自底向上学习以太坊(三):智能合约开发中的构造器、函数定义与存储布局
- 4seasstack
- 发布于 2025-11-04 22:43
- 阅读 661
本文介绍了使用Foundry进行Solidity项目初始化、代码编译、测试和部署的方法,包括构造器的执行原理、函数定义与修饰符、存储变量定义与存储布局等内容,并给出了详细的代码示例和测试用例,同时还介绍了Soldeer包管理工具的使用,以及如何通过内联汇编和读取本地二进制文件部署合约。
概述
在本节内,我们将介绍如何使用 Foundry 进行项目初始化、代码编译与测试以及如何进行常规的合约部署和基于 create2 的确定性合约地址部署。具体来说,本节内容将介绍:
- 构造器的执行原理,以及
create code(也被称为init code) 和runtime code之间的区别 - 常规的函数定义以及函数修饰符(如
external/internal/public) 的工作原理 - 存储变量定义以及存储布局问题
项目初始化
较为现代的 Solidity 开发都会使用 Foundry 或者 Hardhat 开发框架。目前,Foundry 已逐渐超过 hardhat 成为大部分项目的主流框架,比如 Uniswap V4 完全使用了 Foundry 框架。Foundry 框架提供了非常优秀的开发者体验,允许开发者在同一个空间内完成合约的编写、编译、测试和部署。
我们在开始真正的智能合约编程时,第一步就是初始化项目。初始化项目时,Foundry 会在本地安装 forge-std 标准库,该标准库内提供了一系列用于合约测试和部署的函数,以及一些常用的功能函数。在我们后文介绍合约测试时会详细介绍这些 forge-std 内部函数的功能和工作原理。概括来说,大部分函数都是调用了一个特殊的 VM 地址(0x7109709ECfa91a80626fF3989D68f67F5b1DD12D),对该地址的调用会被 Foundry 内部的 EVM 运行时捕捉,并在 Foundry 内部的 Rust 代码内完成计算后返回给调用方。本质上,工作原理类似 EVM 内的预汇编合约。
当然,实际上 Foundry 并不是完全从零开始的,Foundry 内部相当多的思想和实现都来自古老的 dapp.tools。dapp.tools 作为一个由 MarkerDAO 构建的以太坊早期项目,创建了基于 VM 地址调用的测试方法,并且使用如下地址作为 VM 地址:
address constant HEVM_ADDRESS =
address(bytes20(uint160(uint256(keccak256('hevm cheat code')))));此后,所有的智能合约测试工具,包括 Foundry \ echidna \ medusa 都支持这套系统。HEVM 定义的一系列基础的用于测试的函数基本成为了以太坊智能合约测试的实际标准。这极大提高了合约测试时的互操作性,我们可以在 Foundry 内完成基础测试,然后使用 echidna 等高级测试工具完成更加复杂的测试。
echidna 是一个 invariant test 工具,这种工具支持对合约系统的随机调用,并在一系列随机调用后检测某些属性是否被打破,比如是否存在系统负债和资产不相等的情况。一般来说,我们会在服务器上执行千万量级甚至更多的随机调用测试来确保系统的核心不变量不会被打破
在过去,默认情况下 Foundry 会使用 git submodule 方法以 libs 形式安装依赖,但是更加现代的方法是使用 Soldeer 工具。Soldeer 是一个 Solidity 的包管理工具,类似 node.js 生态内的 npm 工具。Foundry 完全内嵌了 soldeer 工具,我们可以使用如下指令查看 soldeer 命令的帮助文档:
forge soldeer -h接下来,我们使用 mkdir 指令创建文件夹并使用 cd 指令进入文件夹:
mkdir basic-contract && cd basic-contract之后在文件夹内使用 forge soldeer init 初始化项目。最后,我们会获得如下的文件夹结构:
.
├── dependencies
│ └── forge-std-1.11.0
├── foundry.toml
├── remappings.txt
└── soldeer.lock使用 code . 指令就可以直接在文件夹内部打开 vscode。在本次课程内,所有的编程都将在 VSCode 内完成。注意,为了开发体验,请读者自行安装 JuanBlanco.solidity 插件。该插件会提供基础的 solidity 语法高亮和提示功能。我们可以看到生成的文件内包括 remappings.txt,该文件内容是:
forge-std-1.11.0/=dependencies/forge-std-1.11.0/该文件的功能是允许我们直接使用 forge-std-1.11.0/ 导入 forge-std 标准库,而不需要输入完整的文件路径。在代码中,我们可以使用:
import {Test} from "forge-std-1.11.0/src/Test.sol";直接导入 forge-std-1.11.0/src/Test.sol 文件而不需要使用完整的 dependencies/forge-std-1.11.0/src/Test.sol 路径。我们称这种路径的重映射为 remapping。更加现代的写法是将 remapping 写入 foundry.toml。那 foundry.toml 是什么?该文件内包含以下内容:
[profile.default]
src = "src"
out = "out"
libs = ["dependencies"]
[dependencies]
forge-std = "1.11.0"
## See more config options https://github.com/foundry-rs/foundry/blob/master/crates/config/README.md#all-options该文件内定义一系列 Foundry 的配置参数,比如此处的 src 是在配置智能合约源代码所在位置,而 out 用来配置 solidity 编译后的输出路径,而 libs 用来配置依赖所在的位置。此处,我们增加一个 remapping 配置:
remappings = [\
"forge-std/=dependencies/forge-std-1.11.0/src/"\
]上述配置的含义是当编译器读到 forge-std/ 路径后,自动将该路径修改为 dependencies/forge-std-1.11.0/src/ 路径。之后,我们就可以使用 rm remapping.txt 直接删除 remapping.txt 文件。这样我们可以通过如下更加简洁且无歧义的方式导入 forge-std 库:
import {Test} from "forge-std/Test.sol";由此,我们就完成了项目的最基础初始化的配置。接下来,我们可以创建 src 文件夹来存储智能合约源代码文件,并在该文件夹内创建 Counter.sol 文件来编写智能合约。
构造器与合约基础架构
在 Contract.sol 内部,我们首先需要声明合约所使用的开源协议和使用的编译器版本,比如:
// SPDX-License-Identifier: MIT
pragma solidity =0.8.30;上述代码内的 SPDX 来自 Linux 基金会,我们可以在 SPDX License List 找到几乎所有可用的协议名称。对于编译器版本的声明,此处的声明指的是当前合约只能使用 0.8.30 版本的编译器进行编译。大部分情况下,核心合约都使用锁定版本的编译器,而库等可能被其他开发者调用的情况一般会使用非锁定版本编译器。比如非锁定版本的代码如下:
pragma solidity ^0.8.30;上述版本标记表示不能使用低于 0.8.30 版本的编译器编译,但可以使用 0.8.30 以上但不高于 0.9.0 版本的编译器进行编译。此处的规则与 npm semver 规则一致。
读者可以在 Solidity Bugs Viewer 内看到 solidity 编译器过去版本的漏洞情况
我们可以编写如下代码:
contract Counter {
uint256 public count;
constructor(uint256 _initialCount) {
count = _initialCount;
}
function increment() external {
count += 1;
}
function decrement() external {
count -= 1;
}
}上述代码内 uint256 public count; 用于声明存储变量。任何对 count 的读写都会被修改为对底层状态的修改,此处的 public 说明该变量可以被外部和内部读取,我们称 public 为可见性修饰符,我们会在后文继续介绍存储变量的可见性修饰符规则。此处的 constructor 用于初始化 count 变量。剩下的函数 increment 和 decrement 用于修改 count 的数值。此处的 external 代表这些函数只能被外部调用,我们不能构建这种函数:
function dupIncrement() external {
increment();
}当我们使用上述代码后,solidity 编译器会抛出如下报错:
Error (7576): Undeclared identifier. Did you mean "decrement" or "increment"?
--> src/Counter.sol:20:9:
|
20 | increment();
| ^^^^^^^^^这是因为 external 版本的函数无法在合约函数内部被调用。我们会在后文继续介绍函数定义的语法定义和原理。接下来,我们简单介绍一下合约的测试。我们创建 test/Counter.t.sol 文件并在内部编写测试代码:
// SPDX-License-Identifier: MIT
pragma solidity =0.8.30;
import {Test} from "forge-std/Test.sol";
import {Counter} from "src/Counter.sol";
contract CounterTest is Test {
Counter internal counter;
function setUp() public {
counter = new Counter(0);
}
function test_Increment() public {
counter.increment();
assertEq(counter.count(), 1);
}
function test_Decrement() public {
counter.increment();
counter.decrement();
assertEq(counter.count(), 0);
}
}上述测试测试代码中,我们导入了 import {Test} from "forge-std/Test.sol"; 库,然后我们的 CounterTest 继承了 Test 合约。Test 合约内部包含一系列与测试直接相关的库。我们可以通过查阅 forge-std 内的源代码:
// ⭐️ TEST
abstract contract Test is TestBase, StdAssertions, StdChains, StdCheats, StdInvariant, StdUtils {
// Note: IS_TEST() must return true.
bool public IS_TEST = true;
}此处的 StdAssertions 内部提供了 assertEq / assertNotEq 等验证函数,而 StdCheats 内部包含 deployCode / skip 等函数,这些函数用于修改 EVM 的环境状态,比如 deployCode 可以将合约字节码部署到测试环境中,而 skip 用于修改 block.time,具体可以参考 Cheatcodes Reference 文档。此处的 StdUtils 提供了一系列功能代码,如 computeCreateAddress 用于计算某一个地址在特定 nonce 下部署出的合约地址。
简单来说,Test 内部包含了一系列用于测试的功能代码。大部分情况下,我们在测试中所需要的一切功能都可以直接在 Test 内找到。在后续课程中,我们会逐渐介绍 Test 内部的功能函数。此处也鼓励读者直接阅读 文档 和 forge-std 源代码。
回到我们上文给出的测试代码,我们首先在 CounterTest 内部定义了 Counter internal counter;。Counter 在合约底层就是 address 类型。然后,我们定义了 setUp 函数,Foundry 测试的执行流程是:
- 执行
setUp函数初始化当前的 EVM 环境状态,一般来说,我们会在setUp内部署待测试合约以及执行一些其他初始化 - 执行测试函数,如执行上述代码内的
test_Increment函数 - 清空所有状态,输出执行测试函数的测试结果
所以,上述测试代码内 test_Increment 与 test_Decrement 之间互不影响。由于这种测试函数之间互不影响的性质,所以 Foundry 在后台实际上会使用多线程并行执行所有的测试来加快测试进度。
有读者好奇是否存在测试函数之间会互相影响的测试方法? 比如执行完成
A调用后,再执行B调用,但B调用的会建立在A调用的结果上,这种测试方法是存在的,即上文介绍的invariant test方法
在此处,我们主要关注 new Counter(0); 函数。此处的 new 用来创建合约。本质上 new 函数在底层使用了 CREATE 操作码,该操作码接受以下三个参数:
value发送给新合约的 ETH 数量offset部署合约字节码在内存中的偏移量size部署合约字节码的长度
换言之,我们需要首先将合约的字节码复制到内存中,然后制定字节码在内存中的起始位置和长度调用 CREATE 指令部署合约。在部署过程中,我们使用的字节码不仅仅是合约的编译后的字节码,具体来说这部分内容包括:
<init code> <runtime code> <constructor parameters>我们可以使用以下指令获得使用参数 1 初始化的 Counter 的部署字节码:
cast concat-hex $(forge inspect src/Counter.sol bytecode) $(cast to-uint256 1)此处的 forge inspect src/Counter.sol bytecode 会返回 <init code> <runtime code> ,而 <constructor parameters> 需要我们自己编码后补充到最终的字节码中。在后文中,我们会给出上述方法的合约形式。
获得输出字节码后,我们可以将输出字节码放到 dedaub Bytecode Decompiler 进行反编译,当然读者也可以直接使用 此链接 看到我的反编译结果,如下:
object "contract" {
code {
mstore(0x40, memoryguard(0x80))
let v0x5 := callvalue()
let v0x7 := iszero(v0x5)
require(v0x7)
let v0x12 := mload(0x40)
let v0x16 := codesize()
let v0x17 := sub(v0x16, 0x246)
codecopy(v0x12, 0x246, v0x17)
let v0x20 := add(v0x17, v0x12)
mstore(0x40, v0x20)
let v0x25 := add(v0x12, v0x17)
let v0x71V0xe := sub(v0x25, v0x12)
let v0x72V0xe := slt(v0x71V0xe, 0x20)
let v0x73V0xe := iszero(v0x72V0xe)
require(v0x73V0xe)
let v0x84V0xe := add(v0x12, 0x0)
let v0x5cV0x7dV0xe := mload(v0x84V0xe)
let v0x4fV0x59V0x7dV0xe := eq(v0x5cV0x7dV0xe, v0x5cV0x7dV0xe)
require(v0x4fV0x59V0x7dV0xe)
sstore(0x0, v0x5cV0x7dV0xe)
datacopy(0x0, dataoffset("data1"), datasize("data1"))
return(0x0, 0x1a8)
function require(condition) {
if iszero(condition){
revert(0x0, 0x0)
}
}
}
data "data1" hex"608060405..."上述代码是 yul 的反编译版本,核心是 sstore(0x0, v0x5cV0x7dV0xe),此处的 v0x5cV0x7dV0xe 其实就是在部署字节码最后读取的 <constructor parameters>,读取后会使用 sstore(0x0, v0x5cV0x7dV0xe) 将其写入存储。这就是构造器的作用,构造器内的函数会在部署时执行来实现对合约参数的初始化等。
yul是目前 solidity 内的底层代码,solidity 存在一种特殊的被称为IR编译模式,在此编译模式下,solidity 代码将首先被编译为yul,然后优化器会对yul代码执行优化,然后最终编译为字节码。当然,solidity 内的内联汇编必须使用yul语法。一般来说,solidity 工程师应该有能力阅读yul源代码并且可以编写yul片段代码
在上文,我们提及 EVM 在执行部署代码时要求部署代码最后返回 runtime code 在内存的位置,上述反汇编代码内的 datacopy(0x0, dataoffset("data1"), datasize("data1")) 和 return(0x0, 0x1a8) 就是在部署最后向 EVM 返回 runtime code 在内存中的位置。当 EVM 获得返回值后,就会将位于内存中的 runtime code 写入当前的 World State。之后,该地址内部就包含了智能合约代码。以下流程也显示 EOA 部署智能合约部署的全流程,当然上文中的 CounterTest 合约部署 Counter 合约的流程也与 EOA 部署合约类似:
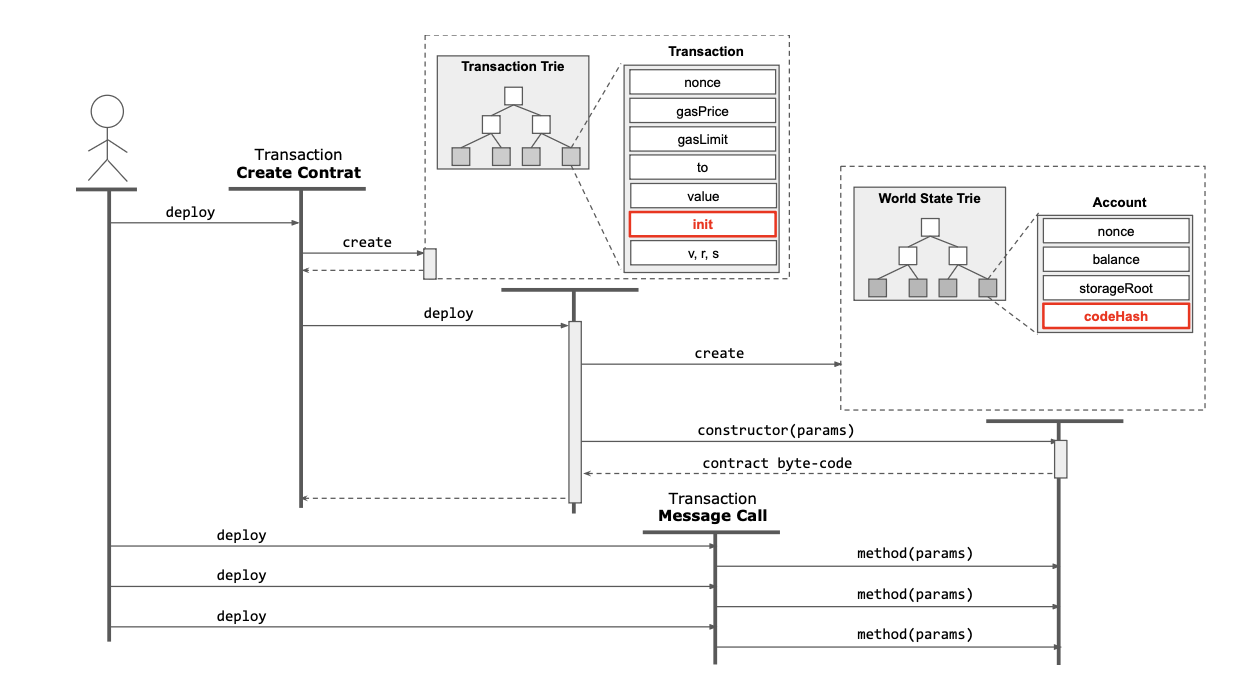
在上述流程中,我们可以发现一种特殊情况,合约在执行 init code 获取 runtime code 和初始化存储槽时,此时合约地址对应的 codehash 为空。这意味着常规的检查 codehash 确定某一个地址是否是智能合约的检测会失效。这意味着我们可以在 init code 种构造一些对外的合约调用,这些调用很有可能是为了对某些限制操作为 EOA 的合约执行某些攻击,此时被攻击合约无法正确检查到调用者是否为智能合约。此时地址的 codehash 代表当前合约为 EOA,但是实际上该地址就是智能合约。
一个在 EIP7702 启用前可以完全确定一个地址是否为智能合约的方法是检查
msg.sender与·msg.origin是否相等,目前 four.meme 仍采用了这种测试手段。在后续课程中,我们会介绍两者之间的区别。简单来说,msg.origin是交易的固有属性,不会因为多次调用改变,而msg.sender会因为调用转移而发生变化
假如智能合约使用 CREATE 操作码部署的合约地址与 EOA 部署合约时的地址计算规则一致,即使用部署者的 nonce 和地址确定性计算出合约部署后的地址。与 EOA 不同的是,智能合约的 nonce 只有在每一次部署合约后才会增加。更加准确的确定性地址部署方案使用的是 CREATE2 操作码,我们会在后续课程中介绍 CREATE2 操作码的功能和应用。但此处可以说明的是,那些前缀包含很多 0 的合约地址基本都是使用 CREATE2 部署获得的。
在构造器内,我们会使用一种特殊的 immutable 变量,比如我们可以在 src/Counter.sol 增加以下代码:
uint256 immutable public version;
constructor(uint256 _initialCount, uint256 _version) {
count = _initialCount;
version = _version;
}然后在测试内修改并增加以下代码:
function setUp() public {
counter = new Counter(0, 1);
}
function test_Version() public {
assertEq(counter.version(), 1);
}然后执行测试,我们可以看到测试中存在一个 Warning:
Warning (2018): Function state mutability can be restricted to view
--> test/Counter.t.sol:14:5:
|
14 | function test_Version() public {
| ^ (Relevant source part starts here and spans across multiple lines).该警告是指我们的 test_Version 应该被标记为 view 函数,关于此处的 test_Version 为什么使用 view 修饰,我们会在后文具体介绍。此处我们还是回到 uint256 immutable public version; 定义,此处的 uint256 指 version 类型,而 public 的含义在上文已经有所介绍,即该变量可以在合约内部读取也可以在合约外部读取,而 version 就是变量名。此处的 immutable 是一个特殊的标识,该标识代表当前变量可以在构造器内完成初始化,但是在完成初始构造后就无法在后期被修改。
而 immutable 的具体原理可以使用如下 yul 代码表示:
let v0xae := mload(0x80)
datacopy(0x0, dataoffset("data1"), datasize("data1"))
let v0xba := add(0xbf, 0x0)
mstore(v0xba, v0xae)
return(0x0, 0x1f5)上述代码内的 v0xae 就是构造器内 version 的数值。该过程简化来说就是将 immutable 类型变量拼接到原始字节码后面,即上文的 mstore(v0xba, v0xae) 然后将其一并返回给 EVM 使其在部署合约时,部署出的合约字节码最后部分包含 immutable 变量。而在合约内部所有使用 version 的地方,本质上都是使用 CODECOPY 直接在字节码内读取。
读者可以使用
cast concat-hex $(forge inspect src/Counter.sol bytecode) $(cast to-uint256 1) $(cast to-uint256 1)获得init code,然后可以直接使用反汇编工具进行反汇编
此处,我们可以顺便执行一下 forge lint。这是一个 Foundry 编写的格式化检查工具,该工具内置了很多规则用于检测代码是否符合最佳实践。比如假如我们在当前项目内执行 forge lint,会抛出以下错误:
note[screaming-snake-case-immutable]: immutables should use SCREAMING_SNAKE_CASE
--> src/Counter.sol:6:30
|
6 | uint256 public immutable version;
| ^^^^^^^
|
= help: https://book.getfoundry.sh/reference/forge/forge-lint#screaming-snake-case-immutable我们可以将 version 重命名为 VERSION,以避免上述提醒。注意,此处的提醒是 note,理论上不修改对于最终的代码编译并没有任何影响。我们可以在配置文件中使用如下配置屏蔽某些 lint 规则的提醒:
[lint]
exclude_lints = ["screaming-snake-case-immutable"]最后,我们可以执行 forge fmt 进行代码格式化。forge fmt 不会检查 lint 规则,该命令的作用只有格式化代码使代码符合 solidity 的最佳实践。
为了进一步了解构造器和合约部署,我们可以使用内联汇编的方法直接部署合约:
function setUp() public {
// counter = new Counter(0, 1);
bytes memory bytecode = type(Counter).creationCode;
address counterAddress;
assembly {
let ptr := add(add(0x20, mload(bytecode)), bytecode)add(0x20, mload(bytecode))
mstore(ptr, 0) // initialCount = 0
mstore(add(ptr, 0x20), 1) // version = 1
counterAddress := create(0, add(bytecode, 0x20), add(mload(bytecode), 0x40))
}
counter = Counter(counterAddress);
}我们此处使用 type(Counter).creationCode; 将 Counter 的 <init code> <runtime code> 字节码。此处我们需要将构造参数 _initialCount 和 _version 拼接到 type(Counter).creationCode 后面。在此处,我们需要在此处引入 bytes memory 的类型。Solidity 文档将 bytes memory 等类型称为 Reference Types。
在内联汇编中,属于 bytes memory 类型的 bytecode 变量本质上是一个数字,这个数字代表 bytecode 在内存中的 offset(或称 bytecode 在内存的起始位置)。在 Solidity 内部,bytes 等变长类型在 memory 中都是使用 <length> <data> 的编码方式。所以此处假如使用 mload(bytecode) 获得的结果是 bytecode 变量的长度。我们可以使用如下方法计算获得 bytecode 的末尾:
- 使用
mload(bytecode)获取bytecode在内存中的起始位置 - 使用
add(0x20, mload(bytecode))计算bytecode总体的长度,此处的0x20是bytecode长度 - 使用
add(add(0x20, mload(bytecode)), bytecode)计算出bytecode在内存中的末尾位置
下图显示 bytecode 在内存中的示意图:

然后,我们使用 mstore(ptr, 0) 和 mstore(add(ptr, 0x20), 1) 将 _initialCount 和 _version 参数写入内存。最后,我们使用 create 指令实现部署:
counterAddress := create(0, add(bytecode, 0x20), add(mload(bytecode), 0x40))此处的 add(bytecode, 0x20) 计算出 bytecode 数据在内存中真实的起始位置,而 add(mload(bytecode), 0x40) 计算出 bytecode 与构造器参数的总体长度。
所有的位于内存中的变长类型变量在内联汇编中其实都标识该变量在内存中的起始位置,比如
bytes memory/string memory以及以uint256[] memory为代表的数组类型
在某些情况下,我们会使用如下代码进行代码部署:
function deployUniswapV4Core(address initialOwner, bytes32 salt) public returns (IPoolManager poolManager) {
bytes memory args = abi.encode(initialOwner);
bytes memory bytecode = vm.readFileBinary("test/bin/v4PoolManager.bytecode");
bytes memory initcode = abi.encodePacked(bytecode, args);
assembly {
poolManager := create2(0, add(initcode, 0x20), mload(initcode), salt)
}
vm.label(address(poolManager), "UniswapV4PoolManager");
}使用这种代码直接读取本地内的二进制版本的 bytecode ,然后部署合约。使用这种方法部署合约的原因是因为版本不兼容问题,比如上述代码内部署的 Uniswap V4 Core 内使用的 pragma solidity 0.8.26;,将核心合约锁定为 0.8.26 版本,而我们自己的合约可能使用了 pragma solidity =0.8.30;,锁定了 0.8.30 版本,此时编译过程中,forge 会抛出版本不兼容错误,所以此时我们只能使用上述这种方法进行合约部署。
此处需要注意的我们需要一个二进制版本的合约字节码,我们在上文中介绍使用
forge inspect获取合约字节码,但获得的字节码仍为 16 进制字符串,此处我们可以使用类似forge inspect src/Counter.sol:Counter bytecode | sed 's/0x//gi' | xxd -r -p > out.bin指令将字节码的二进制版本写入out.bin文件
上述代码类似的版本是 forge-std/StdCheats.sol 内的 deployCode 函数类似,只是 deployCode 内使用了 vm.getCode 直接读取在项目的 out 编译产物输出中读取字节码。
// Deploy a contract by fetching the contract bytecode from
// the artifacts directory
// e.g. `deployCode(code, abi.encode(arg1,arg2,arg3))`
function deployCode(string memory what, bytes memory args) internal virtual returns (address addr) {
bytes memory bytecode = abi.encodePacked(vm.getCode(what), args);
/// @solidity memory-safe-assembly
assembly {
addr := create(0, add(bytecode, 0x20), mload(bytecode))
}
require(addr != address(0), "StdCheats deployCode(string,bytes): Deployment failed.");
}其中第一个参数 what 代表待部署合约的文件名,比如我们可以将上述内联汇编使用以下代码替换:
address counterAddress = deployCode("Counter.sol", abi.encodePacked(uint256(0), uint256(1)));此处我们使用了 abi.encodePacked 函数,该函数是 solidity 内置的用于 ABI 编码的函数。我们常用的 solidity 内的 ABI 编码函数包括:
abi.encode完整的 ABI 编码支持,使用语法类似abi.encode(uint256(1), bytes(hex"0102"));。编码结果严格遵许之前课程内介绍的 calldata 编码规则abi.encodePacked只支持精简版本的 ABI 编码,最大的问题是该编码规则面对动态类型不会执行插入偏移和长度等额外信息而是直接插入真实的数据内容,具体编码可以参考 Non-standard Packed Mode 文档内的内容。但用法也与abi.encode类似,我们可以使用abi.encodePacked(uint256(1), bytes(hex"0102"));调用相关功能
我们可以使用 chisel 进行演示,在终端内输入 chisel 启动 solidity REPL 模式:
➜ bytes memory test;
➜ test = abi.encode(uint256(1), bytes(hex"0102"));
➜ test
Type: dynamic bytes
├ Hex (Memory):
├─ Length ([0x00:0x20]): 0x0000000000000000000000000000000000000000000000000000000000000080
├─ Contents ([0x20:..]): 0x0000000000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000000000000000000000000000000004000000000000000000000000000000000000000000000000000000000000000020102000000000000000000000000000000000000000000000000000000000000
├ Hex (Tuple Encoded):
├─ Pointer ([0x00:0x20]): 0x0000000000000000000000000000000000000000000000000000000000000020
├─ Length ([0x20:0x40]): 0x0000000000000000000000000000000000000000000000000000000000000080
└─ Contents ([0x40:..]): 0x0000000000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000000000000000000000000000000004000000000000000000000000000000000000000000000000000000000000000020102000000000000000000000000000000000000000000000000000000000000
➜ test = abi.encodePacked(uint256(1), bytes(hex"0102"));
➜ test
Type: dynamic bytes
├ Hex (Memory):
├─ Length ([0x00:0x20]): 0x0000000000000000000000000000000000000000000000000000000000000022
├─ Contents ([0x20:..]): 0x00000000000000000000000000000000000000000000000000000000000000010102000000000000000000000000000000000000000000000000000000000000
├ Hex (Tuple Encoded):
├─ Pointer ([0x00:0x20]): 0x0000000000000000000000000000000000000000000000000000000000000020
├─ Length ([0x20:0x40]): 0x0000000000000000000000000000000000000000000000000000000000000022
└─ Contents ([0x40:..]): 0x00000000000000000000000000000000000000000000000000000000000000010102000000000000000000000000000000000000000000000000000000000000
➜ !q当然,abi.encodePacked 编码与 abi.encode 还有很多不同,限于篇幅,还是建议读者自行阅读 文档。在较新的 solidity 版本内引入 abi.encodeCall 方法,该方法用于生产调用某些函数的 calldata,与古老的 abi.encodeWithSelector(bytes4 selector, ...) returns (bytes memory) 相比,abi.encodeCall 会执行严格的类型检查,避免调用过程中传入错误参数。
abi.encodeWithSelector(bytes4 selector, ...) returns (bytes memory)功能类似abi.encode但第一个参数为函数选择器,所以在过去我们一般使用此函数在 solidity 内部生产调用某个函数的 calldata
abi.encodeCall 可以使用如下方法调用:
function test_Increment_encodeCall() public {
(bool success, ) = address(counter).call(abi.encodeCall(Counter.increment, ()));
assertTrue(success);
assertEq(counter.count(), 1);
}第一个参数需要是来自合约的函数,而第二个参数是一个包含所有函数定义参数的元组,比如:
abi.encodeCall(ILicredity.seizePosition, (1, address(0)))函数定义
我们在这里可以直接看 solidity 文档内对 function-definition 的 railroad diagram:
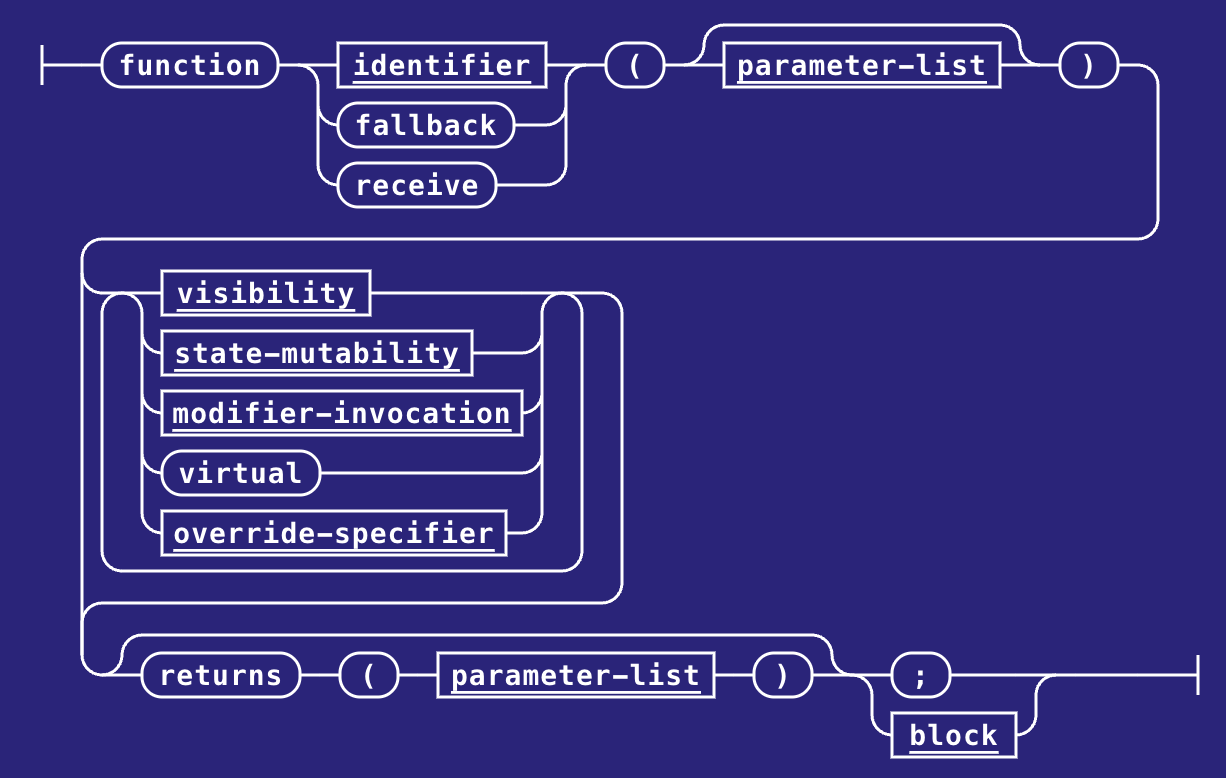
首先,我们可以看到函数名称可以为 identifier 其实就是我们确定的函数名,比如上文内的 increment 或 decrement。我们可以看到函数名称还存在两个特殊版本:
fallback该函数用于兜底,即假如调用者调用的函数不存在,那么该调用就会被fallback函数处理receive函数用于处理 calldata 为空但是包含 ETH 的交易
在 Solidity by Example 内的 Fallback 一节中,给出了如下 flowchart:
send Ether
|
msg.data is empty?
/ \
yes no
| |
receive() exists? fallback()
/ \
yes no
| |
receive() fallback()我们首先考虑 fallback 定义,我们默认使用的 fallback 默认情况下不可以接受 ETH,但我们可以将 fallback 设置为 payable 函数使其可以接受 ETH。比如如下函数定义:
fallback() payable external {
revert("Test");
}但是此时编译合约会抛出警告:
Warning (3628): This contract has a payable fallback function, but no receive ether function. Consider adding a receive ether function.
--> src/SelectorTree.sol:4:1:
|
4 | contract SelectorTree {
| ^ (Relevant source part starts here and spans across multiple lines).
Note: The payable fallback function is defined here.
--> src/SelectorTree.sol:21:5:
|
21 | fallback() payable external {
| ^ (Relevant source part starts here and spans across multiple lines).这是因为最佳实践中,调用包含 ETH 但是没有匹配到函数选择器的函数会被回退到 receive 函数。我们可以看看 fallback 在真实合约内运作原理,我们编写如下合约:
// SPDX-License-Identifier: MIT
pragma solidity =0.8.30;
contract SelectorTree {
function f1() external pure returns (uint256) {
return 1;
}
function f2() external pure returns (uint256) {
return 2;
}
function f3() external pure returns (uint256) {
return 3;
}
function f4() external pure returns (uint256) {
return 4;
}
fallback() external {
revert("Test");
}
}然后我们使用 forge inspect src/SelectorTree.sol deployedBytecode 获取实际字节码。与上述 forge inspect <file> bytecode 不同的是 deployedBytecode 获取的是纯 runtime code 而不包含 init code。然后我们将上述输出的字节码放到 bytegraph 内,我们可以获得如下图像:
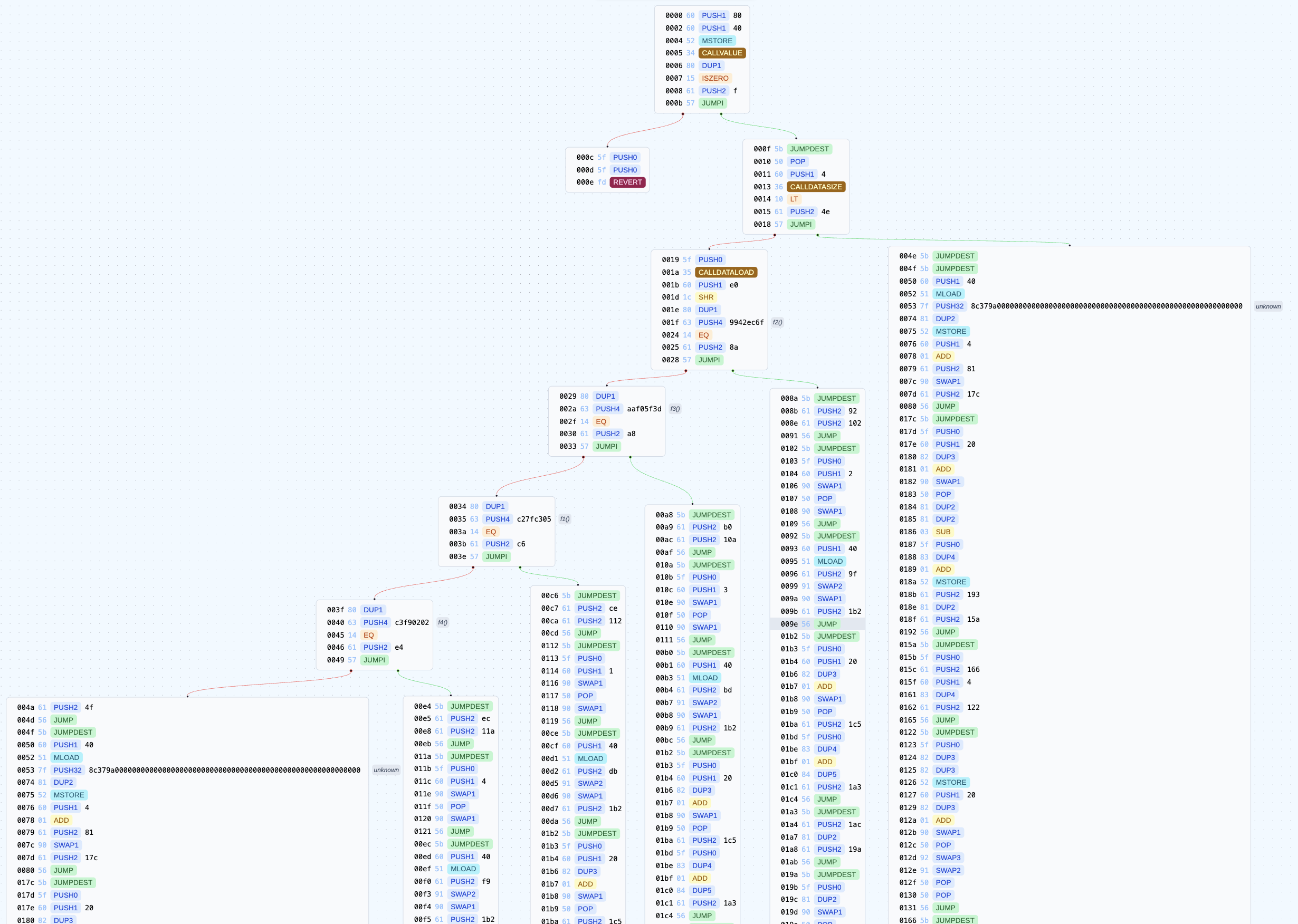
在 Solidity 内部,我们可以发现 solidity 本质上是使用二叉树对 selector 派发位置进行定位,而且按照 selector 的大小进行二分。在某些极端 gas 优化下,我们会为被频繁调用的函数分配较小的 selector。可以注意到在入口二叉树中,fallback 会被两次检测,第一次是在进入二分系统时,假如发现当前调用 calldata 内的 selector 小于目前最小的 selector 时,那么会直接跳入 fallback 函数内部,另一种情况时经过了所有的 selector 仍没有找到对应的 selector 进入,此时也会进入 fallback 逻辑。
对于 fallback 函数,其实可以讨论的不多,一种较为常见的情况是使用 fallback 函数跳过 solidity 的二分查找来实现自己的特殊的函数派发规则,比如 lotus-router 内核心函数是以下代码:
fallback() external payable {
Ptr ptr = findPtr();
Action action;
bool success = true;
while (success) {
(ptr, action) = ptr.nextAction();
...
}
}这种代码一般都在 MEV Bot 或者 DEX 聚合器内被使用。这些系统往往自己定义了一套更加高效的 calldata 编码方法,所以一般需要跳过 solidity 原生的某些系统。
知名的 solidity 优化工程师 vectorized.eth 最近发了一条关于 Solidity function dispatcher 的 推文,推荐读者阅读
对于 reveive 函数,该函数用来接收 ETH,假如智能合约没有实现 recive 函数,我们无法直接对其发送 ETH。我们可以在 test/Counter.t.sol 增加以下代码:
function test_sendEther() public {
payable(address(counter)).transfer(1 ether);
assertEq(address(counter).balance, 1 ether);
}上述代码在测试中会出现如下报错:
[FAIL: EvmError: Revert] test_sendEther() (gas: 11822)
Traces:
[11822] CounterTest::test_sendEther()
├─ [43] Counter::fallback{value: 1000000000000000000}()
│ └─ ← [Revert] EvmError: Revert
└─ ← [Revert] EvmError: Revert这是因为 Counter 合约并没有实现 receive 函数导致的,我们只需要在 Counter.sol 内增加如下函数:
receive() external payable {}此时执行 forge build 会出现如下报错:
Error: Compiler run failed:
Error (7398): Explicit type conversion not allowed from non-payable "address" to "contract Counter", which has a payable fallback function.
--> test/Counter.t.sol:23:19:
|
23 | counter = Counter(counterAddress);
| ^^^^^^^^^^^^^^^^^^^^^^^
Note: Did you mean to declare this variable as "address payable"?
--> test/Counter.t.sol:14:9:
|
14 | address counterAddress;
| ^^^^^^^^^^^^^^^^^^^^^^这是因为包含 receive 函数的合约需要被标记为 payable 的。payable 只是一个特殊的语法糖,要来标识某些函数或者某些合约可以接受 ETH。我们需要修改 Counter.t.sol 内的 setUp 函数的第 23 行为:
address payable counterAddress;在此处,我们刚好可以介绍一下 solidity 内的 ETH 转移方法,存在 3 种情况转移 ETH:
<address payable>.send(uint256 amount) returns (bool)该函数只会为 ETH 转移支付 2300 gas,且该函数返回值为false时意味着转账失败,所以开发者需要自行根据函数的返回值判断转账是否成功<address payable>.transfer(uint256 amount)该函数也只会为 ETH 转账支付 2300 gas,但假如 ETH 转账失败后会直接触发 revert 导致合约执行失败<address>.call{gas: amount, value: amount}(bytes) returns (bool, bytes memory)这是一种在 solidity 内部最底层的 ETH 转账方法,我们可以手动设置 ETH 转账的gas和value,并且我们需要手动检查call返回值中的bool判断转账是否成功
我们需要额外注意 send 和 transfer 都只会附带 2300 gas,这意味着假如接受合约内的 receive 函数代码较为复杂,那么 send 和 transfer 会因为 gas 耗尽而失败。很多时候,我们都会认为 solidity 的 send 和 transfer 转账 ETH 的 gas 效率较低,比如 v4-core 内部使用的 ETH 转账代码如下:
if (currency.isAddressZero()) {
assembly ("memory-safe") {
// Transfer the ETH and revert if it fails.
success := call(gas(), to, amount, 0, 0, 0, 0)
}
// revert with NativeTransferFailed, containing the bubbled up error as an argument
if (!success) {
CustomRevert.bubbleUpAndRevertWith(to, bytes4(0), NativeTransferFailed.selector);
}
}另一个也经常被使用的 ETH 转账代码来自 solady 的 safeTransferETH 函数,该函数实现如下:
/// @dev Sends `amount` (in wei) ETH to `to`.
function safeTransferETH(address to, uint256 amount) internal {
/// @solidity memory-safe-assembly
assembly {
if iszero(call(gas(), to, amount, codesize(), 0x00, codesize(), 0x00)) {
mstore(0x00, 0xb12d13eb) // `ETHTransferFailed()`.
revert(0x1c, 0x04)
}
}
}上述代码的问题是这些代码都会将剩余的所有 gas 都作为 ETH 转账的 gas,这种转账由于带有大量 gas 所以转账接受者可能在 receive 内部编写一些重入攻击代码。但是现代合约开发中,我们对重入攻击并不恐惧,并且有大量手段避免重入攻击,所以我们一般都直接把所有的 gas 附加到 ETH 转账中。另外,读者可以注意到上述代码内使用了两次 codesize()。但 codesize 在此处只是为了占位使用 call 操作码,call 操作码要求用户依次输入 gas, address, value, argsOffset, argsSize, retOffset, retSize。其中 argsOffset 和 argsSize 代表调用所使用的 calldata 在内存中的起始位置和长度,而 retOffset 和 retSize 代表返回值需要在内存中写入的起始位置和长度。而直接转账 ETH 是不需要参数的且不需要关注返回值的,所以上述代码内的 argsSize 和 retSize 都被设置为 0x00。而 codeszie 只是为了占位,使用 codesize() 占位的原因是 codesize() 只消耗 2 gas,是最便宜且最小的向 stack 内推入元素的指令。当然,在有了 PUSH0 操作码后,直接使用 0x00 也和 codesize 一样便宜。
在实际开发中,我们往往都将
retSize设置为0x00,这是因为函数调用返回值即使不写入内存也会在return data特殊区域报错,我们可以在执行call结束后,使用 RETURNDATACOPY 将位于return data区域的数据写回内存
我们可以使用以下代码实现类似 safeTransferETH 的功能:
function test_sendEther() public {
(bool succ,) = address(counter).call{gas: gasleft(), value: 1 ether}("");
assertTrue(succ);
assertEq(address(counter).balance, 1 ether);
}最后,我们介绍一种较为邪门的 ETH 转账方法,该方法依赖于 SELFDESTRUCT 操作码。该操作码在 EIP-6780 有了较大的变化,但目前 SELFDESTRUCT 仍具有发送 ETH 的功能。在 solady 内,存在如下代码:
/// @dev Force sends `amount` (in wei) ETH to `to`, with a `gasStipend`.
function forceSafeTransferETH(address to, uint256 amount, uint256 gasStipend) internal {
/// @solidity memory-safe-assembly
assembly {
if lt(selfbalance(), amount) {
mstore(0x00, 0xb12d13eb) // `ETHTransferFailed()`.
revert(0x1c, 0x04)
}
if iszero(call(gasStipend, to, amount, codesize(), 0x00, codesize(), 0x00)) {
mstore(0x00, to) // Store the address in scratch space.
mstore8(0x0b, 0x73) // Opcode `PUSH20`.
mstore8(0x20, 0xff) // Opcode `SELFDESTRUCT`.
if iszero(create(amount, 0x0b, 0x16)) { revert(codesize(), codesize()) } // For gas estimation.
}
}
}上述代码的作用是构建一个执行后自动销毁的合约。这种 ETH 转账是不会触发接受 ETH 合约的 receive 函数,该函数会被一些 L2 使用。因为 L2 需要为 ETH 转账支付 gas,为了避免 ETH 转账触发 receive 函数导致 L2 排序器大量 gas 消耗,以及出现错误 ETH 转账导致 state root 计算出现问题,所以 L2 在进行 ETH 转账时会使用 SELFDESTRUCT 方法。
继续回到函数定义,我们会看到在函数的 parameter-list 后,我们在函数定义可以增加 visibility:
internal函数只能在合约内部进行调用,该类型的函数不会在合约入口生成 selector 匹配,所以不能在外部被调用。而智能合约内部可以调用函数,这种调用是使用JUMP实现的,即直接跳转到函数字节码处继续执行。现代智能合约开发一般提倡所有的函数默认情况下都处于internalexternal函数刚好与internal相反,该函数只可以被外部调用,但不能被内部调用。一般来说,现代智能合约开发中除了默认使用的internal函数,我们就会使用external函数public函数本质上是internal和external的合体版本,该函数既可以在外部调用又可以内部调用。public函数生成的字节码会大于external函数生成的字节码,所以一般来说,我们提倡如果没有必要不需要使用public版本的函数private函数主要是用于面向对象中的继承规则,被标记为private的函数无法被子合约调用
上述 visibility 除了 external 外都可以被用于 storage 变量,我们可以为合约内的一个状态变量增加 public 标记,那么该变量将自动生成一个与之同名的函数,我们可以在外部调用该函数获得该状态变量的值。
然后,我们可以继续分析 state-mutability 标记。该标记用于确定函数性质,我们存在以下三种函数性质标记:
pure表示该函数是一个纯函数,该函数不会读取或者修改当前合约的任何状态,一般来说,用于纯数学计算的函数会使用pure标记,如function mostSignificantBit(uint256 x) internal pure returns (uint8 r)view表示该函数会读取合约内状态变量,但是不会写入状态变量。另外view函数也不能调用create或者create2函数。payable已经在上文有所介绍,payable用于标记某一个函数可以接受 ETH 转入,默认情况下,我们对一个非payable的函数发起带有 ETH 的调用会失败
特殊的情况是不使用 pure 和 view ,此时代表该函数可以修改状态。一般来说,我们只需要考虑某一个函数是否可以 payable 就可以,其他的标记可以等待编译器给出建议,比如:
Warning (2018): Function state mutability can be restricted to view
--> test/Counter.t.sol:26:5:
|
26 | function test_Version() public {
| ^ (Relevant source part starts here and spans across multiple lines).编译器会在输出中提醒我们需要将函数配置为 view。最后,我们介绍 modifier-invocation。这是一种特殊的函数修饰符。在介绍这种函数修饰符前,我们需要先了解什么是 modifier 函数,举一个简单的来自 openzeppelin-contracts 的例子:
/**
* @dev Throws if called by any account other than the owner.
*/
modifier onlyOwner() {
_checkOwner();
_;
}
/**
* @dev Throws if the sender is not the owner.
*/
function _checkOwner() internal view virtual {
if (owner() != _msgSender()) {
revert OwnableUnauthorizedAccount(_msgSender());
}
}我们可以将 modifier 视为一种特殊的语法宏(Syntactic macros)。在我们的 Counter.sol 内,我们可以编写如下代码:
address internal owner;
error NotOwner();
modifier onlyOwner() {
require(msg.sender == owner, NotOwner());
_;
}
function clear() external onlyOwner {
count = 0;
}在此处中,我们首先定义了 error NotOwner() 错误类型。error 类型是 solidity 在较新版本内引入的,目前使用 error 类型是抛出异常的首选。error 与函数选择器类似,抛出的内容是由 cast sig "NotOwner()" 和错误参数拼接获得。当然,此处的 NotOwner 没有参数,我们不需要考虑该问题。
我们在 clear 函数的定义中增加了 onlyOwner 方法。在编译器内,编译器会大致进行如下操作:

即我们会将被修饰的 clear 函数的代码放到 onlyOwner 的 _; 位置,然后产生的字节码就是 clear 编译后真实的字节码。修饰符函数也可以接受参数,比如 openzeppelin-contracts 内存在如下代码:
/**
* @dev Modifier that checks that an account has a specific role. Reverts
* with an {AccessControlUnauthorizedAccount} error including the required role.
*/
modifier onlyRole(bytes32 role) {
_checkRole(role);
_;
}接下来,我们编写一些测试确定 clear 函数发挥了作用:
function test_Clear() public {
counter.increment();
counter.increment();
assertEq(counter.count(), 2);
counter.clear();
assertEq(counter.count(), 0);
}
function test_Clear_NotOwner() public {
vm.prank(address(0xdeadbeef));
vm.expectRevert(Counter.NotOwner.selector);
counter.clear();
}上述代码内我们使用 vm.prank 操作码修改下一次对外调用的 msg.sender 。更加复杂的方法是使用 vm.startPrank 和 vm.stopPrank,位于两者之间的所有调用的 msg.sender 都会被修改。而 vm.expectRevert 用于检测调用是否抛出了异常。正如我们在上文所述,error 类型类似函数选择器,所以此处我们使用 Counter.NotOwner.selector 获得 NotOwner 的标识。
我们可以简单执行一下 forge lint ,我们会惊喜的发现 forge lint 给出了如下提示:
note[unwrapped-modifier-logic]: wrap modifier logic to reduce code size
--> src/Counter.sol:25:14
|
25 | modifier onlyOwner() {
| ^^^^^^^^^
|
= note: wrap modifier logic to reduce code size
- modifier onlyOwner() {
- require(msg.sender == owner, NotOwner());
- _;
- }
+ modifier onlyOwner() {
+ _onlyOwner();
+ _;
+ }
+
+ function _onlyOwner() internal {
+ require(msg.sender == owner, NotOwner());
+ }
= help: https://book.getfoundry.sh/reference/forge/forge-lint#unwrapped-modifier-logic上述提示告诉我们可以构建一个 _onlyOwner 的 internal 函数,并且使用这种方法可以降低合约的体积(reduce code size)。上述修改的原理是: 在上文,我们已经提到 modifier 内定义的代码会被编译到使用该 modifier 的函数内,比如上文中的 clear 函数。假如我们合约内存在多个函数使用了该 modifier,那么 modifier 的代码会被重复多次。为了降低这种重复的情况,我们可以在 modifier 内定义一个对内部函数(如 _onlyOwner 内部函数)的调用。这样我们在字节码内只会存在一个 _onlyOwner 的字节码,所有使用 onlyOwner 修饰符的函数都会 JUMP 到这段代码执行逻辑。
最后,关于函数定义内的 virtual 和 override 都是与面向对象中的继承有关,我们在此次课程内不再讨论。
有读者好奇为什么本文几乎跳过了所有的面向对象内继承有关的语法元素?这是因为在现代智能合约开发中,我们对 library 的使用远远大于对继承的使用。计算机编程领域近些年一直强调 组合大于继承。所以本课程在早期不会介绍继承,在介绍完成
library后,我们会介绍继承的基础规则,但不会深入讨论继承中的复杂规则。这些规则几乎不会在真实的智能合约开发中出现
存储布局
在本节中,我们注重分析之前 Counter.sol 代码内并没有深入讨论的存储变量:
uint256 public count;
uint256 public immutable VERSION;
address internal owner;对于存储变量,语法规则如下:

首先就是类型名(type-name),比如上述代码内的 uint256 等,然后就是 public 等标识符,这些标识符的含义以此为:
public如前文所述,使用该标识符的变量可以在合约内部被使用,也可以被合约外部使用变量名调用internal变量只能在合约内部被调用,不会自动生成供合约外部调用的函数,使用该类型的变量相比于使用public的变量更加节约字节码private变量类似internal变量,但附带了与继承有关的规则,即该类型的变量不可以被子合约读取(当然,实际上我们可以通过内联汇编绕过该限制)contant常量会被直接编译到字节码内,我们需要附加public或者internal来确定合约内部或者外部是否可以读取immutable也是一种常量,但是该类型常量允许在构造器进行一次初始化,一般来说,我们会使用immutable类型的常量作为合约配置字段transient是一种在 EIP-1153 内引入的功能,该功能依赖于TLOAD和TSTORE操作码。在 solidity 0.8.24 内,solidity 正式引入支持,建议读者阅读 Transient Storage Opcodes in Solidity 0.8.24 一文。transient是一种类似 storage 的状态空间,但是该状态空间会在交易完成后被清空,目前主要用于重入锁和轧差清算
关于
transient,在本文中,我们可能无法非常详细的给出介绍,该操作码最大的用途是在重入过程中保持数据状态。在 Uniswap V4 合约内,transient发挥了重要的作用。Uniswap V4 采用了基于unlock的清算机制,用户可以调用unlock函数打开 uniswap v4 core 合约,然后进行一系列代币兑换,这些代币兑换的结果会被记录到 transient storage 中,用户只需要在交易结束时保证所有记录在transient storage内部的代币数据为 0 即可。这实际上等同于传统金融领域的 轧差清算,这种清算方法规避了大量的资产转移,提供了系统的 gas 效率,也提高了开发者体验。假如读者希望进一步了解 Uniswap v4 内transient storage的作用,可以阅读笔者的 现代 DeFi: Uniswap V4 一文
接下来,我们需要讨论的核心问题是 storage 的布局问题,即每一个存储变量在 storage 的那个位置。在之前的文章内,我们介绍过 storage 本质上是一个 Key-Value 数据库,我们需要制定 slot (位置)然后写入 value (值)。那么我们的 Counter 合约内部的变量是如何排布的?
一个最简单方法是直接使用 forge inspect src/Counter.sol storage 命令,该命令返回值如下:
╭-------+---------+------+--------+-------+-------------------------╮
| Name | Type | Slot | Offset | Bytes | Contract |
+===================================================================+
| count | uint256 | 0 | 0 | 32 | src/Counter.sol:Counter |
|-------+---------+------+--------+-------+-------------------------|
| owner | address | 1 | 0 | 20 | src/Counter.sol:Counter |
╰-------+---------+------+--------+-------+-------------------------╯与我们预期一致,immutable 和 contant 类型的变量由于位于字节码中,所以并不会在此处显示位置。而 count 和 owner 会按照合约源代码内定义的前后顺序被写入从 0 开始的存储内,所以此处我们可以尝试使用内联汇编编写 increment 函数:
function increment() external {
assembly ("memory-safe") {
let c := add(sload(0), 1)
sstore(count.slot, c)
}
}修改后,我们可以发现测试还是可以通过的。此处我们需要额外注意由于存储是昂贵的资源,所以 solidity 编译器会执行存储打包以降低合约变量使用的存储槽数量。比如我们可以将 Counter 的源代码内增加 bool 的存储变量:
uint256 public count;
uint256 public immutable VERSION;
uint256 public constant MAX_COUNT = type(uint256).max;
address internal owner;
bool internal t1;此时,我们可以看到:
╭-------+---------+------+--------+-------+-------------------------╮
| Name | Type | Slot | Offset | Bytes | Contract |
+===================================================================+
| count | uint256 | 0 | 0 | 32 | src/Counter.sol:Counter |
|-------+---------+------+--------+-------+-------------------------|
| owner | address | 1 | 0 | 20 | src/Counter.sol:Counter |
|-------+---------+------+--------+-------+-------------------------|
| t1 | bool | 1 | 20 | 1 | src/Counter.sol:Counter |
╰-------+---------+------+--------+-------+-------------------------╯不能发现 owner 和 initialized 都处于 Slot = 1 的槽内部,这是因为 storage 槽的长度为 32 bytes,而 owner 的长度只有 20 bytes,且 initialized 长度只有 1 bytes,而 owner 和 initialized累加后的长度为 21 bytes,此时小于 32 bytes,所以 solidity 编译器会将两者打包到同一个槽内部。
uint256 public count;
uint256 public immutable VERSION;
uint256 public constant MAX_COUNT = type(uint256).max;
address internal owner;
bool internal t1;
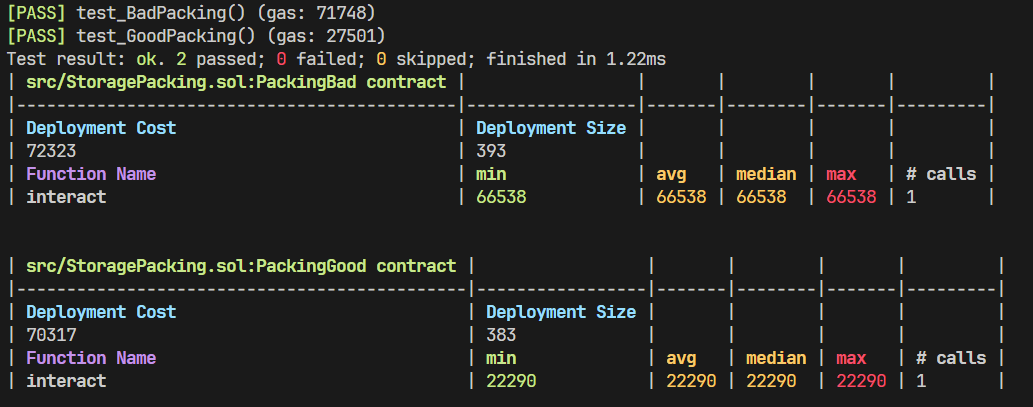
bool internal t2;上述代码内的 owner 、t1 和 t2 都会被打包到一个槽内部。在 solidity 的 Gas 优化领域,我们讨论的最基础的 gas 优化方法就是利用存储变量打包。比如以下合约是一个 gas 效率不高的合约:
contract PackingBad {
uint8 public a;
uint256 public b;
uint32 public c;
uint256 public d;
address public e;
function interact() public {
a = 12;
c = 34;
e = address(0x1234);
}
}由于 b 占据了 256 bit 所以 a 和 b 不能打包到一个存储槽内部,与此类似 c 和 d 也不能打包到一个槽内部,所以上述代码最终会占用 5 个存储槽。一种简单的优化方法如下:
contract PackingGood {
uint256 public b;
uint256 public d;
address public e;
uint32 public c;
uint8 public a;
function interact() public {
a = 12;
c = 34;
e = address(0x1234);
}
}上述代码中 e / c / a 都会被打包到一起。测试表明 PackingGood 的 gas 只有 PackingBad 的 1 / 3:
接下来,我们要讨论几个较为复杂的动态类型的存储变量,最常被使用的是 mapping 类型,最经典的 mapping 类型是被用在 ERC20 合约内用于存储某一个地址的余额情况。mapping 类型可以使用如下方法定义:
mapping (address => uint256) public data;当然,此处的 public 也可以被替换为 internal 。我们可以编写一个简单的写入方法:
function storeData(address key, uint256 value) external {
data[key] = value;
}mapping 类型的内 key 实际的写入位置是 keccak256(key, mapping.slot) 的结果。此处的 mapping.slot 是指上文中定义 data 的 slot。我们可以使用 forge inspect src/Counter.sol storage 获得,也可以在 solidity 语言中的内联汇编内使用 data.slot 获得。
我们首先编写一个简单的测试:
function test_data() public {
counter.storeData(address(1), 42);
assertEq(counter.data(address(1)), 42);
}不出意外,该测试可以通过。然后,我们尝试将 data[key] = value; 修改为内联汇编版本:
function storeData(address key, uint256 value) external {
// data[key] = value;
assembly ("memory-safe") {
// Compute the storage slot for data[key]
mstore(0x00, key)
mstore(0x20, data.slot)
let slot := keccak256(0x0, 0x40)
sstore(slot, value)
}
}此处我们需要简单介绍一条 solidity memory 布局的基础规则,即 memory 中 0x00 - 0x40 区域是可以被随意使用的,内联汇编使用这些区域不会影响 solidity 代码安全性,但是使用其他区域是不一定的,我们会在下一次课程介绍 memory 时详细介绍所谓内存安全内联汇编的规则。此处我们需要注意的,虽然 data 占用了 Slot 2,但是 solidity 并不会在此 slot 内存储任何信息。
在某些底层状态存储 debug 中,我们会启用最高日志等级的 forge test,比如我们可以使用 forge test --match-test "test_data" -vvvvv,我们可以看到如下输出:
[30314] CounterTest::test_data()
├─ [22858] Counter::storeData(ECRecover: [0x0000000000000000000000000000000000000001], 42)
│ ├─ storage changes:
│ │ @ 0xe90b7bceb6e7df5418fb78d8ee546e97c83a08bbccc01a0644d599ccd2a7c2e0: 0 → 42
│ └─ ← [Stop]
├─ [824] Counter::data(ECRecover: [0x0000000000000000000000000000000000000001]) [staticcall]
│ └─ ← [Return] 42
└─ ← [Stop]此处的 @ 后续内容为我们标记出了存储槽的变化情况,智能合约工程师可以依靠该信息判断当前合约内存储写入情况,并与自己的预期对比,这样可以发现一些较难发现的错误。
另一种常见的可变的存储类型是数组(更加准确的称呼是 IterableMapping)。数组一般使用类似 uint256[] 方法定义,数组类型包含以下三种方法:
length返回当前数组的长度,当然更加准确的编程概念是 属性push用于向数组内推入元素pop用于在数组的末尾弹出元素
当然,数组也支持使用 x[1] 这种语法进行元素访问和修改。我们可以在 Counter 内增加以下代码:
uint256[] public numbers;
function storeNumber(uint256 number) external {
numbers.push(number);
}然后在测试中增加以下代码:
function test_storeNumber() public {
counter.storeNumber(7);
counter.storeNumber(11);
assertEq(counter.numbers(0), 7);
assertEq(counter.numbers(1), 11);
}测试可以正常通过。我们可以使用 forge test --match-test "test_storeNumber" -vvvvv 观察一下存储槽变化:
├─ [44721] Counter::storeNumber(7)
│ ├─ storage changes:
│ │ @ 3: 0 → 1
│ │ @ 0xc2575a0e9e593c00f959f8c92f12db2869c3395a3b0502d05e2516446f71f85b: 0 → 7
│ └─ ← [Stop]
├─ [22821] Counter::storeNumber(11)
│ ├─ storage changes:
│ │ @ 0xc2575a0e9e593c00f959f8c92f12db2869c3395a3b0502d05e2516446f71f85c: 0 → 11
│ │ @ 3: 1 → 2
│ └─ ← [Stop]我们可以看到进行第一次 7 写入时, Slot 3 位置内的值从 0 改变为 1,而再次写入 11 时,Slot 3 位置从 1 改变为 2。实际上,Slot 3 内的数值就是数组的长度,而 0xc2575a0e9e593c00f959f8c92f12db2869c3395a3b0502d05e2516446f71f85b 实际上就是 cast keccak $(cast to-uint256 3) 的结果。
我们可以看到 0xc2575a0e9e593c00f959f8c92f12db2869c3395a3b0502d05e2516446f71f85b 就是数组在存储中的起点位置,后续所有写入都按照顺序依次写入存储槽内,比如: 第一个元素被写入了 f85b 内部,而第二个元素被写入了 f85c 内部。此处我们就不再演示如何编写对应的内联汇编代码。
实际上,pop 本质上也是先从 Slot 3 位置读取长度,然后计算出该元素在存储槽内的位置,然后将该元素删除,并将 Solt 3 内长度减 1.
由此,我们可以总结 mapping 和 array 在存储内的区别:
mapping是完全离散的数据类型,我们使用keccak256(key, mapping.slot)计算出每一个 key 所在的存储槽位置。mapping类型虽然占用mapping.slot存储槽但不会在该存储槽内写入任何数据array是连续的数据类型,我们使用keccak256(array.slot)计算出数组在存储内的起始位置,然后我们使用keccak256(array.slot) + index确定每一个元素在存储槽内的位置。另外,与mapping不同,array.slot会被写入当前array的长度以方便后续pop使用
在某些情况下,我们会使用 uint256[16] 进行存储槽占用,比如如下存储变量定义:
uint256 public count;
uint256 public immutable VERSION;
uint256 public constant MAX_COUNT = type(uint256).max;
address internal owner;
uint256[16] private __gap;
mapping(address => uint256) public data;
uint256[] public numbers;我们在 owner 和 data 之间增加 uint256[16] private __gap;,此时存储布局内就会出现一个 gap,如下:
╭---------+-----------------------------+------+--------+-------+-------------------------╮
| Name | Type | Slot | Offset | Bytes | Contract |
+=========================================================================================+
| count | uint256 | 0 | 0 | 32 | src/Counter.sol:Counter |
|---------+-----------------------------+------+--------+-------+-------------------------|
| owner | address | 1 | 0 | 20 | src/Counter.sol:Counter |
|---------+-----------------------------+------+--------+-------+-------------------------|
| __gap | uint256[16] | 2 | 0 | 512 | src/Counter.sol:Counter |
|---------+-----------------------------+------+--------+-------+-------------------------|
| data | mapping(address => uint256) | 18 | 0 | 32 | src/Counter.sol:Counter |
|---------+-----------------------------+------+--------+-------+-------------------------|
| numbers | uint256[] | 19 | 0 | 32 | src/Counter.sol:Counter |
╰---------+-----------------------------+------+--------+-------+-------------------------╯注意到 __gap 占用了 16 个存储槽,这使得 data 在存储内的位置从 18 开始。这种 __gap 会在一些可升级智能合约内看到,比如知名跨链协议 across-protocol 内存在以下代码:
// Reserve storage slots for future versions of this base contract to add state variables without
// affecting the storage layout of child contracts. Decrement the size of __gap whenever state variables
// are added, so that the total number of slots taken by this contract remains constant. Per-contract
// storage layout information can be found in storage-layouts/
// This is at bottom of contract to make sure it's always at the end of storage.
uint256[1000] private __gap;对于存储布局,最近的重大变化是在 solidity 0.8.29 增加了 Support for Custom Storage Layouts,我们可以写出这种代码:
contract C layout at 2**255 - 42 {
uint x;
}上述代码是为了适配 EIP-7702 可能导致的“脏读”问题,由于 EOA 可以任意指定某一个合约作为自己的账户功能合约,这些合约大概率会进行存储槽读写,假如用户将自己的账户功能合约切换为了另一个合约,此时可能导致新合约读取到旧合约的数据,这可能导致严重的资产安全问题。一种解决方案是旧合约内置一个清理函数,用户可以在切换功能合约前手动调用清理函数清理旧合约的数据,另一种方法就是不同的账户功能合约存储分布的起点不同来避免可能的脏读
实际上上述论述在知名的代理合约系统内也存在,代理合约系统内存在一个用于存储数据的代理合约以及一个存在功能实现的逻辑合约,用户与代理合约交互都会被转发给逻辑合约执行,但逻辑合约对存储的读写都发生在代理合约内部,假如逻辑合约实现不慎,可能导致代理合约切换逻辑合约后出现上述描述的“脏读”问题。在 Rekt 内存在 Who Got Rugged? 事件,一个开发中在未验证升级后的逻辑合约与升级前合约存储兼容性情况下直接升级了合约,这导致合约所有权丢失,导致 3000 万美金被锁定
- 本文转载自: hackmd.io/@4seasstack/le... , 如有侵权请联系管理员删除。





