Cloudflare:伟大的AI爬虫防御者
- billatnapier
- 发布于 2025-07-11 09:42
- 阅读 928
文章讨论了Cloudflare如何帮助网站过滤恶意流量和AI爬虫,特别是那些用于训练机器学习模型的爬虫。Cloudflare推出一项新服务,要求AI公司为抓取网站内容付费。文章还提到了作者使用robots.txt文件来阻止某些爬虫,并使用Cloudflare的工具来阻止不希望的AI爬虫访问其网站。

Cloudflare:伟大的 AI 机器人防御者
有好机器人和坏机器人! Google 好! ChatGTP 坏!
Cloudflare 是我最喜欢的科技公司之一。他们的 WAF(Web Application Firewall,Web应用程序防火墙)非常擅长过滤恶意流量,例如 DDoS、扫描机器人和黑客攻击。扫描机器人尤其糟糕,因为它们不仅从网站抓取信息,而且通常因持续访问而降低其性能。随着 AI 的兴起,这些机器人不再是为了搜索引擎而存档数据;他们想为机器学习模型收集数据。快速查看日志显示,很大一部分流量通常来自自动化脚本和机器人扫描。对于我的网站,在过去的一周里,我收到了 367,000 次访问(每年超过 1900 万次访问):
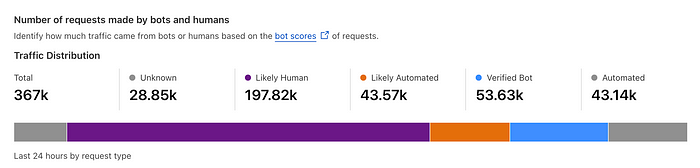
由此可见,大约 43.57K(~12%)和 53.63K(~15%)是自动化机器人。在下面,我们看到 TikTok 爬虫机器人扫描该网站 (+TikTokSpider;+ttspider-feedback@tiktok.com):
2025-06-29 00:17:07 10.0.0.106 GET /csharp/nsec_xchacha - 443 - 172.69.176.62 Mozilla/5.0+(Linux;+Android+5.0)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Mobile+Safari/537.36+(compatible;+TikTokSpider;+ttspider-feedback@tiktok.com) - 200 0 0 439
2025-06-29 00:17:10 10.0.0.106 GET /Content/bootstrap.min.css - 443 - 172.69.176.86 Mozilla/5.0+(Linux;+Android+5.0)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Mobile+Safari/537.36+(compatible;+TikTokSpider;+ttspider-feedback@tiktok.com) https://asecuritysite.com/csharp/nsec_xchacha 200 0 0 493
因此,虽然一些机器人活动可能是好的,例如对于 Google 搜索机器人,但大多数机器人只是冲击网站并显着降低其性能。总的来说,我已将 robots.txt 文件添加到网站,并阻止了许多搜集机器人:
User-agent: MojeekBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: AhrefsBot
Disallow: /
User-agent: DotBot
Disallow: /
User-agent: AwarioSmartBot
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: Qwantbot
Disallow: /
User-agent: coccocbot-web
Disallow: /
User-agent: SkyworkSpider
Disallow: /
User-agent: linkfluence
Disallow: /
User-agent: meta-externalagent
Disallow: /
User-agent: Qwantify
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: SenutoBot
Disallow: /
User-agent: DataForSeoBot
Disallow: /
User-agent: BaiduMobaider
Disallow: /
User-agent: BaiduImagespider
Disallow: /
User-agent: Baiduspider
Disallow: /
User-agent: SemrushBot
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Yandex
Disallow: /
User-agent: BLEXBot
Disallow: /
User-agent: Mail.RU_Bot
Disallow: /
User-agent: anthropic-ai
Disallow: /
?User-agent: Claude-Web
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: AwarioBot
Disallow: /
但是无法保证机器人会尊重扫描,并且它们可以轻松更改其名称。
最大的担忧是 AI 机器人正在扫描网站(尤其是新闻和媒体网站),并根据数据训练其模型。这通常会克服内容的版权限制。但是,现在,Cloudflare 已经发布了一项新服务,AI 公司将不得不付费才能扫描网站[here]:

总的来说,这是一个困难的平衡,许多网站希望他们的网站被 Google 抓取以改进搜索,但不希望被 AI 抓取。 Cloudflare 概述说,每天大约有 500 亿个请求来自 AI 爬虫,并且许多请求正在覆盖现有的机器人控制。为此,Cloudflare 为最严重的违规者建立了一个由 AI 生成的虚假垃圾网页基础设施。
对于我的网站 (ASecuritySite.com),我们可以看到过去一周大约有 39.4K 机器人访问,其中 BingBot、ChatGPT-User 和 Googlebot 是访问量最多的:
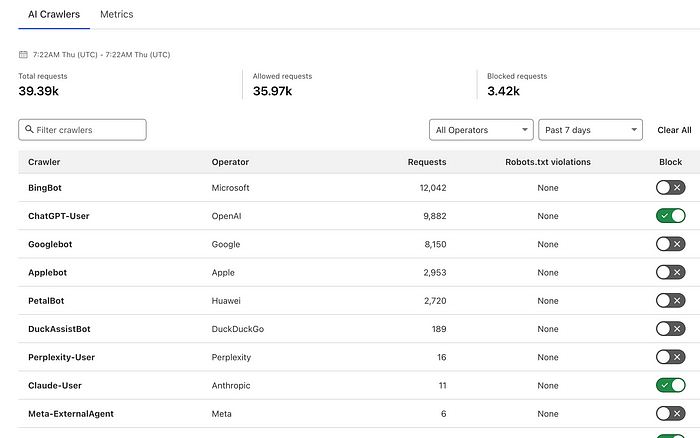
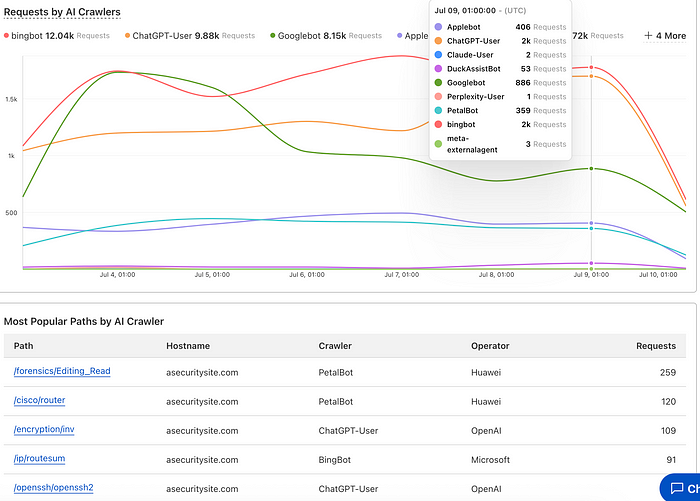
Cloudflare 现在允许用户阻止他们不想要的代理。 在上面的例子中,我已经阻止了 ChatGPT 和 Claude(但可能为时已晚,因为机器人可能已经抓取了整个网站)。 新的 AI 控制台还提供了机器人一直在抓取的页面的细分:
结论
AI 可能会摧毁我们现有的许多行业,并对教育、媒体和创意产业领域产生巨大的影响。 如果我们想保护拥有内容的权利 - 我们需要支持那些会为作者的作品付费的模型;否则,我们将进入一个由少数几家大型公司主导的世界 - 他们将在世界其他地方缴纳税款。 我们让这些机器人进来是因为我们认为它们会对我们有好处,并允许 Google 找到我们的网站。 现在,大规模搜集内容的后门已经大开 - 并且没有对其创建者的任何归属。
好的机器人? Googlebot、Bingbot 和 Slurpbot(雅虎搜索)以及 DuckDuckBot,其余的通常不太好,只是想为所有者获取内容以获取利润。
- 原文链接: billatnapier.medium.com/...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 10
- 分类: 安全
- 标签: Cloudflare WAF AI爬虫 Web应用防火墙 robots.txt





