Sunnyside Devnet更新 - 08/13
- testinprod
- 发布于 2025-04-26 17:34
- 阅读 868
该文章是Sunnyside Devnet在8月13日发布的更新报告,主要介绍了fusaka-devnet-3混合devnet的测试结果,包括在各种场景下的blob吞吐量、网络使用情况、共识机制和GetBlobsV2指标等。报告指出,在带宽限制下,网络仍然可以达到较高的blob吞吐量,但系统会因传播限制而受到影响,同时不同客户端在执行层的行为也存在差异。
Sunnyside Devnet 更新 - 08/13
概述
我们的 fusaka-devnet-3 规范混合 devnet 在所有场景中都实现了 72 个 blobs/块——包括带宽限制的运行——并在 60 M gas、25% 的超级节点/75% 的完整节点混合,以及 1 Gbps/500 Mbps(超级节点)和 50/25 Mbps(完整节点)的上限下,维持了 >60 个 blobs/块(10 分钟平均值)。
随着负载的增加,稳定性降低:在仅 blob 的基线中,超过约 60 个 blob 时,区块时间变得不稳定;添加 +30 M gas 时,超过约 45 个 blob 时;在带宽限制下,超过约 30 个 blob 时——这与完整节点上行链路在 25 Mbps 时饱和、传播速度较慢(峰值时平均约 7 s)、更高的证明分歧和 reorgs(在两个连续的运行中分别为 78 和 120)相吻合。
高 blob 负载下的 GetBlobsV2 因 EL 而异:Geth 显示出最高的可用性和命中率;Besu 降级最严重;Nethermind 报告的平均 blob 池可用性高于 Reth,但命中率较低,这意味着每个块完整的 blob 集较少。
简介
这是在准备与 EthPandaOps 进行的 fusaka-devnet-4 时执行的短暂的混合 devnet 运行,但它仍然产生了有用的信号。我们运行了一个 fusaka-devnet-3 规范的 devnet,其中包含 25% 的超级节点和 75% 的完整节点,对超级节点应用了千兆位上限,对完整节点应用了 25/50 Mbps 的上/下行链路。我们将 gas 限制提高到 60 M,并在“大 tx”阶段针对每个块约 30 M gas。我们逐步分阶段加载:从基线开始(仅 blobs 或仅大型交易),然后将两者结合起来,最后应用带宽限制。目的是推断出 fusaka-devnet-4,它将在相对较少的超级节点、更高的 gas 和有限带宽下,将 blob 目标推向 48/72。
Devnet 信息
设置 & 配置
| 节点组合 | 80 个节点,带有 4 个 Grandine/Lighthouse/Prysm/Teku x Besu/Erigon/Geth/Nethermind/Reth |
|---|---|
| 硬件 | 8 个 vCPU / 16GB RAM / NVMe SSD |
| 验证器分布 | 每个客户端 8 个验证器 |
| 超级节点分布 | 25% 超级节点 / 75% 完整节点 |
| 客户端镜像版本 | |
| 网络配置 |  GitHubfusaka-devnets/network-configs/devnet-ssl-8 at main · testin… GitHubfusaka-devnets/network-configs/devnet-ssl-8 at main · testin… |
测试场景
| 场景 | Blob 吞吐量 | TX 吞吐量 | 带宽 | 仪表板 |
|---|---|---|---|---|
| 1. 基线 Blobs | a) 增量 0 → 72<br>b) 稳定高负载 72 (0.5 小时) | - | - | Grafana (a) Xatu (a) Grafana (b) Xatu (b) |
| 2. 基线大型 Txs | - | ~30M gas @ 2.5~3MB 区块大小 | - | Grafana Xatu |
| 3. 带有大型 Txs 的 Blobs | a) 增量 0 → 72<br>b) 稳定高负载 72 (1 小时) | ~30M gas @ 2.5~3MB 区块大小 | - | Grafana (a) Xatu (a) Grafana (b) Xatu (b) |
| 4. 带有大型 Txs 且带宽限制的 Blobs | 增量 0 → 72 | ~30M gas @ 2.5~3MB 区块大小 | 超级节点:<br>- 1Gbps 下载<br>- 500Mbps 上传<br>完整节点:<br>- 50Mbps 下载<br>- 25Mbps 上传 | Grafana (首次运行) Xatu (a) Grafana (第二次运行) Xatu (b) |
结果
1. Blob 吞吐量
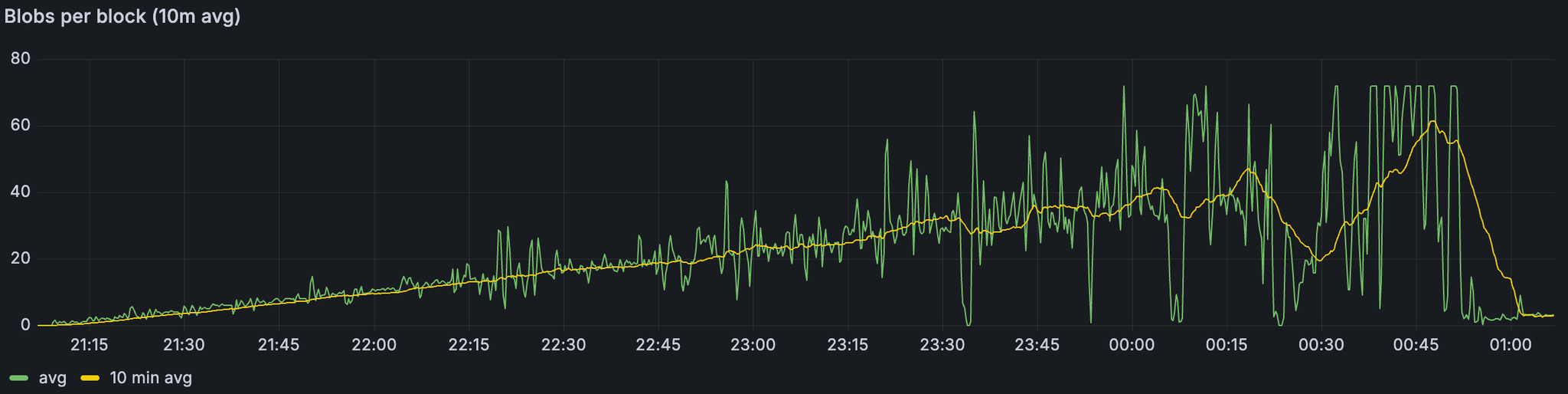
带宽限制场景下的 Blob 吞吐量
ALT
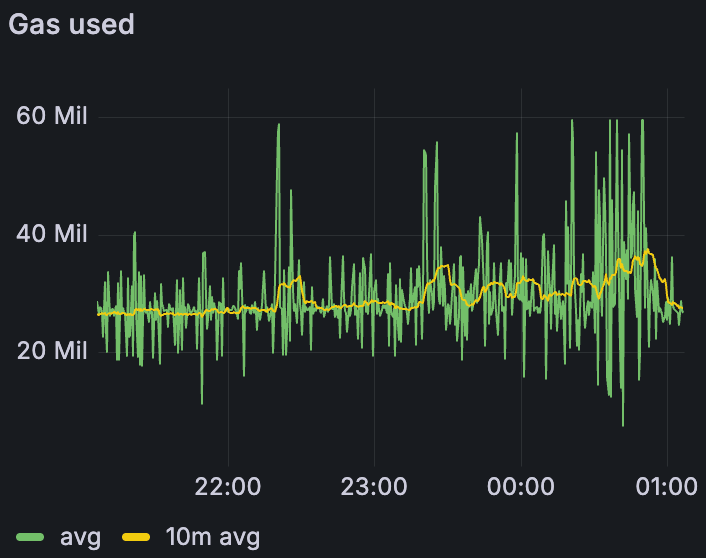
带宽限制场景下的 Gas 使用量
ALT
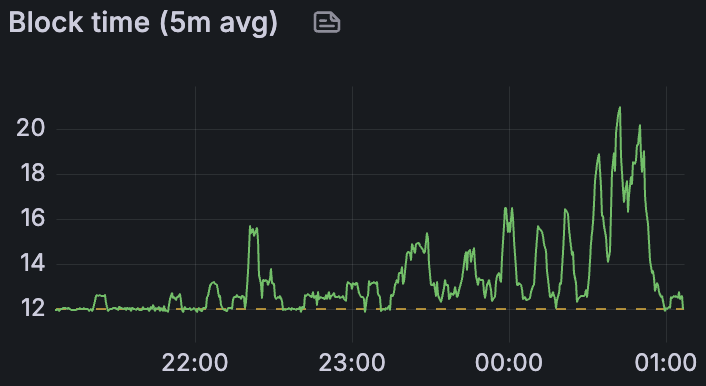
带宽限制场景下的平均区块时间
ALT
在所有场景中——包括带宽限制的运行——我们都能够在峰值时提供每个区块 72 个 blob,并在 10 分钟平均时间内维持 >60 个 blob,这表明网络可以在有利条件下满足 48/72 的目标。值得注意的是,这是在比早期测试更少的超级节点(1/4)和更高的 gas 限制 (60 M) 下实现的;上面的数字反映了带宽限制的情况。主要关注领域是区块时间:在纯 blob 基线中,不稳定 (>14 s) 始于约 60 个 blob;添加 30 M gas 交易时,不稳定始于约 45 个 blob;应用带宽约束时,不稳定始于约 30 个 blob。
| 1) 基线 blobs | 3) Blobs + 30M gas | 4) Blobs + 30M gas + 带宽限制 | |
|---|---|---|---|
| 区块时间不稳定 (≥14s) | 60 | 45 | 30 |
| 最大 10 分钟平均吞吐量 | 60 | 60 | 60 |
| 最大吞吐量 | 72 | 72 | 72 |
2. 网络使用情况
2.1. 带宽限制
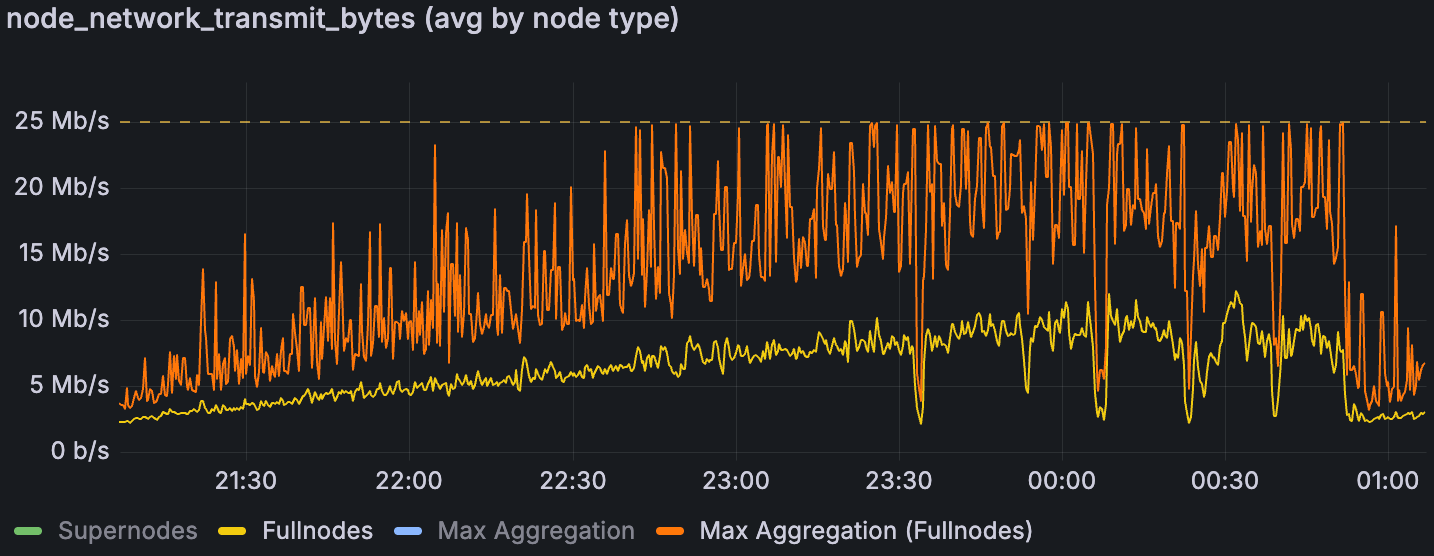
在带宽限制的场景下,完整节点的平均和最大网络传输量
ALT
在带宽上限下,超级节点有充足的余量,但完整节点的上传始终受到限制。一旦完整节点的最大聚合上传饱和了 25 Mbps 的上限,区块时间就会急剧上升,这表明上行链路是及时数据传播的瓶颈。先前的分析表明,这些峰值是聚合的,而不是单个节点的异常值(Sunnyside Devnet Updates - 07/14 - Examining individual nodes, we found no single “bad actor” n…);下面的列侧车 gossip 使用情况表明,在无限制的运行中,列 gossip 占据了峰值。我们假设完整节点峰值与提议者职责相吻合,但尚未有确凿的证据。鉴于 EIP‑7870 的 25/50 Mbps(证明者)和 50/100 Mbps(提议者)指南,如果峰值不局限于提议者,并且证明者在 25 Mbps 的上传速度下受到重大影响,则可能需要重新考虑最低验证器带宽要求。
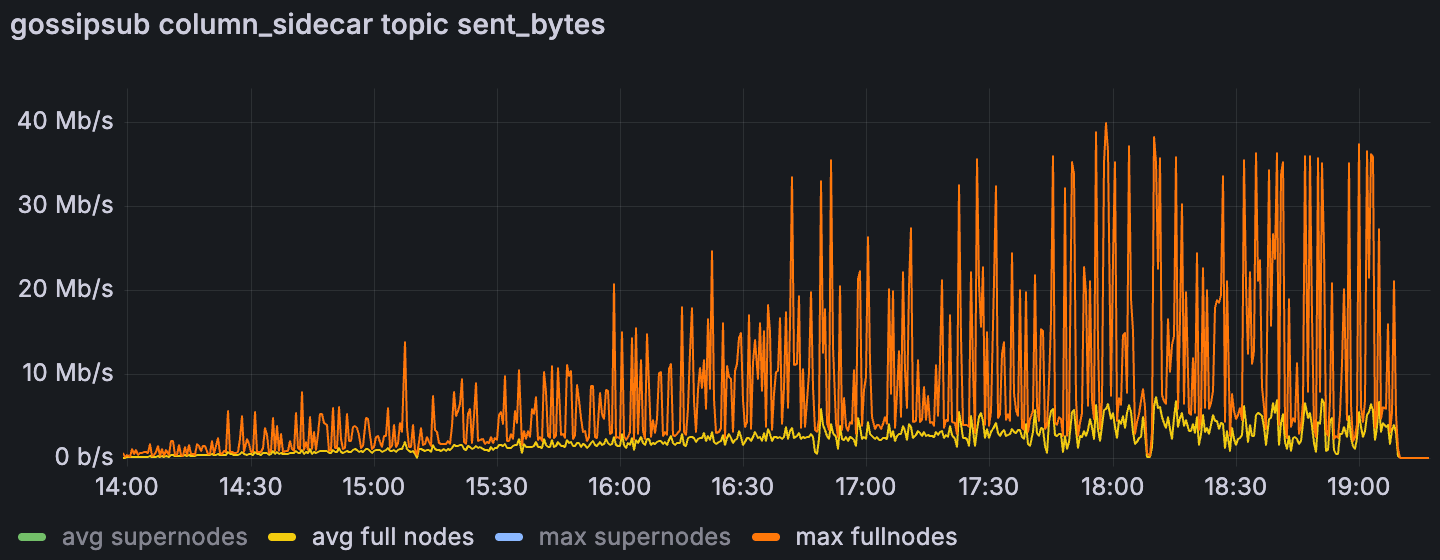
在带有大型 Txs 场景的 Blobs 中,完整节点的平均和最大列gossiping 上传使用情况
ALT
2.2. EL 互操作性
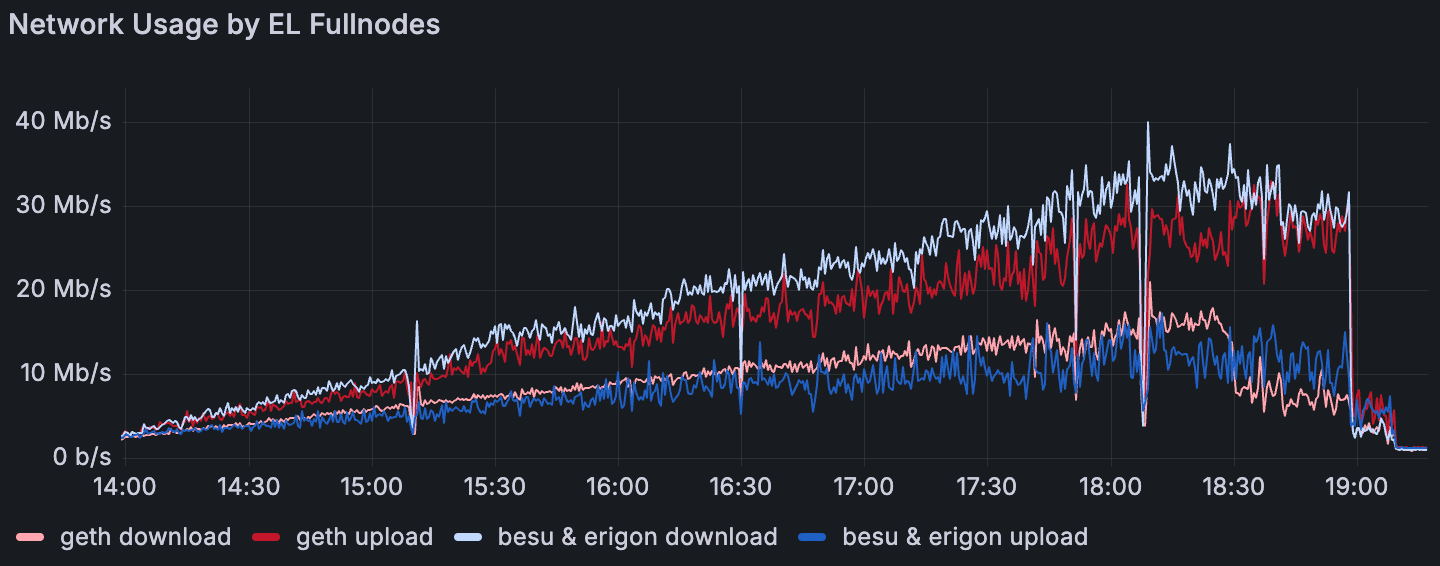
在带有大型 Txs 场景的 Blobs 中,执行层完整节点的平均网络使用情况
ALT
出现了一种一致的 EL 模式:Geth 的平均上传量超过了其下载量,而 Besu 和 Erigon 则相反;Reth 和 Nethermind 更接近对等。这种行为似乎对对等节点数量不敏感。这意味着 Geth 节点充当了强大的传播者,这与 4. GetBlobsV2 Metrics 中的 GetBlobsV2 可用性和命中率结果一致。
3. 共识
随着我们叠加压力源,传播速度降低。在最高负载下,仅限 blob 的基线中的区块传播平均约为 1.5 s(σ≈1.5 s);添加大型交易时,平均约为 3 s(σ≈2 s);在带宽限制下,平均约为 7 s(σ≈3–4 s)(p. 7)。我们失去了带宽限制窗口中列侧车传播的 Xatu 时间,但是区块级别的指标表明了类似的速度下降。传播阻力是在受约束带宽下,1. Blob Throughput 中观察到的区块时间升高的最合理的驱动因素。
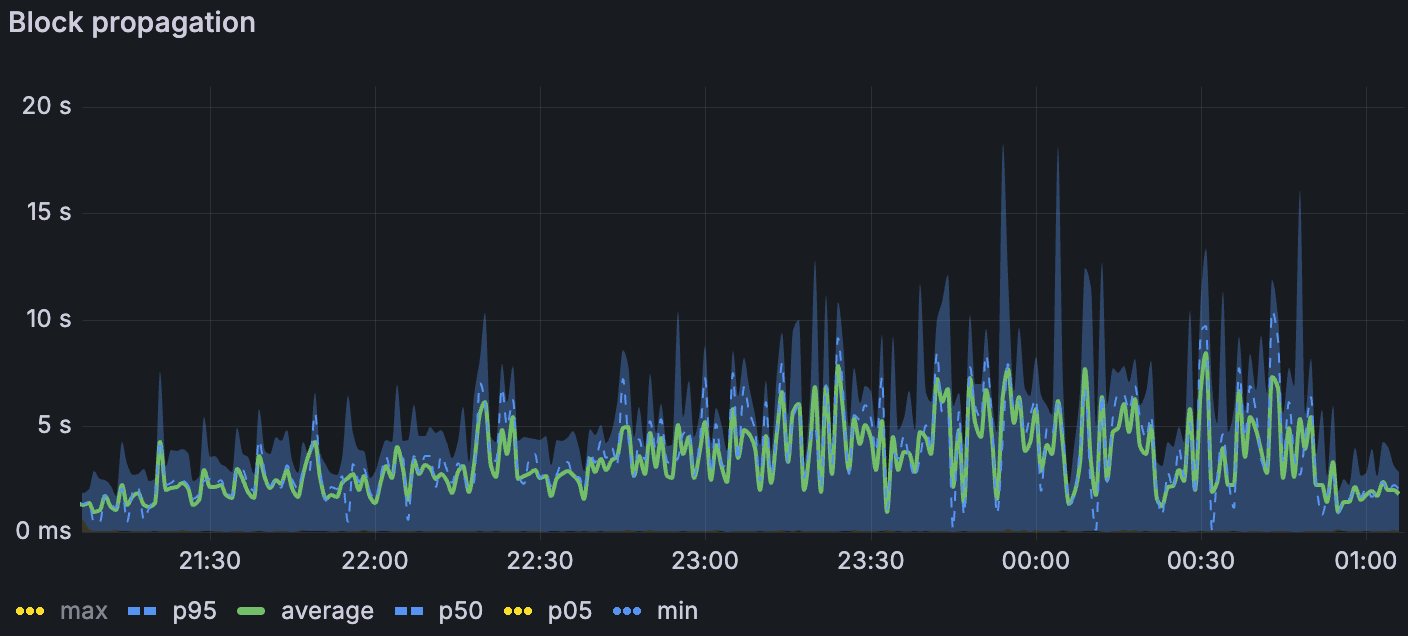
带宽限制场景下的区块传播
ALT
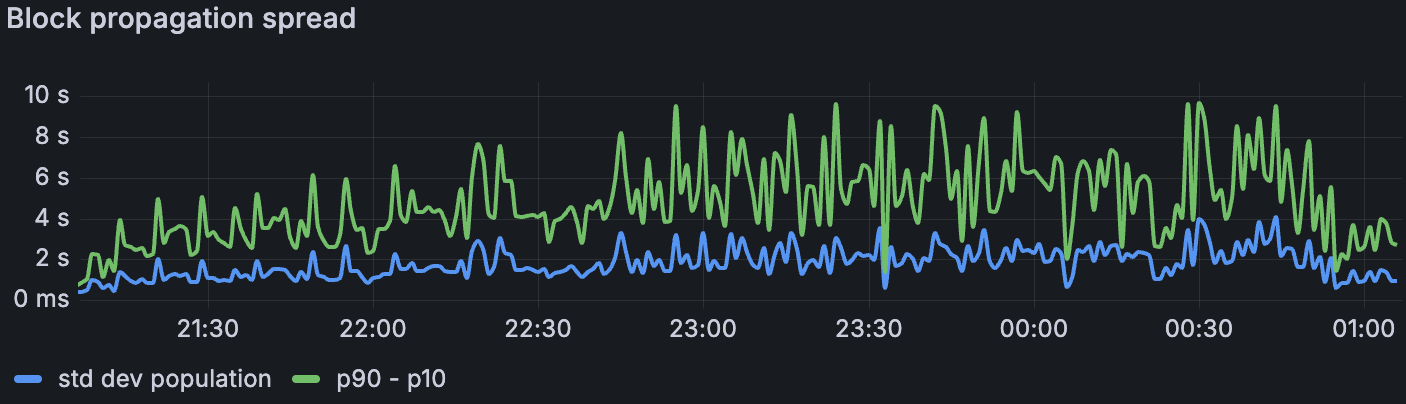
带宽限制场景下的区块传播范围
ALT
证明分歧随着负载的增加而增加——仅在大型 tx 中几乎没有,在 blobs 基线中更多(尤其是在较高的 blob 计数下),并且在组合 blobs + 大型 tx 时更多。在带宽限制下,我们还看到了 reorgs:在两次运行中,第一次限制运行中有 78 个,第二次运行中有 120 个。简而言之,受约束的带宽似乎进一步减慢了数据传播,足以导致非共识,这表现为证明分歧和 reorgs。
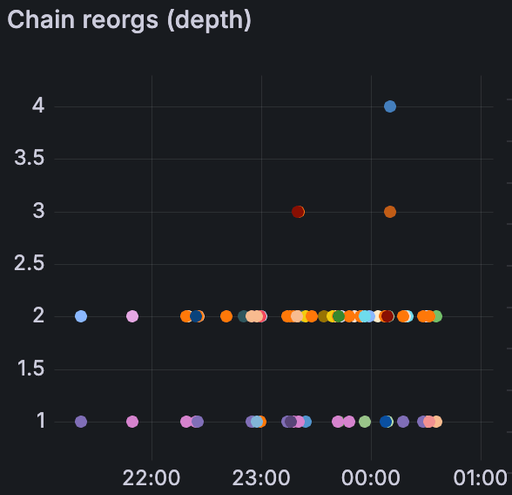
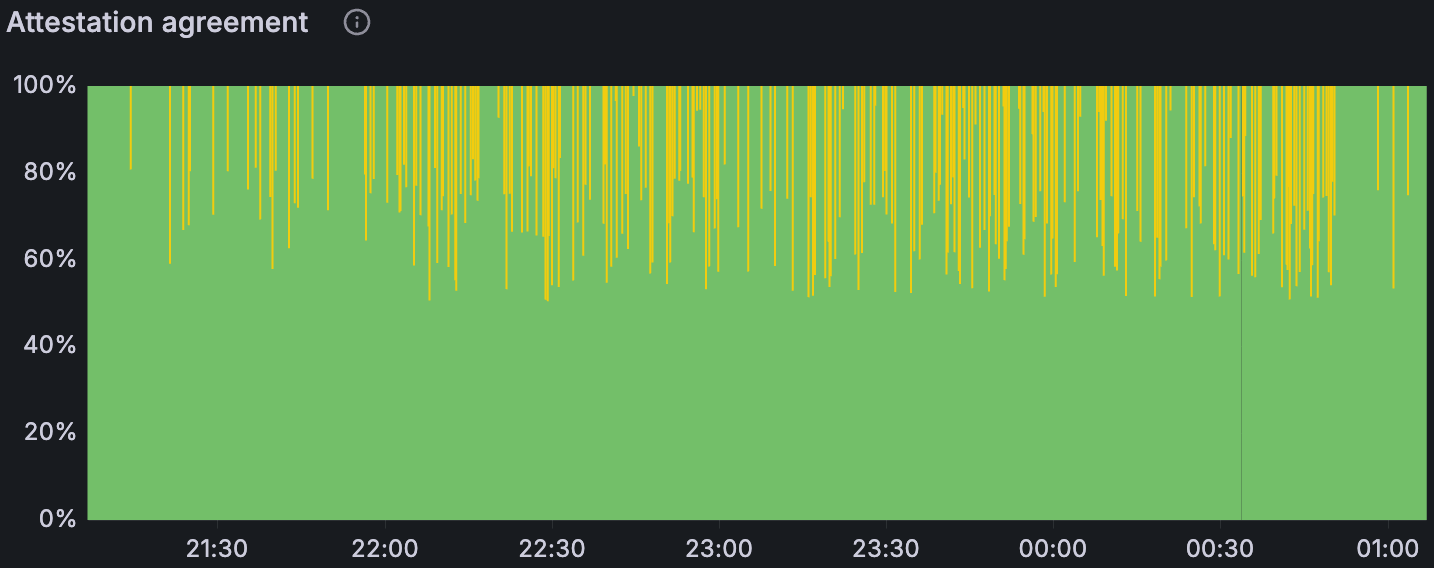
带宽限制场景下的链重组(左) 带宽限制场景下的证明协议比率(上)
ALT
4. GetBlobsV2 指标
我们检测了 EL 端的 GetBlobsV2 指标;Erigon 在测试时未公开这些指标。在组合的 blobs + 大型 tx 场景中(blob 吞吐量随时间增加),Geth 向 CL 提供了最高的 blob 可用性和命中率,这与其在 2.2. EL Interop 中较高的相对上传量一致。在高 blob 负载下,Besu 降级最严重。Nethermind 和 Reth 之间出现了一个有趣的对比:Nethermind 的平均 blob 池可用性更高,但其实际命中率却更低——这表明它更经常缺少每个区块的完整 blob 集(仅当该区块的所有 blob 都存在时,API 才会返回命中)。与 Besu、Geth 和 Nethermind 相比,Reth 的平均对等节点数量只有一半或更少,这可能解释了其较低的 blob 可用性。在带宽限制下,所有客户端的绝对可用性和命中率都有所下降,但是相对模式保持不变。下图说明了这些趋势。
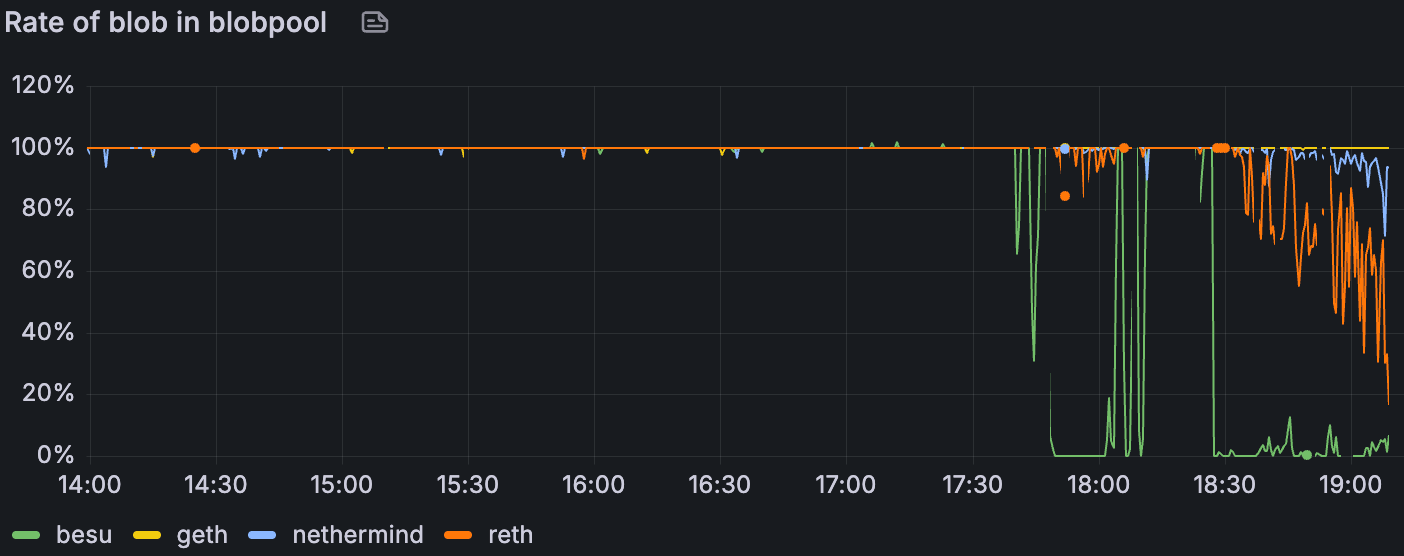
在带有大型 Txs 场景的 Blobs 中,blobpool 中的 blob 速率
ALT
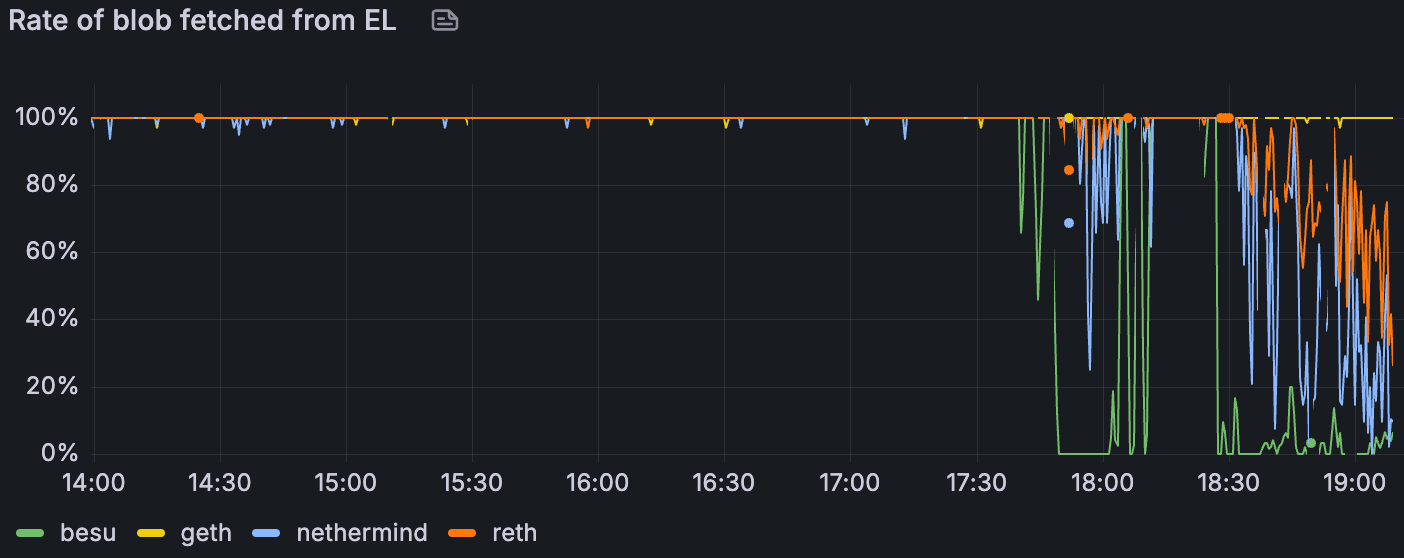
在带有大型 Txs 场景的 Blobs 中,GetBlobsV2 命中率
ALT
5. CPU & RAM 使用情况
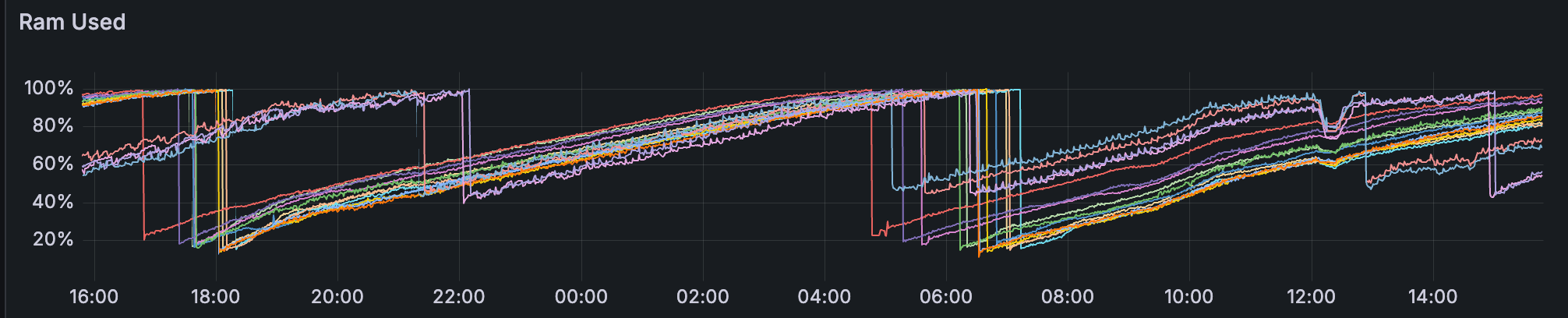
所有 Reth 实例的内存使用情况
ALT
CPU 在整个集群中通常都很舒适,很少有节点出现峰值。
Reth 的内存令人担忧:我们观察到其所有节点都存在泄漏,导致即使在没有 blob 流量的阶段也重复出现 OOM 风格的重启;这个问题在上周已经报告过了。一些 Erigon 和 Besu 节点的使用率很高,超过 80%,但没有达到限制。
结论 & 讨论
此运行表明,高 blob 吞吐量是可以实现的——即使在带宽上限下——峰值传输量为 72 个 blob,并维持 >60 blob 的 10 分钟平均值。但是,随着我们添加压力源,系统变得受传播限制:在仅 blob 的基线中,区块时间在 ~60 个 blob 之后变得不稳定;在 ~30 M gas 交易下,在 ~45 个 blob 之后变得不稳定;在应用带宽上限时,在 ~30 个 blob 之后变得不稳定。带宽上限主要影响完整节点的上传,这与观察到的平均区块传播从 ~1.5 s 阶跃式上升到最高负载下的 ~7 s 以及受约束运行中证明分歧和 reorgs 的激增相一致。在执行方面,客户端行为不统一:Geth 既传播更多数据,又表现出更高的 GetBlobsV2 命中率,Besu 在大量 blob 负载下运行困难,并且相对于 Reth 而言,Nethermind 的更高平均可用性并不总是转化为 GetBlobsV2 的完整集命中。最后,除了 Reth 内存泄漏(需要后续跟踪)外,资源余量大多足够。
展望 fusaka-devnet-4 的更高 blob 目标 (48/72) 和类似带宽限制下增加的 gas (100 M),我们预计吞吐量余量将存在,但越来越多地受到传播的限制。如果对于很大一部分节点来说,验证器上行链路仍然为 25 Mbps,那么我们应该预计区块时间不稳定和共识流失的开始时间会早于无约束运行中的 blob 计数。
后续步骤
本周我们一直在与 EthPandaOps 一起运行和分析 fusaka-devnet-4 节点。我们还将继续与 EthPandaOps 和 Ethereum P2P 团队合作进行其他测试用例,以加强 Fusaka 实施。当前正在讨论的一些测试场景包括:
Perfect PeerDAS
P2P 团队测试用例
Chaos 工具
- 原文链接: testinprod.notion.site/S...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





