以太坊上的大区块扩散和有机大区块 - 分片
- 以太坊中文
- 发布于 2023-11-09 21:20
- 阅读 1061
Codex团队在以太坊主网上发现了大量超过250KB的“有机大区块”,并分析了这些区块的传播时间。研究测量了这些区块在不同地理位置的传播延迟,并比较了五种不同的共识层客户端如何反映这些差异。结果表明,当前以太坊网络可以容纳1MB到2MB的大区块,这对即将到来的EIP-4844(预计平均区块大小约为1MB)是个好消息。

此分析由 @cskiraly 和 @leobago 完成,并得到了来自 @dryajov, @dankrad, @djrtwo, Andrew Davis, 和 Sam Calder-Mason 的支持和反馈。
Codex 团队正在研究以太坊扩容的数据可用性抽样(DAS)。这项研究的一部分是开发一个模拟器,可以为我们提供一些良好的估计,即需要多长时间才能将一个 128 MB 的巨大区块(包括纠删码数据)传播到整个网络。该模拟器已经开始产生结果,但在本文中,我们希望关注这项研究的两个副产品:现有以太坊主网上大区块扩散延迟的特征,以及以太坊主网上有机大区块的存在及其影响。
人为地膨胀区块
每个模拟器都需要进行评估,至少部分要通过真实的测量来证明模拟器产生的结果是准确的。为了验证我们的模拟器,我们开始研究以太坊基金会(EF)所做实验产生的数据。该实验在 5 月 28 日和 6 月 11 日进行,包括向以太坊主网注入大区块。目标区块大小的范围从 128 KB 到 1 MB。这些区块通过使用 CALLDATA 向其中添加随机字节,并以稳定的 64 KB 交易流的方式人为地膨胀。作为参考,以太坊的平均区块大小为 100 KB。目标是测量这些大区块到达位于不同世界区域的多个节点的时间。更准确地说,EF 在三个不同的大洲部署了 15 个节点(称为 Sentry 节点),具体位置是:悉尼、阿姆斯特丹和旧金山,以观察网络延迟对证明和区块传播的影响。这些 Sentry 节点都运行着 Xatu,这是一种网络监控和数据管道工具。每个位置都有五个节点在运行,每个共识层(CL)客户端各一个:Prysm、Lighthouse、Teku、Nimbus 和 Lodestar。下表描述了每个客户端使用的确切版本。
| 客户端 | 版本 |
|---|---|
| Prysm | develop-f1b88d0 |
| Lighthouse | stable-7c0b275 |
| Teku | master-fccbaf1 |
| Nimbus | stable-748be8b |
| Lodestar | unstable-375d660 |
偶然发现有机大区块
在进行 DAS 研究的同时,MigaLabs 团队也在分析区块大小和每个区块的交易数量,以及其他数据点。通过查看实验日期之外的区块大小,我们发现在以太坊主网上存在许多大区块。在与 EF 的研究人员确认这些区块不是人为膨胀之后,我们开始研究这些有机大区块出现的频率。在过去的六个月里,从 2023 年 3 月 1 日到 2023 年 8 月 31 日,我们总共发现了 109,504 个大小超过 250 KB 的区块,约占该时间段内 1,323,034 个 slot 的 8.2%。在这六个月中观察到的最大区块(#17968783)是在 8 月 22 日产生的,其大小为 2.3 MB,这非常令人惊讶。一个区块中使用的最大 gas 量为 30,000,000,CALLDATA 的成本为每字节 16 gas,这应该导致最大区块大小约为 1.8 MB。但是,每字节 16 gas 是非零字节的成本,而零字节的成本为 4 gas。这意味着 CALLDATA 中包含大量零的区块可能会超过 1.8 MB,理论上,甚至可以创建一个超过 7 MB 的区块。
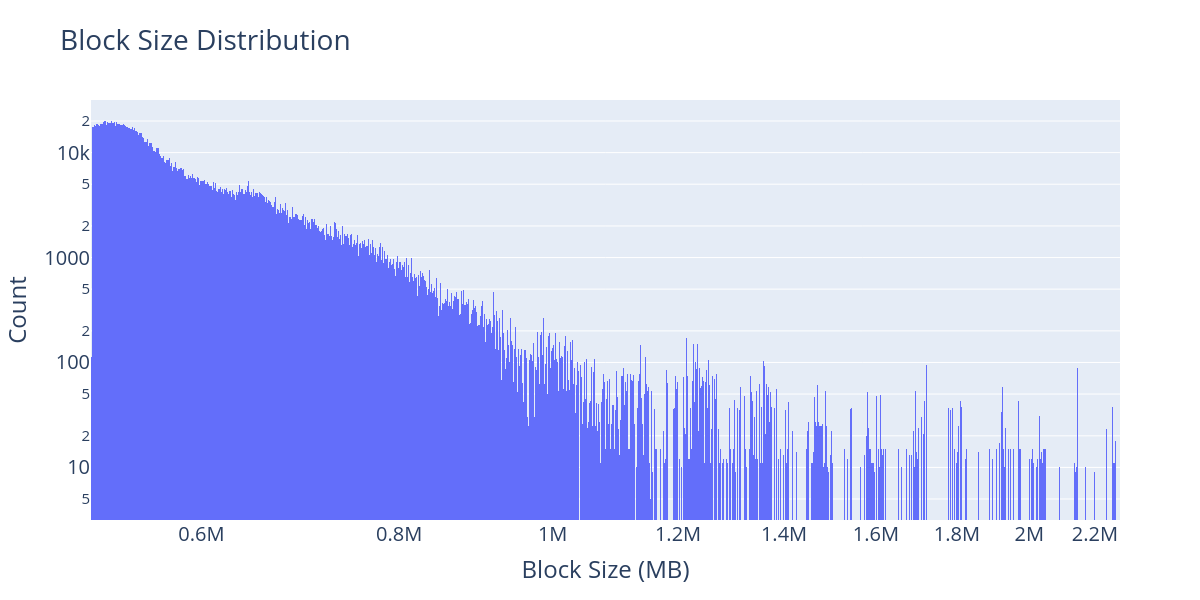 \
blockSizeLog-11200×600 26.3 KB
\
blockSizeLog-11200×600 26.3 KB
上图显示了从 3 月 1 日到 8 月 31 日超过 250 KB 的区块的分布;请注意,我们在 y 轴上使用对数刻度。在这六个月中,15 个 Sentry 节点一直在运行并记录收到区块的确切时间。这使我们能够根据不同 CL 客户端的角度,对区块传播时间进行详细分析,具体取决于它们的大小和地理位置。
地理位置的影响
我们分析了在三个不同位置报告区块的时间。请注意,这三个区域几乎完美地相隔 8 小时。根据 monitorEth 的数据,大多数以太坊节点位于北美、欧洲和亚洲,这使得欧洲成为网络中的中心位置。下图显示了 Lighthouse 节点观察到的所有超过 250 KB 的区块的延迟(以毫秒为单位)的累积分布函数(CDF),针对三个不同的位置。
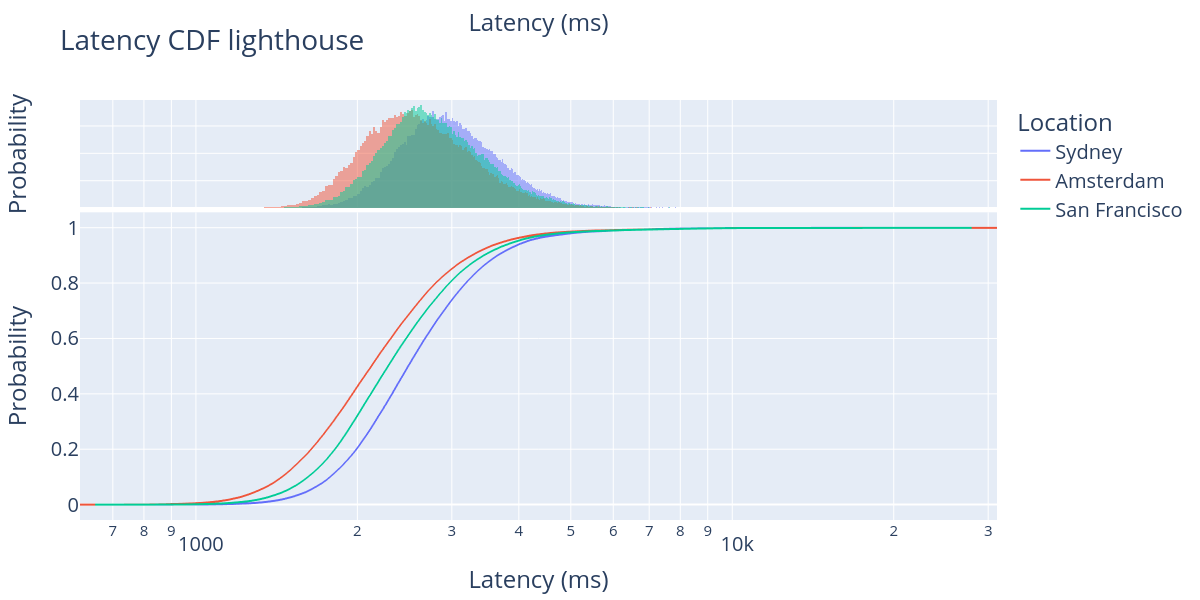 \
lighthouse-geo-11200×600 45.8 KB
\
lighthouse-geo-11200×600 45.8 KB
正如我们在图中观察到的,对于所有三个区域,绝大多数区块在 slot 开始后的 1 到 4 秒之间到达。但是,阿姆斯特丹和悉尼之间的平均到达时间相差约 400 毫秒,而旧金山位于两者之间,与两者相距约 200 毫秒。虽然这种差异并不明显,但几百毫秒确实对节点performance有不可忽略的影响,特别是当节点在生产区块、发送证明和传播聚合方面的时间非常紧张时。我们为其他 CL 客户端生成了类似的图,它们显示了类似的结果。
区块大小传播时间
对于我们在 Codex 进行的 DAS 研究,这项发现最令人兴奋的结果是分析网络中大区块的传播时间。因此,我们选取了我们发现的 10 万多个大的有机区块,并将它们分成 250 KB 的 bin,从 250 KB 到 500 KB 的范围开始,第二个范围从 500 KB 到 750 KB,依此类推,直到最后一个范围从 2000 KB 到 2250 KB。
我们还划分了不同 CL 客户端的数据,因为它们在区块处理流水线的不同时刻报告区块,有些客户端在 p2p 网络层(libp2p/GossipSub)收到区块后立即报告,有些客户端在处理之前批量处理多个网络事件,而另一些客户端仅在区块完全导入(EL、CL 验证并插入到区块 DAG 中)后才报告。换句话说,我们在这里的目的不是比较不同 CL 客户端的延迟。我们目前无法根据可用数据做到这一点。相反,我们应该只比较苹果和苹果,并将不同的 CL 结果视为对处理流水线其他部分的时序的洞察。在这里,我们分别展示了所有五个 CL 客户端的结果。
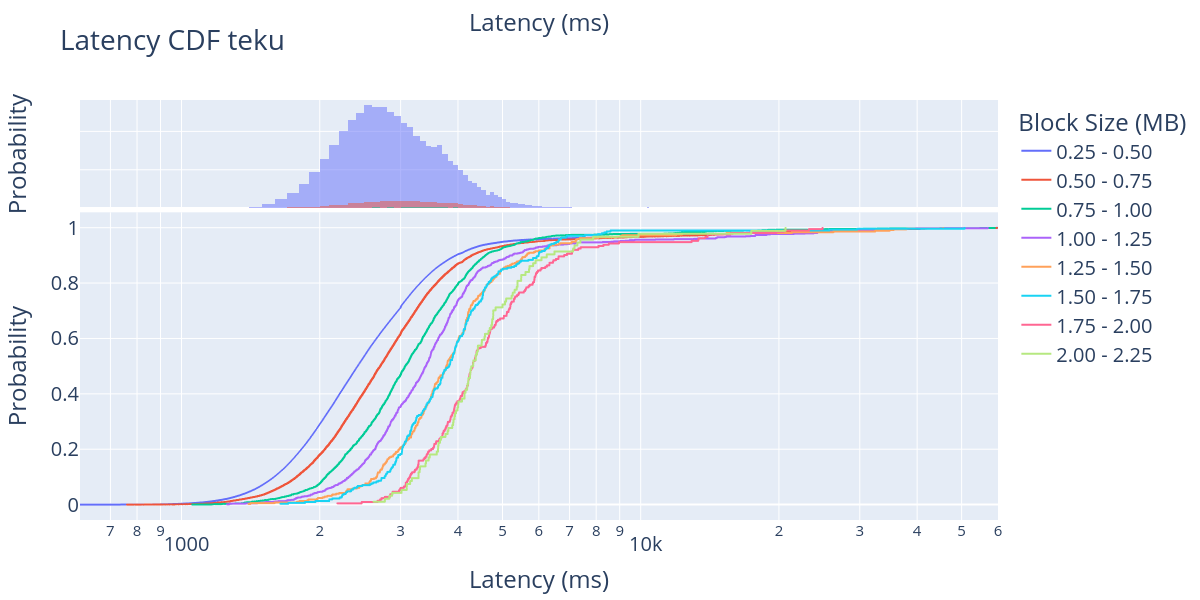 \
teku-bin-11200×600 69.5 KB
\
teku-bin-11200×600 69.5 KB对于每个 CL 客户端,我们都绘制了不同区块大小的区块传播延迟的 CDF(底部)和概率分布函数(PDF)(顶部)。请注意,x 轴是对数的,从 600 毫秒到某些图中的 60,000 毫秒不等。我们在 PDF 中非常清楚地观察到的一件事是,这些图中显示的大多数区块都是第一个大小范围(250 KB - 500 KB)中的区块。这与区块大小分布图中呈现的数据一致。
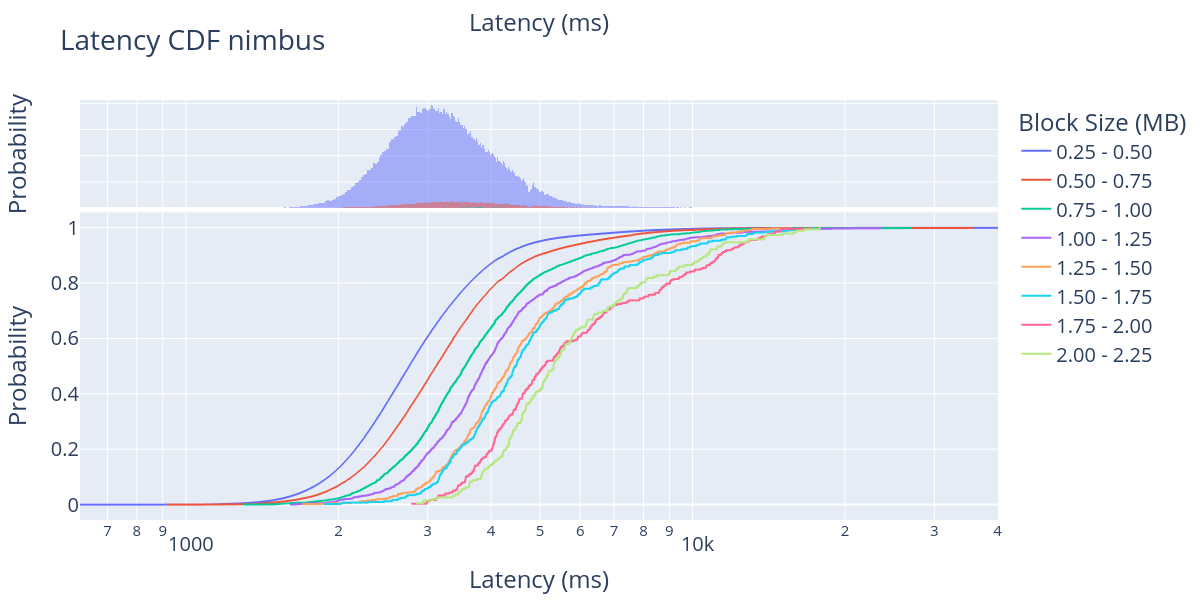 \
nimbus-bin-11200×600 74.4 KB
\
nimbus-bin-11200×600 74.4 KB
查看 CDF,很明显,绝大多数大区块在 slot 开始后的 1 到 8 秒之间报告,除了少数客户端实际上在一些计算密集型处理后才报告区块。我们还看到了一个明显的趋势,即更大的区块需要更多的时间才能在网络中传播,这是可以预料的。然而,在一个拥有超过 10,000 个分布在世界各地的节点和五种具有不同优化策略的不同实现的 p2p 网络中,区块大小之间的距离是极难预测的。
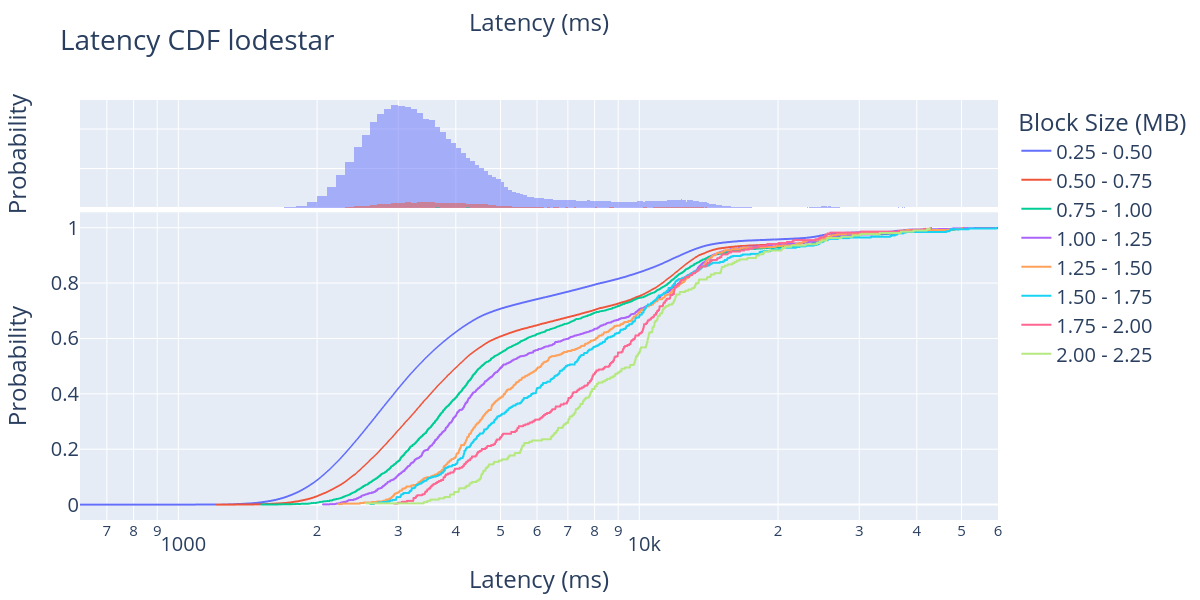 \
lodestar-bin-11200×600 72.7 KB
\
lodestar-bin-11200×600 72.7 KB
在这些结果中,我们可以看到 250 KB 的区块和 2250 KB 的区块之间大约有 2 秒的延迟。例如,查看 Lighthouse 的区块到达时间,我们可以观察到 250 KB - 500 KB 大小范围内的 40% 的区块在大约 2 秒内到达,而 2000 KB - 2250 KB 大小范围内的 40% 的区块在 slot 开始后大约 4 秒内到达。
\
nimbus-bin-11200×600 74.4 KB
类似地,查看 Prysm 的 80% 线,我们可以观察到区块到达时间从 3 秒变为大约 5 秒,从 250KB 到 2000 KB。总的来说,这些结果表明,当前的以太坊网络可以容纳从 1 MB 到 2 MB 的大区块。对于即将到来的 EIP-4844 来说,这是一个好消息,我们预计 EIP-4844 会添加rollup数据的 blob,并且平均区块大小预计约为 1 MB。
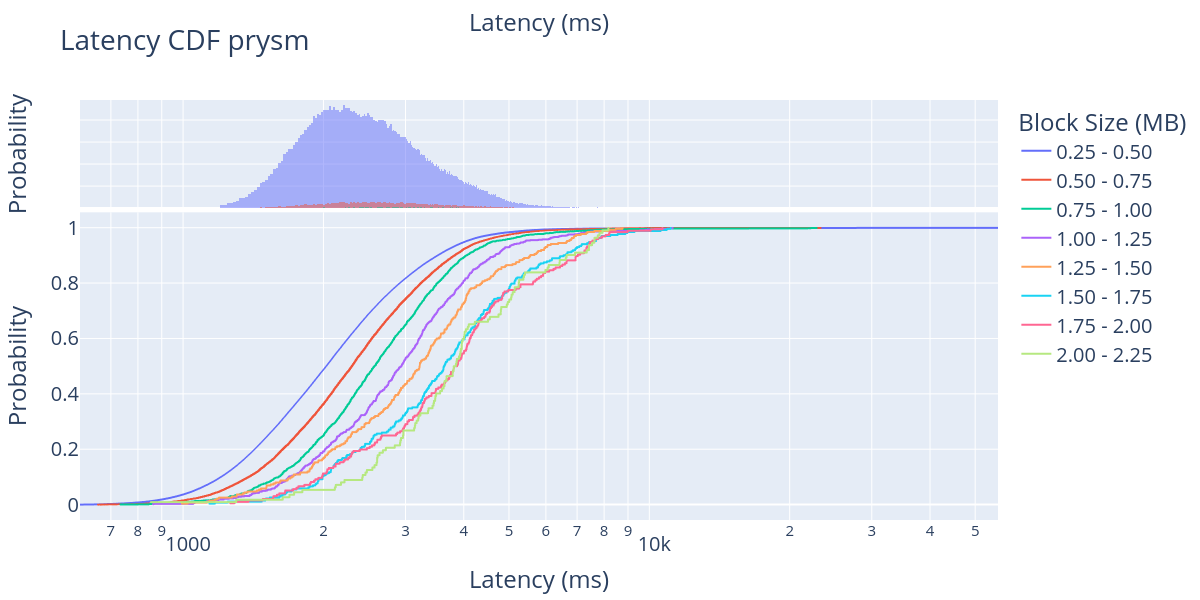 \
prysm-bin-11200×600 72.5 KB
\
prysm-bin-11200×600 72.5 KB详细时序
如上所述,之前显示的数据是通过运行 Xatu 的 Sentry 节点通过 beacon API 获得的,并且正如与客户端团队的讨论中所揭示的那样,每个客户端在此 API 上公开数据的方式都不同。因此,为了进一步验证一些结果,我们专注于一个特定的客户端(Nimbus),并稍微修改了它的代码,以报告每个收到的区块的详细时序,从区块到达到处理流水线的不同事件。修改后的代码可在此处获得:here。
在 4 天内,我们收集了大约 25000 个区块的数据,因为它们到达部署在意大利家庭、位于 1000/100 Mbps 光纤连接后面的单个信标节点。
通过 GossipSub 发送区块时,会使用 Snappy 压缩以压缩形式发送。在原始压缩版本可以转发到 GossipSub 主题网格中的邻居之前,这些区块会被解压缩、SSZ 解码和验证。转发前的这些检查是防止错误传播的协议的重要组成部分。在转发检查之后,必须在节点中进行进一步的验证和内部处理。总的来说,我们收集了每个区块的 8 个时序事件,每个事件都相对于区块的 slot 开始时间:从 GossipSub 邻居接收消息;Snappy 解压缩;SSZ 解码;GossipSub 转发的验证;根据信标链规范进行验证,以及一些与我们当前讨论无关的其他内部事件。
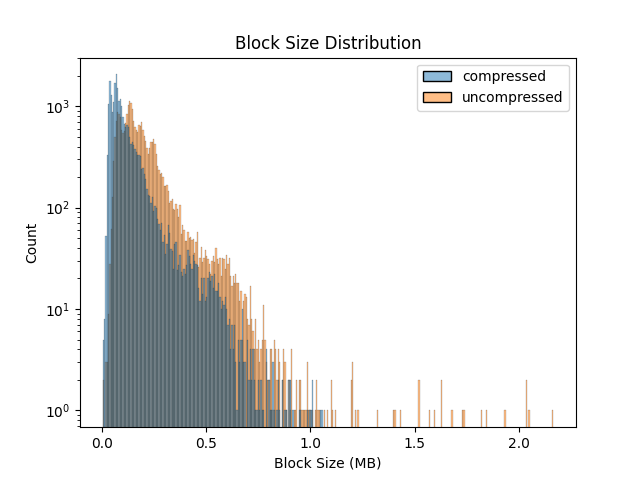
我们还收集了压缩和未压缩的区块大小信息。下面的图显示了区块分布,它是未压缩和压缩大小以及观察到的压缩率的函数。
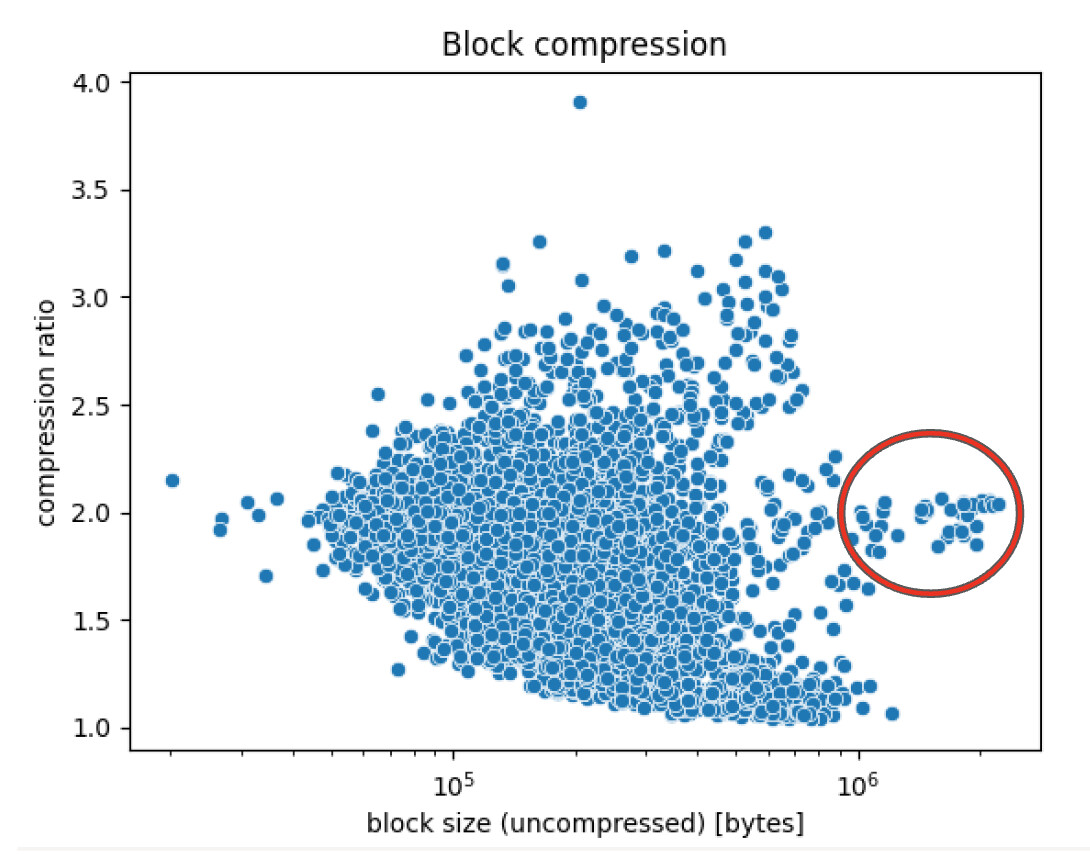
有趣的是,更大的区块都以相似的压缩率到达,这暗示着相似的内部区块结构,我们计划进一步研究。
 \
cimpdist1090×860 203 KB
\
cimpdist1090×860 203 KB接下来,我们看一下区块接收延迟,即我们的第一个计时器,当区块从 GossipSub 到达时,在它被解压缩之前。如下所示,这些与之前通过 beacon API 观察到的行为相似。
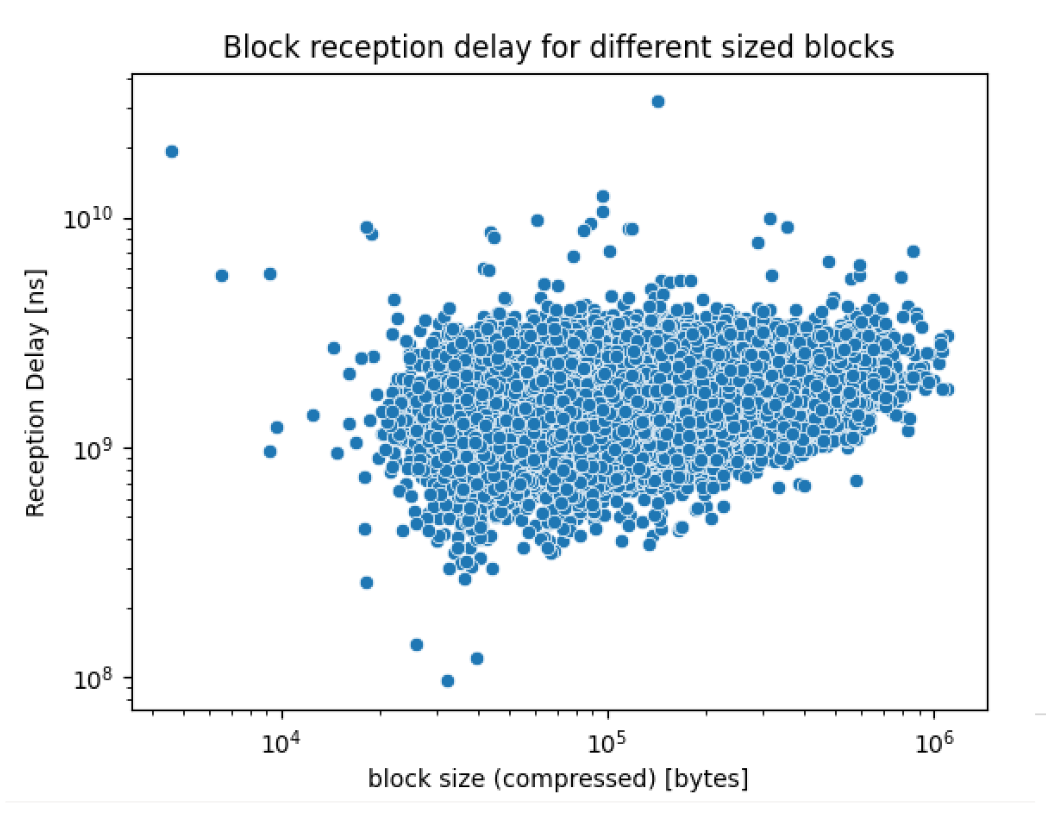 \
dist21046×820 248 KB
\
dist21046×820 248 KB使用大小范围分析区块接收延迟,我们还可以看到类似于大规模数据收集的 CDF。我们拥有的数据点比以前少得多,因为我们只从一个节点观察,而且只观察了几天。因此,大区块的曲线具有较大的步长,并且统计相关性有限。尽管如此,我们仍然可以清楚地看到延迟随着区块大小的增加而增加。
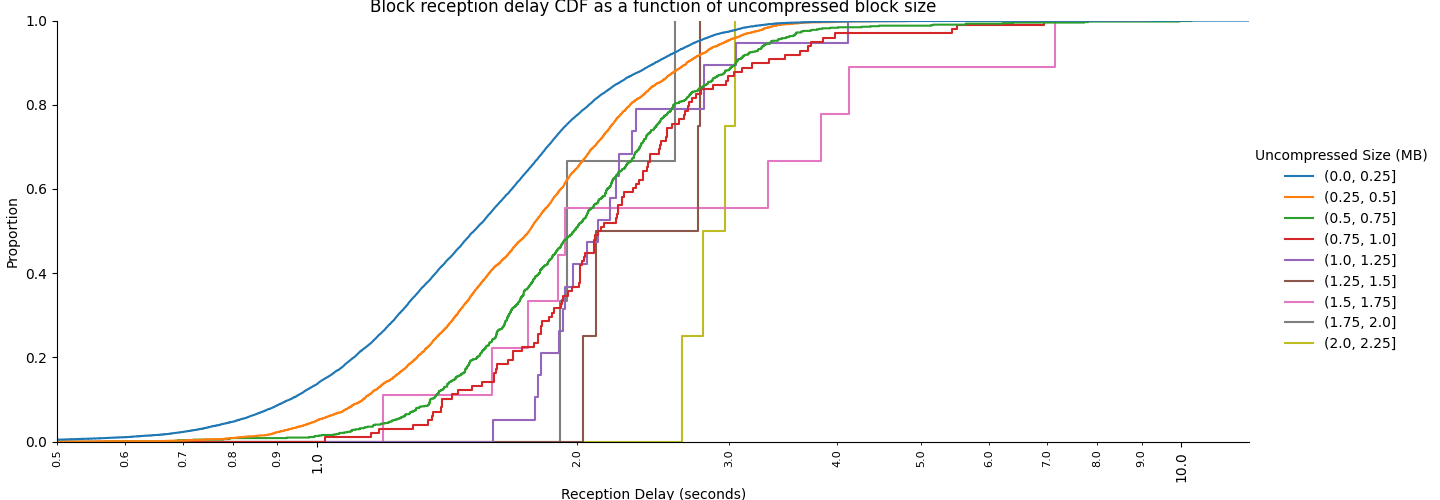 \
bindistnim1440×500 59.4 KB
\
bindistnim1440×500 59.4 KB最后,我们可以根据压缩的区块大小显示曲线。压缩的区块是在网络上传输的区块,因此有人可能会说这与网络(带宽)的角度最相关。很明显,大多数区块,即使是那些未压缩的 2MB、压缩的 1.5 MB 的区块,也可以在 4 秒内到达,即使是到达家庭信标节点。
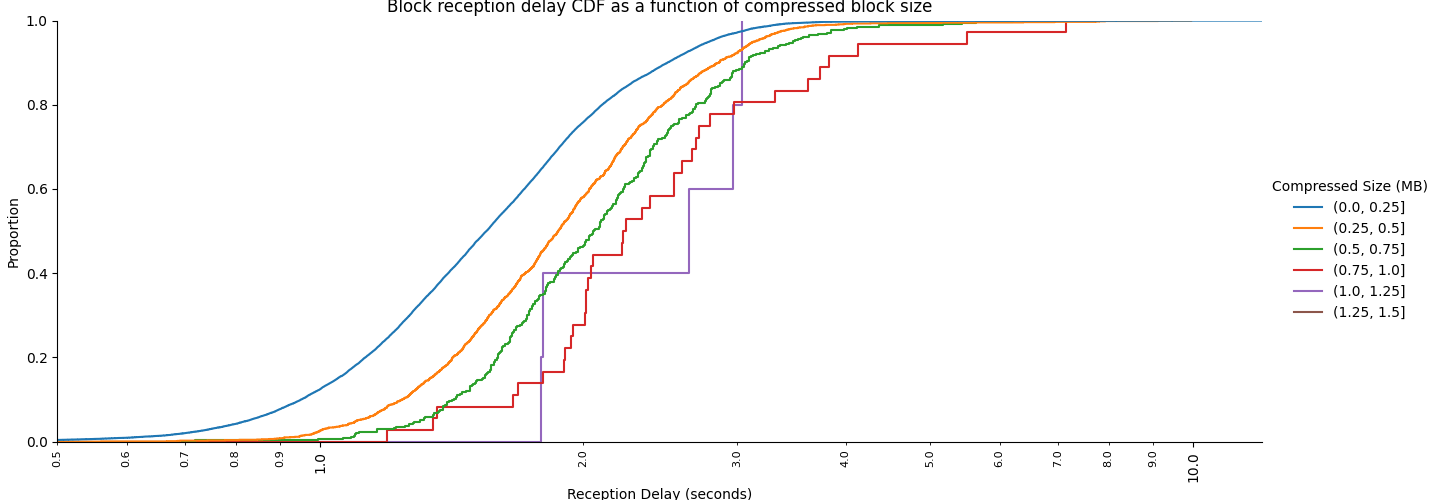 \
bindistnimcmop1440×500 48.9 KB
\
bindistnimcmop1440×500 48.9 KB
结论
我们发现以太坊主网上每天都会自然产生大量的大区块(>250 KB)。我们测量了这些区块在三个不同世界区域的传播时间,并根据地理位置和区块大小比较了它们的延迟。我们分析了这些传播差异如何在五个 CL 客户端中分别反映出来,因为它们报告区块的方式不同。在以太坊主网上测量的经验结果以及本文中呈现的结果,让我们第一次清楚地了解了当 EIP-4844 部署并且 1 MB 的区块成为标准而不是例外时,区块传播时间可能会是什么样子。
未来,我们计划继续进行这些区块传播测量,并监控以太坊网络中大区块的行为。此外,我们希望帮助不同的 CL 客户端协调Event记录和发布系统,以便能够比较 CL 客户端之间的情况。
- 原文链接: ethresear.ch/t/big-block...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





