用 PeerDAS 和分布式 Blob 构建扩展以太坊
- sigmaprime
- 发布于 2024-09-26 13:23
- 阅读 846
本文介绍了以太坊在实现rollup-centric scaling roadmap中,为解决L2交易成本及数据gas价格问题而采用的Data Availability Sampling (DAS) 的一种迭代方案PeerDAS (EIP-7594)。
介绍
随着我们推进以太坊以 Rollup 为中心的扩展路线图,我们看到越来越多的 L2 出现,并且其中一些正朝着更成熟的状态发展(具有故障证明、更好的钱包用户体验等),现在有更多的用户在 L2 上进行交易。Blob 交易 (EIP-4844) 在 2024 年 3 月的 Dencun 升级中引入,降低了 L2 上的交易成本。随着使用量的增加,需要进一步的 L1 扩展以保持低数据 gas 价格。下面的截图显示了随时间推移的 L2 Rollup 活动与以太坊主网(L1)的对比数据。
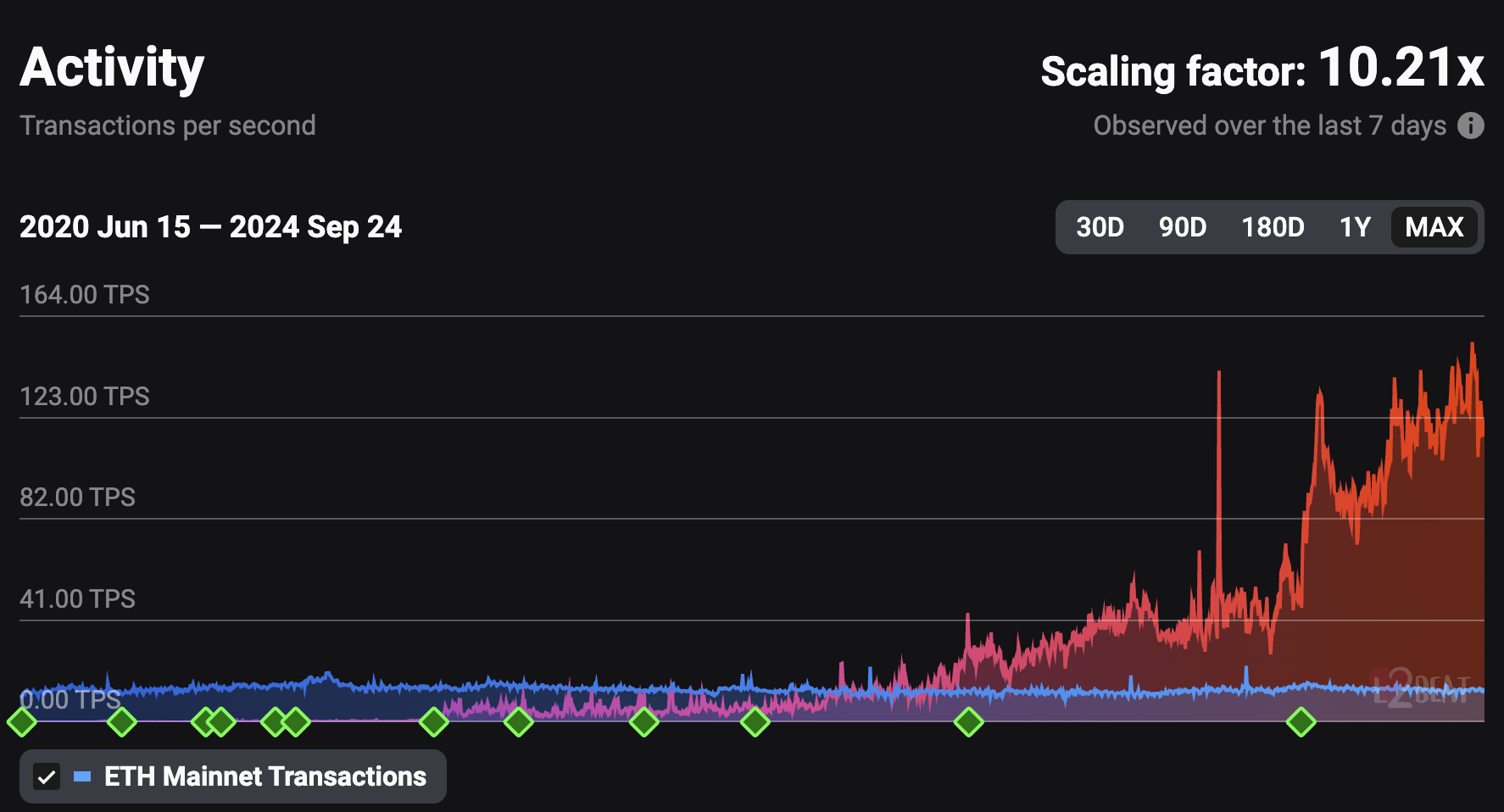 **来源:https://l2beat.com/scaling/activity_
**来源:https://l2beat.com/scaling/activity_
下一个以太坊升级(Pectra)预计将增加每个区块的最大 blob 数量,超过 6 个。虽然这可以通过要求更强大的硬件和更好的带宽来实现,但它可能会通过排挤那些无法承担进一步投资的家庭质押者来损害去中心化。我们的目标是确保当前的验证者,包括那些使用消费级硬件的验证者,在这些升级后能够继续平稳运行。
解决这个问题的方法是数据可用性采样 (DAS),它使网络能够验证数据可用性,而不会给单个节点带来过度的压力。每个完整节点下载并验证一小部分随机选择的数据,从而高度确定完整数据集的可用性。
在过去的几个月中,客户端团队一直在研究 PeerDAS (EIP-7594),这是 DAS 的第一个迭代版本。到目前为止,我们已经取得了重大进展,目前正在解决区块提议者的计算时间和带宽方面的挑战,我们的目标是在增加最大 blob 数量并交付到主网之前解决这些问题。
以下两个部分描述了挑战、优化,并假设你熟悉 EIP-4844。如果你主要对指标和对节点运营商的影响感兴趣,请随时跳到后面的 指标 或 对节点运营商的影响 部分。
目录
挑战和瓶颈
即使 PeerDAS 的当前设计能够在节点运行的大部分时间内降低带宽要求,但在区块提议期间,提议者必须执行密集的计算(KZG 单元格证明),并在证明截止时间(slot 开始后的 4 秒)之前尽快在网络中分发纠删码后的 blob 和证明。否则,他们很可能会错过区块或导致他们的区块被重新组织。本节将解释这些瓶颈。
证明计算
在配备 M1 Pro CPU 的 MacBook Pro 上,计算单个 blob 的 KZG 证明大约需要 200 毫秒。此计算可以在 blob 级别高度并行化。例如,如果有 4 个逻辑核心可用,则可以在相同的 200 毫秒内计算 4 个 blob 的证明。这对于少量 blob 来说效果很好,但当我们扩展到 16 个 blob 时,在 4 个逻辑核心上进行计算可能需要 200 * 16 / 4 = 800 ms。但是,由于节点很少空闲,因此可能需要 1 秒或更长时间。
带宽瓶颈
如果一个区块中有 16 个 blob,则提议者必须发送的数据量 最多 为 32MB(假设所有 16 个 blob 都被使用,并且我们有健康的对等节点数)。对于一般的消费者宽带来说,这可能需要 2-5 秒,这意味着他们很可能会错过区块提议。
128KB * 2 * 16 * 8 = ~32MB
- 128 KB 的 blob
- 纠删码将原始数据扩展 2 倍
- 16 个 blob
- Gossip 放大因子:3-8 倍(数据被发送到每个主题中的多个网格对等节点)
解决方案和可能的优化
几个提出的解决方案旨在解决上述问题:
- 节点从执行层 (EL) mempool 中获取 blob,并在 blob 通过 CL p2p Gossip 网络到达之前使该区块可用。
- 高容量节点计算从 EL 检索到的 blob 的单元格证明,并广播它们,以便它们更快地传播到网络。该技术也称为分布式 blob 构建。
- 在 blob 进入 EL mempool 时预先计算 blob 证明。
这些解决方案相互补充。我们已经在 Lighthouse 中实现了优化 (1) 和 (2),我们将在本文中重点分享我们的发现。我们的实现可以在这里找到:
从执行层 (EL) 获取 Blob
Blob 延迟一直是主网上观察到的问题,如下图所示(运行最新的 Lighthouse v5.3.0),其中区块和 blob 的到达时间经常显示 blob 延迟飙升至 3 秒以上。这些延迟的传播很可能会导致错过或孤立区块。
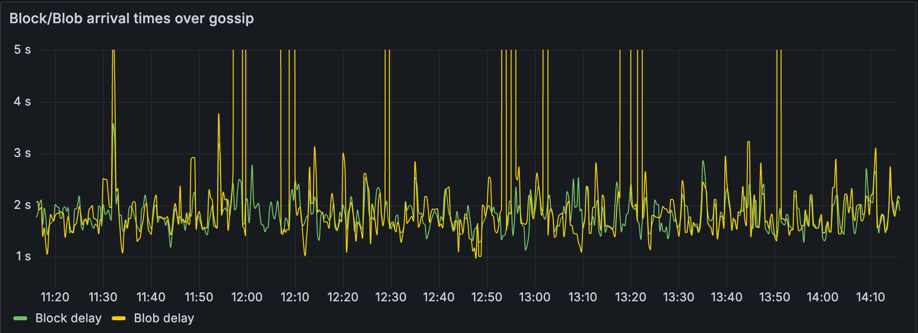
为了解决这个问题,我们引入了一种优化,通过 JSON-RPC 从执行层 (EL) 获取 blob。如果一个 blob 已经在公共 mempool 中被看到,那么就没有必要等待它通过 P2P Gossip 到达。此优化使用一个新的 JSON-RPC 方法 (engine_getBlobsV1),它允许共识客户端 (CL) 快速从 EL 的 blob 池中检索 blob。
此技术也适用于 PeerDAS,在这种情况下,节点可以认为一个区块可用并对其进行证明,而无需等待所有数据列*通过 P2P Gossip 到达。结果是减少了区块导入延迟,并降低了由于 blob 传播延迟而导致错过区块的可能性。
*注意:在 PeerDAS 中,每个 blob 都经过纠删码以实现冗余和可恢复性,并分解为更小的片段(单元格或数据列)以进行采样和分发。
但是,这种方法不包括来自私有 mempool 的 blob 交易。包含私有 blob 交易的区块构建者必须确保及时计算和广播 blob 和证明。
分布式 Blob 构建
此优化旨在通过将证明计算和传播工作负载分发给更多节点(尤其是具有更高带宽的更强大的节点)来解决区块提议者的计算和带宽瓶颈。在 PeerDAS 的情况下,这些通常是负责保管和采样所有数据列的超级节点(通过实验性的 Lighthouse BN 标志 --subscribe-all-data-column-subnets)。
这些超级节点可以从 EL 检索 blob,可以在 slot 开始之前(预计算)也可以在从对等节点接收到区块之后(参见优化 (1))。这意味着区块快速传播至关重要,这可以通过以下方式进行优化:
- 在同时计算 blob 证明时首先发布该区块。
- 为区块头引入一个新的 Gossip 主题,区块头通常比区块小得多,从而允许带有 KZG 承诺的区块头更快地传播(Dankrad 在 这篇文章 中提出)。
一旦超级节点拥有 blob,它们就可以计算证明并代表提议者将其广播到网络。凭借更好的硬件和带宽,超级节点通常可以更有效地执行此任务。指标将在以下部分中分享。
超级节点的逐步发布
虽然假设超级节点比完整节点具有更多的可用带宽,但我们仍然需要有效地利用它,以使超级节点的角色易于访问。
在超级节点的简单实现中,每个超级节点都会重建和发布 所有 数据列,从而以增加带宽和在网络中发送重复项的成本来实现非常快的发布。在我们对优化分支的初步测试中,我们看到超级节点出站带宽平均接近每个区块提议 32MB,并考虑了减少这种情况的方法。我们称我们提出的优化为 逐步发布,它的工作方式如下:
- 在每个节点上随机对数据列进行混排。
- 将混排后的数据列分成
N个块(我们测试了N = 4)。 - 对于每个块,发布任何尚未在 P2P 网络上看到的数据列,然后等待
DELAY毫秒,然后再发布下一个块。
我们使用等于 200 毫秒的 DELAY 进行了测试,这意味着对于 N = 4,一个节点最多花费 600 毫秒来发布其第 4 个块。在具有多个超级节点的网络中,许多后面的块已经被网络完全知晓,根本不需要发布。随机化意味着每个超级节点都承担传播不同列的责任,并且完整列集仍然可能快速可用。
我们希望其他客户端团队(或规范)采用此优化,并帮助我们尝试不同的 N 和 DELAY 值。通过找到正确的参数集,我们有可能进一步降低超级节点的带宽要求。
测试设置
为了评估 PeerDAS 的有效性和上面讨论的优化,以及使用增加的 blob 数量 16 交付 PeerDAS 的可行性,我们在更大的网络上测试了我们的实现。 100 个节点的网络提供了更接近于实时环境的带宽指标,但仍存在一些限制:
- Gossip 消息中的延迟将低于拥有数千个节点的实时网络,在实时网络中,消息可能需要多次跳转才能到达所有对等节点。
- 此测试中的变化较少,因为所有节点都运行相同的软件版本,并且位于相同的地理区域。
- 该测试没有考虑远程同步期间的带宽使用情况,因为所有节点在测试期间都保持同步。
尽管如此,由于对等节点数与主网节点相当,我们预计会看到同样具有代表性的带宽结果。
为了进行此实验并保持设置的简单性和一致性:
- 我们使用 Kurtosis 在 Kubernetes 集群中运行测试。
- 我们在同一区域使用相同的机器类型。
使用的客户端软件
Lighthouse
我们使用两种不同的 Lighthouse 配置运行了两个测试网络:一个经过优化,另一个是基线。
- 这个分支 包含 优化 的实现,具有分布式 blob 构建、从 EL 获取 blob 和逐步发布优化。
- 这个分支 包含用于 基线 比较的代码。它类似于撰写本文时的
unstable分支,进行了一些调整以增加 blob 计数并修复 Kurtosis 下 discv5 的问题。 - 当前优化实现的已知问题:
Reth
- 这个 fork 包含
getBlobsV1端点实现,并将 blob 计数增加到 16 个 blob。 - 在撰写本文时,多个执行客户端已经实现了这个端点并进行了合并,包括 Reth、Nethermind 和 Besu。
网络参数
MAX_BLOBS_PER_BLOCK:16NUMBER_OF_COLUMNS:128DATA_COLUMN_SIDECAR_SUBNET_COUNT:128CUSTODY_REQUIREMENT:8*
* CUSTODY_REQUIREMENT 从当前规范值 4 增加,以考虑最小的 验证器保管 和 子网采样。
网络结构
网络的设计使得:
- 每个 Lighthouse 节点都有 99 个对等节点,与实时网络相当。
- 使用不同数量的 CPU 核心,使我们能够分析各个计算时间。
- 一些节点配置为仅发布区块,模拟无法在证明截止时间之前计算和发布 blob。
| 节点类型 | 节点数量 | 逻辑 CPU 核心数 | 提议者发布区块 + 数据列 |
|---|---|---|---|
| 超级节点 | 10 | 16 | 区块和所有数据列 |
| 超级节点 | 10 | 8 | 区块和所有数据列 |
| 完整节点 | 20 | 8 | 区块和所有数据列 |
| 完整节点 | 20 | 4 | 区块和所有数据列 |
| 完整节点 | 10 | 8 | 区块和 50% 的数据列 |
| 完整节点 | 10 | 4 | 区块和 50% 的数据列 |
| 完整节点 | 10 | 8 | 仅区块 |
| 完整节点 | 10 | 4 | 仅区块 |
可以在 此处 找到使用的 Kurtosis 配置。
为简洁起见,我们在下面展示了 5 类节点的指标:
- 具有 16 个核心的超级节点 (16C)
- 具有 8 个核心的完整节点 (8C)
- 发布 50% 数据列的具有 8 个核心的完整节点
- 发布 50% 数据列的具有 4 个核心的完整节点
- 不发布任何数据列的具有 4 个核心的完整节点
其他类节点的影响仍然间接地体现在我们所选类的指标中。我们发现结果在节点类型、发布百分比和核心数方面通常相似,因此所选的 5 个足以进行总结。将来,我们可能会使用较少的节点类型来简化分析。
指标
我们在下面展示了运行 unstable 变体的 基线 测试网和包含获取 blob、去中心化 blob 构建和逐步发布的 优化 测试网的指标。
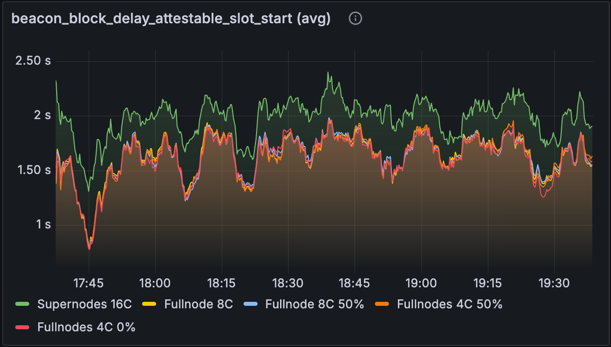
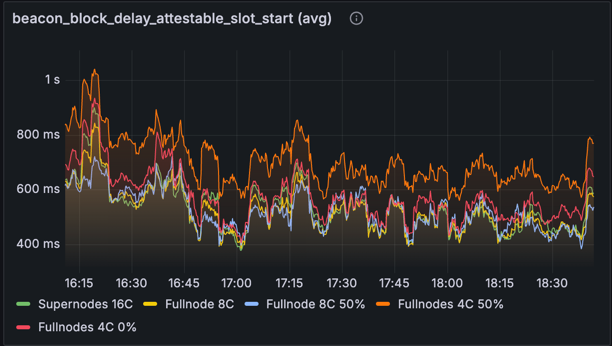
区块可证明时间
指标:beacon_block_delay_attestable_slot_start (平均)
| 基线 | 优化 |
|---|---|
 |
 |
上面的图表显示了区块变为 可证明 之前从 slot 开始的 平均 延迟(越低越好)。理想情况下,我们希望所有区块在 slot 开始后的 4 秒内都是可证明的,并且我们从该图表中看到,这对于所有节点类型来说平均都是正确的。
在基线网络中,超级节点的性能更差,平均慢了大约 500 毫秒 - 这可能是由于数据列重建的未优化方法,它在每个 slot 中执行,并且仅在重建 之后 才使区块可用。 这已经优化为使重建变为非阻塞,从而允许在节点从 Gossip 网络收到所有数据列时立即让区块变为可证明(超级节点需要并保管所有数据列)。但是,你会注意到优化版本中的不同趋势,因为由于可以从 EL blob 获得区块,因此触发重建的次数较少。
在优化网络中,我们看到所有节点类型的显着改进,因为一旦从 EL 检索到所有 blob,或者通过来自分布式 blob 构建的 Gossip 接收到 blob,区块就会变为可证明。 4 核节点比 8 核和 16 核节点慢一点,这是由于其他工作导致更高的 CPU 争用所致。我们无法解释为什么“完整节点 4C 0%”类别的性能优于其 50% 的对应类别,因为发布不太可能对 CPU 造成压力。
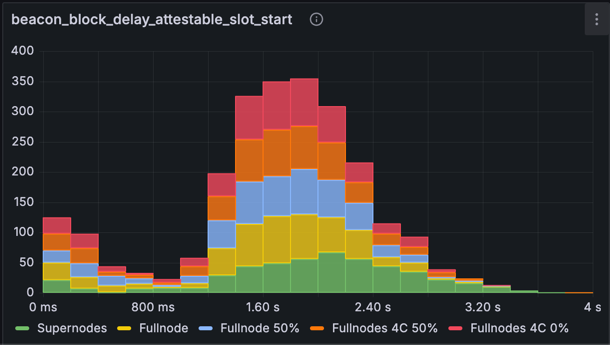
指标:beacon_block_delay_attestable_slot_start(没有基于时间的平均)
| 基线 | 优化 |
|---|---|
 |
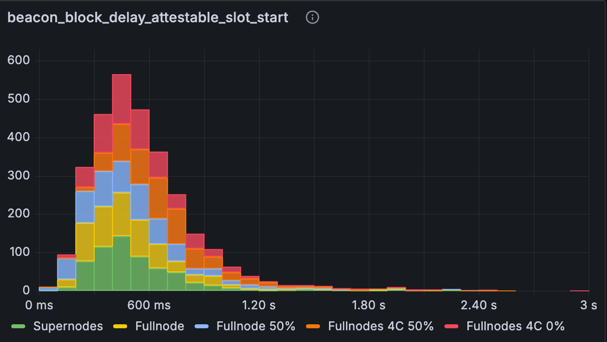 |
上面的直方图显示了没有基于时间的平均的可证明延迟。观察基线数字,我们看到超过 3 秒的更重的尾部和接近 4 秒的少量值 - 接近证明截止时间。优化后,结果显示出显着改善:虽然仍然存在延伸到 3 秒的尾部,但所有区块都安全地保持在 4 秒的证明截止时间之内。主网规模的网络可能会有更多的交易和证明,这将增加一些额外的处理时间,但可证明时间很可能大部分时间都保持在 4 秒的阈值以下。我们想到的一些未来优化也可能会有所帮助。
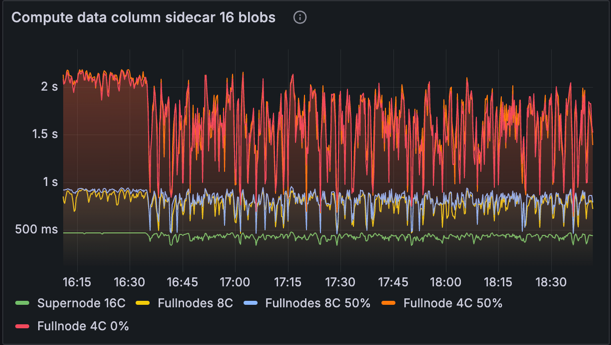
证明计算时间
| 时序图 | 平均 |
|---|---|
 |
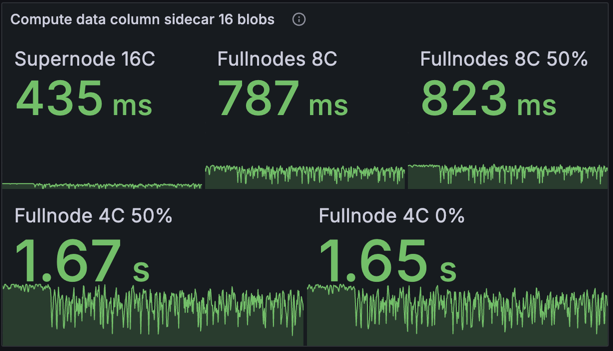 |
此指标跟踪计算数据列侧链所花费的时间:包括单元格、单元格证明和包含证明。此计算是并行化的,因此我们观察到具有更多核心的机器的性能优于较低规范的机器。此图表显示了超级节点对网络的重要性,因为它们能够快速计算证明并开始发布它们。在提议者的节点没有足够的资源来快速计算数据列侧链的情况下,超级节点可以使用 EL mempool 中的 blob 来计算它们并开始传播它们。基线网络和优化网络之间没有差异,因为没有对证明计算进行优化。
数据列 Gossip 时间
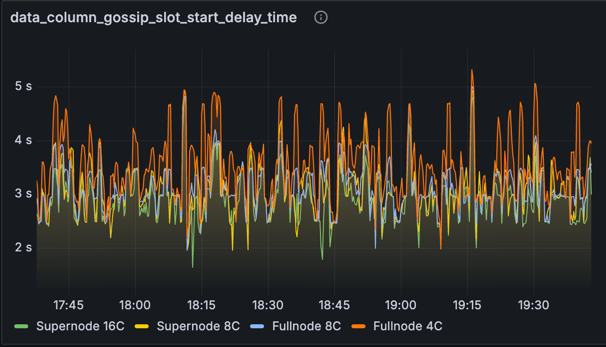
指标:data_column_gossip_slot_start_delay_time
| 基线 | 优化 |
|---|---|
 |
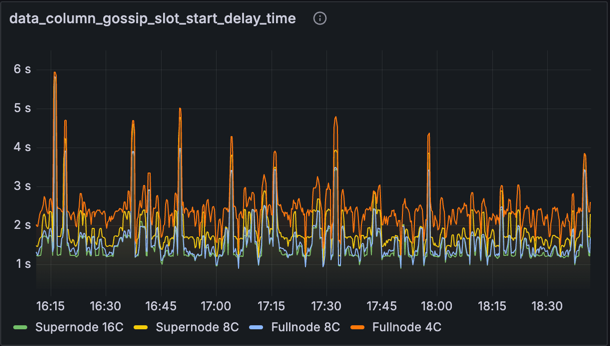 |
此图表显示了相对于发布数据列侧链的 slot 开始时接收到数据列侧链的时间。有趣的是,我们在这里看到一些超过 4 秒的峰值,尤其是在完整节点上。尽管存在这些峰值,但这些 slot 中的区块仍然在 4 秒之前变为可证明的(根据先前关于可证明延迟的图表)。我们怀疑原因是节点可以通过处理 EL mempool 中的 blob 在 4 秒之前将区块标记为可用和可证明。这证明了 mempool 方法的优势:它可以消除数据可用性方面原本会非常严重的延迟。但是,这种优势也是一个潜在的弱点,因为它意味着 mempool 中 blob 的可用性差可能会导致区块被延迟处理并随后被重新组织。在未来的测试中,我们希望纳入一些来自 mempool 之外的“私有”blob 交易,以确保网络能够包含它们而不会引起数据可用性问题。
出站数据列带宽
出站带宽是使用 Lighthouse 的 Gossipsub 协议发送给对等节点的与 blob 相关的数据量。
下面的第一组图表显示了在任何给定类别中,节点在 12 秒内发送的数据的 最大 量。标题数字是随时间推移的最大值(最大值的最大值)。
下面的第二组图表显示了在任何给定类别中,所有节点在 12 秒内发送的数据的 平均 量。标题数字是随时间推移的平均值(平均值的平均值)。
请注意,测试中的大多数区块包含 16 个 blob,因此这里的数字远高于实时网络中的正常情况,考虑到 blob 目标计数为 8,可能会高出大约 2 倍。
黄色 图表来自基线网络,红色 图表来自我们的优化网络。
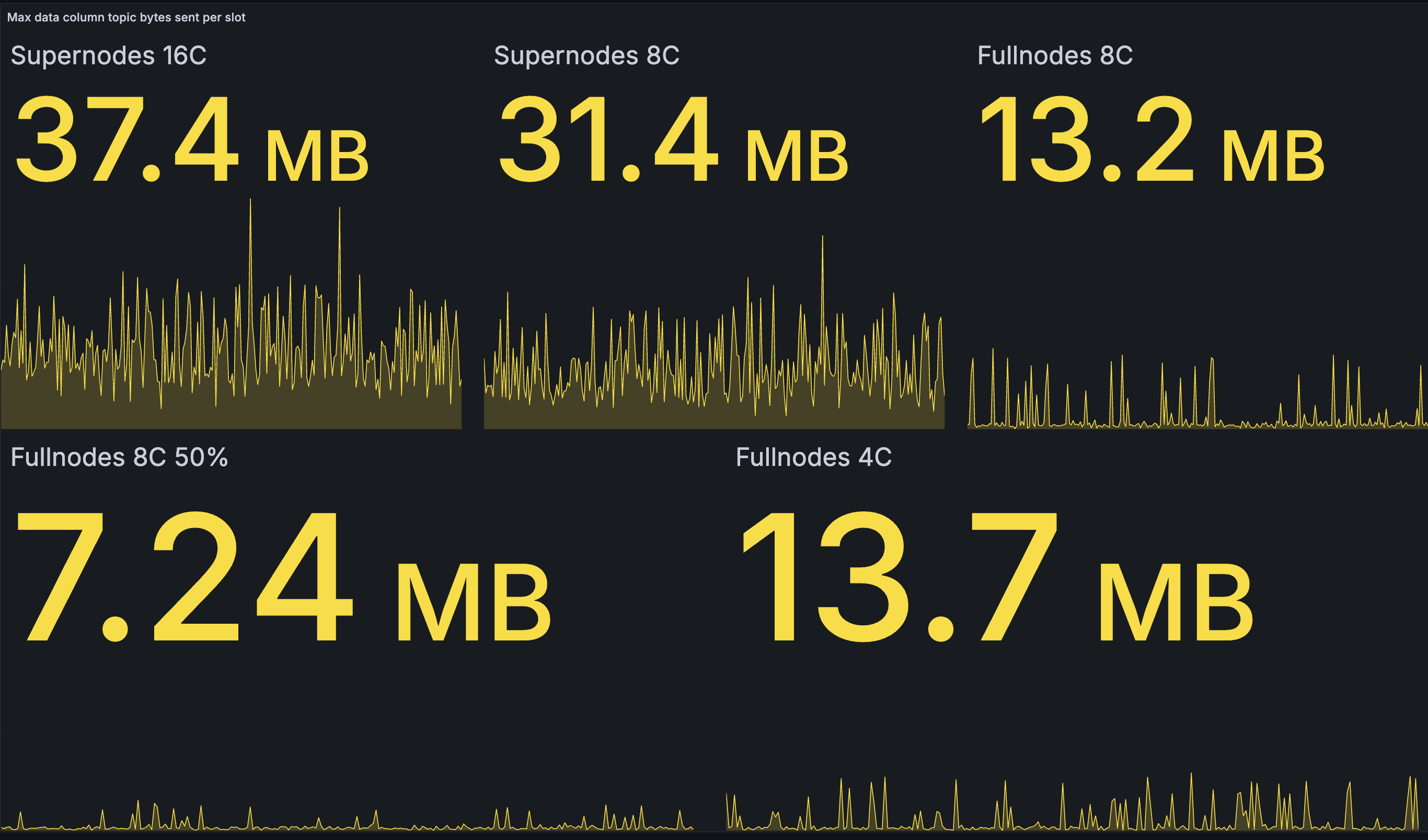
每个 slot 的出站数据列带宽(最大):
| 基线 | 优化 |
|---|---|
 |
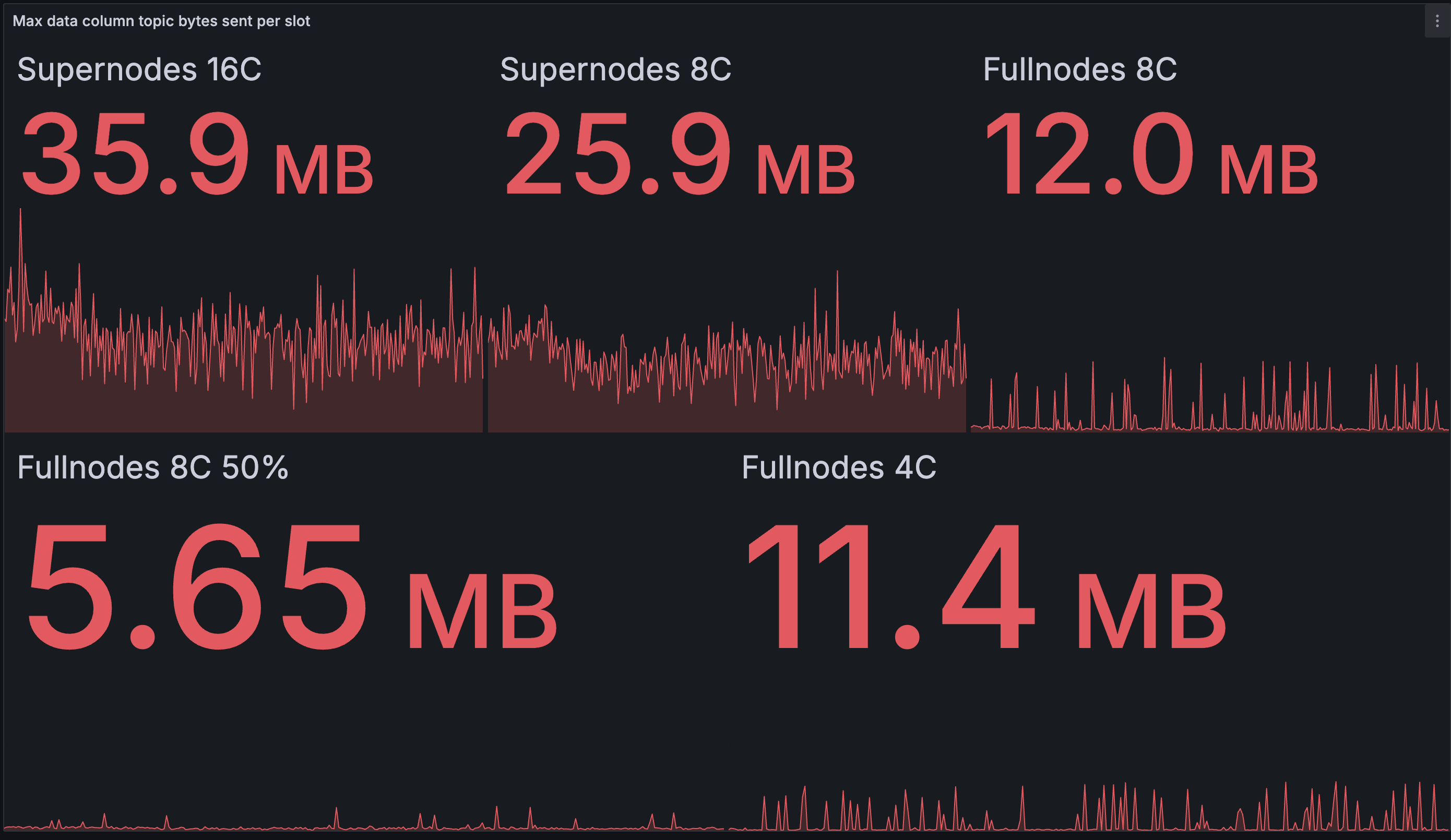 |
与基线测试网相比,我们看到的出站带宽仅略有减少。最大的受益者是 8 核超级节点,节省了 17.5%,以及发布 50% 的 8 核完整节点,节省了 22%。由于测试后发现的次优性,完整节点的峰值不幸地高于必要值:完整节点似乎没有在发布之前检查数据列是否已知。但是,我们对此并不百分之百确定,并将进一步调查。
在基线网络中,超级节点有时最终会发布一个区块 50% 的数据列。最快的节点将在接收 50% 的数据列后完成重建,然后开始将剩余 50% 的重建列发送到网络。较慢的 8 核超级节点完成重建的平均时间比 16 核超级节点晚一点,并且此时要发布的(尚未在 Gossip 上看到的)新颖列更少,因此它们最终发布的会少一点。
在优化网络中,发布的数据量仍然与核心数相关,因为更快的节点仍然会更早开始发布 - 在更多列是新颖列的时候。但是,我们怀疑数据量取决于超级节点的数量和逐步发布算法的配置。在我们当前的测试中,4 批次被 200 毫秒的等待时间分隔开,似乎超级节点在最坏的情况下仍在发布非常相似的数据量,这可能天真地对应于 50% 的数据列(2 批次)。延长批次间隔或缩小批次大小可能是将来减少这种情况的一种方法。
下面我们看一下 平均 出站带宽。
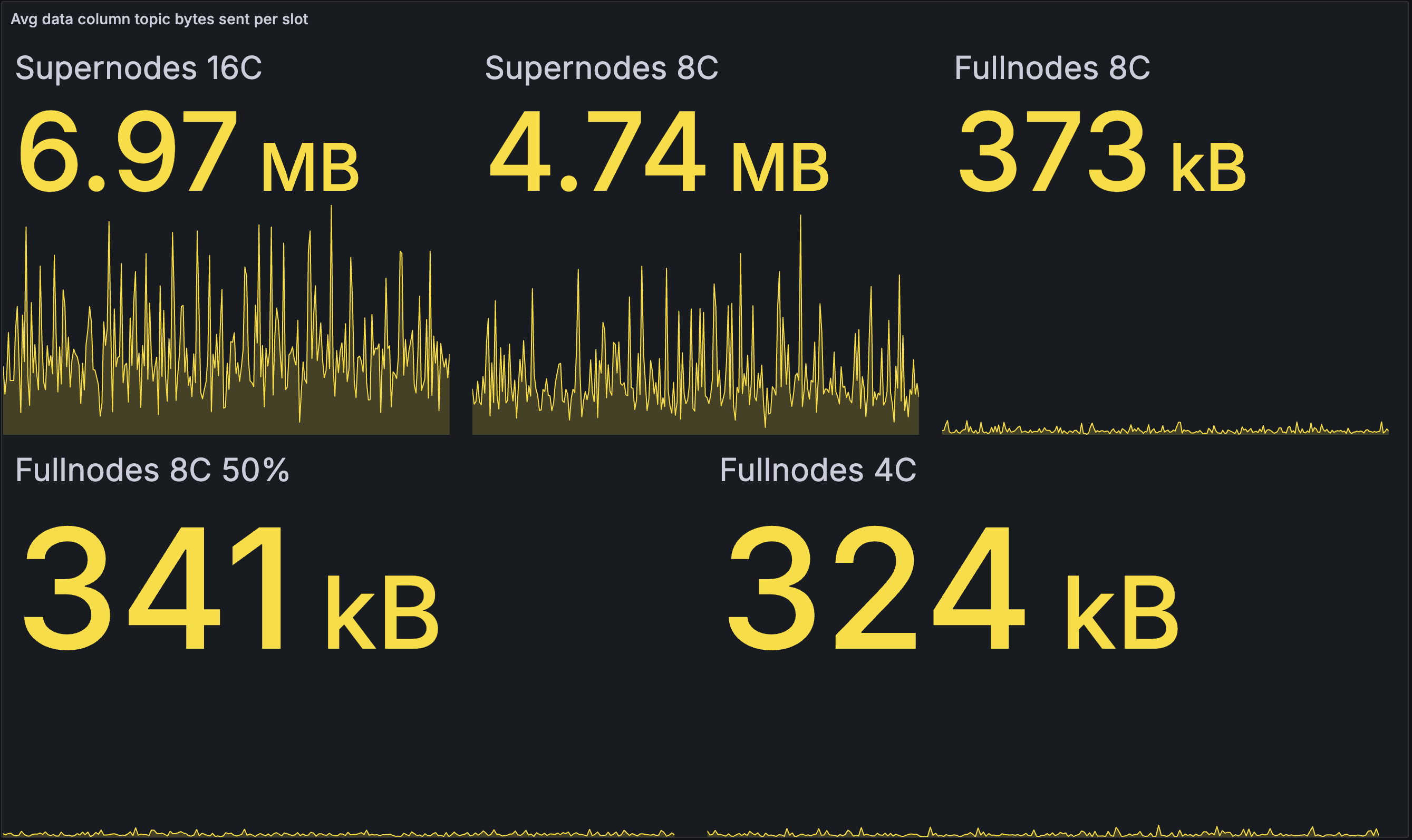
每个 slot 的出站数据列带宽(平均):
| 基线 | 优化 |
|---|---|
 |
 |
在这里,我们看到优化后的网络平均给超级节点带来了更高的负载,并减少了完整节点的负载。这是有道理的,因为超级节点能够更快地将 blob 传播到完整节点,从而减少了完整节点之间的 Gossip 需求。如上所述,通过调整逐步发布的参数,可以进一步减少超级节点的带宽。
请注意,平均值还隐藏了来自完整节点区块发布的峰值 —— 它们可以通过上面的最大数据更好地表示。
入站数据列带宽
入站数据列带宽是使用 Lighthouse 的 Gossipsub 协议从对等节点接收到的与 blob 相关的数据量。
下面的图表显示了在每个类别中,所有节点在 12 秒内接收到的数据的 平均 量。标题数字是随时间推移的平均值(平均值的平均值)。
黄色 图表来自基线网络,红色 图表来自我们的优化网络。
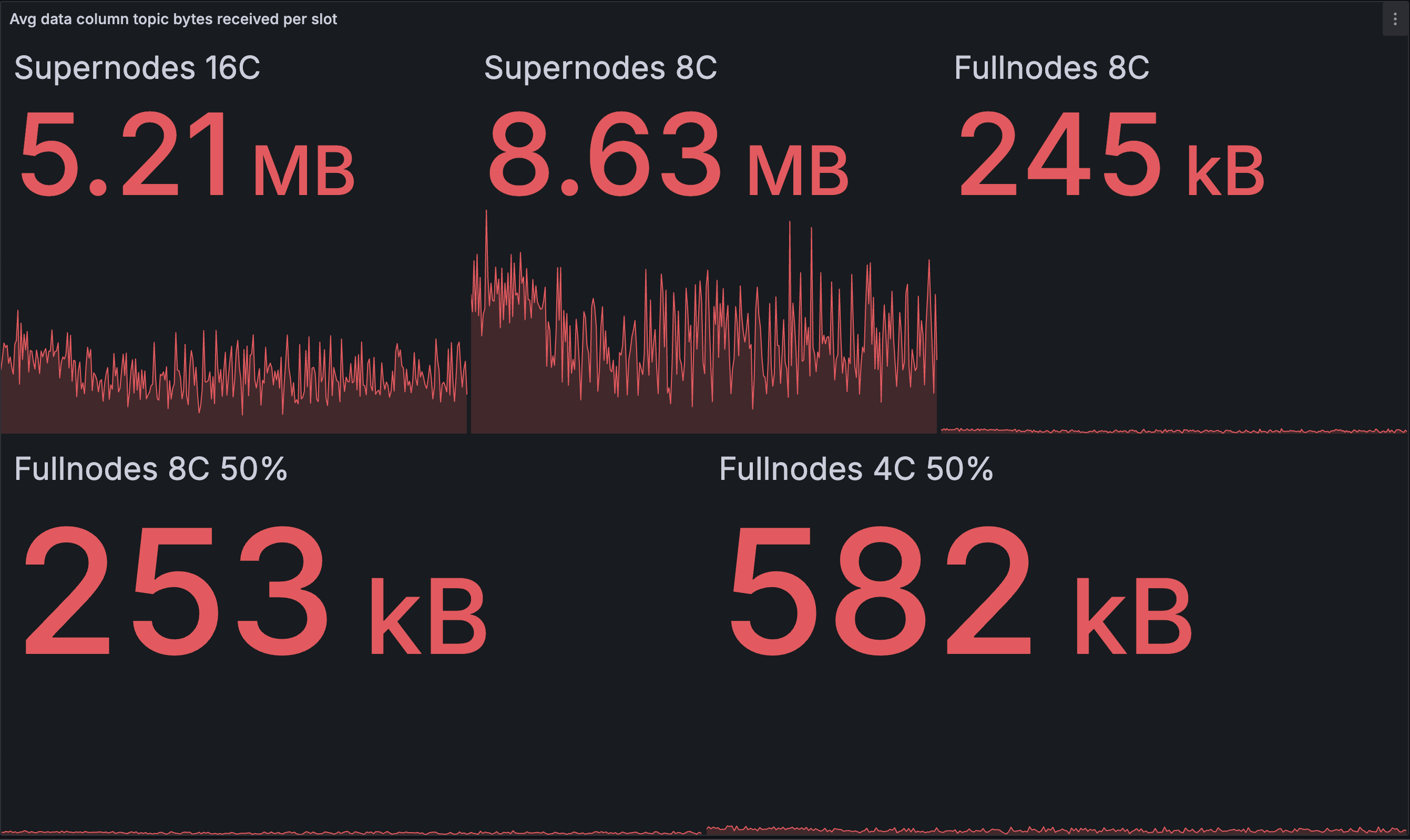
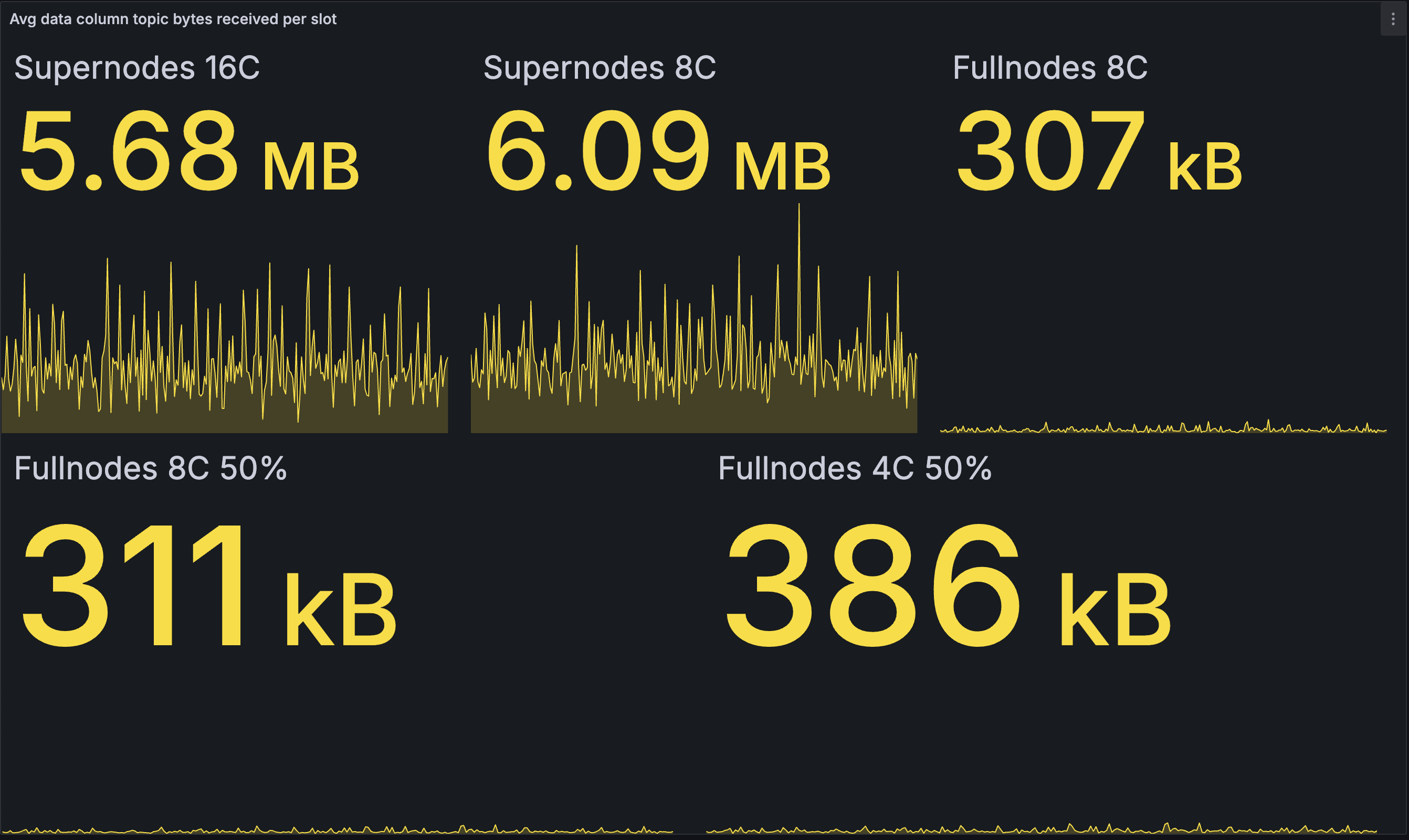
每个 slot 的入站数据列带宽(平均)
| 基线 | 优化 |
|---|---|
 |
|
在超级节点中,我们看到一个有趣的对比:与基线相比,16 核节点下载的略微 少一些,而 8 核节点下载的略微 多一些。这表明两种不同的效果相互作用。我们假设第一种效果可能是优化网络中的快速超级节点在完成重建之前从 EL 接收到完整的 blob 集,并更早地开始数据列发布,从而导致发布更多数据而下载更少数据。这与超级节点出站带宽的增加也是一致的。
我们怀疑第二种效果是在优化网络中发布(和下载)了更多重复数据列。在基线网络中,超级节点仅在完成重建后才开始发布,因此较慢的超级节点最终会自我限制其发布。在优化网络中,假设从 EL 获取 blob 的时间与核心数没有很强的相关性,所有超级节点大约在同一时间开始发布。因此,几乎同时发布了更多重复消息,并且由于这些消息被超级节点(超级节点和完整节点)的对等节点下载而造成了一些浪费。
我们希望未来的测试能够证明或推翻我们的假设,因为我们发现很难从我们的数据中提取这些理论,并且无法使用此初始实验来验证它们。
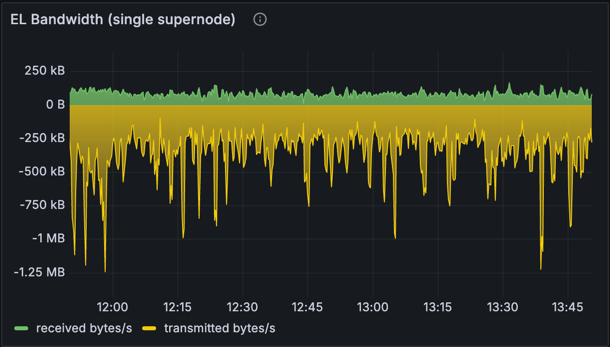
执行客户端 (EL) 带宽
| 单个节点的 EL 带宽 | EL 带宽平均值 |
|---|---|
 |
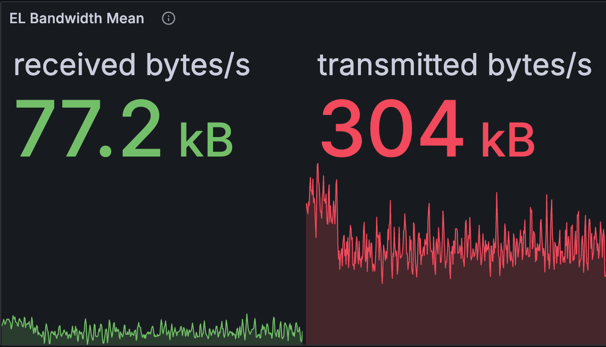 |
上面的图表显示了 EL(Reth)的入站和出站带宽。请注意,此处捕获的出站带宽包括来自 CL 和 EL 交互的数据(JSON-RPC 调用,例如 getBlobsV1 和 getPayloadV3),并不能准确反映 CL 和 EL 位于同一台机器上的典型设置中的出站带宽。
但是,我们可以计算出出站带宽的粗略估计:
- 总出站计算为 304 KB/s * 12 秒 = 每个 slot 3.65 MB。
- 调整
getBlobsV1的使用情况,即每个 blob 128 KB * 16 = 每个 slot 约 2 MB,我们得到每个 slot 约 1.48 MB 或 126 KB/s 用于出站带宽。
实际上,由于费用结构,我们不太可能一直超过 8 的目标 blob 计数。即使我们以 16 个 blob 运行,计算出的 EL 带宽仍然是可管理的。
对节点运营商的影响
PeerDAS 网络参数旨在最大限度地减少对网络运营商的影响,并保持与 4844 相同的带宽数(请参阅 Francesco 的 ethresearch 帖子 此处)。因此,在正常运行期间,我们预计完整节点的带宽与今天的主网类似。在区块提议期间,我们预计由于 blob 传播,CL 出站带宽会激增,并且我们努力确保增加 blob 计数与 PeerDAS 不会使家庭质押变得不可行 - 更多信息如下。
跨节点类型的带宽使用比较
下表显示了此测试中的平均带宽结果:
| 节点类型 | CL 入站 | CL 出站 | 总入站(包括 EL*) | 总出站(包括 EL*) |
|---|---|---|---|---|
| 完整节点 | 356 KB/s | 241 KB/s | 433.2 KB/s | 367 KB/s |
| 超级节点 | 1.12 MB/s | 1.07 MB/s | 1.2 MB/s | 1.2 MB/s |
*有关 EL 带宽数,请参阅上面的部分。
由于超级节点采样和存储的数据列数量(入站带宽)以及它们通过分布式 blob 构建帮助传播的数据列数量(出站带宽),因此超级节点在 CL 端消耗的带宽要高得多。 EL 数在两种节点类型之间相似,并且相对于 CL 而言较低。
在区块提议期间,我们看到在 30 秒内高达 1 MB/s 的峰值,或者所有节点每个 slot 约 12 MB。但是,一旦我们优化了数据列发布以消除重复数据,这种情况可能会减少。
存储要求
我们没有在测试中查看实际的存储使用情况,但是可以根据参数 MIN_EPOCHS_FOR_BLOB_SIDECARS_REQUESTS 或 MIN_EPOCHS_FOR_DATA_COLUMN_SIDECARS_REQUESTS 进行计算,该参数表示每个节点保持 blob 数据的周期数,目前设置为 4096,或大约 18 天。
| 与 Deneb 相比,节点存储所有 blob: | 节点类型 | Deneb 目标值 (3) | Deneb 最大值 (6) | PeerDAS 目标 blob 数 = 8 | PeerDAS 最大 blob 数 = 16 |
|---|---|---|---|---|---|
| Fullnode* | 50.33 GB | 100.66 GB | 16.78 GB | 33.55 GB | |
| Supernode | 50.33 GB | 100.66 GB | 268.44 GB | 536.87 GB |
- *基于 custody 列 = 8 计算(对于附加了 1-8 个验证器的全节点)
- **请注意,在实践中,由于 blob 费用计算方式的原因,无法始终如一地达到每个区块的最大 blob 数,但我们在此处包含了理论上的最大数量以供参考。
由于全节点仅存储 blob 数据的子集(128 列中的 8 列),因此全节点的存储需求已从 50.33 GB 减少到 16.78 GB,尽管最大 blob 计数增加到 16。
构建本地区块的家庭 Staker
基于当前 staking 的最低硬件要求(四核 CPU)(来自 EthStaker),一个包含 16 个 blob 的区块平均需要一个四核 CPU 1-2 秒来计算证明,并且在澳大利亚,通过平均消费者级别的互联网(25-50 Mbps)传播到网络可能需要更长时间。
因此,这些提议者将主要依赖分布式 blob 构建和其他节点来帮助计算并在网络上传播 blob。CL 客户端必须确保 签名的信标块 尽快分发,以便其他节点可以开始构建 cell 证明。从我们的测试来看,我们使用了 4 个逻辑核心的机器来代表这些节点,并且它们能够以与其他节点类型相同的成功率生成包含 16 个 blob 的区块。因此,即使我们将 blob 计数增加到 16 个并使用 PeerDAS,我们也不希望提高家庭 staker 的硬件要求,并且今天的硬件应该足够了。 预计最低硬件要求将在长期内提高,尽管我们希望这种情况随着技术的进步随着时间的推移自然而平稳地发生。
使用 MEV 中继的家庭 Staker
对于使用 MEV 中继的家庭 staker,blob 证明构建和传播工作外包给外部区块构建者,因此,假设外部区块构建者具有足够的硬件和带宽来传播区块和 blob,则对这些用户的影响应最小。如果区块中包含的所有 blob 交易都来自公共 mempool,他们还可以从分布式 blob 构建中受益。我们预计这些 staker 不需要升级他们当前的硬件或带宽。
专业节点运营商
通过 验证器 custody,custody 数据列的数量随着附加验证器的 ETH 余额的增长而增加 - 每 32 ETH 额外增加 1 个 custody 列。拥有超过 128 个验证器的节点需要作为超级节点运行,custody 所有列。由于附加到其节点的验证器数量,专业的节点运营商可能会运行超级节点,并且 CPU 和带宽使用量会增加。这些验证器节点具有更高的 stake,因此预计会验证更多数据以确保网络的安全。
大型节点运营商的硬件要求目前尚不清楚,因为它们取决于我们最终实施的优化。 虽然可能需要也可能不需要硬件升级,但我们预计由于接收和发送的数据列的数量增加,带宽会增加。前面展示的指标反映了这一点,我们将继续努力使 Lighthouse 尽可能高效,包括在可行的情况下减少带宽使用。
未来的工作和优化
这篇文章的目标是分享我们在 PeerDAS 上的进展以及我们在解决提议者带宽问题上的努力,同时展示扩展到 16 个 blob 而不牺牲网络去中心化的可能性。
我们已经发现了许多潜在的优化方法,并且我们预计在 PeerDAS 发布之前会有更多的改进。一些未来的工作和优化包括:
- Peer 采样:当前版本的 PeerDAS 使用“子网采样”,节点订阅 gossip 主题以执行采样。与“Peer 采样”相比,此方法需要更多带宽,在“Peer 采样”中,节点将 RPC 请求发送到 peer 以检索数据列。gossip 协议消耗更多带宽,因为消息同时广播到许多 peer。实施 Peer 采样将显着减少带宽使用并实现进一步的扩展。
- KZG 库优化:在测试时,在单个线程上计算每个 blob 的 cell 证明需要 200 毫秒。在撰写本文时,证明创建时间已缩短至 150 毫秒(截至
rust-eth-kzgv0.5.2)。此改进允许数据列更快地通过 gossip 网络传播。 - 预先计算证明:有一个 提案 预先计算 cell 证明并通过 gossip 网络传播它们,允许区块构建者在 slot 开始时发布他们的区块和 blob。这可以通过消除在 slot 开始时进行证明计算的需要来节省大约 150 毫秒。
- 跨所有节点进行工作负载分配的分布式 Blob 构建:当前形式的分布式 blob 构建要求所有 blob 都存在,然后节点才能计算和广播 cell 和证明。这是因为 blob 数据作为
DataColumn而不是Cell通过 gossip 网络传输。因此,我们可以扩展到的 blob 数量大致受到超级节点拥有的 CPU 数量的限制。例如,具有 16 个逻辑 CPU 的节点可以并行生成 16 个 blob 的证明,因此实现最小的计算时间(~150 毫秒)。为了轻松扩展到 16 个以上的 blob,更有效的方法是在更多节点上分配证明构建工作负载,例如,每个节点可以为 3 个 blob 构建和发布证明。这种方法将减少对超级节点的严重依赖,并减轻它们的压力。
结论
这篇文章详细介绍了我们在 PeerDAS 上的进展以及我们在客户端和研究团队中为扩展以太坊数据可用性层所做的集体努力。提议的优化 - 例如从 EL 获取 blob 和分配 blob 构建 - 已经显示出明显的好处:
- 减少了区块导入延迟,从而使区块可以更快地进行证明。
- 改进了 blob 传播,使网络更具弹性。
- 在不影响去中心化的情况下进行扩展,确保家庭 staker 可以继续使用消费者级硬件参与。
在整个过程中,我们获得了宝贵的见解,并发现了进一步优化和改进的机会。我们很高兴继续在此基础上进行构建,并为以太坊带来更可持续的扩展。
感谢你的阅读,希望你觉得有趣! :)
特别感谢 Lion 和 Pawan 审查这项工作,感谢 Age 和 Anton 帮助进行测试和基础设施建设,感谢 Kev 帮助我们改进各种 KZG 库的性能。
参考文献
- 从 4844 到 Danksharding:扩展以太坊 DA 的路径 - Francesco
- 从 EL 的 blob 池中获取 blob - Michael Sproul
- PeerDAS 提议者带宽问题讨论 - Eth R&D Discord
- 从 EL 池中获取 blob - Dapplion
- 如何帮助使用 blob 的自构建者 - Dankrad Feist
- 原文链接: blog.sigmaprime.io/peerd...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





