理解EVM的栈式架构
- faizannehal
- 发布于 2023-11-20 13:54
- 阅读 500
本文介绍了以太坊虚拟机(EVM)的栈式架构,解释了其工作原理、存储类型(栈、内存、存储和调用数据),以及由于架构限制可能出现的“栈溢出”错误。文章还讨论了栈深度限制的原因以及EVM架构的优缺点。
介绍:
如你所知,以太坊、Polygon、币安链、Optimism 等区块链使用 EVM,即以太坊虚拟机,作为底层环境来执行交易和运行智能合约。EVM 本身是一种基于堆栈的架构,而不是基于寄存器的架构,后者在传统的处理器和计算机中更为常见。在本文中,我们将阐明 EVM 的架构,以及为什么智能合约中会出现像堆栈溢出(stack-too-deep)这样的缺陷。
EVM:
在深入研究架构之前,让我们首先定义 EVM 并解释它的工作原理。EVM 是以太坊虚拟机(Ethereum Virtual Machine)的缩写,它是负责在以太坊和其他利用链上存储的字节码的区块链上运行和执行智能合约的执行组件。它是一个沙箱化的虚拟机,运行在以太坊网络中的每个节点上,负责保持区块链的活力。EVM 是平台独立的,可以用任何编程语言实现。这使得开发人员可以使用 Solidity、Vyper 等广为人知的编程语言创建智能合约。编写完合约后,它会被编译成字节码并部署到 EVM。
当我们说 EVM 是一台基于堆栈的机器时,我们的意思是它在一个名为堆栈的数据结构上运行,该堆栈保存值并执行操作。EVM 有自己的一组指令,称为操作码(opcodes),用于执行诸如读取和写入存储、调用其他合约以及执行数学运算等任务。这使得以太坊能够支持范围广泛的去中心化应用程序,从简单的代币系统到大型的去中心化自治组织(DAOs)。
什么是基于堆栈的架构:
那么,什么是基于堆栈的架构?它是一种计算机架构,它使用堆栈数据结构来存储值和执行操作。堆栈以后进先出(LIFO)的方式运行,这意味着最近插入的项存储在堆栈的顶部,并且是第一个被删除的项。程序的指令和数据都保存在这种架构的内存中,程序的执行由一个堆栈指针控制,该指针指向堆栈的顶部。堆栈指针跟踪下一个值或指令将被保存或检索在堆栈中的位置。
当程序运行时,它会将值添加到堆栈中,并对已存在的值执行操作。当代码想要将两个数字相加时,它会将这些数字压入堆栈,然后对顶部的两个值执行加法运算。然后将结果返回到堆栈。
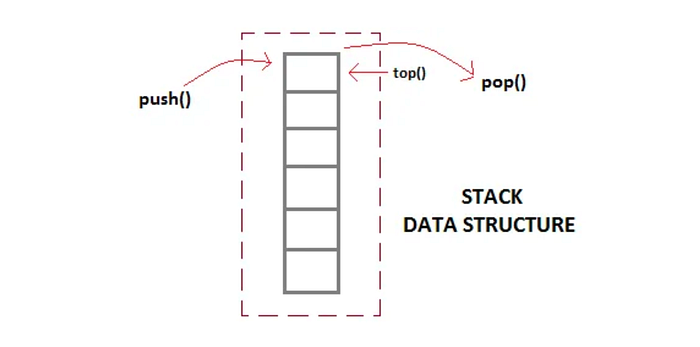
基于堆栈的架构最重要的特性之一是它允许高度简单和高效的操作执行。因为堆栈是一种 LIFO 数据结构,它能够轻松快速地处理数据和指令。这使得它非常适合在像以太坊虚拟机(EVM)这样的虚拟机中使用,虚拟机必须在短时间内执行大量的操作。
基于寄存器的架构:
另一种类型的架构是基于寄存器的架构,它是一种计算机架构,其中数据和指令的主要存储是一组位于 CPU 内的寄存器。与基于内存的架构(例如基于堆栈的架构)不同,在基于内存的架构中,数据保存在主内存中并通过内存地址访问,而基于寄存器的架构中的数据直接存储在 CPU 中,并由 CPU 的寄存器直接访问。我们将不会深入研究这种架构,因为它与本主题无关。
EVM 中的存储类型:
如果我们谈论 EVM 的架构,它的存储可以进一步分为四个主要组件,用于在执行期间存储和访问数据,即 EVM 堆栈(EVM Stack)、EVM 内存(EVM Memory)、EVM 存储(EVM Storage)和 Calldata。
EVM 堆栈:
堆栈是整个基于堆栈的架构的主要组成部分,它是值存储和操作执行的数据结构。它用于存储数学和逻辑运算的操作数,以及函数调用的返回值。堆栈的大小或堆栈深度为 1024 个项目,每个项目是一个 256 位字,总共有 16 个槽。每个项目都被压入堆栈的顶部并从那里移除,用于在堆栈上执行这些任务的操作码是 PUSH/POP/SWAP/DUP。
EVM 内存:
第二个组成部分是 EVM 内存,它是架构中的易失性内存,其数据在区块链上不是持久的,这意味着内存是一种随机访问数据结构,用于在智能合约执行期间存储临时数据。它用于存储不需要存储在存储中的变量和数据结构。内存可以在智能合约执行期间调整大小,但与堆栈相比,访问速度更慢且成本更高。内存被初始化为零,用于访问内存的操作码是 MLOAD、MSTORE、MSTORE8
EVM 存储:
第三个是 EVM 存储,它是一种非易失性存储,保存 256 位 -> 256 位的键值对。合约中的存储槽总数为 2²⁵⁶,这是一个相对较大的槽数,区块链上的每个智能合约都有自己的存储空间。在函数调用期间,它用于需要在函数调用之间记住的数据。它用于存储即使在智能合约执行结束后仍然需要可用的变量和数据结构。用于访问存储的操作码是 SLOAD 和 SSTORE
Calldata:
最后一个用于存储数据的组件是 Calldata,它是一种只读内存。Calldata 的布局和行为与内存相同,唯一的主要区别是它是只读空间,用于保存事务或调用的数据参数。要使用 Calldata 中的数据,你必须指定字节偏移量和要读取的字节数。用于 Calldata 的操作码是 CALLDATASIZE、CALLDATALOAD、CALLDATACOPY
堆栈溢出(Stack-Too-Deep)是如何发生的:
尽管这种架构有其优点,但它也有许多缺点。例如,基于堆栈的架构不太擅长处理复杂的数据结构,如链表或树,使用堆栈可能更难以处理。除此之外,由于这种架构,智能合约中可能会出现一些错误,最值得注意的是 “堆栈溢出” 问题。
那么,什么是堆栈溢出?当函数或合约超过调用堆栈的最大深度时,就会发生 “堆栈溢出” 错误。假设你在合约中调用一个函数,每次调用函数时,都会向堆栈添加一个新的帧,当函数返回时,顶部的帧会被移除。为了防止无限递归和其他堆栈溢出问题,EVM 中调用堆栈的最大深度是有限制的。Solidity 中的最大堆栈深度为 1024 个项目,每个项目都是 256 位的字。此外,EVM 只能访问距离最顶部槽最多 16 个槽的堆栈项目。因此,如果你将超过 16 个项目压入堆栈,然后尝试检索第 17 个项目,EVM 将抛出 “堆栈溢出” 错误。
当一个函数或合约递归重复自身太多次,或者当另一个函数再次调用原始函数,超过最大堆栈深度时,就会发生 “堆栈溢出” 错误,这意味着堆栈上的对象数量超过 16 个。当函数有过多局部变量、参数或返回值时,也会发生这种情况。它也可能由于无限递归、合约调用的长链,或两者的混合而发生。
为什么堆栈深度只有 1024:
你可能在想为什么堆栈深度如此之小,或者是否有一种方法可以增加深度?
将深度保持在 1024 的关键原因是,如果深度更高,合约的执行成本会更高,因为它们需要更多的内存,因此 1024 是深度限制的一个合理选择。此外,拥有动态深度是麻烦的,因为拥有固定大小的深度简化了 EVM 的实现。此外,EVM 只能访问距离最顶部槽最多 16 个位置的堆栈上的对象。因此,即使你有一个 4096 个项目的堆栈,并且你可以将所有内容放入 4096 个项目的堆栈中,你也只能直接访问存储在距离顶部 16 个槽的数据。
结论:
以上是 EVM 基于堆栈的架构的基本概述,以及使用了哪些数据存储组件,以及由于该架构而如何出现堆栈溢出问题。“EVM 的功能很复杂,但对于新手开发人员来说很容易上手,从而产生了大量的去中心化应用程序。然而,EVM 也并非没有缺陷。该系统也受到网络吞吐量和交易速度问题的困扰。这些现在是以太坊开发社区需要解决的关键问题,解决这些问题为以太坊的持续使用和成功提供了一个路线图。
- 原文链接: faizannehal.medium.com/u...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





