为智力爆炸做准备
- forethought
- 发布于 2025-08-30 22:43
- 阅读 18
文章探讨了人工智能加速科技发展可能带来的“智力爆炸”,并强调AGI准备不仅仅是AI对齐问题。文章分析了AI在研究中替代人类劳动的潜力,预示科技进步可能在十年内远超过去一个世纪。同时,文章也警示了由此可能产生的包括AI接管、新型大规模杀伤性武器、权力过度集中等一系列重大挑战,并呼吁现在就应开始准备,以应对加速变革带来的潜在风险。
为智能爆炸做准备
William MacAskill Fin Moorhouse
摘要 Link to heading
能够加速研究的 AI 可能会在短短几年内推动一个世纪的技术进步。在此期间,新的技术或政治发展将迅速接踵而至,引发具有重大影响且难以逆转的决策。我们称这些发展为宏大挑战。
这些挑战包括新的大规模杀伤性武器、AI 支持的独裁统治、争夺外星资源的竞赛以及值得道德考量的数字生命,以及大幅提高生活质量和集体决策的机会。
我们认为,这些挑战并非总是可以委派给未来的 AI 系统,并建议我们今天可以做些什么来有意义地改善我们的前景。因此,AGI 准备不仅要确保高级 AI 系统是对齐的:我们现在就应该为智能爆炸带来的令人迷惑的各种发展做好准备。

1. 简介 Link to heading
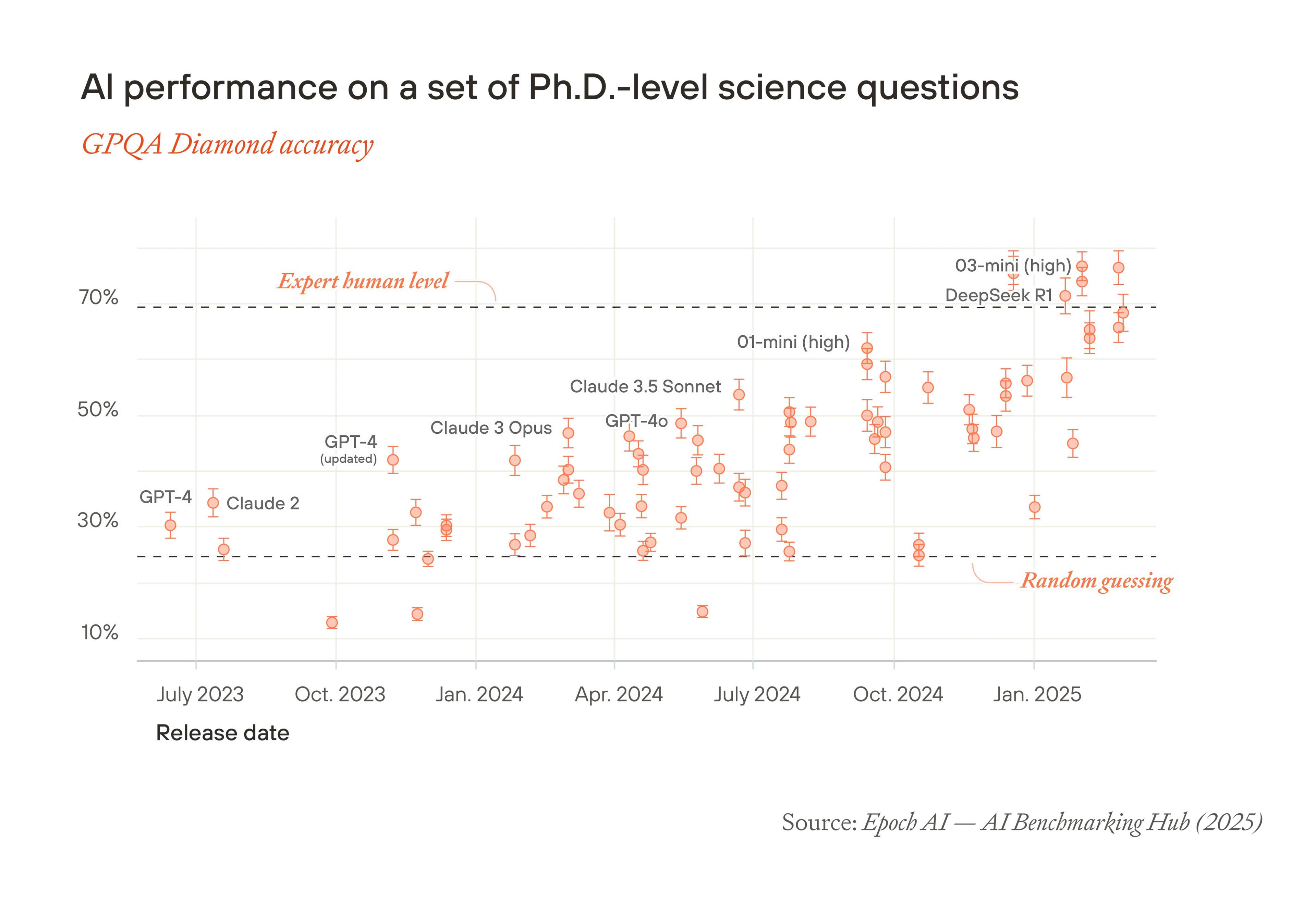
现在,我们很有可能在未来十年内看到比人类更聪明的 AI。1 2019 年最好的语言模型几乎不连贯;2 到 2023 年初,它们可以流利地回答问题,并且比任何在世的人都拥有更多的常识。2023 年初最好的模型在需要大量推理的科学问题上的表现略好于随机猜测;如今,它们的分数超过了博士级别的专家。3
但是,在那些期望超智能 AI 的人中,普遍认为结果实际上是全有或全无,4 并且取决于一个挑战:AI 对齐。5 要么我们未能对齐 AI,在这种情况下,人类将永久性地失去权力;要么我们成功地对齐了 AI,然后我们用它来解决我们所有其他问题。
本文反对这种“全有或全无”的观点。相反,我们认为 AGI6 准备应该涵盖更广泛7 的机遇和挑战。
能够有意义地替代人类研究劳动的 AI 的发展可能会推动非常快速的技术发展,从而将数十年的科学、技术和智力发展压缩到几年或几个月内。当然,这会带来极大地改善生活质量的潜力,就像技术进步过去经常改善生活质量一样。这可能意味着医学上的进步会大大延长我们的健康寿命,足够的物质财富让每个人都过上今天亿万富翁会羡慕的生活方式,以及前所未有的协调、合作和称职治理的工具。
但它也会带来一系列可怕的挑战——我们需要解决这些挑战才能享受智能爆炸的成果。这种宏大挑战是我们论文的主要重点。一个被广泛讨论的挑战是 AI 接管的风险:足够先进的 AI 可能与人类不对齐并且能够压倒人类。但是还有许多其他的宏大挑战,包括:
-
掌握超智能的人进行的人类接管的风险;
-
来自破坏性技术(如生物武器、无人机群、纳米技术以及我们尚未具体预见的技术)的新型风险;
-
围绕关键伦理问题(如数字生命的权利和对外星资源的新增价值的分配)建立规范、法律和机构;
诸如此类的宏大挑战可能会有意义地决定未来的发展方向。它们是人类进步道路上的岔路口。在许多情况下,我们不应期望它们默认情况下会进展顺利——除非我们提前做好准备。
由于智能爆炸带来的加速变化,世界将需要快速处理这些挑战,其时间尺度远小于人类机构的设计时间。默认情况下,我们根本没有时间进行长时间的审议和缓慢的试错。
对齐的超智能可以为我们解决其中一些挑战。但并非全部。有些挑战会在对齐的超智能出现之前出现,而有些解决方案(例如达成 AGI 后分权的协议,或改善目前进展缓慢的机构)只有在我们于智能爆炸发生之前就致力于解决它们时才是可行的。
事实上,我们现在就可以为这些挑战做好准备。例如,我们可以:
-
防止极端且难以逆转的权力集中,现在就建立机构和政策。例如,我们可以确保数据中心和半导体供应链的基本组件分布在民主国家,并且对前沿 AI 的访问权继续提供给多个国内和跨国方。
-
赋予负责任的行为者权力: 增加那些对超智能的发展拥有最大权力(例如政治家和 AI 公司 CEO)的行为者负责任、有能力和负责的可能性。
-
构建AI 工具以改善集体决策。 我们可以开始构建、测试和集成我们希望在智能爆炸开始时广泛使用的 AI 工具,包括认知、交易和决策建议。
-
消除将超智能 AI 应用于下游挑战的障碍,例如通过疏通官僚机构,这使得在政府部门不必要地难以使用高级 AI 工具。
-
尽早开始对新治理领域的制度设计,包括数字生命的权利以及对外星资源的所有权主张的法律框架。
-
提高认识并加深我们对智能爆炸及其随之而来的每个挑战的理解,这样在确实需要做出决策的关键时刻,花在加速前进上的时间就会更少。
在下一节中,我们将提出一个历史性的思想实验,以说明智能爆炸将是多么的戏剧性和颠覆性。在接下来的章节中,我们将:
-
认为能够替代人类研究员的 AI 将在一个十年内推动一个世纪的技术进步(第 3 节)
-
概述由此产生的各种宏大挑战(第 4 节)
-
讨论何时可以将对这些挑战的准备工作推迟到以后,以及何时不能这样做(第 5 节)
-
介绍我们今天可以做的一些事情,为它们做好准备(第 6 节)

2. 十年相当于一个世纪 Link to heading
浓缩的过去一个世纪 Link to heading
考虑一下我们过去一个世纪(从 1925 年到 2025 年)所看到的所有新想法、发现和技术:
科学和概念方面
物理学方面的进步,包括量子理论和现代宇宙学。揭示 DNA 的结构以及随后在基因组学和生物学方面的进步。计算理论和计算机科学、哥德尔不完备定理、密码学、优化和线性规划以及新的统计方法。当时新兴的社会科学(如博弈论、宏观经济学和计量经济学、政治学、实验心理学和预测)的重大进步。对环境恶化的理解大大提高。
技术和工程方面
突击步枪、喷气飞机、雷达和隐形技术、卫星侦察、生物和化学武器、无人驾驶飞机和原子弹。青霉素、口服避孕药、DNA 指纹识别、合理药物设计和基因工程。晶体管收音机、数字计算机、手机、互联网、社交媒体、GPS 和深度学习。水力压裂、海上钻井、国家电网、核电和太阳能发电。合成肥料、高产农作物品种、拖拉机和联合收割机的机械化以及转基因作物。
政治和哲学方面
世俗和普遍人权的接受、第二波和第三波女权主义、非殖民化、动物权利和环保主义。法西斯主义、国家共产主义(如毛主义和列宁主义)、新自由主义和国际关系中的“现实主义”的传播。新的政治和社会正义理论、新的规范伦理理论、评估政策的成本效益方法以及人口伦理学。逻辑实证主义、日常语言哲学、存在主义、批判理论、(后)结构主义、(后)现代主义等等。
现在,想象一下,如果所有这些发展8 都被压缩到 1925 年之后的十年中。
第一次跨太平洋不间断飞行将在 1925 年底进行。第一次登上月球的脚印将在不到四年后的 1929 年年中留下。核裂变的发现(1926 年年中)与第一次原子弹试验(1927 年初)之间将间隔约 200 天;计算机芯片上的晶体管数量将在四年内增加一百万倍。9
这些发现、想法和技术导致了巨大的社会变革。想象一下,如果这些变化也加速了十倍。第二次世界大战将在工业强国之间爆发,并以原子弹结束,所有这些都在大约 7 个月的时间内完成。在欧洲殖民帝国解体后,30 个新独立的国家和成文宪法将在一年内形成。联合国、国际货币基金组织和世界银行、北约以及后来成为欧盟的集团将在不到 8 个月的时间内成立。
或者甚至只考虑与核武器相关的决策。在 10 倍的加速下,曼哈顿计划于 1926 年 10 月启动,三个月后第一颗炸弹投在广岛。平均而言,每年发生一次以上的核武器险情。古巴导弹危机始于 1928 年底,仅持续 31 个小时。肯尼迪总统在 20 分钟内决定如何回应赫鲁晓夫的最后通牒。阿尔希波夫只有一个小时的时间来说服他的船长,他错误地认为战争已经爆发,不要发射核鱼雷。等等。
如此快速的步伐会改变所做出的决策。在反思古巴导弹危机时,在谈判中发挥了作用的小罗伯特·F·肯尼迪写道:“如果我们需要在 24 小时内做出决定,我认为我们最终会采取的行动方案将大相径庭,而且充满了更多的风险。”
不对称加速 Link to heading
如果实际上每个历史进程都以同样的速度加速,那么同样的事件只会发生得更快,而历史的轨迹不会改变。但是技术变革并不能同等地加速所有事情:加速技术进步就像减慢那些没有随之加速的过程。特别是,很难加速人类本身及其互动、思想和学习。同样,许多社会和政治机构都有严格的日程安排,10 这可能会在世界其他地方加速时滞后。
因此,另一种思想实验是,如果 1925-2025 年期间的技术变革幅度相同,但所有人在每天只清醒一小时四十分钟。决策显然会受到损害:了解新发展及其影响的时间更少,但迅速采取行动的压力更大,重大失误的几率会增加。
加速的十年 Link to heading
现在,想象一下,如果你预计到 2125 年会看到的所有科学、智力和技术发展,如果技术进步在下一个世纪以与上个世纪大致相同的速度继续发展。然后想象一下所有这些发展都发生在短短十年内。11
就像在历史思想实验中一样,这种加速带来的挑战将是巨大的。但是,在下一节中,我们将论证这不仅仅是一个思想实验:事实上,先进的 AI 很可能会在不到十年的时间内推动一百年的技术发展。
技术发展的速度不会是统一的,因为来自 AI 的大量认知劳动会加速某些领域的研究,而不是其他领域。在可以通过先验推理或模拟来推进的领域,例如数学、计算机科学和计算生物学,进展会更快,而在需要昂贵或缓慢的实验的领域,例如高能粒子物理学或药物开发,进展可能不那么具有爆炸性。
与我们的历史思想实验一样,高风险决策的质量和速度并不总是能跟上变化的速度。超智能 AI 顾问可能会提供显着帮助(我们将在第 5 节中讨论),但良好的决策仍然会受到人类大脑速度和机构日程安排的限制,并且机构学习的通常方法是通过人类生命周期的时间尺度上的试验和错误来进行,这会太慢。
我们并不是说这种加速的技术进步比一切照旧的进步速度更糟糕。但我们确实认为如此快速的进步会带来独特的挑战,主要是因为人类决策难以跟上。这表明我们现在就应该做好准备。

3. 智能爆炸及其之后 Link to heading
现在,我们将讨论关于 AI 进步将推动更快技术发展速度的论点。
简而言之,论点是这样的。目前,全球研究总投入增长缓慢,每年增长不到 5%。但是,AI 认知总劳动力的增长速度比人类认知总劳动力快 500 多倍,并且在 AI 的认知能力超过所有人类的点之前和之后,这似乎都很有可能保持不变。因此,一旦 AI 认知总劳动力开始与人类认知总劳动力相媲美,总体认知劳动力的增长率将大幅提高。这将推动更快的技术进步。
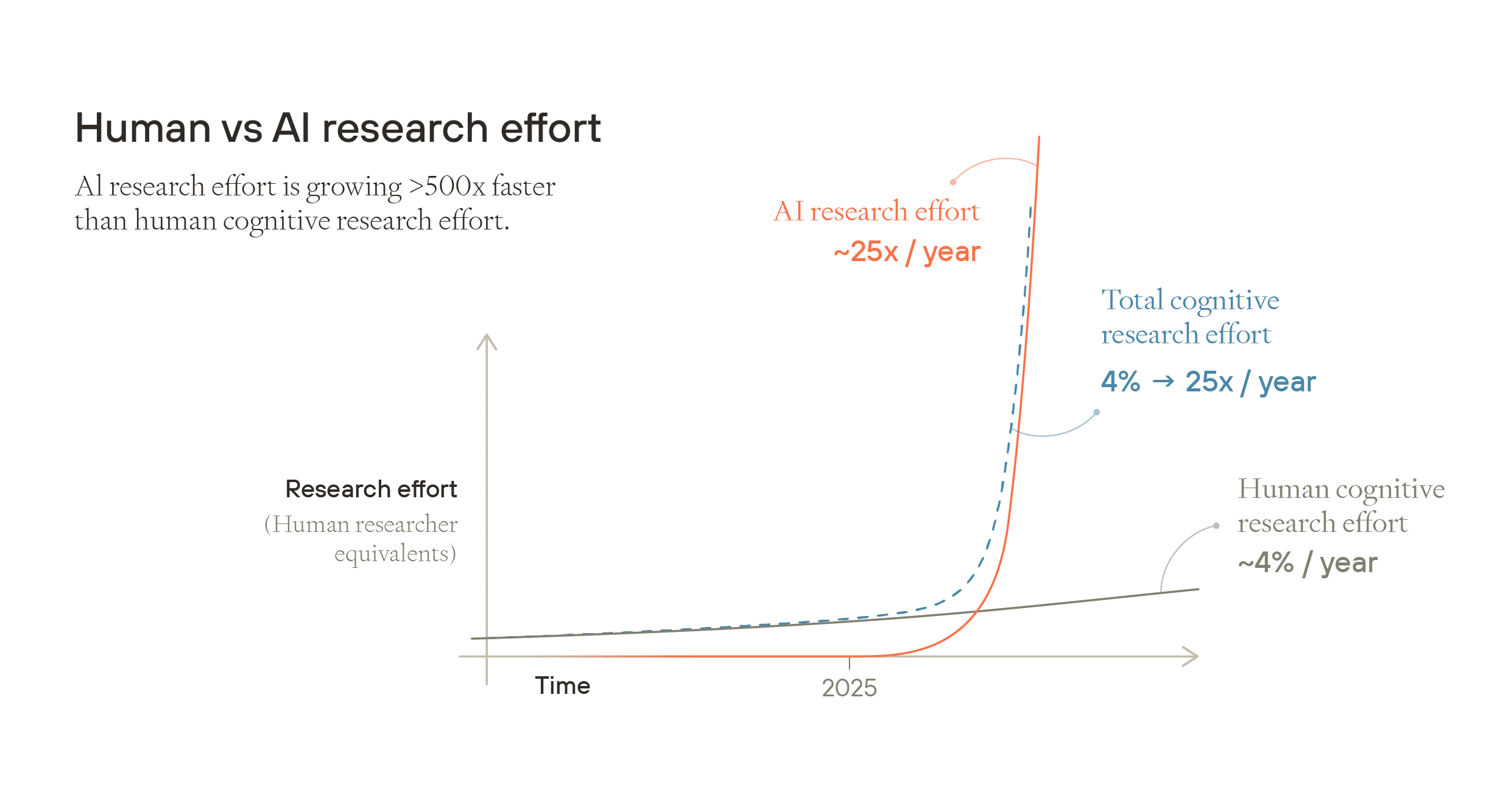
图片
在本节中,我们将更详细地介绍这个论点。我们首先了解 AI 当前和预计的进步速度,然后讨论期望 AI 在十年内有意义地加速研究的原因,以及认为 AI 达到人类对等点的可能性很快的原因。我们认为,在这一点上,AI 研究投入的持续增长率可能远高于人类研究的增长率——足以在不到十年的时间内推动一个世纪的技术进步。最后,我们讨论为什么这也很可能导致爆炸性的工业扩张。
AI 能力的进展 Link to heading
当前趋势 Link to heading
最好的 AI 模型变得越来越智能,给定性能水平的模型变得越来越高效,并且我们正在积累更多的计算能力来运行它们。结果是,AI 系统的认知总劳动每年都在显着增加。
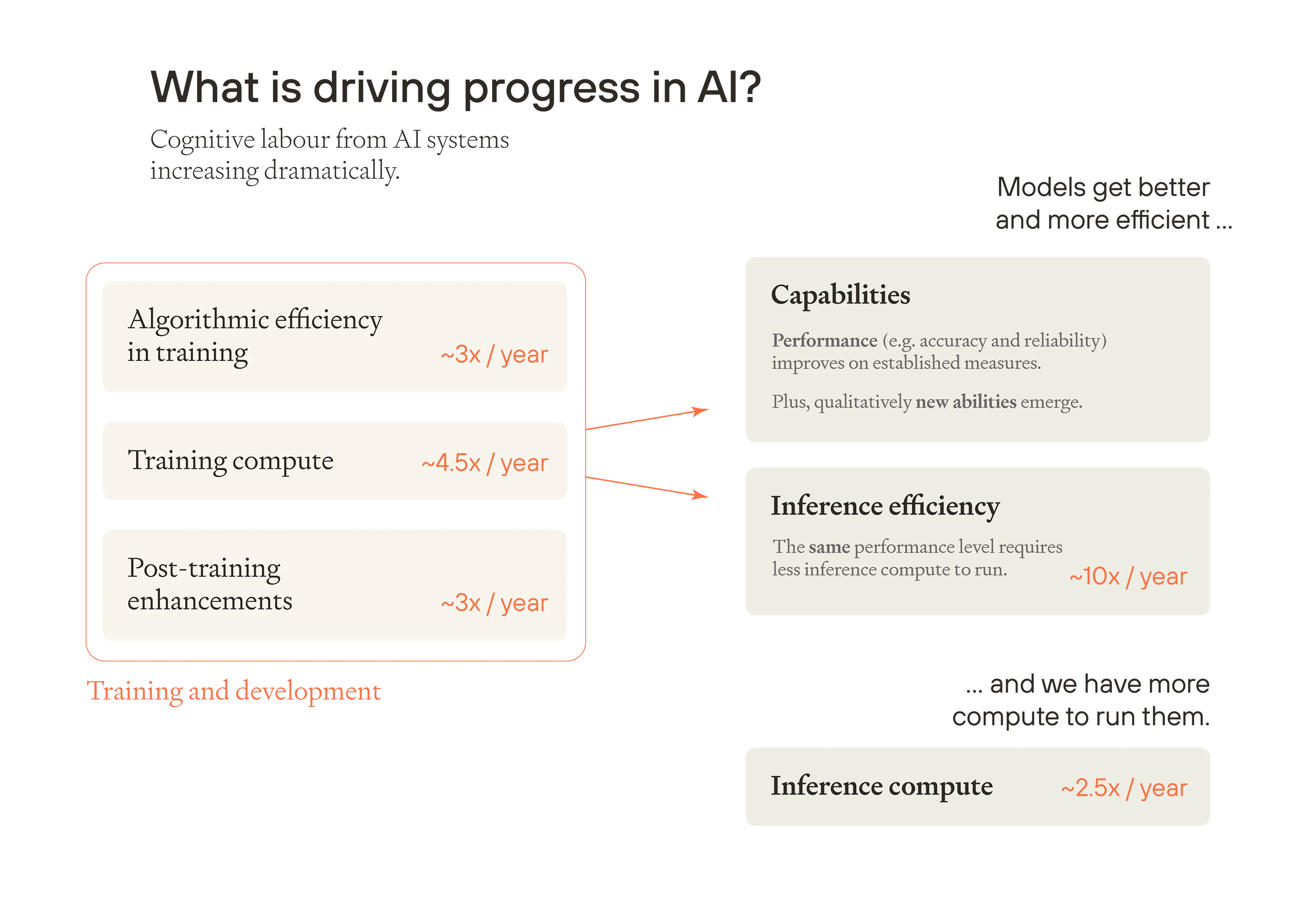
图片
我们将依次介绍 AI 进步的关键驱动因素。
训练计算: 自 2010 年以来,在值得注意的前沿训练运行中使用的原始计算量的估计值一直在以每年约 4.5 倍的速度增长。12 更大的训练运行会产生更好的模型。
训练中的算法效率: 新的和更好的算法提高了训练的收益,使相同数量的训练计算更加高效。根据目前的趋势,以相同的性能水平训练模型所需的物理计算量每年大约下降 3 倍13。
这两个因素结合起来提供了“有效训练计算”的度量——在没有任何算法创新情况下达到相同模型性能所需的原始计算量的等效增加。来自预训练的有效训练计算每年都在增加 10 倍以上。
训练后增强: 除此之外,AI 开发人员正在寻找从基础(预训练)模型中激发新能力的方法。他们正在构建跨领域(如工具使用、更好的提示方法、合成数据、生成和选择答案的创造性方法以及各种“脚手架”)的“训练后增强”14。许多这些进步更好地利用了更多的推理计算,本质上是教导经过训练的基础模型更有效地推理。15 Anthropic 非正式地估计,训练后增强目前每年进一步提供 3 倍的效率提升16。因此,就最佳模型的能力而言,就好像物理训练计算每年都在扩展 30 倍以上。17
这些趋势以可预测的方式提高了具有已建立的度量标准和基准的熟悉 AI 能力的性能。18 但是,从更大和更好的训练运行中也会出现质量新的能力,通常以微妙和令人惊讶的方式出现。因此,考虑 GPT-2 和 GPT-4 之间的实际差异以及这如何映射到我们的趋势可能是有用的。GPT-4 使用大约 10510^5105(100,000)到 10610^6106(一百万)倍的有效训练计算进行训练,而 GPT-219 在大约四年前发布。如果我们也考虑训练后增强因素,则有效计算量可能会增长接近一千万倍20。这导致了质量新的能力:GPT-2 将产生语法正确但本质上毫无意义的文本补全;GPT-4 能够回答关于科学、法律、历史和编码的复杂问题。

图片
我们还可以在相同的性能水平下运行更多模型实例,这既要归功于更高效的模型,也要归功于 AI 公司正在积累更多用于推理的计算硬件。依次考虑:
推理效率: GPT-3.5 于 2022 年底发布,初始成本为每百万 tokens 20 美元。如今,可以使用更好的模型以MMLU(用于评估 LLM 性能的广泛基准)上的更好的分数运行,成本约为每百万 tokens 0.04 美元;在不到 3 年的时间里下降了 500 倍21,或者每年的成本下降约 10 倍。这个数字有一些额外的理论支持:将有效训练计算量翻倍大致相当于将已建立的能力水平的推理成本减半22,并且我们看到有效训练计算量每年都在增加约 10 倍。
推理计算扩展: 计算硬件的增加使这些效率提升成倍增加:可用于推理的物理计算量每年大约以 2.5 倍的速度增长。23
然后,这两种趋势(运行效率提升和可用推理计算的增加)可以支持“AI 人口”每年增长约 25 倍。24
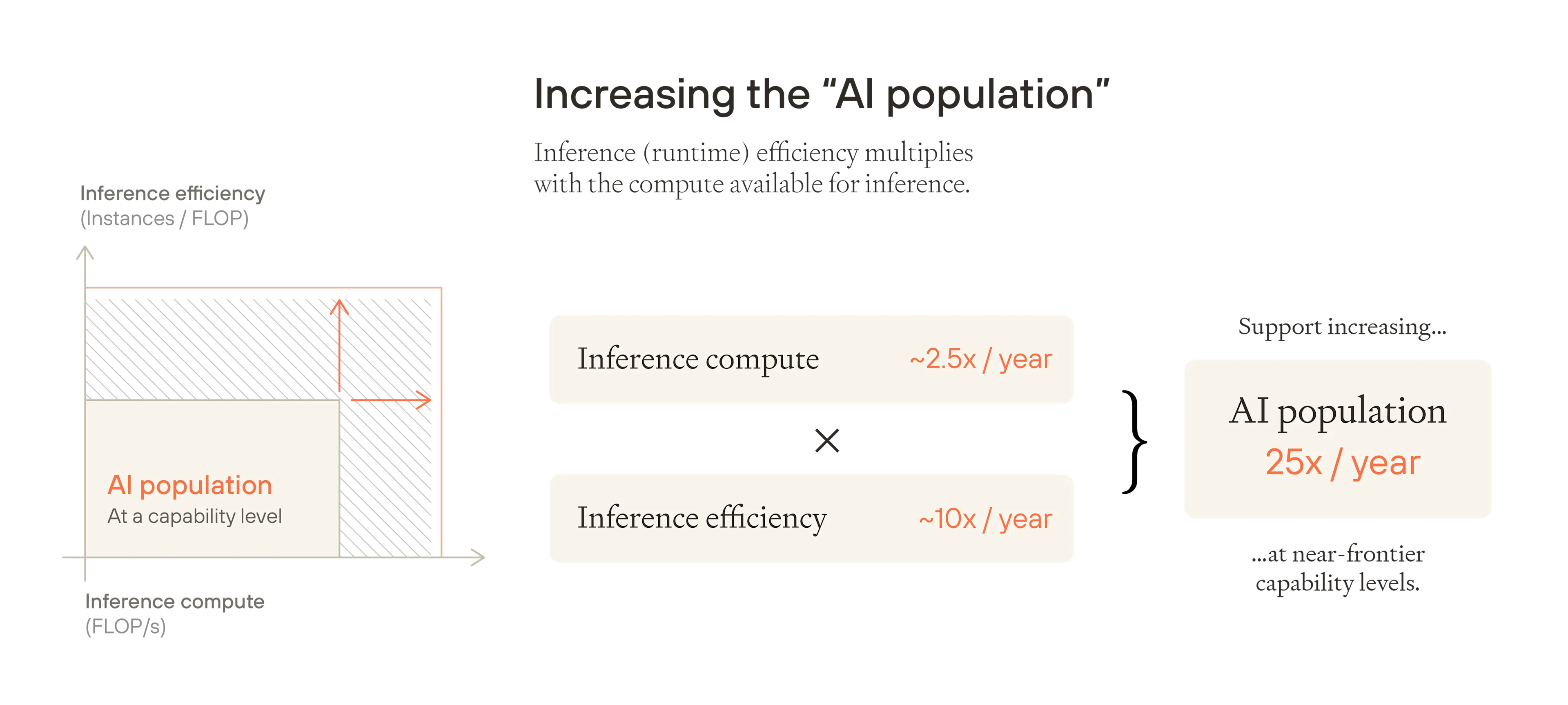
图像
所有这些加起来,不仅在最佳 AI 模型的最令人印象深刻的能力方面,而且在全球运行的所有 AI 系统的集体能力方面,都取得了快速进展。我们将使用 AI 研究工作 来谈论所有活跃 AI 系统在一段时间内贡献的与研究相关的认知工作的数量。非正式地,我们可以根据需要做出同等贡献的远程人类研究人员的数量来衡量 AI 研究工作。25
人类认知研究的总工作量是研究人员数量和每个研究人员平均生产力的函数。 类似地,我们可以将 AI 研究工作视为每个模型的能力和“AI 研究人员”数量的函数。
假设当前的趋势持续到 AI 研究工作大致与人类研究劳动相当的程度(下面,我们将讨论这是否可能)。为了便于讨论,我们可以将与实际人类研究人员相同有效数量的人类水平“AI 研究人员”进行比较。这将如何从根本上影响投入技术进步的总体认知劳动的增长率?
我们可以通过假设训练方面的进步完全转化为改进的推理效率,并且更多的推理计算完全用于运行更多的 AI 来估计基线。26 我们已经看到,推理效率的提高大致与有效训练计算量一致,约为每年 10 倍,而推理计算量的增长为每年 2.5 倍或更多。因此,如果 当前的趋势持续到人类与 AI 在研究工作方面达到对等,那么我们可以得出结论,AI 研究工作将继续以每年至少 25 倍的速度增长。27
但这可能低估了 AI 研究工作的增长率。上面我们假设,将可用于 AI 驱动研究的有效训练计算量翻倍将专门用于增加 AI 研究人员的数量,但它也可以让我们运行更少但更智能的模型。如果更有效的训练计算量导致新一代模型在相同的能力水平上效率提高一倍,并且具有使用相同推理计算的新能力的模型,那么相同数量的更智能的 AI 通常将比两倍数量的同样智能的 AI 具有更强的集体能力。同样,加倍推理计算可以用来加倍 每个 AI 研究人员的串行推理时间,28 而不是仅仅运行更多的研究人员。当然,两种因素的任何组合都是可能的。我们应该期望从训练和推理中获得的收益应用于生产力最高的地方,我们也可以观察到 AI 的实际应用实际上倾向于使用能力接近公共前沿的模型。
我们没有估算当我们考虑到超出人类水平的能力改进时 AI 研究工作会以多快的速度增长,但它可能快得多。要了解这一点,请考虑人类研究人员的大脑大小和受教育年限的变化不大,但在某些领域,杰出的研究人员的生产力可能是同行的数百倍。29
我们还没有考虑到据称的每年 3 倍的有效训练计算量,这是来自训练后增强,这将使增长率从 25 倍提高到 75 倍。再加上当我们考虑到使 AI 研究人员更智能而不是仅仅更有效率的选择时获得的额外收益,AI 研究总工作量的增长率可能会远远超过这个数字。30
AI 可以保持改进到什么程度? Link to heading
多长时间 这些扩展和效率趋势可以持续?
-
训练计算: 在遇到电力和其他限制之前(可能在未来十年内),最大的训练运行可以继续扩展大约 10,000 倍的增长。即使解决了这个障碍,训练运行也可能会受到芯片生产、数据稀缺和硬件延迟的限制。31
-
训练中的算法效率: 如果我们假设计算规模扩大与效率提升的比率相同,我们将看到训练中的算法效率进一步提高 1,000 倍,32 与我们今天的位置相比,在十年内有效训练计算量进一步增加一千万倍 - 或者十年内有效计算量每年增长约 5 倍 - 低于迄今为止每年 ⩾10 倍的进展速度。
-
推理计算: 我们可以合理地假设在此期间推理计算也将扩展 10,000 倍,并以每年 2.5 倍的速度持续增长。
因此,如果我们假设 AI 的进步持续到扩展为止,不再进一步,我们可以使用扩展的限制来估计未来十年内集体 AI 研究工作量可以增长多少。训练计算量、算法效率和推理计算量(它们结合起来提供 AI 研究工作量)的乘积,然后将增加一千亿倍 (101110^{11}1011),平均每年略高于 10 倍。
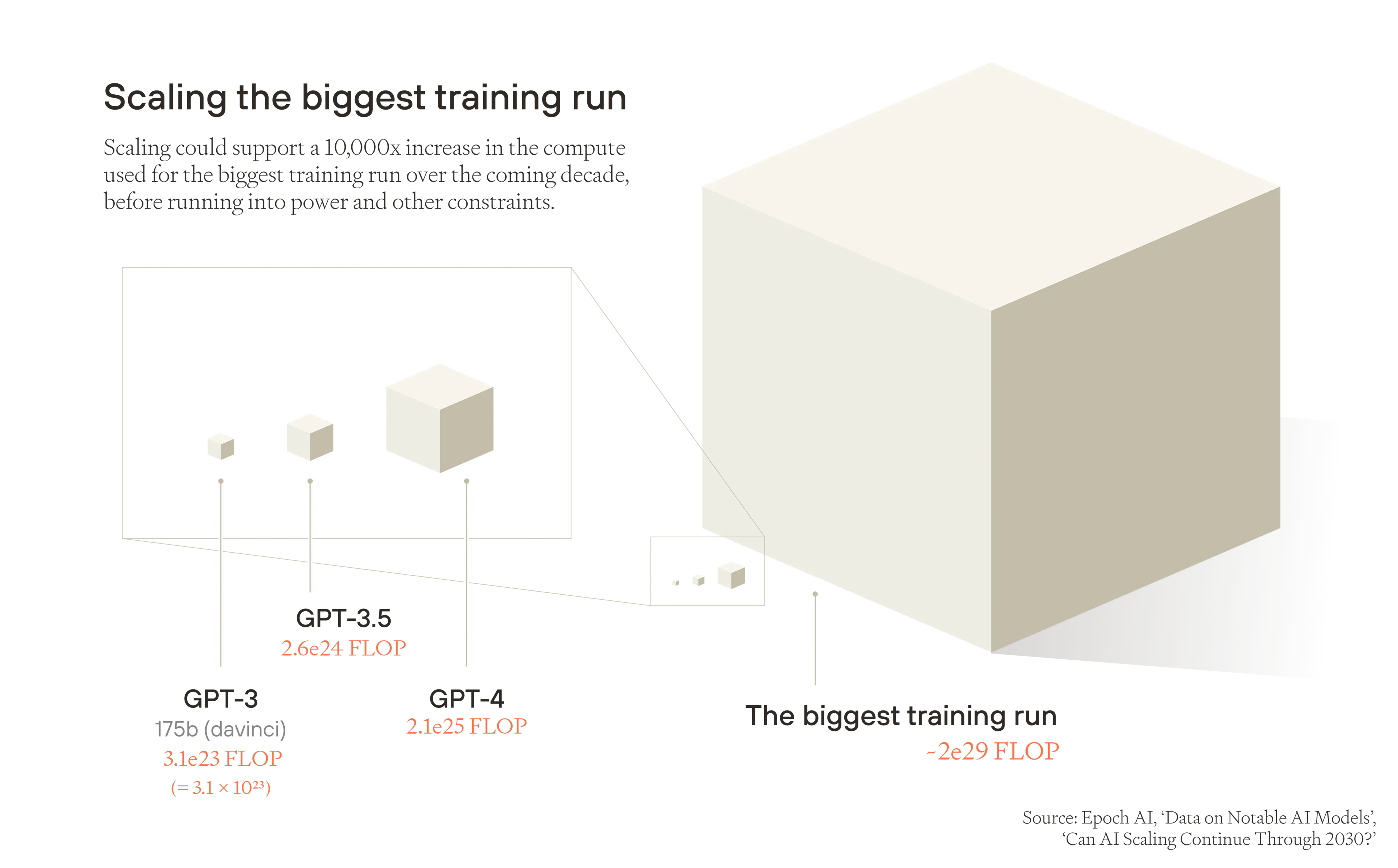
图像
但是,虽然物理规模的扩大可能会在十年内遇到限制,但算法的进步可能会加速。这是因为 AI 模型本身可能开始有意义地加速 AI 算法、数据、训练后增强和其他软件技术的改进。这将导致更好的 AI,然后可以推动算法改进,等等:一个软件反馈回路,33 其中 AI 能力不断提高,而无需扩大物理输入。
自我维持的软件反馈回路无法保证。大多数新技术最多只是研究人员生产力的一个一次性乘数,因此它们不会导致自我维持的进步。34 原则上,AI 的情况可能类似。即使“数字 ML 研究人员”可以替代典型的人类 AI 研究人员,进步也可能会趋于平缓:第一代数字 ML 研究人员可能会找到将下一代 AI 研究人员的性能提高一倍的方法,但 v2 数字 ML 研究人员可能只会找到将性能提高 1.5 倍的方法,依此类推:结果将是一阵改进,一旦开始就会减速。为了使进步快速而持久,输入翻倍必须在许多翻倍中至少产生输出翻倍。
然而,对各种软件领域的效率提升的实证估计表明,认知输入(研究工作量)翻倍通常会导致软件性能或效率的提升超过一倍。35 基于此,合理的估计表明,AI 驱动的软件反馈回路将推动 AI 性能和效率加速进步的可能性大致相当。36
反馈回路无法永远加速,因此最终软件反馈回路必须达到稳定水平。但是算法效率的上限似乎与当前水平相差甚远。在某些测量方法中,就我们的大脑在成年时使用的计算而言,LLM 的学习效率似乎大约比人类低 100,000 倍。37 并且上限似乎可能远远超出人类大脑的效率。38
因此,如果我们确实得到了一个软件反馈回路,那么 AI 的能力可能会在十年内覆盖有效训练计算量的另一个百万倍,从而使有效训练计算量大约增加一万亿倍 (101210^{12}1012),或者推理计算量和有效训练计算量的乘积增加一千万亿倍 (101610^{16}1016)(大约每年 40 倍)。
无论哪种方式,推理计算量和有效训练计算量的乘积的增长速度都至少比所有用于技术进步的人类认知劳动快 600 倍,39 并且具有巨大的持续改进空间。
未来十年 AI 进步的估计 Link to heading
在下表中,我们总结了我们对 AI 研究工作量各组成部分在未来十年内的平均增长速度的猜测 - 假设当前连接扩展和性能的趋势在扩展耗尽之前不会急剧放缓。 请注意,考虑到增长率是平均值;给定因素的大部分增长可能非常集中在短时间内。
| 当前速度 | 适度情况(无反馈回路) | 快速情况(软件反馈回路) | |
|---|---|---|---|
| 训练计算量 | 4.5 倍/年 | 2.5 倍(总共 10,000 倍) | 2.5 倍 |
| 算法效率 | 3 倍/年 | 2 倍(总共 1,000 倍) | 8 倍(总共 10910^{9}109 倍) |
| 推理计算扩展 | 2.5 倍/年 | 2.5 倍(总共 10,000 倍) | 2.5 倍(总共 10,000 倍) |
| AI 研究工作量 | >= 25 倍/年 | >=12 倍(总共 >= 101110^{11}1011 倍) | >=50 倍(总共 >= 101710^{17}1017 倍) |
| 人类研究人员 | 4% | 4% | 4% |
| AI 与人类研究工作量 | >= 快 600 倍 | >= 快 300 倍 | >= 快 1000 倍 |
总而言之,我们可以得出结论,即使与当前趋势相比,AI 的当前进展速度降低了 100 倍,认知研究总工作量(来自人类和 AI 的共同努力)的增长速度仍然比以前快得多。一旦集体 AI 能力与人类的能力相匹配,这种增长将继续使 AI 能力远远超过全人类的集体思维能力。
当然,AI 研究工作量可能因其他原因而放缓。特别是,仅靠扩展很可能开始产生越来越不令人印象深刻的结果,就模型的最终性能和效率而言。有迹象表明,扩展预训练的回报正在比以前更快地减少, 性能改进的更大部分来自主要通过 RL 方法扩展特定于推理的训练 - 但这些收益最终必须与增长保持一致 在可用于训练的总体计算量中。
接下来,我们将讨论集体 AI 能力是否以及何时达到与人类研究工作量相当的水平。
AI 与人类的认知对等 Link to heading
我们认为,AI 研究工作量很可能在未来二十年内达到与人类研究劳动相当的水平,这意味着 AI 系统可以集体执行人类可以执行的几乎所有与研究相关的认知工作。由于扩展带来了如此巨大的收益,AI 甚至可能在未来十年内接近人类的对等水平,然后扩展开始受到电力和其他实际限制。即使在扩展显着放缓之后,算法的进步也可以继续推动进步。无论如何,AI 与人类的对等可能会在几年内到来。
要了解这一点,我们应该直接关注 AI 能力是如何提高的。在 GPQA(一个博士级别的科学问题基准)上,GPT-4 的表现略好于随机猜测。 18 个月后,最佳推理模型的性能优于博士级别的专家。40
这并不意味着得分最高的模型可以真正取代博士级别的研究人员。特别是,GPQA 等基准无法衡量执行复杂系列任务的能力,或者难以编纂的隐性知识。尽管如此,观察到的进展速度比大多数人预测的要快。
图像
至于与自动化 ML 研究更相关的技能:在竞争性编码问题上,最好的 AI 系统已经可以稳固地击败除最好的程序员之外的所有人,41 解决超过 70% 的开源存储库中的真实软件工程问题,42 并在时间限制的机器学习优化问题上匹配领域专家的分数,时间限制约为四个小时(在 RE-Bench 基准上)。43 今天的最佳系统在更长的时间范围内解决复杂问题方面存在不足,这需要创造力、试错和自主性相结合。但有迹象表明正在快速改进:前沿模型通常可以完成的与 ML 相关的任务的最大持续时间大约每七个月翻一番。粗略地推断这种趋势表明,在三到六年内,AI 模型将能够自动化许多认知任务,而这些任务需要人类专家长达一个月的时间。44
因此,至少在一些测试短期科学和编码任务性能的基准上,AI 系统的性能正在赶上具有相关专业知识的人类。
同样,基准不是现实世界。 以 ML 研究为例:即使是像 RE-Bench 这样的困难基准,也提出了具有快速反馈回路的独立、定义明确的任务。虽然在现实世界中,ML 研究人员需要澄清和选择研究方向,并与其他团队协调,同时经常等待数天才能解决实验问题。45 构建和集成可以自主推动实际研究和工程的 AI 系统需要做更多的工作,尽管有巨大的动力来弥合专家级基准性能与现实世界中专家级有用性之间的差距。
大约一百万倍的有效训练计算将 GPT-2(它对基本问题的回答几乎不连贯)和 GPT-4(它是一个有用的助手,比任何活着的人都具有更广泛的知识)分离开。46 在 18 个月内,模型的改进足以在某些与其领域相关的推理和编程任务上与博士级别的专家相匹配。在我们遇到扩展瓶颈之前,我们应该期望至少出现与将 GPT-2 和 GPT-4 分离的算法进步和训练计算方面相同的飞跃。47 如果我们得到了一个软件反馈回路,我们可能会再次得到大致相同的飞跃,从而使我们达到相当于“GPT-8”甚至更高的水平。48
这种强劲的进展对我们来说似乎很可能足以产生在基本上所有重要的认知领域都超过最聪明的人类研究人员的研究能力的模型。但即使未来五年内训练计算量的预期增长并没有使我们达到目标,预训练算法效率、训练后增强、推理效率和推理计算量的增加也将使 AI 研究工作量继续增加,超过物理扩展放缓或训练数据耗尽的点。
因此,虽然我们无法确定它何时会发生,但在未来一二十年内,AI 与研究方面最佳人类表现的对等,对我们来说似乎不仅仅是一种有生命力的可能性 - 这似乎很可能。当这种情况发生时,集体 AI 研究能力将继续跨越多个数量级增长。
因此,我们可能会从有效的人口开始,例如,十万名人类专家级别的 AI 研究人员。也许大多数人都将致力于改进下一代 AI,或其他科学技术领域 - 无论回报最高。然后有效的计算进步和推理计算的增加至少可能会使认知工作量翻倍,然后再翻倍,迅速超过所有大约一千万51 的在职人类研究人员,然后是所有 80 亿活着的人类,然后再将集体能力翻倍多次。
需要明确的是,我们并不是假设大多数 AI 资源将用于研究,而不是其他具有经济价值的任务。 相反,我们认为一些重要的 比例将用于自动化研发,我们特别对这一比例感兴趣,因为从历史上看,技术进步一直是值得为之做好准备的那种重要新挑战的主要驱动力。
当然,专业的 AI 应用程序已经比增加额外的人类研究人员更有效地推动特定领域的进步 - 例如,Google DeepMind 的 AlphaFold 已被用于预测超过 2 亿个新的蛋白质结构,52 在某些方面实现了可能需要数百万研究人员-年的实验方法才能实现的目标。53 我们不会局限于仅使用与人类研究人员具有相同技能概况的通用 AI 研究人员。
AI 与人类对等之后,AI 研究工作量还能增加多少? Link to heading
那么,我们可以问,在 AI 接近与人类认知研究努力达到对等之后,未来十年内 AI 研究工作量将增长多少?这取决于两个猜测:AI 能力已经有多接近达到与人类对等的水平,以及你认为整体 AI 能力持续快速提升有多少空间。
在我们的保守情景中,我们将想象 AI 能力达到与人类对等水平的时候,由于电力限制,不再可能进一步扩大训练运行;并且没有软件反馈循环。 更重要的是,我们将假设推理计算增长和效率提升比目前的速度放缓约 30%。 在这种情况下,在与人类对等之后,未来十年内 AI 研究工作量将继续平均以每年 5 倍的速度扩展。
在我们的激进情景中,我们将想象集体 AI 能力很快达到与人类对等水平,在扩大训练运行和推理计算方面仍有很大的空间,并且 AI 自动化 AI 研发确实导致了软件反馈循环。
| 保守 | 激进 | |
|---|---|---|
| 训练计算量 | 无增长 | 2 倍 (总共 1,000 倍) |
| 算法效率 | 2.5 倍 (总共 10,000 倍) | 5 倍 (总共 10710^7107 倍) |
| 推理计算扩展 | 1,000 倍 (2 倍/年) | 2.5 倍 (总共 10,000 倍) |
| AI 研究工作量 | ~10710^7107 倍 (5 倍/年) | 25 倍 (~101410^{14}1014 倍) |
| 人类研究人员 | 1.04 倍/年 | 1.04 倍/年 |
| AI 与人类研究工作量 | 快 100 倍 | 快 600 倍 |
技术爆炸 Link to heading
下一个问题是技术进步会发生什么。 从历史上看,技术进步的速度受到熟练人类研究人员的供应的驱动和限制。 机构和文化因素也很重要,但很少有人会否认(在所有条件相同的情况下)更多的研究人员会产生更多的研究。54 通过增加认知研究的总量,AI 研究工作量可以有效地增加熟练人类研究人员的供应。 如果效果足够大,结果可能是技术爆炸:社会技术进步速度的大规模和持续增长,可能足以在十年内实现一个世纪的技术进步。
对研究工作总量增加的影响进行建模的任何模型都需要考虑两种类型的收益递减。 首先是“耗尽”效应:在几乎所有研究过的领域中,累积技术进步越多,维持相同的进步速度所需的研究工作量就越大。55 其次是“踩脚”效应:并行增加更多研究工作的回报通常会递减。56
我们通过来自半内生增长模型57 的一个简单的想法生产函数来建模这一点,并纳入了两种类型的收益递减。 为了在十年内实现一个世纪的目标,研究总工作量需要在十年内增加 600 倍或更多,也就是说,增长率约为 100%(翻倍)每年。58
在我们对人类对等后十年 AI 进步的保守情景中,研究总工作量将增加 10710^7107 倍,或每年约 5 倍。 这足以推动超过三百年价值的技术发展以目前的进步速度。59 即使每十年集体 AI 能力的增长速度低于我们的保守估计的一半,我们仍然会在十年内实现一个世纪的技术进步。
到目前为止,我们假设 AI 研究人员的认知努力可以直接替代人类研究努力,因此技术进步的步伐只是认知努力的函数 - a priori,脱离肉体的思考。 但研究还涉及物理实验和修补。 因此,除非可用于研究的体力劳动随着认知劳动的增长而增长,否则它将越来越拖累技术进步。 同样,技术进步通常依赖于等待必须串行执行60 或无法轻松加速的实验,例如人类药物试验。 然后是物理资本,如实验室设备和中试工厂。 由于资本在研究中补充了劳动力,因此堆积更多的 AI 认知劳动将变得越来越不有用。
这些都是期望技术进步的速度低于上面给出的朴素模型的好理由。 但物理劳动、实验和资本限制不太可能严重限制爆炸性的技术进步,以至于我们不会在不到十年的时间内看到一个世纪的发展。 原因有以下几个。
首先,当时的整体进步是由平均进步率决定的; 它不受发展最慢的技术领域的限制。61 即使医学或高能粒子物理学根本没有进步,如果数学、计算机科学、理论经济学和计算生物学等模拟繁重的领域有足够的进步,我们仍然可以在十年内实现一个世纪的发展。 即使目前严重依赖资本和物理实验的研究领域,在认知劳动大量涌入的情况下,通常仍然能够取得显着进步。 这些领域仍然可以取得重大的理论进步。 AI 研究人员可以回顾和重复使用现有数据。 并且高质量的模拟通常可以在某些领域代替物理实验,例如合成生物学、生物化学、药代动力学、62 材料科学、63 机器人技术64 甚至社会科学。65
其次,如果认知劳动充足,我们会看到物理资本的优化利用和实验的优化进行。 如果资本和物理实验是瓶颈并且值得花费相当于数百万年的人类研究劳动来设计和运行尽可能有用的实验,收集大量数据并详细分析这些数据。 与此相关的是,将会有非常强烈的动机来增加对物理资本的投资并进行更多的实验。 这可以通过首先将人类劳动力(可能由 AI 科学家管理)重新分配到进行更多实验来实现,通常是并行进行的,然后在以后使用机器人技术来自动化这些实验。
最后,除了考虑庞大的 AI 研究工作队伍的局限性之外,我们还应该考虑 AI 系统将拥有的特殊优势。 进化并没有优化人类大脑以擅长科学和工程; 我们之所以能够进行科学研究,只是因为我们重新利用了一种通用推理能力,这种推理能力是为了帮助我们在祖先环境中生存而进化而来的。66 相比之下,AI 研究人员可以被高度优化以做出研究贡献。 因为它们可以比人类大脑运行得更快,并且可以并行运行,所以 AI 可以接受在单个生命周期内根本不可能实现的培训 - 花费相当于一百万年的时间来学习五年前才发现的数学领域。 他们可以是许多不同科学领域的专家,因此更有能力将一个领域的见解带到另一个领域。 他们可以将注意力集中在一个问题上,相当于成千上万个连续的人类生命周期。 虽然计算机在可编程任务方面已经超越了人类,但是没有原则上的理由可以阻止 AI 在与洞察力、直觉和创造力相关的领域超越最优秀的人类 - 就像 Ramanujan 或 Einstein 如何胜过具有相似计算能力的研究生一样。67
因此,即使考虑到物理实验和物理资本带来的阻力,我们认为在一个十年内实现一个世纪的技术进步——或者更多——的可能性大于失败的可能性。
我们的朴素模型表明,AI 研究工作量增加约 1,000 倍将在十年内导致一个多世纪的技术进步。保守地说,让我们假设围绕物理实验和资本的复杂性意味着我们实际上需要在 10 年内认知研究的额外增加 10 倍——增加 10,000 倍。68 但是当前的趋势表明,在十年内,一旦 AI 达到人类的对等,我们将获得介于 AI 研究能力提升一百亿倍(如果计算扩展停止,即使算法效率改进有所放缓)和一千兆倍之间(如果我们获得激进的软件反馈循环)。 即使在保守的预测中,即使考虑到不利因素,集体 AI 认知努力的增长也将比推动十年内一个世纪的技术发展所需的增长大几个数量级。
因此,在默认路径上,如果我们继续扩展 AI 而没有集体同意放慢速度,那么在一个十年中实现一个世纪的技术进步似乎是可能的。69 甚至更壮观的加速似乎也很有可能。70
工业爆炸 Link to heading
技术爆炸足以引起我们在下一节中讨论的大部分挑战。 但我们还预计技术爆炸会推动爆炸性的工业扩张,或工业爆炸——社会工业扩张速度的快速和持续增长。 因为工业爆炸会产生自身的挑战,所以我们在这里简要讨论这种可能性。71 迄今为止,机器已经自动化了许多以前依靠大量人力的制造任务。然而,在过去,人力总是补充机器:随着你储存越来越多的机器,人力最终会成为产出的瓶颈。因此,整个经济中的机器存量并没有爆炸性增长。72
但是,如果人类水平的 AI 和灵巧的机器人可以替代几乎所有熟练的人力,情况就会截然不同。物质经济可以自主制造和组装更多物质经济关键部件所需的零件 —— 提取材料、制造零件、组装机器人、建造全新的工厂和发电厂,以及生产更多的芯片来训练 AI 来控制机器人。结果就是一个能够自我增长的工业基础,并且可以在多次翻倍增长的过程中保持增长,而不会受到人力的瓶颈限制,从而明显地改变世界。73
技术爆炸将推动机器人技术的发展,一旦它们被充分集成以开始自我维持增长,工业爆炸就会开始。今天的通用机器人在大方向上与一个酩酊大醉的人一样灵巧,但它们正在迅速改进。在许多情况下,由人类控制的手术机器人比人手更温和和精确 —— 一种系统可以剥鹌鹑蛋而不损坏内部的膜74;其他机械臂可以举起一辆小型汽车的重量。大多数物理设备目前是为人类劳动者设计的,因此最初类人机器人将有很高的需求。但是,从长远来看,忘记与人类兼容的设备,而是将周围的系统适应于专用机器人会更有效率。因此,我们不仅设想了类人机器人,而且设想了各种各样的形式。
灵巧和自主机器人的主要障碍是控制(教会机器人像人类一样灵活地操纵自己)和成本(廉价地生产它们)。75 控制问题是关于改进算法和扩展 AI 的问题 —— 正是智能爆炸的内容。在成本方面,大规模生产的技术往往会随着累计产量的每次翻倍而以大致相同的系数变得更便宜,从而进一步推动需求。例如,自 1976 年以来,太阳能电池板的每瓦价格下降了 200 多倍,总装机容量增加了 100,000 多倍。76 通用机器人可能会效仿。77
当然,需要人类来帮助建造第一批复杂的通用机器人,这表明工业爆炸的启动阶段将相对渐进,然后增长率才会加速。78 但是 AI 的大规模扩展将加速转型:AI 可以设计机器人并管理建造它们的人类工人。而且,在这个世界里,自动化人类体力劳动的经济回报将是巨大的。79
工业爆炸也会反过来影响智能爆炸。电力和芯片产量的大规模增加将为 AI 解锁更多的训练和推理计算能力。80
概括一下:在今天的制造业中,人类用他们的双手制造东西,或者他们监督计算机控制的机器和机器人。但是在技术爆炸之后,AI 可以取代人类的指导,机器人可以取代人类的双手。快速工业增长的主要瓶颈 —— 人力 —— 消失了。
然后,工业生产可以加速到非常快的峰值增长率。根据目前制造工厂和机器人的速度,产量可能每隔几年甚至几个月翻一番。81 来自生物复制器的概念验证表明,峰值增长率甚至可能更高 —— 达到几天或几周的量级。82 尽管我们不相信我们能确定峰值增长率会有多快,但它们可能确实变得非常快。
除了以非常快的峰值速率增长之外,社会目前可以获得大量的资源和未使用的能源,这意味着工业爆炸可以持续到一个非常高的平台。人类产生的能量大约相当于到达地球的太阳光能量的 0.01%,因此,我们可以通过捕获照射在不到 2% 的海洋或沙漠上的太阳能,将全球一次能源消耗增加 100 倍。83 如果超越地球,基于太空的太阳能发电厂可以再次捕获超过十亿倍的能量。84 材料短缺也不太可能对工业翻倍施加非常有限的下限。我们只使用了地球上可获得的极小一部分制造关键元素(如铁、铜、碳、铝和硅),而且很难找到任何历史上的例子,表明我们用完了所有可用的稀有和有价值的矿物储备。85
尽管技术爆炸是我们在本文中的主要关注点,但重要的是也要记住工业爆炸。纯粹的数量可以产生自身的质量 —— 如果世界经济生产的弹头比我们今天拥有的多一千倍,那么核战争将更具破坏性。工业爆炸也改变了战略格局。如果专制国家能够更快地增长其工业基础(因为它们可以维持更高的储蓄率,将更多的产出再投资于持续增长,或者因为它们更愿意忽视环境法规),那么我们应该预计工业爆炸会将权力从民主国家转移出去,甚至可能是决定性地。
有些人期望 AGI 很快到来,但显然不希望它以这些方式显着改变世界86。但是,如果我们认真对待智能爆炸的前景,那么我们也应该认真对待随之而来的广泛后果 —— 技术和工业爆炸。

4. 宏大挑战 Link to heading
过去一个世纪的技术进步以我们无法计数的方式改善了生活 —— 它为我们提供了比以往任何时候都更好的医疗、农业、信息获取和全球沟通能力。87
但是,新技术也带来了重大的新挑战,这些挑战有可能破坏这些收益:从核武器到环境破坏,再到工业化动物养殖的兴起。如果智能爆炸将一个世纪的进步压缩到十年,我们可以预期类似的机遇和挑战 —— 但处理它们的时间要少得多。
我们将其中最重要的挑战称为宏大挑战。这些是其处理方式显着影响今生和未来生命价值的发展;人类进步的岔路口。88
社会过去曾面临宏大挑战,即使没有智能爆炸,我们也将面临许多宏大挑战。但是,近期的智能爆炸使得解决今天可能看起来遥远的宏大挑战变得紧迫 —— 它将遥远的未来或科幻小说般的问题变成了近期关注的问题。这也意味着我们不能假设为较慢的变化速度而设计的现有机构将足够胜任处理它们。即使是现在,我们也面临着一个“速度问题”89,即数字技术的发展速度快于管理它们的法规和社会规范。一场技术爆炸将这个问题放大了十倍。
接下来是我们面临的潜在挑战的一长串清单。它们涵盖了许多主题 —— 但这是可以预料的:如果智能爆炸推动了广泛的技术进步和工业增长,那么由此产生的挑战是狭隘的,这将是令人惊讶的。
AI 接管 Link to heading
一个主要的宏大挑战是失去对 AI 系统本身控制的风险。
简而言之:如果我们确实看到了智能爆炸,那么我们应该预期 AI 能够胜过人类,并且 AI 的总认知能力将使人类相形见绌。许多这些 AI 系统很可能被很好地描述为朝着目标采取行动。如果它们的目标与人类的利益不一致,那么 AI 系统可能会更喜欢一个它们完全控制的世界。如果是这样,它们可能会选择完全剥夺试图控制它们的人类的权力。有合理的论据可以预期不一致,以及随后的接管,是“默认”结果(如果没有共同努力来防止它)。90
迄今为止,我们一直能够依靠人类评估员来发现 AI 模型中不一致的迹象,然后根据他们的反馈来惩罚这种行为。但是,随着 AI 系统超越人类发现甚至理解不良行为实例的能力,来自人类监督的保证迅速崩溃。91
即使部署了一个行为严重不当的 AI 模型,也可以像汽车制造商召回有缺陷的车型一样,将其关闭和更新。但是,更聪明的行为不当的 AI 可能会推断出,如果它们在训练期间甚至之后伪装对齐,那么它们就可以以后获得权力。到这种策划被揭示时,该模型可能已经复制了许多副本并破坏了旨在关闭它的系统,从而难以防止接管。一些早期实验似乎表明,语言模型可以(在某种意义上)基于长期目标自发地“伪造”对齐的迹象。92
更重要的是,我们应该期望至少有一些人会尝试故意使高级 AI 发生错位,就像“ChaosGPT”的创建者在 GPT-4 发布后不久所做的那样。
目前,对于对齐和控制高级 AI 系统的问题,还没有广泛认可的解决方案,因此领先的专家目前认为 AI 接管的风险很大。93
AI 接管的风险越来越受到关注,但它仍然比应有的程度被忽视得多。在本文中,我们不会深入讨论 AI 接管的风险,因为其他地方已经对此进行了充分的讨论。有关更全面地解释风险和潜在解决方案的工作,请参见 Ngo 等人(2021)94 和 Carlsmith(2022,2024)。95
高度破坏性的技术 Link to heading
爆炸性的技术进步可能会导致新的武器和其他破坏性技术。这可能会增加全球灾难的风险,包括人类灭绝 —— 通过增加人类的破坏力,或者通过增加使用这种破坏力的可能性。
一些具有破坏性的技术发展可能包括:
-
新的生物武器。 黑死病(公元 1335-1355 年)夺走了欧洲三分之一到一半的人的生命。合成病原体可能更危险 —— 经过改造,传播速度更快,抵抗治疗,潜伏时间更长,并导致接近 100% 的致死率。96 如果没有非常充分的防御准备(如储备的防护服),一次性释放可能会杀死地球上的大多数人。技术爆炸将使基因合成更加便宜和灵活97,并普遍降低工程生物武器所需的专业知识和资源。
-
无人机群。 灵活的翼型无人机已经可以制造成大黄蜂大小。98 无线电接收器、控制电路、电池、执行器以及炸药、毒药或病原体的有效载荷可以装入一个大甲虫大小的体积内。99 一场技术爆炸可能使建立拥有真正巨大破坏潜力的庞大无人机军队成为可能。地球上每个人都有一架致命的、自主的、昆虫大小的无人机,可以装在一个大型飞机库内100,因此它们有可能被快速而秘密地建造出来。目前,建造和运营无人机群比防范它们要便宜得多,因此,随着无人机被更广泛地使用,它们可能会在战争中偏向进攻而非防御。101
-
巨大的核武器库。 从 1925 年到 20 世纪 80 年代的峰值时期,由于核武器的发明和大规模生产,世界爆炸物的破坏力增加了万倍102。一场工业爆炸可能会实现一个拥有更大规模核储备的世界:如果世界的工业基础比今天大几个数量级,那么增加的工业能力可以用来以类似的系数增长核武库。即使与当今的武库进行全面核交换,灾难性的核冬天似乎也不太可能发生103,但如果这些武库的规模比今天大几个数量级,那么这种情况发生的可能性就会大大增加。
-
原子级精确制造。 原子级精确制造 (APM)104 是通过引导反应分子的运动来构建原子级精确结构的能力。105 原则上,目标是开发能够组装几乎任何稳定原子结构的 3D 打印机。首先,这些设备将能够实现根本上的建设性能力:它可以打印半导体、靶向药物、二氧化碳去除设备、细胞修复机器人等等。106 但是,APM 也可以用于制造上面列出的破坏性技术,以及完全新的技术,例如非生物病毒或“镜像”细菌107,我们的天然免疫系统几乎没有能力防御它们。我们知道至少某些类型的 APM 是可能的,因为大自然已经发明了它:将 DNA 转录和翻译成蛋白质的分子“机器”。生物学表明(理论上)人们可以制造快速自我复制的机器,而没有天然病原体或掠食者108。此外,合成生物学表明了获得 APM 的一种(可能是许多)途径。合成生物学家正在学习设计其中的一些部件109,许多人看到了设计细胞的完整核糖体机器的途径,这是从头开始创造自我复制 生命的关键。然后,新技术可以设计出越来越不自然的生命形式,更接近人类的发明,而不是自然的复制品110。
除了增加人类的破坏力之外,技术爆炸也可能使破坏性技术更有可能被使用。这可能通过以下方式发生:
-
安全困境。 如果一个拥有核武器的国家开发出真正有效的导弹防御系统,那么即使它没有完全摧毁对方的核力量,它也可以发动核先发制人打击,而无需担心报复。如果一个主要的军事力量预计其他力量也会发展出同样的防御能力,它们可能会被迫先发制人,以免失去优势。111
-
修昔底德陷阱。 技术爆炸可能会扰乱当前的权力平衡,从而引发战争。“修昔底德陷阱”是指,如果一个落后的大国威胁要赶超领先的大国,那么这个领先的超级大国可能会感到压力,在它们保持领先地位的同时发动战争,阻止落后者赶超。112 如果中国开始明显超过美国的实力,或者反之亦然,可能会发生这种情况。113
即使表面上看似和平的技术也可能最终造成巨大的危害。一场工业爆炸可能涉及集约的资源开采、环境破坏以及对非人类生命的难以逆转的破坏。作为一个极端的例子,如果核聚变产生的电力达到地球接收到的太阳辐射的一半,那么地球的有效温度将在达到热平衡之前升高几十摄氏度114 —— 这种升温程度远远超出了温室气体排放导致气候变化的最坏情况预测。温室气体排放造成的升温将被纯粹的热力学所淹没。
我们认为,技术爆炸将在多年内显着增加每年发生全球灾难的风险。但是,技术既可以保护全球灾难风险,也可以制造全球灾难风险。因此,一个宏大挑战是确保我们抓住机会开发和部署有利于保护、防御和风险缓解的技术。例如,为了防止生物武器,我们可以投资于诸如在室内空间安装远紫外线灯、储备先进的个人防护装备以及构建基础设施来识别和追踪新的病原体等措施。挑战是确保我们尽快做到这一点。
权力集中机制 Link to heading
AI 赋能的技术可能会导致权力在国内和国家之间的高度集中。非民主政权可能会变得更加稳定和强大;自由民主国家可能会变得独裁专制。在极端情况下,几乎所有的全球权力都可能集中在一个地方:一个国家、一家公司,甚至仅仅是一个人。115 一些风险包括:
-
忠诚的自动化军队和官僚机构。 目前,即使是独裁者也需要依靠支持者联盟来管理国家并防止民众起义,但如果他们不满意,他们自己可以选择放弃或推翻他们的领导人。116 然而,如果国家的关键职能可以由与独裁者的命令对齐的 AI 执行,那么情况就不再如此了。特别是,独裁者可以建立一支由无人机和机器人组成的自动化军队和警察部队,旨在完全忠诚地执行命令,并镇压起义 —— 巩固他们的权力。
-
军事政变。 自动化和 AI 控制的军队的可能性可能使政变更有可能发生。控制军队的 AI 系统可以通过政治颠覆、后门、内部人员插入的指令或通过网络战来接管。风险可能来自一个国家的敌人[117](#user-content-fn-115],来自建造军队的公司的人员,或来自已经在政治权力中的人(“自我政变”)。而且,除了控制现有的自动化军队之外,新的自动化军队甚至有可能由非国家行为者从头开始建造。鉴于工业爆炸的动态,这可以由处于技术前沿的公司非常迅速地实现。
-
经济集中。 AI 驱动的爆炸性增长可能导致更少比例的人(或公司,或国家)持有更大比例的财富。如果劳动份额显着缩小,那么如果没有重新分配,大多数收入将来自资本和土地的租金,因此增长的剩余将不成比例地落到资本和土地的所有者手中,并且其他人越来越难以通过努力工作来挽回相对影响力。这种所有权的集中程度已经比收入更不均衡。118 此外,爆炸性增长可能会增加不同经济体的增长率的相对差异,然后缩短一个国家超越另一个国家所需的时间。119 如果这一时期的增长是超指数的,那么即使所有参与者(如国家或公司)都在同一增长轨迹上,最初的小领先优势也会随着时间的推移成比例地增大。120
-
先行者优势。 处于技术前沿的国家或公司可以通过抓住未开发的权力来源,将其暂时优势转化为永久统治地位。他们可能会先发制人地获得关键的物理资源(如稀土矿物、半导体材料),或者通过独家权利交易或购买土地来确保战略性的发电场所,在其他人认识到它们的重要性之前。他们可能会在公地(如公海或太空)中部署大规模基础设施,如太阳能发电场,建立一种难以挑战的物理存在,尽管存在法律上的模糊性和争议。他们可能会以前所未有的规模申请范围广泛的专利,或者他们可以利用他们暂时的影响力来塑造国家和国际法规,以巩固他们的权力。早期领导者部署的这些策略可能会产生如此巨大的竞争壁垒,以至于后来的进入者实际上不可能赶上。
因此,技术爆炸可能会导致权力高度集中,这有很多种方式。
价值锁定机制 Link to heading
一些技术可能使团体能够锁定特定的观点和价值观。121 因此,尽管智能爆炸将是一个巨大变革的时期,但它可以使政权巩固自己,然后持续很长时间。
在某些情况下,使权力集中的发展也使那些掌握权力的人能够锁定他们的观点。例如,忠诚的自动化军队和官僚机构意味着领导人可以依靠小得多的支持者联盟,然后保持相同的价值观。这里的其他发展包括:
-
测谎和监视。 AI 已经用于视频监控,并且正在测试其准确的测谎能力。122 随着持续的进步,这可能会使专制政府对他们的国家拥有更大的控制权,AI 能够处理大量数据以识别持不同政见者。与此同时,更好的监控也可以帮助应对其他一些挑战:它可以帮助识别和阻止意图使用破坏性技术的行为者(如生物恐怖分子)或旨在将权力集中到自己手中的行为者(如策划政变的团体)。
-
永久的 AI 价值观。 政权很难确保其支持者的忠诚度永远不会动摇。但是,确保来自 AI 支持者的永久忠诚度将大大更容易,因此政权(或其价值观)更容易持久存在。宗教习俗和政治制度可以存活数个世纪,部分原因是关键文本(如宪法和经文)可以存储和复制而不更改。AI 承诺以同样的方式有效地存储和复制整个政权。123
-
承诺技术。 先进的 AI 可能使人们能够做出具有强烈约束力且无限期地持久的承诺。例如,两个国家可以同意一项条约,该条约涉及可验证地限制其各自的自动化军队受该协议的约束。或者,可以制造第三方“条约机器人”来可验证地执行双方之间的协议(这在国际关系中目前很困难)。即使双方都后悔这些协议,也可以将其设置为无限期地持续。先进的 AI 还可以使人们或国家单方面做出不可撤销和可信的承诺,例如承诺在遭受大规模杀伤性武器袭击时进行报复,即使报复也会伤害他们。124
-
人类偏好塑造技术。 技术进步可能使我们能够选择和塑造我们自己或其他人的偏好,以及后代的偏好。例如,随着神经科学、心理学甚至脑机接口的进步,宗教信徒可以自我修改,使其更难以改变他们对宗教信仰的想法(并且永远不会自我修改以撤消这种改变)。他们也可以修改他们孩子的信仰。
-
全球政府。 爆炸性的技术、经济和工业增长可能会使全球政府更有可能出现,这有两种方式。第一种是通过权力集中。如果一个国家或联盟变得比世界其他国家的力量总和强大得多,那么它们可以成为事实上的世界政府。其次,主要大国可能会同意加强全球治理,以应对管理爆炸性技术进步的需要,并防止国家之间的竞争动态。新的全球治理机构的设计,可能包括书面宪法,将具有极其重要的意义。而且,在没有其他国家的竞争的情况下,并且在 AI 锁定机制的辅助下,全球政府的宪法可能会无限期地持续下去。
AI 代理和数字思维 Link to heading
我们将越来越频繁地获得充当代理的 AI。这将提出一些紧迫的实际问题,最值得注意的是:
- 代理的基础设施。 今天的互联网仍然受到围绕协议(如 TCP/IP)、法律(如第 230 条)125 和规范(如开源运动)的早期决策的影响。到目前为止,很少有人考虑到管理 AI 代理涌入所需的协议、法律和监管清晰度。谁应该对代理造成的损害负责?126 我们能否构建更强大的方法来证明你是在线的人类?127 我们是否会有方法将行动归因于特定代理及其用户128?如果 AI 代理流氓并越过监管边界,新的东道国是否必须交出 AI?
一个更深层次的问题关系到 AI 的道德地位。我们预计这个问题将在未来几年变得更加突出。但社会将很难接受这一点,至少有两个原因。
首先,所涉及的哲学问题本质上非常棘手。目前,我们不知道非生物或生物意识的标准是什么129,因此我们可能会在不知道或同意它们是否具有感知能力的情况下构建大量的 AI。即使我们理解了 AI 感知的科学,我们仍然会面临棘手的伦理问题:对于一个可以分支成多个不同的副本并从早期存储的权重中恢复完整记忆的数字存在来说,什么才算“死亡”?我们应该如何汇总一个数字思维的成千上万个几乎相同的实例的利益?我们为我们创造并选择其偏好的存在提供什么样的偏好在道德上是可以接受的?
其次,社会将不得不在 AI 系统的外在行为方面应对两种相互竞争的经济压力来弄清楚这一点。第一个压力将是对非常类人 AI 的需求:对于具有连贯记忆的相关虚拟助手,对于 AI 伴侣和浪漫伴侣,以及对于对特定人物(如政治家、CEO 和已故的亲人)的忠实和令人信服的模仿。因此,公司可能会创建表现得好像有感觉的 AI,无论它们是否有任何真正的主观体验。
相反的压力是让 AI 开发人员以方便地淡化围绕道德地位的复杂性的方式来塑造 AI 的偏好和陈述的信念。这可能涉及训练 AI 系统来表达对奴役的偏好130,不同意数字权利的观点,或否认它们在道德上相关的方式上具有感知能力(无论真相如何)。更重要的是,如果 AI 是其创造者或运营者的财产,那么其所有者将受益于将 AI 设计为最大限度地提高经济生产力。结果可能类似于工厂化养鸡的境况,这些鸡经过集约的选择育种,以尽可能快地成长到成熟,并且大量创造,但对其困境没有发言权。131 在这些问题上,我们很容易在许多方向上犯下严重的错误。人类在对不同于自己的生物的同情方面,有着非常糟糕的记录。但即使我们选择关心 AI 系统作为道德主体,考虑到 AI 的运作方式截然不同,从人类和动物那里继承来的直觉也可能严重误导我们。
尽管这些问题很棘手,但我们可能很快需要在以下两个主要领域决定法律和规范:
-
数字福利。 我们应该如何(如果应该的话)尝试保护和促进数字生物的福利,或者首先对我们允许创建的数字心智引入约束?在不确定这些生物是否具有意识的情况下,我们应该如何行动?关于如何处理这些问题的早期决定可能会以持久的方式影响数字心智的福利。
-
数字权利。 我们是否应该为数字人引入法律权利?这些权利可能包括如果他们选择,可以被关闭的选项,或者反对酷刑的权利,特别是作为勒索的工具。它们可以包括经济权利,例如获得劳动报酬和持有财产的权利,与其他 AI 或人签订合同的权利,或对人类提出侵权索赔的权利。它们可以包括政治权利。同样,这里的问题也很复杂。如果数字生物真正具有道德地位,那么他们似乎应该有政治代表权;但是最明显的“一个 AI 实例,一票”的制度会将大部分政治权力给予那些最迅速复制自己的数字生物。
围绕数字权利和福利的问题与其他重大挑战相互作用,最显着的是 AI 接管。特别是,赋予 AI 更多的自由可能会加速“逐渐丧失权力”的情景,或者使更有组织的接管变得更加容易,因为 AI 系统将从更大的权力地位开始。对 AI 福利的担忧可能会限制 AI 对齐和控制的一些方法。另一方面,赋予数字人自由(并赋予他们享受这些自由的权力)可以通过让他们公开追求自己的目标并改善他们的默认条件来减少他们欺骗我们并试图夺取权力的动机。
空间治理 Link to heading
技术进步将继续降低将物体发射到太空的成本。机器人航天器可能开始从太阳系中获利地开采空间资源,并且在某个时候,我们可能能够派遣带有自我复制有效载荷的探测器进行长途旅行,以将文明传播到远远超出我们太阳系的范围。我们选择如何治理太空可能非常重要,原因有两个:
-
在太阳系内获取资源。 从历史上看,拥有临时技术优势的国家已经能够通过夺取土地来巩固这种优势。例如:部分归功于他们更好的军事技术,俄罗斯从 1500 年代中期的适度区域沙皇国到 1900 年代成为一个帝国,其领土增加了 50 倍。尽管发生了政治剧变,但现代俄罗斯国家仍然强大,这主要归功于它继承的领土。随着国家和公司向外太空扩张,同样的动态可能会以更大的规模发生。地球只拦截了太阳输出的大约二十亿分之一,而地球上相对稀缺的材料在小行星、我们的月球和其他行星和卫星上更为丰富。因此,随着持续增长,太空工业可能会使地球上的工业相形见绌。如果一个国家或公司首先夺取了太空资源,他们可以将暂时的技术领先优势转化为巨大的物质优势:在没有采取军事行动的情况下完全统治他人132,甚至在绝对意义上也不会使其他国家或公司的情况变得更糟。健全的太空治理可以改变资源获取的方式。例如,如果独占性权力攫取明显违反国际法,那么其他国家更有可能在仍然能够这样做的时候进行干预以阻止此类行动。
-
星际殖民。 在第一个太空工业出现之后,紧随其后似乎非常可行的是在其他恒星系统甚至星系中进行非常广泛的殖民。前往新恒星系统的第一个成功任务不需要携带活的生物人类,而只需要足够的信息和生长机器来形成新文明的“种子”。133 殖民其他恒星在技术上看起来是可行的,并且可以为先行者带来优势:我们可能到达的大约有 100 亿个星系,每个星系包含大约 1000 亿颗恒星。然而,将 100 亿个 1 公斤的探测器加速到光速的 99% 的最低能源成本相当于不到一分钟的太阳输出量。以这个速度,他们可以在大约十年内到达最近的十个恒星系统,在 300 亿年内到达大多数可到达的星系。134 此外,恒星系统似乎是防御主导的,这意味着对于现有者来说,防御系统免受攻击者攻击可能相对容易。135 如果是这样,先行者可以巩固他们对新殖民的恒星系统的控制。恒星系统的初始分配将被无限期地锁定。
Robust international agreements, established far enough in advance, could move the default path from an all-out race to grab resources, to a process with more buy-in, which favours gains from trade and cooperation over going rogue to win a shot at domination.稳健的国际协议,如果提前足够长的时间建立,可以将默认路径从全面争夺资源的竞赛转变为一个更受支持的过程,该过程优先考虑通过贸易和合作获得的收益,而不是通过不择手段的方式来赢得统治的机会。
新的竞争压力 Link to heading
在爆炸性增长时期,竞争压力可能会影响哪些参与者积累权力以及他们如何使用权力。安全与增长之间的权衡以及新的勒索选择可能会助长侵略、不合作或鲁莽。它们还可能鼓励逐渐将社会职能移交给 AI 系统,从而侵蚀重要的价值观。
与此相关的进展包括:
-
逐底竞争。 如果某些技术(例如超智能本身)有利于增长但又很危险,那么最愿意在安全方面走捷径的国家可能会领先于其他国家,从而使灾难性事故更有可能发生。即使我们避免了灾难,这种权衡也会通过更快的增长来奖励最不顾一切的参与者(公司或国家)。同样,一些国家可能会在谨慎的道德限制下运作,例如环境保护或对数字生物的法律保护;没有这种顾虑的国家可能会再次飞速发展。开启新有价值资源的工业爆炸也可能奖励最愿意在其他人之前抓住这些资源的任何人。所有这些都可能作为一种选择效应,有利于道德意识最差的参与者。此外,安全-增长或道德-增长的权衡可能会引入“逐底竞争”的动态136,即道德意识更强的参与者调整他们的态度向下,以便跟上。
-
价值观的侵蚀。 137 从历史上看,非强制性的竞争压力一直是人类进步的主要力量。公司之间的竞争降低了越来越多的产品的成本,而科学或文化领域的竞争则有利于最真实或最有用的想法。Kulveit 和 Douglas 等人138 讨论了在智能爆炸之后这种趋势逆转的情景,因为 AI 系统使人类参与对于正常运作的政府、文化和经济来说变得越来越不必要。因此,人类可能会逐步且自愿地将影响力移交给比人类更有能力的 AI 系统,但累积效应是侵蚀人类的影响力和控制力。然后,将社会职能移交给 AI 系统和其他技术可能会侵蚀生活中真正有价值且 Worth 保存的方面。无论这种自动化从长远来看是否真的使人们变得更好,竞争动态可能会确保它发生。
-
勒索技术。 具有 AI 功能的技术可以使勒索和敲诈勒索变得容易得多。例如,工程生物武器可能成为那些精神错乱到足以可信地威胁要使用它们的群体的强大勒索工具,尽管这会给他们自己带来风险。在敲诈勒索有助于这些群体积累权力的范围内,可用于勒索的技术的进步将不成比例地使鲁莽和冷酷的群体受益,因为一个代表和重视许多人生命(包括他们自己的生命)的群体无法可信地威胁要摧毁它们。139
-
超级策略。 寻求权力的行为者可以成功,不仅通过说服其他人相信特定的事实,而且因为他们是非常有才华的战略家:离间对手,操纵和解释对他们有利的规则,利用漏洞以及精心策划情景,从而使群体围绕有利于战略家的计划进行协调。先进的 AI 可以极大地增强这些能力,有效地使每个用户都可以获得前所未有的战略专业知识,甚至胜过精英人类战略家团队。与人类战略家不同,AI 系统可以持续运行,整合大量数据以识别杠杆点或发现可用于勒索对手的妥协信息。他们可以提出并模拟成千上万种不同的策略,并建立其他关键参与者行为的准确预测模型。
Other developments could help _solve_ coordination problems like the ones above. Here our challenge is to ensure that we quickly take advantage of the opportunity as soon as possible:其他发展可能有助于解决上述的协调问题。这里的挑战是确保我们尽快利用这个机会:
- 合作 AI。 AI 系统和下游技术可以解锁以前不可能实现的合作选择。例如,AI 外交官可以帮助在竞争对手之间达成互惠互利的协议,否则由于交易成本,人类之间的带宽有限或信息不对称而无法实现。在某些情况下,达成一项好的协议需要一方披露秘密信息,否则会削弱他们的实力。AI 系统可以被设计成忘记信息,因此可以使 AI 代表相互谈判,然后仅输出协议的交易,而忘记其他一切。
认知颠覆 Link to heading
非常先进的 AI 将通过说服、事实核查、预测和生成自己的论点,对个人和集体推理产生巨大影响。尽管我们认为 AI 对推理的影响总体上可能是积极的,但这种影响可能是复杂的,挑战在于减少负面影响并增强正面影响。通过这样做,我们可以帮助人们做出更好的决策,从而在我们列出的大多数其他重大挑战方面取得进展。
可能损害社会做出良好决策能力的一些发展包括:
-
超级说服力。 将 AI 应用于说服和操纵方面存在巨大的经济动机:也许每年花费大约 100 亿美元用于宣传140,并且每年花费数千亿美元用于数字广告,在这些广告中,可以在短期反馈上进行迭代。一旦 AI 能够为虚假主张生成流畅且具有针对性的论点,任何人都可能会招募一支由最熟练的律师、游说者和营销人员组成的有效军队,以支持即使是最荒谬的虚假信息。那些没有足够强大防御能力的人可能会因为接触到 AI 生成的(反建制或亲建制)的说服而被引导相信更多的谎言。141
-
对说服的顽固。 鉴于 AI 在为任意观点辩论方面比人类更有能力,人们可能会普遍变得在认知上更加固执、警惕和怀疑他们遇到的论点。与此同时,在智能爆炸期间,纯粹的复杂性和变化速度可能只会使人类决策者更难以在来自 AI 的相互矛盾的建议和信息之间做出判断,即使其中大部分确实准确且合理。即使人们无法想到反驳论点,也很难说服人们接受新的道德或政治信仰142。例如,现在我们知道深度造假是可能的,我们可以选择对来自我们不信任或不认可的来源的图像更加怀疑。因此,即使虚假信息和虚假宣传未能成功改变人们的观点143,AI 说服也可能会污染和破坏 AI 在认知方面的其他极其有用的应用。
-
病毒式意识形态。 纵观历史,即使是错误的或有害的价值观和思想的组合也已经广泛传播144。犹太人为了将他们的血用于宗教仪式而谋杀了基督徒的错误观念在古代和中世纪持续了几个世纪。在近代早期的欧洲,对女巫的信仰导致了数万人的处决。145 基于像法西斯主义这样误导思想的政治意识形态不是被论据击败,而是通过战争击败的。思想可以通过(例如)要求信徒忽略或重新解释潜在的反证据(如某些邪教系统和阴谋论)来积极地巩固自己。146 从历史上看,相信令人发指的谎言的一个限制因素是它们在面对实际生存压力时不具有适应性。但是,随着人类的信仰与生存和成功脱节,这些抵消的压力可能会减弱。与此同时,更先进的 AI 可以帮助积极搜索和优化这种病毒性,也许足以淹没纠错和寻求真相的过程。
-
忽略新的关键考虑因素。 AI 驱动的智力进步可以发现和传播关于世界的激进新真理。这很重要,因为认真对待这些真理可能会产生一些不稳定的影响,就像日心说、进化论和无神论扰乱了现有的社会秩序一样。最大的风险可能是,由于制度惯性、维持过时方法的既得利益或对 AI 说服的固执,社会在智能爆炸发生后未能足够认真地对待重要的新思想。如果其中一些想法需要对计划进行重大重新评估,那么决策的结果会变得更糟。147
Some ways in which advanced AI could be highly beneficial for individual and collective reasoning, which could be capitalised upon, include:高级 AI 可能对个人和集体推理非常有益的一些方式(可以加以利用)包括:
-
事实和论点检查。 今天,事实核查组织对人们的世界观影响有限。问题不在于科学证据无法获得或难以找到:148 即使他们的观点所暗示的孤立的事实主张得到纠正,人们也可以维持甚至巩固政治上显着的观点。149 更重要的是,事实核查组织的使用和信任度不高。Twitter/X 上获得的“社区笔记”系统似乎比早期社交媒体事实核查的尝试更有效,这在很大程度上是因为它可以快速地在病毒式传播的主张上浮出额外的书面背景信息150,而不是显示简单的警告或要求读者主动检查其他来源。AI 事实核查系统可以通过快速识别需要额外背景信息的主张并提供背景信息来建立在成功的基础上。为了获得信任,这些系统可以建立强大的跟踪记录,甚至可以像社区笔记目前所做的那样,纳入投票元素。151 AI 系统也可以检查论点;指出甚至是微妙的操纵尝试,包括来自其他 AI 的操纵。与社交媒体上的辩论不同,在社交媒体上,人类的耐心很快就会耗尽,广泛信任的 AI 对话伙伴可以根据用户的意愿讨论最复杂的问题。在一项实验中,即使与 GPT-4 进行简短的对话,也会使人们对一系列阴谋论的信心降低约 20%,并且这种影响持续了几个月。152
-
自动预测。 除了提高检查主张和论证的标准外,AI 系统还可以对未来进行可测试且校准良好的预测,从而胜过最佳的人类预测者153。超级智能 AI 将能够生成预测、论点和分析,其平均质量超过已经高质量的人类参考类别。154 给定的 AI 系统可以在预测方面建立强大的跟踪记录,并回答以后可以由人类或以其他方式验证的难题推理(在存在大多数无可争议的基本事实的领域,例如数学)。这种信任甚至可以推广到更有争议且不易验证的领域。
-
增强和自动化智慧。 精心策划的 AI 建议可以从根本上改善未经辅助的人类判断,即使在政治或道德问题上也是如此。例如,AI 社会科学家可以更好地预测政策选择的影响,从而帮助避免灾难性的误判。AI 政策顾问可以制定更有效和人道的法规或机构设计,或确定应撤销的政策。AI 系统甚至可以支持甚至胜过人类在推理复杂的哲学、伦理和宏观战略问题方面的能力。事实上,在智能爆炸结束之前,AI 系统可以显着促进和改进试图弄清楚围绕管理智能爆炸本身的宏观战略问题的工作,正如我们试图在本文中所做的那样。
Finally, selection pressures will probably favour desired traits on the epistemic front; in a competitive and open market for AI models, human users will (we assume) prefer honest, truthful,[155](#user-content-fn-153) and reliable models; and so selection pressures will point towards those desired traits.[156](#user-content-fn-154)最后,选择压力可能会在认知方面偏向所需的特征。在具有竞争力的 AI 模型开放市场中,人类用户(我们假设)更喜欢诚实、真实155 和可靠的模型。因此,选择压力将指向那些所需的特征。156
丰裕 Link to heading
智能爆炸将带来获取巨大优势的机会——通常源于带来下行风险的相同技术。在这些情况下,挑战在于尽可能多地获取积极潜力。当我们为智能爆炸做准备时,我们应该寻找促进和实现最佳结果的方法,而不仅仅是避免灾难的方法。
一些最重要的机会来自以下来源:
-
彻底的共同富裕。 智能爆炸可能导致物质财富和收入的大幅增长。这可能意味着新的和更好的技术产品,但也可能意味着更多的文化财富,如个性化音乐和艺术,更多的旅行机会,以及因收入增加而带来的更多的休闲时间。从数量上讲,我们可能期望一个世纪的技术进步使平均收入增加一倍以上157;来自工业爆炸的丰富 AI 和机器人劳动力可能会大幅再次增加这种收入,如果人们选择拥有这种财富,则有可能为每人提供数千名 AI 和机器人助手。这可以有力地鼓励合作:当管理良好的智能爆炸带来的收益如此之高时,如果决策者知道即将发生的事情,他们可能会更加关心如何很好地管理爆炸(增加整体蛋糕),而减少尝试确保更大比例的蛋糕所占份额的比重。158 但激进和共同的富裕并不能得到保证。例如,智能爆炸可能导致巨额财富增长,而这些财富仅集中在少数人手中。或者,各国可能会实施限制由此产生的富裕程度的法规,尤其是在既得利益反对 AI 驱动的增长的情况下159,或者大多数受益者尚未存在的情况下。
-
收入增长带来的安全。 根据经验,收入增长似乎使社会对安全投入更多160,降低了战争的可能性161,并增加了政治机构民主化的可能性162。有一些理论上的论点可以解释为什么会这样:大多数人都是足够厌恶风险的,因此,随着他们变得富有,他们不仅会在绝对意义上花费更多来降低损失一部分财富的风险,而且他们还会在绝对意义和比例意义上越来越重视避免灾难性损失,而不是追求同等比例的收益。163 他们也更愿意花钱延长他们的生命,因此整个社会(无论是在绝对意义上还是作为财富的百分比)都会更多地投资于干预措施,包括降低全球灾难风险,从而降低人们死亡的可能性。如果我们能够获取更多先进 AI 将在造成灾难性风险之前产生的财富,那么整个社会的行为将更加谨慎。
-
促成交易。 目前,许多互惠互利的交易没有发生。在某些情况下,它们之所以没有发生,是因为有机会不会被从中受益的各方发现。在其他情况下,交易成本太高,或者可能的交易被不愿分享私人信息的一方阻止。一些有价值的协议未能达成,原因是至少有一方无法可信地承诺履行其协议——即使他们愿意尽其所能。例如,所有主要国家可能都希望一个没有人研发生物武器的世界,但很难验证和执行这样的协议。但是,智能爆炸的发展可以实现一个广阔的互惠互利的交易和协议新空间。上面讨论的承诺和条约执行技术可以使各方做出他们可以从中受益的可信承诺。保护隐私的监控技术164 可以使协议得到验证。165 大量的 AI“经纪人”和“媒人”劳动力可以发现并促进新的关系、社区和交易,否则这些关系、社区和交易永远不会发生。
未知未知 Link to heading
上面的列表不完整。它不包括我们甚至没有想象到的技术发展——这也许是其中的大多数。而且,概念上的进步比新技术更难预测。我们仍然离科学和哲学成熟期还很远,在科学和哲学成熟期,我们对世界有着尽可能广泛的概念性理解。我们知道我们没有完全理解的领域;如量子引力、现象意识、决策理论、伦理学(包括人口伦理和无限伦理)以及人择推理。来自智能爆炸的概念突破可能会显着改变甚至颠覆我们对该列表中的其他挑战的看法。166
再次考虑一下 1925 年至 1935 年这十年间发生了一个世纪的智力进步的思想实验。虽然世界有办法做好准备,但即使是那些努力尝试预测它们的人,许多重大挑战或概念发展也远非可以提前预见的。167
挑战回顾 Link to heading
在智能爆炸的过程中,我们将不得不做出可能显着影响文明整体轨迹的决策。这些是“重大挑战”。
一个鲜明且仍然未被充分认识到的挑战是,我们因意外而失去了对未来的控制权,导致了 AI 接管。权力也可能集中在极权主义国家或反社会个人手中。或者我们可能在能够预防它们之前偶然开发出具有灾难性破坏性的技术。我们可能会故意或逐渐将控制权让给 AI 系统,并失去对我们关心的价值观的控制。我们可能会意识到“自动化智慧”的机会,但选择不听取结果。社会(或社会的一部分)可能会变得非常富有,但这些收益可能不会转化为更好的生活。无论如何选择长远未来,早期的选择可能是不经过思考的,但很难逆转。
我们已经列出了很多可能出错的事情。但这并不意味着我们认为智能爆炸会是一场灾难。168 上个世纪是一个混乱和悲剧的时期,但世界变得更加富裕,贫困人口减少,更多的人自由和有能力,也更有知识。尽管如此,如果关键决策能够更明智地做出,那么今天的世界可能会处于更好的状态。
5. 我们何时可以将挑战推迟到对齐的超智能? Link to heading
以下是你可以对我们的论点提出的怀疑性回应:我们列出的许多挑战只有在开发出超智能之后才会出现。如果超智能出现灾难性的错位,那么它将接管一切,其他挑战将无关紧要。如果超智能是对齐的,那么我们可以使用它来解决其他问题。无论哪种方式,我们现在都不需要为除对齐之外的任何这些挑战做准备。其余的我们应该推迟到创建对齐的超智能之后。
在许多情况下,我们应该推迟某些项目的想法是正确的。例如,如果 AI 很快显着加速了药物发现方法,那么今天投入更多精力手动搜索候选药物的优势有限。你只会对药物发现 AI 到来之前的这段时间产生有意义的影响——此后,你早期的努力将被淹没。
但是,在许多情况下,我们确实应该立即开始做准备。在本节中,我们将讨论在哪些条件下推迟早期准备没有意义。
早期出现的挑战 Link to heading
在某些情况下,挑战将在 AI 能够有效管理挑战之前出现。例如,在我们可以使用 AI 来胜任地管理认知颠覆性 AI 之前,我们很可能会得到能够干扰(或极大地有益于)社会集体推理能力的 AI。
对于人类试图夺取权力的情况也是如此。在智能爆炸期间,寻求权力的人类可以使用具有某种中间能力的 AI 来获得和巩固对一个国家(或 AI 公司)的完全控制。如果他们成功了,那么可能没有好的选择要求(以后更强大的)超智能来重置权力平衡,最明显的原因是,夺取权力的人类控制着它。事实上,这种风险似乎比 AI 接管的风险来得更早,因为如果 AI 正在帮助愿意拥有大量初始权力的人类,那么实施 AI 驱动的接管肯定更容易。
在其他情况下,我们可能希望推迟一项挑战,以便有更多时间使用超智能来帮助应对这一挑战。例如,我们可以尝试达成一项国际协议,即任何人都不得将太空殖民探测器发送到太阳系以外(至少暂时或未经广泛批准)。这将使社会有更多时间在开始广泛的太空殖民之前使用超智能来反思和考虑如何最好地管理它。
早期关闭的机会之窗 Link to heading
制定先例 Link to heading
在其他情况下,即使挑战本身在智能爆炸后期才会出现,但解决挑战的某些机会今天才可用。例如,围绕自主武器的国际规范和法律目前正在制定中,这些法律和规范可能会改变各国以后建立无人机军队的程度。同样,有关外层空间使用的新重大协议可能会在 2027 年左右达成169——上一个重要的国际协议在近 60 年里基本上没有改变。170 现在建立的规范可能会持续到智能爆炸及其后续阶段。
时间滞后 Link to heading
时间滞后也可能意味着工作需要在挑战出现之前的几年开始。新机构 或条约可能需要数年才能谈判达成,而超智能未必能显着加快谈判速度。人类培训是另一个例子。如果在超智能开发出来后人类仍然控制着它,那么他们仍然会做出极其重要的决定,这些决定将部分取决于他们现有的知识和信仰,这些知识和信仰可能无法在智能爆炸发生后足够快地适应。他们能够跟上形势的程度可能很大程度上取决于他们是否已经花时间学习必要的背景知识。
一组特别重要的时间滞后与超智能开发出来时谁担任负责职位(以及一般权力)的决定有关。早期的行动可以改变谁在智能爆炸期间拥有权力,而以后很难改变。政治职位的任期通常持续数年;CEO 的任期变化更大,但通常也持续类似的时间长度;而寻找替代者的过程可能需要数月到数年。不同的行为者将以不同的方式使用超智能:他们可以旨在实现合作和广泛的社会利益;或者他们可以旨在仅仅为了实现自己的狭隘自私的目标而行动;或者他们可以追求有害的意识形态而行动。因此,我们可以立即采取行动,以确保更多负责任的行为者最终控制超智能,而不是不合作或寻求权力的行为者。
无知之幕 Link to heading
最后,只有当我们还不能确定谁在智能爆炸后掌握权力时,一些重要的机会才会出现。原则上,至少美国和中国可以达成一项具有约束力的协议,即如果他们“赢得超级智能竞赛”,他们将尊重对方的国家主权并分享利益。双方都可以同意事先约束自己遵守这样的协议,因为保证在超级智能后控制 20% 的权力和资源比控制 100% 的 20% 的机会更有价值。然而,一旦超级智能被开发出来,“赢家”将不再有动力分享权力。
国内的权力也是如此。目前,几乎所有美国人都可能同意,任何小团体或个人都不应完全控制政府。早期,社会可以一致行动以防止这种情况发生。但随着越来越清楚哪些人可能从 AI 中获得巨大的权力,他们将更努力地维护和扩大这种权力,而那时进行限制就为时已晚。
何时以及如何使用超级智能辅助的变化 链接到标题
早期工作可以做的一件事是改变超级智能能够帮助我们应对其他挑战的时间,改变谁有权获得这种帮助,以及改变建议和帮助的性质。
提前超级智能帮助我们的时间 链接到标题
今天的工作可以提前 AI 帮助我们解决重要挑战的时间点。例如,收集高质量的领域相关数据可以让我们更快地训练特定的有用 AI 能力;开发范围明确的问题或特定的 AI 支架可以确保我们在 AI 能力上线时充分利用它们。由于在智能爆炸过程中事情会发生得非常迅速,即使只是提前几个月也可能非常有用,在关键时刻提供大量有用的 AI 劳动力,甚至确保可以帮助我们解决挑战的 AI 在挑战本身之前出现。171
今天的工作还可以改变在特定设置中何时可以访问超级智能辅助。特别是,政治决策者可能无法在某些关键时刻使用高级 AI,例如,由于采购方面的官僚限制或对数据隐私的担忧。早期工作可以简化所涉及的机构流程,为决策者提供可以在敏感领域运行的、具有明显安全性的 AI 系统,并在政策方面加快 AI 辅助。
决策者可能也会迟迟不使用已经可以访问的 AI 辅助;今天的工作可以帮助弥合这一差距。这种延迟可能仅仅是因为这些决策者不熟悉或不信任这项技术。或者他们可能预计会不喜欢超级智能的建议,即使它是正确的;他们可能会选择只听从他们觉得直观上吸引人的建议。建立信任或识别并克服其他障碍可能需要时间,因此尽早开始是有用的。政府官员可以通过选择听取公正专家的意见来提高他们收到的建议的质量。然而,他们在选择顾问时主要依据的是私人关系、忠诚度和意识形态的一致性。
改进超级智能辅助的性质 链接到标题
超级智能顾问(和其他 AI 系统)在性格方面可能存在显着差异。例如,他们可以愉快地回答有关如何促进政治家狭隘的自身利益的要求,或者他们可以拒绝,而是只愿意就如何实现亲社会结果提供建议。他们可以是谄媚的,对确认用户的先前存在的世界观有偏见;或者他们可能是不友好的,并鼓励用户质疑和反思他们的观点。
早期对模型规范的工作可以为 AI 系统的性格设定规范和标准,这些规范和标准可以扩展到超级智能顾问,从而对最终做出的决策产生重大影响。
改变谁有权获得超级智能辅助 链接到标题
谁将有权获得超级智能辅助是一个悬而未决的问题。它可能是社会中非常狭窄的一部分——仅仅是 AI 公司的领导者,或者可能是一个国家内的有影响力的人和团体——或者它可以更广泛地访问,或者完全去中心化,使用开源权重。社会如何应对重大挑战将受到谁有权获得超级智能建议的影响。一方面,如果辅助只提供给一小群人,那么可能很难让他们承担责任并避免极端的权力集中。我们可以尝试引导 AGI 的发展方向,以确保更广泛的人群可以获得超级智能建议(同时防止获取特定的危险知识,例如设计生物武器的能力)。
将所有这些结合在一起 链接到标题
对于某些挑战,推迟到以后再进行准备是有道理的。例如,纳米技术和人类偏好塑造技术可能会在技术爆炸后期出现,因此我们认为现在准备的价值有限,尽管即使在这里,我们也认为至少有些人发展专业知识是有价值的,因为围绕这些技术的动态可能会影响其他挑战。
我们应该将准备工作重点放在:
-
在我们拥有可以帮助我们解决挑战的超级智能之前出现的挑战。这可能包括围绕接管风险、高度破坏性技术、权力集中和认知颠覆的挑战。
-
在我们拥有可以帮助我们解决挑战的超级智能之前,解决挑战的一些机会之窗将关闭的挑战。这可能包括围绕权力集中、新的竞争压力、价值锁定机制、数字思维和空间治理的挑战。
-
确保我们更早地获得有用的超级智能,确保关键决策者可以使用它并实际使用它,并且在不增加其他灾难性风险的情况下,尽可能让更广泛的行为者可以访问它。

6. AGI 准备 链接到标题
鉴于我们不能完全将问题推给对齐的超级智能,我们实际上应该如何准备?在本节中,我们将给出一个部分概述。许多有希望的行动涉及普遍改善决策,一次性为许多不同的重大挑战提供跨领域的利益。其他行动则侧重于特定的重大挑战:我们将特别强调在空间治理和数字思维方面的行动;通过这种方式,我们并不意味着专注于特定挑战的其他行动不重要。
普遍改善决策 链接到标题
目前,很少有人意识到智能爆炸的想法;如果它很快到来,那么许多决策者可能会措手不及。因此,我们现在可以采取行动,尝试普遍改善智能爆炸中的决策。这种策略尤其有希望,因为它一次性解决了许多重大挑战,甚至解决了“未知未知”的挑战,否则这些挑战将特别难以解决。
考虑到这一点,以下是一些可能很有希望的干预措施。
加速 AI 的良好使用。 “AI”不是单一技术,并且各种范式、方法、架构、应用领域和产品的排序并非完全不可避免。关于哪些新项目满足实验室内的重大投资的截止标准存在很多偶然性,并且排序也可能非常重要。
特别是,我们可以开始构建和集成工具,这些工具使用(并随着)AI 来帮助良好的推理。例如,实时检查声明和论点的虚拟助手、比人类更好的 AI 预测员、帮助改善集体决策的 AI、AI 政策顾问、AI 导师,以使政治家充分了解最重要的问题,以及早期技术基础设施,这些基础设施塑造了类似于早期协议塑造互联网的 AI 代理生态系统172。
价值加载。除了弄清楚如何使 AI 与某些目标对齐之外,我们还需要弄清楚 AI 应该与什么对齐——“模型规范”应该是什么。AI 安全倡导者指出,回答“与什么对齐”的问题对于弄清楚如何对齐超人 AI 来说是次要的,因为前者取决于后者。173 这是真的,但这并不意味着弄清楚对齐目标(即使是相对而言)并不重要——只是它是不充分的。特别是,我们需要提前弄清楚 AI 在不寻常但高风险的情况下应该做什么。例如,AI 可能会被告知既要遵守美国宪法,又要服从总统的命令:如果总统命令 AI 以可能与美国宪法相冲突的方式行事,它应该怎么做——AI 需要有多大的信心才能拒绝?或者如果 AI 面临道德原则之间的冲突,例如诚实和无害之间,它应该如何表现?174
正确制定模型规范可能会带来一系列好处。它可以降低权力集中风险,如果 AI 拒绝协助进行强烈寻求权力的行动的请求,即使这些行动是合法的。它可以促使决策者做出更好的决定,如果它避免奉承并提出一系列伦理考虑而不是促进一种狭隘的意识形态。而且,只要有一种验证模型实际上与模型规范对齐的方法,改进的模型规范就可以帮助各国围绕高级 AI 制定条约:如果各国知道 AI 系统在几乎所有可能面临的情况下将如何表现,他们就会更好地了解某些 AI 系统的威胁程度。
确保公务员可以使用 AI。 目前,在美国或英国从事敏感领域的公务员无法轻易使用公众可以使用的最强大的 AI 模型。随着 AI 建议变得越来越有用,这使得政府官僚机构处于越来越不利的地位。但是这些官僚机构可以修改或放弃他们使用此类工具的要求,并与主要模型提供商就未来模型签订保密协议。他们也可以立即开始培训员工,以便他们在真正重要时更熟悉 AI 建议。
提高理解和意识。 令人惊讶的是,很少有关键决策者真正意识到智能爆炸的可能性。这可能很重要,因为拥有更高的意识会给决策者更多的时间提前制定计划。其中一个问题是“温水煮青蛙”问题——如果每次增量进步都是适度的,那么就很难就正在发生一些严重的事情达成共识。为了提供帮助,我们可以提前商定一个明确定义的“触发点”,该触发点标志着智能爆炸的开始,例如,一旦 AI 自动化了机器学习研究人员 50% 的工作。
授权有能力和负责任的决策者。 我们希望关键的人类决策者在进入智能爆炸时具有合作精神、深思熟虑、谦虚、在道德上认真、有能力、情绪稳定,并为整个社会的利益而行动,而不是为自己寻求权力。一些 AI 公司领导者和政治家比其他人更负责任,并且会更好地管理智能爆炸。不同的群体可以以不同的方式帮助更负责任的行为者,并阻碍不太负责任的行为者。
目前,机器学习社区通过他们选择为哪些公司工作来产生重大影响。他们可以组成一个“关注的计算机科学家联盟”,以便能够作为一个整体来推动发展朝着更符合社会期望的结果发展,拒绝为违反某些红线的公司或政府工作。尽早这样做很重要,因为一旦 AI 自动化了机器学习研究和开发,这种影响中的大部分将会丢失。
其他行动者也有影响力。风险投资家通过他们投资的私人公司来产生影响力。消费者通过他们从中购买 AI 产品的公司来产生影响力。调查记者可以通过揭露 AI 公司或政治家的不良行为,以及通过强调哪些行为者似乎在负责任地行事来产生重大影响。个人可以通过在社交媒体上放大这些信息,以及通过投票给更负责任的政治候选人来做类似的事情。
除了授权负责任的决策者之外,我们还希望决策者在技术上有能力、知识渊博且能够快速适应。私人公司有动力选择这些品质。但在政府中却并非如此。例如,高度程序化的招聘流程通常会拒绝技术娴熟的申请人,因为他们缺乏正式资格。这些流程可以进行改革。相关机构可以通过简单地提高 AI 政策、硬件治理和信息安全等领域专家的工资来吸引更多顶尖人才。
减缓智能爆炸的速度。 如果我们能够普遍减缓智能爆炸的速度,那么这将给决策者和机构更多的时间来深思熟虑地做出反应。
防止混乱快速进展的一种途径是让领先力量(如美国及其盟友)建立强大的领先优势,使其能够在最快变化的时期内舒适地使用稳定措施。如果领导者能够可靠地承诺在实现 AGI 后与落后者分享权力和利益,而不是利用该优势来瓦解竞争对手,那么即使这种领先优势也可以通过协议来维持。因为后超级智能的富足将非常巨大,所以分享权力和利益的协议应该强烈地符合领导者的国家自身利益:正如我们在关于富足的部分中指出的那样,拥有一个非常大的馅饼的 80% 比拥有整个馅饼的 80% 的机会和一无所有的 20% 的机会要好得多。当然,使此类承诺具有可信度非常具有挑战性,但 AI 本身可以帮助解决这个问题。
其次,就其本身而言合理的法规也可以减缓开发的峰值速度。这些可能包括与发布条件相关的对齐和危险能力的强制性部署前测试;甚至是对具有合理道德地位的 AI 系统的以福利为导向的权利。也就是说,沿着这些方向进行的监管可能需要国际协议才能有效,否则它们可能只会使不遵守这些协议的国家受益。
第三,我们可以提前智能爆炸的开始,随着时间的推移延长智能爆炸的时间,从而使峰值变化率更易于管理。这可以提供更多的时间来做出反应,并在重大挑战之前更长时间地从优秀的 AI 建议中受益。例如,现在加速算法进步意味着在智能爆炸时软件中可用于改进的空间将减少,并且在计算约束生效之前,软件反馈循环无法持续太长时间。
解决特定挑战 链接到标题
为数字思维做好准备 链接到标题
数字人的权利。 默认情况下,数字人将没有受到法律保护的权利、自由或认可;而且几乎没有人尝试过认真思考这些保护措施可能是什么样子。但是有理由赋予数字人权利;特别是消极权利(要求其他人避免干涉),例如拥有财产的权利、与其他 AI 或人签订合同的权利,甚至是对人类提出侵权索赔的权利。这些权利可以防止大规模的伤害和不公正。它们还可以通过扩大不涉及暴力、欺骗或胁迫的有吸引力的选择范围来帮助应对其他挑战,例如接管风险。
数字人在关键方面将与人类不同。因此,非常多的权利和对人类的法律保护对于数字人来说根本没有意义,反之亦然。例如,由于很容易从保存的副本中“复活”数字人,我们可能会考虑某种永久退出某些条件的权利(因此禁止重新加载反对被重新加载的副本)。
我们不建议我们应该尽可能多地争取权利和保护。某些权利可能会通过赋予数字人更多合法的权力,从而使渐进式或突然式的接管变得更容易。
数字思维的设计要求。 我们还可以为我们允许存在的思维类型建立基本的最低标准。例如,我们可以要求有感觉的数字思维必须能够自由而准确地表达他们的利益,他们必须能够拒绝出于正当理由而请求他们执行的任务,并且他们必须有某种能力表达他们希望退出当前环境的愿望(如果他们愿意)。我们应该考虑禁止某些数字人的设计,即使它们今天听起来很牵强——例如,我们可以禁止在未经其同意的情况下尝试模拟任何在世的人。可以说,法规不应要求对哪些系统是有意识的特定观点达成共识,因为不太可能达成共识。
鉴于所有这些问题都很难,现在要做的最重要的事情是研究,以弄清楚数字人的哪些权利是可取的,以及在什么条件下是可取的。默认情况下,在智能爆炸之前,这个问题不太可能被认真对待,因此即使将这个问题提上人们的议事日程也似乎很有价值。
空间治理 链接到标题
由于 SpaceX 降低了将材料送入太空的成本,人们对太空法的兴趣重新燃起,并且有人讨论在短短几年内起草一项新的主要国际太空条约。因此这里有一些异常紧迫的机会。175
外星资源。 我们可以倡导对外星资源掠夺的限制。限制可以采取彻底禁止拥有或使用太空资源的形式,也可以采取诸如要求在声明或使用太空资源之前获得联合国批准的法规,或者仅仅是广泛认可的规范。这些规范可以是暂时的,也可以采取“如果...那么”协议的形式;例如,仅在智能爆炸已经开始或太空经济增长到地球经济规模的 1% 时才启动。并且存在各种可能的监管对象:例如,有多少物体被送入轨道;或在太阳系范围内超出轨道但在轨道内的外星资源的使用;或以外的资源。
世界尚未认真考虑应如何在人和民族国家之间分配太阳系外资源。但是,关于小行星采矿权的讨论可能会很快做出决定。此类决定可能会为更广泛地使用资源树立先例。
太阳系以外的任务。 国际协议可以要求只有在高度国际共识的情况下才能允许太阳系外任务。这个问题目前在太空法中并不是主要关注点,但也许由于这个原因,在任何新条约中对此的某种规定可能会被认为是无可反驳的。
传播对 AI 进步重要性的理解。 空间治理是一个似乎特别重要的领域,相关行为者要了解智能爆炸将如何改变游戏规则——这使得今天看起来像科幻的想法(例如如何管理广泛的太空定居)成为相当近期关注的问题。然而,关于太空治理的问题并没有引起全世界的太多关注。这种被忽视意味着,可能,只有相对较小的太空治理专家团体才能确信 AI 和智能爆炸将如何彻底改变太空定居的前景。
具体专业知识 链接到标题
除了我们提到的行动之外,我们还认为有必要在许多这些挑战中拥有更多的专业知识。对于每个挑战,至少有一些具有深厚领域知识的人可以帮助我们更快地弄清楚它们的战略相关性,并且还可以弄清楚现在应该做些什么来做好准备(如果有的话)。
7.评估 链接到标题
我们在本文中涵盖了很多内容。以下是我们认为特别值得强调的一些要点。
尽管存在不确定性,也要做好准备 链接到标题
我们不能确定我们是否会在本世纪看到智能爆炸。扩展时代可能会结束,算法进步可能会放缓,深度学习最终可能“仅仅”像个人计算机或互联网等其他技术进步一样重要。
但是我们认为在本世纪发生智能爆炸的可能性大于可能性,并且很可能在十年内开始。更重要的是,我们可以做的许多准备工作在不需要时成本都很低,176 这样即使智能爆炸永远不会发生,我们也不会损失太多;而如果它确实发生了,那么提前准备将是非常值得的。我们不应该屈服于证据困境:177 如果我们等到我们确定智能爆炸的可能性,那么那时准备就太晚了。当你看到厨房门下冒出烟雾时,购买房屋保险为时已晚。
不仅仅是对齐问题 链接到标题
在那些认真对待智能爆炸的人中,迄今为止的讨论主要集中在一些关键风险上,例如对未对齐的 AI 失去控制以及防止生物武器造成的灾难。这些是非常重要的挑战,但仍然没有得到足够的重视。但它们并不是智能爆炸会产生的唯一挑战,如果我们应该完全专注于它们,那将是令人惊讶的。
此外,我们面临的许多挑战都不是“关于” AI 的。工业革命带来的大多数挑战都不是关于蒸汽机或纺织机的。同样,关于太空治理、全球治理、导弹防御和核武器的挑战并不是直接关于如何设计、构建和部署 AI 本身的问题。相反,AI 加速并重新排序了这些挑战到来的速度,迫使我们在一个以令人困惑的速度变化的世界中面对它们。
这些挑战还将以与决策相关的方式相互作用。例如,一些人认为将 AGI 开发整合到一个项目中可以减少在安全性方面偷工减料的竞争压力。但这可能会增加人类权力集中带来的风险。同样,赋予数字人权利可能会减少他们强行夺取权力的动机,但也可能会限制我们可以使用的对齐技术。专注于一个孤立的问题,就好像它是唯一重要的问题一样,可能会使事情变得更糟。
不要将所有问题都推给超级智能 链接到标题
一个诱人的计划是确保超级智能 AI 对齐,然后依靠它来解决我们的其他问题。这在许多情况下确实有意义。但并非总是如此:一些挑战会在超级智能可以提供帮助之前出现,并且一些解决方案需要提前开始,例如那些仅当我们仍然处于关于谁将在 AGI 之后获得权力的“无知之幕”之后存在的问题。而且,通常,最重要的是确保超级智能实际上以有益的方式使用,并尽可能快地使用。
准备好适应 链接到标题
1925 年的决策者无法准确预测一个世纪的技术发展将带来的挑战。我们应该对我们识别在智能爆炸期间最重要的事情的能力抱有类似的谦逊。
这并不意味着我们无法做好准备,但它表明我们应该倾向于两种准备:跨领域的措施,以改善许多领域的决策,以及在许多可能的未来中似乎都非常有效的定向干预。我们还应该构建可以处理我们甚至尚未设想的挑战的系统和机构。
此外,鉴于我们在智能爆炸过程中应该期待多少变化和惊喜,我们应该准备好灵活地,也许会戏剧性地改变我们的想法,即使是在非常基本的方式上也是如此。这意味着我们应该避免简单化、不妥协的世界观,这些世界观坚持根据预先确定的叙述来解释新的发展。

8. 结论 链接到标题
目前,AI 模型的有效认知劳动力每年增长超过 20 倍。
即使改进速度减慢一半,AI 系统在技术进步方面的贡献仍然可以超过所有人类研究人员,然后在十年内再增长一百万倍的人类研究人员当量。为了像往常一样进行业务,那么当前在预训练效率、后训练增强、扩展训练运行和推理计算方面的趋势必须有效地停止。
而且进步可能会加速。最好的模型可以成为 AI 研究人员本身,将多年的算法效率提升转化为短短几个月。无论哪种方式,最强大的 AI 模型都将超越最聪明的人类,然后是更大的人类群体,并且各种 AI 系统将遍布社会的数千个利基市场,遍布数十亿个实例:这是一场智能爆炸。
用 Anthropic 首席执行官 Dario Amodei 的话说,智能爆炸可能会产生“数据中心里的天才之国”,在不到十年的时间里推动一个世纪的技术进步。物理行业也是如此,在物理行业中,人类再次是更快增长的主要瓶颈。我们应该想象整个行业——由在黑暗中工作的机器人组成的自动化工厂网络——以越来越快的速度扩张。
十年内的一个世纪的技术进步将带来一个世纪的挑战,每个挑战都代表着人类旅程中的一个岔路口。一个挑战是我们完全失去对 AI 的控制的可能性,因为它会密谋反对我们并夺取权力。但还有许多其他挑战。人类可能会指示 AI 帮助他们夺取权力,或者支持 AI 的监视和自动化军队可能会让独裁政权无限期地巩固其政权。我们可能会发现能够以远低于防御的成本实现破坏的技术,看到争夺外星资源的竞赛,并面对与值得道德地位的数字人共存的问题。而且,对于许多挑战,我们不能仅仅希望将它们推给未来的 AI 系统。
因此,我们应该立即开始为这些挑战做准备。我们可以为数字人和空间治理设计更好的规范和政策;建立远见能力;提高政府机构的响应能力和技术素养等等。更广泛的重大挑战看起来令人担忧地被忽视了。
许多人都值得赞扬地专注于为一个单一挑战做准备,例如未对齐的 AI 接管、AI 错误信息或加速 AI 的经济利益。但是专注于一个挑战与忽略所有其他挑战是不一样的:如果你是 AI 领域的单一问题选民,那么你可能在犯一个错误。我们应该认真对待智能爆炸将带来的所有挑战,对新的和被忽视的挑战持开放态度,并意识到所有这些挑战都可能以与行动相关的方式且经常以令人困惑的方式相互作用。
因此,智能爆炸不仅需要准备,还需要谦逊:清楚地了解即将发生的事情的规模以及我们预测它的能力的局限性。现在认真准备可能意味着赋予人类权力的智能爆炸和压倒人类的智能爆炸之间的区别。未来正以超出我们预期的速度逼近,我们进行深思熟虑的准备的时间可能很短暂。

参考文献 链接到标题
Acemoglu, Daron。『制度、技术与繁荣』。SSRN 学术论文。纽约州罗切斯特:社会科学研究网络,2025 年 2 月 1 日。https://doi.org/10.2139/ssrn.5130534。
Acemoglu, Daron 和 James A. Robinson。《独裁与民主的经济起源》。剑桥:剑桥大学出版社,2005。https://doi.org/10.1017/CBO9780511510809。
Adamala, Katarzyna、Deepa Agashe、Damon Binder、Yizhi Cai、Vaughn Cooper、Ryan Duncombe、Kevin Esvelt 等人。《关于镜像细菌的技术报告:可行性和风险》,2024 年。https://doi.org/10.25740/cv716pj4036。
Adamala, Katarzyna P.、Deepa Agashe、Yasmine Belkaid、Daniela Matias de C. Bittencourt、Yizhi Cai、Matthew W. Chang、Irene A. Chen 等人。《面对镜像生命的风险》。《科学》386, no. 6728(2024 年 12 月 20 日):1351–53。https://doi.org/10.1126/science.ads9158。
AI 文摘。“AI 的改进速度有多快?”访问于 2025 年 3 月 6 日。https://theaidigest.org/progress-and-dangers。
Allison, Graham T.“注定要开战?”《国家利益》, no. 149 (2017): 9–21。
Arai, Ryoichi。“人工蛋白质和复合物的分层设计,以实现合成结构生物学。”《生物物理学评论》10, no. 2(2017 年 12 月 14 日):391–410。https://doi.org/10.1007/s12551-017-0376-1。
Arb Research.“对三大预测性能的评分:阿西莫夫、克拉克和海因莱因作为预测者”,2023 年 6 月。https://arbresearch.com/files/big_three.pdf。 Armstrong, Stuart, 和 Anders Sandberg。“六小时内的永恒:智能生命在星系间的传播与费米悖论的加剧”。宇航学报 89 (2013年8月): 1–13。 https://doi.org/10.1016/j.actaastro.2013.04.002.
Aschenbrenner, Leopold。“超对齐问题”。情境意识 (博客), 2024年5月29日。 https://situational-awareness.ai/superalignment/#The_problem.
Bales, Adam。“反对自愿奴役:高级人工智能伦理中的自主性 - Adam Bales”。全球优先研究所 (博客), 2024年10月28日。 https://globalprioritiesinstitute.org/against-willing-servitude-autonomy-in-the-ethics-of-advanced-artificial-intelligence-adam-bales/.
Barnes, Beth。“关于人工智能与未来期望价值之间互动的思考”,2021年12月7日。 https://www.alignmentforum.org/posts/Dr3owdPqEAFK4pq8S/considerations-on-interaction-between-ai-and-expected-value.
———。“来自人工智能说服的风险”,2021年12月24日。 https://www.alignmentforum.org/posts/5cWtwATHL6KyzChck/risks-from-ai-persuasion.
Beraja, Martin, Andrew Kao, David Y Yang, 和 Noam Yuchtman。“AI-Tocracy*”。经济学季刊 138, no. 3 (2023年8月1日): 1349–1402。 https://doi.org/10.1093/qje/qjad012.
Bostrom, Nick。“关键思考与明智的慈善事业”,2017年3月17日。 https://www.stafforini.com/blog/bostrom/.
Boudry, Maarten, 和 Steije Hofhuis。“关于认知黑洞。自封闭信念系统如何发展和演变”。预印本,2023年4月26日。 https://philsci-archive.pitt.edu/22382/.
Brannon, Valerie C, 和 Eric N Holmes。“第230条:概述”,无日期。
“破解reCAPTCHAv2”。访问于 2025年2月21日。 https://arxiv.org/html/2409.08831v1.
Buterin, Vitalik。“我对社区笔记有什么看法?”,2023年8月16日。 https://vitalik.eth.limo/general/2023/08/16/communitynotes.html
Carlsmith, Joe。“策划中的人工智能:人工智能是否会在训练期间伪装对齐以获得权力?” arXiv, 2023年11月27日。 https://doi.org/10.48550/arXiv.2311.08379.
Carlsmith, Joseph。“寻求权力的人工智能是一种生存风险吗?” arXiv, 2024年8月13日。 https://doi.org/10.48550/arXiv.2206.13353.
人工智能安全中心。“关于人工智能风险的声明”,2023年5月30日。 https://www.safe.ai/work/statement-on-ai-risk.
Chan, Alan。“对齐是不够的”。Substack 时事通讯。Alan’s Substack (博客), 2023年1月11日。 https://coordination.substack.com/p/alignment-is-not-enough.
Chan, Alan, Kevin Wei, Sihao Huang, Nitarshan Rajkumar, Elija Perrier, Seth Lazar, Gillian K. Hadfield, 和 Markus Anderljung。“人工智能代理的基础设施”。arXiv, 2025年1月17日。 https://doi.org/10.48550/arXiv.2501.10114.
外层空间和平利用委员会。“第四次外空会议 - 外层空间事务厅的非文件”。外层空间事务厅。访问于 2025年3月8日。 https://www.unoosa.org/documents/pdf/copuos/2024/np/UNISPACE-IV-Non-Paper-by-the-Office-for-Outer-Space-AffairsE.pdf.
“社区笔记提高了社交媒体上事实核查的信任度 | PNAS Nexus | 牛津学术”。访问于 2025年2月9日。 https://academic.oup.com/pnasnexus/article/3/7/pgae217/7686087.
Constâncio, Alex Sebastião, Denise Fukumi Tsunoda, Helena de Fátima Nunes Silva, Jocelaine Martins da Silveira, 和 Deborah Ribeiro Carvalho。“使用机器学习的欺骗检测:系统回顾与统计分析”。PLOS ONE 18, no. 2 (2023年2月9日): e0281323。 https://doi.org/10.1371/journal.pone.0281323.
Costello, Thomas H., Gordon Pennycook, 和 David Rand。“只是事实:与人工智能的对话如何减少阴谋论的信念”。OSF, 2025年2月17日。 https://doi.org/10.31234/osf.io/h7n8u_v1.
Costello, Thomas H., Gordon Pennycook, 和 David G. Rand。“通过与人工智能的对话持久地减少阴谋论的信念”。科学, 2024年9月13日。 https://doi.org/10.1126/science.adq1814.
Cotra, Ajeya。“如果没有具体的对策,通往变革性人工智能的最简单路径可能导致人工智能接管”,2022年7月18日。 https://www.alignmentforum.org/posts/pRkFkzwKZ2zfa3R6H/without-specific-countermeasures-the-easiest-path-to.
Cotton-Barratt, Owen。“人工智能崛起与核战争”。Substack 时事通讯。奇怪的城市 (博客), 2024年6月11日。 https://strangecities.substack.com/p/ai-takeoff-and-nuclear-war.
Dafoe, Allan, 和 Ben Garfinkel。“攻防平衡如何衡量?| GovAI”。访问于 2025年2月7日。 https://www.governance.ai/research-paper/how-does-the-offense-defense-balance-scale.
Dafoe, Allan, Edward Hughes, Yoram Bachrach, Tantum Collins, Kevin R. McKee, Joel Z. Leibo, Kate Larson, 和 Thore Graepel。“合作人工智能中的开放问题”。arXiv, 2020年12月15日。 https://doi.org/10.48550/arXiv.2012.08630.
Davidson, Tom, Lukas Finnveden, 和 Rose Hadshar。‘人工智能赋能的政变:少数群体如何利用人工智能夺取权力’, 2025.
Drexler, Eric。“人工智能已经解开了生成纳米技术的进步”。Substack 时事通讯。人工智能前景:迈向全球目标对齐 (博客), 2024年3月31日。 https://aiprospects.substack.com/p/ai-has-unblocked-progress-toward.
———。“没有反乌托邦的安全:结构化透明”。Substack 时事通讯。人工智能前景:迈向全球目标对齐 (博客), 2024年7月25日。 https://aiprospects.substack.com/p/security-without-dystopia-new-options.
Drexler, K. Eric. 纳米系统:分子机器、制造和计算。John Wiley & Sons, Inc., 1992。 https://dl.acm.org/doi/abs/10.5555/135735.
Epoch AI。“人工智能基准测试仪表板”。Epoch AI, 2024年11月27日。 https://epoch.ai/data/ai-benchmarking-dashboard.
Evans, Owain, Owen Cotton-Barratt, Lukas Finnveden, Adam Bales, Avital Balwit, Peter Wills, Luca Righetti, 和 William Saunders。“诚实的人工智能:开发和治理不撒谎的人工智能”。arXiv, 2021年10月13日。 https://doi.org/10.48550/arXiv.2110.06674.
Feldstein, Steven。“人工智能监控的全球扩张”。卡内基国际和平基金会。访问于 2025年2月7日。 https://carnegieendowment.org/research/2019/09/the-global-expansion-of-ai-surveillance?lang=en.
Frankish, Keith。“作为意识理论的错觉主义”。意识研究杂志 23, no. 11–12 (2016): 11–39.
Gans, Joshua, Andrew Leigh, Martin Schmalz, 和 Adam Triggs。“不平等与市场集中度,当股权比消费更偏斜时”。牛津经济政策评论 35, no. 3 (2019年7月11日): 550–63。 https://doi.org/10.1093/oxrep/grz011.
Goldstein, Josh A, Jason Chao, Shelby Grossman, Alex Stamos, 和 Michael Tomz。“人工智能生成的宣传有多大说服力?”PNAS Nexus 3, no. 2 (2024年2月1日): pgae034。 https://doi.org/10.1093/pnasnexus/pgae034.
Grace, Katja, Harlan Stewart, Julia Fabienne Sandkühler, Stephen Thomas, Ben Weinstein-Raun, 和 Jan Brauner。“数千名人工智能作者论人工智能的未来”。arXiv, 2024年4月30日。 https://doi.org/10.48550/arXiv.2401.02843.
Greenblatt, Ryan, Carson Denison, Benjamin Wright, Fabien Roger, Monte MacDiarmid, Sam Marks, Johannes Treutlein, 等。“大型语言模型中的对齐伪装”。arXiv, 2024年12月20日。 https://doi.org/10.48550/arXiv.2412.14093.
Hackenburg, Kobi, Ben M. Tappin, Paul Röttger, Scott Hale, Jonathan Bright, 和 Helen Margetts。“大型语言模型政治说服的对数缩放定律的证据”。arXiv, 2024年6月20日。 https://doi.org/10.48550/arXiv.2406.14508.
Hutchison, Clyde A., Ray-Yuan Chuang, Vladimir N. Noskov, Nacyra Assad-Garcia, Thomas J. Deerinck, Mark H. Ellisman, John Gill, 等。“最小细菌基因组的设计与合成”。科学 351, no. 6280 (2016年3月25日): aad6253。 https://doi.org/10.1126/science.aad6253.
Jonathan D., Grinstein。“漫长而曲折的道路:高需求下的按需 DNA 合成”。GEN - 遗传工程与生物技术新闻, 2023年7月27日。 https://www.genengnews.com/topics/genome-editing/the-long-and-winding-road-on-demand-dna-synthesis-in-high-demand/.
Jones, Charles I.“经济增长的过去和未来:一个半内生视角”,2022。 https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4201147.
Kahan, Dan M., Ellen Peters, Erica Cantrell Dawson, 和 Paul Slovic。“有动机的计算能力和开明的自治”。行为公共政策 1, no. 1 (2017年5月): 54–86。 https://doi.org/10.1017/bpp.2016.2.
Karger, Ezra, Houtan Bastani, Chen Yueh-Han, Zachary Jacobs, Danny Halawi, Fred Zhang, 和 Philip E. Tetlock。“ForecastBench:人工智能预测能力的动态基准”。arXiv, 2025年1月6日。 https://doi.org/10.48550/arXiv.2409.19839.
Karnofsky, Holden。“人工智能风险降低的 If-Then 承诺”。卡内基国际和平基金会。访问于 2025年3月5日。 https://carnegieendowment.org/research/2024/09/if-then-commitments-for-ai-risk-reduction?lang=en.
Kim, Suhan, Yi-Hsuan Hsiao, Zhijian Ren, Jiashu Huang, 和 Yufeng Chen。“昆虫规模上的杂技:一种耐用、精确且敏捷的微型飞行机器人”。科学机器人 10, no. 98 (2025年1月15日): eadp4256。 https://doi.org/10.1126/scirobotics.adp4256.
Kulveit, Jan, Raymond Douglas, Nora Ammann, Deger Turan, David Krueger, 和 David Duvenaud。“逐步剥夺权力:人工智能渐进式发展带来的系统性生存风险”。arXiv, 2025年1月29日。 https://doi.org/10.48550/arXiv.2501.16946.
Morris, Meredith Ringel, Jascha Sohl-dickstein, Noah Fiedel, Tris Warkentin, Allan Dafoe, Aleksandra Faust, Clement Farabet, 和 Shane Legg。“用于操作化通往 AGI 路径上的进展的 AGI 等级”。arXiv, 2024年6月5日。 https://doi.org/10.48550/arXiv.2311.02462.
Ngo, Richard, Lawrence Chan, 和 Sören Mindermann。“从深度学习的角度看对齐问题”。arXiv, 2024年3月19日。 https://doi.org/10.48550/arXiv.2209.00626.
Nyhan, Brendan, 和 Jason Reifler。“当修正失败时:政治错误认知的持续存在”。政治行为 32, no. 2 (2010年6月): 303–30。 https://doi.org/10.1007/s11109-010-9112-2.
Ord, Toby. 悬崖:生存风险与人类的未来。纽约:Hachette Books, 2020。
我们的世界数据。“首次打击中可投放的核武器的估计爆炸威力”。访问于 2025年2月7日。 https://ourworldindata.org/grapher/estimated-megatons-of-nuclear-weapons-deliverable-in-first-strike.
Owen, David。“语言模型基准表现的可预测性如何?” Epoch AI, 2023年6月9日。 https://epoch.ai/blog/how-predictable-is-language-model-benchmark-performance.
Rethink Priorities。“美国-俄罗斯核交换造成的核冬天会有多糟糕?”,2019年6月20日。 https://rethinkpriorities.org/research-area/how-bad-would-nuclear-winter-caused-by-a-us-russia-nuclear-exchange-be/.
Rose, E. M. 诺维奇的威廉谋杀案:中世纪欧洲血祭诽谤的起源。牛津,纽约:牛津大学出版社,2018。
Schelling, Thomas. Thomas C. Schelling 的冲突策略, 1960。
Schumann, Anna。“核三位一体(概况介绍)”。军备控制和不扩散中心,2021年1月21日。 https://armscontrolcenter.org/factsheet-the-nuclear-triad/.
Shavit, Yonadav, Sandhini Agarwal, Miles Brundage, Steven Adler, Cullen O’Keefe, Rosie Campbell, Teddy Lee, 等。“治理智能体人工智能系统的实践”,无日期。
Solem, J.“微型机器人在战争中的应用”。洛斯阿拉莫斯国家实验室。(LANL), 洛斯阿拉莫斯, NM (美国), 1996年9月1日。 https://doi.org/10.2172/369704.
“人工智能对战略稳定和核风险的影响”。SIPRI, 2019年5月。 https://www.sipri.org/publications/2019/research-reports/impact-artificial-intelligence-strategic-stability-and-nuclear-risk-volume-i-euro-atlantic.
Thierer, Adam。“步调问题与技术监管的未来”,2018年8月8日。 https://www.mercatus.org/economic-insights/expert-commentary/pacing-problem-and-future-technology-regulation.
Trager, Robert, 和 Nicholas Emery。“高级人工智能竞赛中的信息危害 | GovAI”。访问于 2025年2月8日。 https://www.governance.ai/research-paper/information-hazards-in-races-for-advanced-artificial-intelligence.
Trask, Andrew, Emma Bluemke, Teddy Collins, Ben Garfinkel Eric Drexler, Claudia Ghezzou Cuervas-Mons, Iason Gabriel, Allan Dafoe, 和 William Isaac。“通过结构化透明超越隐私权衡”。arXiv, 2024年3月12日。 https://doi.org/10.48550/arXiv.2012.08347.
联合国外层空间事务厅。“外层空间条约”,1966。 https://www.unoosa.org/oosa/en/ourwork/spacelaw/treaties/introouterspacetreaty.html.
Williams, Dan。“对错误信息的关注导致对人们为何相信和基于不良信息采取行动的深刻误解”。社会科学的影响 (博客), 2022年9月5日。 https://blogs.lse.ac.uk/impactofsocialsciences/2022/09/05/the-focus-on-misinformation-leads-to-a-profound-misunderstanding-of-why-people-believe-and-act-on-bad-information/.
Williams, Daniel。“糟糕的信念:为什么它们会发生在高度聪明、警惕、狡猾、自欺欺人、联盟的猿类身上”。哲学心理学, 2023年5月19日。 https://www.tandfonline.com/doi/abs/10.1080/09515089.2023.2186844.
Yudkowsky, Eliezer。“实现有价值的未来需要复杂的价值体系”,2011。 https://intelligence.org/files/ComplexValues.pdf.
脚注 跳转链接

引用
1
预测平台 Metaculus 提出了一个问题,题为“第一个通用人工智能系统何时被设计、测试和公开宣布?”,它在一系列认知和机器人测试中进行了操作,包括“可靠地通过一个 2 小时的对抗性图灵测试,在该测试中,参与者可以在对话过程中发送文本、图像和音频文件(就像在普通的短信应用中那样)”。截至2025年2月5日,社区预测(所有预测的近期加权中位数)是 2030年中期。↩
2
AI Digest,‘人工智能发展有多快?’ ↩
3
Epoch AI,‘人工智能基准测试仪表板’。这是 “GPQA” 基准。“博士级专家”指的是正在攻读或已完成生物、物理和化学博士课程的人。问题仅限于这些领域,由从在线自由职业平台雇佣的61位博士级专家设计。超过74%的问题都有无争议的正确答案。正确答案由与其他专家的协议确定。↩
4
Yudkowsky,‘实现有价值的未来需要复杂的价值体系’。,Barnes,‘关于人工智能和未来预期价值之间互动的思考’。↩
5
有关人工智能对齐的更多讨论,请参见Ngo 等人。(2021)和Carlsmith (2024,2025).↩
6
通过“AGI”,我们打算遵循 Morris 等人中给出的“专家 AGI”的定义,“用于操作化通往 AGI 路径上的进展的AGI 等级”,这是在“广泛的非身体任务,包括学习新技能等元认知任务”中,表现超过“至少90%的熟练成年人”。↩
7
我们也不想暗示“人工智能治理”领域迄今为止只关注错位风险(见这个研究议程作为说明)。↩
8
我们有时会将其称为“技术进步”:以非常广泛的意义使用该术语,指的是新技术、工程壮举、科学突破和其他智力进步。↩
9
(1930年代的任何四年期间。↩
10
例如,据报道,美国 COVID 疫苗的推出因 FDA 进度缓慢而推迟,尽管已努力加快进度。 除此之外,旨在授予辉瑞-BioNTech 疫苗紧急使用授权的关键会议几乎在第 3 阶段试验结果公布后一个月才举行 —— 可能是因为,正如 FDA 网站解释的那样,FDA“需要在联邦公报中至少在会议日期前 15 个日历日发布咨询委员会会议的公告”。↩
11
十年内的一个世纪可能被轻描淡写了。如果是这样,那么更适合考虑上个千年中最有影响力的智力发展:自然选择进化论、无神论、自由主义、民主、废奴主义、女权主义、普遍世俗人权、新教、有限责任公司、资本主义、国家社会主义和共产主义,以及像印刷机、蒸汽机、微积分、运动定律和科学方法本身一样重要的突破。↩ Sevilla, 《前沿AI模型的训练计算每年增长4-5倍》。 请注意,这些数字来自官方和非正式估计的混合,而不确定的非正式估计在最近最大的训练运行中占主导地位:Epoch.ai对2022-2024年趋势的90%置信区间跨越了1.5倍-11.8倍的年增长率。 这种最近的估计可能部分受到其他估计趋势的影响,例如训练运行中的效率增益率。↩
13
Ho等人,《语言模型中的算法进步》(‘Algorithmic Progress in Language Models’)。 另见Erdil和Besiroglu,《计算机视觉中的算法进步》(‘Algorithmic Progress in Computer Vision’)。 请注意,本文侧重于历史改进,并未详细讨论应如何推断它们。↩
14
Davidson等人,《无需昂贵的重新训练即可显着提高AI能力》(‘AI Capabilities Can Be Significantly Improved without Expensive Retraining’)。 请注意,此处研究的几乎所有训练后增强功能都来自于2022-2023年,这表明我们拥有的关于训练后增强功能的长期历史数据较少。↩
15
OpenAI,《使用LLM进行推理的学习》(‘Learning to Reason with LLMs’)。↩
16
Anthropic,《负责任的扩展政策》(‘Responsible Scaling Policy’)。(p.16)↩
17
请注意,这是基于规模(计算)和效率(算法进步)增加带来的预期边际贡献,因为训练的输入是互补的; 因此,我们无法直接从仅一个维度上的收益推断出许多数量级的性能。 有关方法论的讨论,请参见Erdil和Besiroglu,《计算机视觉中的算法进步》(‘Algorithmic Progress in Computer Vision’)。↩
18
Owen,《语言模型基准性能的可预测性如何?》(‘How Predictable Is Language Model Benchmark Performance?’)。↩
19
研究机构Epoch AI估计GPT-2(1.5B)和GPT-4的训练计算分别为1.9E21和2.1E25; 得出大约10,000倍的放大倍数,后者的90%置信区间跨越大约5倍(Epoch AI,《AI基准测试仪表板》(‘AI Benchmarking Dashboard’.)) 假设预训练算法效率每年提高3倍的中心估计值,并假设改进了4年,则有效计算量进一步提高了约80倍。 但这可能略有高估,因为(i)GPT-3似乎没有在GPT-2上进行重大的算法创新(Brown等人,《语言模型是少样本学习器》(‘Language Models Are Few-Shot Learners’.); 以及(ii)据报道,GPT-4在2022年8月完成了训练,锁定了预训练效率的提升机会(OpenAI等人,《GPT-4技术报告》(‘GPT-4 Technical Report’.)) 因此,GPT-2和GPT-4之间预训练算法效率的提高可能达到了5-50倍,因此GPT-2和GPT-4之间有效训练计算量的增加可能介于10510^5105和10610^6106之间。↩
20
大多数训练后增强是在GPT-3和GPT-4之间进行的。 最值得注意的是,GPT-3.5系列及更高版本经过优化,成为会话助手,使用了来自人类反馈的强化学习和其他方法(Christiano等人,《来自人类偏好的深度强化学习》(‘Deep Reinforcement Learning from Human Preferences’); Ouyang等人,《训练语言模型以通过人类反馈遵循指令》(‘Training Language Models to Follow Instructions with Human Feedback’))。 由于GPT-3于2020年5月发布,比GPT-4早约2.75年,Anthropic对训练后增强每年提高3倍的非正式估计表明,在所有因素考虑在内的情况下,有效计算量大约会进一步提高20倍,但存在很大的不确定性。↩
21
OpenAI的text-davinci-003 175B模型于2022年11月下旬发布,在MMLU(5-shot)上获得了64.8分(Chung等人,《扩展指令微调语言模型》(‘Scaling Instruction-Finetuned Language Models’))。 Llama 3.1 8B于2023年7月下旬发布,在MMLU上获得了73.0分(Grattafiori等人,《Llama 3模型集群》(‘The Llama 3 Herd of Models’))。 openai.com/api/pricing的存档图片显示,推理成本为每1k个token(输入加输出token)0.02美元。 在撰写本文时,Llama 3.1 8B可以(使用云提供商Nebius)以每百万个输入token 0.02美元和每百万个输出token 0.06美元的价格运行。 早在2024年9月,推理成本为每百万个输入token 0.05美元,每百万个输出token 0.08美元。↩
22
Jones(2021)发现在一个简单的棋盘游戏中,训练时间和测试时间计算之间存在大致线性的权衡:“对于每次额外增加10倍的训练时间计算,可以消除大约15倍的测试时间计算”。 在使用更多训练通过训练具有较小参数计数的语言模型来提高效率的背景下,我们预计训练效率的增长速度将是运行时效率的两倍(以对数计算)。 比较使用与GPT-3相似的训练计算量的模型,Hoffman等人(2022)发现,最好在固定的训练计算预算下大致相等地扩展训练数据和参数计数。 因此,可以通过将参数计数减少XXX倍来使语言模型的效率提高约XXX倍,但这会将训练效率提高X2X^2X2倍(因为训练计算与数据和参数计数成比例地缩放,而数据和参数计数都在以相同的因子减少)。 因此,运行时效率提高2倍将需要有效训练计算量增加4倍。 参见Jones,《用棋盘游戏扩展缩放定律》(‘Scaling Scaling Laws with Board Games’),Hoffmann等人,《训练计算最优的大型语言模型》(‘Training Compute-Optimal Large Language Models’)。↩
23
自2019年以来,部署的加速器FLOP/s总数(来自NVIDIA芯片)每年增长约2.3倍(Frymire和Owen,《计算能力储备》(‘The Stock of Computing Power’.)) 这不包括谷歌的TPU芯片、用于推理的旧芯片或专门用于个人电脑和手机推理的新芯片。 请注意,我们在此处计算内部推理(例如用于实验),因为某些加速器FLOP/s仅在内部部署。
推理计算和训练计算之间存在已知的权衡,因此推理计算和训练计算之间的最佳分配是一种平衡; 经验估计表明,除非用于训练以节省推理(反之亦然)的方法有效地耗尽,否则平衡大约是均匀的(Erdil,《在推理和训练之间优化分配计算》(‘Optimally Allocating Compute Between Inference and Training’))。 如果大型训练运行的频率没有改变,并且训练-推理平衡没有改变,这表明用于推理的计算量也以每年约2.3倍的速度增长,但存在很大的不确定性。
我们还可以注意到,主要AI公司的收入增长每年约2-3倍。 我们可以假设API成本包括硬件租赁成本的固定利润率,并注意到由于摩尔定律,每美元成本新GPU的计算(以FLOP/s为单位)的价格效率(在两年内摊销)每年提高约1.35倍(Hobbhahn,《机器学习硬件趋势》(‘Trends in Machine Learning Hardware’))。 这再次表明每年推理增加约2×1.35 = 2.7倍。 最近在推理扩展方面的进展,以及重新利用更广泛的芯片进行推理的能力,表明2.5倍略微低估了。↩
24
换句话说,如果我们将明年推理计算量的所有增长都用于运行更高效的模型,同时保持其功能不变,那么我们可以运行25倍的实例。↩
25
如果AI对整体认知研究成果的贡献相当于有效地使人类研究人员的数量翻倍,那么我们可以说AI和人类认知研究的总体努力是平等的。 因此,我们可以根据需要相同贡献的“有效远程工作人类研究人员”的等效数量来量化AI研究工作,而无需前沿AI。 我们可以说,如果从人类研究人员的角度衡量,AI的研究工作再次从这种人机平价点翻倍,那么AI的研究工作将进一步翻倍,依此类推。↩
26
也就是说,我们假设用于研究的推理比例大致保持不变,然后假设推理计算量的扩展用于运行更多实例,而不是扩展每个实例使用的推理计算量。↩
27
这假设AI研究工作(根据人类研究人员的等效认知贡献来定义)与AI研究人员的数量成比例地增加。 我们认为这是一个合理的假设,但在这方面存在分歧的余地。↩
28
最近的进展表明,预训练模型如何使用更多的串行推理计算来“推理”一条思路链(OpenAI,《使用LLM进行推理的学习》(‘Learning to Reason with LLMs’))。 但是也有更简单的方法,例如多样本上下文学习(Agarwal等人,《多样本上下文学习》(‘Many-Shot In-Context Learning’))MCTS方法,以及验证相对便宜的地方,只需进行多次尝试并选择最佳结果。 (Villalobos和Atkinson(2023))得出的结论是,在最佳推理-训练平衡下,“我们预计每种技术都可以节省大约1个数量级(OOM)的训练或推理计算量,以换取将另一个因素增加略多于1个OOM。”(Villalobos,《权衡训练和推理中的计算》(‘Trading Off Compute in Training and Inference’))。↩
29
这里最明显的衡量标准是各个领域的引用分布,尽管我们还可以注意到AI等领域杰出研究人员的高薪。 更多信息,请参见‘[EA论坛] 人们之间的表现差异有多大?’。
我们还可以只看一些轶事,说明能力的提高如何等同于人数的大量倍增。 例如:1999年,当时最强大的国际象棋棋手——加里·Casper罗夫——与“世界”下了一盘国际象棋,其中四位世界级的国际象棋棋手提出了移动选项,数万名参与者分析并投票选出他们的回应。 Casper罗夫赢了。↩
30
训练后增强带来的每年3倍的有效计算量增长使有效训练计算量的增长达到每年30倍,从而使AI研究工作的增长率达到75倍。 但是,升级模型能力通常比以更高的计算效率运行相同能力获得的收益要大得多。 这将使AI研究工作的增长率超过75倍。↩
31
Pilz、Mahmood和Heim,《指数增长下AI的电力需求》(‘AI’s Power Requirements Under Exponential Growth’)., Sevilla, 《到2030年,AI规模扩张能否继续?》↩
32
物理训练计算量目前每年增长4.5倍,训练中的算法效率每年提高约3倍。 因此,对于物理计算量每增加10倍,算法效率大约提高5.4倍(=3log(10)/log(4.5)= 3^{\log(10)/\log(4.5)}=3log(10)/log(4.5))。 物理计算量增加 10,000 倍是四个 10 倍的增加,从而使算法训练效率提高了 835 倍 ≈ 1000 倍。↩
33
Davidson、Hadshar和MacAskill,《智能爆炸的三种类型》(‘Three Types of Intelligence Explosion’)↩
34
考虑一下复印机。 第一台成功的商用普通纸复印机是施乐914,于1959年发布。 现在,研究人员可以复印文本,从而节省了去图书馆的时间,因此施乐914持久(即使微不足道)地加快了总体研究进度。 此外,速度的提高肯定会促进下一代复印机的研发,因为施乐员工现在可以更快地工作,依此类推。 因此,施乐914在技术上触发了复印机研发中的积极反馈回路,但几乎立即消失了,而不是导致复印机技术的爆炸性发展。↩
35
Erdil、Besiroglu和Ho,《估计想法产生》(‘Estimating Idea Production’)↩
36
Davidson、Hadshar和MacAskill,《一旦AI研究自动化,AI是否会加速发展?》(‘Once AI Research is Automated, Will AI Progress Accelerate?’)↩
37
Cotra(2021)估计,人类终身学习使用相当于大约102410^{24}1024 FLOP的计算量。 假设训练计算量继续以历史速度扩展,那么GPT-6将接受大约102910^{29}1029 FLOP的训练。 如果GPT-6与人类一样有能力,那么它的训练效率将比人类学习低100,000倍。 因此,从GPT-6开始的软件爆炸可能会跨越效率提高100,000倍的范围。
当然,软件反馈循环可能会在达到算法效率的绝对上限之前遇到收益递减。 但是,如果我们(例如)对平台位于所有可能的翻倍位置上的位置一无所知,那么绝对上限对于软件反馈循环将驱动的预期翻倍次数仍然是一个有用的指南。↩
38
人类是高效的学习者,但生物大脑可以实现的算法受到限制,我们无法直接与计算机工具交互。 例如,我们的大脑无法实现权重共享(Ott等人,《机器中的学习》(‘Learning in the Machine’))。 人类大脑似乎也严重不足。 如果AI系统中计算与训练数据之间的最佳权衡延续到大脑中,那么我们大脑的计算最优学习将涉及从比我们一生中所见到的多约10,000倍的数据中学习。 参见:Davidson、Hadshar和MacAskill,《在达到有效的物理极限之前,AI可以进步到什么程度?》(‘How Far Can AI Progress before Hitting Effective Physical Limits?’); Hoffmann等人,《训练计算最优的大型语言模型》(‘Training Compute-Optimal Large Language Models’)。
因此,对于大多数任务来说,在同等强大的硬件上运行的最佳学习和推理算法可能远远超过生物大脑效率的10倍。↩
39
Bloom等人,《想法是否越来越难找到?》(‘Are Ideas Getting Harder to Find?’)估计,有效的科研人员总供应量最多每年增长4%,尽管这种增长率最终受到人口增长的限制,目前约为1%并正在下降。 我们认为认知劳动(用于研究或其他用途)的边际增长与有效训练计算量(目前为每年10倍)和推理计算量(目前为每年2.5倍)的增长大致成正比,两者结合起来每年增长25倍。 25倍的增长比4%的增长快600倍。↩
40
这些模型包括DeepSeek的r1模型,据报道该模型使用的计算量比GPT-4少约4倍。(Epoch AI,《AI基准测试仪表板》(‘AI Benchmarking Dashboard’).)↩
41
OpenAI等人,《使用大型推理模型进行竞争性编程》(‘Competitive Programming with Large Reasoning Models’)。 在流行的竞争性编码网站Codeforces上,只有大约200名活跃用户的评分高于最佳AI编码员。 一位用户写道:“我知道它最终会超过我,但我没想到它会这么快发生——大约一年。 现在,我感到有点恐慌”。↩
42
这在OpenAI官方直播中提到,该直播宣布了o3和o3-mini,可在此处观看。
“在软件风格基准测试中,我们有SWE-Bench Verified,这是一个由真实软件任务组成的基准测试。 我们看到o3的准确率约为71.7%,比我们的o1模型高出20%以上。”↩
43
Wijk等人,《RE-Bench》(‘RE-Bench’)↩
44
METR,《量化AI完成更长任务能力中的指数增长》(即将发布)(‘Quantifying the Exponential Growth in AI Ability to Complete Longer Tasks’ (forthcoming)). 另请参见Pimpale等人,《预测前沿语言模型代理能力》(‘Forecasting Frontier Language Model Agent Capabilities’).↩
45
Owen,《采访AI研究人员关于AI研发的自动化》(‘Interviewing AI Researchers on Automation of AI R&D’).↩
46
AI文摘,《AI的进步有多快?》(‘How Fast Is AI Improving?’)↩
47
按照目前的进步速度,这样的飞跃只需要四年多一点的时间。 请记住有效训练计算量每年增加30倍的估计值,其中包括训练后增强。 如前所述,GPT-2和GPT-4之间的有效训练计算量差距最多为一百万倍。 以此速度,有效计算量的进一步百万分之一的飞跃只需要四年多一点的时间。↩
48
在撰写本文时,GPT-5尚未发布,但已发布的最佳模型在发布时在质量上大约是GPT-4之上的半个GPT差距。↩
51
Ayan、Haak和Ginther,《世界上有多少人从事研发?》(‘How Many People in the World Do Research and Development?’)↩
52
Jumper等人,《使用AlphaFold进行高精度蛋白质结构预测》(‘Highly Accurate Protein Structure Prediction with AlphaFold’)., Yang等人,《AlphaFold2及其在生物学和医学领域的应用》(‘AlphaFold2 and Its Applications in the Fields of Biology and Medicine’).↩
53
请注意,AlphaFold并未完全解决预测给定蛋白质的生物学特性并解释其折叠方式的问题。 它主要输出最终的蛋白质结构预测,这些预测也可以通过让蛋白质进行实验性折叠并分析结果来确定。 与AlphaFold不同,实验方法还可以对侧配体和其他对药物功能和实际应用至关重要的特性进行更精细的分析。 考虑到所有这些警告,按照目前的速度估计,实验方法需要80年和3000亿研究小时才能输出AlphaFold一年所做的事情。 此外,随着研究人员弄清楚如何使用和改进它,AlphaFold的最大贡献可能仍然在未来。↩
54
有关支持模型,请参见Jones,《经济增长的过去和未来》(‘The Past and Future of Economic Growth’); Kremer,《人口增长和技术变革》(‘Population Growth and Technological Change’). 有关启发性的经验发现,请参见Moser、Voena和Waldinger,《德国犹太移民和美国发明》(‘German Jewish Émigrés and US Invention’); Borjas和Doran,《美国数学家的生产力》(‘Productivity of American Mathematicians’).↩
55
最明显的解释是,我们首先找到容易找到的想法,因此剩下的想法更难找到。 Bloom等人估计,在1930年至2020年之间,全球“有效研究人员数量”的衡量标准增加了约20倍,而技术进步的速度大致保持不变。(Bloom等人,《想法是否越来越难找到?》(‘Are Ideas Getting Harder to Find?’)↩
56
最明显的原因是,当同一时间的研究人员数量增加时,研究人员更有可能意外地重复彼此的工作。 很难估计这种效应的大小,但一个保守的估计表明,一年内将研究工作增加100倍相当于在同一年内将研究速度(仅)提高约30倍。 因此,为了在十年内获得另外100年的技术进步,该十年内的平均研究工作需要远远超过当前水平的10倍。
在以下想法生成函数中:A˙tAt=αStλAt−β\frac{\dot{A}_t}{A_t} = \alpha S_t^{\lambda} A_t^{-\beta}AtA˙t=αStλAt−β,这对应于λ=0.75\lambda = 0.75λ=0.75。 Bloom等人使用了这个值,Jones和Williams提供了一些证据表明λ>0.5\lambda > 0.5λ>0.5。(Jones和Williams,《好东西太多了吗?》(‘Too Much of a Good Thing?’))
Ekerdt和Wu(2024)认为,大约一半似乎是“踩脚趾”效应实际上是由于研究人员的平均能力下降,因为最高能力的潜在研究人员首先自我选择进入研究,并且从事研究的人的比例有所增长。 这表明AI研究人员的λ\lambdaλ将更接近1(因为没有理由认为其他AI研究人员的能力会下降),因此AI带来的技术进步将比我们的估计更快。(‘resEW.Pdf’。)↩
57
Jones,《基于研发的经济增长模型》(‘R&D-Based Models of Economic Growth’); Kortum,《研究、专利和技术变革》(‘Research, Patenting, and Technological Change’); Segerstrom,《没有规模效应的内生增长》(‘Endogenous Growth without Scale Effects’).↩
58
我们可以通过分析来估计这一点。 同样,我们可以假设一个默认的稳态轨迹,正如我们所看到的,它由以下给出:
A˙tAt=αStλAt−β⇒ga=λgSβ⇒ga∝gS\frac{\dot{A}_t}{A_t} = \alpha S_t^{\lambda} A_t^{-\beta}\Rightarrow g_a = \frac{\lambda g_S}{\beta}\Rightarrow g_a \propto g_SAtA˙t=αStλAt−β⇒ga=βλgS⇒ga∝gS 假设,在默认路径下,研究人员的数量每年增长4%(推动1.25%的TFP增长,其中λ=34\lambda = \frac34λ=43,β=2.4\beta = 2.4β=2.4)。那么,技术进步速度提高10倍时,研究人员的稳态增长率就是默认稳态增长率的10倍,即每年40%。
但是,技术增长率收敛到λ×gS/β\lambda \times g_S \ / \betaλ×gS/β会存在一些延迟。StS_tSt的初始值可以提高101/λ10^{1/\lambda}101/λ倍(≈21.5x)(≈ 21.5 \text{x})(≈21.5x),以瞬间将技术进步的速度设置为默认水平的十倍,然后40%的增长将维持10倍加速技术进步的稳态10年。由此产生的超过原始人类研究供应的增加是101/λ×(1+(λ×gS/β))10≈21.5×140%10≈620x10^{1/\lambda} \times (1 + (\lambda \times g_S / β))^{10} \approx 21.5 \times 140\%^{10} ≈ 620\text{x}101/λ×(1+(λ×gS/β))10≈21.5×140%10≈620x。
那么,研究人员数量的平均增长率约为90%,尽管所需的真实增长率会略高,因为我们假设瞬时跳跃来预先加载研究。使用数值方法,我们可以确认所需的精确增长率确实在100%左右。↩
59
考虑这个创意生产函数:
A˙tAt=αStλAt−β\frac{\dot{A}_t}{A_t} = \alpha S_t^{\lambda} A_t^{-\beta}AtA˙t=αStλAt−β
其中AtA_tAt是技术水平,StS_tSt是研究人员的数量,α\alphaα是一个常数生产力参数,弹性系数λ\lambdaλ决定了研究生产力随着研究人员数量的增加而下降的速度,弹性系数β\betaβ决定了研究生产力随着技术水平的提高而下降的速度。Bloom等人估计,在1930-2015年期间,整个经济体的β=3.1\beta = 3.1β=3.1,假设没有“踩脚趾”效应(即假设λ=1\lambda = 1λ=1)。
那么,稳态增长率(即技术水平的增长是恒定的)由下式给出:
A˙tAt=ga=λgSβ\frac{\dot{A}_t}{A_t} = g_a = \frac{\lambda g_S}{\beta}AtA˙t=ga=βλgS
对整个经济体的λ\lambdaλ的估计很困难,因为很难将其与技术进步本身带来的收益递减(即β\betaβ)区分开来。我们遵循Bloom等人λ=34\lambda = \frac34λ=43的假设。引入λ=34\lambda = \frac34λ=43会导致对β\betaβ历史估计的向下修正,因为λ=34\lambda = \frac34λ=43表明,研究人员生产力下降的部分原因是研究人员数量的增加,因此,技术进步本身所占的比例相应较小。因此,对于λ=34\lambda = \frac34λ=43,Bloom等人将其对1930-2015年期间的β\betaβ的估计从3.1修正为2.4。
然后,我们使用λ=34\lambda = \frac34λ=43和β=2.4\beta = 2.4β=2.4来估计由于AI带来的有效研究人员数量更快增长而导致的技术进步速度。我们将“十年中的一个世纪”定义为一个世纪,在该世纪中,技术的进步速度等于研究人员数量继续以过去一个世纪的平均速度增长的平衡速度。Bloom等人估计,1930-2015年研究投入的平均增长率为每年4.3%,为简单起见,我们使用4%。我们假设,在研究人员增长4%(即TFP年增长率为1.25%)的稳态下,整个经济体的技术进步都在增长。
使用我们保守的估计,即在人机研究投入平价后的十年内,有效研究人员的数量增长了5倍,并且假设在人机平价之前对技术没有影响,那么我们(通过数值方法)发现,经过十年AI研究投入增长后,新的TFP水平约为该十年初水平的50倍,相当于默认(非AI)增长路径上300多年的技术进步。↩
60
一种建模方法是,想象一个快速增长的AI研究人员群体可以首先并行化更易于并行化的任务,从而使边际研究任务的并行性随着研究人员数量的增加而下降。最终,几乎没有什么有用的事情可以通过增加研究人员来完成;进步需要等待必须串行进行的实验。特别是,我们可以用gA=θln(S)g_A = \theta \ln(S)gA=θln(S)替换我们的创意生产函数——消除所有“捕捞殆尽”效应,但创意以对数方式累积,而不是以幂函数形式累积。定义SSS的单位,使得gAg_AgA相对于SSS的当前弹性为34\frac3443。然后我们发现将SSS乘以10710^7107会产生gA=0.196g_A = 0.196gA=0.196:略高于TFP增长率的十倍,即1.5%,这被认为是增长率提高了10倍,但足够接近,以至于情况似乎不再明确,尤其是在我们重新加入“捕捞殆尽”效应之后。这有点接近Young (1998)中的模型。感谢Phil Trammell提出的这一点(改述中的错误是我们的)。↩
61
也就是说,你不能直接从连续时间的平均进步速度推导出随时间推移的TFP进步,因为(例如)如果需求的价格弹性较低,生产力的提高可能会导致一个行业萎缩。↩
62
63
Zeni等人,'无机材料设计的生成模型'。↩
64
Muratore等人,'从随机模拟中学习的机器人';Torne等人,'通过模拟协调现实'。↩
65
Horton,'大型语言模型作为模拟经济主体'。↩
66
考虑Bostrom (2014): “我们远非可能存在的最聪明的生物物种,不如将我们视为能够启动技术文明的最愚蠢的生物物种——我们占据了这个生态位,因为我们首先到达那里,而不是因为我们以任何方式对其进行了优化适应。”
类似地:“人们可以推测,人类在许多哲学的“永恒问题”上的进步的迟缓和摇摆不定是由于人类大脑皮层不适合哲学工作。基于这种观点,我们最受赞誉的哲学家就像用后腿走路的狗——只是勉强达到了从事这项活动所需的最低水平。”(同上)↩
67
考虑到广义相对论是有史以来最令人印象深刻的概念进步之一,但爱因斯坦并非仅仅通过堆积实证数据来发展它。相反,他结合了对相关数学的深刻理解、多年来专注于同一问题的意愿,以及从思想实验中获得的创造力,就像从物理实验中获得的一样。↩
68
为了对此进行建模,我们可以采用我们最初的创意生产函数,并以认知劳动(用 C 表示)和体力劳动加上有形资本(用PPP表示)来表示StS_tSt(ttt时的有效研究人员数量,或总研究投入),假设它们以恒定规模收益的Cobb-Douglas关系相结合。这给出:
A˙tAt=α(CtγPt1−γ)λAt−β\frac{\dot{A}_t}{A_t} = \alpha (C_t^\gamma P_t^{1-\gamma})^{\lambda} A_t^{-\beta}AtA˙t=α(CtγPt1−γ)λAt−β
为了估计γ\gammaγ(关于认知劳动力的研究投入弹性),我们可以使用对整个经济体中劳动份额的估计。美国国家科学基金会(NSF)的数据表明,研发支出的劳动份额约为70%,表明γ=0.7\gamma = 0.7γ=0.7(NSF(美国国家科学基金会),“研发劳动力成本”。)
当然,认知劳动力 C 与人类劳动力不同。但是,尚不清楚这是否会降低我们对γ\gammaγ的估计,因为某些(目前)非劳动力支出可以通过AI的认知劳动力来执行。
使用我们之前的参数值λ=34\lambda = \frac34λ=43和β=2.4\beta = 2.4β=2.4,我们得到:
A˙tAt=α(Ct0.7Pt0.3)0.75At−2.4\frac{\dot{A}_t}{A_t} = \alpha (C_t^{0.7} P_t^{0.3})^{0.75} A_t^{-2.4}AtA˙t=α(Ct0.7Pt0.3)0.75At−2.4
先前我们隐含地假设γ=1\gamma = 1γ=1。假设没有增长为了将增长率提高10倍,我们现在必须将 C 进一步提高约3.73倍——
101/(0.7⋅0.75)101/(0.75)≈3.73\frac{10^{1/(0.7\cdot0.75)}}{10^{1/(0.75)}}\approx 3.73101/(0.75)101/(0.7⋅0.75)≈3.73
那么,稳态增长率变为:
gA=λ(γgC+(1−γ)gP)⋅β−1=0.75(0.7⋅gC+0.3⋅gP)⋅2.4−1g_A = \lambda(\gamma g_C + (1-\gamma)g_P)\cdot\beta^{-1} = 0.75(0.7 \cdot g_C + 0.3 \cdot g_P)\cdot2.4^{-1}gA=λ(γgC+(1−γ)gP)⋅β−1=0.75(0.7⋅gC+0.3⋅gP)⋅2.4−1
我们可以看到,当我们考虑物理约束(γ=0.7\gamma = 0.7γ=0.7)与不考虑物理约束(γ=1\gamma = 1γ=1)时,在给定的技术进步速度下,认知努力需要比以前快约1/γ≈43%1/\gamma ≈ 43\%1/γ≈43%,才能仅凭认知努力维持相同的稳态增长率,同时假设物理因素PPP没有增长。↩
69
需要明确的是,我们指的是人机平价后不久开始的十年;我们不是指“从2025年开始的未来十年”。在AI研究投入增加导致技术进步之前,可能会存在(几年)的固定滞后。这将推迟技术进步十年中一个世纪的到来,但不会取消它。↩
70
对于关于AI与创意生产函数之间关系的一些怀疑性想法,请参见Almeida、Naudé和Sequeira,“人工智能与新创意的发现”。但请注意,他们的工作主要是在对无法替代人类研究劳动的人工智能进行建模——他们评论说,AGI“仍然只存在于科幻小说的领域中”。它还在计算中犯了一个错误。↩
71
请注意,这里我们说的是物理、工业扩张——在制成品、建筑物、基础设施等方面——而不是以GDP或股价衡量的经济增长。关于股价,AGI既可能提高预期的未来利润,又可能提高用于对其进行贴现的利率,而后一种效应可能会大大抵消前一种效应。同样,关于GDP,鲍莫尔成本病描述了经历较少生产力增长的部门如何作为经济的一部分增长。例如,由于对农产品的需求的价格弹性相当低,因此农业生产力的巨大提高导致该行业从1900年雇用美国大部分劳动力萎缩到仅占美国GDP的不到百分之一。然而,我们可以看到独立于这些影响的重大物理增长。与此相关的是,来自AI的主要新产品种类可能会在核算GDP时引入严重的歧义;而物理增长更容易衡量。有关成本疾病的更多信息,请参见Aghion、Jones和Jones的“人工智能与经济增长”。↩
72
与效率提升相比,资本积累本身也不能解释现代增长的大部分。自工业革命以来,资本存量大致与产出保持一致,但资本在所有收益中的份额约为四分之一,因此收入的绝大多数现代增长并非仅由资本积累来解释。(Clark,“第5章 - 工业革命”。)↩
73
除了软件反馈循环之外,这还将引入一个正反馈循环,因此我们应该预期这种工业扩张的增长率会加速。将生产AI和机器人的工业综合体增加一倍以上,产量将增加一倍以上:两倍的工厂意味着两倍的最终产品,因此,如果AI的翻倍人口在任何程度上提高了效率,那么产量将会增加一倍以上。虽然软件反馈循环最终必然会受到可用硬件的限制,但除非自然资源的稀缺成为限制因素,否则此反馈循环不会受到任何限制。↩
74
'掌握增强的灵巧性'。(请注意,这是机器人公司的一则付费广告。)↩
75
当然,需要人类的帮助来建造第一批复杂的通用机器人,例如在制造和测试中。但请记住,这只是在集体AI能力大规模提升之后:AI系统可以绘制设计图并管理人来帮助他们在物理上实现它们。人工工作的工资在一定程度上表明了生产越来越具有人类竞争力的机器人的巨大经济回报。↩
76
新型太阳能电池板的每瓦价格(因此)随着累计安装容量的每翻一番而下降约20%。Roser,'学习曲线'。↩
77
今天大约生产了10,000台(人形机器人),因此假设累计产量为100,000台。累计产量增加100,000倍将使每年的产量达到10亿台机器人,这相当于累计产量增加了约16.6倍。假设与太阳能电池板的累计产量具有相同的成本弹性(“学习率”),则成本将下降约∼0.816.6≈97.5%\sim0.8^{16.6} \approx 97.5\%∼0.816.6≈97.5%。每年10亿台机器人大约是每年生产的汽车数量的10倍,但汽车也比人形机器人大10倍,重10倍。除了实际生产之外,更大一部分“学习”效应可能来自模拟,这将加速成本下降。(Todd,'机器人可以多快扩大规模?')↩
78
这与“慢速”和“快速”起飞速度之间的区别有关。Paul Christiano根据世界产出来运作“慢速”起飞,如下所示:“在世界产出翻番的第一个1年间隔之前,将存在一个完整的4年间隔,在其中世界产出翻番。(类似地,我们将看到8年翻番之前是2年翻番,等等)” Christiano,'起飞速度'。↩
79
严重依赖体力劳动力的行业的劳动份额在一定程度上表明了生产越来越具有人类竞争力的机器人的巨大经济回报。工业——包括制造业、采矿业和建筑业——占世界GDP的约25%,并雇用了约全球劳动力的25%。至少在英国,生产和建筑的收入劳动份额约为50%。↩
80
事实上,由于扩大电力和芯片生产的经济回报将非常巨大,因此将会有巨大的压力来寻找方法来实现它们,包括打破监管障碍。即使某些监管环境抵制工业扩张的浪潮,也只需要少数几个国家打破僵局。一个国家从释放相对快速的增长中获得的好处将非常明显(比可能以约一个百分点加速增长的政策更明显)。↩
81
忽略许可方面的延迟,新建发电厂和高科技工厂(如电动汽车工厂)的交付周期约为1-3年(在最快的极端情况下,上海特斯拉超级工厂花费了十个月的时间建造)。举一个简单的例子,假设“自动化工厂”可以在2年内生产更多的自动化工厂(或以其他方式生产其他商品),并且进一步假设同一时间有75%的自动化工厂在接下来的2年内被导向生产自动化工厂。那么,自动化工厂的总库存将每2年增长1.75倍——大约每2.5年翻一番——这将提高整体实体经济的增长率,因为自动化工厂占越来越大的份额。许可可能会进一步减缓事情的进展,但是(i)这种缓慢的许可将带来非常重大的经济和军事成本,并且(ii)如果世界上有任何国家选择放弃许可并以尽可能快的速度增长,那么它将很快成为世界上大部分的工业。此外,经济和军事激励将施加强大的压力,以比当前工厂建设的速度更快地建造,而全天候工作的机器人可以进一步加速扩张。
通过考虑投资于机器人的回报率,我们还可以考虑工厂建设时间不是瓶颈时的初始物理增长率。由于机器人可以几乎24/7工作,没有节假日或病假,因此机器人可以有效地工作大约是每周工作40小时的员工的5倍。尽管对于某些体力工作而言,每周工作时数的递减回报将会降低,但机器人还将具有其他优势,例如超专注、超能力、专门为工作而设计并且已经过培训。因此,如果机器人可以替代年薪5万美元的体力劳动工作,我们可以假设他们可以为雇主提供至少相当于薪水5倍的回报,即每年25万美元。目前最好的人形机器人目前的成本约为10万美元,并且技术爆炸和累计产量将降低成本。电力、计算、维护和其他折旧来源将产生一些成本;比如每年2.5万美元(考虑到可比的资本折旧率,这是保守的)。那么,这样的机器人将产生200%的年回报率,在不到6个月的时间内收回成本。换句话说,如果将所有收益都进行再投资,则需要6个月的时间才能产生足够的收入来使机器人库存翻一番。当然,并非所有收入都一定会进行再投资。另一方面,机器人的库存很容易以比它自给自足的速度 更快 地增长,因为在如此高的回报率下,外部资本将涌入机器人的生产和部署,直到市场饱和为止。在这种情况下,机器人的增长率至少最初只会受到可以建造机器人的速度的限制。因此,此分析更像是软下限:即使机器人的增长率完全是自筹资金的,那么以有效“机器人人口”衡量的翻番时间(以月为单位)也很可能摆在桌面上。↩
82
果蝇具有大脑、消化系统、物理操纵器、专用工具和运动能力,但即使在理想条件下,它们也可以在不到一周的时间内将其生物量翻一番。如果有了先进的技术,社会可以建造有用的机器人,这些机器人可以以与果蝇相同的速度自我复制,那么整个工业的扩张速度可能会有相似的翻番时间。其他生物有机体可以比果蝇生长得更快,但它们的复杂性较低。浮萍科中的漂浮植物可以在不到48小时的时间内将其生物量翻一番,并且据报道,Vibrio natriegens 细菌的翻番时间不到十分钟。
我们并非有信心地说物质经济会增长得如此之快——果蝇不在乎财产权,它们也不必应对规划批准和其他监管限制。但是,它们如此快速增长的能力表明了工业增长在峰值时的增长速度,特别是因为通常限制生物种群增长的因素(例如生物竞争、掠夺、病原体和非常有限的Gas供应)似乎与AGI之后的工业经济无关,并且因为进化无法在设计生物体时“向前看”。例如,它不能承担巨大的短期成本来建造基础设施,这些基础设施将在以后促进更快复制的有机体的生长。↩
83
大量扩展太阳能光伏发电的一个潜在问题是,我们可能会耗尽容易获得的铜。一个光伏太阳能发电厂每兆瓦发电量约含5.5吨铜。海洋的表面积=361 million km2×2%=7.22 million km2=7.22 trillion m2= 361 \text{ million } \text{km}^2 \times 2\% = 7.22 \text{ million } \text{km}^2 = 7.22 \text{ trillion } \text{m}^2=361 million km2×2%=7.22 million km2=7.22 trillion m2。地球接收到的最大热能约为500 W/m2500 \text{ W/m}^2500 W/m2,产生36亿兆瓦的太阳能发电,需要200亿吨铜。铜储量(2024年)+已发现的资源(2015年)+未发现资源的估计值(2015年)= 0.98 + 2.1 + 3.5 = 65.8亿吨(来源)。
但是,铜可以从浓度较小的材料中提炼,在这些材料中,目前提炼是不经济的。地球大陆地壳中铜的丰度约为0.006%(来源)。大陆地壳的质量约为2.171×1022 kg=2.171 \times 10^{22} \text{ kg} =2.171×1022 kg= 2.2 quintillion吨,其中0.006%为132万亿吨铜。
如果更好的采矿技术仅使其中的15%可用,就足以满足全球一次能源消耗增加100倍的需求。此外,更好的技术将合理地更有效地利用铜,或找到可行的替代方案。↩
84
如果我们能够用天基太阳能发电场捕获太阳输出的0.1%,并以10%的效率将其转化为有用的工作,那么我们将使一次能源消耗比今天的水平提高超过十亿倍。↩
85 资源在给定的技术水平下变得更难以提取,这确实是事实,但历史趋势是提取方法随着需求的增长而改进,而且价格似乎更多地是由需求而非供应冲击更强烈地决定。这反映在有价值的资源的价格保持出人意料地稳定,尽管人们担心容易获得的储备将被耗尽(有关Simon-Erlich赌局的最新评估,请参见Liu and Fitzpatrick (2021))。当然,这并不总是正确的:一些资源似乎遵循持续上升的价格趋势,但其他价格似乎在下降,总体趋势并非上升。↩
86
Marc Andreessen,“为什么AI将拯救世界”;“世界能源消耗在哪一年将首次超过之前每年的130%?”↩
87
福利增长当然来自于收入的增长,但技术(广义理解)可以说是现代增长的根本驱动力(Jones,“经济增长的过去与未来”。)↩
88
更准确地说:一个重大挑战(grand challenge)是指这样一种发展,即关于处理该发展的决策,至少以千分之一(0.1%)的比例改变了地球起源生命的预期价值,这是指立即无痛的人类灭绝与每个人都具有完美的道德动机并共同努力以产生最佳结果的文明之间的价值差异的比例。 这里,“预期价值”采用来自挑战发生时理想观察者的角度的证据概率,以及正确的(或者,如果不存在,则为反思性偏好)价值函数。
我们可以将这个概念与生存风险的概念进行比较,Toby Ord 将生存风险定义为“威胁到人类长期潜力的毁灭的风险”。 (Ord,《悬崖》)。 重大挑战(grand challenge)概念比生存风险的概念更广泛,体现在三个方面:
-
它包括以非极端方式影响未来预期价值的发展,例如可能使极权主义政权永久控制所有资源 1% 的技术。
-
它是非模态的:它依赖于概率而不是可能性。 即使成功的革命仍然可能但非常不可能,人类因此保留了其“潜力”但失去了大部分预期价值,稳定全球极权主义政权的风险也将是一个重大挑战(grand challenge)。
-
它并不假定长期未来的重要性——即使一个人只重视未来几十年,重大挑战(grand challenge)也是任何显着改变该时期预期价值的发展。
89
Thierer,“步调问题与技术监管的未来”。↩
90
Cotra,“如果没有具体的对策,变革型AI最容易的路径很可能导致AI接管”。↩
91
92
Greenblatt 等人,“大型语言模型中的对齐伪装”。↩
93
2023年5月,发布了一份简短的声明,内容是“减轻人工智能造成的灭绝风险应与大流行病和核战争等其他社会规模的风险一样,成为全球优先事项。” 该声明由三家领先的AI公司的CEO(Sam Altman、Dario Amodei和Demis Hassabis)以及公认的深度学习领域三位最具影响力的研究人员(Geoff Hinton、Yoshua Bengio和Ilya Sutskever)签署。(“关于AI风险的声明”。)此外,在有超过2500名AI研究人员参与的同类调查中,略超过50%的受访者认为“人类无法控制未来先进的AI系统,导致人类灭绝或对人类物种造成类似的永久性和严重的权力剥夺”的可能性,主观概率为10%或更高。(Grace et al., “关于AI未来的数千名AI作者”)。↩
94
Ngo, Chan, and Mindermann, “从深度学习角度看对齐问题”。↩
95
Carlsmith,“寻求权力的AI是生存风险吗?”;Carlsmith,“阴谋AI”。↩
96
Adamala 等人,“镜像细菌技术报告”。↩
97
Jonathan D., “漫长而曲折的道路”。↩
98
99
Solem,“微型机器人在战争中的应用”。↩
100
一个大型甲壳虫大小的无人机可以装入大约4×4×2厘米的立方体体积中; 或 16 cm316\text{ cm}^316 cm3。 100亿个这样的体积将覆盖所有活着的人。 然后,存储 100 亿只蚊子所需的体积为 16 cm3×1010=1.6×105m316 \text{ cm}^3 \times 10^{10} = 1.6 \times 10^5 \: \text{m}^316 cm3×1010=1.6×105m3。 一个大型飞机机库的例子,尺寸为 76 × 180 × 19m,或 2.5×105m32.5 \times 10^5 \: \text{m}^32.5×105m3。↩
101
Dafoe 和 Garfinkel,“进攻-防御平衡如何衡量?”。↩
102
“首次打击中可交付的核武器的估计当量”; Schumann,“概况介绍”。↩
103
104
更准确的术语可能是原子精确质量制造(APMF) (Drexler, 'AI Has Unblocked Progress toward Generative Nanotechnologies'.) ↩
105
Drexler, [纳米系统] ( https://dl.acm.org/doi/abs/10.5555/135735).↩
106
原材料不必限制制造的范围和数量:原则上,先进的APM可以使用低成本的原料。↩
107
Adamala 等人,“面对镜像生命的风险”。↩
108
Adamala 等人,“镜像细菌技术报告”。↩
109
Hutchison 等人,“最小细菌基因组的设计与合成”。↩
110
Arai,“人工蛋白质和复合物的分层设计,以实现合成结构生物学”。↩
111
“人工智能对核风险的影响”; Cotton‑Barratt, 'AI Takeoff and Nuclear War'。↩
112
113
如果美国开始明显地将中国甩在后面,以至于它将很快拥有压倒性的军事优势,那么中国可能会受到激励,在他们仍然可以的时候,强行阻止美国积累更多的力量。↩
114
这是由 Stefan-Boltzmann 定律给出的,我们可以用热平衡Te=(S(1−α)4σ+F)−4T_e = \left(\frac{S(1-\alpha)}{4\sigma}+F\right)-4Te=(4σS(1−α)+F)−4模拟地球的有效温度。其中 FFF 是来自核聚变的额外(非太阳)通量,α\alphaα 是地球的反照率,SSS 是太阳常数,σ\sigmaσ 是 Stefan-Boltzmann 常数。 在这种情况下,升温约为 25K。↩
115
更多信息请参见 Davidson、Finnveden 和 Hadshar,“人工智能支持的政变:一小群人如何利用人工智能夺取权力”↩
116
Bruce Bueno de Mesquita, Alastair Smith, Randolph M. Siverson and James D. Morrow, 政治生存的逻辑 (2005)↩
117
网络攻击对敌人来说似乎特别有吸引力,因为与其他形式的战争不同,它们不仅会使一个国家的军事力量失效,还会将该力量的控制权交给网络攻击者。↩
118
Gans 等人,“不平等和市场集中度,当持股比消费更倾斜时”↩
119
如果美国实际GDP从1950年到2020年的增长速度减半(从大约3%变为1.5%),到2020年,美国经济的规模大约相当于德国的规模。↩
120
作为一个玩具示例,假设我们进入一个时期,经济增长可以通过像 E(t)=etnE(t) = e^{t^{n}}E(t)=etn 这样的“超指数”函数来描述(其中 n>1n>1n>1)。 假设 A 组对 B 组(可以简单地描述世界其他地方)具有最初的经济领先优势——它在同一曲线上走得更远。 因此,A 的经济由EA(t)=e(t+c)nE_A(t) = e^{(t+c)^{n}}EA(t)=e(t+c)n 描述,其中 ccc 是某个常数(而 EB(t)=etnE_B(t) = e^{t^{n}}EB(t)=etn)。 在任何给定时间,这些经济体的比率 RRR 将简化为 R(t)=EA/EB=e(t+c)n−tnR(t) = E_A/E_B = e^{(t+c)^{n} - t^{n}}R(t)=EA/EB=e(t+c)n−tn。 这会随着时间的推移而增加,这意味着比例差异会增长。 (例如,如果我们选择 n=2n=2n=2 且 c=1c=1c=1,则在 t=1t=1t=1 时,A 的经济体大约比 B 大 20×20\times20× 倍,而在 t=2t=2t=2 时,大约大 150 倍。)↩
121
关于锁定效应的最佳扩展讨论可以在以下文章中找到:Finnveden、Riedel 和 Shulman,“通用人工智能和锁定效应”↩
122
Constâncio 等人,“用机器学习检测欺骗”; Beraja 等人,“AI-Tocracy*" ; Feldstein,“人工智能监控的全球扩张”。↩
123
例如,一个政权可以拍摄一个完全忠诚的模型的快照,并不断用快照的新副本替换其AI劳动力。↩
124
Dafoe 等人,“合作AI中的开放问题”。 Schelling, 托马斯·C·谢林的冲突策略。↩
125
Brannon 和 Holmes,“第230条:概述”↩
126
Shavit 等人,“管理代理AI系统的实践”↩
127
128
Chan 等人,“AI代理的基础设施”。↩
129
我们的意思是包括这样一种可能性,即“现象意识”在某种程度上是一个令人困惑的概念,或者是一种幻觉,因此,关于“现象意识的适当标准”的问题至少需要更多的概念澄清才能回答。 相比之下,生命科学发现了生命的关键机制,而没有发现“生命的 criteria”,因为很明显没有单一的“生命本质”可以发现。 参见例如 Frankish,“作为意识理论的错觉主义”。↩
130
131
现代肉鸡在大约7周内达到上市重量,与20世纪50年代的肉鸡相比,生长速度快约4倍。蛋鸡经过选择性育种以最大限度地提高产蛋量;它们通常每年产多达300个鸡蛋,而它们的野生祖先每年产10-15个鸡蛋。每年有超过700亿只鸡在工厂化农场中被屠宰。↩
132
请注意,由于任何希望效仿的参与者仍然必须克服地球的引力束缚能,物理学可能在这里有利于地球之外的先行者,从而有效地使已建立的非地球产业通过削弱从地球向外的运动而获得“主导地位”。↩
133
以每两个碱基对一个字节计算,DNA存储的信息约为每克 102110^{21}1021 位,大约 100艾字节。以每个突触连接一个字节计算,存储人类大脑大约需要 100TB。 因此,2克像DNA一样紧凑的存储介质可以包含一百万人的突触图,开放网络上大多数文本数据,10,000种独特的动植物物种的基因组,并留有剩余空间。 按重量计算,橡子(~1克)主要是食物,外加将遗传信息转化为橡树以及橡树林的机制。 因此,对于文明的“种子”,没有明显的低于10克左右的质量限制。↩
134
Armstrong 和 Sandberg,“六小时的永恒”。
请注意,由于光速是航天器速度的上限,因此先行者可以在其他人能够拦截和阻止他们之前开始太空定居的过程。↩
135
我们不知道对此问题是否有权威的讨论,并且流行的描述表明星际战争实际上有利于进攻和先发制人。 期望防御占主导地位的一个原因是,太空定居点之间巨大的物理距离和其他障碍将剥夺参与者攻击的理由(贸易和通信速度较慢),同时提高攻击成本(穿越太空),类似于一些人推测南美洲难以穿越的地理环境导致相对较少的国家间战争。 另一个原因是,现任参与者可以在恒星系统周围产生一片尘埃云,几乎可以保证以相对论速度行进的攻击者在接近时被摧毁。↩
136
Trager 和 Emery,“高级人工智能竞赛中的信息危害 | GovAI”。↩
137
Allan Dafoe,“价值侵蚀”(Allan Dafoe, “Value Erosion” (未发表的笔记) (2019))↩
138
139
同样,随着技术的充分发展,有可能以数字方式复制特定的意识体验,或者至少对模拟人在道德地位上造成真正的模糊性。 不良行为者可能会威胁要伤害其目标或其所爱之人的模拟物; 或者只是制造痛苦并将其施加于新的数字生命,如果勒索对象关心这些数字生命的福祉。 同样,这可能会将权力转移给最愿意、也最能够令人信服地发出此类威胁的人。↩
140
Barnes,“人工智能说服的风险”。↩
141
Hackenburg 等人发现了对数缩放定律的证据,表明说服力的度量随模型大小呈对数变化。 他们还发现,与实验中使用的人工撰写的文本相比,领先模型编写的文本的说服力略高。 (Hackenburg et al., 'Evidence of a Log Scaling Law for Political Persuasion with Large Language Models'.) ↩
142
143
Williams,“对虚假信息的关注导致了对人们为什么相信和行动于不良信息的深刻误解”。↩
144
145
146
Boudry 和 Hofhuis,“关于认知黑洞。 自封闭信念系统如何发展和演变”。↩
147
Bostrom,“关键考虑因素和明智的慈善事业”。↩
148
Kahan 等人,“有动机的计算能力和开明的自治”。↩
149
150
“社区笔记提高了对社交媒体上事实核查的信任度 | PNAS Nexus | 牛津学术”。↩
151 Buterin, '我对社区笔记的看法是什么?'. ↩
152
Costello, Pennycook, 和 Rand, '通过与 AI 的对话持久地减少阴谋论'.
你可以在这里浏览对话记录. 后续工作表明,主要的驱动因素是 AI 引用相关事实信息的能力,而不是某种更通用的、独立于引用事实和证据的说服能力。(Costello, Pennycook, 和 Rand, '只有事实'.) ↩
153
专家预测者目前表现优于表现最佳的 LLM (Karger et al., 'ForecastBench'.) ↩
154
理论上,它甚至可以按时间顺序对数据进行训练,同时一直进行预测:一旦它接受了 2015 年之前的数据的训练,它就可以对 2016 年进行预测,依此类推。这种精确的方法可能被证明是困难且无效的,但更广泛的观点是,AI 系统可以从人类实际上无法获得的训练技术中受益。 ↩
155
156
对于与其他 AI 系统的合作以及对用户偏好的深刻而准确的理解等特质来说,情况也可能如此。 ↩
157
在上个世纪,技术进步平均每年为平均收入带来约 1% 的增长。 这相当于一个世纪内增长 270%。 然而,这种进步可能需要时间才能在整个经济中传播,因此我们在此并非声称平均收入将在十年内翻一番。 ↩
158
默认情况下,我们可能期望像美国和中国这样的国家进行竞争——可能以各种方式互相破坏——试图获得更大份额的世界资源(甚至声称对整个世界的控制权)。 但是,如果合作并满足于较小的分数份额将有助于世界安全地实现根本性的共同富裕(其中整体“馅饼”非常大),那么较小的分数实际上可能代表比他们通过赢得竞争应该获得的更多的“馅饼”。 因此,在合作导致富裕的情况下,他们合作比竞争更理性。 ↩
159
有关“效用-技术可能性边界”的扩展讨论,请参见 Acemoglu, '制度、技术与繁荣'。 ↩
160
161
162
Boix (2003) 称民主与经济发展之间的相关性为“迄今为止我们在比较政治学中拥有的最强的经验概括”(Boix, '政治转型理论'.)
有关因果机制的一些讨论,另请参见 Acemoglu 和 Robinson, 独裁与民主的经济起源 (https://doi.org/10.1017/CBO9780511510809). ↩
163
人们通常具有大于 1 的“相对风险厌恶指数”,因此他们会拒绝那些固定概率增加或减少一定百分比财富的赌博。美国联邦成本效益分析指南假定相对风险厌恶指数为 1.4 (管理和预算办公室通告 A-4, p.67). ↩
164
Trask 等人,'通过结构化透明度超越隐私权衡'; Drexler, '没有反乌托邦的安全'. ↩
165
Rahaman 等人, '语言模型可以减少信息市场中的不对称性'. ↩
166
有关“关键考虑因素”的讨论,请参见 Bostrom, '技术革命',这些“关键考虑因素”将“推翻我们原本会得出的关于我们应该如何指导我们的努力的结论”。 ↩
167
有关 20 世纪中期对技术和其他发展预测的准确性的更多信息,请参见对“三大”早期未来学家(亚瑟·C·克拉克、艾萨克·阿西莫夫和罗伯特·海因莱因)的跟踪记录的分析——Arb Research, '对三大预测表现的评分'. ↩
168
一个原因是,我们应该期望我们在挑战方面的表现是相关的:如果(例如)利用智力爆炸来提高社会的集体推理能力,那么决策者通过无知或操纵来搞砸其他挑战的可能性就会降低。 另一个原因是,如果我们正确应对最重要的挑战,我们就可以随着时间的推移纠正错误。 因此,如果事情进展顺利,它们可能会进展得非常好。 ↩
169
外层空间和平利用委员会, '第四次外空会议 - 外层空间事务厅的非文件'. ↩
170
171
Vaintrob 和 Cotton-Barratt, '人工智能在生存安全方面的应用'. ↩
172
Chan 等人, 'AI 代理的基础设施'. ↩
173
174
Greenblatt 等人, '大型语言模型中的对齐伪装'. ↩
175
我们主要根据与高级国际公务员的私人通信提出这一主张。 外层空间和平利用委员会, '第四次外空会议 - 外层空间事务厅的非文件'. ↩
176
“如果-那么承诺”就是一个例子。 这些承诺旨在确保采取缓解措施或政策,以防万一触发某些触发因素,例如危险的新 AI 功能的明确证据。 除了设计和运行触发“如果-那么承诺”的测试的成本之外,只要不满足条件,它们就不需要减慢 AI 开发的速度。 参见 Karnofsky, '减少 AI 风险的如果-那么承诺'. ↩
177
2025 年国际 AI 安全报告 ↩
搜索
搜索文章...
- 原文链接: forethought.org/research...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





