详解 Optimism Bedrock 系列 4 - 区块推导
- aaronlee94
- 发布于 2024-01-17 11:19
- 阅读 1157
本文是 Optimism Bedrock Wrap-Up 系列的第四篇,深入分析了区块衍生过程,即提交到 L1 的批处理交易如何转换回 L2 区块。
分析区块推导过程
Onther 旨在为当前对 Optimism 和以太坊生态系统的发展感兴趣的开发者提供有价值的信息。

图。 Optimism 说明 (来源: OP LABS)
这篇文章是“Optimism Bedrock Wrap-Up 系列”的第四篇,该系列由 Onther 计划撰写的五篇文章组成。我们将分析区块推导过程,其中提交给 L1 的批处理交易被转换回 L2 区块。
考虑到本系列的相互关联性,我们建议按顺序阅读这些文章,以获得连贯的理解。
系列 1. Bedrock 升级概述:它提供了 Bedrock 升级、其组件以及在其层中部署的智能合约的概述。 Optimism Bedrock 总结系列 1
系列 2. Bedrock 升级以来的主要变化: 在本节中,我们的目标是阐明 Bedrock 升级引入的重大变化,为全面理解奠定基础,从而顺利阅读本系列接下来的部分。
Optimism Bedrock Wrap-Up Series 2 Bedrock 升级的主要变化
系列 3. 存款/取款流程分析: 我们将对存款/取款流程进行逐步分析,揭示其各层中的核心代码逻辑。
Optimism Bedrock Wrap Up Series 3 存款/取款流程
系列 4. 区块推导: 一旦在 Layer 2(Optimism 主网)上生成区块,系统就会启动一个过程,将这些区块 Roll-up 到 Layer 1。随后,在区块推导阶段,仅使用已 Roll-up 的数据重建 L2 区块。我们将提供详细的步骤指导,并在此过程中进行代码检查。
Optimism Bedrock Wrap-Up Series 4 分析区块推导流程
系列 5. Optimism Bedrock 组件的角色和行为: 作为本系列的最后一部分,我们将全面检查 Op-Batcher 和 Op-Proposer 的角色和操作逻辑。
Optimism Bedrock Wrap-Up Series 5 Optimism Bedrock 的基本组件的角色和行为
Sequencer 生成 L2 区块,而 batch submitter 的任务是将 L2 区块信息压缩并发送到 L1。
区块推导
Sequencer 生成 L2 区块,而 batch submitter 压缩并将生成的 L2 区块信息发送到 L1。 基于发送到 L1 的信息重建 L2 链的过程称为“区块推导”。 这使验证者能够对 sequencer 生成的区块执行健全性检查。 目前,一个中心化的 rollup-node 运行着该网络,处理着所有的角色和职责。
推导的先决条件包括以 2 秒的间隔生成 L2 区块(区块生成时间),并确保 L2 区块时间戳与 L1 的时间戳同步。 同步不仅仅意味着相同的时间戳,而是保证了每个链中生成的区块的逻辑时间顺序。 Bedrock 升级引入了一些对于实现此目的至关重要的概念,我们将在深入代码级分析之前解释这些概念。
Sequencing Window(排序窗口)
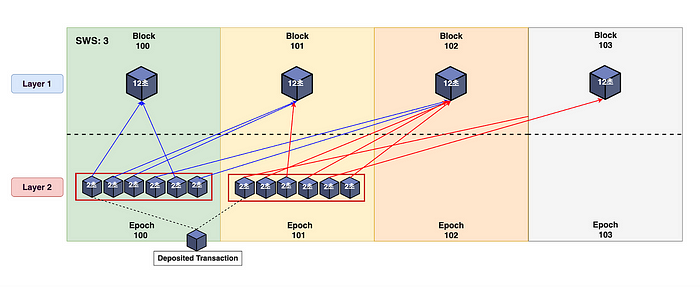
图:每个 epoch 的 L1 和 L2 区块的映射示例,其中 SWS 设置为 3。
在映射过程中,每个 L1 区块都与一个 Sequencing Epoch 相关联,并链接到一个 L2 区块。 一个 Epoch 包含指定范围内多个 L2 区块。 每个 Sequencing Epoch 都由一个 Epoch 编号唯一标识,并且在一个 Epoch 内,一个 L2 区块和一个 L1 区块之间存在一一对应的关系。
这些 Sequencing Epoch 的范围被称为 Sequencing Window Size (SWS),用于指定何时提交每个 epoch 并在特定时间间隔与 L1 同步。 因此,Epoch N 对应于 L1 区块 N,并且 Epoch N 的 L2 区块的批处理信息在 L1 区块编号 N 和 N + SWS 之间定义。 简而言之,Epoch N 的 L2 区块信息存储在编号为 N 和 N + SWS 之间的 L1 区块中。 使用上面的例子,如果 Epoch 100 中的 L2 区块映射到 L1 区块,假设 SWS 为 3,则它们仅映射到区块 100、101 和 102。
一个 epoch 中的所有 L2 区块共享相应 L1 区块的区块哈希和时间戳。 此外,epoch 的第一个区块包括通过 L1 的 OpimismPortal 发起的所有存款交易。
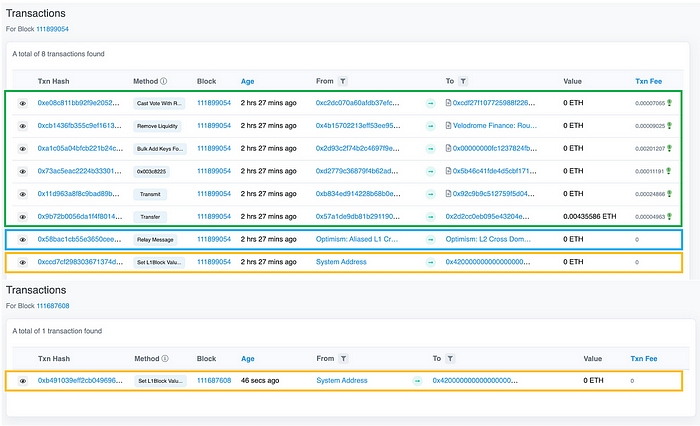
图。 每个 epoch 中第一个 L2 区块交易的示例(来源:optimistic.etherscan。 optimistic.etherscan)
提供的屏幕截图显示了两个不同 L2 区块 epoch 的第一个区块的交易日志。 检查第 111899054 个 L2 区块,底部以黄色高亮显示的交易是 L1 属性存款交易,而它上面的交易是用于存款交易的中继消息。 剩余的绿色交易包含在该区块内执行的各种其他 L2 交易。
相比之下,在第 111687608 个 L2 区块中,没有存款交易或源自 L2 内的交易,因此在该区块中仅创建了一个 L1 属性存款交易。
与特定 epoch 相关的 L2 区块的批处理信息可以提交到 Sequencing Window Size (SWS) 内的任何 L1 区块编号。 为了重建一个 epoch,必须考虑该 epoch 内的所有区块,并检索它们的批处理信息。 本质上,排序窗口减少了不确定性。 如果没有它,sequencer 可能会将区块附加到先前的 epoch,或者在跟踪特定交易时消耗不必要的资源。
现在,让我们深入研究如何处理 L2 生成的区块并将其提交给 L1。
批处理提交架构
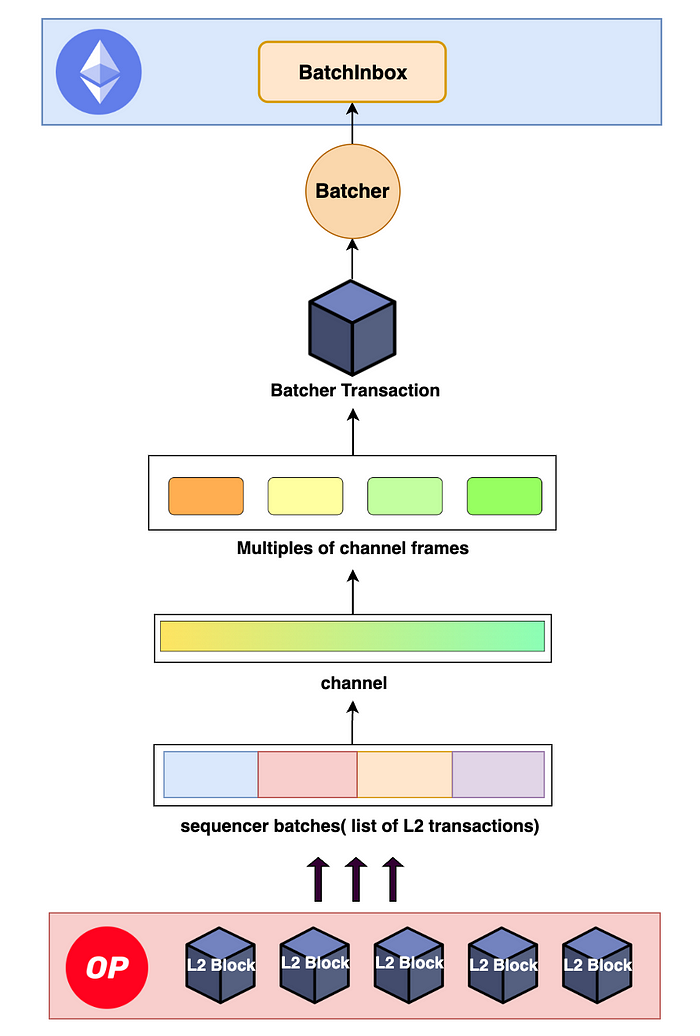
图。 要提交到 L1 BatchInbox 的 L2 区块的数据转换过程
收到 L1 交易后,Sequencer 生成 L2 区块,并将多个区块组装以形成一个 sequencer 批次。 然后,将此批次转换回数据,形成“channel(通道)”的形状,该通道进一步拆分为多个 channel frames(通道帧)。 这些帧被转换回 batcher 交易,最终由 batch submitter 提交给 L1 的 BatchInbox,从而完成 rollup 过程。
L2 区块和批处理之间的区别在于 L2 区块包含状态根,而批处理仅包含交易数据,例如 L2 区块编号或时间戳。 本质上,批处理提供了一种高效且透明的方式,可以从 L1 引用到 L2 区块,而无需状态信息。
批处理提交 Wire Format
提交批处理与 L2 链的推导密切相关,类似于反向推导。 本质上,L2 链推导旨在从提交给 BatchInbox 的 batcher 交易中重建 L2 区块,以用于健全性检查。
在深入代码分析之前,让我们使用 Optimism 提供的图示来探索整个推导过程。
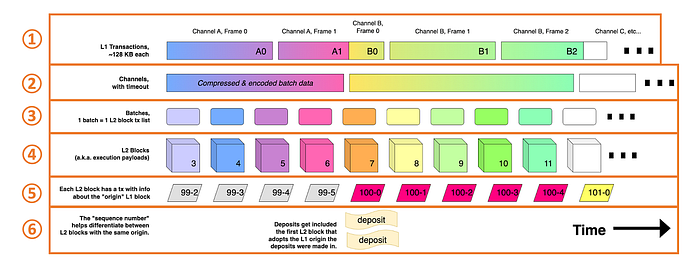
图。 说明区块推导过程的示意图(来源:github link)
① 说明了 batcher 交易。在给定的示例中,通道中的所有帧都是有序的,但通常,它们是混合的。但是,顺序不会影响它们,因为它是在压缩和编码过程之前。例如,如果在第二个交易中交换了 A1 和 B0,则不会对结果产生影响。
② 重新排序分割的通道帧以重建通道。
③ 再次从通道中提取压缩的批次。
④ 从每个批次中提取交易。(虽然批次和区块具有 1:1 的映射,但如果 L1 中的交易之间存在“间隔”,则可能会插入空区块)。
⑤ 表示 L1 属性存款交易,记录有关与每个 L2 区块的 epoch 相对应的 L1 区块的信息。第一个数字 (99) 表示 epoch 编号,第二个数字 (2) 表示 epoch 中的顺序。
⑥ 表示从 L1 存款合约 ( OptimismPortal) 事件生成的user-deposited交易。
健全性检查
我之前提到“sanity-check(健全性检查)”作为区块推导的目的。 最初,我认为区块推导过程旨在验证先前创建的 L2 区块的正确性或检测篡改。 但是,由于批处理是基于 sequencer 生成的 L2 区块创建的,因此验证单个区块或交易似乎不合逻辑。
因此,将区块推导视为确保系统没有错误配置 forkchoice 状态(代表交易的初始形式)和提交给 L1 的实际批处理之间的区块的过程,更容易理解。
另一个方面是检测是否发生了 L1 链重组,从而有助于跟踪 L1 区块的最终性,并提供核心功能来最终确定区块类型(有关 L2 区块的最终性,请参阅 系列 2 中的“Rollup 节点中的区块推导”)。 这个过程最终决定了一个 L2 区块是否可以被重组。 现在,让我们深入研究代码中的检查过程。
L2 链推导 Pipeline
在本节中,我们将逐步了解实际的推导过程,其中提交给 L1 的 batcher 交易通过推导 pipeline 架构被重新创建为 L2 链。
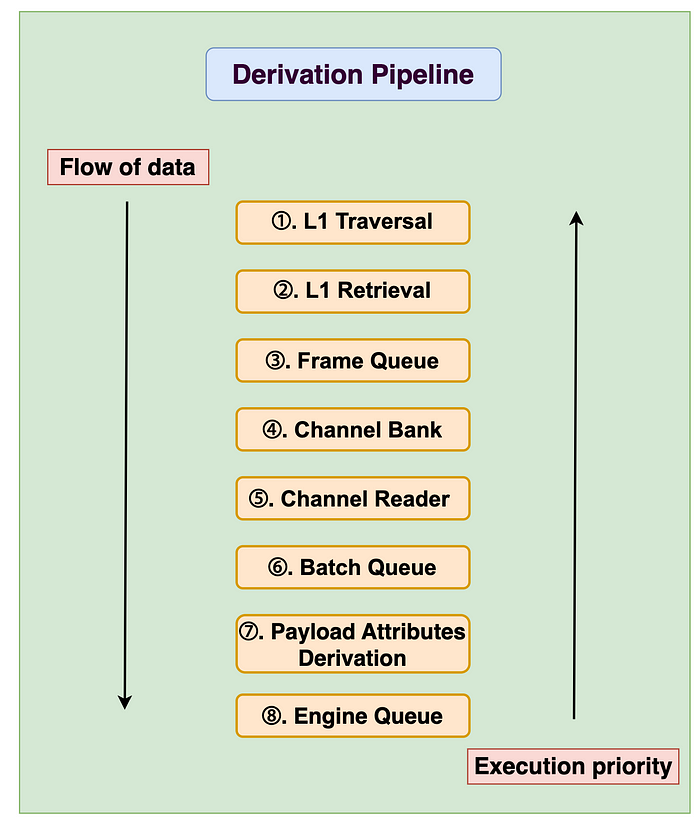
图。 推导 pipeline 期间与数据流相反的执行优先级。
在上图中,数据流是顺序的,从步骤 1 开始,其中提交给 L1 的 batcher 交易被转换回 L2 区块。 但是,执行优先级与步骤 8(引擎队列)相反,这意味着如果每个步骤中没有更多数据要处理,它会从上一步骤请求数据,并接收要在步骤中转换的数据。 换句话说,当在每个步骤中接收和转换数据时,函数调用从引擎队列中按顺序调用。 因此,如果你想知道一个步骤是如何被调用的,你可以看到在下一步骤中调用了什么方法,而不是上一步骤。
①. L1 Traversal(L1 遍历)
L1 遍历阶段仅读取下一个 L1 区块的header信息。
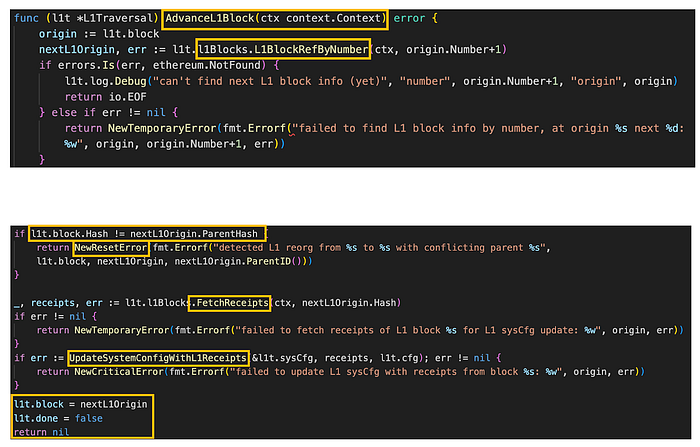
图。 l1_traveral.go/AdvanceL1Block (来源: github link)
AdvanceL1Block 检查当前 L1 区块哈希是否与下一个 L1 区块的父哈希匹配,如果不匹配,则表示发生了 L1 重组并返回 NewResetError。
如果父哈希匹配,则使用 FetchReceipts 方法检索下一个 L1 区块的 receipts。 然后,使用 UpdateSystemConfigWithL1Receipts 函数继续更新 L1 系统配置。 最后,将区块的 header 更新到 L1Traversal 结构。
②. L1 Retrieval(L1 检索)
L1 检索步骤涉及从 L1 遍历步骤中获取的区块 header 信息中提取 batcher 交易数据。 在提取期间必须满足两个条件:
- 接收者必须与 BatchInbox 地址匹配。
- 发送者必须与 batcher 的地址匹配。
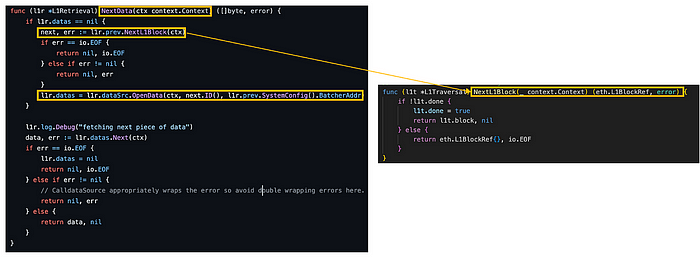
图。 l1_retrieval.go/NextData (来源: github link), l1_traveral.go/NextL1Block (来源: github link)
NextData 函数评估是否从 L1 区块检索 header 信息。 如果信息不可用,它会在 L1Traversal 中触发 NextL1Block 方法。
相反,如果区块 header 信息可用,它会利用 dataSrc 的 OpenData 方法来访问上下文、下一个 L1 区块 ID 和 batcher 合约地址。 通过从区块 header 中读取此信息,可以促进提取 batcher 交易数据。
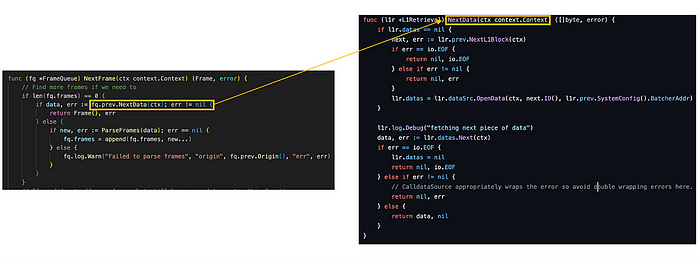
图。 frame_queue.go/NextFrame (来源: github link), l1_retrieval.go/NextData (来源: github link),
此外,L1 检索步骤的 NextData 方法在后续“Frame Queue(帧队列)”步骤的 NextFrame 函数中用于传输数据。 与其他步骤类似,通过观察 prev. 字段可以轻松识别“下一步”中调用的方法。
以下是几个有助于 L1 检索步骤的对象。
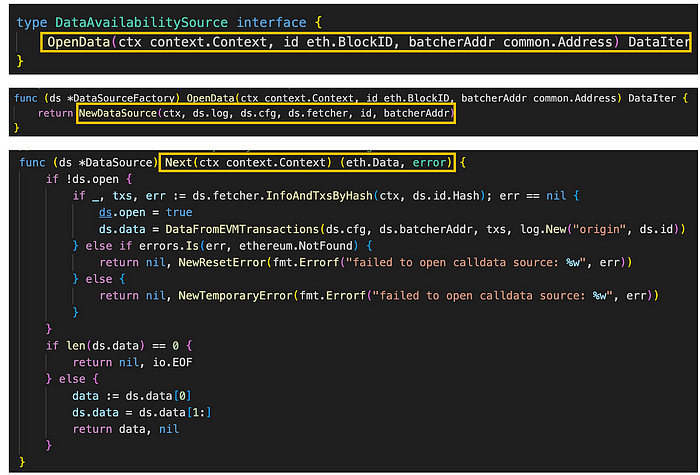
图。 l1_retrieval.go/DataAvailabilitySource (来源: github link), calldata_source.go/OpenData, Next (来源: github link)
DataSourceFactory 通过上面调用的 OpenData 方法将 context.Context、eth.BlockID 和 common.Address 对象作为参数,并返回一个 Datalter。 为此,OpenData 方法迭代下一个 L1 区块 ID 和 batcher 合约地址,并使用 NewDataSource 函数和传入的参数创建一个 DataSource,从而返回一个 DataIter。
然后,Next 方法负责从传入的数据中返回下一个数据。 它检查是否还有任何数据要检索,如果没有,则获取下一个 L1 区块,如果有,则获取下一个数据。 这会一个一个地返回 batcher 交易。
③. Frame Queue
Frame Queue 将 batcher 交易解码为 channel frame,然后将其插入到以下步骤中。
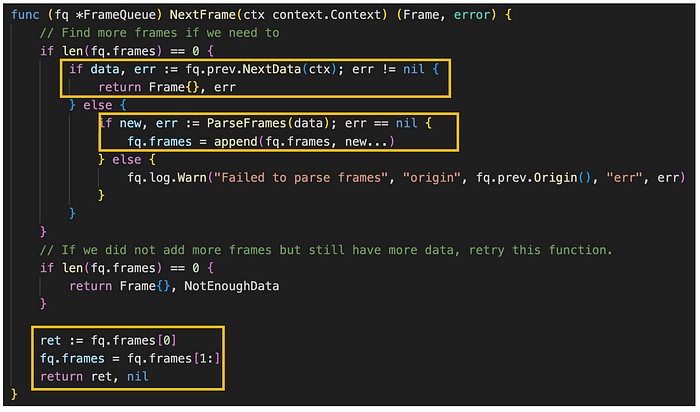
图。 frame_queue.go/NextFrame (来源: github link),
NextFrame 方法也在 Channel Bank 步骤的 NextData 方法中调用,负责返回帧队列中的下一帧。
最初,当队列中没有帧时,NextData 函数检索在 L1 检索步骤中准备的 batcher 交易。 随后,它将 batcher 交易解码为 channel frame,并使用 ParseFrames 将它们填充到帧中。
④. Channel Bank
按顺序在channel队列中列出channel frame。
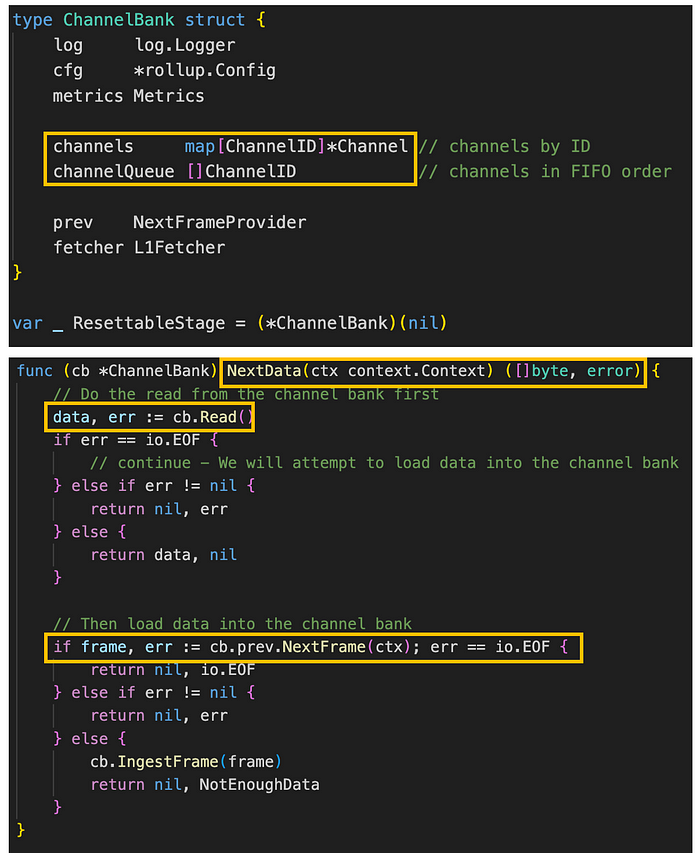
图。 channel_bank.go/ChannelBank, NextFrame (来源: github link),
NextData 首先使用 Read 方法从 channel bank 对象读取数据,并将数据传递到 channel bank。 如果 channel bank 中没有剩余数据,它会使用 channelBuilder 的 NextFrame 方法将数据加载到 channel bank 中。 加载的数据在 channel 队列中收集并以 FIFO(先进先出)顺序处理。
以下是关于 Read 过程的更详细的介绍。
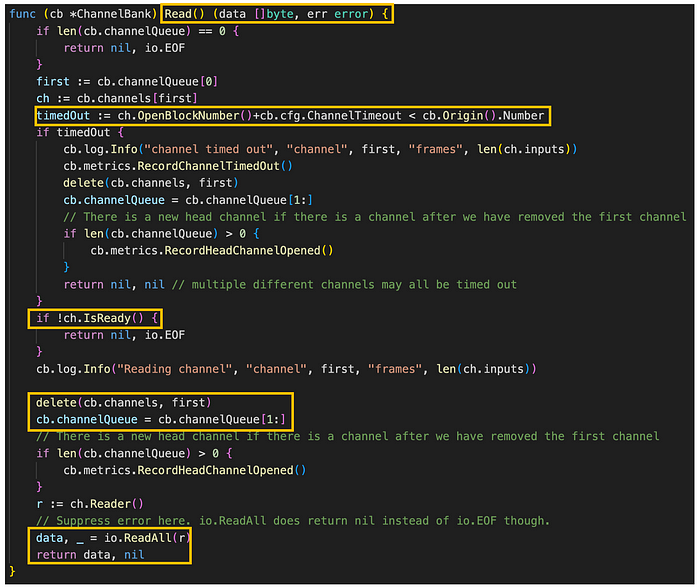
图。 channel_bank.go/Read() (来源: github link),
Read 方法负责读取 channel bank 中第一个 channel 的原始数据。 该方法首先检索队列中最新的 channel,并检查是否有超时,以确保该 channel 具有可读数据。
一旦找到 channel 并准备好进行读取,它将从 ChannelBank 的 channels 字段和 channelQueue 字段中删除。 随后,使用 io.ReadAll 函数读取该 channel 中的所有数据。
如果在读取过程中返回 io.EOF,则 Frame Queue 步骤会获取一个新的 channel frame 并将其插入到 channel 中。 在这种情况下,channel frame 结构如下所示:
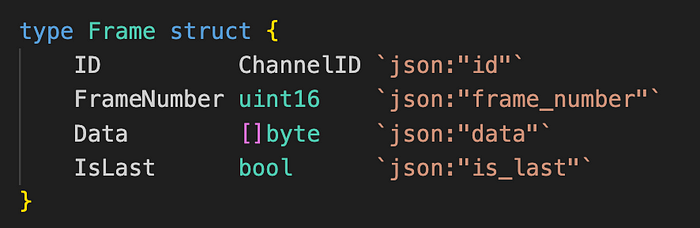
图。 frame.go/Frame (来源: github link)
Frame 结构。
- channel_id:标识 channel 的 ID。
- frame_number:channel 中帧的索引。
- frame_data:channel 帧的数据。
- is_last:一个标志,指示最后一帧,如果是最后一帧则为 1,否则为 0。
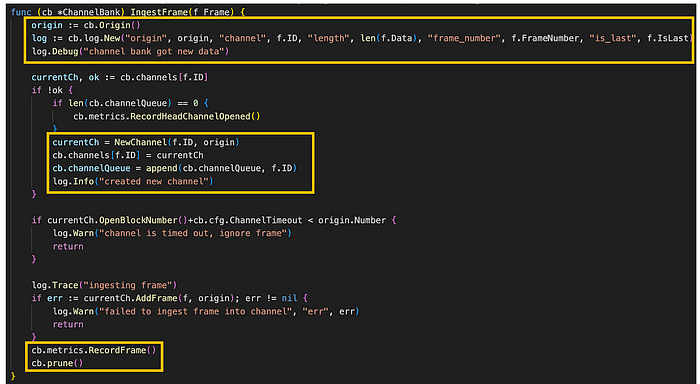
图。 channel_bank.go/IngestFrame (来源: github link)
IngestFrame 最初检查帧的 channel_id 值,以确定当前 channel 队列中是否已存在具有相同 ID 的 channel。 如果没有,它会使用 NewChannel 函数生成一个新的 channel,并将其包含在 ChannelBank 的 channels 字段中。 随后,它将新创建的 channel_id 写入 channelQueue 字段,并将帧添加到 channel 队列。 之后,执行 ChannelBank 的 prune 方法。
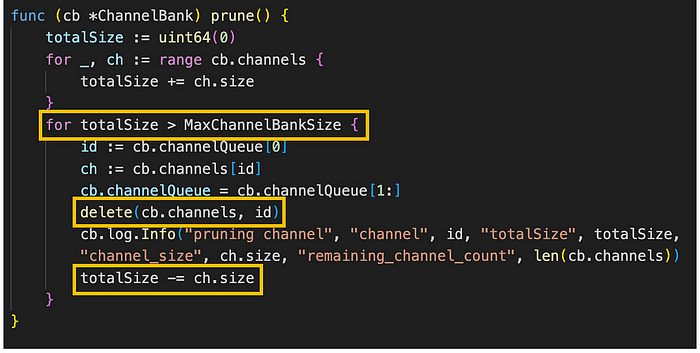
图。 channel_bank.go/prune (来源: github link)
prune 方法修剪 channel bank,使其不超过最大大小。 它首先计算 ChannelBank 的 channels 字段中所有 channel 的总大小。 然后,它循环直到 channel 的总大小小于或等于最大 channel bank 大小。
每次循环迭代时,该方法都会从 ChannelBank 的 channelQueue 字段中检索最新的 channel_id,从 channels 字段中检索具有该 ID 的 channel,并从这两个字段中删除该 channel ( MaxChannelBankSize: 100,000,000 字节)。
⑤. Channel Reader (批处理解码)
从 Channel Bank 获取 channel,并进行解压缩和解码过程。
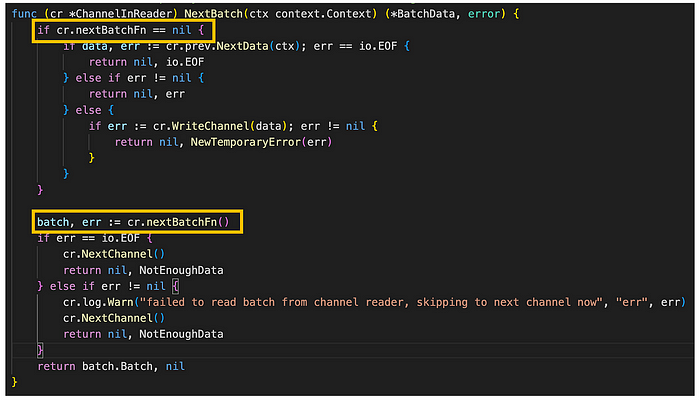
图。 channel_in_reader.go/NextBatch (来源: github link)
NextBatch 方法在 Payload Attributes Derivation 步骤的 NextAttributes 方法中调用,任务是从 channel 中读取下一个批次。 最初,它检查 ChannelInReader 的 nextBatchFn 字段是否为 nil(表示先前的批次没有结束)。 在这种情况下,它会读取下一组数据并将其存储在 channel 中。 相反,如果 nextBatchFn 字段不为 nil,它会在 channel 中找到下一个批次并将其返回。
负责读取批次的实体称为 Reader,并定义为一个函数。 这是因为处理批次涉及不仅仅是简单的复制; 它需要对数据进行解压缩和解码。 因此,BatcherReader 函数概述如下。
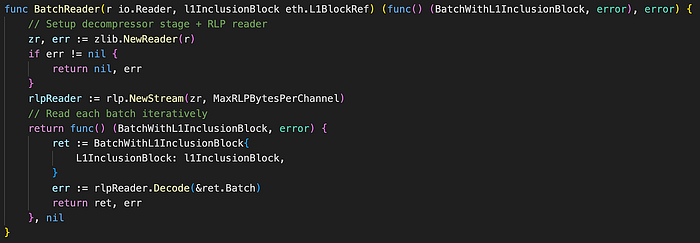
图.channel.go/BatchReader (来源: github link)
BatchReader 函数通过利用 zlib.NewReader 函数和一个 io.Reader 对象来启动解压缩阶段。 随后,它通过 rlp.NewStream 函数建立一个 RLP 读取器,合并解压缩阶段以促进解压缩。 然后,该函数根据配置的设置从 RLP 读取器中按顺序读取每个批次。 在读取每个批次时,它会使用 rlpReader.Decode 方法对批次数据进行解压缩和解码。 最终,它通过将其存储在 BatchWithL1InclusionBlock 对象中来返回结果。
⑥. Batch Queue
BatchQueue 根据时间戳和header是否安全/不安全来重新排序下一个批次。
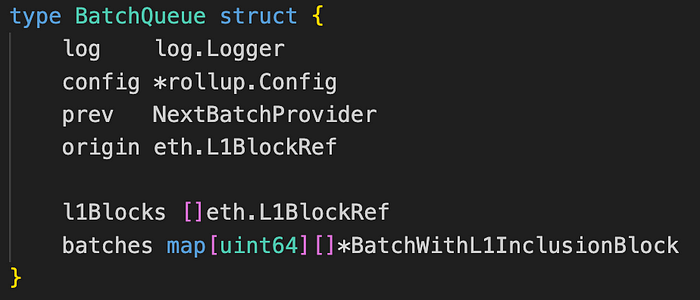
图。 batch_queue.go/BatchQueue (来源: github link)
BatchQueue 结构。
- log:用于记录消息。
- config:一个表示 BatchQueue 的形状或配置的对象。
- prev:一个 NextBatchProvider 对象,用于提供下一个批次。
- origin:一个 eth.L1BlockRef 对象,表示 L1 区块的引用。
- l1Blocks:表示 L1 区块。
- batches:一个将 uint64(批次索引)键映射到 BatchWithL1InclusionBlock 对象切片的字段。
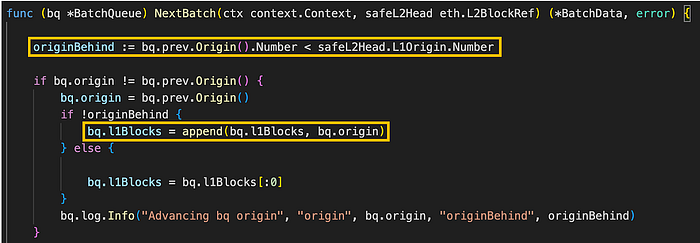
图。 batch_queue.go/BatchQueue (来源: github link)
BatchQueue 结构中的 NextBatch 方法负责从 BatchQueue 提供下一个批次的数据。 最初,它检查 BatchQueue 对象的 origin 是否晚于 L2 安全头的 origin。 此条件意味着正在处理的批次比安全 L2 头的 timestamp 更新。 如果属实,则将其视为安全批次,并且 origin 会提前以将更多数据加载到批次队列中。
⑦. Payload Attributes Derivation(Payload 属性推导)
将上一步导入的批次转化为 Payload Attributes 结构的实例。 Payload 属性包括交易和其他区块输入,例如时间戳、费用、收款人等,这些属性应合并到区块中。
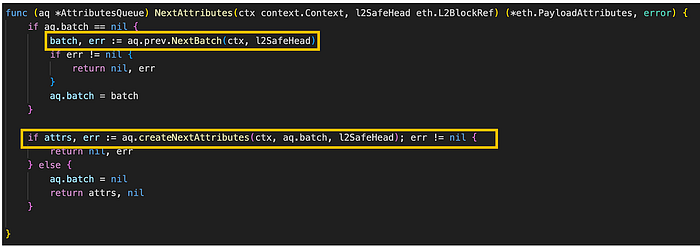
图。 attributes_queue.go/NextAttributes (来源: github link)
NextAttributes 方法验证 AttributesQueue 的批处理字段是否为 nil。 如果是,它会在 prev 字段中调用 NextBatch 方法以获取下一个批次。
随后,它调用 AttributesQueue 对象的 createNextAttributes 方法来生成 payload 属性。 此方法接收诸如 context.Context、BatchData 和 eth.L2BlockRef 之类的参数,并返回 PayloadAttributes。
然后,createNextAttributes 方法继续为即将到来的 L2 区块创建 payload 属性。
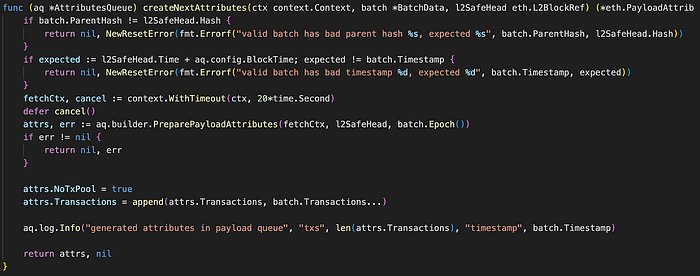
图。 attributes_queue.go/createNextAttributes (来源: github link)
createNextAttributes 方法负责从批次数据和 L2 安全头生成下一组 payload 属性。 创建新的 payload 属性类似于向 AttributesQueue 添加新的队列。 AttributesQueue 中的 builder 对象利用 PreparePayloadAttributes 方法来获取下一个 L2 区块的 payload 属性。 随后,它捕获相应 PayloadAttributes 对象中批次的交易数量和时间戳信息。 最后,它生成并返回一个新的 PayloadAttributes 对象。
⑧. Engine Queue
将上一步中的 payload 属性数据传输到执行引擎以创建 L2 区块。
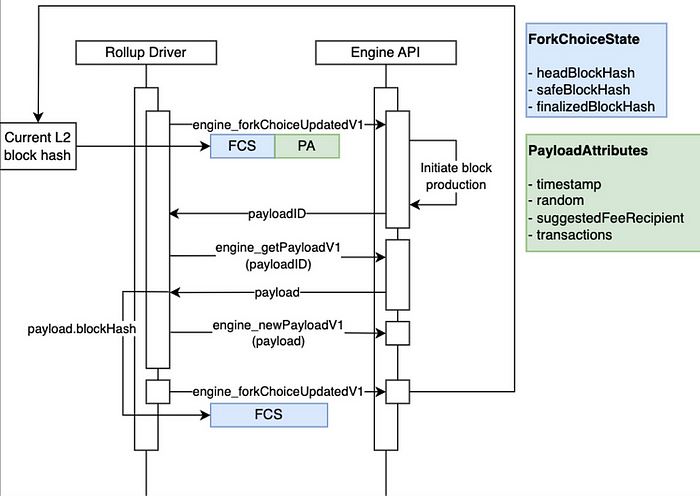
图。 Rollup 节点和引擎 API 交互架构 (来源: github link)
为了与执行引擎交互,采用了各种 API,每个 API 如下所述:
- engine_forkchoiceUpdateV1:如果链头不同,则此 API 会更新链头,如果 payload 属性不为 null,则指示引擎构建执行 payload。
- engine_getPayloadV1:此 API 检索先前构造的新的执行 payload。
- engine_newPayloadV1:此 API 执行创建的执行 payload 以生成区块。
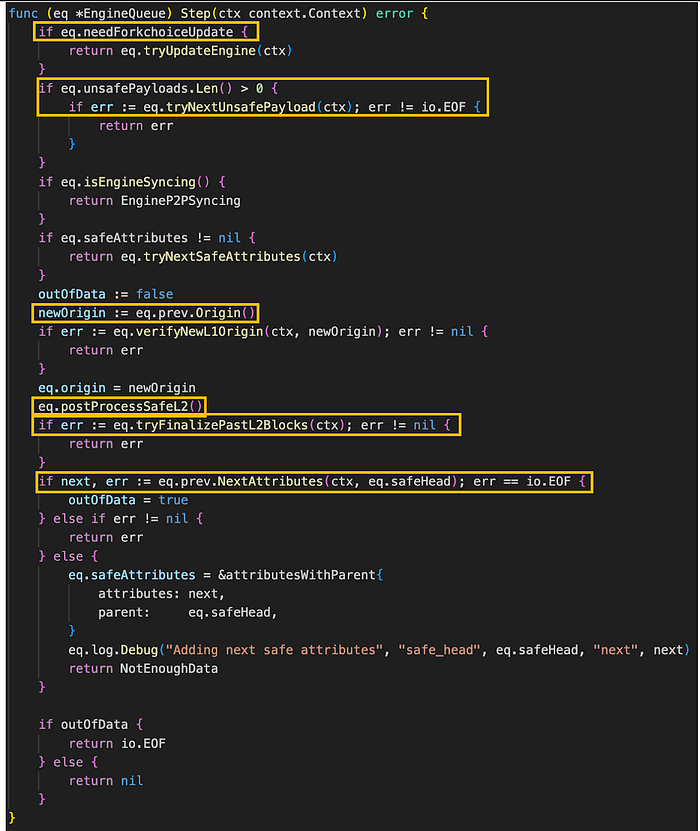
engine_queue.go/Step (来源: github link)
Step() 方法利用 EngineQueue 中的多个字段来指导通过以下步骤生成区块的过程:
- 如果 needForkchoiceUpdate 字段为 ‘true’,则调用 EngineQueue 的 tryUpdateEngine 方法来更新引擎。
- 检查 EngineQueue 的 unsafePayloads 字段的长度是否大于零,调用 tryNextUnsafePayload 来处理下一个不安全的 payload。
- 确保 EngineQueue 的 safeAttributes 字段不为 nil。 如果是,则调用 tryNextSafeAttributes 方法来处理下一个安全的属性。
- 调用 prev 字段的 origin 以将 newOrigin 变量设置为上一个区块的 origin。 随后,调用 verifyNewL1Origin 方法以确认 L2 不安全头的 origin 是否与 newOrigin 匹配。 这是一个验证过程,用于确保引擎队列正在为新队列处理正确的区块顺序。
- 调用 postProcessSafeL2 以验证最新创建的 L1 区块是否与最后一个 L2 安全头正确对齐。
- 最后,执行 tryFinalizePastL2Blocks 以最终确定同步到当前点的 L2 区块,并调用 NextAttributes 以继续处理下一个安全属性。
然后,当发生 fork choice 更新时,将执行 tryUpdateEngine 方法以启动同步操作。 这在以下情况下发生。
- 将 L2 区块更新为“安全”状态。
- 将 L2 区块更新为“已最终确定”状态。
- 重置 pipeline。
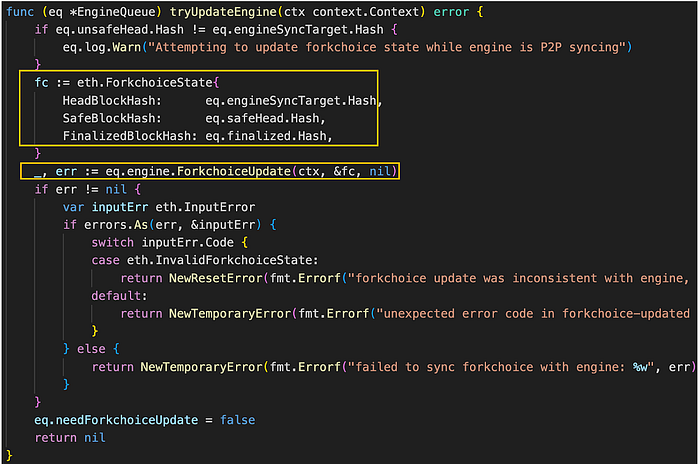
engine_queue.go/Step (来源: github link)
最初,tryUpdateEngine 方法验证 L2 不安全头是否与引擎同步目标的哈希不同。 如果它们匹配,它会使用 EngineQueue 的头区块哈希、安全区块哈希和已完成区块哈希来构造 ForkchoiceState 对象。
随后,在引擎字段上调用 ForkchoiceUpdate 方法以将引擎更新为当前 ForkchoiceState。 验证需要同步的数据,并且引擎字段的状态与 L1 区块同步。 这可以概念化为管理引擎队列中的队列和处理交易。
接下来,如果从 L1 区块检索到的最新不安全头在安全头之前,则检查现有的不安全 L2 链以确定它是否与从 L1 数据推导的 L2 输入对齐,然后合并。
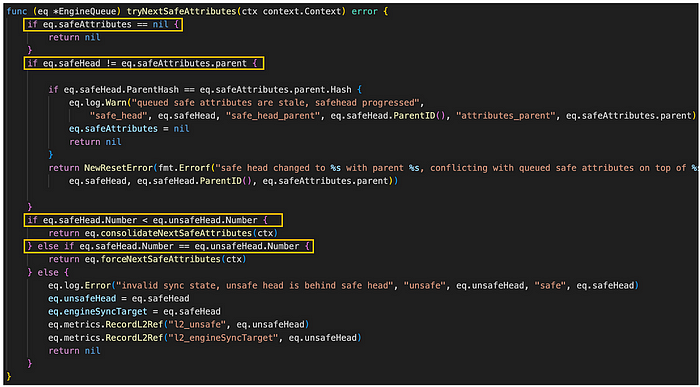
engine_queue.go/trySafeNextAttributes (来源: github link)
tryNextSafeAttributes 方法尝试从引擎队列检索下一个 safeAttributes 并对其进行处理。 最初,它检查 safeAttributes 字段是否为 ‘nil’,并且还验证 EngineQueue 的 safeHead 字段是否等于 safeAttributes 字段的父级。 如果 safeAttributes 字段不是 ‘nil’ 并且 safeHead 字段等于父级,则表示不安全头领先于安全头,从而提示合并。 在这种情况下,合并意味着最新不安全头与安全头匹配,并且此不安全头也被认为是安全的,随后成为新的安全头。
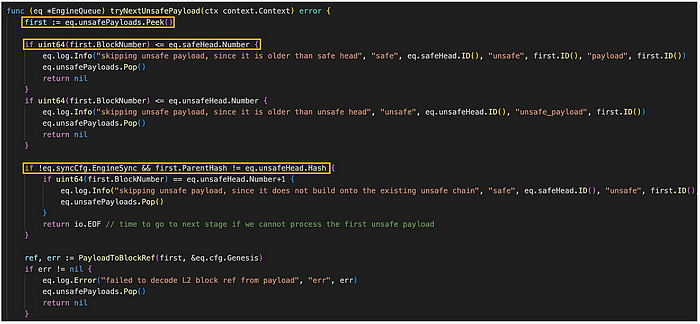
engine_queue.go/tryNextUnsafeAttributes (来源: github link)
tryNextUnsafePayload 方法执行以下操作顺序:
- 它在 EngineQueue 的 unsafePayloads 字段上调用 Peek 以检索引擎队列中最新的 unsafePayload。
- 随后,它检查该 unsafePayload 中的区块数量是大于还是小于安全头或不安全头的数量。 此验证检查在当前队列中将 unsafePayload 作为 L2 区块时可能出现的错误。
- 在没有错误的情况下,它在引擎字段中调用 NewPayload 以将最新的 unsafePayload 合并到引擎中。 NewPayload 方法需要 context.Context 和 payload 作为参数,并且它返回一个 *eth.Status 和一个 error 对象。
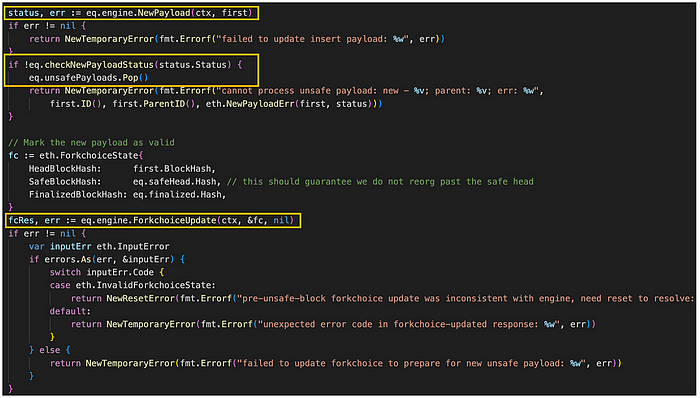
engine_queue.go/tryNextUnsafeAttributes (来源: github link)
如果在插入过程中没有错误,它将使用头部区块哈希、安全区块哈希和已完成区块哈希作为参数来组装 ForkchoiceUpdate 对象。 然后,通过调用 engine 字段的 ForkchoiceUpdate 方法来利用此对象来更新 fork choice。
最终,ForkchoiceUpdate 方法需要 context.Context、*eth.ForkchoiceState 和 *eth.ForkchoiceUpdateOpts 作为参数。 它返回一个 *eth.ForkchoiceUpdateResult,从而有助于重新创建 L2 区块。
结束语
总之,我们深入探讨了将提交给L1的批处理交易转回L2区块的过程,在每个步骤进行合理性检查,并检查区块类型以确认L2区块的最终性。尽管引入了新概念,但基本目标保持不变:将提交给L1的批处理交易重构为L2区块——反向组装。Optimism采用这种方法以确保数据的有效性,验证者对将L2生成的区块提交给L1的过程进行双重检查。即将发布的Optimism Bedrock Wrap Up系列的第五篇也是最后一篇将全面探讨Op-Node、Op-Batcher和Op-Proposer的角色及其功能。
引用
**在Optimism上已经挖掘和确认的交易。该列表包括发送ETH的交易以及...
optimism/op-node/rollup/derive/l1_traversal.go
optimism/op-node/rollup/derive/calldata_source.go
optimism/op-node/rollup/derive/channel_bank.go
optimism/op-node/rollup/derive/frame.go at develop
*optimism/op-node/rollup/derive/channel_in_reader.go
**optimism/op-node/rollup/derive/batch_queue.go
**optimism/op-node/rollup/derive/attributes_queue.go
optimism/op-node/rollup/derive/engine_queue.go at develop · ethereum-optimism/optimism
- 原文链接: medium.com/tokamak-netwo...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~



