Ethereum: 面试官最爱问的Merkle Patricia Trie (MPT) 到底是个啥
- 一眼万年
- 发布于 2025-08-09 23:21
- 阅读 3583
Merkle Patricia Trie (MPT) 是以太坊的核心数据结构,巧妙结合了 Patricia Trie、Merkle Tree 和 RLP 编码的优势,实现了高效、可验证且紧凑的数据存储。
1. MPT 算法概述
1.1 什么是 MPT
Merkle Patricia Trie (MPT) 是以太坊的核心数据结构,用于存储和验证状态、交易、收据等关键数据。它巧妙地结合了三种经典数据结构的优势:
- Patricia Trie:基于路径压缩的前缀树,优化稀疏键空间
- Merkle Tree:提供密码学验证能力,支持轻客户端
- RLP 编码:以太坊标准序列化格式,确保共识一致性
1.2 核心设计原则

关键特性:
- 确定性:相同数据总是产生相同的根哈希
- 高效性:O(k) 复杂度,k 为键长度,与数据量无关
- 可验证性:支持 Merkle 证明,无需完整数据即可验证
- 压缩性:路径压缩大幅减少存储空间
1.3 MPT 工作原理
MPT的核心工作机制可以概括为"路径导航 + 节点分化 + 哈希验证"三个层面
MPT 插入操作步骤:
-
键预处理阶段
- 接收原始键值对插入请求
- 对键进行 Keccak256 哈希化,得到 32 字节固定长度哈希
- 将哈希值转换为 64 个 nibble(半字节)的路径序列
-
树遍历导航
- 从 MPT 根节点开始向下导航
- 根据当前 nibble 位置和节点类型选择处理策略
-
节点类型处理
- 遇到 nil 节点:在空位置创建新的 shortNode 叶子节点
- 遇到 shortNode:进行路径前缀匹配检查
- 完全匹配 → 继续向下递归或直接更新值
- 部分匹配 → 执行节点分裂,创建 fullNode 分支
- 遇到 fullNode:根据当前 nibble 选择对应分支,递归处理子节点
-
结构优化处理
- 新建节点时应用路径压缩优化
- 节点分裂时创建合适的分支结构
- 确保树保持最优的存储效率
-
哈希更新传播
- 计算修改节点的新哈希值
- 自底向上传播哈希变更到所有受影响的父节点
- 最终更新根哈希,完成插入操作
- 关键:新的根哈希将被写入下一个区块的 Header 中(如 StateRoot、TxRoot 等),成为区块链共识的一部分
1.4 在以太坊中的应用
| Trie 类型 | 用途 | 存储内容 |
|---|---|---|
| 状态 Trie | 全局状态管理 | 账户状态(余额、nonce、代码哈希等) |
| 存储 Trie | 合约存储 | 智能合约的存储变量 |
| 交易 Trie | 区块交易索引 | 区块中的所有交易 |
| 收据 Trie | 交易执行结果 | 交易收据和事件日志 |
2. 节点类型
| 节点类型 | 结构字段 | 用途说明 | 使用场景 |
|---|---|---|---|
| fullNode | Children[0-15]: 十六进制分支<br>Children[16]: 可选值<br>flags: 节点标志 |
处理路径分歧,支持多分支 | 密集键空间,多个键在同一位置分叉 |
| shortNode | Key: 压缩路径<br>Val: 子节点或值<br>flags: 节点标志 |
路径压缩,减少树深度<br>• Val=valueNode → 叶子节点<br>• Val=其他node → 扩展节点 | 稀疏键空间,长公共前缀 |
| hashNode | []byte: 32字节哈希引用 |
延迟加载,内存优化 | 大规模数据,历史状态引用 |
| valueNode | []byte: 实际存储数据 |
存储最终数据值 | 叶子节点的终端数据 |
3. 关键操作实现
3.1 插入操作(Insert)
插入操作是MPT中最复杂的操作之一,它需要根据当前节点类型和新键的路径关系做出不同的处理决策。当插入一个新的键值对时,系统首先将键转换为nibble路径,然后从根节点开始向下遍历。在遍历过程中,如果遇到空节点(nil),则直接创建新的shortNode叶子节点;如果遇到shortNode,需要比较路径前缀的匹配情况,完全匹配时继续向下或更新值,部分匹配时则需要进行节点分裂,创建fullNode来处理路径分歧;如果遇到fullNode,则根据当前nibble选择对应分支继续递归;如果遇到hashNode,则先解引用获取实际节点再进行处理。
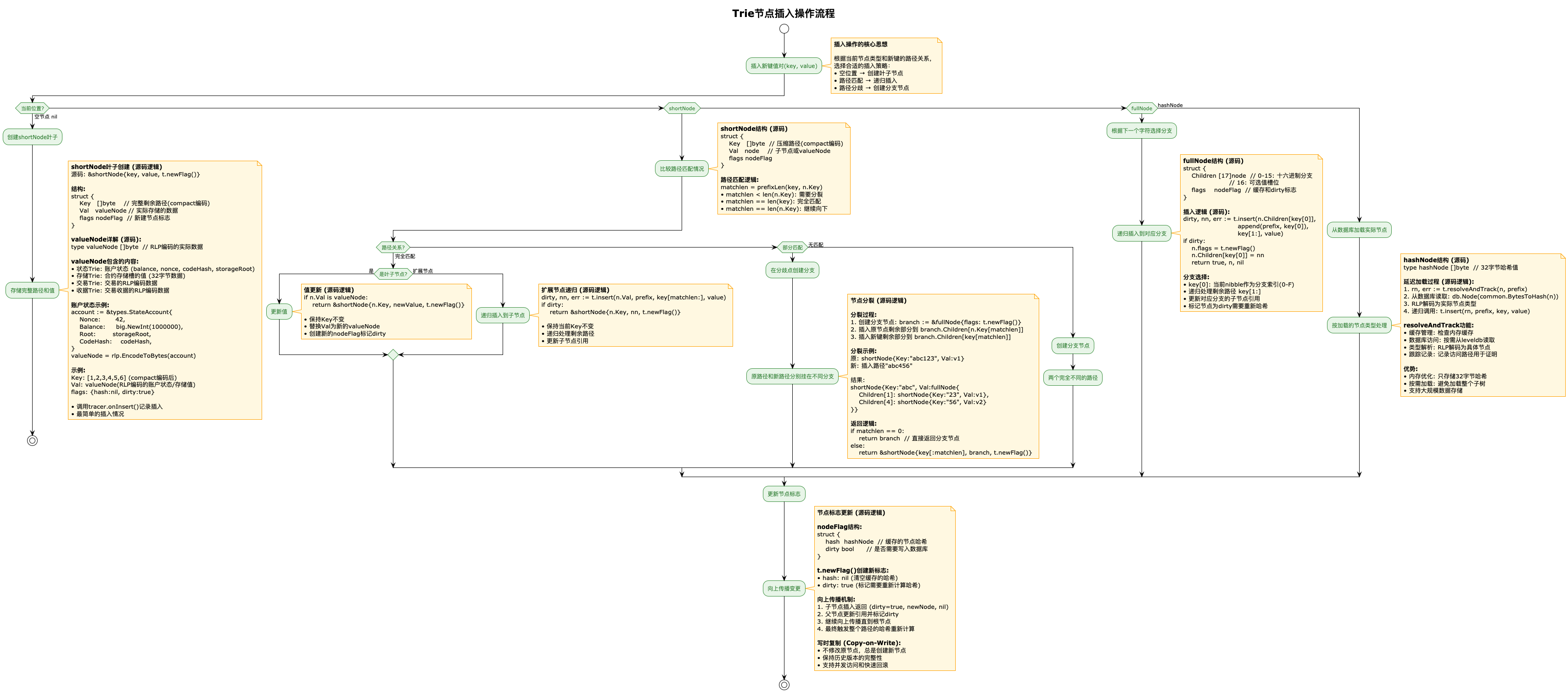
3.2 删除操作(Delete)
删除操作相比插入操作更加注重结构优化和路径合并。当删除一个键值对时,系统不仅要找到并移除目标节点,还需要自底向上地进行结构调整以保持MPT的最优形态。删除过程中,如果遇到shortNode且路径完全匹配,则直接删除该节点;如果路径部分匹配,则需要递归删除子节点,并根据删除结果决定是否需要路径合并或节点删除。对于fullNode,删除操作会递归处理对应分支,然后根据剩余分支数量进行结构调整:如果所有分支都被删除则移除整个fullNode,如果只剩一个分支则退化为shortNode以实现路径压缩,如果还有多个分支则保持fullNode结构。这种自适应的结构调整确保了MPT始终保持最紧凑的存储形态。
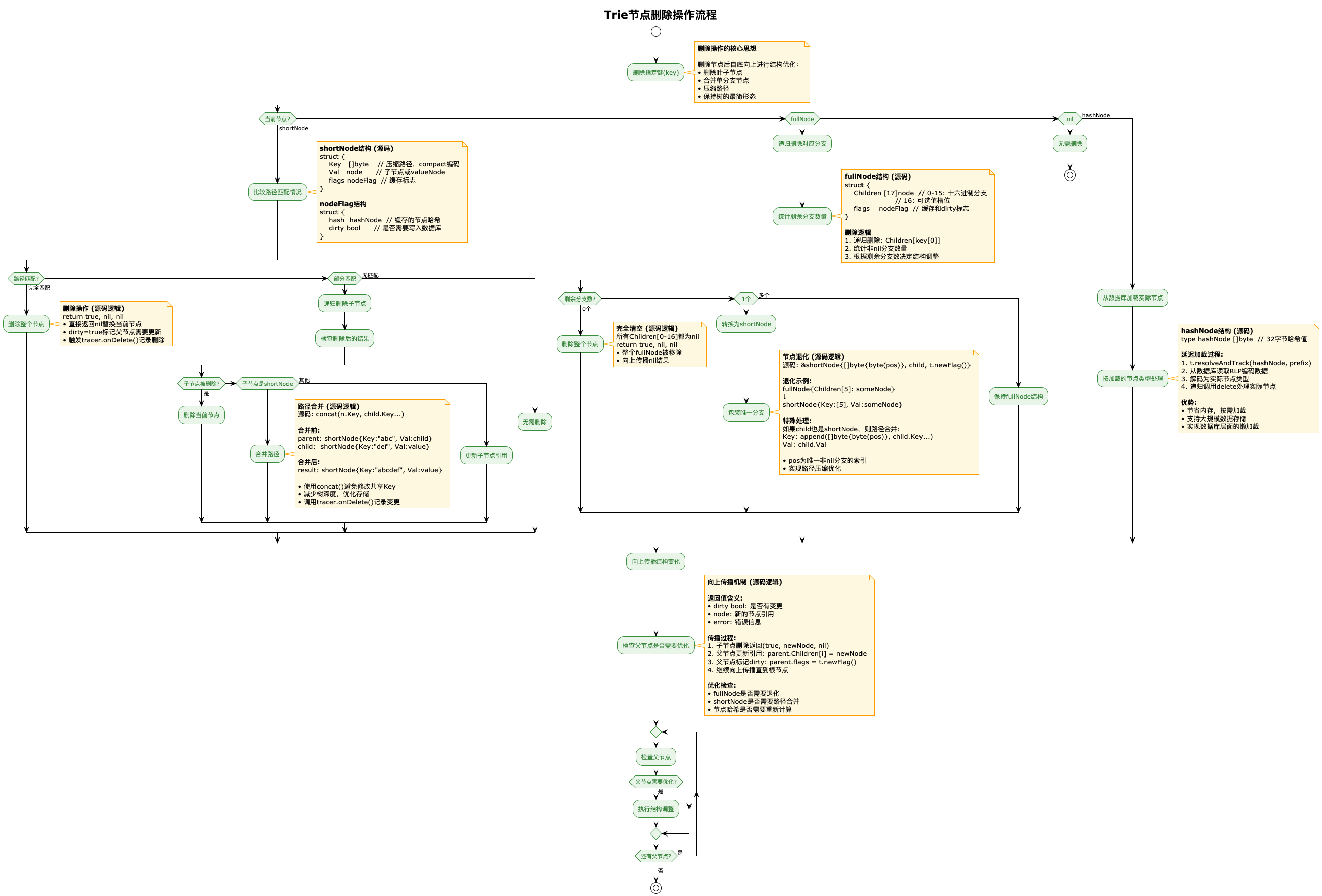
4. 实现中的优化
-
小节点内嵌优化: 当节点的RLP编码长度小于32字节时,不对其进行哈希处理,而是直接将编码后的数据内嵌到父节点中。Keccak256哈希值本身就是32字节,如果原始数据更小,那么存储原始数据比存储哈希值更高效。通过这种内嵌机制,系统避免了大量小节点的数据库读写操作,提升了访问性能,特别是在处理大量小型叶子节点时效果尤为明显。 -
并行哈希计算: 在处理fullNode时采用了并行哈希计算策略。当需要计算一个fullNode的哈希值时,系统会将其16个子分支分配给多个工作协程并行处理,每个协程负责计算几个分支的哈希值。减少了大型fullNode的哈希计算时间,特别是在状态树提交(commit)阶段,能够有效提升整体性能。所有工作协程完成后,主线程会收集结果并计算最终的fullNode哈希值。 -
写时复制(Copy-on-Write):当需要修改MPT中的节点时,不会直接修改原有节点,而是创建一个新的节点副本进行修改。这种设计确保了历史版本的完整性,使得系统能够在任何时候回滚到之前的状态。写时复制机制还支持多个并发操作同时进行,每个操作都在自己的副本上工作,避免了数据竞争问题。这对于以太坊这样需要处理大量并发交易的系统来说至关重要。 -
缓存与延迟加载:系统使用hashNode作为"占位符",只存储32字节的哈希值而不是完整的节点数据。当实际需要访问节点内容时,系统首先检查内存缓存,如果缓存命中则直接返回;如果缓存未命中,则从数据库加载对应的RLP编码数据,解析为实际的节点对象,并更新缓存以供后续使用。这种延迟加载策略使得系统能够处理远超内存容量的大型MPT,同时通过LRU等缓存策略确保热点数据的快速访问。
5. 实战演示
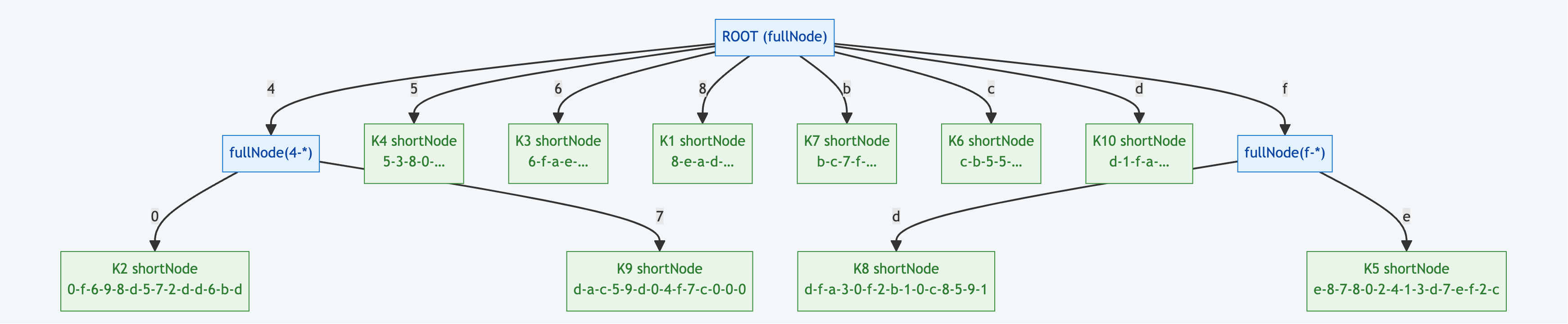
5.1 演示数据集
使用10个真实以太坊地址作为演示键:
| ID | Address | Key (first 16 nibbles) |
|---|---|---|
| K1 | 0x742d35Cc6634C0532925a3b844Bc454e4438f44e | 8-e-a-d-1-c-d-5-3-b-2-f-c-3-6-5 |
| K2 | 0xA16081F360e3847006dB660bae1c6d1b2e17ec2a | 4-0-0-f-6-9-8-d-5-7-2-d-d-6-b-d |
| K3 | 0x00000000219ab540356cBB839Cbe05303d7705Fa | 6-f-a-e-9-6-9-e-9-a-3-e-5-8-9-d |
| K4 | 0x0000000000000000000000000000000000000000 | 5-3-8-0-c-7-b-7-a-e-8-1-a-5-8-e |
| K5 | 0x000000000000000000000000000000000000dEaD | f-e-8-7-8-0-2-4-1-3-d-7-e-f-2-c |
| K6 | 0x1111111254fb6c44bac0bed2854e76f90643097d | c-b-5-5-7-c-a-d-f-9-9-7-9-2-b-c |
| K7 | 0x281055afc982d96fab65b3a49cac8b878184cb16 | b-c-7-f-9-4-7-3-1-3-f-f-c-a-6-8 |
| K8 | 0xfe9e8709d3215310075d67e3ed32a380ccf451c8 | f-d-f-a-3-0-f-2-b-1-0-c-8-5-9-1 |
| K9 | 0x53d284357ec70cE289D6D64134DfAc8E511c8a3D | 4-7-d-a-c-5-9-d-0-4-f-7-c-0-0-0 |
| K10 | 0x5a52e96bacdabb82fd05763e25335261b270efcb | d-1-f-a-1-0-7-1-b-1-0-3-e-c-0-4 |
5.2 状态可视化
总结
MPT将"可验证性、紧凑性、可扩展性"完美统一在一个数据结构中。通过精心设计的节点模型和大量工程优化,确保了在真实网络环境下的高效运行。深入理解MPT的实现原理,不仅能帮助开发者深刻理解以太坊状态变化的底层机制,在区块链相关的技术面试中也能展现扎实的基础功底,为职业发展提供有力支撑。





