Solx:新型 Solidity 编译器 - 为何对你至关重要
- ZKsync 中文
- 发布于 2025-05-09 11:44
- 阅读 1533
Solx 是一个用于以太坊智能合约的新型优化编译器,它基于 LLVM 构建,可以提高运行时 Gas 效率,并减少手动优化的需求。文章介绍了 Solx 的优势,使用方法,以及未来发展方向,并鼓励开发者试用并提供反馈。

solx: 新的 Solidity 编译器 - 为什么它对你很重要
ZKsync
致 Solidity 开发者 - 编写更简洁的代码,花费更少的 Gas
solx 是 一个新的以太坊优化编译器,可能会改变你编写和优化 Solidity 代码的方式。solx 构建于 LLVM 之上,专注于提高 运行时 Gas 效率,同时减少手动解决问题的需求。
如果你是一名 智能合约开发者 并且 Gas 成本对你很重要,solx 可能会有所帮助 - 你过去常做的一些底层调整可能已经没有必要了,而且更多的改进正在进行中。
如果你是一名 工具或编译器工程师,或者正在思考以太坊开发者工具的未来,第二部分 探讨了 solx 作为一个模块化的编译器基础设施——准备好支持新的语言、EVM 扩展,甚至 将 Solidity 编译为 RISC-V。我们仍然建议从这里开始,看看 solx 今天在实践中能带来什么。
今天的 solx
solx 的构建是为了提高运行时 Gas 效率 - 但没有一个单独的数字可以捕捉到这种效果,因为不同的合约受益程度不同。了解影响的最好方法是使用我们准备的演示亲自尝试 solx。它经过了简化,可以快速测量 Gas,并且添加新的合约也很容易。下图显示了演示中的一些改进 - 如果看起来令人信服,请随时在此处暂停并尝试一下。
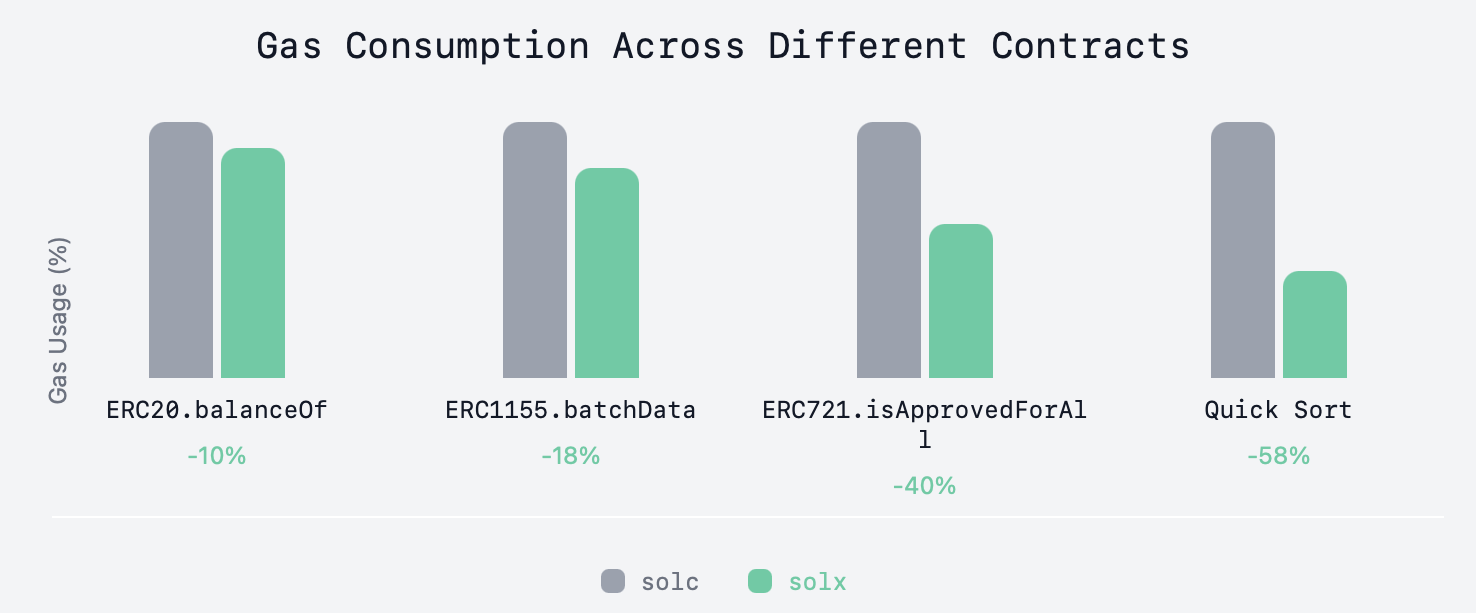
不同合约之间的 Gas 消耗
solx 目前处于 pre-alpha 阶段。 它通过了我们的内部测试套件,包括来自 Solidity 编译器存储库的所有测试以及 Uniswap V2 和 Solmate 等许多真实世界的合约。除了大型项目中出现 stack-too-deep 错误之外,我们没有观察到代码生成问题。下面是一个分解。这些数字表示每个项目中成功编译的合约数量占总数的百分比。
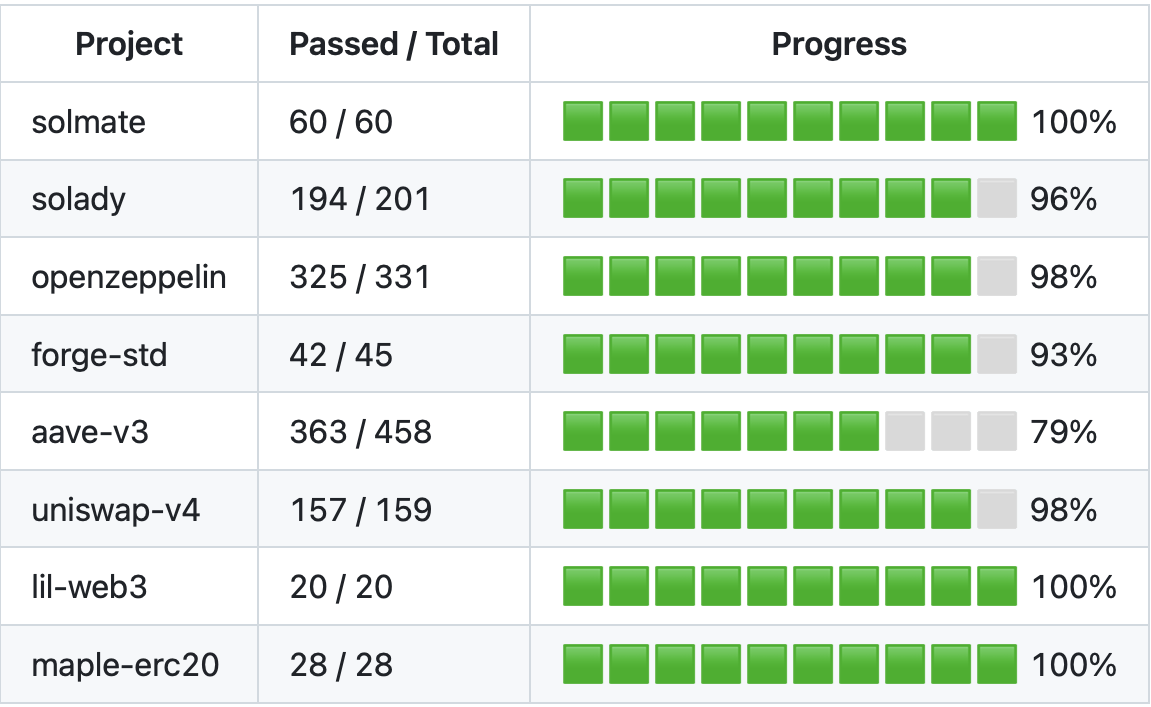
成功编译的合约数量
基本的 Foundry 集成已经可以使用。 solx 可以在 Foundry 工作流程中用作 solc 的直接替代品,尽管合约链接尚未完全支持。Hardhat 集成更具挑战性,需要进一步的工作。
尽管如此,不要因为 solx 在 Foundry 中可以作为 solc 的替代品而认为它可以直接用于生产环境。你仍然需要 重新测试你的合约。即使合约已经使用 solc 可靠地工作,solx 可能会暴露不同的边缘情况 - 反之亦然。当从 solx 切换回 solc 时,尤其是其现代优化管道 solc --via-ir --optimize,重新测试也是必不可少的。
以达到 100% 的代码覆盖率为目标,几乎可以排除编译器错误影响你的项目的可能性。模糊测试和其他形式的测试也很受欢迎 - 根据我们的经验,当开发人员严格测试自己的代码时,编译器错误根本不会被忽视。尽管如此,在我们解决剩余的 stack-too-deep 问题并在更广泛地针对真实世界的合约检查 solx 之前,我们建议暂停在生产中使用。
或者,如果你有兴趣做更多的事情而不仅仅是等待 - 让我们了解你的项目以及你使用 solx 的意图。我们可以将你的合约添加到我们的基准测试套件中,并开始针对你的用例进行优化。你可以通过 Telegram 或通过电子邮件 solx@matterlabs.dev 联系我们。
下一节将解释 solx 何时工作良好,何时可能不足,以及它在常见使用模式下与 solc 的比较。
Gas 消耗何时下降
别担心 - 我们不会在这里解释每一个经典的编译器优化。相反,本节将引导你完成 四个简单的示例,这些示例突出了 solx 在实践中可以做什么。
这些示例是有意简化的,并且侧重于极端情况,以使模式显而易见。但更广泛的指导是:
-
你的合约中的计算与存储操作越多,你从 solx 中受益的可能性就越大。
-
你的代码包含的分支和循环越多,你从 solx 中受益的可能性就越大。
-
你的代码越简洁,手动优化越少,solx 可以提供的帮助就越大。
如果你已经手动内联函数、预先计算常量或重新排序表达式以节省 Gas,那么你可能做得很好。但 solx 可能会使手动优化变得不必要。
对于每个示例,我们都会分享一个 Compiler Explorer的链接,该工具可让你检查生成的 EVM 汇编并并排比较来自不同编译器的输出。为了简单起见,我们使用默认参数将 solc --optimize 与 solx 进行比较,或者使用 solc --via-ir --optimize 与 solx --via-ir 进行比较。欢迎你尝试其他选项或 LLVM 特定的标志。
注意:solx 为 EVM 汇编输出略有不同的文本格式,但我们已尝试使其易于理解,而无需在此处解释语法。
示例 1:缓存存储变量
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
contract FactorialStorage {
uint256 private result;
// 57! 适合 uint256,58! 不适合
uint256 constant MAX_SAFE_N = 57;
function computeFactorial(uint256 n) external {
if (n > MAX_SAFE_N) {
revert("Overflow: n too large");
}
result = 1;
unchecked {
for (uint256 i = 2; i <= n; ++i) {
result *= i;
}
}
}
function getResult() external view returns (uint256) {
return result;
}
}
在 FactorialStorage 示例 ( 在 Compiler Explorer 上查看) 中, solc 的两个优化管道 — 传统路径和 --via-ir --optimize — 都将存储访问 ( sstore 和 sload) 保留在循环内。具体来说,solc 发出:
-
循环前的一个初始
sstore, -
以及每次循环迭代时的
sload/sstore对。
相比之下,solx 识别出这种模式并重构代码:
- 它使用一个临时变量进行循环计算,
- 并将
sstore从循环中移出。
请注意,unchecked 是必不可少的 — 如果没有它,编译器无法假定乘法不会溢出,因此每次迭代时更新存储对于正确性是必要的。尽管如此,即使在这种情况下,solx 也会消除循环中的 sload。
循环之前的初始 sstore 仍然存在,即使可以对其进行优化。除此之外,生成的二进制文件按以下循环工作。
uint tmp = 1;
for (uint i = 2; i <= n; ++i) {
tmp *= i;
}
result = tmp;
示例 2:常量折叠的复杂情况
// SPDX-License-Identifier: MIT
pragma solidity >=0.4.16;
contract Foldable {
function entry() public pure returns(uint64) {
return test() + test() + test();
}
function test() private pure returns(uint64) {
for (uint8 i = 0; i < 2; i++) {
uint8 j = 1;
while (j < 4) {
uint8 p = 0;
do {
p += 2;
if (p == 8)
break;
for (uint8 h = 1; h <= 4; h++) {
if (h > 2)
break;
for (uint8 k = 10; k < 12; k++) {
uint8 x = 6;
do {
x -= 1;
if (x == 0)
break;
uint8 y = 10;
while (y < 17) {
y += 1;
}
} while (true);
}
}
} while (true);
j *= 2;
}
}
return 1;
}
}
Foldable 示例 ( 在 Compiler Explorer 上查看) 展示了 LLVM 如何能够预先计算甚至可以在编译时完成的复杂表达式。
虽然带有 --via-ir --optimize 的 solc 执行了源代码中编写的大多数计算,但 solx --via-ir 检测到最终结果是 3,并将整个计算直接替换为常量。
如果你之前已将预先计算的数字放入合约中,那么你现在可以显式地编写计算 - 这通常比编写注释来解释特定数字的含义更可靠。
更重要的是,常量折叠不限于预先计算独立的常量。常量表达式通常作为其他优化过程或逻辑降级的副作用出现,例如按索引寻址数组元素。每当它们是静态可确定的时,solx 甚至可以在分支和循环中折叠此类表达式。
示例 3:循环优化
我们观察到,与 Solidity 当前的优化器相比,solx 中的没有存储交互的通用排序算法效果更好。
特别是,在我们对随机输入的基准测试中,与 solc --via-ir --optimize 相比,冒泡排序 使用的 Gas 减少了 64%,而 快速排序 使用的 Gas 减少了 51%(solc --optimize 的性能甚至更差)。
其中一个原因是,在 solc 中,数组的基地址在每次迭代时都会重新计算,而 solx 会将独立于循环计数器的计算从循环中提取出来并折叠常量。
如果使用数组进行计算是你的热代码,solx 可以自动优化它们,而无需手动重构。
示例 4:循环展开和数组
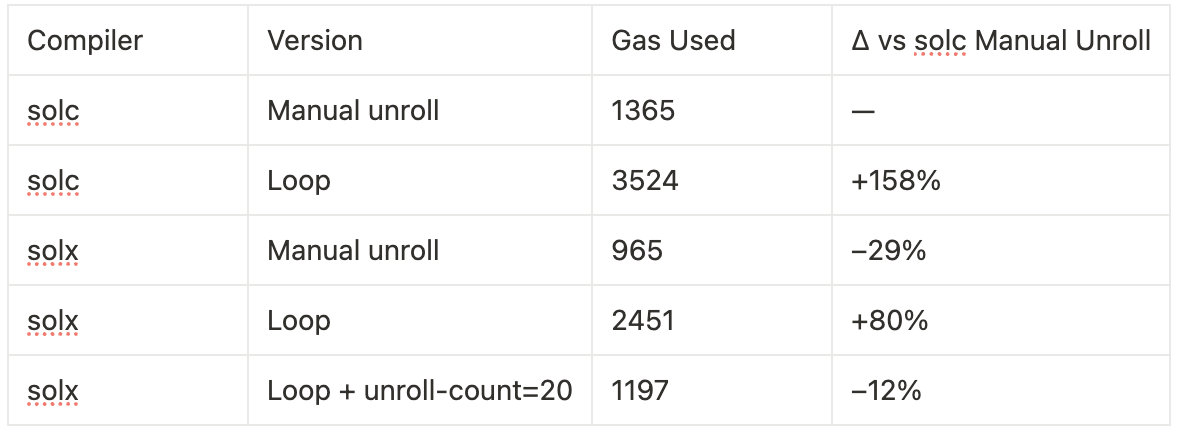
手动循环展开在 Solidity 库中很常见。在 Uniswap V4 的 TickMath.getSqrtPriceAtTick 中,显式地展开了 19 个步骤,而不是使用循环 (在 Compiler Explorer 上查看)。
我们使用 for 循环和一个常量数组重写了逻辑 (在 Compiler Explorer 上查看):
-
使用 solc,Gas 使用量从 1365 增加到 3524 - 增加了 2.5 倍。
-
使用 solx,Gas 从 965 增加到 2451 - 同样增加了约 2.5 倍。
-
但是 solx 可以在编译时知道迭代次数时 自动展开循环。
要启用此功能,请使用:
--llvm-options='--unroll-count=20'
这会将 Gas 降低到 1197 - 仅增加了 24% 而不是 150%,并且已经优于 solc 的手动展开版本。
我们默认不启用此展开,因为它涉及权衡:展开会减少运行时 Gas,但会增加字节码大小。由于 Solidity 合约的大小有限制,因此不加区别地应用此优化可能会适得其反。这就是 solx 将其留给你的原因。
剩余的一些开销来自低效的常量数组初始化 - 这是我们即将推出的基于 MLIR 的前端要改进的另一个领域。
接下来是什么
以下是我们目前认为最重要的领域 - 有些已经在进行中,另一些则在我们的列表中:
-
Stack-too-deep 解决方案 正在进行中。这是我们的首要任务,它将消除大型合约中采用 solx 的最后一个障碍之一。
-
基于 MLIR 的 Solidity IR 正在积极开发中。目前,solx 重用了 solc 前端的部分内容,直至中间表示的发出。这有助于我们更快地交付 pre-alpha 版本,但代价是二进制文件臃肿并错过了优化机会。通过用我们自己的前端替换这些组件,我们的目标是解锁 solc 无法支持的优化 - 就像常量数组折叠(见示例 4)和消除冗余堆分配一样,如下例所示。
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.20;
contract HeapLoopExample {
struct Item {
uint256 x;
uint256 y;
}
function compute() public pure returns (uint256 sum) {
for (uint256 i = 0; i < 100; ++i) {
// This allocates memory for a struct in each iteration
Item memory item = Item({x: i, y: i * 2});
sum += item.x + item.y;
}
}
}
- ethdebug 支持 指日可待。LLVM 通过优化过程跟踪调试信息;solx 将在前端发出 LLVM 调试元数据,并在后端将其转换为 ethdebug - 使优化的合约更容易调试。
我们的优先级不是一成不变的。你的意见可以帮助我们将重点放在真正需要的功能上。如果我们遗漏了什么 - 请随时告诉我们。
如何参与
如果你已经读到这里,那么你很可能对 solx 感兴趣。以下是如何开始并做出贡献:
-
🔥 尝试演示: 如果你还没有尝试过,请花点时间尝试 演示。它包括开始使用 solx 所需的一切。但不要止步于捆绑的示例——编译你自己的合约,比较 Gas 使用量、字节码和行为。这是了解 solx 可以做什么的最快方法。
-
📝 分享反馈: 在你进行实验时,请告诉我们你的发现。solx 是否减少了特定函数的 Gas?它是否在某些边缘情况下表现出意外的行为?我们正在倾听。联系我们的最佳方式是通过我们的 Telegram 频道。你也可以通过电子邮件发送问题或反馈:solx@matterlabs.dev。
-
📣 传播信息: 如果你发现 solx 有趣或有用,请与你的团队分享,发布你的发现,或者只是在开发者论坛中提及它。尝试的人越多,我们就能越快地识别出实际需求并进行改进。我们还会推广社区分享的博客文章、基准测试和反馈 - 因此,如果你撰写或录制有关 solx 的内容,请告知我们!
- 原文链接: zksync.mirror.xyz/aCTbO6...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





