solx 编译器彻底消除 "Stack too deep" 错误
- ZKsync 中文
- 发布于 2025-07-17 23:23
- 阅读 1705
本文深入探讨了zkSync的solx编译器如何解决Solidity开发者长期面临的“Stack too deep”错误。Solx通过扩展Solidity的内存布局,引入spill区域,并在LLVM基础设施之上进行优化,实现了比solc --via-ir更高效且语义更安全的代码生成,从而彻底消除了该错误,同时保持了合约行为的一致性。

长期以来,Solidity 开发者一直害怕臭名昭著的 “Stack too deep(堆栈太深)” 错误。为了解决这个问题,他们经常分割函数,将变量打包到结构体中,或者手动将值卸载到内存中——只是为了让代码能够编译。这是一个持续存在的痛点,著名的 Ethereum 工程师公开质疑为什么这个问题仍然没有解决。一个部分的解决方案是 --via-ir 标志,它允许编译器自动将多余的变量移动到内存中,而不是仅仅依靠 DUP 和 SWAP 来进行堆栈操作。它在大多数情况下都有效——但有一个主要的警告:它可能会微妙地改变合约的语义。结果是什么?大多数项目仍然停留在传统的编译器路径上,进行 “stack too deep” 的变通工作,而底层问题没有得到解决。
solx 消除了这个错误,同时保持你的合约行为完全相同。
solx 内存布局和当前约束
Solx 扩展了 solidity 的内存布局——类似于 solc --via-ir——通过插入一个专用的溢出区域。这保证了溢出永远不会干扰用户内存:
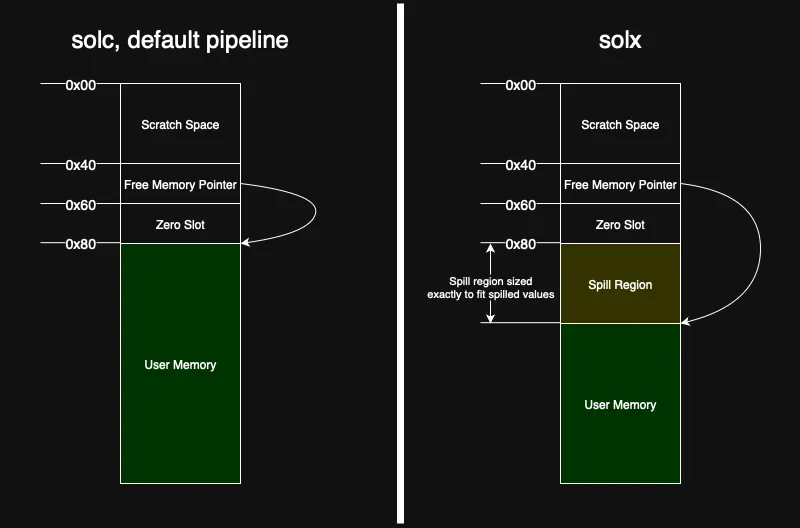
溢出区域在编译时布局:前端从第一个安全偏移量 ( 0x80) 开始预留它,后端计算这个区域的精确大小,并且空闲内存指针 ( 0x40) 被更新为指向紧随其后的位置。因为这个区域在运行时无法增长,并且所有的堆分配都从它的末尾之外开始,所以用户代码和内存安全的内联汇编都无法触及溢出槽,并且溢出写入永远不会超出它的边界。因此,内存损坏在设计上是不可能的。
这种确定性的布局带来了一个有意的权衡:不支持自递归和间接递归函数。支持递归将需要为每次调用分配一组新的溢出槽,但是 solx 有意避免为溢出进行动态内存分配。因此,如果递归函数存在 “stack too deep” 问题,它们会在编译时被明确拒绝。编写内联汇编的开发者应该小心。当需要溢出并且合约包含一个没有内存安全注释的汇编块时,solx 将产生如下错误:
Error (5726): This contract cannot be compiled due to a combination of a memory-unsafe assembly block and a stack-too-deep error. The compiler can automatically fix the stack-too-deep error, but only in the absence of memory-unsafe assembly.
To successfully compile this contract, please check if this assembly block is memory-safe according to the requirements at
https://docs.soliditylang.org/en/latest/assembly.html#memory-safety
and then mark it with a memory-safe tag.
Alternatively, if you feel confident, you may suppress this error project-wide by setting the EVM_DISABLE_MEMORY_SAFE_ASM_CHECK environment variable:
EVM_DISABLE_MEMORY_SAFE_ASM_CHECK=1 <your build command>
Please be aware of the memory corruption risks described at the link above!
--> forge/test/strategy/CommonBaseTest.t.sol:25:9:
|
25 | assembly {
| ^ (Relevant source part starts here and spans across multiple lines).
如果一个汇编块是内存安全的,它必须明确地用 "memory-safe" 注释,以告知编译器它可以安全地为溢出区域预留空间并发出溢出。
另一方面,如果一个汇编块不是内存安全的,但是被错误地标记为内存安全的,它可能导致不正确和未定义的行为——因为用于溢出的内存可能会被意外地覆盖。
还有一些重要的当前限制需要记住。首先,EVM 对操作数堆栈施加了 1024 个元素的硬性限制,但是 solx 目前在代码生成期间不跟踪这个全局堆栈深度。虽然这在典型的合约中很少构成问题,但在涉及非常深的嵌套或激进的内联的情况下,它可能会变得相关。如果在运行时超过了限制,执行将会失败,而不会事先发出编译器警告。
另一个限制出现在函数具有大量参数或返回值时——通常超过 16 个。在这种情况下,在堆栈化期间可能会发生 “stack too deep” 问题。虽然 solx 通常可以通过将中间值溢出到内存来恢复,但这并不能保证在所有情况下都有效,尤其是在值在复杂的控制流中保持活动状态时。
solx 内存溢出 vs solc --via-ir
solc --via-ir 和 solx 都旨在解决相同的问题:通过引入内存溢出来修复 EVM 中的 “stack too deep” 问题。然而,它们以非常不同的策略来处理这个问题。
solc 的 StackLimitEvader 对潜在的堆栈压力做出假设,并重写代码以抢先将中间结果存储在内存中。这些溢出通常是安全的,但往往是预防性的,并且一旦一个值被存储在内存中,即使不再需要,该插槽也不会被重用。在某些情况下,合约可能仍然会因为 “stack too deep” 错误而失败,正如在 GitHub 上报告的几个问题中所见。
相比之下,solx 在堆栈化期间插入溢出,但仅在需要时才插入。内存插槽基于 LLVM 的内部分析进行重用,该分析会考虑活跃性信息。这种重用不是 solx 中自定义逻辑的结果,而是 LLVM 基础设施的自然优势。solx 在编译时付出更多努力,以生成更有效和紧凑的运行时代码——这是一个有意的权衡。它不是假设可能发生堆栈压力,而是在真正必要时才发出溢出。
Stack too deep 可解决性表
该表说明了不同管道和代码生成器中 “stack too deep” 解决方案的状态。我们可以看到,由于在同名代码生成器中的 EVM 汇编之上添加了额外的 IR,它成为了最强大的编译器设置,而没有 --via-ir 可能带来的危险的语义更改。
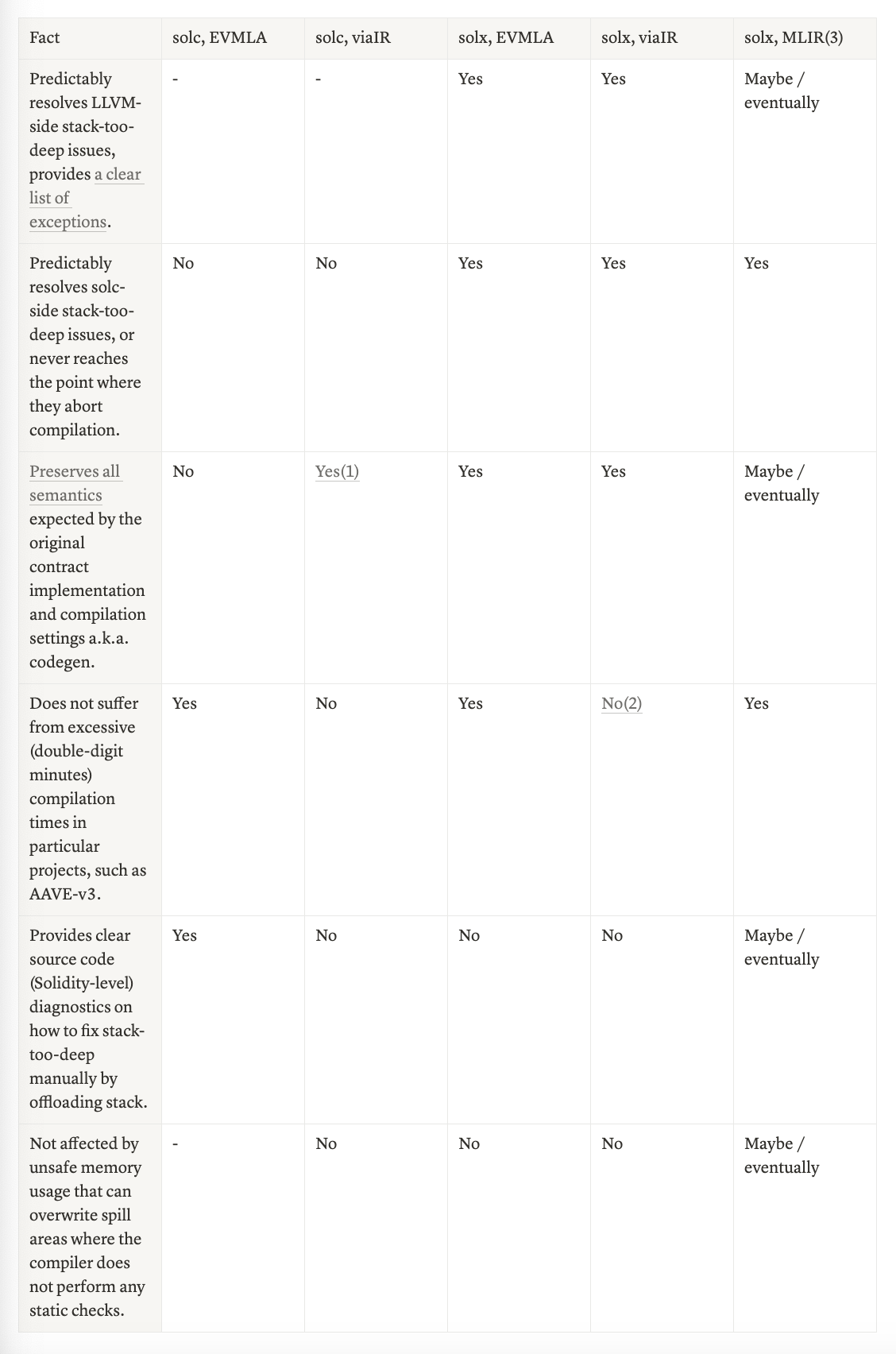
-
仅当项目是使用 viaIR 开发的,或者迁移后经过了测试(占在线项目的总数不到 20%)。
-
关闭 solx 中的 Yul 优化器可以在保持其库内联完整的同时缓解此问题。
- 它将在 solx 的后续版本中推出。
- MLIR 是一种新的代码生成器,它将在 solx 中取代 EVM 汇编和 Yul。它仍在开发中,但我们很快就会分享一些有趣的消息。
从仅仅起作用的溢出到生产级别
今年五月,当我们开始在 solx 中解决 “stack too deep” 问题时,我们的期望并不高。最初的目标是务实的:解除最大的真实世界合约的阻塞,这些合约在我们的早期 pre-alpha 版本中无法编译。该计划很简单——溢出任何导致 “stack too deep” 的东西,并将正确性置于性能之上。如果一个合约能够编译,那已经是一个胜利,即使这意味着一些 gas 效率低下。仅仅几个月的工作,我们并不期望在相同的合约上比 solc 有显著的改进。即使我们想要改进实现,LLVM 似乎也不是一个可能的帮助候选者。EVM 是一个没有寄存器的堆栈机器,而 LLVM 是为基于寄存器的架构构建的。它的寄存器分配基础设施对于基于堆栈的目标来说似乎无关紧要。
事实证明,这两个期望都是错误的。首先,在我们测试的绝大多数真实世界合约(来自生产级项目的约 2000 个)中,solx 的性能优于 solc——即使在需要溢出的情况下也是如此。其次,LLVM 为构建生产级代码生成提供了坚实的基础——即使对于基于堆栈的架构——允许我们快速移动并以最少的自定义工作进行迭代。最初作为一个简单的实现,迅速演变成一个强大而高效的解决方案。
选择要溢出的寄存器
溢出是在堆栈化期间确定的——堆栈化是将代码从中间表示降低到 EVM 的字节码的阶段。无法通过 DUP 或 SWAP 访问的寄存器会被溢出到内存中,并在稍后需要时重新加载。这个过程会迭代地进行,直到所有 “stack too deep” 问题都得到解决。
在我们最初的寄存器溢出实现中,我们选择了一个无法通过 DUP 或 SWAP 指令访问的寄存器。虽然这种方法确保了正确性,但导致了大量的溢出。为了改进这一点,我们使用了 LLVM 的寄存器权重启发式算法,该算法根据寄存器的使用频率和活动范围来估计溢出每个虚拟寄存器的成本:
let x := add(a, b)
let y := sub(c, d)
pop(init(y)) // first use of y
// Inside a loop
...
let z := mul(x, e) // first use of x
...
pop(final(x)) // second use of x
pop(done(y)) // second use of y
// Weights:
x: high - used in the loop
y: low - used outside the loop
=> Heuristic prefers spilling y
在寄存器变得无法访问时,会检查从该寄存器到堆栈顶部的活动寄存器集合,并选择权重最低的寄存器——溢出成本最低的寄存器。这个改变,结合改进了启发式算法以考虑函数中每个寄存器的使用次数,将需要溢出的寄存器数量平均减少了 65%。为了实现这一点,我们只需要连接到 LLVM 的现有基础设施,并进行少量的自定义以调整使用计数:
/// EVM-specific implementation of weight normalization.
class EVMVirtRegAuxInfo final : public VirtRegAuxInfo {
float normalize(float UseDefFreq, unsigned Size, unsigned NumInstr) override {
// All intervals have a spill weight that is mostly proportional to the
// number of uses, with uses in loops having a bigger weight.
return NumInstr * VirtRegAuxInfo::normalize(UseDefFreq, Size, 1);
}
public:
EVMVirtRegAuxInfo(MachineFunction &MF, LiveIntervals &LIS,
const VirtRegMap &VRM, const MachineLoopInfo &Loops,
const MachineBlockFrequencyInfo &MBFI)
: VirtRegAuxInfo(MF, LIS, VRM, Loops, MBFI) {}
};
EVMVirtRegAuxInfo EVRAI(MF, LIS, VRM, *MLI, MBFI);
// Use LLVM's heuristic to assign weights to registers
EVRAI.calculateSpillWeightsAndHints();
减少溢出内存
随着实现的成熟,我们引入了 StackSlotColoring,这是一个标准的 LLVM pass,它可以为生命周期不重叠的变量重用堆栈槽——这意味着如果两个值永远不会同时处于活动状态,那么它们可以安全地被分配到相同的内存位置。以前,每个溢出都被分配一个专用的槽,导致过多的内存使用。启用着色导致在多个案例中平均减少了 25% 的已分配溢出槽。值得注意的是,这种优化是通过更新 pass 使用的分析并运行该 pass 以最小的努力实现的——展示了利用 LLVM 基础设施的优势:
// Updating the analysis
StackSlot = VRM.assignVirt2StackSlot(Reg);
auto &StackInt =
LSS.getOrCreateInterval(StackSlot, MF.getRegInfo().getRegClass(Reg));
StackInt.getNextValue(SlotIndex(), LSS.getVNInfoAllocator());
StackInt.MergeSegmentsInAsValue(LIS.getInterval(Reg),
StackInt.getValNumInfo(0));
// Running the pass
addPass(&StackSlotColoringID);
小型实现,大型基础设施
为了让你了解实现工作和代码影响,以下输出高亮显示了 solx EVM 后端中此功能引入的更改、重用了多少代码以及来自 solc 的实现。solx 的实现大约花费了两个月的时间,而最初的 solc 实现至少需要三个半月的时间,如此 PR所示——甚至可能更长。
Code changes introduced by the feature:
---------------------------------------------------------------------------------------
Language new files added blank comment code
---------------------------------------------------------------------------------------
C++ 2 100 116 495
C/C++ Header 0 7 10 55
TableGen 0 1 0 3
CMake 0 0 0 2
---------------------------------------------------------------------------------------
SUM: 2 108 126 555
---------------------------------------------------------------------------------------
Reused LLVM code:
llvm/include/llvm/CodeGen/CalcSpillWeights.h
llvm/include/llvm/CodeGen/LiveIntervals.h
llvm/include/llvm/CodeGen/LiveStacks.h
llvm/include/llvm/CodeGen/MachineBlockFrequencyInfo.h
llvm/include/llvm/CodeGen/VirtRegMap.h
llvm/lib/CodeGen/CalcSpillWeights.cpp
llvm/lib/CodeGen/LiveIntervals.cpp
llvm/lib/CodeGen/LiveStacks.cpp
llvm/lib/CodeGen/MachineBlockFrequencyInfo.cpp
llvm/lib/CodeGen/StackSlotColoring.cpp
llvm/lib/CodeGen/VirtRegMap.cpp
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 6 476 644 2650
C/C++ Header 5 212 346 567
-------------------------------------------------------------------------------
SUM: 11 688 990 3217
-------------------------------------------------------------------------------
solc:
libyul/optimiser/StackLimitEvader.cpp
libyul/optimiser/StackLimitEvader.h
libyul/optimiser/StackToMemoryMover.cpp
libyul/optimiser/StackToMemoryMover.h
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 2 59 64 456
C/C++ Header 2 24 179 85
-------------------------------------------------------------------------------
SUM: 4 83 243 541
-------------------------------------------------------------------------------
在传统模式下避免 solc 的堆栈深度限制
有人可能会认为我们只是依赖 solc 在传统模式下编译合约,而不会遇到 “stack too deep” 问题。但这并不是全部。我们还修改了 solc 本身,通过发出扩展的堆栈操作指令——特别是 SWAPX 和 DUPX ——来成功生成 EVM 汇编。这允许我们将堆栈布局解析推迟到 LLVM 后端,在那里堆栈化和溢出处理以受控和优化的方式执行。
如果你有任何想法、问题或反馈——我们很乐意听到。你可以直接在 Telegram 上联系我们。归根结底,我们希望 solx 对你有用。如果你还没有尝试过,请前往 solx.zksync.io,只需点击几下即可开始。
- 原文链接: zksync.mirror.xyz/Kj2ENE...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





