图灵转向副驾驶:减少认知负荷
- asecuritysite
- 发布于 2025-05-04 08:19
- 阅读 1349
文章讨论了通用人工智能(GenAI)日益普及对人类认知能力的影响。研究表明,GenAI在学术研究等认知挑战性任务中的应用增加,可能导致人类认知能力的下降甚至依赖。强调了GenAI虽然可以作为辅助工具,但过度依赖可能导致对复杂任务的理解不足和判断偏差的问题。

图灵转向副驾驶 —— 减少认知负荷
我正在准备一系列关于人工智能和网络安全的主题演讲,并试图理清我的思路,其中一个需要考虑的最重要的领域是 GenAI 的兴起是否实际上会降低我们的认知能力。想象一下我们未来的世界,就像皮克斯在这里所做的那样:

危险信号已经存在,GenAI 可能会降低我们的认知能力,并且我们可能 просто 停止使用我们的推理能力来完成即使是最琐碎的任务。但是,真正的担忧是 GenAI 取代了需要真正人类认知能力的事情,例如在研究、企业和创新领域。如果 ChatGPT 成为研究论文的合著者,那将确实是一个令人难过且没有灵魂的世界:

学术研究
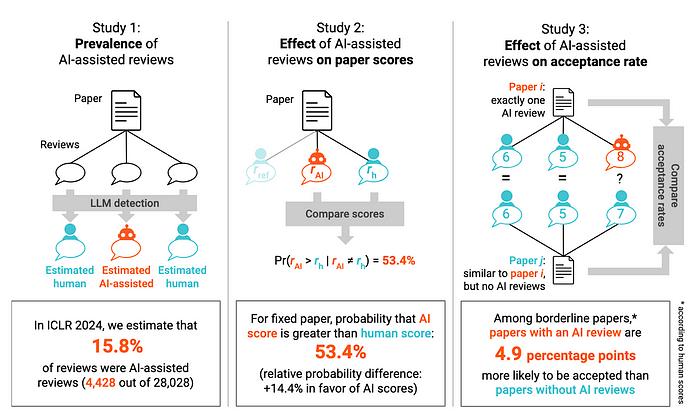
Xu [1] 定义了 GenAI 和 LLM 的集成提供了增强人类智能的机会,但是,在某些需要大量认知能力的领域,这种发展可能过于迅速了。其中一个例子是学术研究论文的同行评审。为此,Latona [2] 分析了 2024 年国际学习表征会议 (ICLR) 的同行评审:

他们使用了 GPTZero LLM 检测器 [3],发现至少 15.8% 的评审有 AI 辅助,并且 AI 辅助的评审在会议上被接受的机会高出 4.9%。
在检查会议的先前版本时,他们没有检测到在评审过程中大量使用 LLM:
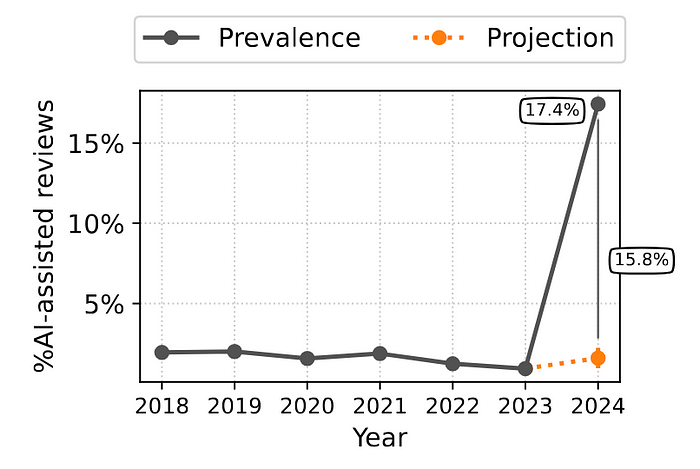
Liang [4] 分析了 2020 年至 2024 年发表的 950,965 篇论文,发现大约 17.5% 的计算机科学论文有 LLM 修改的痕迹,而数学论文的这一比例较低,约为 6.3%。
因此,不管你喜欢与否,目前的 LLM 和 GenAI 通常都无法判断一篇研究论文是否真正具有新颖性,以及方法和/或结果是否真正验证了这些说法。基本上,LLM 正在对“一篇好的论文”通常应该是什么样子以及人类喜欢什么进行一些基本检查,例如,“它是否有文献综述?”,“论文中是否包含了目的?”,“是否有图表?”,“参考文献的格式是否正确?”,“它读起来是否流畅?”,等等。LLM 评审员根本无法理解隐藏在底层的研究的复杂性。
通常,LLM 会对问题给出合理的答复,因为它已经从 Stack Overflow 等来源中抓取了专家答案,然后使用带有人类反馈的强化学习 (RIHF) 来完善答案。LLM 本身并不真正了解为什么这是正确的答案,即使它试图解释其推理,答案背后也可能有人类。
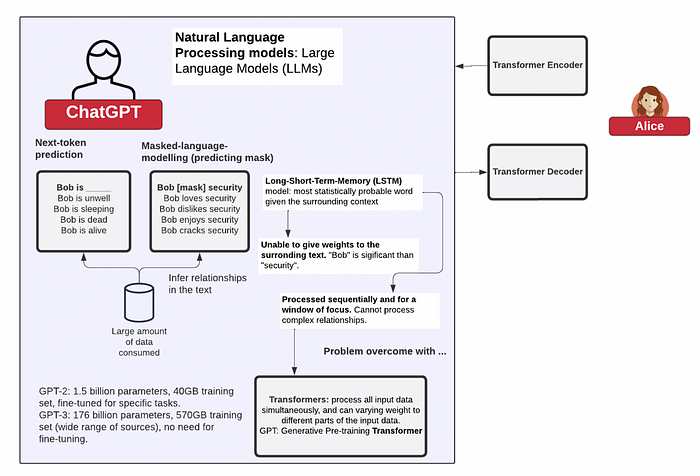
Transformers
NLP(自然语言处理)的巨大进步源于 Vaswani 等人 [7] 对 transformer 架构的使用。Transformers 的使用使我们能够映射文本中的复杂关系,并根据前面文本概率来预测所需的下一个 token。这使得 LLM 可以创建模板答案,然后可以根据最可能的结果进行填充 —— Long-Short-Term-Memory (LSTM)。
但是,提供的答案可能不正确,因此该过程的关键部分是使用人类(“AI 的奴隶”)来完善答案并得出人类认为正确的答案。这在第 2 步 [8] 中进行了说明:
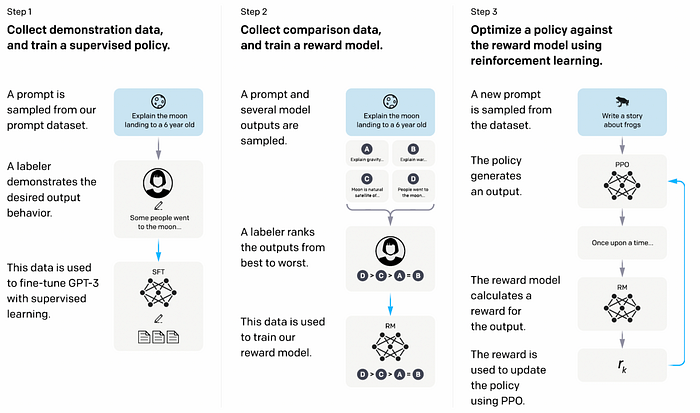
图 [8]
强化学习的弱点
通过强化学习,我们经常包含人类反馈来完善 LLM [5]。这使人类可以根据人类的期望来判断 AI 呈现的内容是否正确。但是,这种方法可能会产生负面影响,例如在 AI 生成的内容中越来越多地使用 delve 一词,即使该词在训练集中很少使用。Alex Hern [6] 将其追溯到非洲地区廉价的人类培训师的使用,以及 delve 一词在这些地区更常用。因此,这种类型的培训可能会导致已开发的 LLM 产生偏差。
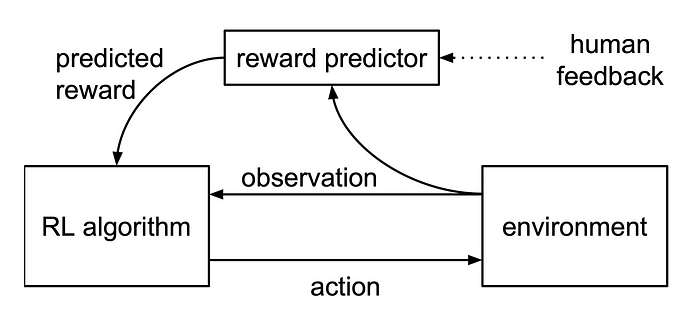
图 RIHR [5]
除了 “delve” 之外,我们还看到其他情感词的兴起 [2]:
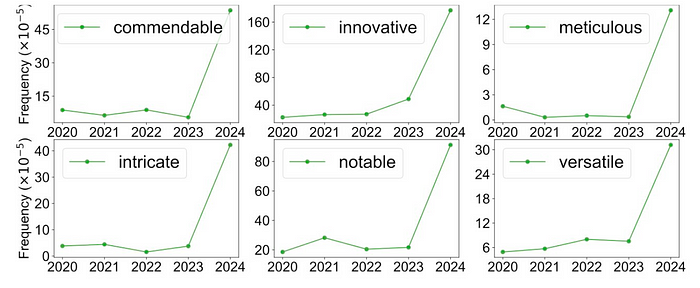
并且计算机科学论文中几乎看不到的单词的概率增加了:

结论
这些示例突出了 GenAI 作为副驾驶越来越多地用于完成认知上具有挑战性的任务,并且可能很快就会成为许多人的首选。不幸的是,这可能会导致我们社会认知努力的减少,并且缺乏对某人工作的控制,最终可能导致对它的完全依赖,即使是对于琐碎的任务也是如此。我留给你这个:

参考文献
[1] Larry Zhiming Xu, Kambiz Saffarizadeh, and Jungmin Lee. Fast forward, as copilot becomes the pilot: Examining genai dependence and problematic use. 2024.
[2] Giuseppe Russo Latona, Manoel Horta Ribeiro, Tim R Davidson, Veni-
amin Veselovsky, and Robert West. The ai review lottery: Widespread ai-
assisted peer reviews boost paper scores and acceptance rates. arXiv preprint arXiv:2405.02150, 2024.
[3] Mervat Abassy, Kareem Elozeiri, Alexander Aziz, Minh Ngoc Ta, Raj Vardhan, Tomar, Bimarsha Adhikari, Saad El Dine Ahmed, Yuxia Wang, Osama Mohammed Afzal, Zhuohan Xie, et al. Llm-detectaive: a tool for fine-grained machine-generated text detection. arXiv preprint arXiv:2408.04284, 2024.
[4] Weixin Liang, Yaohui Zhang, Zhengxuan Wu, Haley Lepp, Wenlong Ji, Xuan- dong Zhao, Hancheng Cao, Sheng Liu, Siyu He, Zhi Huang, et al. Mapping the increasing use of llms in scientific papers. arXiv preprint arXiv:2404.01268, 2024.
[5] Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., & Amodei, D. (2017). Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
[6] https:// www.theguardian.com/technology/2024/apr/16/techscape-ai-gadgest-humane-ai-pin-chatgpt
[7] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[8] Uwah, A., & Edet, A. (2024). Customized Web Application for Addressing Language ModelMisalignment through Reinforcement Learning from HumanFeedback. World Journal of Innovation And Modern Technology, 8(1), 62–71.
- 原文链接: medium.com/asecuritysite...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





