又一个circle STARK 教程
- XPTY
- 发布于 2024-09-23 11:29
- 阅读 1580
最近,circleSTARK引起了很多人的兴趣。我也没有忽视,我的兴趣也被激起了。
原文:https://research.chainsafe.io/blog/circle-starks/ 作者:Timofey Yaluhin 译者:Kurt Pan
最近,circle STARK引起了很多人的兴趣。我也没有忽视,我的兴趣也被激起了。不仅是因为大声的“突破”的公告和解锁比特币可验证计算的前景,还有通过应用精妙优雅的代数几何的来突破限制以及简化以前的方案。
- https://eprint.iacr.org/2024/278
- https://x.com/StarkWareLtd/status/1807776563188162562
- https://github.com/Bitcoin-Wildlife-Sanctuary/bitcoin-circle-stark
- https://arxiv.org/abs/2107.08473
目前,我们已经有了zkSecurity 、 Vitalik和LambdaClass撰写的几篇优秀的介绍解释性文章。我尽力不重复他们的话,而是专注于我个人认为非常有趣的未探索的方面和元素。这是我边学习边写的,所以不能排除错误。
Circle STARKs 系列(一):梅森素域
探秘 Circle STARKs (重排版)
引言
Circle STARK 使得证明者可以在模Mersenne 31素数 (M31)的有限域上面工作。这个域具有非常高效的算术。也就是说,它会比 SP1、Valida 和 RISC Zero 中使用的先前最高效的 BabyBear 域快 1.3 倍。有关为什么在 M31 上工作是如此理想的更多见解,请参阅 [[Circle STARKs 系列(一):梅森素域]] 。 然而,简单地将 M31 换入现有的单变量 STARK 中是行不通的。原因是Mersenne素数并不 FFT/FRI 友好。我们看看为什么。
FFT“分治”算法的效率依赖于递归地将问题大小除以 2 的幂的能力。在有限域上工作时,这要求求值定义域具有乘法群的“结构”,其阶的因子分解要包含 2 的大幂次。我们将此称为高度2-adicity 。我们希望这样做的原因是,在 FFT 的每一步中,通过对定义域中每个数字进行平方,可以将定义域的大小减小两倍。
例如,考虑在整数模337的有限域中的定义域$[1,85,148,111,336,252,189,226]$。这个定义域形成了一个有$8 = 2^3$元素的乘法群。这个群中的元素都是$\omega=85$的幂次,$\omega$是群的生成元。如果对定义域中的每个数字进行平方, 则定义域的大小将减少两倍:$[1,148,111,336]$。如果你采用相同的定义域,但比如说有 6 个元素, 那么你将不再具有这个性质了。
构造满足 2-adicity 要求的另一种相关方法是搜索一个阶数为小素数乘积的群。我们称这些数为平滑数。由于域的乘法群包括了除0外的所有元素 , 群的阶恰好比域中元素的数量少一。满足这个条件的域$\mathbb{F}_p$被称为$p -1$光滑的。
BabyBear 素数$p = 2^{31} - 2^{27} - 1$就是一个典型的例子。BabyBear 域中最大的乘法群有$p - 1 = 2^{27}·3·5$个元素。你可以清楚地看到它既平滑又高度 2-adic。太完美了。
Mersenne-31素数$p = 2^{31} - 1$又怎么样呢?很遗憾,$2^{31} - 2$只能除以 2 —次。因此传统的 Cooley-Tukey FFT 算法对于这个域群来说效率会非常低。Circle STARK的作者们通过从一个单位圆设计出一个群解决了这个问题。
作为一个群的圆
圆群是由一个满足$x^2 + y^2 = 1$(即位于单位圆上)的点$(x,y)$通过应用一个不同的乘法律所生成的: $(x_0, y_0) \cdot (x_1, y_1) := (x_0 \cdot x_1 - y_0 \cdot y_1, x_0 \cdot y_1 + y_0 \cdot x1)$ 生成子群元素不是对一个生成元简单地取幂,我们从一个圆上的点 到下一个点是这么移动的: $(x{i+1}, y_{i+1}) = (g_x \cdot x_i - g_y \cdot y_i, g_x \cdot y_i + g_y \cdot x_i)$
事实表明在Mersenne素数$2^{31} -1$上定义的圆上的点的个数是相当大的$(2^{31})$。可以从$(x_0,y_0) = (1,0)$开始,对生成元$(g_x,g_y) = (2,1268011823)$使用上述乘法律,就可以生成所有的$2^{31}$个群元素。
对于圆 FFT/FRI,我们还需要两个群运算:群平方映射$\pi$和逆映射$J$。
平方是二次映射,定义为 $\pi(x, y) := (x, y) \cdot (x, y) = (x^2 - y^2, 2 \cdot x \cdot y) = \big(2 \cdot x^2 - 1, 2 \cdot x \cdot y\big)$ 此个变换将集合大小减少一半。
逆由这个一次映射给出 $J(x, y) := (x, -y)$ 这个操作映射每个点$(x,y)$为其映像点$(x,-y)$。
映射$J$是一个对合函数, 即$J(J(P))=P$。映射$J$和$\pi$满足交换律, 即对每一个$P \in C(\mathbb{F}_p) \ , \ \pi(J(P)) = J(\pi(P))$ 。
圆定义域上的FFT
与经典的 STARK 相同, 圆 FFT 用于对一个特殊定义域上的某个多项式进行求值。在常规 FFT 中,定义域包括$n$次单位根${1,\omega,\omega^2,...,\omega^{n-1}}$。在圆 FFT 中, 定义域是圆曲线上的由如下方式生成的一组点。 https://rdi.berkeley.edu/zkp-course/assets/lecture8.pdf#page=23
首先, 用一个圆群的生成元$g$,将其平方$\log n - 1$次,得到一个子群$G_{n-1}$。然后创建两个孪生陪集, 它们是通过取一个不在$Gn$中的元素$Q$,并创建两个不相交的集合得到的:$Q·G{n-1}$和$Q^{-1}·G_{n-1}$。这些集合的并集形成了包含$2^n$个元素的圆FFT的定义域。可以在Plonky3中找到有清晰描述的实现。
下面是一个用于演示定义域点的分布的图像,它使用 Mersenne-17 域上的圆群的简单 TS实现。即使这里是模素数$p$的,你仍然可以看到关于线$p/2$对称的规则的圆形图案。这种现象也存在于椭圆曲线(亏格 1)中,但在圆曲线(亏格 0)和复单位根上更为明显。
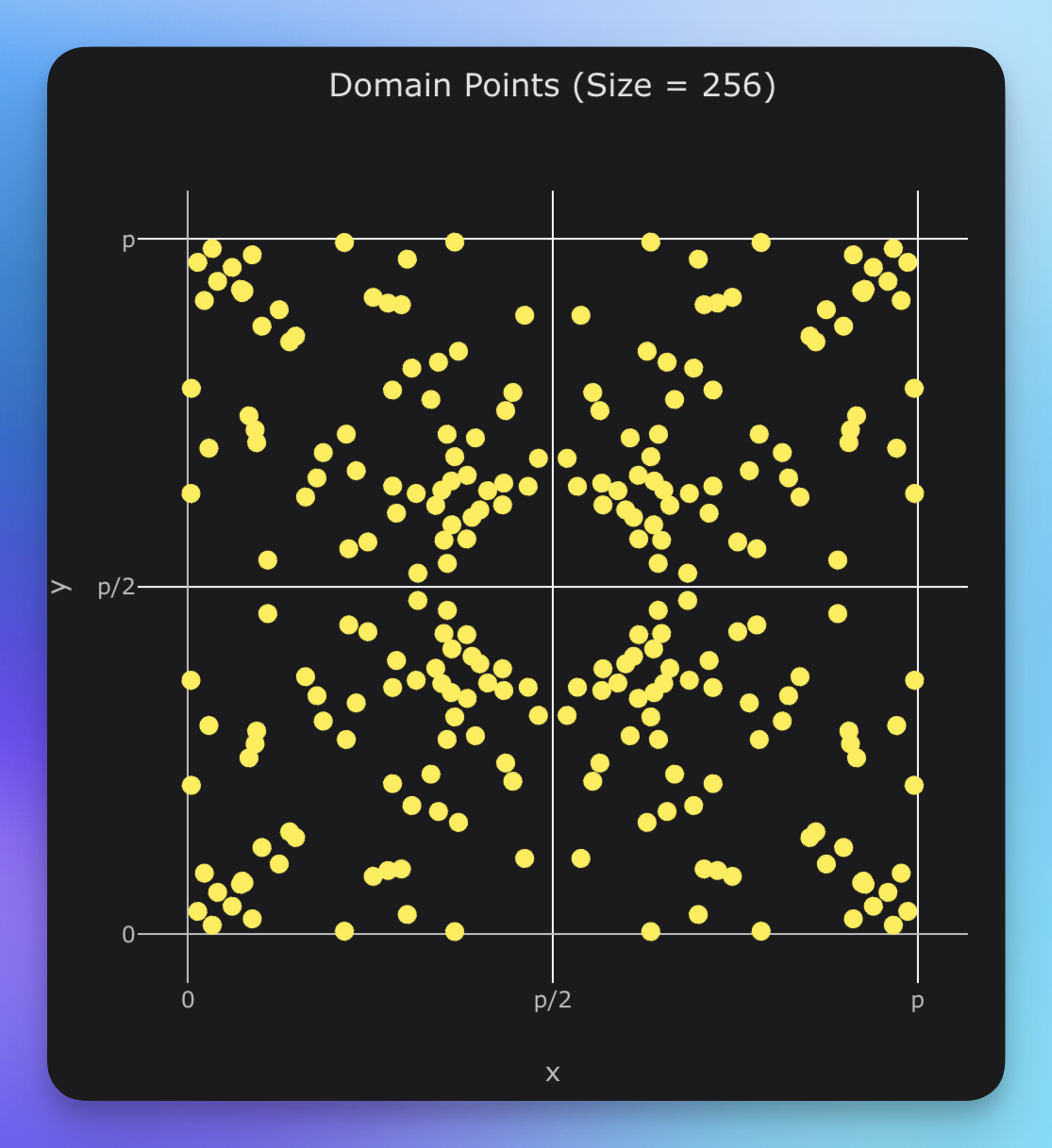
- https://graui.de/code/elliptic2/
- https://gist.github.com/nulltea/2429c8588362990df30125f530287876
- https://www.geogebra.org/m/sZFwAZfs
FFT 的工作原理是将较大的问题递归地分成两个较小的问题。在多项式求值的上下文中,这意味着将多项式分解为"偶数"和"奇数"部分。在常规 FFT 中, 这些子多项式只是简单地由原始多项式的偶数和奇数项系数组成。正如我们将看到的, 在圆 FFT 中, 这会更复杂一点, 但底层机制是相同的 - 原始多项式$f$是一个线性组合$f(x) = f{\mathrm{even}}(x) + x \cdot f{\mathrm{odd}}(x)$。在每次分割时, 也将域减小两倍。
第一步中,我们通过简单地取每个点的$x$投影来将定义域"减半"。这是通过在执行分解$f(x, y) = f{0}(x) + y \cdot f{1}(x)$时使用逆映射来证实其有效性的: $\vec{f}0[\text{index}{D1}(x)] = \frac{\vec{f}[\text{index}{D0}(x, y)] + \vec{f}[\text{index}{D_0}(J(x, y))]}{2}$ $\vec{f}1[\text{index}{D1}(x)] = \frac{\vec{f}[\text{index}{D0}(x, y)] - \vec{f}[\text{index}{D_0}(J(x, y))]}{2 \cdot y}$
我修改了符号以演示在实践中是如何把多项式$f,f_0,f_1$作为其系数的向量的。请将此处的原始符号与此处Vitalik 的实现进行比较。
- https://eprint.iacr.org/2024/278.pdf#page=15
- https://github.com/ethereum/research/blob/master/circlestark/fft.py#L72-L91
你可以把逆映射$J(x, y) = (x, -y)$想为识别垂直镜像点对的一种方法, 从而它们可以被视为单个的一个实体。这使得我们能够仅用$x$坐标继续。
在后面的步骤中, 我们继续使用单变量平方映射将定义域减半$\pi(x) = 2 \cdot x^2 - 1$。这类似于对$k$次单位根平方使得$\omega^{2k} = \omega_{k}$ 。(原始记号的)奇偶分解$fi(x) = f{j+1}(\pi(x)) + x \cdot f_{j+1}(\pi(x))$现在看起来是这样的:
$f_0(\pi(x)) = \frac{f(x) + f(-x)}{2}$
$f_1(\pi(x)) = \frac{f(x) - f(-x)}{2 \cdot x}$
虽然加速 FFT 不是本文的重点,但正如作者在这里指出的那样,它有效地展示了在圆群上工作的核心原理。在研究这篇论文时,我犯了一个错误:跳过了它并急于进入圆FRI了,结果却陷入了混乱。因此我鼓励你花上一些时间来欣赏下这个机制。如果你想尝试一下,我制作了这个 Python笔记本(警告:糟糕的代码)。
- https://x.com/UHaboeck/status/1666851531004555283
- https://colab.research.google.com/drive/1tJY19c921toxz7HEIb2CAL3vHJlQuUqf?usp=sharing
常规 FRI
FRI 算法的结构很像 FFT。但在 FRI 中,证明者不是将多项式递归地划分为许多较小的多项式,而是迭代地降低多项式的次数,直到其达到某个小的常数大小的多项式。这是通过随机线性组合来实现的,即通过将"偶"和"奇"子多项式与一个随机权重组合起来。
在 STARK 中,我们使用 FRI 进行所谓的"低次测试"——通过了解最终的次数和归约步的数量, 验证者可以向后工作并检查原始多项式的次数界是否是如所声称的那样。更形式化地说, FRI 使不受信任的证明者能够说服验证者, 一个承诺的向量是接近一个次数$d$的在定义域 $D$上的 Reed-Solomon 码字的。
这里, "接近"是指由相对汉明距离$\delta$定义的,使得承诺向量和码字不一致的点数最多为$\delta ·|D|$。距离$\delta$使得$\delta \in (0, 1 - \sqrt{\rho})$,其中$0 < \rho < 1$是Reed-Solomon 码的码率。而码率$\rho$由膨胀系数$2^B$定义,$B \geqslant 1$使得$\rho = 2^{-B}$。最后, 定义域大小为$|D| = 2^{n+B}$,其中$2^n$是原始向量的大小。
为了更好地理解这些定义, 我们指定一些标准值:常用的膨胀系数是$2^B = 4$, 所以码率是$\rho = 0.25$。最坏的可能距离是$\delta = 0.5$, 因此对于一个1024 个元素的向量, $2^{B+n} = 4096$大小的定义域上的码字最多可以在一半的点上不一致。在实践中$\delta$会更小,以提供更好的可靠性保证。
另一个有趣的性质是解码的范围。在唯一解码范围中, 目标是识别出接近承诺向量的单个低次多项式。唯一解码半径通常定义为:$\theta \in \left[ 0, \frac{1 - \rho}{2} \right]$。
STARK 在该范围之外也被证明是可靠的, 因为目标只是要证明此类多项式的存在, 即使是有多个多项式是符合给定点的。我们将这种简化的要求称为列表解码范围。_列表解码半径_通常定义为:$\theta \in \left[ \frac{1-\rho}{2}, 1 - \sqrt{\rho} \right]$。[HAB23]
圆 FRI
圆定义域上的低次测试背后的一般机制与常规 FRI 保持不变。提醒一下, 请参阅[[FRI邻近性测试]]以进行深入的理论讨论。如果你只关心实现,请参阅这篇博文。
圆 FRI 对循环码$C$中的码字进行操作,这是对定义在圆群的元素以及在Riemann-Roch空间中特殊多项式上的Reed-Solomon码的一个推广。过度简化地说,它们是模上单位圆方程$(x^2 + y^2 = 1)$的二元多项式 ,所以每当多项式有了$y^2$,就会被替换为$1 - x^2$。
对于给定的邻近性参数$\theta \in (0, 1 - \sqrt{\rho})$ , 函数$f : X \rightarrow \mathbb{F}^D$(映射承诺向量)$\theta-$是接近圆码字$C$的交互式预言证明包括$r$轮的承诺阶段和后续的一个查询阶段如下。
承诺阶段
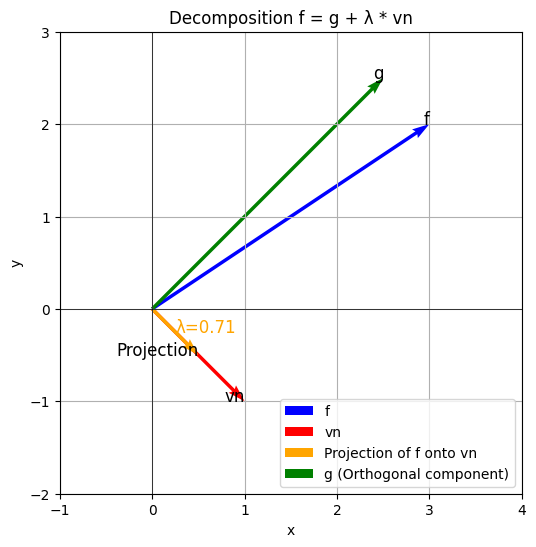
- $P$分解$f$为$f = g + \lambda ·\nu_n$并发送$\lambda$给$V$
- $V$对于第$j$层选择随机权重$\lambda_j$
- 对每个$j = 1,...,r,P$分解$g_{j-1}$为"偶"和"奇"部分;发送承诺$[g_j]$给$V$
- 在最后一轮中,$P$直接发送$g_{r+1}$。
1.$P$分解$f$为$f = g + \lambda ·\nu_n$并发送$\lambda$给$V$
我们从扩展定义域陪集$D_{n+B}$开始 。首先, 我们要找到$f$与$\nu_n$对齐的部分 。这可以使用向量投影来完成:给定两个函数(或向量)$f$和$\nu_n$,把$f$到$\nu_n$的投影由下式给出:
- https://en.wikipedia.org/wiki/Vector_projection $\text{proj}_{v_n}(f) = \frac{\langle f, v_n \rangle_D}{\langle v_n, v_n \rangle_D} \cdot v_n$
注:尖括号表示内积$\langle v_n, f \rangleD = \sum{x \in D} v_n(x) \cdot f(x)$。
用$\lambda$表示这个投影的模,这将确保$\lambda ·\nu_n$就是$f$在$\nu_n$上的部分 $\lambda = \frac{\langle f, v_n \rangle_D}{\langle v_n, v_n \rangle_D}$
消失多项式$\nu_n$在定义域$D$上存在一种交替行为,例如如果$D$大小为$N = 2^n$,则$\nu_n$交替为$(1,-1,1,-1,...)$。这大大简化了内积计算,因为$\nu_n(x) \in {1,-1}$,每一项$\nu_n(x)^2 = 1$于是
知道了$\lambda$, 我们现在可以找到$g$, 它代表$f$正交于$\nu_n$的组成部分 $g = f - \lambda \cdot v_n$
这确保了$g$完全位于 FFT 空间$\mathcal{L}_{N}^{\prime}(F)$中 , 正交于$\nu_n$。这是因为内积$\langle g, v_n \rangle_D = 0$,通过构造使得$g$和$\nu_n$正交。
2.$V$对于第$j$层选择随机权重$\lambda_j$
但在实践中,$P$可以计算$\lambda_j$为一个从 开始的,使用一个$V$选择的随机权重$\alpha \in \mathbb{E}$的随机线性累加器。 $\lambdaj = \lambda{j-1} \cdot \alpha + \lambda$ 请参阅Stwo中这是怎么做的。
3. 对每个$j = 1,...,r,P$分解$g_{j-1}$为"偶"和"奇"部分
"奇偶"分解遵循与 FFT 相同的过程。在第一轮中, 我们使用二维点$(x,y)$并使用完全平方$\pi (x,y)$和逆$J(x,y)$映射。逆映射变换使我们能够识别点$(x,y)$及其映像$(x,-y)$,所以在后续轮中我们可以将其视为一个$x$- 轴上的点$x$。平方映射$\pi$通过高效地将点空间减半将域$D_{j-1}$变换为$Dj$: $g{j-1,0}(\pij(x)) = \frac{g{j-1} + g{j-1}(J(x))}{2}$ $g{j-1,1}(\pij(x)) = \frac{g{j-1} - g_{j-1}(J(x))}{2 \cdot t_j}$ 其中$\pi(x) = 2·x^2 - 1$,以及$t_j$是一个旋转因子。然后, 用$\lambda_j$折叠成随机线性组合 :
- https://github.com/Plonky3/Plonky3/blob/a650e8c5b1e800de7fce43b4e9b22a41e36eaa03/circle/src/cfft.rs#L238-L258 $gj = g{j-1,0} + \lambdaj \cdot g{j-1,1}$
承诺$[g_j]$就是一个简单的 Merkle 根。在Fiat-Shamir变换下,$P$还要发送打开, 即用于 FRI 查询的 Merkle 分支。
查询阶段
1.$V$从定义域$D$上均匀采样$s \geq 1$个查询
对每个查询$Q$,$V$将其"迹"视为通过重复应用平方映射和协议定义的变换而得到的点序列。初始查询点$Q_0 = Q$经过几轮变换, 得到一系列在不同定义域$D_j$中的点$Q_j$: $Q_j = \pij(Q{j-1})$
2. 对每个$j = 1,...,r,V$询问函数$g_j$在查询点$Q_j$及其映像$T_j(Q_j)$的处的值
给定承诺$[g_j]$, 和在预言访问中一样,$V$可以向预言询问查询点的值(打开)。换句话说就是在以下点验证 Merkle 证明: $g_j(Q_j)$和$g_j(T_j(Q_j))$ 其中在$j = 1$,$T_j = J$;在$j > 1$ 时,$T_j(x) = -x$。
3.$V$根据折叠规则检查返回值是否与预期值匹配
这涉及检查偶数和奇数分解是否正确以及用于从$g_{j-1}$构造$g_j$的随机线性组合是一致的。
DEEP 求商
求商是 STARK 和 PLONKish 系统中使用的基本多项式恒等性检查。利用多项式余数定理,它可以证明多项式在给定点的值。Vitalik 对求商的概述已经很好,因此我将重点关注圆群上的DEEP-FRI 。
- https://en.wikipedia.org/wiki/Polynomial_remainder_theorem
- https://vitalik.eth.limo/general/2024/07/23/circlestarks.html#quotienting
- https://blog.lambdaclass.com/diving-deep-fri/ DEEP(伪装者消除域扩展)是一种通过从大定义域中采样随机点来检查两个多项式之间一致性的方法。通俗地说,它使得 FRI 可以用更少的 Merkle 分支来保证安全。
在 STARK 中,我们对约束组合多项式(组合所有约束的多项式)和迹列多项式之间的关系使用 DEEP 方法,均在随机点处求值 。有关更多背景信息,请参阅这篇文章和ethSTARK论文。
- https://blog.lambdaclass.com/diving-deep-fri/#sampling-outside-the-original-domain
- https://eprint.iacr.org/2021/582.pdf#page=17
第一部分是DEEP代数链接(DEEP-ALI):它可以让我们将 STARK 电路可满足性检查(针对许多列和许多约束)归约为一个对单点商的低次测试(FRI)。就其本身而言, DEEP-ALI 是不安全的, 因为证明者可以欺骗并发送$z$处不一致的求值。我们通过另一个商化实例来解决这个问题——DEEP求商。
我们在分母上用单点消失函数$\nu_z$来构造 DEEP 商, 去说明一个特定多项式,比如一个迹的列$t$, 在处求值为声称的$y_j$, 即$\frac{t - t(z)}{v_z}$。
在经典的 STARK 中, 只是一个线函数$X - z$。在circle STARK 中, 除了没有线函数之外,我们还遇到了单点(或任何奇数次)消失多项式不存在的问题。为了解决这个问题,我们转向复扩张, 即分解为实部和虚部 $\frac{t - t(z)}{v_z} = \operatorname{Re}\left(\frac{t - t(z)}{v_z}\right) + i \cdot \operatorname{Im}\left(\frac{t - t(z)}{v_z}\right)$
利用这个技巧,我们遵循标准程序将组合DEEP商多项式构造为随机线性组合。对实部和虚部使用不同的随机权重 $Q = \sum_{i=0}^{L-1} \gamma^i \cdot \text{Re}_z(ti) + \sum{i=0}^{L-1} \gamma^{L+i} \cdot \text{Im}_z(t_i) = \text{Re}z \left( \sum{i=0}^{L-1} \gamma^i \cdot t_i \right) + \gamma^L \cdot \mathrm{Im}z \left( \sum{i=0}^{L-1} \gamma^i \cdot t_i \right)$
供参考:在ethSTARK论文中,证明者使用$L$个由验证者提供的随机权重$\gamma_1,...,\gamma_L$进行批处理(仿射批处理)。而在这里,证明者使用单个随机权重的幂$\gamma^1,...,\gamma^L$(参数批处理)。
直接计算$Q$会由于复扩张而带来开销,实质上由于实部和虚部的分解会使工作量加倍。作者们通过利用上述方程中的线性来解决这个问题。证明者现在计算 $Q = \left( \operatorname{Re} \left( \frac{1}{v_z} \right) + \gamma^L \cdot \operatorname{Im} \left( \frac{1}{v_z} \right) \right) \cdot (\bar{g} - \bar{v}_z) = \frac{\operatorname{Re}(v_z) - z^L \cdot \operatorname{Im}(v_z)}{\operatorname{Re}\left(v_z\right)^2 + \operatorname{Im}\left(v_z\right)^2} \cdot (\bar{g} - \bar{v}_z)$
其中$\bar{g} = \sum_{k=0}^{L-1} \gamma^k \cdot g_k$以及$\bar{v}z = \sum{k=0}^{L-1} \gamma^k \cdot g_k(z)$。
有趣的是,Stwo 和 Plonky3 实际上使用了不同的求商方法:Plonky3实现了论文中和此处描述的方法,但 Stwo选择使用 2 点消失多项式,如 Vitalik 文章中所述。
- https://github.com/Plonky3/Plonky3/blob/a650e8c5b1e800de7fce43b4e9b22a41e36eaa03/circle/src/deep_quotient.rs
- https://github.com/starkware-libs/stwo/blob/8344112d446d638ed55156aba5b4385c036bda8e/crates/prover/src/core/backend/simd/quotients.rs
工作域
在 circle STARK 中,工作是在有限域上$\mathbb{F}p$及其扩张$\mathbb{E} = \mathbb{F}{p^k}$上完成的,其中$k$是扩张次数。对$\mathbb{F}_p$,我们选择M31,但任何其他$p+1$光滑素数也可以。Stwo 和 Plonky3 中使用的扩域$\mathbb{E}$是 QM31,一个 M31 的 4 次扩张,又名安全域。
在极少数情况下,使用复扩张$\mathbb{F}(i)$会很有用,$\mathbb{F}$用虚数单位$i$扩张出的域 。注意$i$可能会平凡地包含在某些域中, 例如,如果$-1 \equiv 4 \mod 5$,则$\mathbb{F}_5$中的$i$既是$\sqrt{4} = 2$也是$3$(因为$2^3 \mod 5 \equiv 4$)。对于那些并非如此的域,例如$\mathbb{F}3$,我们可以设计一个二次扩张,$\mathbb{F}{9} = {a + bi \mid a, b \in \mathbb{F}_{3}}$, 它以与复数扩张有理数相同的方式扩张了原始域。
供参考: 更常见的记号是$\mathbb{F}[X]/(X^2 + 1)$,意思是形成一个域扩张,其中$X^2+1=0$。这会产生一个包含以下形式元素的新域$a+bi$,其中$a,b\in \mathbb{F}$,$i$是一个的根$X^2 + 1$, 使得$i^2 = -1$。
- 迹的值位于基域上,迹的定义域是基域$\mathbb{C}(\mathbb{F})$上的点 。
- 求值定义域由基域$\mathbb{C}(\mathbb{F})$上的点组成 。
- 用于线性组合的所有随机挑战和权重均来自安全域。
- 当计算 DEEP 商时,我们从基域转移到安全域,同时对消失多项式分母短暂使用复扩张。
- 圆 FRI 主要在安全域上工作。然而, 查询值是基本域元素, 因为我们 Merkle 承诺的是基域中的值。
结果
这很酷,但让我们看看这一切如何转化为实际的性能差异。下面是比较用BabyBear上的常规STARK的Plonky3 与以及M31上的circle STARK的分析图表。
- https://github.com/Plonky3/Plonky3/blob/1ee813b1bada8eb5615d2956088b93624cd0a0b2/keccak-air/examples/prove_baby_bear_poseidon2.rs
- https://github.com/Plonky3/Plonky3/blob/1ee813b1bada8eb5615d2956088b93624cd0a0b2/keccak-air/examples/prove_m31_poseidon2.rs
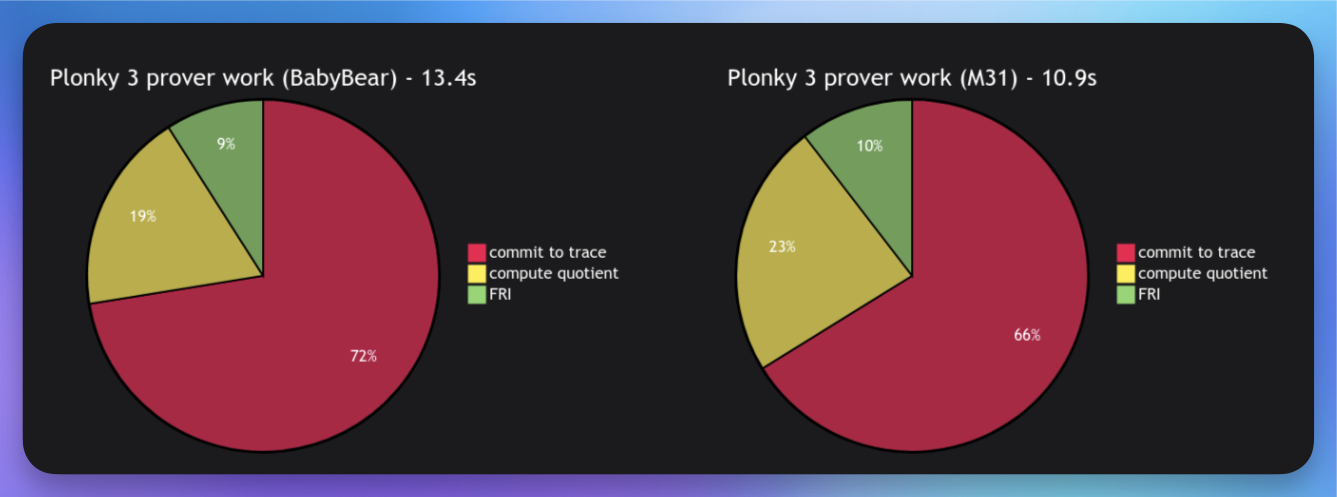
首先要注意的是,证明时间的差异确实约为 1.3 倍。可以看到,circle STARK 花费更少的时间对迹承诺,因为它是在更高效的基域上完成的。因此,由于计算商和 FRI 会涉及扩域工作,因此它们现在占总工作的比例更大。
参考文献
- [HLP24] Haböck et al. (2024) "Circle STARKs" , https://eprint.iacr.org/2024/278
- [HAB23] Ulrich Haböck (2023) "A summary on the FRI low degree test" , https://eprint.iacr.org/2022/1216.pdf
- [ethSTARK] StarkWare Team (2023) "ethSTARK Documentation — Version 1.2" , https://eprint.iacr.org/2021/582.pdf
相关文章:
Circle STARKs 系列(一):梅森素域
探秘 Circle STARKs (重排版)
FRI邻近性测试
代数快速傅立叶变换
- 转载
- 学分: 0
- 分类: 密码学
- 标签: circleSTARK





