理解区块级访问列表
- Franco Victorio
- 发布于 19小时前
- 阅读 70
EIP-7928(区块级访问列表)是 Glamsterdam 升级的核心特性,旨在通过允许并行交易执行和 I/O 预取来加速以太坊的区块验证。它通过在区块中包含交易的状态读写列表(BALs)来实现,从而解决现有顺序执行的瓶颈,提升网络吞吐量并为 zkEVM 等未来技术奠定基础。
EIP-7928 (区块级访问列表) 是即将到来的 Glamsterdam 升级的主要特性1,预计年中激活。 EIP 网站将其总结为一项“在以太坊上解锁并行交易执行”的功能。在本文中,我们将了解这意味着什么、EIP 如何工作以及它为何如此设计。
这将是一个迂回的解释:我们将有意地从一个错误的开端入手,以便更好地理解实际的解决方案。如果你只想快速了解,我建议观看 这个短视频。
区块提议和验证
在以太坊中,每个新区块都由随机选择的验证者提议,并传播到网络的其余部分,其他节点接收并检查其是否有效。此验证中最耗时的部分是重新执行区块中的所有交易,以验证结果状态是否与预期状态匹配。
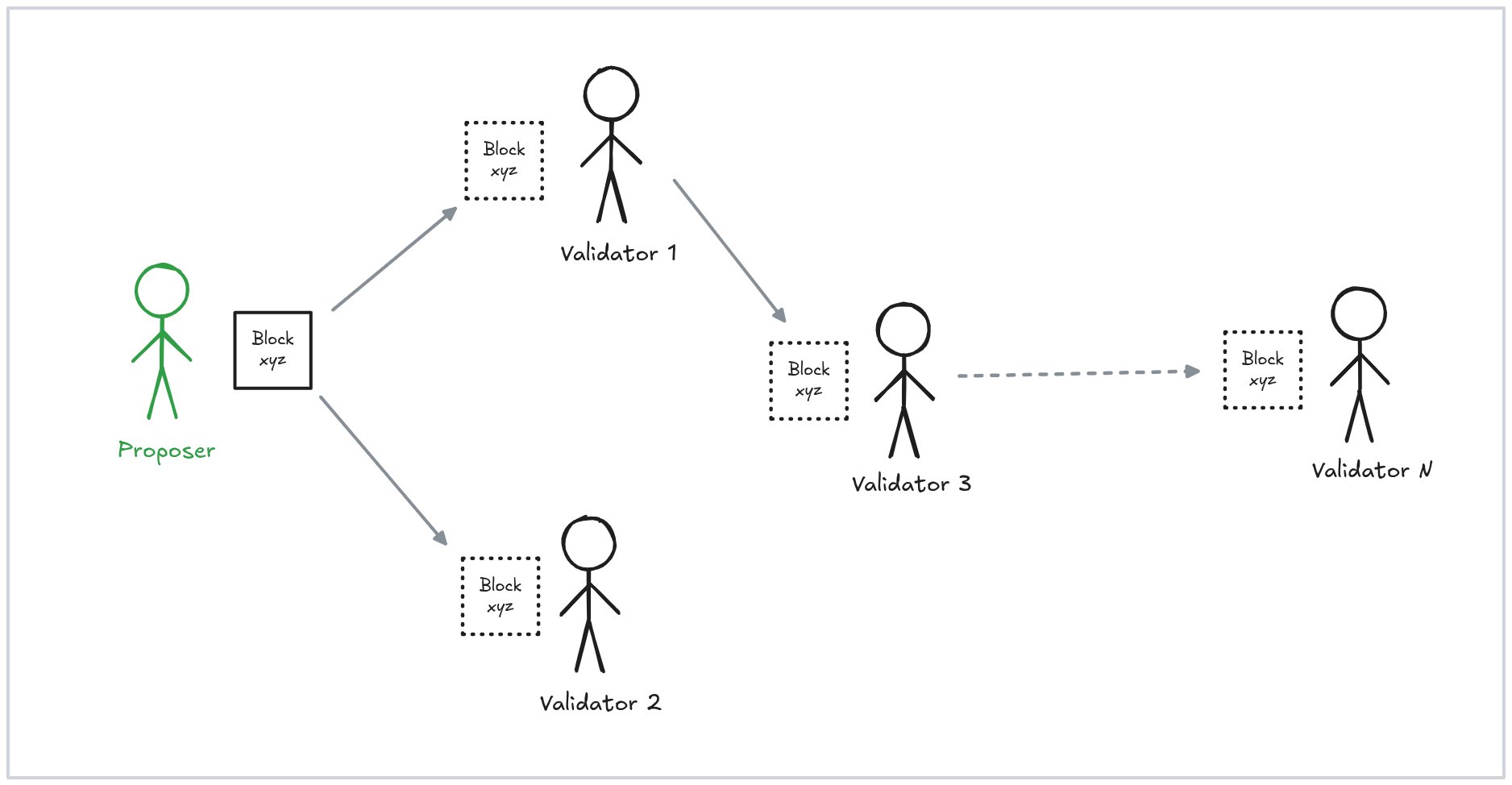 一个区块被提议、传播和验证。
一个区块被提议、传播和验证。
区块中的交易有一个由区块构建者确定的顺序。在验证区块时必须遵守这个顺序;否则,结果状态可能会不同。例如,想象一个只有两笔交易的区块,两笔交易都调用同一个合约:
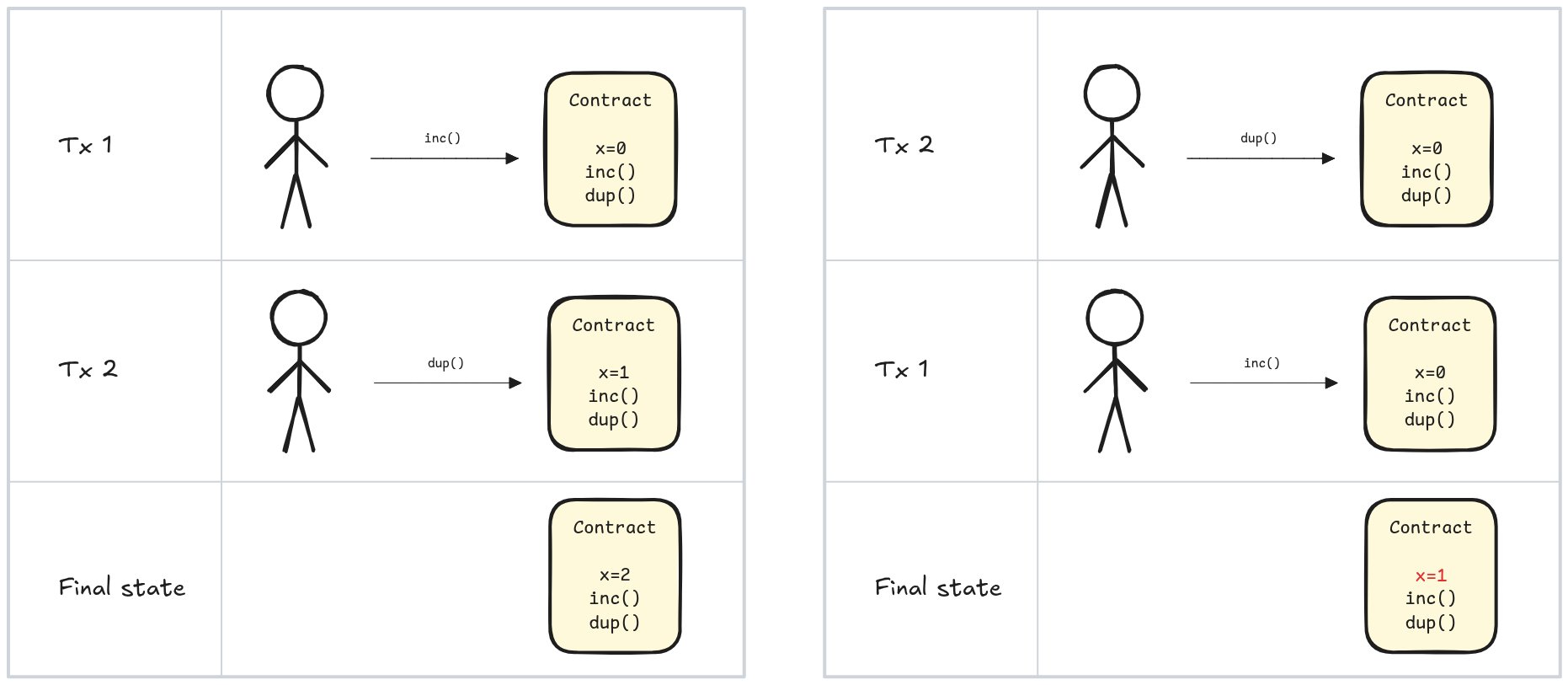 示例 1:两笔交易,根据它们的执行顺序会产生不同的最终状态。
示例 1:两笔交易,根据它们的执行顺序会产生不同的最终状态。
在这里,我们需要按顺序执行交易才能得到预期的状态。但情况并非总是如此。看这个例子:
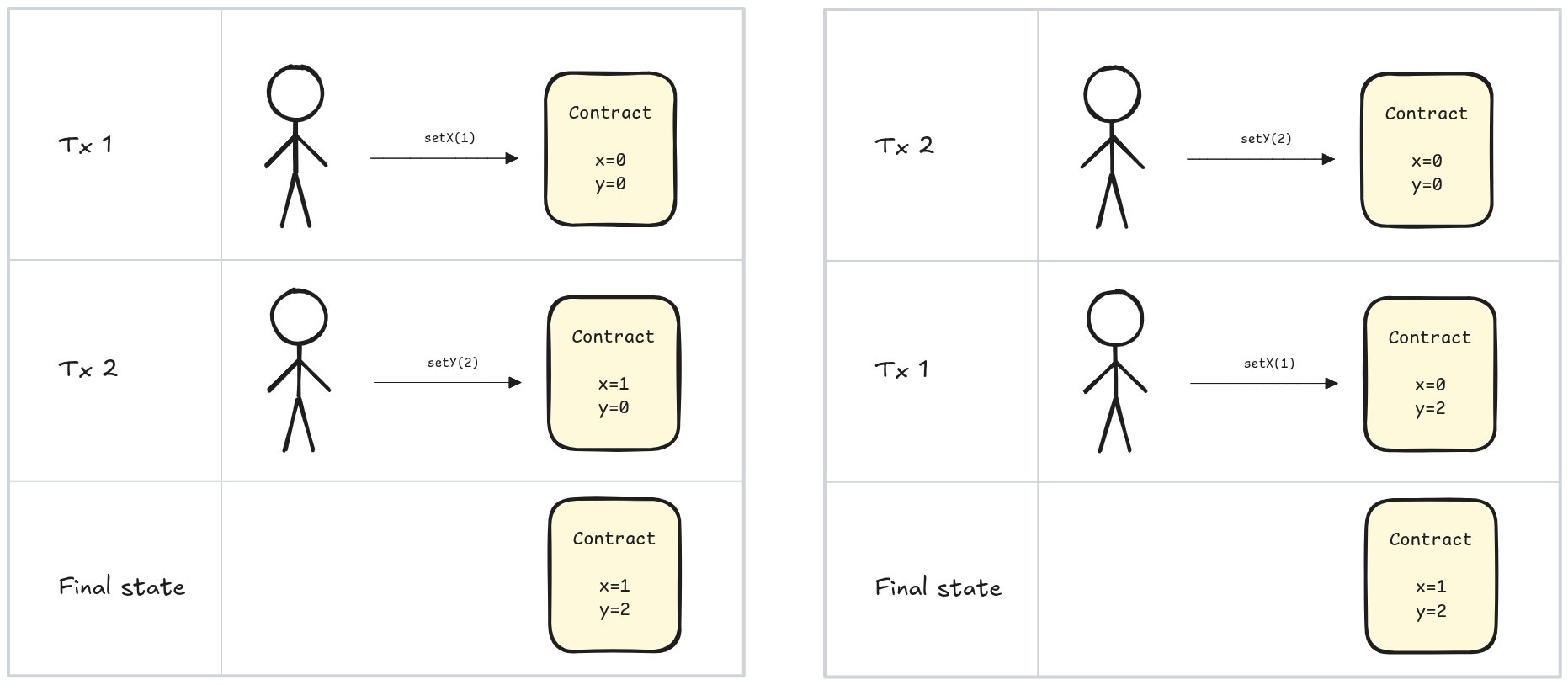 示例 2:两笔交易,无论它们的执行顺序如何,都会产生相同的最终状态。
示例 2:两笔交易,无论它们的执行顺序如何,都会产生相同的最终状态。
在这种情况下,我们执行交易的顺序并不重要,因为结果状态是相同的。顺序重新执行这些交易将是浪费:我们可以同时运行它们,而不会影响结果。
这些示例说明,有时交易可以并行化,有时则不能。我们能否以某种方式利用这一点来实现更快的重新执行?
依赖图
我们可以通过说 tx 2 依赖于 tx 1 来描述上一节中的示例 1。但“依赖”到底是什么意思?现在让我们使用这个定义:
给定两笔交易 A 和 B,如果满足以下条件,我们称 B 依赖于 A:
A 在区块中先于 B。
A 写入了一些 B 读取的状态。
在示例 1 中,tx 2 读取了一个先前由 tx 1 写入的存储槽 (x),从而产生了依赖关系。请记住,“状态”可以指合约的存储(如该示例所示),但它也可以指世界状态的其他部分,例如账户余额或某个地址的代码。
现在让我们问,如果我们能提前知道区块中的所有依赖关系会发生什么?暂时忽略我们如何找出这一点;只假设我们知道。如果拥有这些信息,我们就可以在执行期间实现一定程度的并行化。例如,给定一个包含这些交易的区块:
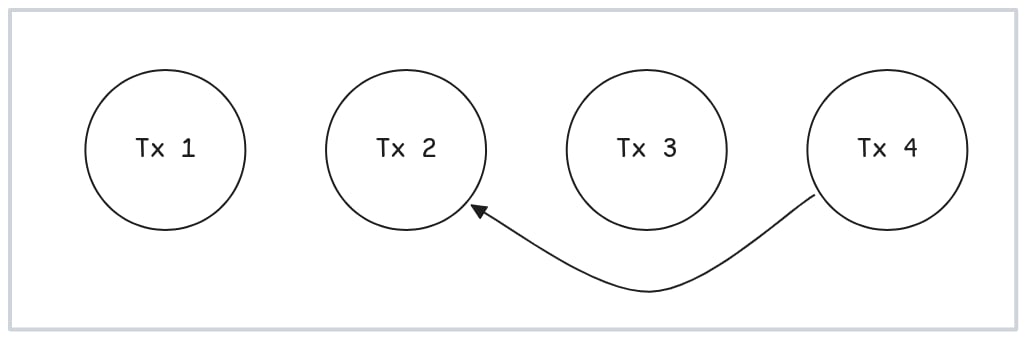 一个包含四笔交易且只有一处依赖关系的区块。
一个包含四笔交易且只有一处依赖关系的区块。
那么我们可以并行执行前三笔交易,然后2执行最后一笔交易:
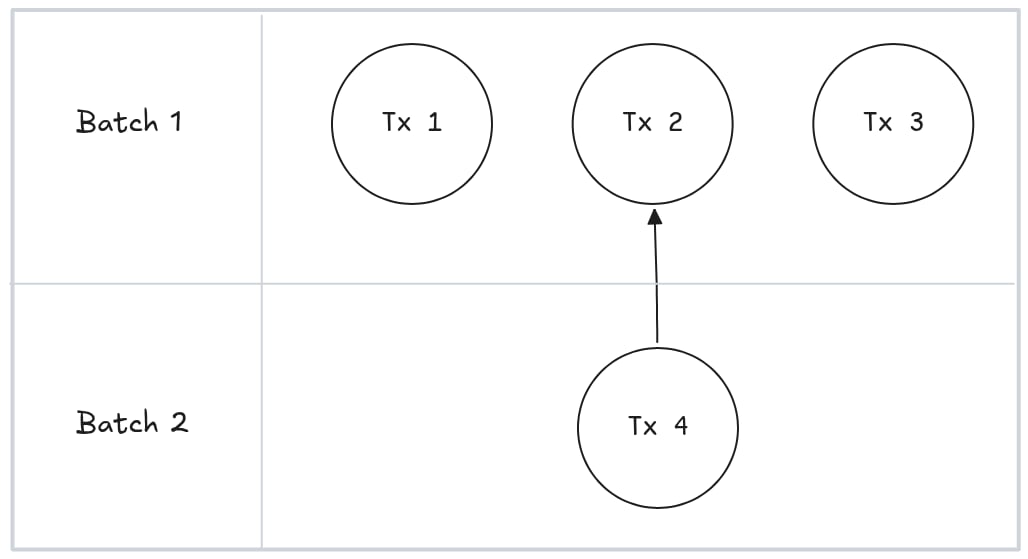 使用依赖图并行执行交易。
使用依赖图并行执行交易。
此时你可能想知道这对真实区块来说有多现实。这是一个真实的依赖图,取自 dependency.pics:
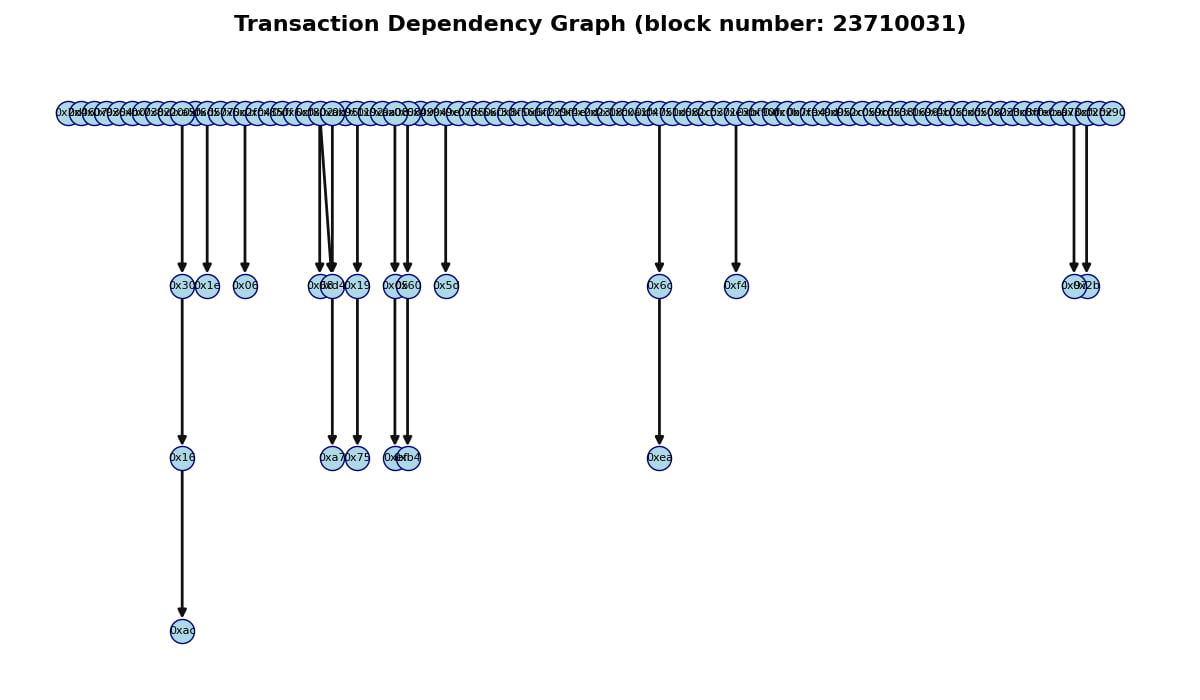 区块 23710031 的依赖图(来源)。
区块 23710031 的依赖图(来源)。
在这种情况下,整个区块只需分四批重新执行,这对于一个包含 161 笔交易的区块来说似乎相当不错。但我们可能不会总是那么幸运:
 区块 23710002 的依赖图(来源)。
区块 23710002 的依赖图(来源)。
这里我们有一个很长的依赖链,显著降低了我们从并行化中可能获得的速度提升。
总之,如果我们(以某种方式)拥有了一组交易的依赖图,我们可以以一定程度的并行化重新执行它们,但从中能获得多少好处将取决于图的结构。很容易想象一个病态情况,其中每笔交易都依赖于前一笔交易,使得顺序重新执行不可避免。
构建依赖图
到目前为止,我们假设我们有一个可以使用的依赖图,但这个依赖图从何而来?我们如何知道哪些交易依赖于哪些?
我们说过,如果两笔交易中的一笔写入了另一笔稍后必须读取的状态,那么它们之间就存在依赖关系。但由于 EVM 是图灵完备的,在不实际执行它们的情况下,无法提前知道这一点。也许我们可以采取一种保守的方法,比如说“如果两笔交易调用同一个合约,它们就存在依赖关系”,但很容易证明这行不通。在示例 2 中,我们看到了两笔调用同一个合约但可以独立执行的交易:
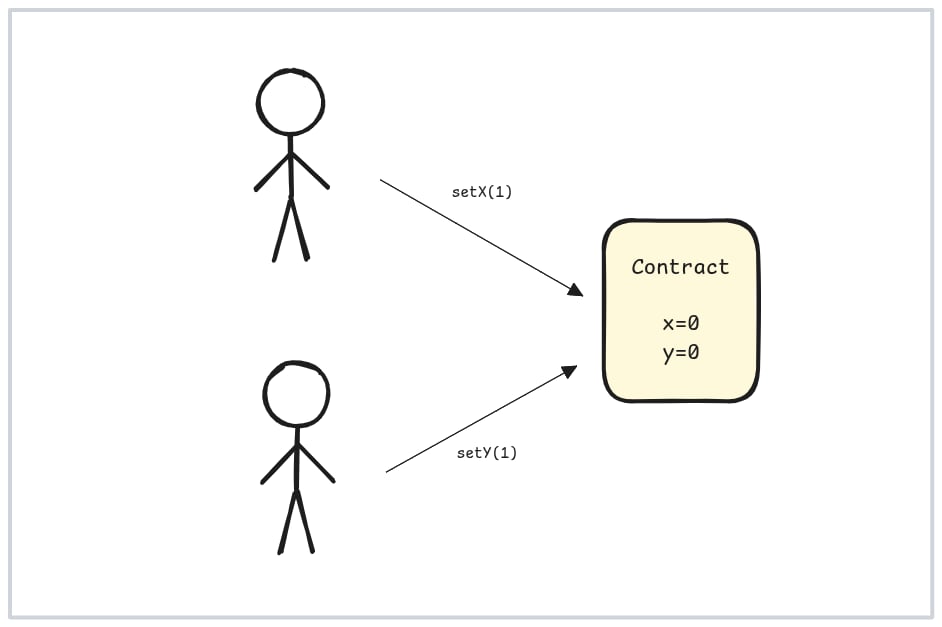 两笔交易调用同一个合约但可以独立执行。
两笔交易调用同一个合约但可以独立执行。
更糟糕的是,我们可能有两笔交易调用不同的合约,但它们之间仍然存在依赖关系:
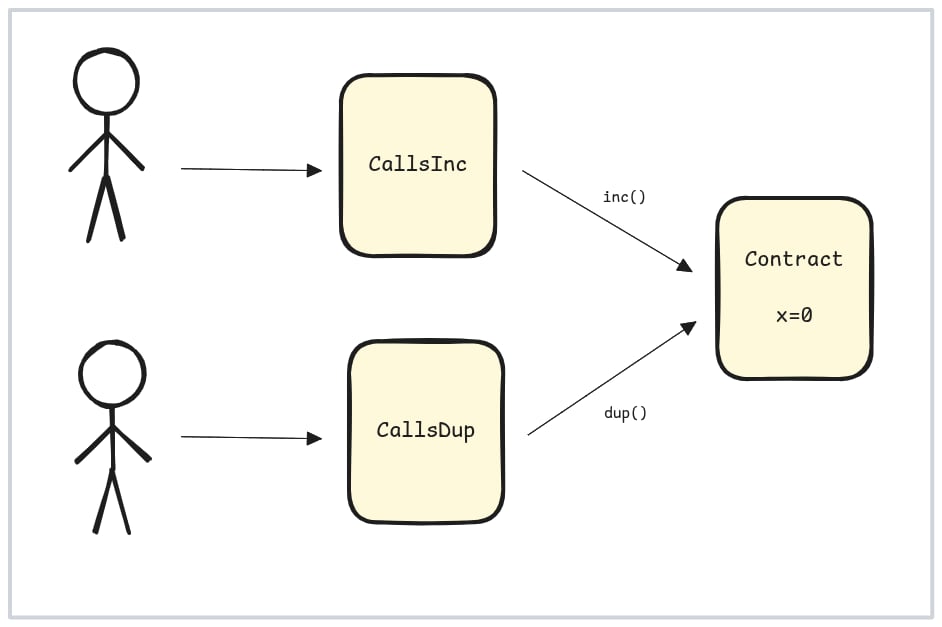 两笔交易调用不同的合约但不能独立执行。
两笔交易调用不同的合约但不能独立执行。
我们无法逃避这样一个事实:我们需要执行交易来构建依赖图。但我们希望依赖图能够加快区块交易的执行速度……
这似乎是一个无法解决的问题,但让我们回顾一下区块是如何产生的:一个验证者提议一个区块,网络中的其他节点验证它。这意味着区块提议者3可以顺序执行交易,在此过程中构建依赖图,并将该图与区块一起传播。其他验证者随后可以使用这些数据来并行化重新执行。
要构建依赖图,我们只需顺序运行交易,并跟踪哪些状态被哪些交易读取或写入。
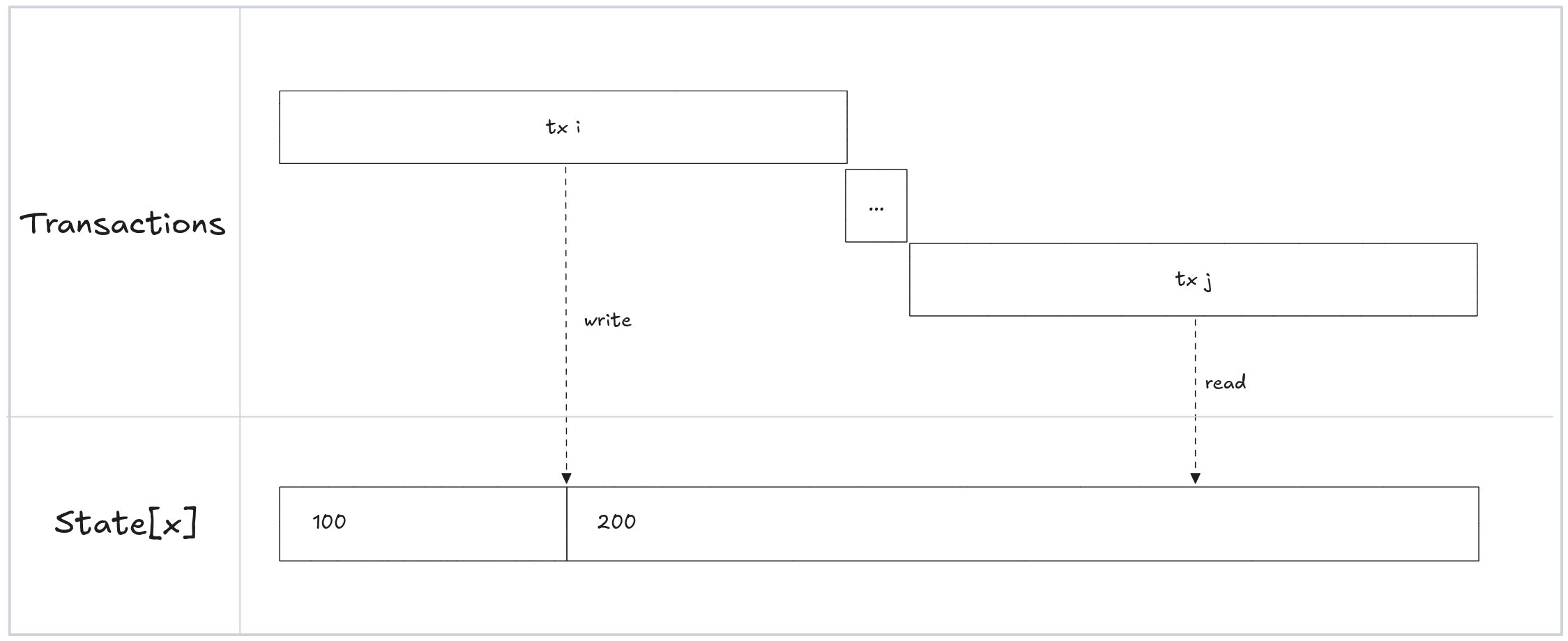 两笔交易使用相同的状态片段。
两笔交易使用相同的状态片段。
在这个例子中,tx i 写入 state[x],随后被 tx j 读取,因此我们会添加一个从 j 到 i 的依赖关系。如果我们对所有交易都这样做,我们将获得每个交易的依赖列表,代表区块的依赖图。
这种方法似乎可行。但我们无法实现完全并行化,而且最坏的情况仍然是顺序执行。我们能做得更好吗?
区块级访问列表
让我们改变策略,转而问:我们需要什么才能无论如何都能并行运行所有交易?
让我们再次看之前的例子。交易 j 有一个依赖关系,因为它读取了由交易 i 修改的 state[x]。但是,如果 j 提前知道 state[x] 在它需要时的值,那么就没有理由不能独立执行它。我们已经跟踪了状态变化来构建依赖图。为什么不传播那些呢?
换句话说,对于每笔交易,我们可以跟踪它们写入的状态,以及该状态的最终值。对于上述示例,结果状态差异将是:
{
[i]: {
[x]: 200
}
}有了这些信息,我们可以使用一个简单的状态读取算法并行执行所有交易:
def read(j, x):
last = find_last_writer(j, x) # j 之前修改 x 的最后一笔交易
if last:
return state_diff[last][x]
else:
return state[x]就是这样。这就是区块级访问列表(BALs)所做的。差不多。
实际上,BALs 既包括状态更改,也包括读取列表。之前的示例将类似于:
{
[i]: {
writes: {
[x]: 200
},
reads: []
},
[j]: {
writes: {},
reads: [x]
}
}这样做的原因是 I/O。当我们说“读取状态”时,我们指的是磁盘访问,这是一个相对较慢的操作。如果我们可以提前知道所有写入和读取,那么我们就能知道所有交易需要的所有状态,从而允许我们在执行开始前一次性预取必要的数据。这意味着我们可以并行执行所有交易,并且在执行过程中无需执行任何磁盘 I/O。4
实际的 BAL 格式比我分享的要复杂得多。它看起来更像这样:
BlockAccessList = List[AccountChanges]
AccountChanges = [ Address, List[SlotChanges],\
List[StorageKey],\
List[BalanceChange],\
List[NonceChange],\
List[CodeChange]\
]
SlotChanges = [StorageKey, List[StorageChange]]
## etc这是因为,正如我们之前提到的,“状态”可以指代多种事物:存储槽、余额、nonce、代码等。你可以在 EIP 中查看 BAL 的完整定义。
尽管并行执行 + I/O 预取带来的速度提升看起来很棒,但也存在缺点。我们现在必须同时共享区块及其 BAL。这会增加传播时间,原则上可能产生比我们从 BAL 获得的性能收益更显著的负面影响。论点是这种权衡是值得的。例如,请参阅 Worse-case analysis for BALs。5
遗留问题
区块级访问列表还有其他几个重要(或至少有趣)但对上述解释并非必不可少的方面。
面向用户的更改
在协议的内部工作原理之外,BALs 对事物改变不大。据我所知,两个主要变化发生在区块头和 JSON-RPC 层。
-
区块头新增了一个字段
blockAccessListHash,其中包含 BAL 的哈希值。这允许你在不重新执行区块的情况下检查给定区块的 BAL 是否正确,这在无执行验证等场景中很有用。 -
有一个新的 eth_getBlockAccessList 方法,可用于获取给定区块的 BAL。不过,BALs 并非永久可用:客户端只需将其保留约 3553 个 epoch(约 2 周),之后可以将其修剪。BAL 哈希作为区块头的一部分,当然会永久保留。
为何需要更快的重新执行?
在我们的讨论中,我们理所当然地认为更快的重新执行是好的,好到甚至值得将其作为主要特性。但为什么会这样呢?老实说,EIP 中没有提及这一点。我所看到的唯一解释是在 主要特性提案 中:
社区表达了一个明确的愿望:以太坊 L1 必须扩展以满足用户和开发者的需求。BALs 带来了性能提升,对于更高的吞吐量和/或更短的插槽时间至关重要。它们也为基于 zkEVM 的轻节点(无执行 + 无状态)、全节点(无执行 + 有状态)和部分无状态执行铺平了道路。
这看起来很合理。
BALs 与可选访问列表
“访问列表”这个术语在以太坊中已经存在:交易可以包含一个可选访问列表6,这是一个非常不同的概念:
-
它们作用于交易层面,而非整个区块层面。
-
它们只关乎访问,不包括状态差异。
-
它们不必是完整的。一笔交易可以读取某些状态,而不将其包含在其访问列表中。
-
它们甚至不必是正确的。如果一个区块的 BAL 与其应有的不完全一致,则该区块会被拒绝。一笔交易的访问列表可以包含实际未被访问的项。
-
而且,正如其名称所示,它们是可选的。你可以发送不带访问列表的交易。
我不清楚一旦 BALs 加入后,交易级访问列表会受到怎样的影响。我看到有人暗示从长远来看它们将不再有意义,但我并不完全理解原因。
历史注解
 早期 BALs 提案的截图
早期 BALs 提案的截图
如你所见,最初的想法只包括读取,并且完全是关于 I/O 预取的。写入是后来添加的,以实现并行执行。从这个意义上说,BALs 的发展方式与我在这里解释它们的方式是相反的。但由于该功能的“营销”重点是并行执行,我认为从那里开始解释是有意义的。我也认为这是一种更好的理解它们的方式。
这个早期迭代也解释了为什么 BALs 会有这个名字,在我看来这似乎是个用词不当。它并非 100% 错误,因为写入也是一种访问,但感觉有点不对劲。无论如何,现在改变它为时已晚。
感谢阅读!在下一篇文章中,我们将探讨 EIP-8024 (向后兼容的 SWAPN, DUPN, EXCHANGE),这是另一个(可能)将包含在 Glamsterdam 中的 EIP,我们希望它能一劳永逸地解决 Solidity 臭名昭著的“栈深度过大”错误。
如果你想在新文章发布时收到通知,可以订阅本博客。
订阅
- 主要特性是网络升级中包含的旗舰功能。要了解更多关于它们如何决定的信息,请查看 这篇 Ethereum Magicians 帖子。 ↩
- 我们也可以在 tx 2 完成后立即执行 tx 4。为简化起见,我们这里使用执行批次。 ↩
- 我在这里对术语的使用有些随意。区块构建者和区块提议者可能是不同的实体,实际上通常就是如此。我在这里将它们用作同义词是为了简化解释。 ↩
- 我不知道这些好处中哪一个影响更大。对我来说,并行执行带来的速度提升是否比 I/O 预取更大并不明显。希望我们将来能获得这方面的实际数据。 ↩
- 第一次了解 BALs 时,我很惊讶没有人提到状态膨胀。那肯定也是一个缺点吧?但 BALs 不会成为区块链状态的永久部分,并且如“面向用户的更改”部分所解释的,它们可以在大约 2 周后被修剪。 ↩
- 可选访问列表在 EIP-2930 中引入,主要目的是允许“解救”那些在同一升级中包含的某些 gas 重新定价后可能变得无法使用的合约。解释很复杂,但如果你感兴趣,请参阅 我的这篇旧的(且已过时)文章。 ↩
- 或者至少是 EIP 网站 中链接的最早文档。显然,这个想法之前已经被探讨过,例如在 这篇 2021 年的帖子 中。 ↩
- 原文链接: paragraph.com/@cethology...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





