使用Cryo分析以太坊
- mteam88
- 发布于 2023-09-24 14:48
- 阅读 959
本文介绍了Cryo,是由Paradigm开发的区块链分析工具,可以方便地提取区块链数据。文章展示了如何安装Cryo,下载以太坊数据,并使用Polars进行数据分析,包括区块时间戳、额外数据(Block Graffiti)、Gas使用情况和区块大小等。
Cryo 是一个由 Paradigm 构建的区块链分析工具。Cryo 是提取区块链数据进行分析的最简单方式。在本文中,我将安装 Cryo,下载一些以太坊数据,并使用 polars 进行分析。
❄️🧊 Cryo 🧊❄️ 介绍
来自 Cryo readme
❄️🧊 cryo 🧊❄️
cryo 是将区块链数据提取到 parquet, csv, json 或 python dataframe 的最简单方式。
cryo 也非常灵活,有许多不同的选项来控制数据的提取 + 过滤 + 格式化方式
cryo 是一个早期的 WIP (进行中的工作),请向 issue 跟踪器报告错误 + 反馈
Storm Silvkoff 在他的 Rust x Ethereum day 演讲中给出了一个关于 Cryo 的精彩指南:
Rust x Ethereum Day - Cryo and Data Endgame - YouTube
Rust x Ethereum Day - Cryo and Data Endgame
Cryo 基于 Rust 编程语言构建。 在使用 Cryo 之前,你需要 安装 Cargo。
在本文的第二部分,我们将探索我们使用 Cryo 收集的数据。 为此,我们将使用 Python 库,因此你需要安装 Python。
安装 Cryo
使用 Cryo 的第一步是 安装它。
我选择从源代码构建,因为 Cryo release 0.2.0 在使用 cargo install 时,目前存在一些 构建问题。
要安装:
git clone https://github.com/paradigmxyz/cryo
cd cryo
cargo install --path ./crates/cli要测试你的安装,请运行:
cryo -V下载数据
Cryo 可以下载许多不同的 数据集:
- blocks
- transactions (alias = txs)
- logs (alias = events)
- contracts
- traces (alias = call_traces)
- state_diffs (alias for storage_diffs + balance_diff + nonce_diffs + code_diffs)
- balance_diffs
- code_diffs
- storage_diffs
- nonce_diffs
- vm_traces (alias = opcode_traces)
在本文中,我们将下载并分析 blocks 数据集:
cryo blocks <OTHER OPTIONS>数据源
Cryo 需要 一个 rpc url 来提取区块链数据。 Chainlist 是一个 RPC 聚合器,它收集最快的免费和开放的端点。 列出的任何 http 端点都应该有效,但我选择了来自 LlamaNodes 的 https://eth.llamarpc.com/
我们的 cryo 命令现在看起来像这样:
cryo blocks --rpc https://eth.llamarpc.com <OTHER OPTIONS>如果你收到如下错误:
send error, try using a rate limit with --requests-per-second or limiting max concurrency with --max-concurrent-requests你可以尝试其他 rpcs。
关于 RPC 的说明
如果你使用的是在线 RPC,那么你的性能可能会比运行像 reth 这样的本地节点更差。
如果你设置了自己的 reth 节点,你可以获得 10 倍的速度 — Storm Silvkoff 在 Telgram 上说
数据目录
为了使我们的数据与用于分析的其他文件分开,我创建了一个 .data 目录。 在运行 cryo 之前,你必须创建此目录。
将我们的数据目录添加到命令中:
cryo blocks --rpc https://eth.llamarpc.com -o ./.data/ <OTHER OPTIONS>附加列
默认的 blocks schema 包括以下列:
schema for blocks
─────────────────
- number: uint32
- hash: binary
- timestamp: uint32
- author: binary
- gas_used: uint32
- extra_data: binary
- base_fee_per_gas: uint64但也有其他可用的字段:
other available columns: logs_bloom, transactions_root, size, state_root, parent_hash, receipts_root, total_difficulty, chain_id通过运行为你的数据集查找此信息:
cryo <DATASET> --dry --rpc https://eth.llamarpc.com对于此分析,我对 size 列感兴趣。 我们可以使用命令中的 -i 标志来告诉 cryo 我们想要 size 数据:
cryo blocks --rpc https://eth.llamarpc.com -o ./.data/ -i size <OTHER OPTIONS>让我们开始吧!
在运行之前,我们应该指定我们感兴趣的特定区块,以避免下载整个 blocks 数据集(它非常庞大)。 Cryo 以(默认)1000 个区块的块来下载数据,因此我们将使用 --align 标志来“将区块块边界对齐到规则的间隔”。
我们的最终命令如下所示:
cryo blocks -b 18100000:18190000 -i size --rpc https://eth.llamarpc.com --align -o ./.data/它从我们的节点下载 9 万个区块 并将它们存储为 parquet 格式。
在我的笔记本电脑上运行只花了 1 分 38 秒 !! (仍然想尝试在 reth 节点上运行。)
Polars 分析
此过程的下一步是分析我们拥有的数据。 我们将使用 polars DataFrame 库来读取我们下载的 parquet 文件。
我将在我的 VSCode 开发环境中使用一个 交互式 Python 笔记本(也称为Jupyter Notebook)。
Paradigm 在他们的 数据网站 上提供了一个 示例笔记本,我已将其用作我们分析的模板。
你可以在 Github 上找到 完整笔记本,在本节中,我将讨论我的一些发现:
时间戳
在本节中,我探索了我们下载的区块的时间戳数据:
## 获取 np 数组中的所有时间戳
timestamps = scan_df().select(pl.col('timestamp')).collect(streaming=True).to_numpy()
## 计算区块之间的时间差
time_diff = np.diff(timestamps, axis=0)Average Block Time: 12.136534850387227
Standard Deviation of Block Time: 1.2814744196308057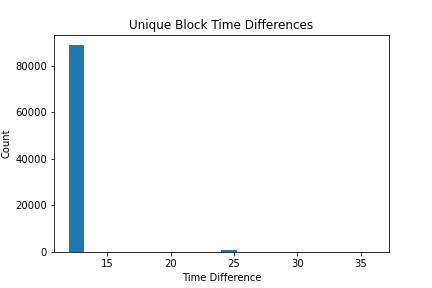
额外数据 aka 区块涂鸦
额外数据是
一个可选的免费但最大 32 字节长的空间,用于保存以太币的智能物品。 :) — https://ethereum.stackexchange.com/a/2377
许多 区块构建者 使用额外数据来识别他们构建了该区块。
## 获取唯一 extra_data 使用的总gas
result_df = scan_df().groupby('extra_data').agg(pl.col('gas_used').sum().alias('tot_gas_used')).collect(streaming=True)
sorted_result_df = result_df.sort('tot_gas_used', descending=True).head(10)
extra_data = sorted_result_df['extra_data'].to_numpy()


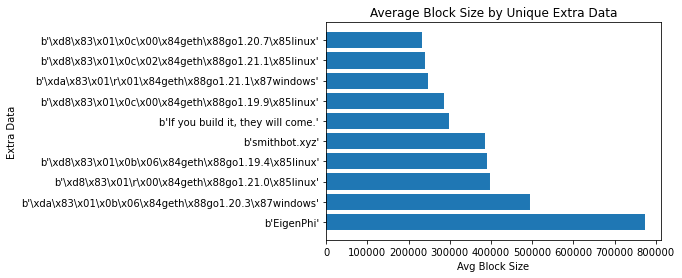
Gas
接下来,我探索了区块随时间的 base_fee。 如 EIP-1559 中所定义,Gas 价格包括每个区块定义的 base_fee 和由每个交易的发送者确定的优先级费用。 在本节中,我们分析 base_fee 以了解 Gas 随时间的变化。
## 获取 base_fee_per_gas 和时间戳,按时间戳排序
scan_df().select('base_fee_per_gas', 'timestamp').collect(streaming=True).sort('timestamp').to_numpy()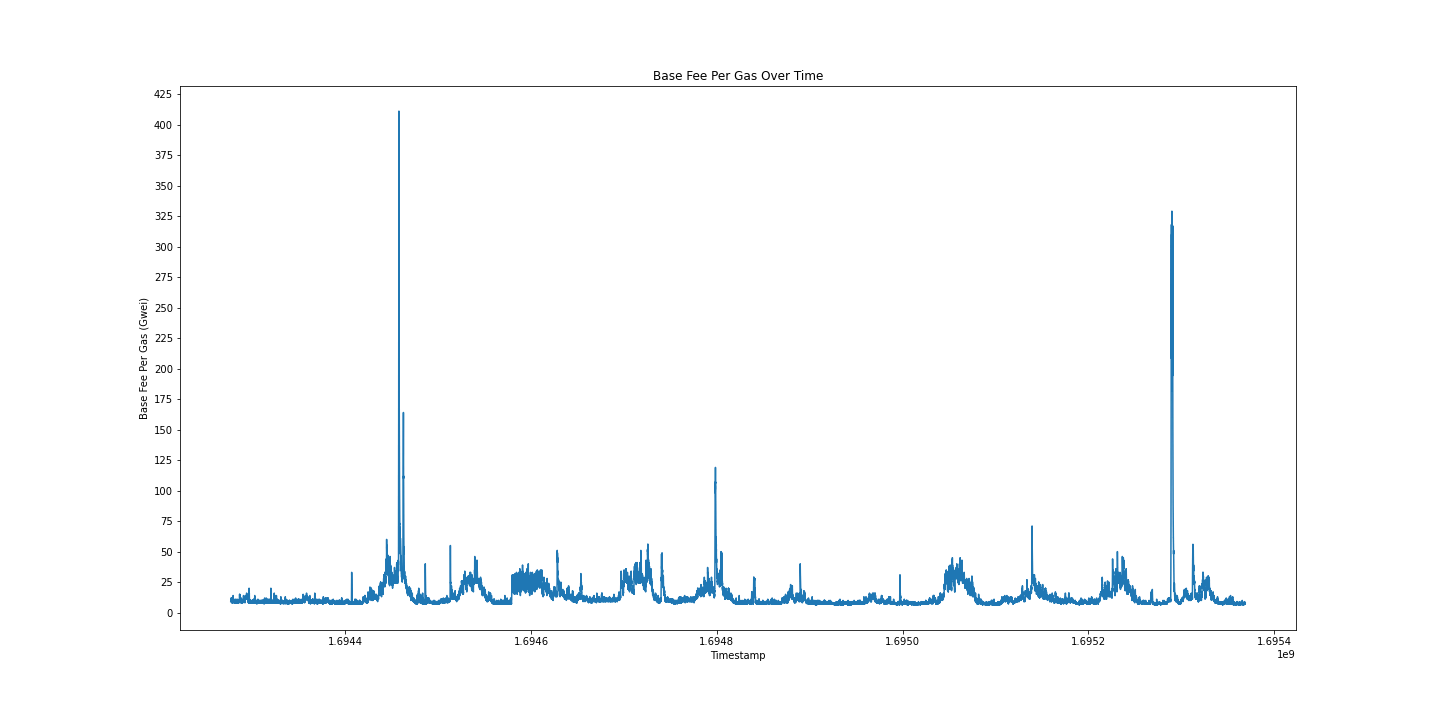
我们拥有的另一个与 Gas 相关联的有趣数据点是每个区块中使用的 gas_used。 让我们使用钟形曲线来绘制每个区块使用的 gas_used:
## 获取 gas_used
res = scan_df().select('gas_used').collect(streaming=True).to_numpy()
## gas_used 的钟形曲线图
plt.figure(figsize=(20, 10))
plt.hist(res, bins=100)
plt.title('Gas Used')
plt.xlabel('Gas Used')
plt.ylabel('Count')
plt.show()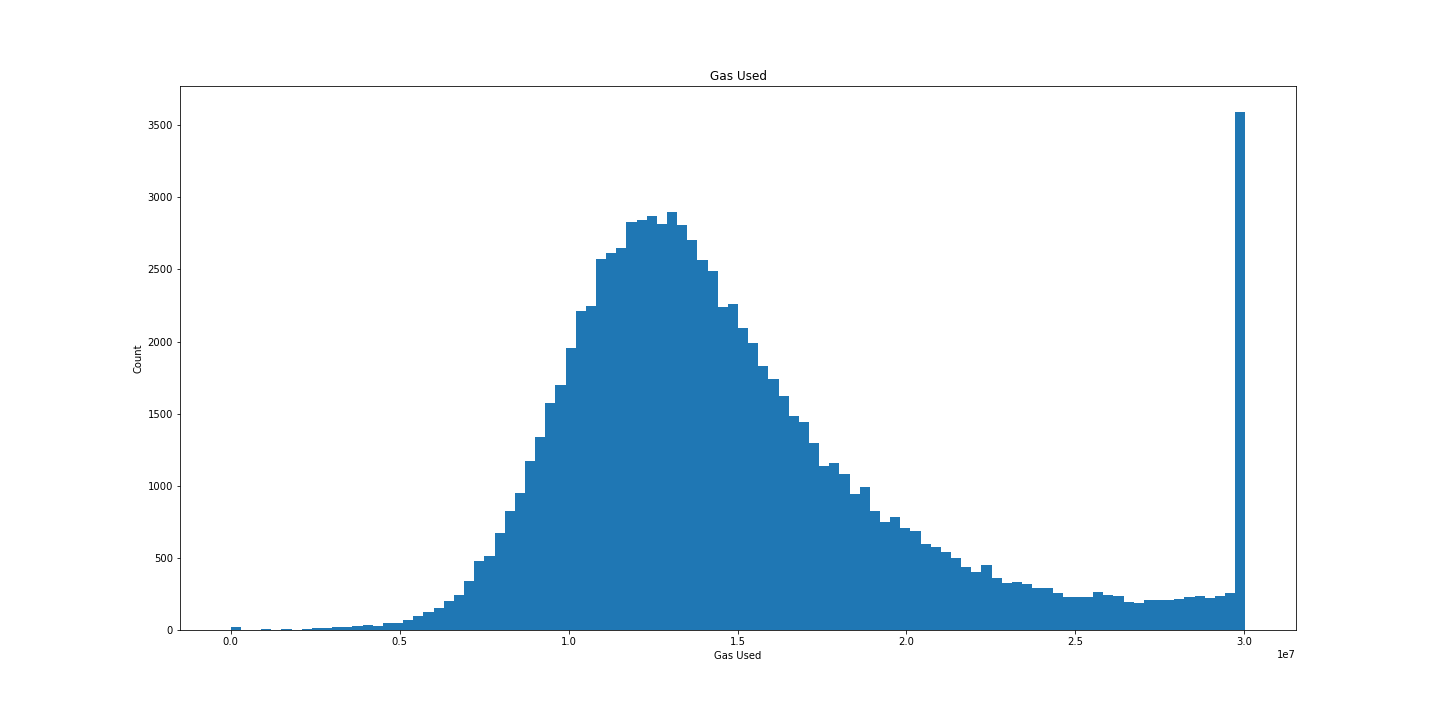
漂亮。
区块大小
如前所述,我们还下载了每个区块的 size(以字节为单位)。
之前的分布非常漂亮,让我们再试一次:
## 获取 size
res = scan_df().select('size').collect(streaming=True).to_numpy()
## gas_used 的钟形曲线图
plt.figure(figsize=(20, 10))
plt.hist(res, bins=150)
plt.title('Block Size')
plt.xlabel('Block Size (bytes)')
plt.ylabel('Count')
plt.show()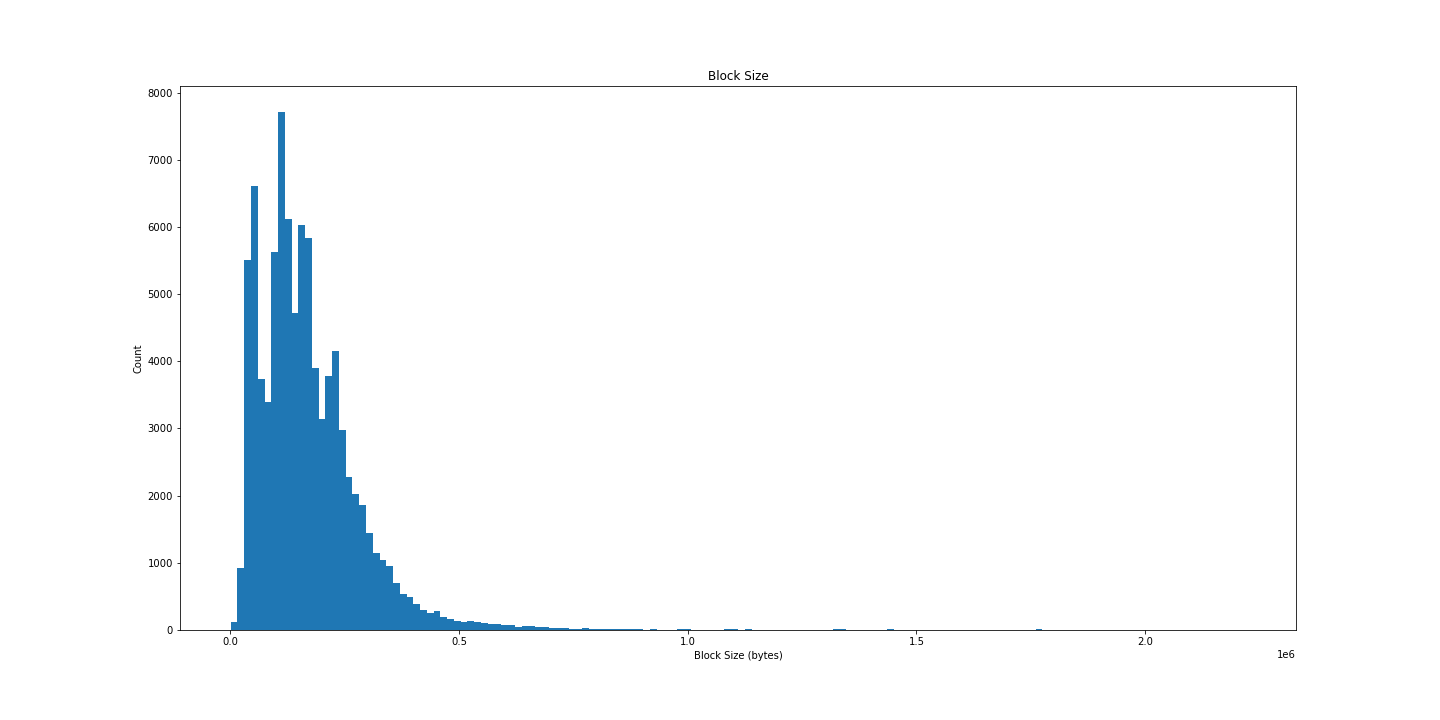
不太令人满意,但同样有趣。 让我们尝试及时绘制:
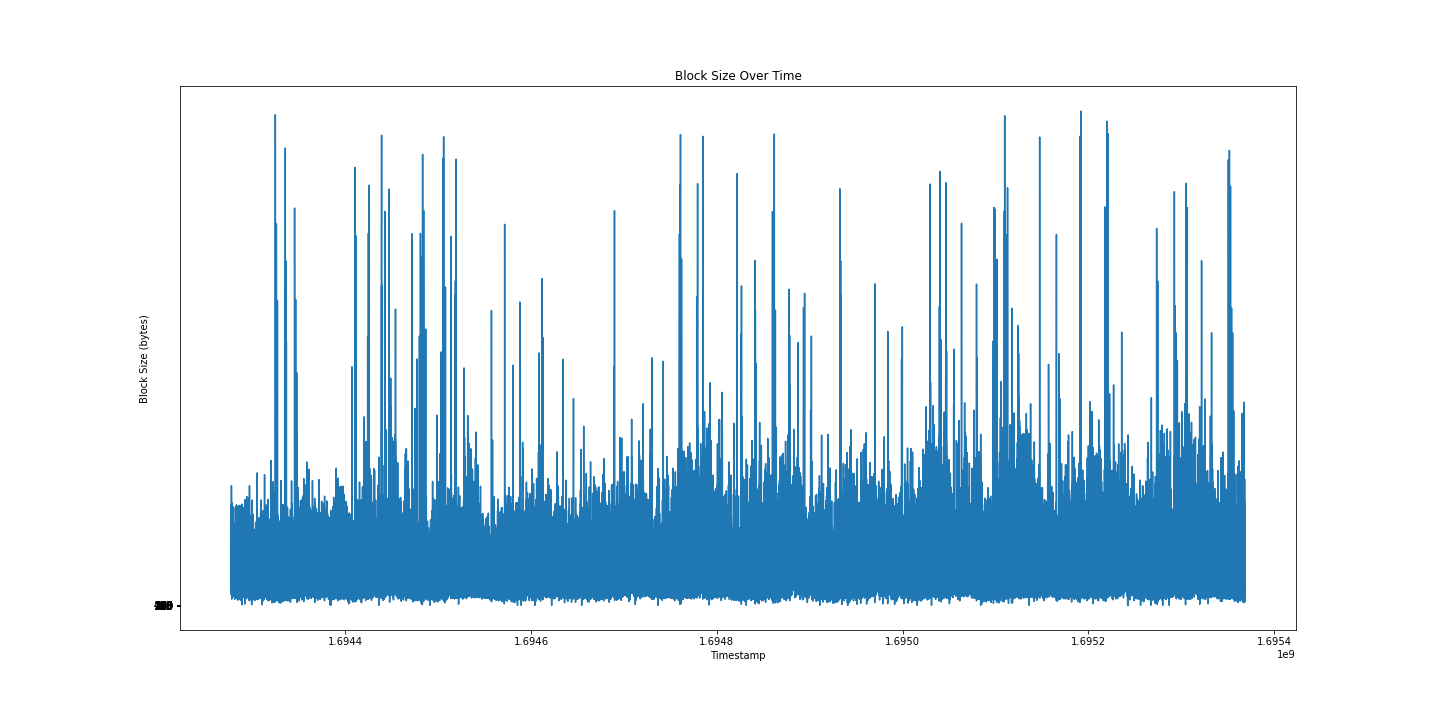
我仍然无法从这张图中看出什么,也许箱线图会提供更多信息?
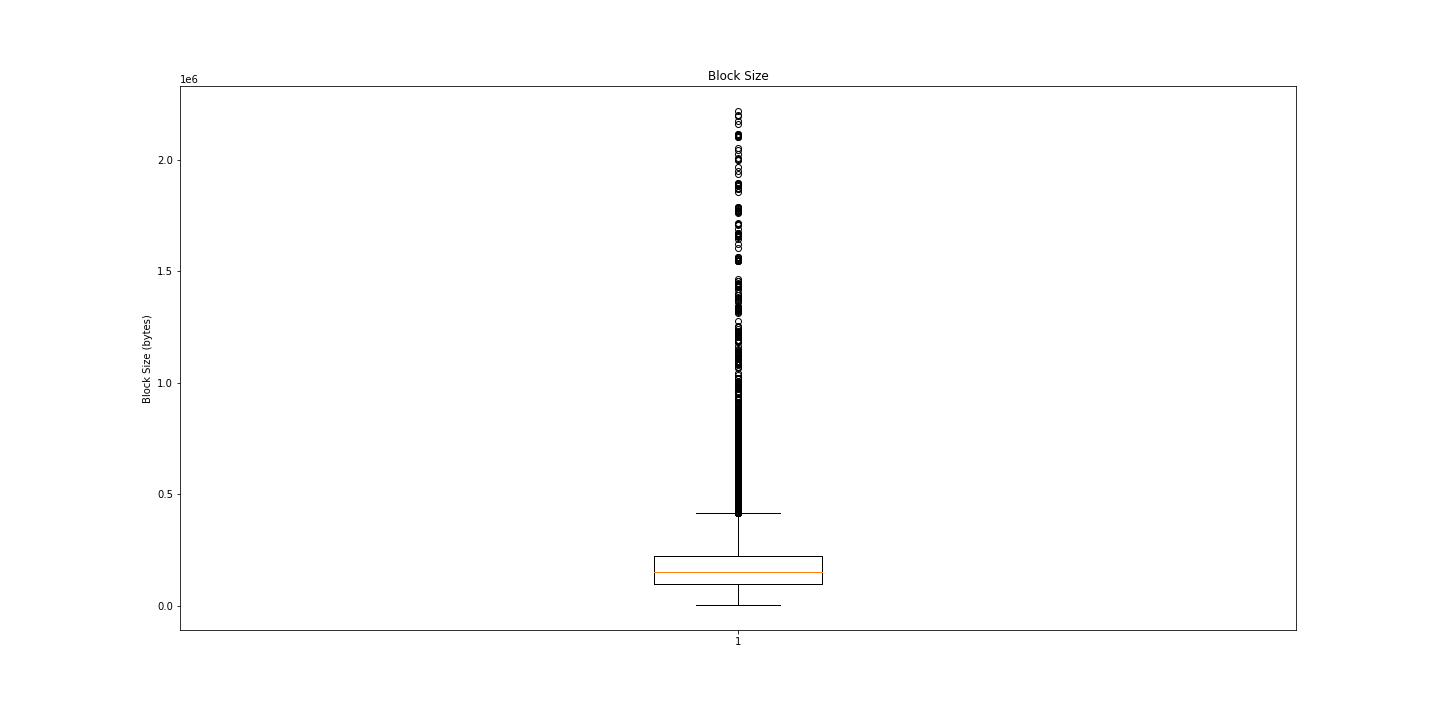
嗯。 很多异常值。 也许我们只需要数字?
## 打印一些摘要统计信息
print("Min: ", np.min(res[:, 0]))
print("Average: ", np.mean(res[:, 0]))
print("Median: ", np.median(res[:, 0]))
print("Std Dev: ", np.std(res[:, 0]))
print("Max: ", np.max(res[:, 0]))Min: 1115 # 1.115KB
Average: 172033.70095555554 # 0.172MB
Median: 150470.0 # 0.15MB
Std Dev: 125779.71706563157 # 0.126MB
Max: 2218857 # 2.2MB有意思。
结论
我们在这里只探索了表面数据。 我真的很喜欢这种摆弄数据的乐趣。 运行 整个笔记本 只需几秒钟。
能够如此轻松地访问复杂数据的分析,增加了人们探索其数据并发现见解的可能性。
- 原文链接: mteam.space/posts/analyz...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





