Solidity编码规范汇总篇
- Keegan小钢
- 发布于 2024-09-23 21:00
- 阅读 2529
Solidity 编码规范汇总篇。
上周,完成了 Solidity 编码规范的视频录制并上传到了 B 站、Youtube 和视频号。总共分为了 6 个小节,在 B 站的合集地址为:
https://space.bilibili.com/60539794/channel/collectiondetail?sid=3780183
为了方便一些更习惯看文章的同学,这两天我又整理出了文字版本,以下就是该 Solidity 编码规范汇总篇。
为什么需要编码规范
我们知道,每一门编码语言都会有各自的编码规范。那为什么需要编码规范呢?我总结出以下几个原因:
- 提高代码可读性: 编码规范使得代码结构更加清晰,命名更加直观,逻辑更加明确,这样其他开发者(包括编写代码的开发者自己)可以更容易地理解和维护代码。
- 促进团队协作: 在团队开发中,统一的编码规范使得不同开发者编写的代码风格一致,避免了代码风格上的差异导致的混乱和误解,有助于团队成员之间的合作和代码的整合。
- 减少错误: 良好的编码规范通常包括一些最佳实践,如变量命名规则、代码注释等。这些规范可以帮助开发者避免常见的错误,提高代码的可靠性和健壮性。
- 提高维护性: 当代码风格统一时,维护代码的工作量会显著减少。开发者可以快速理解代码的逻辑,进行修改和扩展,降低维护的成本和难度。
- 有助于代码审查: 编码规范使得代码审查变得更加高效,审查者可以专注于代码的逻辑和功能,而不是在代码风格上浪费时间。
- 提升代码质量: 统一的编码规范通常伴随着对代码质量的关注,如代码的可扩展性、可测试性等。这些规范有助于编写出高质量的代码。
- 遵循行业标准: 编码规范通常是根据行业标准或社区共识制定的,遵循这些规范可以确保代码与其他项目或开源库兼容,促进代码的复用和共享。
总的来说,编码规范对于保证代码的质量、提高开发效率、促进团队合作、降低维护成本等方面都有着重要作用,因此每一门编程语言都需要编码规范,Solidity 作为智能合约的开发语言也不例外。下面就会正式介绍 Solidity 这门语言的编码规范。
文件命名
我们编码的第一步就是需要创建源文件,所以第一步我想从文件命名说起。而关于文件命名这部分的编码规范,我总结下来可以归为四点:
- 采用大驼峰式命名法
- 与合约组件名保持一致
- 每个文件里只定义一个合约组件
- interface 命名额外添加大写 I 作为前缀
在 solidity 官方文档里,有列出几种不同的命名风格,如下:
b(single lowercase letter)B(single uppercase letter)lowercaseUPPERCASEUPPER_CASE_WITH_UNDERSCORESCapitalizedWords(or CapWords)mixedCase(differs from CapitalizedWords by initial lowercase character!)
首先,所谓大驼峰式命名法,其实就是 CapitalizedWords 这种风格的命名法,就是由首字母大写的单词组合而成的写法。而 mixedCase 也称为小驼峰式命名法。
合约组件,其实就是 interface、library、contract。文件名要与合约组件名保持一致,就是说要与文件里所定义的 interface/library/contract 的名称一样。比如文件名为 UniswapV3Pool.sol,文件里定义的 contract 名称就是 UniswapV3Pool。
每个文件里只定义一个合约组件,就是不要在文件里同时定义多个合约组件。比如,Uniswap 的 v3-core 里,有定义了几个回调类的接口:
IUniswapV3FlashCallbackIUniswapV3MintCallbackIUniswapV3SwapCallback
这三个接口,每个接口里面都只定义了一个函数。从语法上来说,是可以只用一个文件来包含这三个接口的,比如就用 UniswapV3Callback.sol,文件里则大致如下:
// SPDX-License-Identifier: GPL-2.0-or-later
pragma solidity >=0.5.0
interface IUniswapV3FlashCallback {
...
}
interface IUniswapV3MintCallback {
...
}
interface IUniswapV3SwapCallback {
...
}从语法上来说,这是没有错的。但是,Uniswap 则将其分为了三个文件,如下:
IUniswapV3FlashCallback.solIUniswapV3MintCallback.solIUniswapV3SwapCallback.sol
这就是每个文件里只定义一个合约组件。
另外,上面这个例子也涉及到了最后一点命名规范,即 interface 命名额外添加大写 I 作为前缀。你可以看到这几个 interface 都是加了大写 I 作为前缀的,而 library 和 contract 则不会有这种前缀。遵循这种规范,就可以直接从文件命名区分出哪些是 interface 了。
文件编排
在一个项目中,通常都不会只有少数几个文件,那文件多了,自然是需要做好文件编排了。那关于文件编排这块的规范,我的建议就是,可以将不同类型的多个合约文件归类到不同文件夹下。
比如,存在多个 interface 时,可以将这些 interface 文件统一归类到 interfaces 目录下。而多个 library 文件则可以统一归类到 libraries 目录下。抽象合约则可以放置于 base 或 utils 目录下。而需要进行部署的主合约则大多直接放在 contracts 或 src 主目录下。
另外,文件比较多的情况下还可以进一步拆分目录。比如,Uniswap/v3-core 的 interfaces 下还再划分出了 callback 和 pool 两个子目录。
而像 OpenZeppelin 这种库则又不一样,它更多的是按功能模块进行目录分类,不同的合约文件是划分到不同的功能目录下的。在这些功能目录下,大多就没有再根据合约组件类型进行进一步的目录划分。比如,access 目录下就直接放置了 IAccessControl.sol,一来,并没有那么多 interface,二来,目录编排更多是根据功能设置的。但它依然也有一个 interfaces 目录存放了所有的接口文件。
合约声明
接下来,就开始进入文件内部编码的规范了。这一小节,先来总结下合约声明部分。
首先,第一行,我们应该声明 SPDX-License-Identifier,指定要使用的许可证。虽然不声明这个,编译不会报错,但会有警告,为了消除警告,所以我们最好还是把这个声明补上。
第二行,使用 pragma 声明要支持的 solidity 版本。关于这个,我的建议是分情况。如果是 interface、library、抽象合约,建议声明为兼容版本,比如 ^0.8.0。如果是需要部署的主合约则建议声明为固定版本。关于这一点,Uniswap/v4-core 是个很好的示例。其主合约 PoolManager 的 pragma 声明如下:
pragma solidity 0.8.26可以看到,它声明为了一个固定的版本 0.8.26。
而所有 interface、library、抽象合约全都声明为兼容版本,有的是 ^0.8.0,有的是 ^0.8.24。声明为 ^0.8.24 的通常是因为用到了该版本才开始支持的一些特性。
而关于 import 部分,主要有两个建议:一是建议指定名称导入;二是要 import 的第三方合约存在多个版本时,建议指定版本号。
直接看下面这几个例子:
import "@openzeppelin/contracts/token/ERC20/ERC20.sol";
import {ERC20} from "@openzeppelin/contracts/token/ERC20/ERC20.sol";
import {ERC20} from "@openzeppelin/contracts@0.5.2/token/ERC20/ERC20.sol";上面三种 import 的写法,第一种是很多人(也包括我)之前最常用的写法,就是直接导入整个文件。第二种增加了要导入的具体合约名称,这就是前面说的,建议指定名称导入。第三种,在 contracts 后面增加了 @0.5.2 的声明来制定要导入的具体版本号。
这第三种写法就是我们最推荐的一种导入方式。因为 OpenZeppelin 已经发布了多个不同版本的库。
不过,如果要导入的第三方合约并不存在多个不同版本的情况下,则没必要增加版本声明了。比如,@uniswap/v3-core 只有一个版本的库,那导入该库的合约时就没必要指定版本了,如下即可:
import {IUniswapV3Pool} from "@uniswap/v3-core/contracts/interfaces/IUniswapV3Pool.sol";interface
interface 是合约交互的接口,也是前端和后端交互时用到的 abi 的来源,所以我们编写实际代码时,通常都会先定义 interface。这一节就来讲讲关于 interface 编码时有哪些编码规范。
首先,从代码结构上,建议以下面这种顺序进行编排:
ErrorsEventsEnumsStructsFunctions
首先定义 Errors。error 类型是在 0.8.4 才开始支持的,所以,如果 interface 里面有定义 error,建议声明 pragma 时至少指定为 ^0.8.4。而声明 error 时,命名建议采用大驼峰式命名法,如果有带参数,则参数采用小驼峰式命名法。如下示例:
error ZeroAddress();
error InvalidAddress(address addr);接着,定义 Events。所定义的事件名采用大驼峰式命名法,事件参数同样也是采用小驼峰式命名法。另外,如果参数较多的情况下,建议每个参数单独一行。如下示例:
event Transfer(address indexed from, address indexed to, uint value);
event TransferBatch(
address indexed operator,
address indexed from,
address indexed to,
uint256[] ids,
uint256[] values
);其实,官方文档里也有说明,建议每一行代码不要超过 120 字符,所以太长的情况下就要用换行的方式进行编排。在 Solidity,每个参数单独一行是很常见的一种编码格式。
紧接着,如果有的话则可以定义 Enums,即枚举类型。命名也是采用大驼峰式命名法,如下示例:
enum OrderStatus {
Pending,
Shipped,
Delivered,
Canceled
}之后,则可以定义 Structs,即结构体。结构体的名称采用大驼峰式命名法,里面的字段则采用小驼峰式命名法,如下示例:
struct PopulatedTick {
int24 tick;
int128 liquidityNet;
uint128 liquidityGross;
}然后,就可以定义 Functions 了。但函数还可以再进行细分,可以根据下面的顺序进行声明:
External functions with payableExternal functionsExternal functions with viewExternal functions with pure
就是说,我们在 interface 里定义多个函数的时候,建议按照这个顺序对这些函数进行编排。以下是几个示例:
// external function with payable
function burn(uint256 tokenId) external payable;
function createAndInitializePoolIfNecessary(
address token0,
address token1,
uint24 fee,
uint160 sqrtPriceX96
) external payable returns (address pool);
// external function
function mint(
address recipient,
int24 tickLower,
int24 tickUpper,
uint128 amount,
bytes calldata data
) external returns (uint256 amount0, uint256 amount1);
// external function with view
function getPopulatedTicksInWord(address pool, int16 tickBitmapIndex)
external
view
returns (PolulatedTick[] memory populatedTicks);
function ticks(int24 tick)
external
view
returns (
uint128 liquidityGross,
int128 liquidityNet,
uint256 feeGrowthOutside0X128,
uint256 feeGrowthOutside1X128,
int56 tickCumulativeOutside,
uint160 secondsPerLiquidityOutsideX128,
uint32 secondsOutside,
bool initialized
);
// external function with pure
function mulDiv(uint a, uint b, uint c) external pure returns (uint d);除了顺序之外,这里面还有一些细节需要说一说。
首先,可以看到,不管是函数名还是参数名,都是采用了小驼峰式命名法。
其次,还可以看到有不一样的换行格式。createAndInitializePoolIfNecessary 和 mint 这两个函数都是参数各自一行。getPopulatedTicksInWord 则变成了函数修饰符和 returns 语句各自一行,这也是一种换行的写法。最后,ticks 函数的返回参数列表又拆分为每个返回参数单独一行,当返回参数较多的时候这也是常用的写法。
library
接着,来聊聊关于 library 的用法。
library 里无法定义状态变量,所以 library 其实是无状态的。
从语法上来说,library 可以定义不同可见性的函数,但实际应用中,通常只定义 internal 和 private 的函数,很少会定义外部可见的 external 和 public 函数。如果一个 library 里有定义了外部可见的函数,那部署的时候也会和只有内部函数的 library 不一样。当然,这是另一个话题了。
library 也可以定义常量和 errors。有些当纯只定义了常量的 library,比如 Uniswap/v4-periphery 里有一个 library 如下:
// SPDX-License-Identifier: GPL-2.0-or-later
pragma solidity ^0.8.0;
/// @title Action Constants
/// @notice Common constants used in actions
/// @dev Constants are gas efficient alternatives to their literal values
library ActionConstants {
/// @notice used to signal that an action should use the input value of the open delta on the pool manager
/// or of the balance that the contract holds
uint128 internal constant OPEN_DELTA = 0;
/// @notice used to signal that an action should use the contract's entire balance of a currency
/// This value is equivalent to 1<<255, i.e. a singular 1 in the most significant bit.
uint256 internal constant CONTRACT_BALANCE = 0x8000000000000000000000000000000000000000000000000000000000000000;
/// @notice used to signal that the recipient of an action should be the msgSender
address internal constant MSG_SENDER = address(1);
/// @notice used to signal that the recipient of an action should be the address(this)
address internal constant ADDRESS_THIS = address(2);
}可以看到,这个 ActionConstants 就只是定义了 4 个常量而已。
library 使用场景最多的其实是对特定类型的扩展功能进行封装。UniswapV3Pool 代码体里一开始就声明了一堆 using for,如下所示:
contract UniswapV3Pool is IUniswapV3Pool, NoDelegateCall {
using LowGasSafeMath for uint256;
using LowGasSafeMath for int256;
using SafeCast for uint256;
using SafeCast for int256;
using Tick for mapping(int24 => Tick.Info);
using TickBitmap for mapping(int16 => uint256);
using Position for mapping(bytes32 => Position.Info);
using Position for Position.Info;
using Oracle for Oracle.Observation[65535];
...
}这些 using 后面的 libraries 封装的函数大多就是对 for 类型的功能扩展。比如,LowGasSafeMath 可以理解为就是对 uint256 类型的功能扩展,其内定义的函数第一个参数都是 uint256 类型的。LowGasSafeMath 里有定义了一个 add 函数,如下:
function add(uint256 x, uint256 y) internal pure returns (uint256 z) {
require((z = x + y) >= x);
}在 UniswapV3Pool 使用到 LowGasSafeMath 的 add 函数的地方其实不少,比如下面这个:
uint256 balance0Before = balance0();
require(balance0Before.add(uint256(amount0)) <= balance0(), 'IIA');其中,balance0Before.add(uint256(amount0)) 其实就是调用了 LowGasSafeMath 的 add 函数。而且,通过这种语法糖的包装调用,不就等于变成了uint256 这个类型本身的扩展函数了,所以才说 library 可以理解为是对特定类型的功能扩展。
最后,虽然 library 本身没法直接访问状态变量,但状态变量是可以通过函数传参的方式间接被 library 函数所访问到的,只要将函数参数声明为 storage 即可。比如 library Position,声明了 get 和 update 函数,这两个函数的第一个参数都带了 storage 修饰,其核心代码如下:
function get(
mapping(bytes32 => Info) storage self,
address owner,
int24 tickLower,
int24 tickUpper
) internal view returns (Position.Info storage position) {
position = self[keccak256(abi.encodePacked(owner, tickLower, tickUpper))];
}
function update(
Info storage self,
int128 liquidityDelta,
uint256 feeGrowthInside0X128,
uint256 feeGrowthInside1X128
) internal {
...
// update the position
if (liquidityDelta != 0) self.liquidity = liquidityNext;
self.feeGrowthInside0LastX128 = feeGrowthInside0X128;
self.feeGrowthInside1LastX128 = feeGrowthInside1X128;
if (tokensOwed0 > 0 || tokensOwed1 > 0) {
// overflow is acceptable, have to withdraw before you hit type(uint128).max fees
self.tokensOwed0 += tokensOwed0;
self.tokensOwed1 += tokensOwed1;
}
}get 函数的 self 参数就是 storage 的,而且数据类型是 mapping 的,意味着传入的这个参数是个状态变量,而返回值也是 storage 的,所以返回的 position 其实也是状态变量。
update 函数的 self 参数也一样是 storage 的,也同样是一个状态变量,在代码里对 self 进行了修改,也是会直接反映到该状态变量在链上的状态变更。
contract
下面就来聊聊 contract 方面的编码规范,主要讲代码结构,一般建议按照以下顺序进行编排:
using for常量状态变量EventsErrorsModifiersFunctions
首先,如果需要用到库,那就先用 using for 声明所使用的库。
接着,定义常量。常量还分为 public 常量和 private 常量,一般建议先声明 public 的再声明 private 的。另外,常量命名采用带下划线的全字母大写法,像这样:UPPER_CASE_WITH_UNDERSCORES。
声明完常量之后,紧接着就可以声明状态变量。状态变量也是先声明 public 的,然后再声明 private 的。命名则通常采用小驼峰式命名法。另外,private 的状态变量通常还会再添加前下划线,以和 public 的变量区分开来。如下示例:
// public state variable
uint256 public totalSupply;
// private state variable
address private _owner;
mapping(address => uint256) private _balanceOf;之后,如果有事件需要声明,则声明事件。再之后,如果有错误需要声明,则声明错误。
事件和错误,通常会在 interface 中进行声明,所以直接在 contract 里声明的情况相对比较少。
然后,就是声明自定义的 modifiers 了。另外,modifier 的命名采用小驼峰式命名法,以下是一个示例:
modifier onlyOwner() {
if(msg.sender != _owner) revert OwnableUnauthorizedAccount(msg.sender);
_;
}最后,就是一堆函数定义了。因为函数众多,所以我们还需要再进行编排,可按照如下顺序编排函数:
构造函数receive 函数fallback 函数external 函数external payableexternalexternal viewexternal pure
public 函数public payablepublicpublic viewpublic pure
internal 函数internalinternal viewinternal pure
private 函数privateprivate viewprivate pure
可见,先定义构造函数,接着定义 receive 和 fallback 回调函数,如果没有则不需要。
之后,根据可见性进行排序,顺序为 external、public、internal、private。
不同的可见性函数内,又再根据可变性再进行排序,以 external 类函数为例,顺序为 payable 函数、external 写函数、external view 函数、external pure 函数。其他可见性类型函数也是同理。
另外,关于 internal 和 private 函数的命名,建议和私有状态变量一样,添加前下划线作为前缀,以和外部函数区分。如下示例:
// internal functions
function _transfer(address from, address to, uint256 value) internal {}
function _getBalance(address account) internal view returns (uint256) {}
function _tryAdd(uint256 a, uint256 b) internal pure returns (uint256) {}
// private functions
function _turn() private {}
function _isParsed() private view returns (bool) {}
function _canAdd(uint256 a, uint256 b) private pure returns (uint256) {}最后,每个函数里的多个函数修饰符也需要进行排序,一般建议按照如下顺序进行排序:
可见性(external/public/internal/private)可变性(payable/view/pure)VirtualOverride自定义 modifiers
直接看以下例子:
function mint() external payable virtual override onlyOwner {}以上就是关于 contract 部分的编码规范建议了。
注释
最后聊聊注释。
首先,要记住一点:良好的命名即注释。
即合约、事件、错误、状态变量、函数、参数等等,所有的命名本身都应该能很好地说明其所代表的含义,这本身就是一种最直观的注释。额外添加的注释更多其实是为了进行补充说明用的。
Solidity 里支持的注释标签包括以下这些:
@title@author@notice@dev@param@return@inheritdoc@custom:...
这些标签的说明在官方文档中也有说明,如下图:

官方编码规范建议对于所有公开的接口添加完全的注释,也即是说,我们可以给 interface 添加完整注释。Uniswap 就是一个很好的实践方,你可以看到 Uniswap 的所有 interface 都有很完整的注释。
另外,添加的注释内容还可以在区块浏览器上看到注释内容。比如,我们查看 COMP 代币合约:
在交互页面,点开 approve 时如下:
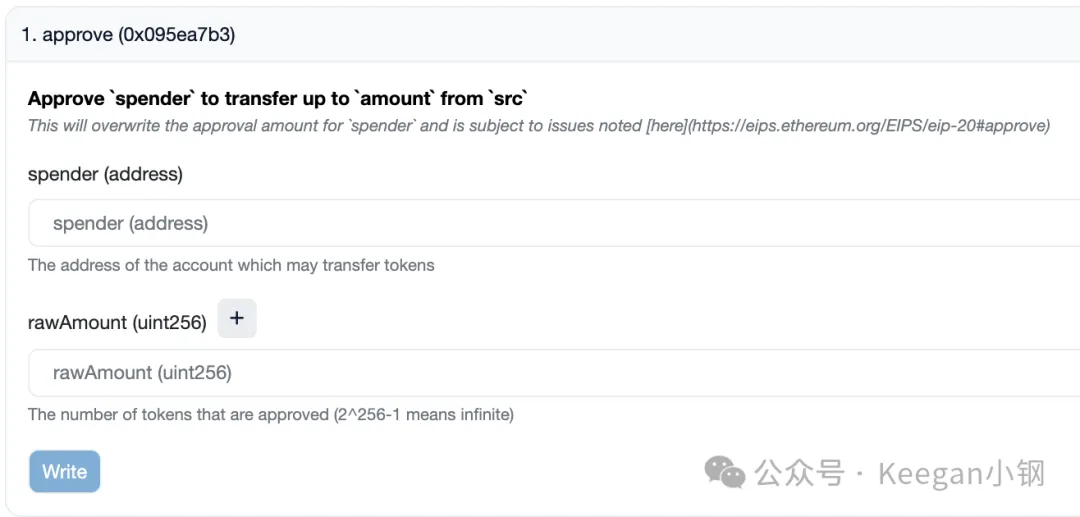
再查看源代码里该 approve 函数的注释:
/**
* @notice Approve `spender` to transfer up to `amount` from `src`
* @dev This will overwrite the approval amount for `spender`
* and is subject to issues noted [here](https://eips.ethereum.org/EIPS/eip-20#approve)
* @param spender The address of the account which may transfer tokens
* @param rawAmount The number of tokens that are approved (2^256-1 means infinite)
* @return Whether or not the approval succeeded
*/
function approve(address spender, uint rawAmount) external returns (bool) {
...
}可以看出,@notice、@dev 和 @param 的内容都展示在了区块浏览器交互页面上了。
- 原创
- 学分: 12
- 分类: Solidity
- 标签:





