SeiDB深度解析
- blog.sei
- 发布于 2024-01-26 20:25
- 阅读 1235
SeiDB 是 Sei v2 的关键组件,旨在解决区块链状态膨胀问题,通过分离状态承诺层(SC)和状态存储层(SS),显著提升了性能,主要改进包括:减少活跃状态大小,降低历史数据增长率,改善状态同步时间,加快区块提交速度,同时确保归档节点的高性能。
Sei 更快、更高效的存储
如果你希望收到未来技术博客文章、产品新闻和开发者倡议的通知,你可以使用本文底部的表格注册我们的开发者邮件列表
设定场景
自 2023 年 8 月以来,Sei 一直在主网 beta 上运行,在此期间,它一直以 390 毫秒的速度完成区块,使其成为现存速度最快的链
最近,提出了 Seiv2——第一个并行化 EVM 区块链。此次升级将使 Sei 获得 Solana 和 Ethereum 的最佳优势——一个超优化的执行层,受益于 EVM 周围的工具和思想。该提案将使用乐观并行化来支持每秒处理的更多交易。
处理更多交易会导致创建更多的区块链状态,因此仅并行化运行时是不够的——还需要考虑状态管理。Sei v2 的主要组成部分之一是 SeiDB,它从根本上改变了状态访问、状态提交和状态存储的工作方式。
SeiDB 解决了并行执行的状态 i/o 问题,同时考虑了状态膨胀和状态同步时间,同时确保节点硬件要求保持较低水平。
这篇博文将介绍 SeiDB 最重要的部分。
主要内容
SeiDB 的主要内容是:
- 将活动状态大小减少 60%
- 将历史数据增长率降低约 90%
- 将状态同步时间缩短 1200%,区块同步时间缩短 2 倍
- 使区块提交时间提高 287 倍
- 提供更快的状态访问和状态提交,从而使整体 TPS 提高 2 倍
- 同时确保 Sei 归档节点能够实现与任何完整节点一样的高性能。

状态膨胀:区块链存储问题
活动状态
所有区块链都需要节点存储链上的数据,以便能够就链的状态达成共识。这些数据通常会随着时间的推移而增长。因此,当链状态增长到超过一定水平时,关键的链级操作会变得非常慢:
- 快照创建可能需要长达几个小时才能完成。这导致最新的快照与最新的区块高度相差太远,因此节点在完成状态同步后面临更长的追赶期
- 状态同步也会随着快照大小的增加而减慢。从快照恢复从几分钟变为几小时
- 区块同步可能需要几个小时才能完成,才能从快照高度赶上最新的链高度
- 验证器节点在运行很长时间后,会发现签名性能不佳,并且区块时间会增加
- 回滚单个区块可能需要几个小时才能完成
- 转储状态数据以进行调查需要几个小时,这使得调试和灾难恢复更加困难和麻烦
导致状态大小过大的另一个问题是写放大(使用的存储空间与实际存储的“有用”数据量之比)。使用 Sei v1 存储,此比率约为 2.5 倍。因此,要存储 10GB 的实际应用程序状态,需要 15GB 的元数据(总计 25GB)。
历史状态
历史数据也增长了很多。在 Sei V1 的 atlantic-2 测试网上,归档节点的磁盘使用量每天增长超过 150 GB——每周约 1TB!
如此规模的存储增长可能会导致几个负面影响:
-
随着节点运行时间的推移,性能会不断下降,例如 RPC 节点会开始落后,并且需要不断进行状态同步才能跟上。
-
以这种速度增加存储容量给服务提供商的基础设施带来了巨大的财务负担,这可能会变得难以维持。
-
归档节点将无法跟上链的步伐。
-
历史查询可能非常慢。
-
- *
进入 SeiDB:为最快的区块链提供更快的存储
为了不辜负作为最快区块链的声誉,Sei 的新存储层必须有效地处理状态膨胀问题。这将同时有助于加快区块时间和交易执行速度,从而提高 TPS。
Sei Labs 工程团队构建了 ADR-065(架构决策记录) 中 Cosmos SDK 团队提出的工作,以开发 SeiDB。
采取的主要方法是避免将所有内容存储在一个巨大的数据库中,而是将数据解耦到两个不同的层中:
- 状态承诺 (SC) - 这会将活动链状态数据存储在内存映射的 Merkle 树中,从而提供快速的交易状态访问和 Merkle 哈希
- 状态存储 (SS) - 专门设计并经过优化调整,供完整节点和归档节点提供历史查询
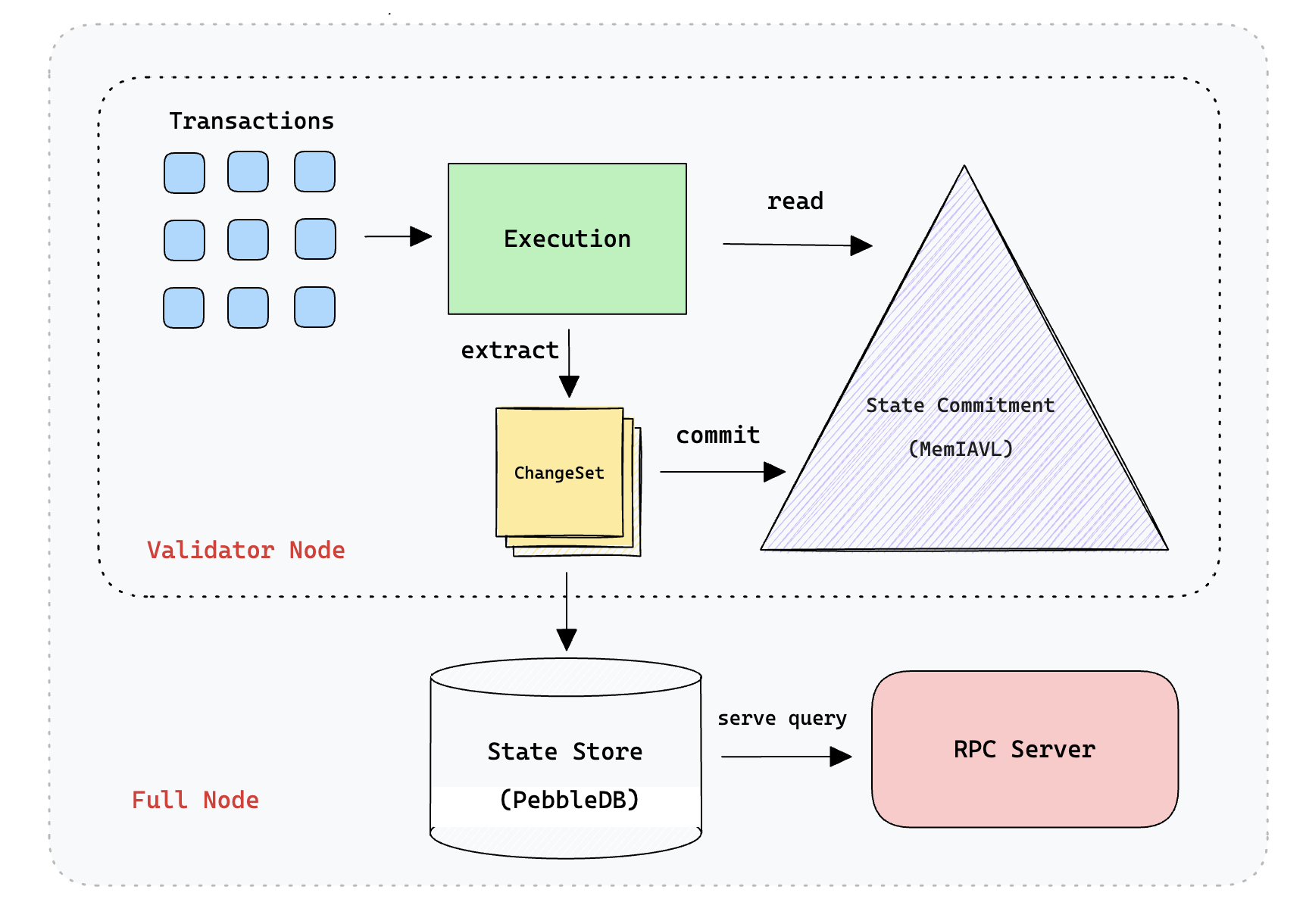
图 1:SeiDB 状态承诺和状态存储区别的示意图
状态承诺 (SC) 层
活动状态和历史数据的划分大大提高了 Sei 生态系统中所有节点运营商的性能。这种设计使 Sei Lab 的工程团队能够使用 MemIAVL 将当前链状态表示为内存映射的 IAVL 树。
反过来,这允许验证器节点使用 mmap 跟踪区块链状态,从而使状态访问达到 100 纳秒的数量级,而不是 100 微秒的数量级,这极大地改善了状态同步时间以及读/写放大。

当提交一个新区块时,SeiDB 首先从该区块的交易中提取变更集,并将这些更改应用到内存映射的 IAVL 树以计算区块哈希。然后,它将以异步方式将这些变更集刷新到预写日志 (WAL) 中。验证器节点不需要提供历史查询,因此只需要保留最新的几个区块。会定期对内存中的树进行快照并将其持久化到磁盘上。WAL 将包含自上次快照以来的变更集。当节点崩溃时,它可以通过从快照高度加载并重放 WAL 中的变更集来快速恢复到之前的状态。
基准
在 Sei 测试网和主网上进行的基准测试结果已经验证了这种方法。在 Sei v1 Atlantic-2 测试网上:
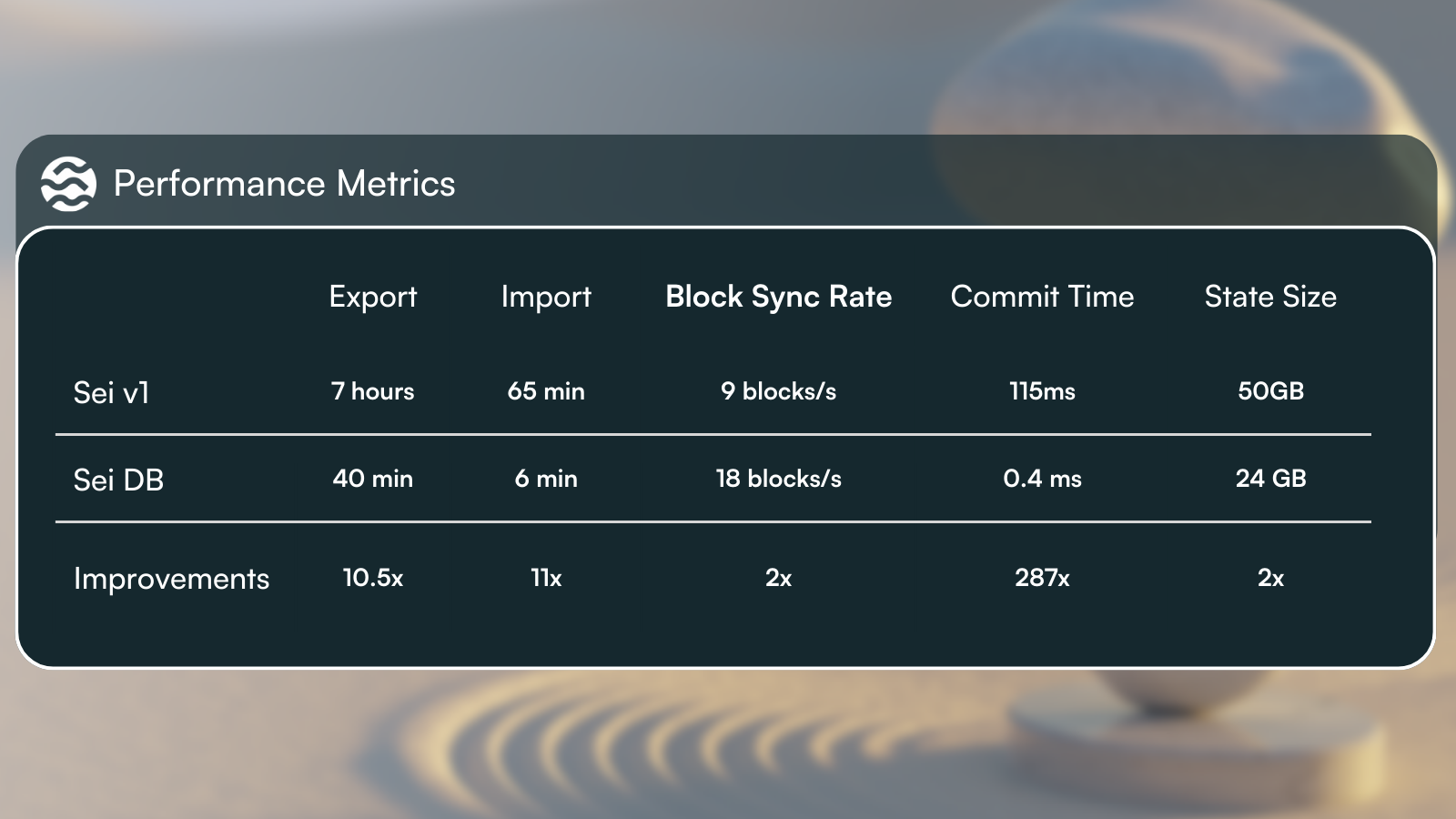 SeiDB 前后 Sei 之间基准性能改进
SeiDB 前后 Sei 之间基准性能改进
SeiDB 使状态同步速度提高了 1200%(这就是为什么图 3 中黄线比绿线小很多的原因)。这是因为元数据需求减少,并且从 MemIAVL 访问状态的读写速度更快。

由于 SeiDB 以异步方式提交所有交易状态,因此无论我们在单个区块中处理多少交易,提交延迟都将看起来恒定。我们最新的基准测试表明,切换到 SeiDB 后,ABCI 区块提交延迟最多可以提高 287 倍。
所有这些性能改进数字都是巨大的。这是一个坚实而快速的基础,将支持 Sei 网络上的验证器节点在未来发展。但是,对于需要保留历史数据的归档节点和 RPC 节点呢?SeiDB 也对它们进行了改进。
状态存储 (SS) 层
状态存储 (SS) 层旨在存储和提供历史链数据。在 Sei v1 中,版本化的 IAVL 树将存储在 LevelDB 后端。这将存储大量元数据(请参阅上面引用的写放大),并具有低效的架构,如果没有复杂的 IAVL 库,很难解释。
Sei Lab 的工程团队通过在 SS 层中存储原始键值对以及最少的元数据子集解决了这些问题。具有纯键值存储的优化架构(不使用哈希)可以更好地利用 LSM 树中的局部性。此外,修剪已变为异步,因此节点在打开时不会落后于链。
由于需要的元数据较少,这些修改至少使状态存储大小需求减少了 60%。通过 SeiDB 中更优化的 SS 存储,写放大已大大减少,从而使总数据增长率降低了 90%。因此,节点运行时间越长,从长远来看,我们将能够观察到更多的磁盘节省。

节点运营商可以利用这种减少的存储需求,以及大大减少的状态同步时间。这降低了基础设施成本并提高了运营效率。
灵活的数据库后端支持
SeiDB 认识到节点运营商有各种各样的需求和存储需求。因此,SS 的构建旨在支持各种后端,以允许运营商自由和灵活性。
使用 Sei 链键值数据进行了广泛的基准测试,测量了 RocksDB、SQLite 和 PebbleDB 的随机写入、读取和正向/反向迭代性能。进行这些实验是为了在内部告知 Sei V2 的设计,并为社区提供未来架构讨论和优化的起点。
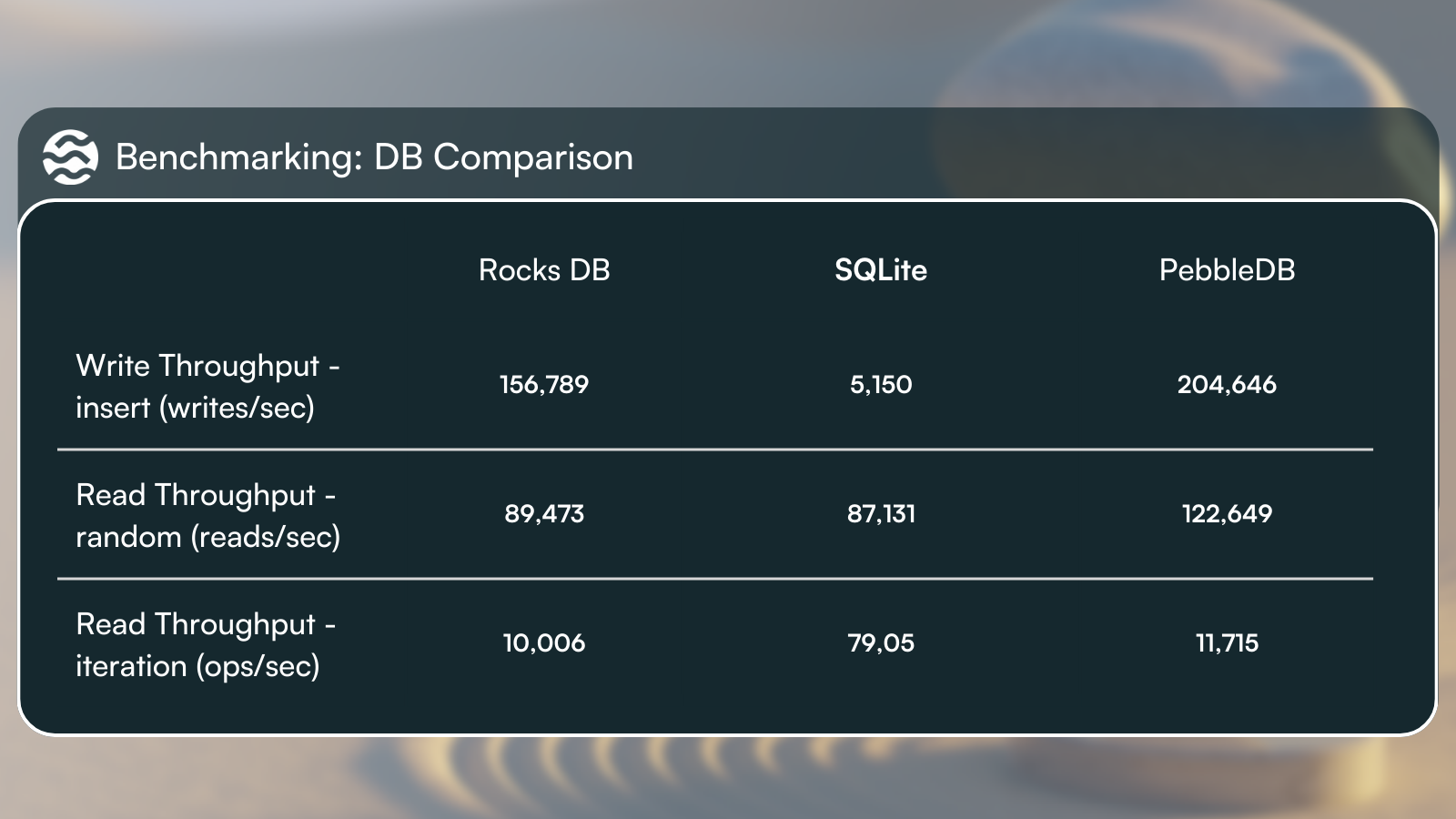 基准测试结果 - RocksDB、SQLite 和 PebbleDB 的比较
基准测试结果 - RocksDB、SQLite 和 PebbleDB 的比较
这种原始数据库性能使归档节点和 RPC 节点能够使用 Sei v2 以更可扩展和存储高效的方式提供历史查询。虽然 PebbleDB 在基准测试中取得了最佳性能,但使用这些数据库后端中的每一个都存在优势和劣势:
 数据库后端的优点和缺点
数据库后端的优点和缺点
资源:goleveldb 、CGO 、cockroackdb
结论
Sei Labs 工程团队显着优化了 Sei 区块链存储,并实施了高性能和高效的解决方案,从而在关键基准测试中实现了巨大的加速,并显着改善了不同类型节点运营商的 UX。
Sei Labs 工程团队对 SeiDB 的持续工作将提高 Sei 区块链的存储速度、性能和可靠性,并有助于提高 TPS 和吞吐量。如果你有兴趣阅读更多信息或参与有关技术架构和配置的讨论,你可以在 Sei 开发者论坛上查看原始的 SeiDB 提案。
我们要感谢 Cosmos SDK 的 Bez 和 Cronos 团队在 MemIAVL 提案中为这项工作做出的贡献。
如果你希望收到未来技术博客文章、产品新闻和开发者倡议的通知,你可以使用下面的表格注册我们的开发者邮件列表(当前成员将不会看到此选项):
注册 Sei 开发者邮件列表
订阅
已发送电子邮件!检查你的收件箱以完成注册。
没有垃圾邮件。随时取消订阅。
- 原文链接: blog.sei.io/developers/s...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





