椭圆曲线深度解析(第 9 部分)
- Frank Mangone
- 发布于 2025-10-07 07:46
- 阅读 1027
本文深入探讨了配对技术的计算方法,重点介绍了米勒算法,该算法通过平方和加法在对数时间内计算配对,并讨论了不同类型的配对(Type 1, 2, 3, 4)及其在密码学中的应用。文章还详细解释了非退化性对于配对的重要性,以及如何通过选择合适的配对类型和曲线来确保配对的有效性。
好的!我们在前一篇文章中结束了对配对定义方式的详细介绍。
尘埃落定后,我们得到了 Weil 和 Tate 配对的一些可疑的简单定义。对于如此复杂的构造来说,我们最终得到的表达式竟然如此简单,简直像诗一样:
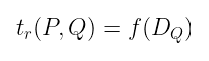
然而,正如你现在可能已经预料到的那样,表象是具有欺骗性的:事实上,我们还没有说明如何从这些简单的表达式中计算配对。
如果我们希望能够有效地利用配对,那么这实际上是最重要的部分!
今天,我们将研究使配对计算成为可能的技术,以及一些最终将所有元素组合在一起的更详细的信息。
我们现在离终点线更近了。再多一点点!
计算
让我们关注一下 Weil 配对:
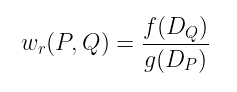
在前一篇文章中,我们看到了一种在除子上求函数值的自然方法 —— 这正是我们计算此配对所需要的。也就是说,对于除子 D 和函数 f:
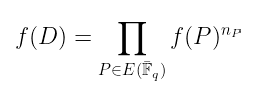
那些 f 和 g 并不是任意函数 —— 我们说过它们恰好是除子为以下的函数:
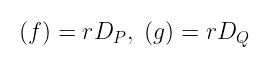
我们从未提到的是如何获得它们 —— 上次,我们只是提到可以构造这样的函数,但没有说明如何构造。很明显,一旦我们有了它们,就只是将它们插入定义的问题。但是我们如何找到它们呢?
让我们看看我们如何才能做到。
构建函数
为了开始,我们需要回到上一篇文章开头的一个断言:我们可以构建一个函数 fₘ,ₚ,其除子(是主除子)的形式如下:
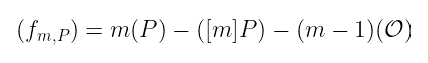
我们将要做的是一个归纳过程:假设我们有 fₘ,ₚ,我们可以构建 fₘ₊₁,ₚ 吗?
答案是可以 —— 而且是以一种非常优雅的方式。
我们将使用我们已经看到的几个技巧,其中涉及两个非常简单的函数。首先,让我们取通过 P 和 [m]P 的直线,它的除子只是:
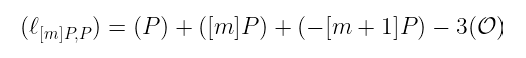
其次,取通过 [m+1]P 的垂直线:
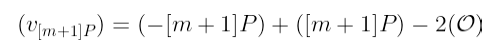
使用这两个除子,我们可以找到 fₘ,ₚ 和 fₘ₊₁,ₚ 之间的一个非常巧妙的关系:
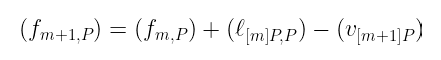
我们之前对除子的了解揭示了上述观察的一个惊人之处:除子等式可以直接映射到一个我们可以操作的代数表达式:
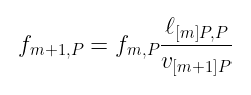
这差不多就是全部了!给定任何 m 值,我们可以从函数 f₁,ₚ 开始,然后逐步得到所需的函数。小菜一碟,对吧?

随便你怎么说,伙计。
别太快了,牛仔。
棘手之处
记住我们做这一切的目标是构造一个除子为以下的函数:
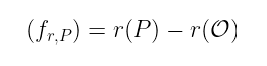
那里的 r 值正是 r-挠群 的大小。在实践中,r 的值将是巨大的(我们说的是超过 2¹⁵⁰),这意味着通过一次执行一个更新来找到我们的函数将一事无成。
换句话说,通过使用上面的策略,配对计算在实践中将是不可行的,所以我们所拥有的只是一个漂亮但无用的理论。
但是,配对确实在实践中用于各种密码学协议 —— 所以这里一定有一些诀窍。而且可以肯定的是,配对计算成为可能归功于一个叫做 Victor S. Miller 的人的巧妙想法。
这就是接下来我们要看到的。
Miller 算法
与其尝试在每次迭代中将 m 加 1,如果我们尝试将其加倍会怎么样?
让我们看看。我们从某个函数 fₘ,ₚ 开始:
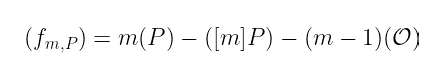
即使一次只迭代一次,我们最终也会得到以下函数:
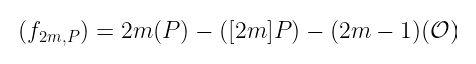
当我们尝试平方我们的原始函数时,有趣的事情发生了。通过我们已经知道的除子的性质,我们可以算出结果除子为:
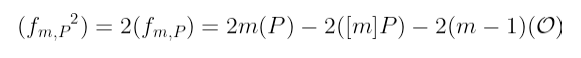
这几乎非常类似于我们想要得到的除子!
事实上,我们可以算出它们的差为:
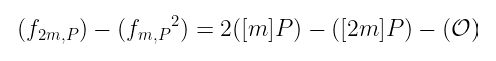
现在这应该看起来很熟悉了吧?

*眯起眼睛*
让我为你省去麻烦:它是与 [m]P 相切的线的除数,减去通过 [2m]P 的垂直线的除数。本质上,用于加倍 [m]P 的函数。
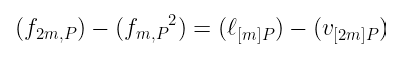
这个绝妙的见解使我们能够通过以下方式加倍当前的 m 值:
- 平方当前函数,
- 乘以与 [m]P 相切的线,
- 除以 [2m]P 处的垂直线(它只是一个标量值)。
通过平方和加法,我们可以在对数时间内得到任何 r 值,并在需要时使用单个步骤。
例如,为了得到 r = 28,我们可以执行 double,add, double, add, double, double。
这应该让人想起我们用于快速乘法椭圆曲线点的 double-and-add 算法。在幕后,两者都使用切线规则进行复制 —— 只是在 Miller 算法的情况下,我们在构建函数。
最后需要注意的是,随着我们深入算法,得到的函数将具有高阶,因此完整地存储它们变得非常昂贵。
诀窍是不存储完整函数,而是存储其在某个除子处的求值。当然,我们所要做的就是选择我们想要计算配对函数的除子!
Miller 优雅的算法最终实现了实际的配对计算。但这并不是配对的全部 —— 我们还需要考虑一些其他的事情。
配对类型
我们遗忘在架子上的一件事是 trace 和 anti-trace 映射的定义。似乎我们做了所有的努力,但没有明显的原因。
直到现在。
你看,当我们定义一个配对为:
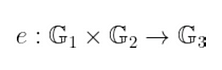
我们需要考虑这些群实际上是什么。当然,我们知道它们属于 r-挠群,但是我们选择任何挠子群可以吗?或者我们应该注意我们的决定?
正如你可能期望的那样,在选择这些群时确实需要小心。否则可能会导致一些问题。
这将最终引导我们到配对类型的概念,它们本质上描述了 𝔾₁ 和 𝔾₂ 之间的关系。但为了充分理解其中的利害关系,我们必须首先了解一些关于我们可能使用配对的目的。
群的要求
当使用配对构建密码学协议时,我们需要执行两个基本操作。
首先,我们需要哈希到我们选择的群中。通过这种方式,我们指的是获取任意数据 —— 比如用户的姓名、电子邮件地址、某些消息,或者几乎任何东西 —— 并确定性地将其映射到 𝔾₁ 或 𝔾₂ 中的一个点。
例如,这对于像 基于身份的加密 这样的方案至关重要,其中一个人的身份本身通过哈希变成他们的公钥。
我们还希望这个哈希过程是高效的。某些群的选择使得这样做非常困难,所以相反,我们被迫使用固定的 生成器 和标量倍数,这严重限制了我们可以构建的协议。也就是说,我们只能为某个固定生成器 P 创建形式为 [k]P 的点,并且我们不能直接处理任意输入 —— 这对于大多数应用程序来说是一个破坏者。
其次,我们偶尔需要群之间的高效同态。拥有一个像这样的高效可计算映射:
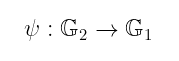
可以被证明是非常有用的。
原因是某些协议需要检查关系或执行操作,这些操作只有当元素在同一个群中时才有意义。此外,某些群中的操作比其他群快得多 —— 所以如果我们可以通过在群之间移动来实现更快的计算,那将是一个巨大的胜利!
有点像计算作弊码!
但当然,有陷阱。总是有陷阱。
在这种情况下,问题在于我们不能同时轻松地拥有这两件事。不同的群选择在这种权衡中提供了不同的平衡。而这正是不同配对类型的意义所在。
有了这个,我们现在准备好正式地介绍它们。
类型 1:对称配对
我们可以想象的最简单的情况是当 𝔾₁ = 𝔾₂ = 𝒢 ₁.
回想一下,𝒢 ₁ 是 base field subgroup。
由于我们对 𝔾₁ 和 𝔾₂ 使用相同的群,所以这些被称为对称配对也就不足为奇了。
让我们看看它们如何满足我们的要求。首先,哈希到 𝒢 ₁ 相对高效,因为整个群都在基域上 —— 所以这是一个胜利。并且由于两个群是相同的,我们只需要一个哈希函数。
在群之间的映射方面,我们实际上有一个微不足道的映射 —— 恒等映射!我想这不算数吧?反正,让我们说这是另一个胜利。
那么权衡是什么呢?一切似乎都很好……

我不再信任你了
好吧,记住为了使配对工作,除数支持必须是不相交的。当 P 和 Q 都来自 𝒢₁ 时,确保不相交的支持变得有问题 —— 我们本质上是将一个群与自身配对。
解决这个问题的方法是使用所谓的扭曲映射:一个高效可计算的映射 φ,它将 𝒢₁ 中的一个点移动到不同的 r-挠群中。有了这个,我们可以计算:
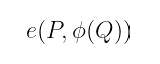
并且不相交的支持条件将更容易覆盖。
所以这是真正的问题:扭曲映射只存在于 超奇异曲线 上。

你说超奇异?哦,是的,宝贝!
超奇异曲线具有小的 嵌入度,通常 k ≤ 6。小的嵌入度意味着配对输出落在小的域扩展上,这反过来导致输出群中的离散对数问题变得易于处理,从而导致曲线容易受到攻击。
简而言之,类型 1 的简单性是以安全性为代价的。随着更安全的替代方案的出现,类型 1 配对在实践中已经失宠。
类型 2:具有同构的非对称配对
我们现在转向类型 2、3 和 4 的非对称配对。在这三种情况下,我们将取 𝔾₁ 为 𝒢 ₁.
在类型 2 配对中,选择 𝔾₂ 为其他 r-挠群之一,除了 𝒢₂(迹零子群)。
再次,让我们检查一下我们的要求:
- 在可用同构方面,我们确实有一个高效可计算的映射 ψ: 𝔾₂ → 𝔾₁,并且你已经看过它了 —— 它是迹映射!这允许我们在协议需要时将元素从 𝔾₂ 移动到 𝔾₁。我们甚至可以使用反迹映射进行某些操作来反向移动,尽管这不会直接映射回 𝔾₂。
- 然而,在哈希方面,这种选择很困难。没有已知的高效方法来直接哈希到这些其他 r-挠群中。
所以哈希是这里真正的罪魁祸首。我们能做的最好的就是,正如我们之前提到的,选择一个固定的生成器 P₂ ∈ 𝔾₂ 并通过标量乘法 [k]P₂ 创建元素。但是这意味着每个元素都有一个相对于 P₂ 的已知离散对数**,这破坏了需要随机或哈希派生点的协议。
这个单一的限制非常关键,以至于它阻止了类型 2 配对的广泛实际应用 —— 大多数协议只是需要能够哈希到两个群中,这立即排除了这种类型。
类型 3:没有同构的非对称配对
现在对于这种类型,我们取 𝔾₂ 为 𝒢₂ —— 迹零子群本身。
这个看似很小的改变具有深远的影响 —— 它实际上完全颠倒了这种权衡的局面。让我们看看:
- 与类型 2 不同,我们可以现在哈希到 𝔾₂。该机制涉及首先哈希到整个 r-挠群,然后简单地应用反迹映射来移动到 𝒢₂。
- 当然,我们必须为此付出代价。在这种情况下,这转化为我们没有一种高效的方式来计算我们可以使用的同构 ψ。
重要的是要指出,这样的同构必须存在 —— 毕竟,𝔾₁ 和 𝔾₂ 具有相同的大小。问题是没有已知的高效方法来计算它。
具有讽刺意味的是,我们唯一可以高效哈希到的群(除了 𝒢₁)是我们无法高效映射出去的子群。
因此,我们失去了类型 2 提供的计算捷径和协议灵活性。同样重要的是,大多数安全证明实际上依赖于拥有这样一个映射,因此为了证明类型 3 配对的鲁棒性,协议需要围绕不同的硬度假设进行设计。
在实践中,这种权衡已被证明是可以接受的,因为对于大多数协议来说,哈希到两个群中的能力是最关键的方面。
类型 3 是现代基于配对的密码学的黄金标准。
类型 4:完全扭转
最后,类型 4 取 𝔾₂ 为整个 r-挠群 E[r]。
- 哈希到 E[r] 是可能的,但它不如哈希到 𝒢₁ 或 𝒢₂ 高效。由于群更大(正如我们已经看到的,它的阶数为 r²),因此有更多的计算开销。
- 然后,我们可以看一下 E[r] 的结构。从这个意义上说,它具有一个独特的特征:它是非循环的。我们已经知道它与 ℤᵣ×ℤᵣ 同构,所以没有一个生成器可以产生群中的所有元素。某些协议依赖于循环性来工作,因此它们不能使用类型 4 配对。
奇怪的是,当哈希到 E[r] 中时,落入 𝒢₁ 或 𝒢₂ 中的概率接近 2 / r —— 对于大的 r 值来说是可以忽略不计的。某些专门的协议可能需要确保避免特定的子群,在这些情况下,类型 4 配对可能是有用的。
效率成本和缺乏循环性意味着类型 4 配对很少在实践中使用。
总而言之,类型 3 配对是现代基于配对的密码学中的主要变体。说实话,我们几乎从不担心我们正在使用哪种类型的配对。只是如果我们在协议设计中必须非常技术性,我们可能必须考虑使用每个群选择的含义!
现在我们了解了不同的配对类型及其权衡,让我们在结束对这些惊人结构的章节之前,解决另一个关键问题。
退化
我们已经讨论了配对类型以及如何构造计算所需的函数,但是我们需要确保的还有另一个关键属性:我们的配对实际上有效。

我说的有效是什么意思?记住,配对的目的是双线性映射。但是有一种满足双线性的简单方法:只需将所有内容映射到 1!
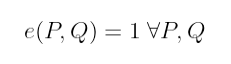
虽然这样的配对在技术上会满足双线性,但它完全没用。我们称这样的配对为退化。
当然,如果存在点 P 和 Q 使得 e(P, Q) ≠ 1,则配对是非退化的。
我应该担心吗?
在我们费力地以这些复杂的方式定义配对之后,我们的配对似乎不太可能是退化的,对吧?
嗯……不完全是。如果我们不小心选择 𝔾₁ 和 𝔾₂,即使正确地遵循所有构造步骤,我们最终也可能会得到一个退化的配对。数学可能是合理的,但是结果在密码学上是无用的。
当我们尝试将 Weil 配对与 𝔾₁ = 𝔾₂ = 𝒢₁ 一起使用,但在具有没有扭曲映射的普通(非超奇异)曲线的情况下,可能会出现问题的具体示例。
当 Weil 配对作用于来自同一 Frobenius 特征空间(在这种情况下,𝒢₁) 的两个点时,无论你选择哪个点,配对总是求值为 1。以忽略一些细节为代价,这是简短的解释:
- 首先,我们知道 Frobenius 自同态对 𝒢₁ 中的点的作用是微不足道的,因此对于 𝒢₁ 中的任何 P 和 Q,我们有 π(P) = P 和 π(Q) = Q。
- 然后,对于曲线上的有理函数,Frobenius 映射具有一个特殊的属性:
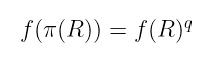
- 我们可以将此属性插入到 Weil 配对本身中,并查看结果的除数,我们得到:
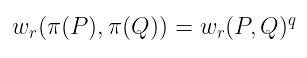
- 但是由于 P 和 Q 在 𝒢₁ 中:
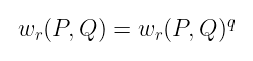
我们要说的是,无论配对的输出是什么,它都被q-th 幂映射固定。换句话说,它必须是基域中的一个元素,因为如果 wᵣ(P, Q) 属于一个域扩展,那么将其提高到 q-th 幂将不会产生相同的结果。
我们还知道 wᵣ(P, Q) 必须是单位的 r-th 根。
回想一下,为了使一个域包含单位的 r-th 根,r 必须除以该域的乘法子群的基数,因此在这种情况下,q - 1。
这是棺材上的最后一颗钉子:我们通常选择 r,因此它不除以 q - 1,这意味着没有单位根 —— 除了平凡的那个:乘法单位元素。因此,wᵣ(P, Q) 必须等于 1.
这正是类型 1 配对需要具有扭曲映射的超奇异曲线的原因 —— 没有它们,退化是不可避免的。
要求
好的!这当然很多。抱歉!

你为什么要这样对我?
除了具体的例子之外,我们还应该检查一些一般条件,以确保非退化。让我们通过查看它们来结束。
- 首先也是最重要的:𝔾₁ 和 𝔾₂ 必须是不相交的(当然除了单位元,𝔾₁ ∩ 𝔾₂ ={𝒪})。如果它们共享非平凡点,则配对在这些点上退化。我们已经看到了在没有扭曲映射的情况下 𝔾₁ = 𝔾₂ 的极端情况 —— 配对变得完全退化。
这就是为什么迹和反迹分解如此有价值:它自然地允许我们使用 𝒢₁ 和 𝒢₂,它们在定义上是不相交的。
- 其次:除数支持必须是不相交的。我们之前已经提到过这一点,但是重复一遍并没有什么坏处:如果支持不相交,则函数求值会崩溃为 0 或爆炸为无穷大,从而导致未定义的行为,从而导致退化。从不同的特征空间中选择 𝔾₁ 和 𝔾₂ 自然地确保了这一点。
- 第三:嵌入度必须足够大。回想一下,嵌入度 k 是最小的正整数,使得 r 除以 qᵏ - 1,并且它决定了配对值的存在位置。从本质上讲,我们必须确保有足够的独立单位 r-th 根来支持非退化配对。
在实践中,选择正确的配对类型(尤其是类型 3)并使用正确构造的 配对友好曲线 会自动满足所有这些条件。数学机制确保了非退化,因此我们可以专注于密码学应用程序,而不是担心边缘情况。
尽管如此,理解为什么这些条件很重要可能有助于我们欣赏配对密码学的精心设计。朝着错误的方向迈出一步,整个事情都可能崩溃!
总结
有了这个,我们已经完成了对配对的探索,涵盖了一些使它们可以在密码学中使用的最重要的实际方面。
与往常一样,还有更多要说的。特别是,我想指出我们仍然需要为这些构造找到合适的曲线。大多数时候,我们假设我们可以找到它们,但是这不一定是一项容易的任务。
尽管如此,通过过去的一些文章,你应该对配对有一个大致的了解。有趣的是,我们着手寻找具有看似简单和有害属性(双线性)的函数,但最终却不得不深入研究非常深刻的东西才能使其工作。
我想,这就是数学美的一部分:一切最终都会很好地点击!
为了总结今天的文章,请记住:大多数时候,你将使用类型 3 配对,米勒算法在后台运行以进行实际计算,并且你将使用确保非退化的曲线和嵌入度。
虽然我们可以说更多关于椭圆曲线的内容(如果你有兴趣,甚至有关于它们的 整本书),但我不想在本系列中介绍所有内容。
但是,我认为一些实际的考虑将是一个很好的总结。因此,下一篇文章将致力于理解一些最广泛采用的曲线及其特殊性。
我们将在终点线见面!
- 原文链接: medium.com/@francomangon...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~



