用 Rust 写一个 AI 日志分析器
- King
- 发布于 2026-01-01 12:23
- 阅读 591
祝大家2026新年快乐,身体健康,今天来思考一个有趣的问题:——在大厂,日志类系统以前是怎么做的?现在因为AI变得有多简单?在大厂做后端的那几年,我几乎没有遇到过「不需要看日志」的系统。监控和告警解决的是“哪里出问题了”,日志解决的永远是那个更难的问题:为什么会出问题?当
祝大家2026新年快乐,身体健康,今天来思考一个有趣的问题: —— 在大厂,日志类系统以前是怎么做的?现在因为 AI 变得有多简单?
在大厂做后端的那几年,我几乎没有遇到过「不需要看日志」的系统。
监控和告警解决的是 “哪里出问题了”, 日志解决的永远是那个更难的问题:
为什么会出问题?
当系统规模还小时,人肉分析日志勉强能扛; 但一旦到了高 QPS、多服务、多团队的环境,日志分析就会变成一种持续消耗工程师精力的体力活。
在没有 AI 的年代,大厂是怎么做日志分析的?
先说一个很多人可能不知道的事实:
大厂并不是“不用看日志”,而是尽量“让人少看日志”。
1️⃣ 日志聚合与标准化
在大厂时期,我们会先做几件基础设施层面的事情:
- 统一日志格式
- 结构化日志(JSON)
- 集中式日志系统(ELK / ClickHouse)
这一步的目标是: 让日志“可查询”,而不是“可理解”。
2️⃣ 人工设计规则 + 聚合维度
接下来是最重的一步:
- 人工设计 error code
- 人工定义错误分类
- 按服务 / 接口 / 错误类型聚合
这些规则的特点是:
- 非常依赖资深工程师经验
- 新错误必须手动补规则
- 无法覆盖所有边界情况
本质上,这是在用规则模拟语义理解。
3️⃣ 人仍然是系统里最贵的一环
即使做了所有这些事情:
- 真正的异常归因,仍然要人来判断
- 低频但致命的问题,很容易被埋没
- 新系统、新业务,规则几乎要重写
日志分析的瓶颈,从来不在机器,而在人。
如果当年有现在的 AI,会发生什么?
直到这两年,大模型真正可用之后,我才意识到一件事:
我们当年用大量规则、人工经验、复杂系统去解决的问题, 本质上就是“文本语义理解”。
而这,正是 AI 最擅长的事情。
于是,一个想法就变得非常自然:
能不能把“理解日志”这件事,直接交给模型?
AI 日志分析器的整体架构
先看一个可以真正跑在生产环境里的最小架构:
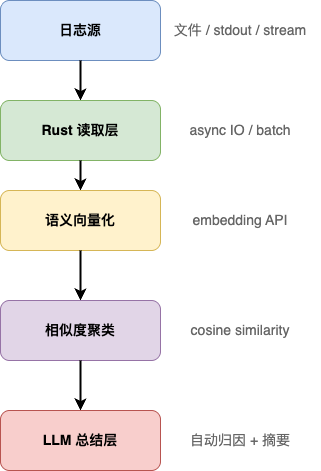
这个架构的核心思想只有一句话:
让机器做理解、归类和总结,人只看结果。
第一步:用 Rust 高效读取和批处理日志
这是 Rust 非常擅长的部分。
use tokio::fs::File;
use tokio::io::{AsyncBufReadExt, BufReader};
pub async fn read_logs(path: &str) -> anyhow::Result<Vec<String>> {
let file = File::open(path).await?;
let reader = BufReader::new(file);
let mut lines = reader.lines();
let mut logs = Vec::new();
while let Some(line) = lines.next_line().await? {
logs.push(line);
}
Ok(logs)
}在真实系统里:
- 可以加 batch
- 可以加 channel
- 可以并行处理多个文件
这和传统日志系统的处理方式完全一致。
第二步:日志语义向量化(关键转折点)
过去我们用规则,现在直接用 embedding。
#[derive(Serialize)]
struct EmbeddingRequest {
model: String,
input: Vec<String>,
}async fn embed_logs(logs: Vec<String>) -> Vec<Vec<f32>> {
// 调用 embedding API,返回语义向量
}这一层的意义在于:
日志不再是字符串,而是“语义坐标”。
第三步:用相似度自动聚类错误
fn cosine_similarity(a: &[f32], b: &[f32]) -> f32 {
let dot = a.iter().zip(b).map(|(x, y)| x * y).sum::<f32>();
let norm_a = a.iter().map(|x| x * x).sum::<f32>().sqrt();
let norm_b = b.iter().map(|x| x * x).sum::<f32>().sqrt();
dot / (norm_a * norm_b)
}只要设定一个阈值,就能自动把:
- timeout 类
- permission 类
- 参数错误类
自然聚到一起。
这一步,在过去几乎不可能低成本实现。
第四步:让 LLM 自动总结“发生了什么”
以下是同一类错误日志,请总结问题原因,并给出可能的排查方向:
- log1
- log2
- log3模型给出的结果,往往已经接近一个合格工程师的分析结论。
为什么现在变得这么容易?
回头看会发现:
- 架构思路 和当年在大厂时是一样的
-
不同的是:
- 过去:规则 + 人工经验
- 现在:embedding + LLM
AI 并没有改变系统工程本身, 它只是把“最难的一环”变成了可调用的能力。
写在最后
如果你维护过一个日志量巨大的系统, 你会知道:
真正值钱的不是日志,而是结论。
AI 的出现,让我们第一次可以:
- 用机器理解日志
- 用机器做初步归因
- 把工程师从“翻日志”中解放出来
而 Rust,正好是把这套能力稳定落地的最好工具之一。





