Monad上的Prop AMM - 一种机制完善的、最佳原子执行路由
- thogiti
- 发布于 2025-09-07 09:14
- 阅读 2686
本文介绍了一种为Monad构建的执行时路由,用于在黑暗/专有 AMM 上实现原子最佳执行和激励对齐。该路由利用 Monad 的gas和延迟模型,在一个交易中探测多个AMM,选择最佳AMM执行。通过oracle轮次锁定,bonding, refunds, and penalties等机制,使得诚实报价成为平衡。
介绍
在我之前关于 shMONAD 带宽分配中的博弈论漏洞的文章中,我展示了带宽质押如何创建一个高风险、非合作的拥塞博弈,其中策略性时机(例如,闪电提交突发)扭曲了对 RPC 吞吐量的访问。这篇关于 Monad 的后续博客着眼于另一个瓶颈——价格发现和路由。我们没有关注带宽,而是设计了一个 taker 端的原语:一个为 Monad 上的暗盘/专有 AMM 服务的执行时路由器,该路由器在 Monad 独特的 gas 和延迟模型下实现原子最优执行和激励对齐。
为什么 Monad 适合:EVM 语义、并行执行、亚秒级终局性
用于 tx 内 best-of-N 探测的 EVM 语义
暗盘 AMM——也称为专有(“prop”)AMM,将其定价逻辑移至链上,以便 maker 在执行时而不是在更早的模拟步骤中进行报价。这减少了做市商的库存风险并收紧了价差——但只有当 taker 也可以在交易本身期间选择最佳 AMM 时,你才能实现全部好处。这个想法很简单:用户提交一个交易,该交易在 EVM 内部探测几个 AMM,忽略失败或较差的选项,并恰好一次在胜者上结算。这符合 EVM 语义:外部调用可能会回滚,而调用者继续执行,并且 Solidity 的 try/catch 让路由器处理这些失败,并继续执行[^1]。
具有串行等效结果的并行/乐观执行
Monad,正如 Alex 在此解释的那样,是这种“一个 tx 中 best-of-N”模式的特别好的宿主。它在保持完全 EVM 兼容性的同时,通过并行、乐观执行实现高吞吐量,并在冲突时重新执行,但区块结果与串行链保持相同(相同的线性顺序,相同的结果)。并行性是一个实现细节,它提高了吞吐量而不改变应用程序语义[^4]。
终局性和延迟情况
延迟是 UX 优势显而易见的地方:官方文档描述了 \~400–500 毫秒的区块频率,并在两个区块(\~800–1000 毫秒)处完成,并在稍早的一个区块处有一个“已投票”(投机性)阶段,并在之后不久有一个“已验证”(状态根)阶段,供想要额外确定性的应用程序使用[^3]。Monad 的博客还将 \~1 秒的终局性 视为市场微观结构密集型应用程序的设计目标[^7]。
高级路由器设计(一个交易中 best-of-N)
Gas 模型约束:按 limit 收费(而不是使用量)
你必须围绕设计一个 Monad 特定的转折:用户按 gas limit 而不是 gas 使用量 收费。文档 明确指出:扣除的金额为 value + gas_price * gas_limit。他们还注意到 1.5 亿 的区块 gas limit 和 3000 万 的每次交易 limit,以及默认的 优先级 gas 拍卖 排序。该定价保护异步/并行管道免受 DoS 攻击,但这意味着你的 SDK 必须 预先预算 紧凑的 gas 并设置显式 limit——当钱包在探测期间遇到故意回滚时,钱包估计可能会超调[^2]。
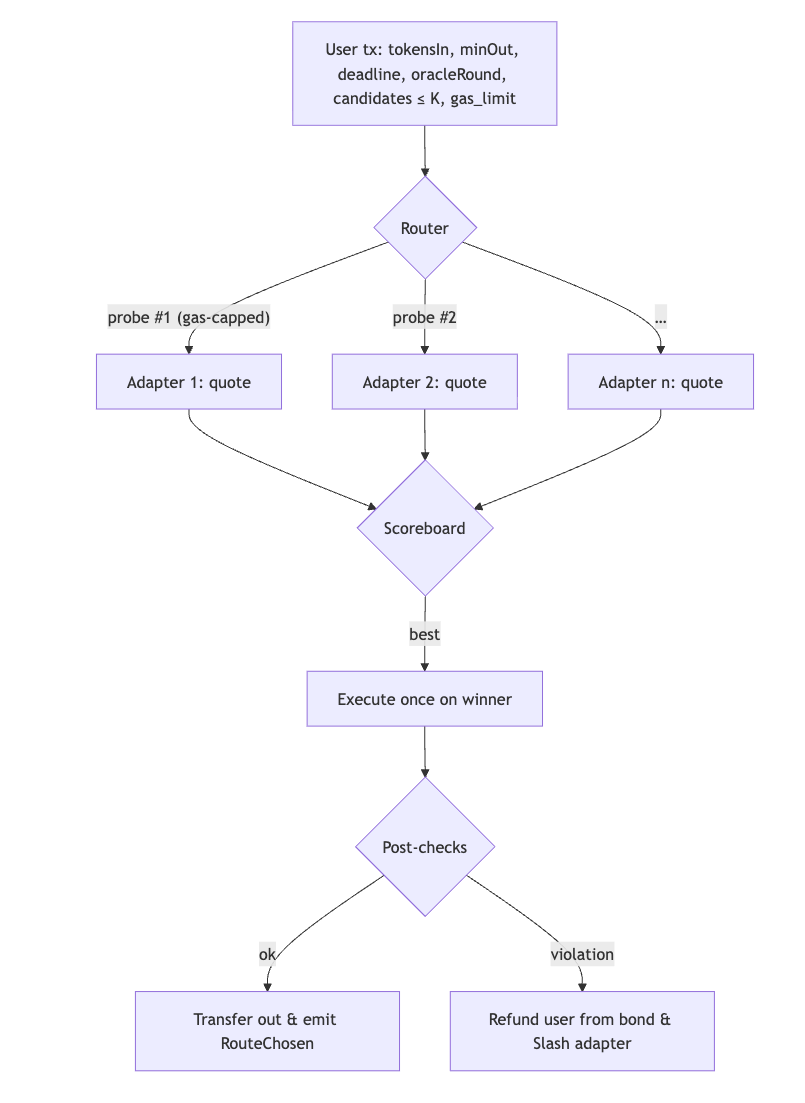
交易中探测和结算流程
有了这些基本规则,执行时路由器就是干净的工程。用户提交 tokens in/out,金额,minOut,截止日期,一小部分候选 AMM 和一个将每个人锁定到同一 oracle 轮次的参数。在 EVM 内部,路由器在小的 每次探测 gas 上限下迭代候选者,使用便宜的 staticcall 到只读报价或 revert-quote 变体,其中 AMM 运行实际交换路径,但当 simulate=true 时,使用 ABI 编码的报价数据回滚。路由器捕获失败或无法解码的 payloads,对成功的报价进行评分,选择获胜者,并执行一次真正的交换,同时强制执行用户的 minOut。因为它都发生在一个交易内部,所以在模拟时选择和执行时现实之间没有竞争。[Solidity 文档][S1]
Oracle 轮次锁定(什么 & 为什么)
轮次锁定概述
有两个细节使这保持稳健和无需许可。首先,oracle 轮次锁定:SDK 从链上 oracle 获取 roundId(Monad 测试网支持 提供者,例如 Blocksense、Chainlink、Chronicle、Pyth 等),并将其传递给每个适配器;适配器计算并回显该轮次(并在其元数据中提供身份)。路由器拒绝不匹配,并且可以针对锁定的轮次惩罚未交付。这消除了在探测期间引用更新的私有 ticks 的优势[^5]。
多提供者同步、回退和延迟
实际上,轮次锁定应该以一个 (provider, feed, roundId, updatedAt) 元组而不是一个裸整数为关键,因为不同的提供者以不同的方式编号轮次。路由器可以选择一个锚点(例如,Chainlink 的特定 feed 的轮次),并要求每个适配器针对其自身提供者的 updatedAt ≤ anchor.updatedAt 的最新轮次进行报价;适配器必须回显 provider ID 和 updatedAt,以便路由器可以验证跨提供者对齐。如果锚点存在差距或该窗口没有数据,请使用确定性级联(下一个优先级提供者 → 最大陈旧窗口内最后接受的轮次 → 回滚)。这保留了活跃性,而没有无声漂移。最后,oracle 更新延迟 限制了你的实际刷新率:Monad 的 \~400–500 毫秒区块和 \~1 秒终局性在轮次存在后 快速结算,但如果 feed 更新(例如)每隔几秒钟更新一次,则轮次锁定的最佳执行仍然以 oracle 的节奏移动;设置严格的 maxStaleness,如果你需要在更新之间获得更平滑的行为,请考虑 TWAP[^3][^5]。
债券、退款和处罚(BondVault)
其次,gas 退款和处罚 依赖于 选择加入债券,而不是协议魔法。在 EVM 上,你不能强制被调用者支付你的 gas。相反,每个适配器将 MON 债券发布到 BondVault,并且 路由合约是唯一可以借记该债券的链上权威。该 vault 公开了一个受限制的 slashAndRefund(...) 可调用函数仅由路由器 ;路由器地址是不可变的(或受时间锁管理),并且每次削减都会发出证据事件(适配器、calldata 哈希、原因代码)。当路由器看到接口违规(格式错误的 payloads,通过委托链超过每次探测上限)或适配器获胜,然后未能在相同参数和 oracle 轮次下交付报价金额时,它会调用 vault 退还用户(抵消他们在 Monad 的 gas-limit 模型下预付的费用)并 削减适配器。这保持了注册无需许可,同时使适配器具有参与性。
sequenceDiagram
autonumber
participant U as 用户
participant R as 路由器
participant A as 适配器
participant V as BondVault
Note over A,V: 适配器注册并发布 MON 债券
U->>R: 提交 tx (候选者 ≤ K, 预先预算的 gas_limit)
R->>A: 在 gas 上限下探测
alt 接口违规或交付不足
R->>V: slashAndRefund(…)
V-->>U: MON 退款转移
else 获胜者是干净的
R->>A: 在获胜者上执行一次
A-->>U: tokenOut
endMonad 上的 Gas 预算(SDK 指导)
由于 Monad 按 limit 收费,因此 SDK 应将 gas 视为优化问题,而不是猜测。实际上,你预算:保守的每次探测上限(staticcall 较小,revert-quote 较大),获胜路径的最坏情况 G_swap,路由器开销和少量安全余量——然后显式设置该 limit。这在 Monad 的模型下将变量、对估算敏感的费用变成了可预测的费用[^2]。
gantt
title Gas 预算时间表(Monad 上的单笔交易)
dateFormat X
axisFormat %L
section 探测次数
探测次数 1 :0, 1
探测次数 2 :1, 1
… :2, 1
探测次数 K :3, 1
section 执行
获胜者交换 :4, 2
section 开销
簿记 :5, 1实用说明:时间戳、终局性窗口、JIT
一些 Monad 的优点在实践中很重要。 TIMESTAMP 操作码具有一秒的粒度;对于 \~400–500 毫秒的区块,两个或三个连续的区块可以共享相同的时间戳,因此不要完全基于每个区块的时间来判断公平性或惩罚。对于确切的并列,请使用共识随机性或 VRF,而不是挂钟时间。如果你的下游系统有繁重的链下义务,请考虑等待 已验证 状态根终局性,即使对于大多数 UX 来说,在 已投票 或 已完成 时安全更新也是可以的。请记住,Monad 的客户端包括一个用于热合约的本机代码 JIT——保持适配器代码路径精简和可预测,以便从中受益,同时保持精确的 EVM 语义^3。
从路由器到机制:为什么真实性是均衡
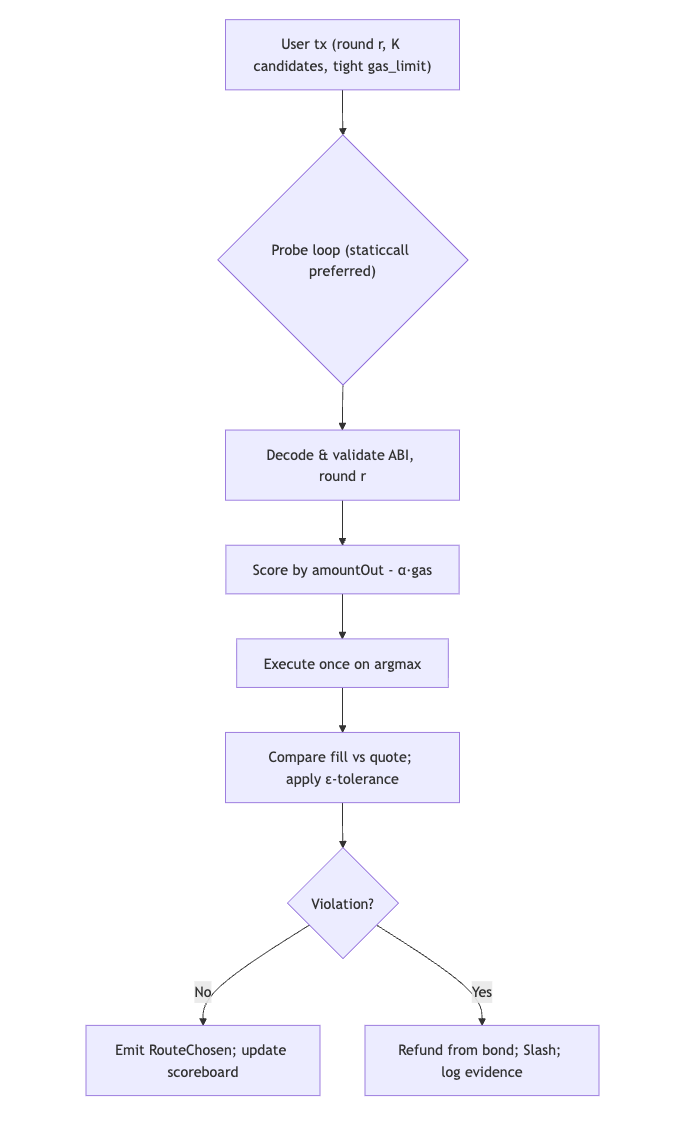
评分规则和选择
每笔交易都是一个小机制。适配器提交一份报告——他们为用户的输入和锁定的 oracle 轮次报价的 amountOut——并且路由器恰好选择一个适配器来执行。与 RFQ 交易台不同,此处的“付款”是在你的条款下清除交换的权利。为了使选择规则稳健,撒谎必须付出代价。轮次锁定的报价,严格的 ABI 卫生和 债券支持的处罚 创建了一种 适当评分 的风格:最佳响应是报告你实际将交付的内容。
形式上,对于输入 $x=(\text{tokenIn},\text{tokenOut},\text{amountIn},\text{deadline},\text{oracle round } r)$,适配器 $i$ 具有可实现的结果 $R_i(x)$ 并报告报价 $Q_i(x)$。路由器计算
$$ S_i(x)=Q_i(x)-\alpha\,\widehat{g}_i, $$
其中 $\widehat{g}_i$ 是观察到的探测 gas(受上限限制)。它选择 $i^\star\in\arg\max_i S_i(x)$ 并执行一次。
惩罚函数和真实的报告
BondVault 对选定的适配器执行惩罚
$$ \Pi_i(Q_i,R_i)=\lambda\,(Q_i-Ri)+ \;+\; \mu\,\mathbf{1}{\text{格式错误的 payload 或轮次不匹配}}, $$
因此已实现的效用是
$$ U_i = \text{maker 利润} \;-\; \Pi_i(Q_i,R_i)\;-\;c_i. $$
只要 $\lambda$ 超过夸大的最大增量利润,那么最佳策略就是 真实 的报告 $Q_i=R_i$。(有关 多提供者轮次同步、回退和延迟 的操作说明位于上面的轮次锁定部分。)
选择 $\alpha$:效率与探测约束
一个实际的细微差别:$\alpha$ 参数在 效率 和 探测约束 之间进行权衡。将 $\alpha$ 设置得太高,你可能会低估报价更高但计算成本更高的适配器;将 $\alpha$ 设置得太低,你将消除保持路径精简的任何动力。实际上,$\alpha$ 应该很小(决胜局),并且你可以使用 硬 gas 上限 和 记分板修剪 来补充它,因此选择仍然关于用户价值,而不是探测剧场。
Maker 端模型和轮次锁定的影响
在 maker 端,交付的金额可以看作是
$$ R_i(x)=f!\big(p_r,\;\theta_i,\;\ell_i(b_i)\big), $$
其中 $p_r$ 是第 $r$ 轮次的 oracle 价格,$\theta_i$ 是 AMM 参数,$b_i$ 是链上余额,$\ell_i$ 是库存倾斜(“精益”)函数,推动你朝着目标库存前进。链上求解意味着 $\ell_i$ 使用执行时的 实际 余额,而不是模拟时的猜测。轮次锁定消除了在更新的 tick 上报价并在较旧的 tick 上执行的楔形:如果 $p_r$ 是通用参考,则任何高估 $Q_i>R_i$ 都有正的惩罚概率 $\Pi_i>0$,而没有补偿利润。
Gas 经济学作为机会约束优化
Monad 的 gas 模型还改变了你对费用的看法。因为费用本质上是 $p\cdot L$(基本费用+小费乘以 limit),而不是 $p\cdot G$(乘以已实现的使用量),所以 SDK 应该通过 机会约束预算 设置 $L$:
$$ \min_{L}\; pL \quad \text{以…为条件}\quad \mathbb{P}(G>L)\le \delta, $$
其中 $G$ 是探测加执行 gas 总量,$\delta$ 是一个很小的公差。凭经验为获胜的交换路径拟合一个第 99 个百分位数,加上 $K$ 倍的保守探测上限和开销项,然后乘以一个小的安全系数。这就是为什么该设计 首选 staticcall 用于报价:它收紧了 $G$ 的尾部,这使你可以设置更小的 $L$,并在 Monad 的“按 limit 收费”规则下保持用户成本可预测。[Gas on Monad][M1]
学习和选择:安全土匪
在交易中,你的记分板只是 安全学习。定义已实现的每笔交易优势
$$ A{i,t}=R{i,t}-\alpha\,\widehat{g}_{i,t} $$
并保持具有置信界限的后验均值 $\hat A{i,t}$。在链下,你按 $\hat A{i,t}$ (加上置信项)预先对适配器进行排名,并将前 $K$ 个适配器交给链上循环。如果学习者是错误的,安全性不会中断:轮次锁定和债券处罚仍然强制执行真实性。学习改进了你询问谁,而不是如何安全地询问他们。
对抗策略和缓解措施
通常的攻击都会在本地关闭。 Gas 悲伤 被每次探测 gas 上限中和;燃烧完整的上限会降低你的分数并可能触发“过多的gas”处罚,但不会提高用户的费用(该费用由提交时的 limit 设置)。 Payload 悲伤 被严格的 ABI 解码阻止——仅限固定的选择器和紧凑编码;长字符串不会进入评分。 过度报价然后少交付 受短期惩罚 $\lambda(Q_i-Ri)+$ 的阻止。 共谋 由于透明性(事件记录报价和选定的带有轮次的路径)和确定性选择(仅对确切的结进行随机性,来源于共识随机性或 VRF)而变得不经济。
均衡特征和实用的调整
一个紧凑的均衡画面有所帮助:给定 $x,r$,每个适配器选择 $Q_i$ 知道 (i) 选择是通过 $$Q_i - \alpha\widehat{g}_i$$ 和 (ii) 任何正的短缺都会产生 $$\lambda(Q_i-Ri)+$$。 如果 $\Delta_i$ 是如实选择时的边际 maker 盈余。如果 $$\lambda \ge \overline{\Delta}_i$$ (从 $x$ 处的任何可行的错误报告中的最高盈余),那么最佳响应是 $Q_i=R_i$。在每个人都如实的情况下,选择减少为 $$\arg\max_i{R_i-\alpha\widehat{g}_i}$$,即给定探测预算的用户的福利最大化。两个小的调整保持均衡紧密:一个 epsilon-tolerance $(Q_i-Ri-\varepsilon)+$ 以避免惩罚灰尘/FO-T 费用,以及元数据中可选的 gas 声明 $\tilde g_i$(如果已实现的交换 gas 超过 $\tilde g_i+\tau$,则进行惩罚)以阻止“探测便宜,执行昂贵”的路径。
实现该机制的工程原语
所有激励支架都是使用你已经看到的相同部分实现的:staticcall 探测(以保持用户在 Monad 模型下紧凑的 gas limit),在需要精确路径奇偶校验的情况下使用“恢复报价”,使用低级 call{gas:cap} 并严格的 ABI 解码进行探测,具有小 $\alpha$ 的确定性分数,具有策略常数 $(\lambda,\mu,\varepsilon,\tau)$ 的债券 vault,以及用于可审计性的事件日志。图表没有改变;改变的是解释——每笔交易都是一个小的、完全在链上的竞赛,其中 真实报告是均衡,而 最佳执行是结果。
结论
这不是“一个尝试了一堆事情的路由器”。这是一个 机制合理 的原语,其均衡是诚实的报价和有竞争力的价格,其经济学与 Monad 的 按 limit 收费 gas 模型相匹配,并且其安全性不依赖于白名单或管理。它在 Monad 上是可行的,因为链为你提供 (i) 用于 tx 内探测的 EVM 语义,(ii) 具有串行结果的 并行/乐观执行,(iii) 亚秒级终局性, 和 (iv) 用于热路径的 JIT/本机编译器——所有这些都保留了熟悉的工具和 RPC。
参考文献
[^1]:Solidity 语言 — 外部调用、回滚行为、try/catch
[^2]:Monad:Gas 模型 — 按 gas limit 收费;1.5 亿个区块 / 3000 万个 tx;PGA 排序。
[^3]:Monad:部署摘要 — \~400–500 毫秒区块;在两个区块处完成;时间戳粒度注释;终局性阶段。
[^4]:Monad:并行执行 — 具有重新执行的乐观并行性、串行等效结果。
[^5]:Monad:Oracles — Monad 测试网上的提供者(Blocksense、Chainlink、Chronicle、Pyth 等)。
[^7]:Monad 的博客
- 原文链接: github.com/thogiti/thogi...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





