PeerDAS前后Blob的Gossip和验证机制
- mikeneuder
- 发布于 2025-04-15 20:31
- 阅读 1430
本文深入探讨了以太坊在PeerDAS前后,Blob的 gossip 和验证机制。
PeerDAS 前后 Blob 的 Gossip 和验证

↑ https://whyy.org/episodes/why-we-gossip/
⋅
tl;dr; Blob 通过为 L2 交易提供确认规则,从而为以太坊的扩容做出贡献。此确认规则的价值取决于 L2 的定序器模型,并可能导致公共或私有的 L1 blob 交易(如今,80% 的 blob 在公共 mempool 中进行 gossip)。在此背景下,我们通过考虑执行层(简称 EL)的 mempool 和共识层(简称 CL)的 blob 验证,来研究协议目前如何处理 blob。然后,我们将注意力转向 PeerDAS 引入的变更(以太坊数据扩容路线图中的下一步),以展示虽然 CL 仅对总 blob 数据的一个子集进行抽样,但默认情况下,EL 的 mempool 仍然会接收所有公共 blob。这一事实降低了首先对 blob 进行分片的好处,最后,我们通过研究一些候选机制来对 EL mempool 进行水平或垂直分片,以及它们所做的权衡来得出结论。
⋅
作者:mike neuder – 2025 年 4 月 15 日(税务日快乐!🪙📅)
⋅
_感谢 Julian Ma 和 Francesco D'Amato 提出的丰富意见。 还要感谢 Alex Stokes 和 lightclients 的有益讨论。_
🔗 规范和协议文档
| 描述 | 链接 |
|---|---|
| 4844 网络规范 | ethereum/EIPs – EIP-4844: Networking |
| EL mempool 规范 | ethereum/devp2p – NewPooledTransactionHashes |
| Deneb p2p 接口 | ethereum/consensus-specs – Deneb: Blob Subnets |
| Cancun 引擎 API | ethereum/execution-apis – engine_getBlobsV1 |
| Fulu p2p 接口 | ethereum/consensus-specs – Fulu: Data Column Subnets |
📄 相关文章、笔记和仪表盘
| 描述 | 链接 |
|---|---|
| Davide 关于 Taiko 排序的文章 | Understanding Based Rollups & Total Anarchy – ethresear.ch |
| Pop、Nishant、Chirag 关于改进 CL gossip 的文章 | Doubling the Blob Count with GossipSub v2.0 – ethresear.ch |
| Francesco 的 blob mempool tickets | Blob Mempool Tickets – HackMD |
| Dankrad 的 mempool 分片文档 | Mempool Sharding – Ethereum Notes |
| DataAlways 的 orderflow 仪表盘 | Private Order Flow – Dune |
目录
(1.2). 完全无政府状态 ⇒ impatient blobs
(1.3). 旁注: “preconf” 世界中的 blob
(2). PeerDAS 之前的 Blob gossip 和验证
(3). PeerDAS 之后的 Blob gossip 和验证
(1). L2 交易生命周期
要理解 blob 交易的属性,我们首先需要理解 blob 为 L2 用户提供的 服务。Blob 是以太坊 rollup 向 L1 发布 L2 交易数据的媒介。通过这种方式,看到他们的交易在 blob 中排序并包含在 L1 上的 L2 用户可以使用它作为他们交易包含和排序的“确认规则”。
定义(非正式) – 确认规则是表明交易已被包含和排序的信号。
这个定义很模糊,因为确认规则可以有很多种。我们将在下面进行详尽的讨论,但这里有一些应该让你感到熟悉的例子。
确认规则示例:
- 六个比特币区块 – 比特币核心客户端将任何在其包含区块上构建了六个或更多区块的交易标记为已确认。
- 以太坊最终性 – 以太坊区块以批次(称为 epoch)最终确定。 一旦交易最终确定,只有在 1/3 的验证器集被证明可被罚没的情况下,它才会被回滚。 最终性是一个强大的保证,但有点慢。
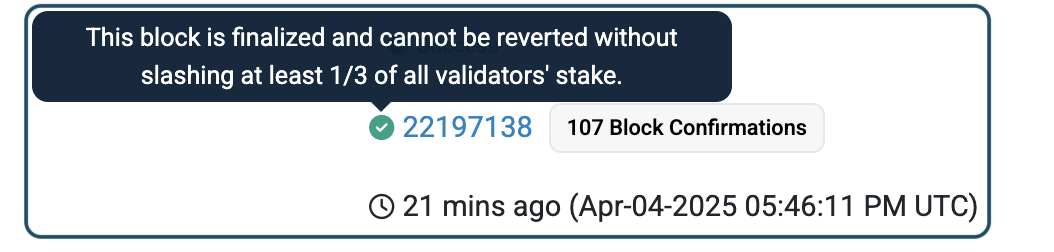
如上图所示,Etherscan 会让你知道此确认规则的强度。
- 以太坊区块包含 – 甚至在最终确定之前,以太坊交易通过包含在区块中来确认。
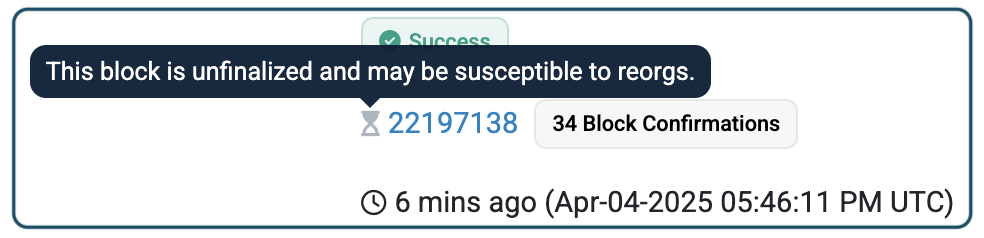
如上图所示,Etherscan 会给你一个绿色的勾,并附有一些文字,提示该区块尚未最终确定。 尽管如此,对于大多数交易而言,此确认规则已足够。
- Base 中心化定序器的绿色勾勾 – 由于 Coinbase 是唯一对 Base 交易进行排序的方,因此你只需要来自其定序器的确认即可。
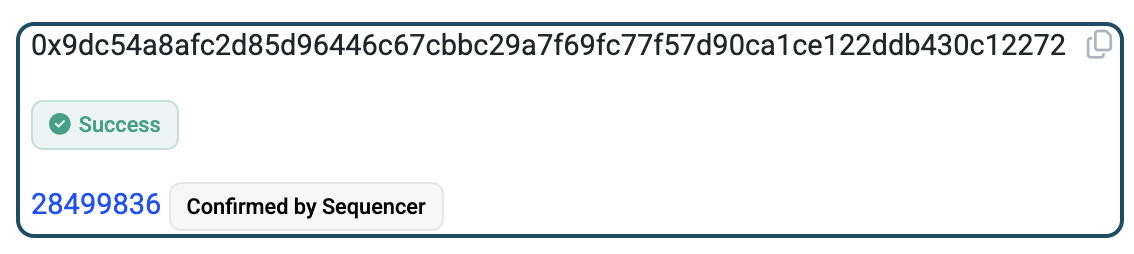
上图显示 Basescan 给你一个绿色的勾,因为定序器确认了交易。
回到 blob,L2 交易包含在登陆 L1 上的 blob 中是一种确认规则,但这种特定确认的重要性在很大程度上取决于 L2 如何对交易进行排序。 对于集中排序的 L2(例如,Base、OP Mainnet、Arbitrum),你从定序器获得的绿色勾勾是你唯一关心的确认规则,而实际将数据发布到 L1 对 L2 用户而言并不那么有意义。[1] 相比之下,对于使用完全无政府状态排序(例如,Taiko)的 based rollup,L2 交易包含在登陆 L1 区块中的 blob 中是你获得的 第一个,也是最重要的确认。 这种区别 至关重要,因为它决定了 L1 上 blob 交易的属性,我们在设计 L1 时应该考虑这些属性。
第 (1.1) 节和第 (1.2) 节分别进一步描述了中心化排序和完全无政府状态排序的 L2 交易生命周期。 我们详细检查这两种模式,因为它们是目前存在的模式。 第 (1.3) 节简要考虑了一个 based 和原生 rollup 给出“preconf”的世界的潜在影响。
(1.1). 中心化定序器 ⇒ patient blobs
让我们从最基本的 rollup 构造开始:中心化定序器偶尔将 L2 交易数据作为 blob 发布到 L1。 下图演示了此流程。
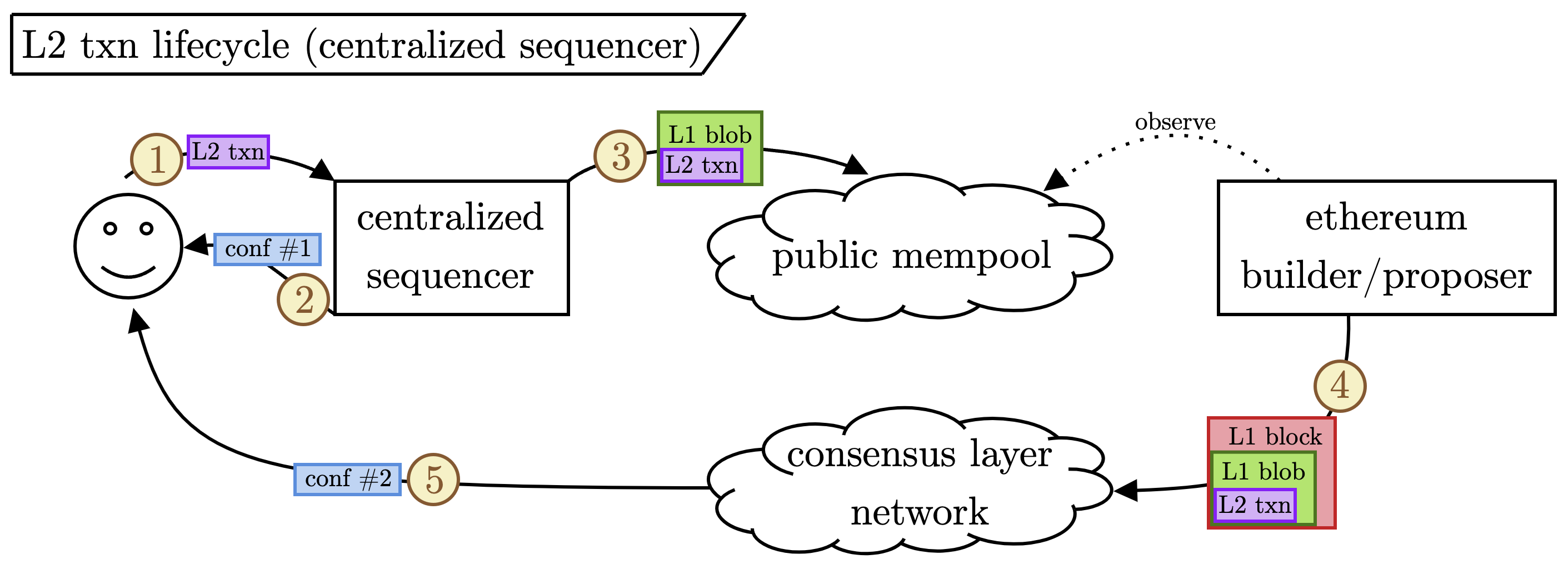
逐步注释:
- 用户将其 L2 交易提交给中心化定序器。
- 定序器立即为用户确认交易。 我们将此称为
conf #1作为第一个确认。 - 定序器将许多 L2 交易批处理到 L1 blob 中,然后将其提交到公共 mempool。
- 以太坊构建者/提议者观察 mempool,拾取 blob 以包含在区块中,并将区块发布到共识层网络。
- 当包含其交易的 blob 发布到 L1 时,用户收到他们的第二个确认。[2]
关键点: 几乎所有 L2 交易都将依赖于中心化定序器确认(conf #1),并且不会要求 L1 上的及时 blob 包含(conf #2)。 有许多针对中心化定序器在中断或审查情况提出的后备方案(例如,Arbitrum 的 "Censorship Timeout" 或 Optimism 的 "OptimismPortal")。 尽管如此,绝大多数交易将主要依赖于定序器确认。 至关重要的是,这意味着由中心化定序器 rollup 发布的 blob 对延迟不敏感。[3] 我们将这些 blob 分类为“patient”(借用 Noam 的 Serial Monopoly 论文中的定义),因为它们对 blob 包含在哪个确切的 L1 区块中(在合理的时间范围内)漠不关心。
(1.2). 完全无政府状态 ⇒ impatient blobs
转移到非常不同的定序器模型,让我们考虑 Taiko,它使用“完全无政府状态”的无需许可的定序器模型(目前 - 他们计划升级到区块构建者的允许列表,部分原因是下面概述的问题)。下图演示了这种情况下的 L2 交易生命周期。
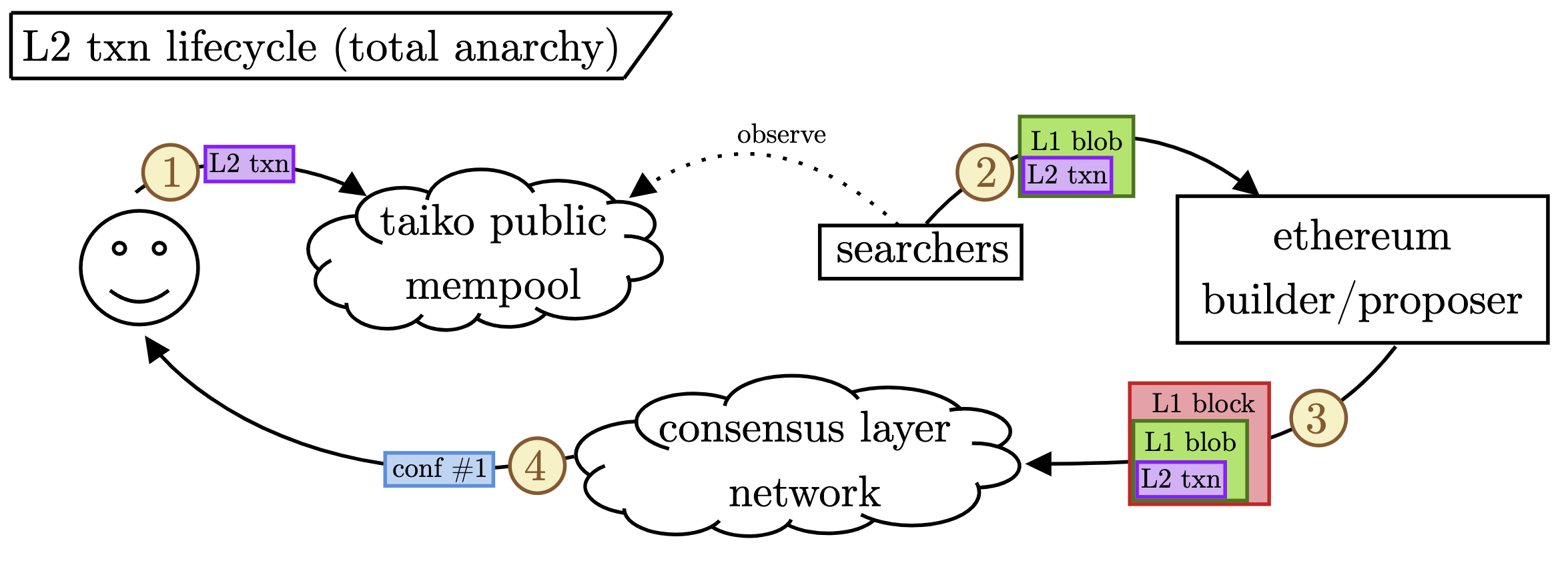
逐步注释:
- 用户将其 L2 交易提交给 Taiko mempool。
- 搜索者监听 mempool,构建包含 L2 交易的 L1 blob,并将 blob 直接发送给 L1 构建者(下面将详细介绍这种私有连接)。
- 构建者/提议者在其发布的区块中包含 blob。
- 当用户看到包含包含其交易的 blob 的 L1 区块时,他们会收到他们的第一个确认。
关键点: 所有这些 L2 交易都将依赖于 L1 上的及时 blob 包含(conf #1)。 在此之前,他们的交易将保持挂起状态。 搜索者将竞争提交具有盈利 L2 交易排序的 L1 blob。 我们称这些 blob 为“impatient”,因为 (i) 它们的及时包含和 (ii) 它们在 L1 区块中的顺序对于 L2 功能至关重要。 我们已经从经验上看到了这一点; 请参阅 Davide Rezzoli 的最新文章,其中概述了 Taiko 实验室在发布 blob 时面临不利选择,并且经常被更具竞争力的搜索者超越。
上面步骤 2 中提到的一个微妙之处:我们预计绝大多数这些 blob 会直接发送给构建者,而不是通过公共 mempool。 我们也从经验上看到了这一点,如 DataAlways 在这条推文中所述。 当存在对 L2 交易进行排序的公开竞争时,blob 将携带 MEV,因此必须通过私有通道传输,以避免被抢先交易和/或被解绑。 DataAlways 在这条推文中进行了很好的总结; 请参阅周围的线程以获取更多上下文。
(1.3). 旁注: “preconf” 世界中的 blob
"Preconf" rollup 旨在将 L2 排序权授予选择加入协议外服务的 L1 验证器。 凭借此权限,被选为提议下一个 L2 区块的下一个领导者的 L1 提议者可以向 L2 交易发出“预确认”(包含和/或排序的承诺)(preconf 本身就是一种确认规则)。 因此,也构建 L2 区块的 L1 提议者从构建 L2 区块中获得付款和 MEV。
我们不会在此处花费太多时间,因为 preconf rollup 尚未存在,但值得一提。 我们认为由向 L2 用户提供 preconf 的 L1 提议者(或构建者/中继者)构建的 blob 可能会进入公共 mempool。 考虑一个验证器(下一个注册的 preconfer),它是未来八个Slot中的 L1 提议者。 因此,他们在 96 秒内拥有对 L2 的唯一排序权。 他们发出的每个 preconf 都对应于一个 L2 交易,他们必须将其打包到 blob 中并发布到 L1(以特定顺序)。 此验证器可以按顺序发布 blob,并且不一定需要等待他们的Slot才能将 blob 包含在他们自己的区块中。 同样,这一切都有些推测性,并且取决于 L2 构造,但似乎这些 blob 可能需要在接下来的八个Slot中包含,但不会像那些使用完全无政府状态进行排序的 blob 那样对延迟敏感(如上一节所述); 这些 blob 可能最好被建模为“准patient”交易(例如,请参阅本文)。
当然,一旦到了验证器的Slot,他们只需直接包含任何剩余的包含 preconfed L2 交易的 blob。 现有设计通过罚没条件强制执行这些 preconf,因此验证器将被强烈激励以确保 blob 按照他们承诺的顺序在链上发布。 我们在此处结束此主题,但如果我们看到 preconf rollup 的使用增加,则对此进行讨论将非常重要。
(2). PeerDAS 之前的 Blob gossip 和验证
让我们根据第 (1) 节来评估我们目前的状况。 我们将 blob 分为两类:
- Patient,公共 mempool blob。
- Impatient,私有 mempool blob。
从 DataAlways 的仪表板中,我们看到大约 80% 的 blob 进入公共 mempool,并且只有 Taiko 定序器(如上所述的无需许可的集合)始终如一地发送私有 blob。 目前,此分区准确地描述了现有的 blob 流。 我们回到 L1,并考虑 blob 如何消耗参与共识的验证器的网络带宽。 验证器具有以下与 blob 相关的角色:
- gossip blob 交易,以及
- 在 attest 之前,验证区块提交的 blob 是否可用。
这些角色对每个验证器的网络资源消耗具有非常不同的影响,具体取决于它们在Slot中发生的时间。
(2.1). Blob gossip 和 mempool
如今,验证器使用他们的 EL 和 CL 客户端连接到不同的对等方。“mempool”是指 EL 客户端在包含在区块中之前听到的交易集。 如 EIP-4844 中指定的,blob 交易以基于拉取的方式进行 gossip。
“节点不得自动将其 blob 交易广播给其对等方。 相反,这些交易仅使用 NewPooledTransactionHashes 消息进行宣告,然后可以通过 GetPooledTransactions 手动请求。”
NewPooledTransactionHashes 消息用作 blob 的宣告,并且任何尚未下载该 blob 的对等方都直接使用 GetPooledTransactions 请求进行响应。 通过这种方式,进入公共 mempool 的所有 blob 都会迅速传播到每个节点。 下面的时序图演示了此过程。
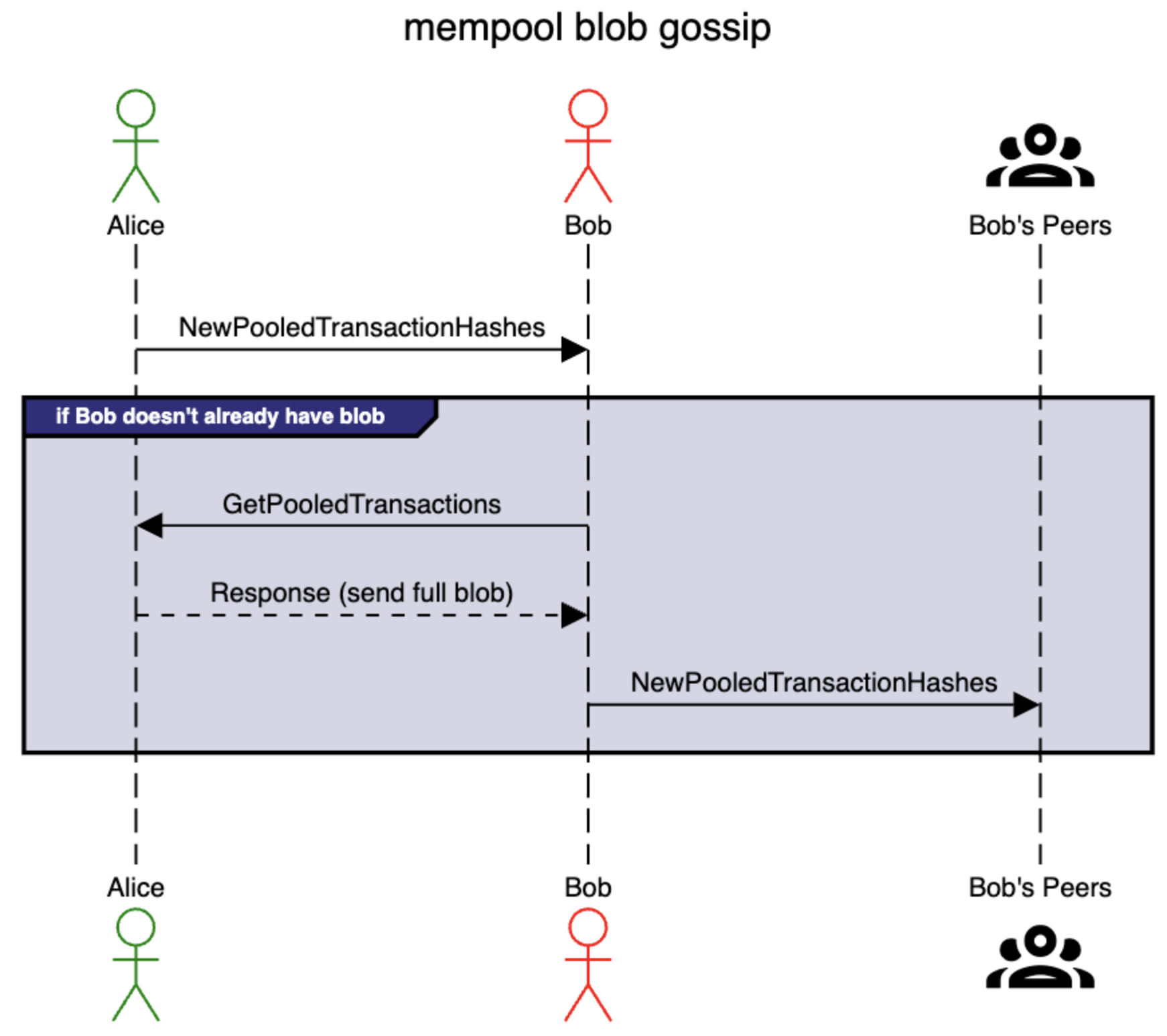
逐步注释:
- Alice 使用
NewPooledTransactionHashes通知 Bob 新的 blob 交易,其中包含交易类型、大小和哈希。 - 如果 Bob 尚未拥有该 blob,他会使用
GetPooledTransctions从 Alice 请求该 blob。 - Alice 通过将完整的 blob 发送给 Bob 来响应。
- Bob 使用
NewPooledTransactionHashes消息通知他的对等方。
关键点: 从第一个对等方请求时,每个节点应该只下载每个 blob 一次,因为他们一次按顺序从一个对等方请求 blob。 之后,他们将忽略任何包含他们已经下载的 blob 的 NewPooledTransacionHashes。
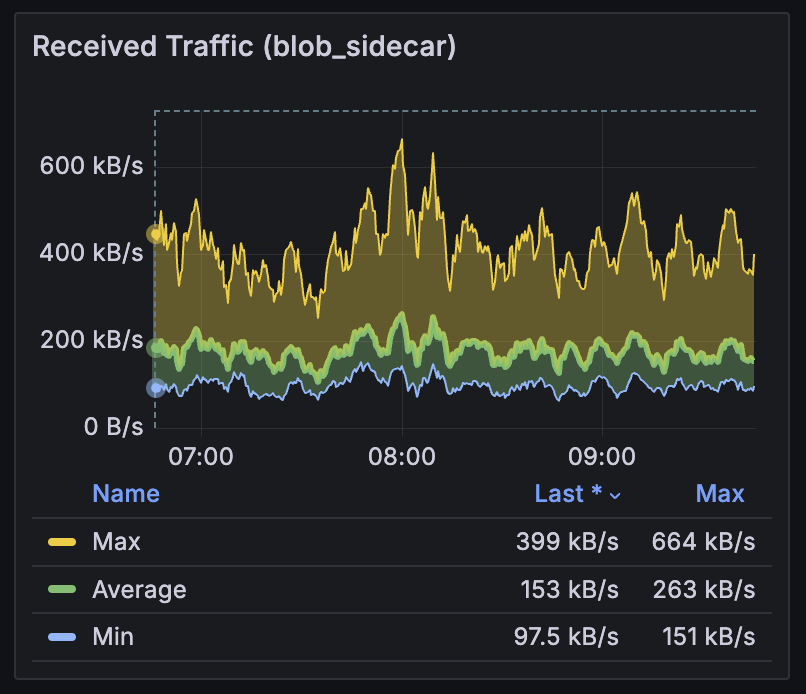
使用这种启发式方法,我们计算出今天的 blob mempool 带宽消耗应约为 32 kB/s = (128 kB/blob * 3 blob/slot) / 12 s/slot。 下图显示经验数据接近该理论值。
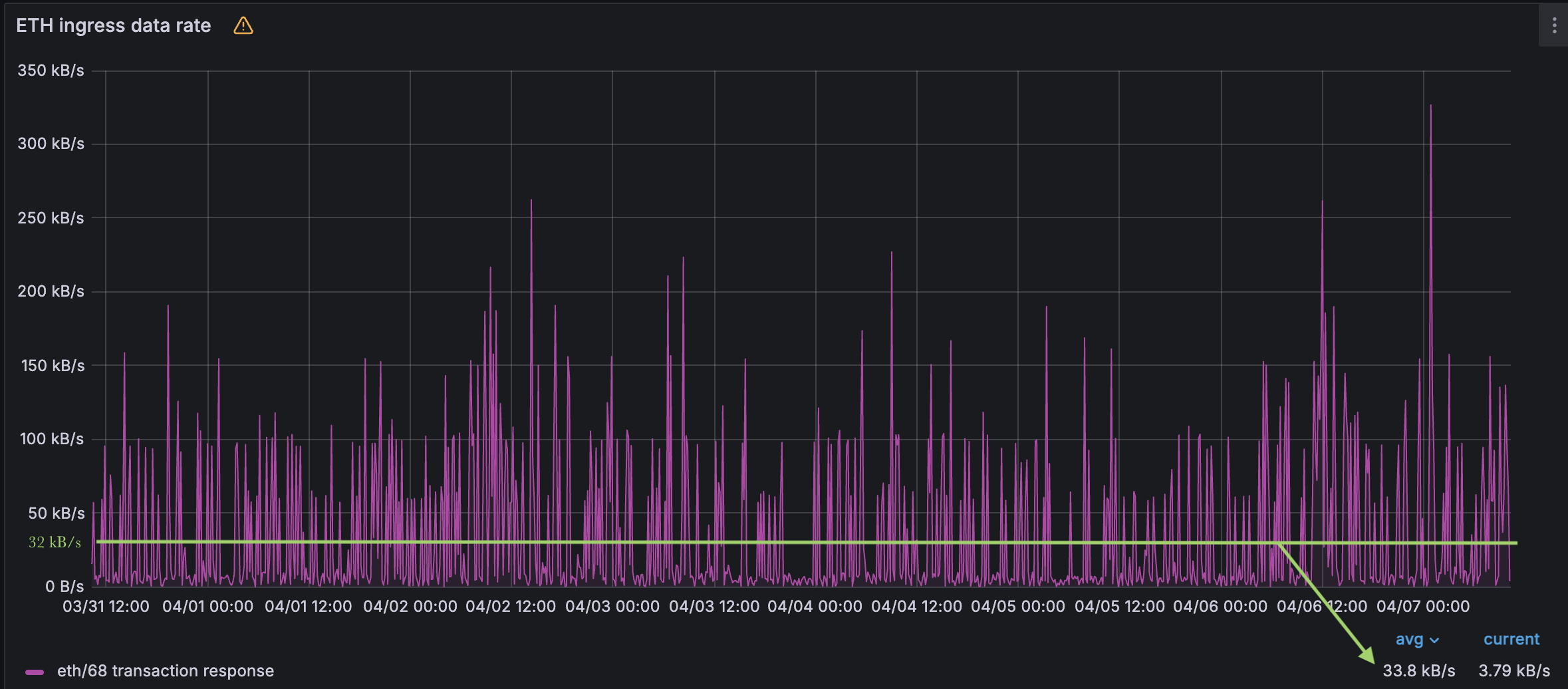
Blob mempool 入口带宽消耗。 33.8 kB/s 仅比预期的 32 kB/s 略高,这是由于每个Slot 3 个 blob 造成的。
关键点: 公共 mempool blob 分布在 12 秒的Slot内,将网络负载分布在该时间间隔内。 此外,每个节点都希望看到 每个公共 mempool blob。
(2.2). 区块验证和 blob
Mempool 解释了尚未包含在区块中的 blob 交易。 另外,当验证器收到新区块时,他们必须确保区块提交的 blob 可用以确定整个区块的有效性。 如今,验证器通过完全下载 blob 来确定此 blob 可用性。 如上所述,CL 具有与 EL 完全不同的 gossip 网络和对等方。 验证器结合使用这两种网络来接收 attest 区块所需的所有 blob 数据。 CL 的 blob 的第一个也是主要的来源是 blob 子网(blob_sidecar_{subnet_id})。 最多有六个 blob,每个验证器都连接到六个子网。 在 gossip 区块时,相应的 blob 在其各自的子网上进行 gossip(例如,在索引二中提交的 blob 在 blob_sidecar_2 上进行 gossip)。 如果验证器没有通过他们的 CL gossip 收到 blob,[4]他们可以检查他们的 EL 客户端是否在 mempool 中有该 blob(通过 EL gossip 收到); 他们使用此 engine_getBlobsV1 API。 最后,验证器可以使用 blob_sidecar_by_range API直接向其 CL 对等方请求 blob(而不是仅仅等待通过 gossip 听到它)。 但是请注意,req/resp 模型通常不用于关键路径,并且不太可能在听到信标区块和 attest 截止日期之间的时间内帮助检索丢失的 blob。 尽管如此,我们在此处包含它,因为它构成规范的一部分并且值得强调。 下面的时序图显示了此流程,其中 Bob 以三种不同的方式接收了三个 blob。
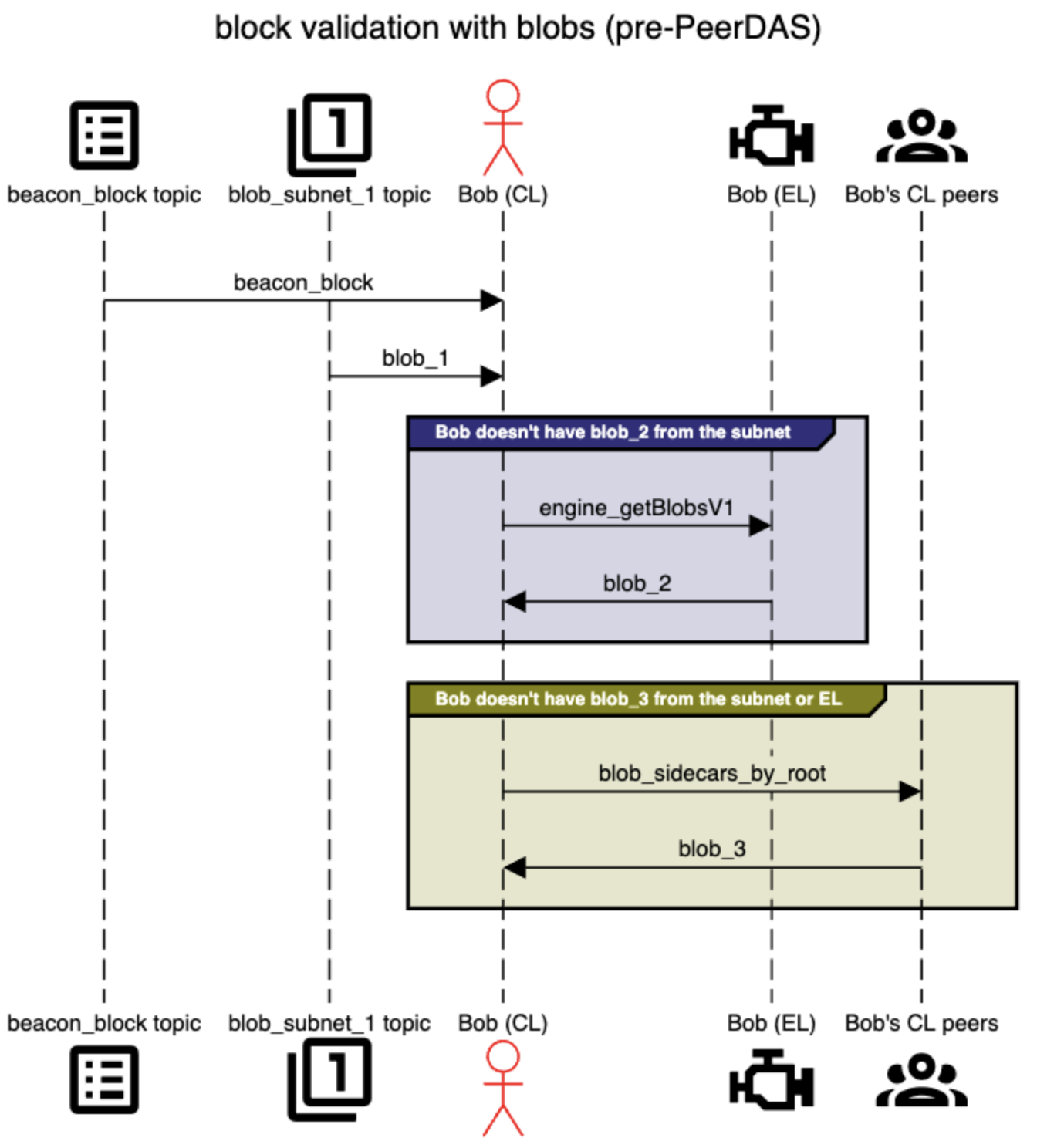
逐步注释:
- Bob 通过 pub-sub 主题收到
beacon_block,并且需要 attest 其有效性。 该区块包含三个 blob(但 blob 是单独 gossip 的)。 - Bob 通过
blob_subet_1主题上的 CL gossip 听到blob_1。 他仍然没有来任一子网的blob_2或blob_3。 - Bob 调用
engine_getBlobsV1以查看 EL 是否通过 mempool gossip 听到了任何 blob。 引擎调用返回blob_2,但不返回blob_3。 - Bob 直接向他的 CL 对等方发出
blob_3请求。
关键点: blob 子网是 推送 模型,而不是拉取。 当 Bob 通过子网收到 blob 时,他会将其转发给他的 CL 对等方,即使他们没有明确要求它。
推送模型可能会导致冗余,在这种情况下,节点会多次收到 blob,我们从经验上看到了这种情况。
通过 blob_sidecar 主题的入口流量。 平均为 153 kB/s (
≈ 每个Slot 14 个 blob),我们看到的 blob 比每个区块中包含的 blob 多大约 4 倍。
基于拉取的模型可以更有效地消耗带宽,但会以延迟为代价(在传输 blob 之前提供额外的控制消息往返)。 请参阅 Pop、Nihant 和 Chirag 的 Gossipsub v2.0,旨在减少这种放大。
(2.3). PeerDAS 之前的完整图景
下图重点介绍了 blob gossip 和区块验证的Slot内事件时间表。
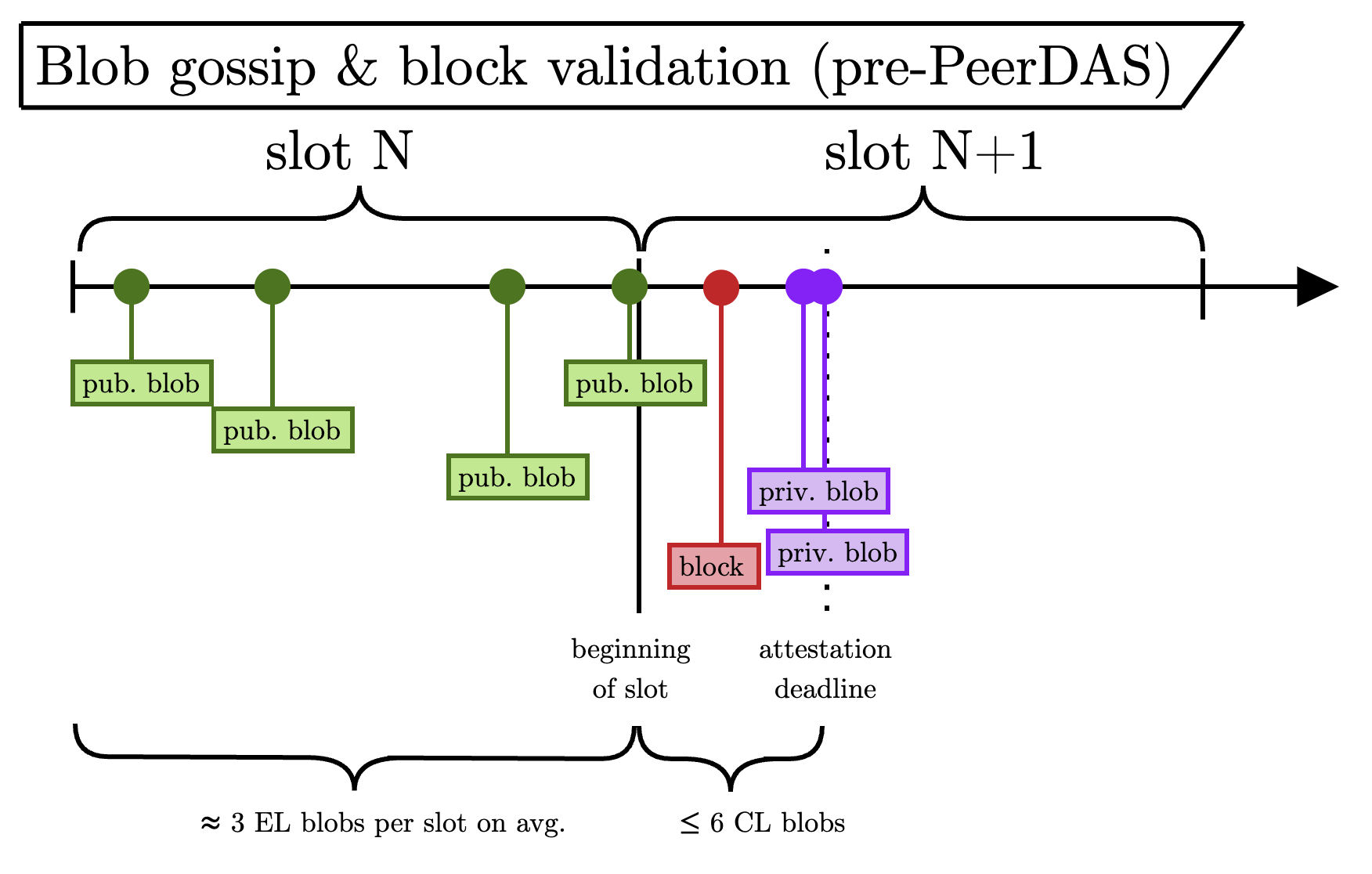
逐步注释:
- 绿色(公共)blob 在整个Slot中以均匀的速率通过 mempool (EL) 到达(它们是 patient 的,不需要在时机上具有策略性)。
- 区块在Slot开始后但在 attest 截止日期之前到达。 它提交了一些 blob,这些 blob 可能是私有的或公共的。
- 紫色(私有)blob 与该区块一起通过共识层网络到达(它们是 impatient 的,因此在时机和传播方面具有策略性)。
(3). PeerDAS 之后的 Blob gossip 和验证
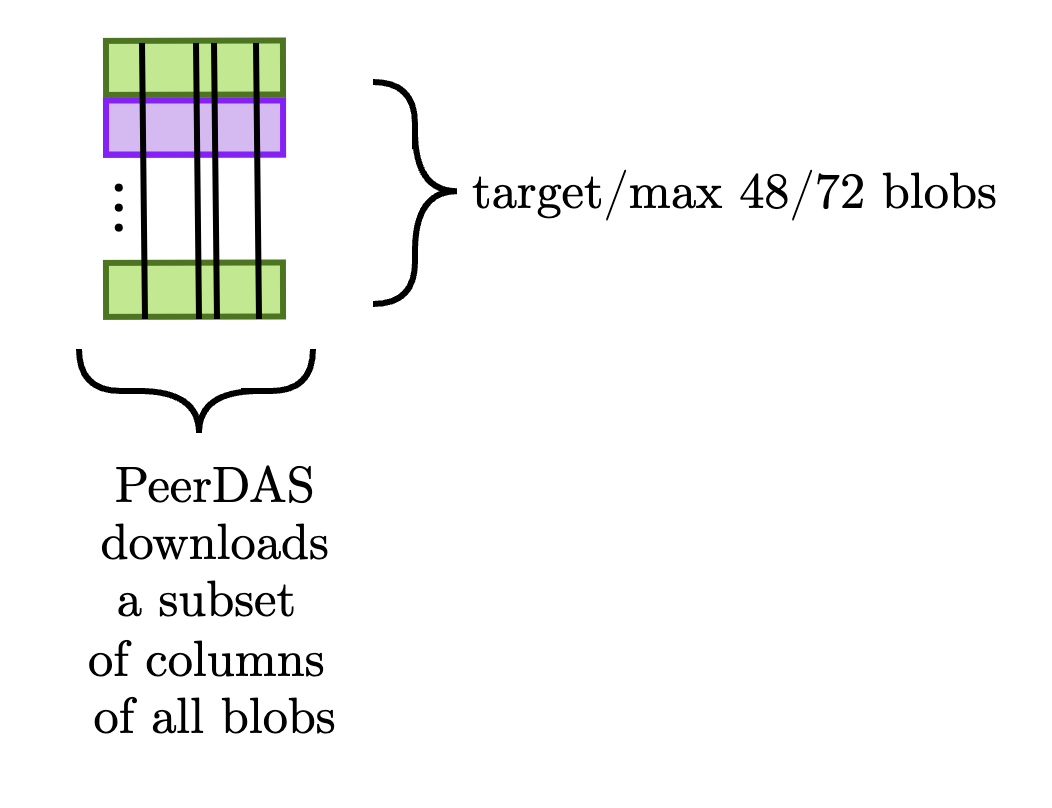
PeerDAS 被广泛认为是 Fulu/Osaka 硬分叉的主要优先事项,它改变了协议与 blob 交互的方式。 就本文而言,我们需要介绍的 PeerDAS 的唯一内容是 CL 用于验证数据可用性的柱状方法。 下图演示了这种区别。
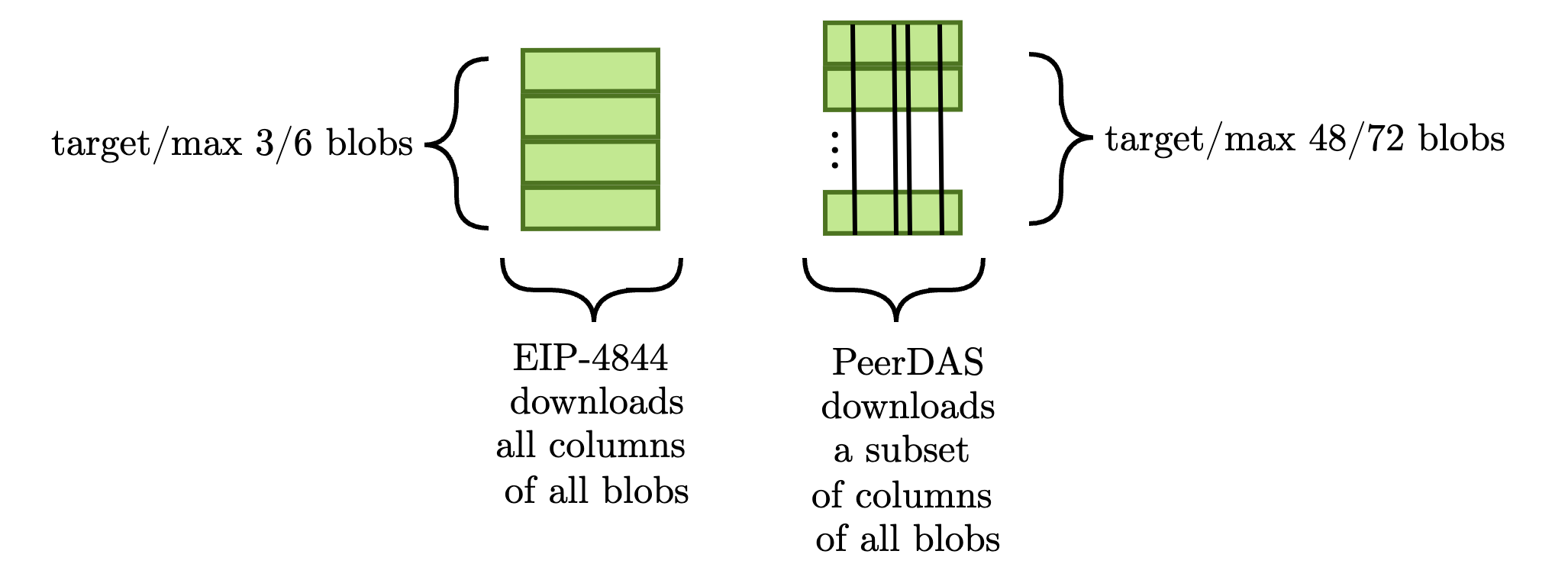
为简单起见,我们假设执行这两项任务所需的数据量大致相同。 换句话说,PeerDAS 确实 增加了每个区块的 blob 数量,但它 并没有 显着增加 CL 下载的 blob 数据量,因为每个验证器仅下载每个 blob 的一个子集(例如,如果目标是 48 个 blob,如果每个验证器下载每个 blob 的 1/8,那么总共他们下载六个 blob - 布拉格/Electra 目标– 值得的数据)。
通过此设置,我们可以考虑验证器与 blob 的交互如何变化。 我们将颠倒顺序,通过检查 CL 区块验证规则,然后再讨论 mempool 和 EL gossip。
(3.1). 区块验证和 blob
在 CL 方面,验证器仍然必须根据 blob 的可用性来确定区块有效性。 验证器不是下载完整的 blob 集,而是从每个 blob 下载一组随机的列子集。 上面描述的 blob 子网已被弃用,转而支持使用数据列 sidecar 子网(data_column_sidecar_{subnet_id}),这是 blob 的完整列进行 gossip 的主题。 关键的是,没有 部分列 的概念; 因此,每列都依赖于区块提交的完整的 blob 集。 为了验证区块,CL 检查 is_data_available 函数的结果,该函数确保节点有权访问为区块中每个 blob 分配的列。 和以前一样,让我们考虑检索列数据的三种方法:
- 通过
data_column_sidecar子网上的gossip, - 从使用
engine_getBlobsV1从 EL 获取的 blob(与之前相同,下面会详细介绍),或 - 从请求/响应域,使用新的
data_column_sidecars_by_rootAPI。
关键点: 上面的步骤 (2) 返回 blob 本身,而不是验证器需要检查的列。 为了构造整个列,只有当 它返回区块中的每个 blob(这意味着该区块不能有任何私有 blob)时,EL 才会有所帮助。
这有很多问题。 首先(也是最明显的是),如果 EL 具有该区块的完整 blob 集,那么 CL 仅对每个 blob 的一个子集进行抽样有什么意义? (以下部分将详细介绍。) CL 只是从 EL 获取每个 blob,就可以直接确认数据是否可用。 其次,如果该区块中的 任何 blob 是私有的,那么 EL 调用将无法帮助构造整个列(回想一下:没有部分列)。 所以……这很尴尬。 我们对 CL blob 验证进行了分片,但这样做消除了公共 EL mempool 对区块验证的价值(它仍然可能对区块构建有用,特别是考虑到第 1 节中描述的 patient 公共 mempool blob)。 请看下图作为示例。
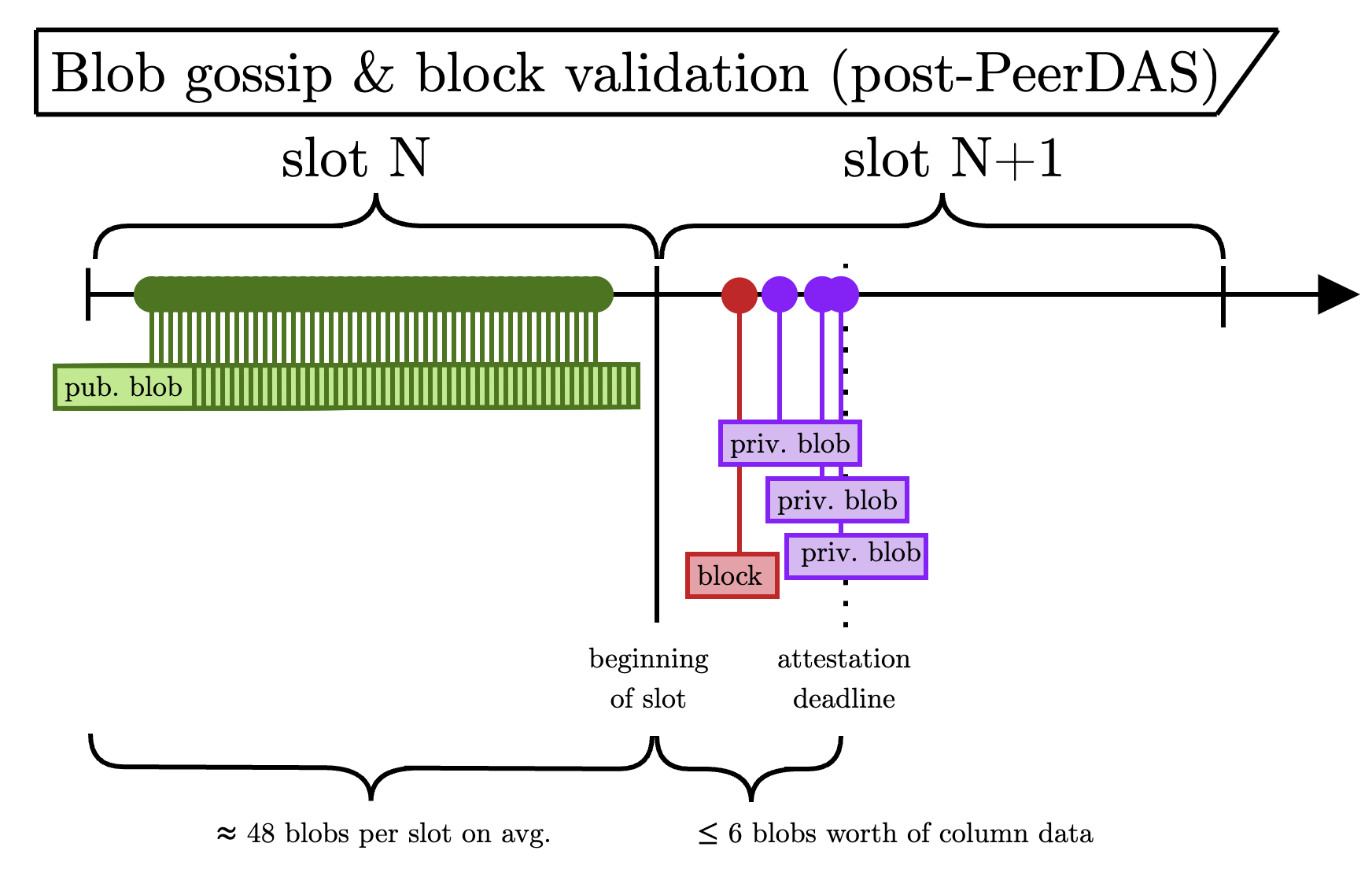
和以前一样,绿色 blob 在整个Slot中均匀到达(现在有 48 个),而紫色 blob 直到发布区块后才进行 gossip。 现在,诚实的 attest 者面临以下情况:
他们需要这些完整的列,但由于该区块中的某些私有(紫色)blob,公共 mempool 不足以进行完整的列构造。 因此,如果他们没有通过 data_column_sidecar 经由 gossip 收到完整的列,则他们无法将该区块视为有效(与之前一样,我们假设请求/响应域 API 对于区块验证的关键路径是不可靠的)。
请注意,构建者/提议者 受到高度激励 以确保数据列分布在 CL gossip 上,因为其区块的有效性取决于此。 仅仅由他们来决定如何最大限度地提高延迟来分配列 可能 是可以的。 这存在一定的风险,因为构建者可能会将延迟推到极限,从而导致低带宽的 attest 者无法足够快地下载列以进行正确的 attest。 即使在今天,构建者也会做出关于包含哪些 blob 的艰难决定,尤其是在高度波动期间 - 请参阅此处的讨论。 即使我们很乐意将大部分 blob 分配留给构建者(尽管这是一个很大的假设),我们仍然存在 blob gossip 在 blob 吞吐量显着增加的情况下。
(3.2). Blob gossip 变更
现实情况仍然是 EL blob gossip 仍然接收所有公共 blob,从而消除了仅在 CL 上对每个 blob 的一个子集进行抽样的好处。 我们计算出三个 blob 的平均速度为 32 kB/s; 在 48 个 blob 的情况下,这将是 512 kB/s = (128 kB/blob * 48 blob/slot) / 12 s/slot。 这是一个显着的增长,并且对于许多独立/小型运营商来说,潜在的带宽太大。 因此,值得考虑对 gossip 进行更改以缓解这种情况。 为了结束本文,我们将考虑 EL mempool 的水平和垂直分片,每种分片都可以通过不同的复杂性和有效性来实现; 此列表绝不是详尽无遗的,并且每个提案可能都值得用整篇文章- 最小化带宽消耗并镜像CL。 从第一性原理来看,很明显这是“更正确”的方法,因为它镜像了CL的垂直分片。回想一下,CL上数据分片的全部意义在于消除节点下载完整 blob 集的需求。水平分片EL和垂直分片CL严重限制了EL mempool的效用。
- 保留公共mempool。 通过显式解决带宽问题,存在一条清晰的路径,可以保留公共 mempool 作为耐心 blob 利用的默认路径。
- Blob 票证可以用作 blob 包含列表机制。(更具推测性)因为协议明确知道谁有权通过 mempool 发送 blob,所以也可以使用证明者来强制包含及时的 blob(类似于 FOCIL)。
缺点
- 实施复杂。 显然,这些系统中的任何一个都比上面列出的任何水平分片选项都难得多;工程开销很大(尤其是在修改分叉选择规则的情况下)。
- 经济上难以推理。 除了工程挑战之外,这些提案还伴随着一系列经济问题。我们如何给票证定价?Rollup 将如何制定购买 mempool 访问权限与直接去找构建者的策略?对于一个健壮的声誉系统,需要哪些启发式方法?这里的设计空间非常广阔,可能简单的规则就可以奏效,但这并不明显。
(4). 总结和结论
我们讨论了很多。总结如下:
- L2 交易有多种确认规则,其中一种是包含在 L1 blob 中。L1 blob 确认根据 L2 的排序模型提供非常不同的效用。这些确认也对 L1 blob 交易的属性产生影响。
- 1.1. 由具有中心化排序器的 L2 生成的 blob 既不携带 MEV,也不对延迟特别敏感。这使得它们很可能成为公共 mempool 的候选者,并且今天 80% 的 blob 都符合这种模型。
- 1.2. 由具有无需许可排序器的 L2 生成的 blob(例如,在 Taiko 的完全无政府状态中)携带 MEV,并将竞争 L1 包含。这种范式导致私有 blob 流,今天 20% 的 blob 遵循这条路径(仅限 Taiko 的 blob)。
- 1.3. 在基于/原生 rollup 中,L1 验证器发出预确认,包含 L2 交易的 blob 可能会在某种程度上对延迟敏感,具体取决于 L2 的构造。我们在这里没有花太多时间,因为这些rollup 尚未出现。
- 我们通过考虑 EL mempool 和 CL blob 验证来检查协议今天如何处理 blob。
- 2.1. EL 使用基于拉取的模型将 blob 下载到 mempool 中。期望每个节点最终都具有相同的公共 blob 集视图。此 blob 下载在 slot 中均匀分布。
- 2.2. CL 必须确定 blob 可用性,作为区块验证逻辑的一部分。在 CL 上了解 blob 的主要场所是通过 blob 子网上的 CL gossip,但他们也可以检查其 EL mempool 中区块引用的 blob。CL 只有四秒钟的时间来检查他们是否有权访问所有 blob,然后才能证明该区块。
- PeerDAS 改变了协议与 blob 交互的方式。具体来说,CL 现在只下载每个 blob 的一个子集,而不是整个 blob。
- 3.1. 数据列和信标区块在 CL 上进行 gossip(完整的 blob 不再通过 blob 子网进行 gossip)。因此,在 EL 上进行 gossip 的任何 blob 仅在没有私有 blob 的情况下才有助于构建列,这似乎不太可能。默认情况下,EL mempool 将尝试下载所有公共 blob。这消除了 CL 只需要观察总 blob 数据的某个子集的好处。
- 3.2. 我们需要通过以某种方式分片 EL mempool 来解决这种不对称性(或者承认公共 mempool 从长远来看是不可行的)。
- 3.2.1. mempool 的水平(blob 方式)分片最容易,但具有显着的缺点,可能会限制公共 mempool 的价值。
- 3.2.2. mempool 的垂直(列方式)分片与 CL 中完成的 blob 的垂直分片对齐。但是,它更难实现,并且需要强大的反 DoS 机制。
用 ♥ 和 markdown 制作。感谢阅读!–mike ░▒▓
-
当然,blob 发布对于欺诈证明和强制退出至关重要,这是 L2 的两个关键功能。我们强调确认规则方面,因为 L2 交易的默认路径是将排序器确认视为最终确认。↩︎
-
用户可以进一步等待 L1 区块的最终确定,作为第三次确认。↩︎
-
Terence 提到了一些其他原因,中心化排序器 L2 可能对时间敏感,但在 blob 可以发布而不显着影响 rollup 运营的情况下,仍然有很长的时间窗口。↩︎
-
CL gossip 中的许多技术细节都会影响 blob 通过子网传播的可能性。像
IHAVE, IWANT, IDONTWANT这样的控制消息会向你的对等方发出你拥有和需要哪些数据的信号。对于本文档,我们省略了这些细节。↩︎ -
这篇文章最初是关于 blob mempool 票证的市场设计的……但我们现在在这里,哈哈。↩︎
- 原文链接: hackmd.io/@mikeneuder/bl...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





