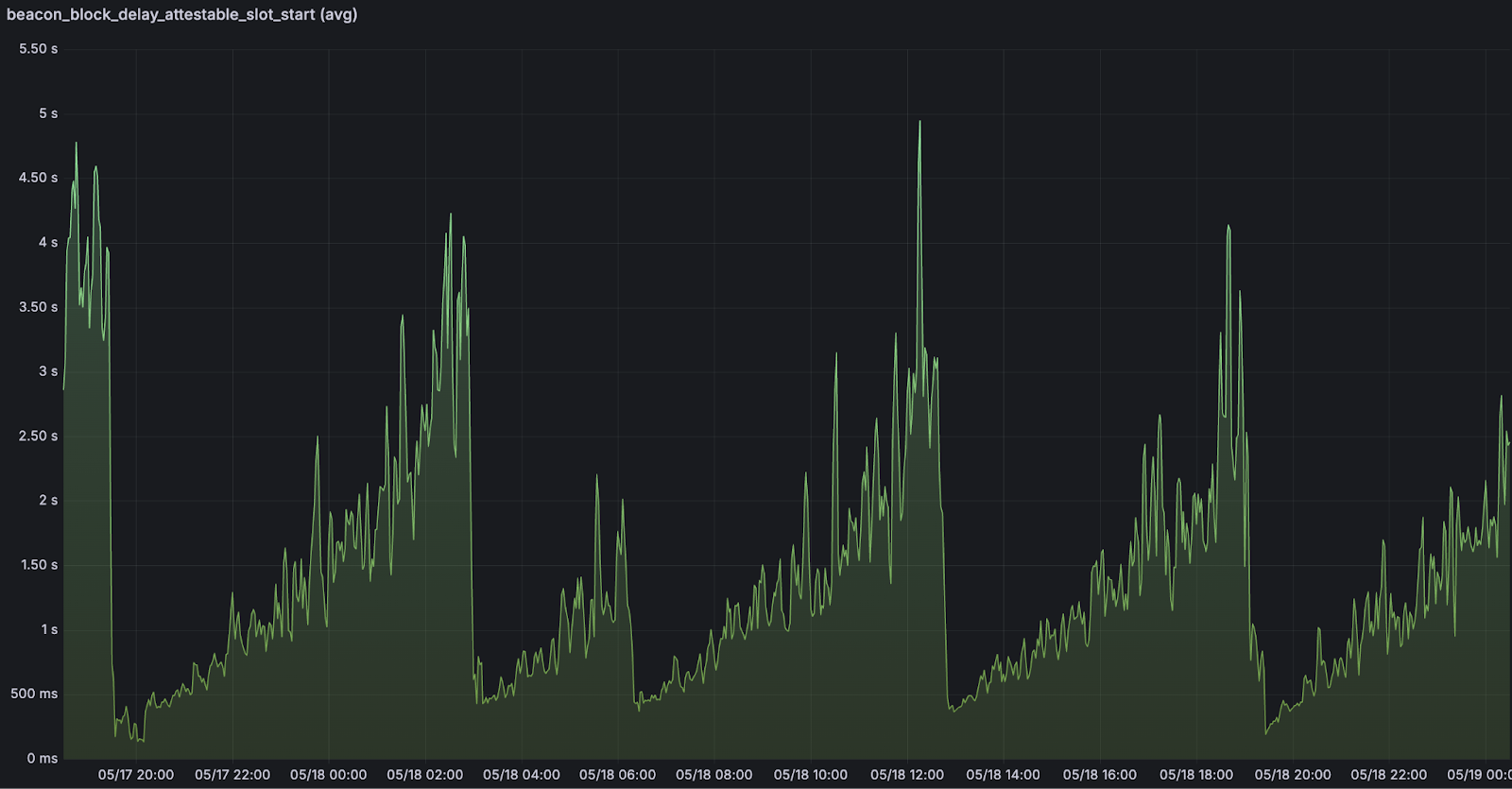 <br>可证明 slot 开始时间的延迟。随着 blob 数量的增加,我们注意到 slot 的可证明时间窗口开始时的延迟。 <br>可证明 slot 开始时间的延迟。随着 blob 数量的增加,我们注意到 slot 的可证明时间窗口开始时的延迟。 |
在 blob 数量达到峰值时,我们还观察到共识不稳定迹象,如小的重组、不一致的证明以及偶尔的头部分歧,这表明 CL 承受了压力。因此,一些测试运行看到持续的吞吐量限制在每个区块 25-35 个 blob 左右,远低于在孤立突发中观察到的峰值容量。
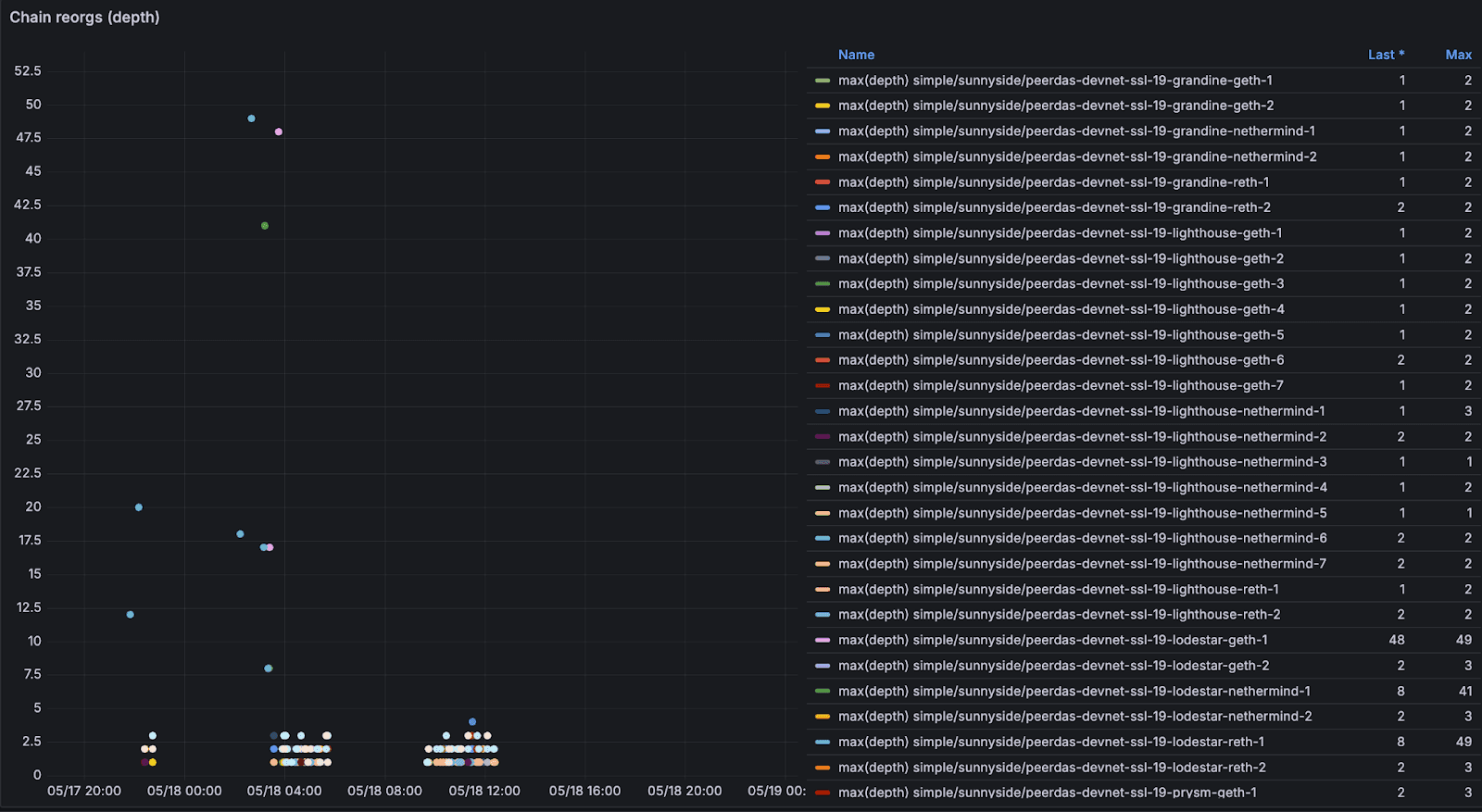 <br>随着 blob 数量的增加,链重组增加。 <br>随着 blob 数量的增加,链重组增加。 |
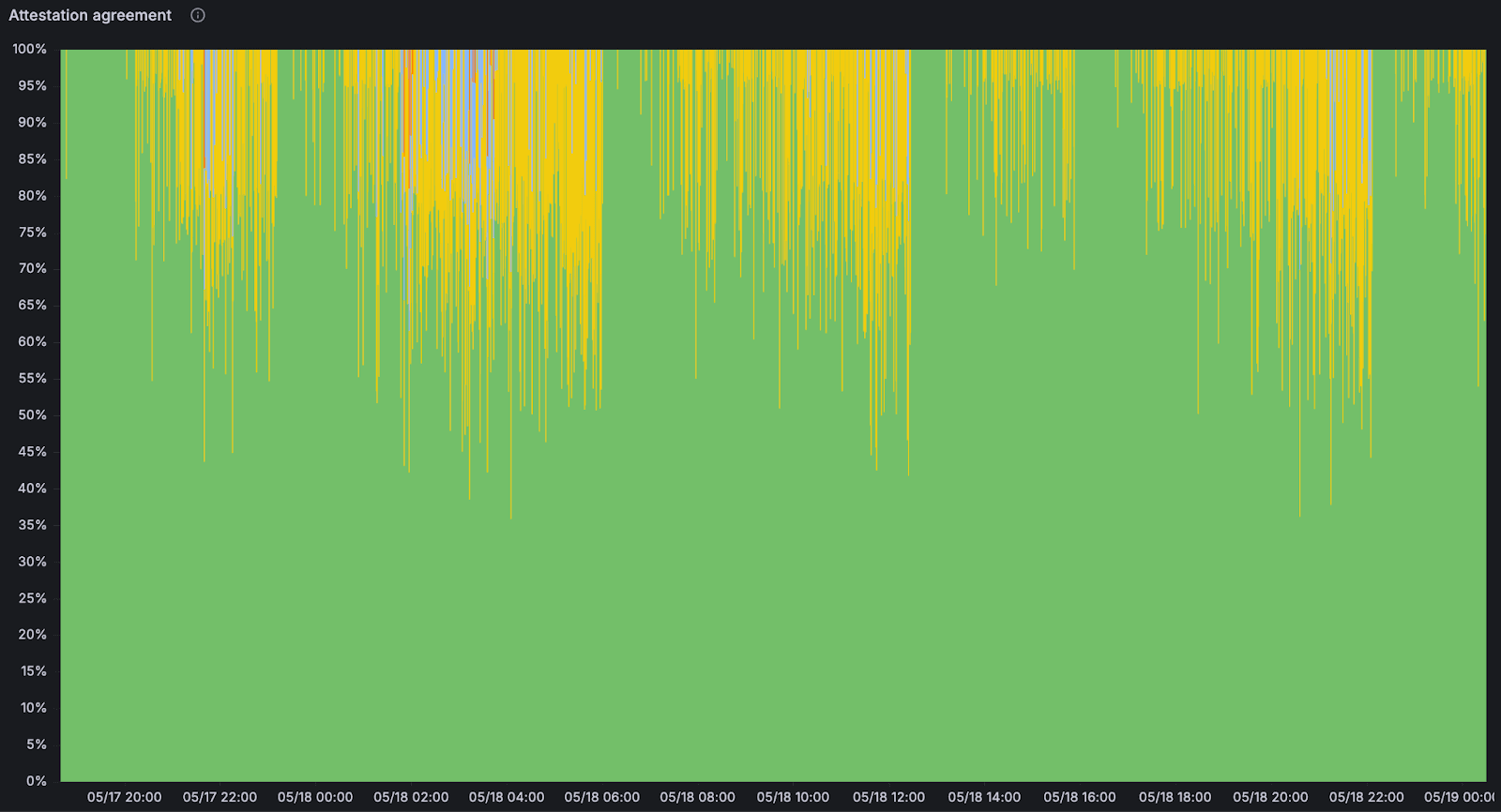 <br>证明协议:对于给定的 slot,哪些信标区块根具有针对它们的证明。随着 blob 数量的增加,我们注意到证明下降。 <br>证明协议:对于给定的 slot,哪些信标区块根具有针对它们的证明。随着 blob 数量的增加,我们注意到证明下降。 |
在高 blob 计数下,从执行客户端获取 Blob 的速度明显下降,给尝试验证和证明区块的共识客户端增加了压力。这创建了一个反馈循环,共识延迟使执行层性能恶化,反过来使共识延迟更加明显。
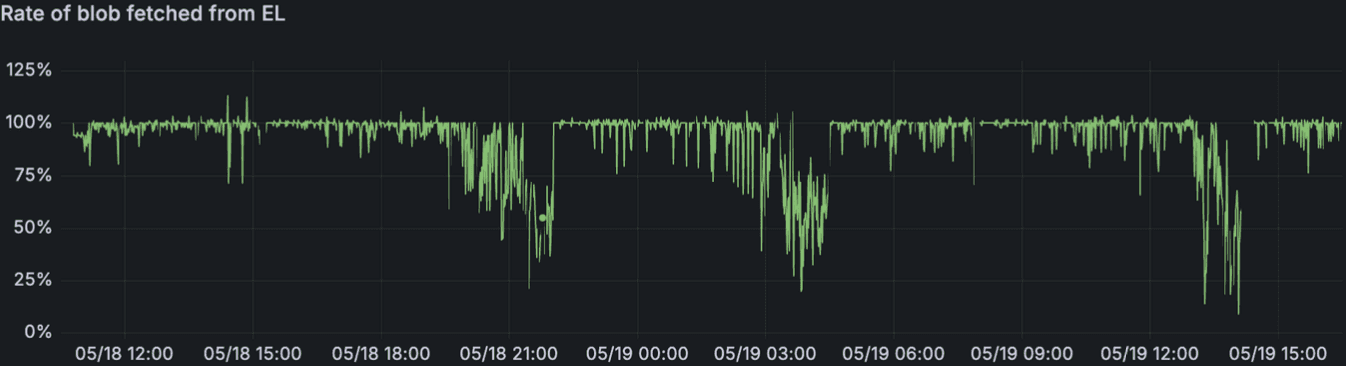
随着负载增加,从 EL 获取的 blob 速率恶化
超级节点的稳定性
超级节点性能在 blob 数量达到峰值时下降。崩溃仅发生在每个区块 blob 达到 50 个 blob / 区块级别时,这表明在高 blob 压力下存在可重现的性能弱点。Lodestar 超级节点是我们在 devnet 中第一个出现故障的。在压力下,它们的同步过程被证明是不稳定的,经常退出并落后于其他客户端实现(更多信息将在下一节中介绍)。
这些结果突出表明,需要更容错的架构和改进的恢复机制,特别是对于在高吞吐量环境中运行的超级节点。
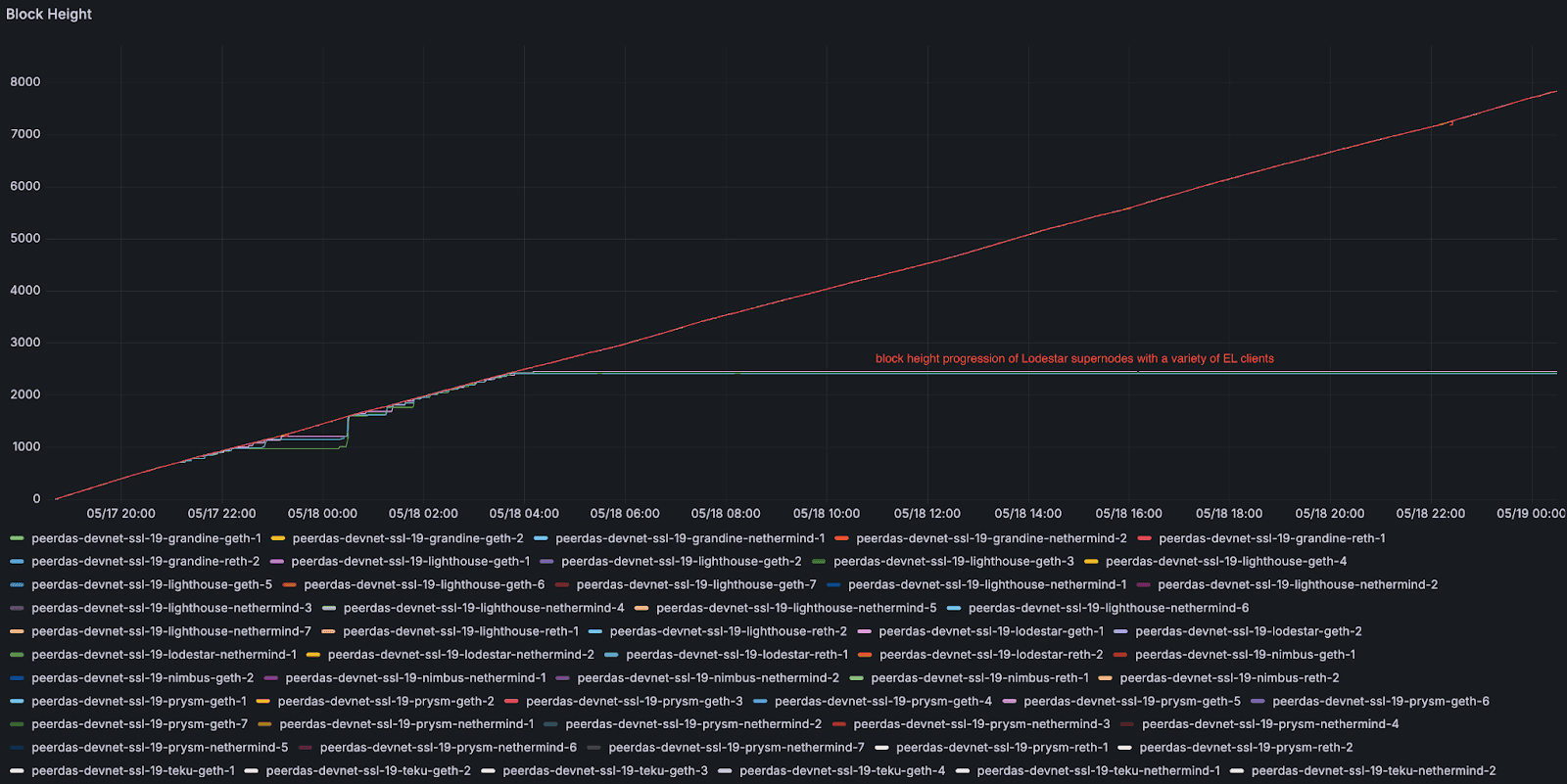
负载下的区块高度进展。平滑的线条显示正常节点稳步前进,而阶梯状的线条显示 Lodestar 超级节点停滞然后赶上。此模式表明 Lodestar 超级节点在 blob 峰值期间落后,并且仅在失败后才突发恢复。
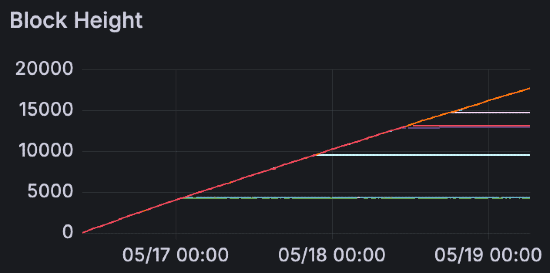
一旦 blob 数量达到峰值,超级节点将无法继续前进
Lodestar 性能分析
在中等负载下(最高约每区块 35 个 blob),Lodestar 保持了与其他共识客户端相当的性能。随着 blob 吞吐量超过此阈值,我们观察到了一些稳定性挑战,这些挑战为高吞吐量场景提供了重要的学习机会。
Lodestar 超级节点显示出更高的 CPU 使用率,尤其是在恢复阶段,这表明密集的追赶过程。
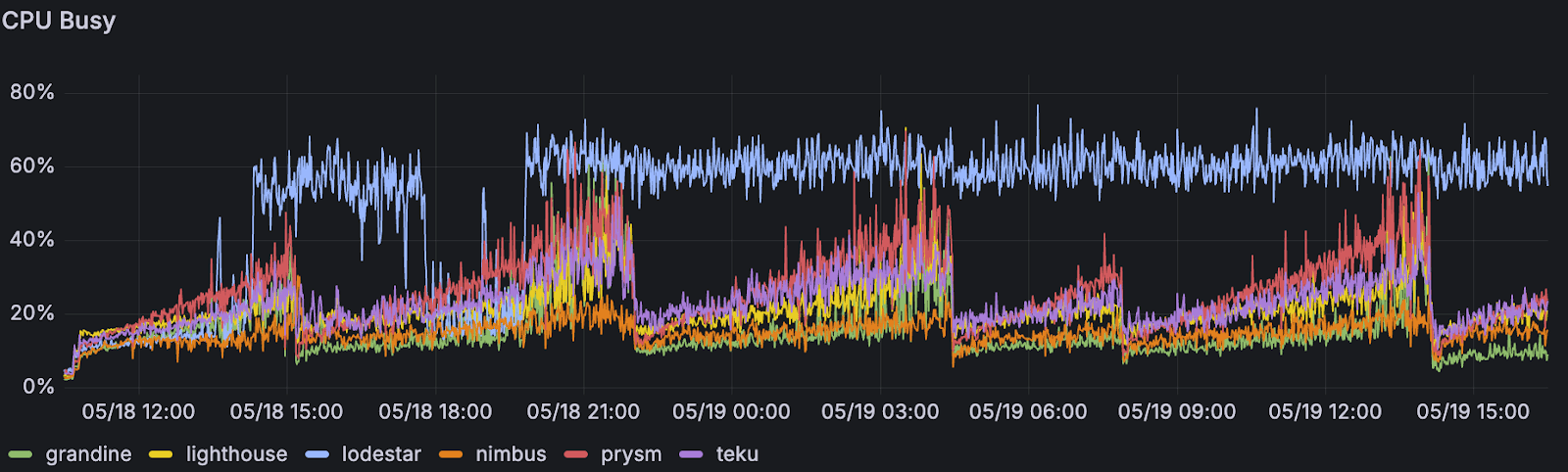
按共识客户端划分的超级节点的平均 CPU 使用率。
我们还观察到 RAM 消耗增加,以及入站网络使用量激增,这表明有机会优化 blob 和边车的传播效率。
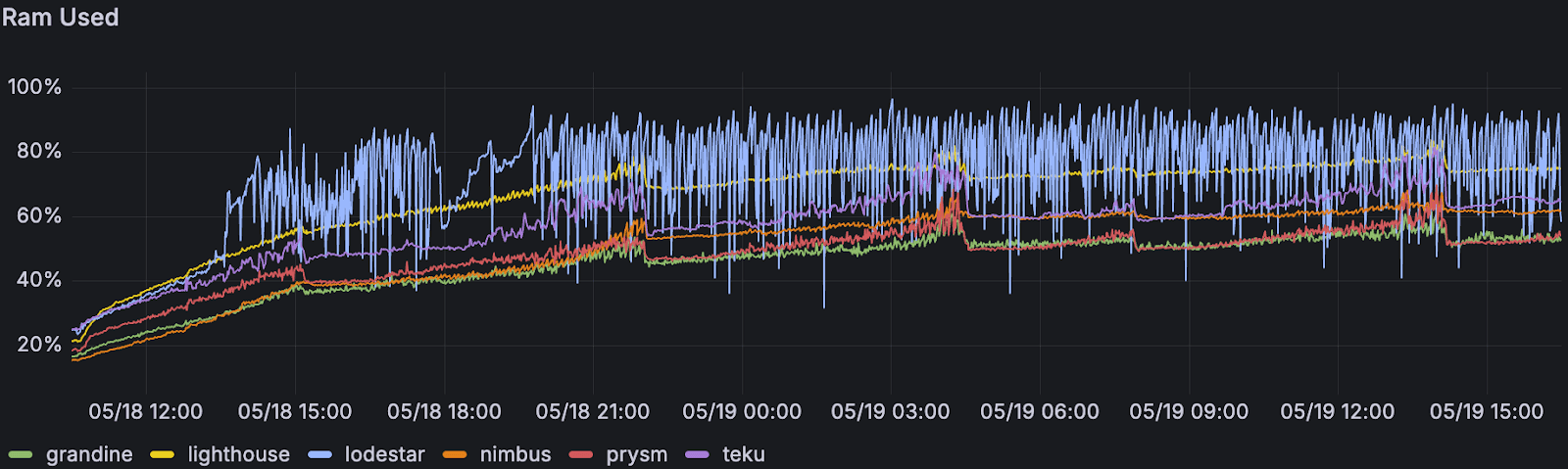 <br>按共识客户端划分的超级节点的平均 RAM 使用率 <br>按共识客户端划分的超级节点的平均 RAM 使用率 |
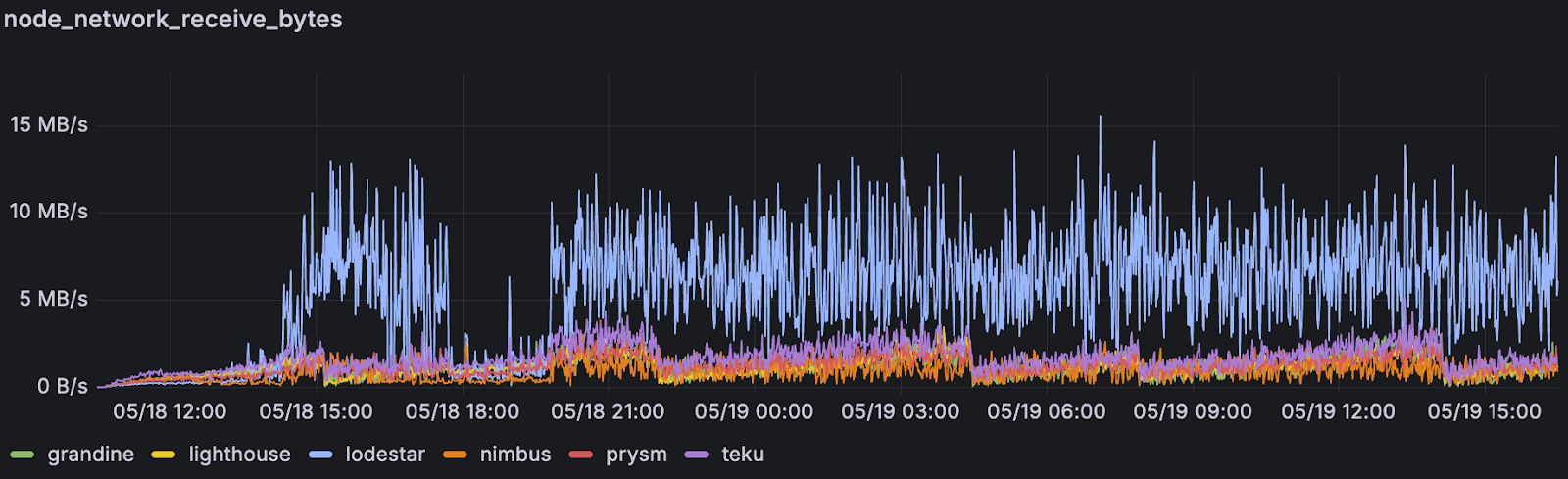 <br>按共识客户端划分的超级节点的平均网络入站 <br>按共识客户端划分的超级节点的平均网络入站 |
边车数据列处理也显示出更长的验证时间,这可能导致了同步问题。在我们整个测试中,Lodestar 节点的数据列边车 gossip 验证的完整运行时间始终较高。
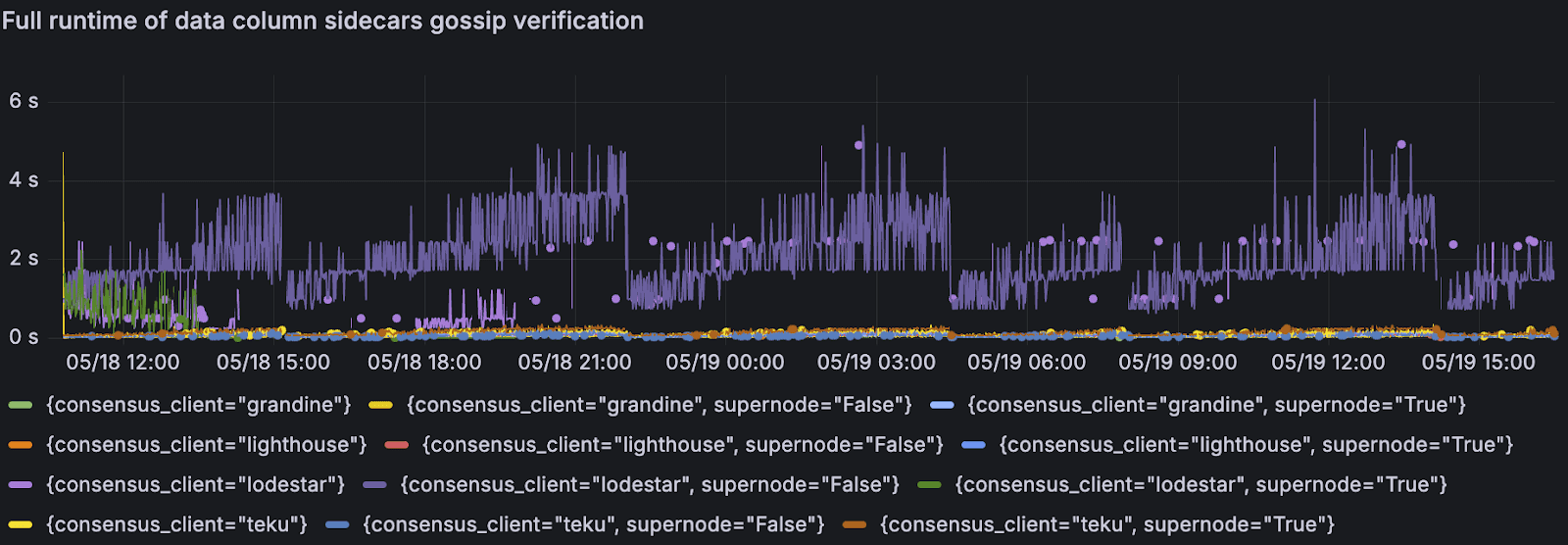
每个节点 / 客户端类型的数据列边车 gossip 验证的完整运行时间
ChainSafe 团队已经打开了一个 PR,以改进 DataColumnSidecars 的批量验证,我们预计这将带来性能提升:https://github.com/ChainSafe/lodestar/pull/7910。
为什么这很重要:这些发现不是为了宣布赢家和输家;而是为了识别具体的优化机会。每个客户端实现在规模上面临着独特的挑战,而理解这些模式有助于整个生态系统改进。
前进的道路
Sunnyside 的 peerdas-devnet-7 测试证实,我们可以接近每个区块 50 个 blob,但要可靠地达到并超过此阈值,需要在客户端和网络基础设施上进行有针对性的优化。当前的瓶颈包括累积共识延迟、执行层获取滞后以及超级节点鲁棒性不足,所有这些都必须解决,以确保规模上的稳定性。
需要调查的瓶颈:
-
在持续高负载下累积的共识层延迟
-
导致级联性能问题的执行层获取滞后
-
在峰值吞吐量条件下的超级节点鲁棒性
我们将更深入地研究分布式 blob 构建是否(以及如何)有助于提高所有客户端对的性能,以及这对可持续的 blob 吞吐量意味着什么。我们还将分析为什么某些运行的持续吞吐量远低于峰值容量,并确定这是否是由于网络限制、客户端特定问题或我们的负载生成器配置所致。
现在上限更加清晰 - 我们正在接近 48-50 个 blob 的目标,并相信我们将根据这些发现为未来的改进做好充分准备。Superchain 需要可预测的、高吞吐量的数据可用性,而 blob 性能的每一步前进都会直接使我们的用户和开发者受益。
下次再见!为了所有人更便宜的 blob 而努力 ✨
- 原文链接: optimism.io/blog/peerdas...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





